Postgresql — кириллица в psql под windows
Содержание:
- Other Versions
- Swarm64 DA — PostgreSQL Accelerator
- Релизы
- Архитектура Клиент-Сервер¶
- Статьи
- Картирование¶
- Простое создание пространственной таблицы¶
- PostgreSQL 9.4 Now EOL
- Releases
- Current Version 42.2.16
- Updating
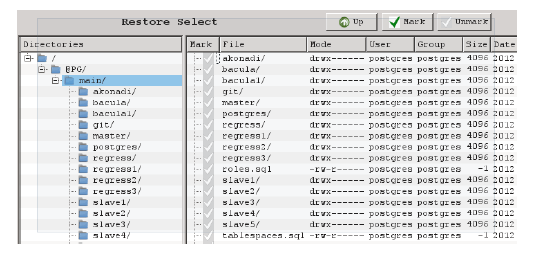
- Directories
- Простые запросы¶
- Пространственные запросы¶
- Завязка
- Bug Fixes and Improvements
- Наивно оптимизируем поиск
- Texcaller
Other Versions
Many other versions of the JDBC driver are available. This includes
development versions, compatibility with older JDKs, and previous
versions of the driver.
To determine JDK/JVM compatibility this following list matches up
versions of the JVM with the JDBC specification implemented.
- JDK 1.1 — JDBC 1. Note that with the 8.0
release JDBC 1 support has been removed, so look to update your
JDK when you update your server. - JDK 1.2, 1.3 — JDBC 2.
- JDK 1.3 + J2EE — JDBC 2 EE. This contains additional support
for javax.sql classes. - JDK 1.4, 1.5 — JDBC 3. This contains support
for SSL and javax.sql, but does not require J2EE as it has been
added to the J2SE release. - JDK 6 — JDBC 4.0 Support for JDBC4 methods is not complete,
but the majority of methods are implemented. - JDK 7 — JDBC 4.1 Support for JDBC4 methods is not complete,
but the majority of methods are implemented. - JDK 8 — JDBC 4.2 Support for JDBC4 methods is not complete,
but the majority of methods are implemented.
| Version | JDBC 4.0 | JDBC 4.1 | JDBC 4.2 | Source |
|---|
42.2.16
42.2.16 JDBC 4
42.2.16 JDBC 41
42.2.16 JDBC 42
42.2.16 JDBC Source
42.2.15
42.2.15 JDBC 4
42.2.15 JDBC 41
42.2.15 JDBC 42
42.2.15 JDBC Source
42.2.14
42.2.14 JDBC 4
42.2.14 JDBC 41
42.2.14 JDBC 42
42.2.14 JDBC Source
42.2.13
42.2.13 JDBC 4
42.2.13 JDBC 41
42.2.13 JDBC 42
42.2.13 JDBC Source
42.2.12
42.2.12 JDBC 4
42.2.12 JDBC 41
42.2.12 JDBC 42
42.2.12 JDBC Source
42.2.11
42.2.11 JDBC 4
42.2.11 JDBC 41
42.2.11 JDBC 42
42.2.11 JDBC Source
42.2.10
42.2.10 JDBC 4
42.2.10 JDBC 41
42.2.10 JDBC 42
42.2.10 JDBC Source
42.2.9
42.2.9 JDBC 4
42.2.9 JDBC 41
42.2.9 JDBC 42
42.2.9 JDBC Source
42.2.8
42.2.8 JDBC 4
42.2.8 JDBC 41
42.2.8 JDBC 42
42.2.8 JDBC Source
42.2.7
42.2.7 JDBC 4
42.2.7 JDBC 41
42.2.7 JDBC 42
42.2.7 JDBC Source
42.2.6
42.2.6 JDBC 4
42.2.6 JDBC 41
42.2.6 JDBC 42
42.2.6 JDBC Source
42.2.5
42.2.5 JDBC 4
42.2.5 JDBC 41
42.2.5 JDBC 42
42.2.5 JDBC Source
42.2.4
42.2.4 JDBC 4
42.2.4 JDBC 41
42.2.4 JDBC 42
42.2.4 JDBC Source
42.2.3
42.2.3 JDBC 4
42.2.3 JDBC 41
42.2.3 JDBC 42
42.2.3 JDBC Source
42.2.2
42.2.2 JDBC 4
42.2.2 JDBC 41
42.2.2 JDBC 42
42.2.2 JDBC Source
42.2.1
42.2.1 JDBC 4
42.2.1 JDBC 41
42.2.1 JDBC 42
42.2.1 JDBC Source
42.2.0
42.2.0 JDBC 4
42.2.0 JDBC 41
42.2.0 JDBC 42
42.2.0 JDBC Source
42.1.4
42.1.4 JDBC 4
42.1.4 JDBC 41
42.1.4 JDBC 42
42.1.4 JDBC Source
42.1.3
42.1.3 JDBC 4
42.1.3 JDBC 41
42.1.3 JDBC 42
42.1.3 JDBC Source
42.1.2
42.1.2 JDBC 4
42.1.2 JDBC 41
42.1.2 JDBC 42
42.1.2 JDBC Source
42.1.1
42.1.1 JDBC 4
42.1.1 JDBC 41
42.1.1 JDBC 42
42.1.1 JDBC Source
42.1.0
42.1.0 JDBC 4
42.1.0 JDBC 41
42.1.0 JDBC 42
42.1.0 JDBC Source
42.0.0
42.0.0 JDBC 4
42.0.0 JDBC 41
42.0.0 JDBC 42
42.0.0 JDBC Source
9.4.1212
9.4.1212 JDBC 4
9.4.1212 JDBC 41
9.4.1212 JDBC 42
9.4.1212 JDBC Source
9.4.1211
9.4.1211 JDBC 4
9.4.1211 JDBC 41
9.4.1211 JDBC 42
9.4.1211 JDBC Source
9.4.1210
9.4.1210 JDBC 4
9.4.1210 JDBC 41
9.4.1210 JDBC 42
9.4.1210 JDBC Source
9.4.1209
9.4.1209 JDBC 4
9.4.1209 JDBC 41
9.4.1209 JDBC 42
9.4.1209 JDBC Source
9.4.1208
9.4.1208 JDBC 4
9.4.1208 JDBC 41
9.4.1208 JDBC 42
9.4.1208 JDBC Source
9.4.1207
9.4.1207 JDBC 4
9.4.1207 JDBC 41
9.4.1207 JDBC 42
9.4.1207 JDBC Source
9.4 Build 1206
9.4-1206 JDBC 4
9.4-1206 JDBC 41
9.4-1206 JDBC 42
9.4-1206 JDBC Source
9.4 Build 1205
9.4-1205 JDBC 4
9.4-1205 JDBC 41
9.4-1205 JDBC 42
9.4-1205 JDBC Source
9.4 Build 1204
9.4-1204 JDBC 4
9.4-1204 JDBC 41
9.4-1204 JDBC 42
9.4-1204 JDBC Source
9.4 Build 1203
9.4-1203 JDBC 4
9.4-1203 JDBC 41
9.4-1203 JDBC 42
9.4-1203 JDBC Source
9.4 Build 1202
9.4-1202 JDBC 4
9.4-1202 JDBC 41
9.4-1202 JDBC 42
9.4-1202 JDBC Source
Swarm64 DA — PostgreSQL Accelerator
| Description | License | Pricing | Publisher | |
|---|---|---|---|---|
|
Swarm64 DA extends PostgreSQL (and EnterpriseDB Postgres) with performance acceleration features that enable PostgreSQL to:
Swarm64 DA achieves this by extending the PostgreSQL query engine with the following: Greater Parallelism Columnar indexing Data compression and IO reduction FPGA support Deployment flexibility |
Commercial | Swarm64 | View |
Релизы
PostgreSQL 11.4, 10.9, 9.6.14, 9.5.18, 9.4.23 и 12 Beta 2eVOL Monkey.Postgres Pro Standard 11.4.1, 10.9.1, 9.6.14.1, 9.5.17.1 и Postgres Pro Enterprise 11.4.1в документацииИзменения в EnterprisepgAdmin4 4.10версииpg_probackup 2.1.3Теперьbarman 2.8поддержкаWAL-G 0.2.9инструмента бэкапаrepmgr 4.4новой версииpg_partman 4.1.0новой версииdbForge Studio for PostgreSQL v.2.1новая версиятеперьpgFormatter 4.0симпатичная утилитаPsycopg2 2.8.3коннектораPgpool-II 4.0.5, 3.7.10, 3.6.17, 3.5.21 и 3.4.24ЗдесьHAProxy 2.0прочитать на русском языкеPostgreSQL JDBC 42.2.6этой версииpsqlODBC 11.01.0000этой версииPostGIS 3.0.0alpaha3здесьpostgres-checkup 1.1эта утилитаpgwatch2 v1.6вышлаpgBadger 11.0появилисьpgMustardумеет подсказывать
Архитектура Клиент-Сервер¶
PostgreSQL, как и другие СУБД, работает в качестве сервера в системе клиент-сервер.
Клиент отправляет серверу запрос и получает отклик. По такому же принципу работает сеть Интернет:
ваш браузер является клиентом, посылающим запрос, а веб-сервер возвращает обратно веб-страницу.
Запросы PostgreSQL производятся с помощью языка SQL, откликами обычно являются таблицы данных из базы данных.
Ничего не мешает серверу PostgreSQL находится на одном компьютере с клиентом.
Ваш клиент подключается к серверу по внутреннему IP-интерфейсу обратной связи, который не виден для других компьютеров (если вы не настроите иначе).
Статьи
PostgreSQL Deep Dive: PostgreSQL Defaults and Impact on Security — Part 1, 2Огромная двучастная статьяPostgres 12 highlight — SQL/JSON pathпродолжает обозреватьвот этупредыдущей серии Мишеля былиTable Access Methods and blackholesоказалисьWAL в PostgreSQL: 1. Буферный кешоткрываетИгра в прятки с оптимизатором. Гейм овер, это CTE PostgreSQL 12статьяЧто заморозили на feature freeze 2019. Часть I. JSONPathПрофессиональный PostgresрасшифровкаLinear Interpolation with PostgreSQLкак заполнить дырына InfluxDBDistributed PostgreSQL on a Google Spanner Architecture – Storage LayerрассказываютPostgreSQL logging best practicesпропагандируютОтказоустойчивость для СУБД PostgreSQLрассказываютWhy the RDBMS is the future of distributed databasesпишетManaging Query Execution Plans for Aurora PostgreSQLуправление планами запросовHypothetical Indexes in PostgreSQLразъясняетПодписывайтесь на канал postgresso!Идеи и пожелания присылайте на почту: news_channel@postgrespro.ru#15#14#13#12#11 (спец)#10#9#8#7#6#5#4#3#2#1
Картирование¶
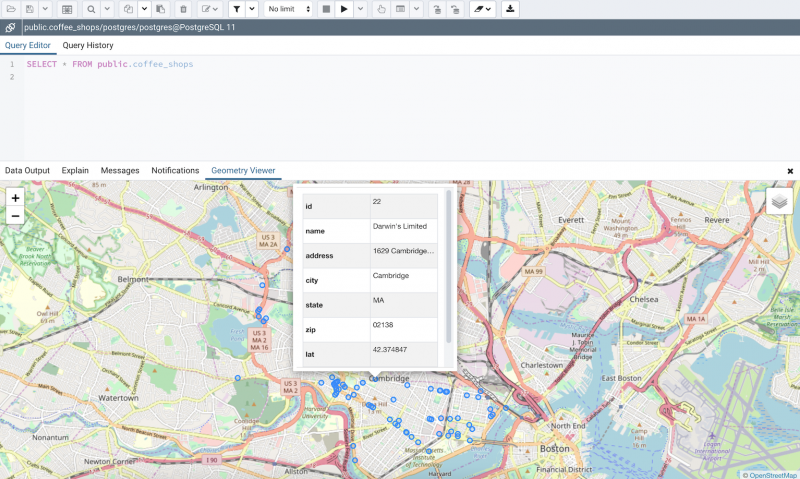
Для создания карты из данных PostGIS вам необходим клиент, с помощью которого вы сможете интерпретировать данные.
Многие из открытых ГИС могут делать это, например, Quantum GIS, gvSIG, uDig.
Далее будет показано, как сделать карту с помощью Quantum GIS.
- Запустите Quantum GIS и выберите Add PostGIS layers из меню Слой. Параметры для подключения к данным
- Natural Earth в PostGIS уже определены в выпадающем меню Соединения. Там же вы можете создать новое подключение к серверу и хранить настройки для быстрого доступа. Нажмите Edit, если хотите увидеть, какие параметры указаны для данных Natural Earth,
или нажмите Connect, чтобы продолжить:
Появится список пространственных таблиц базы данных:
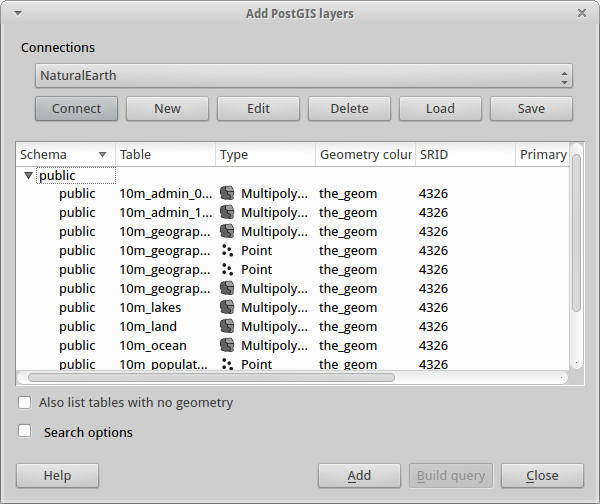
Выберите озёра (“Lakes”) и нажмите Add внизу (не Load«вверху, которая подгрузит параметры подключения базы данных),
после чего слой откроется в QGIS:

Простое создание пространственной таблицы¶
Большинство приложений OSGeo поддерживают импорт пространственных данных из файлов
в базу данных PostGIS. Для демонстрации этого будет использован QGIS.
Импорт шейп-файлов в PostGIS через QGIS можно сделать в с помощью дополнения PostGIS Manager.
Чтобы установить его, перейдите в меню Модули, далее Загрузить модули. QGIS загрузит самую
новую версию из репозитория (для этого вам потребуется работающее интернет-соединение).
Найдите PostGIS Manager и нажмите кнопку Install plugin.

В меню Модули должен появиться пункт PostGIS Manager.
Для запуска плагина также можно кликнуть по кнопке с логотипом PostGIS (слон с земным шаром), расположенной на панели.
После этого будет уставновлено соединение с базой данных Natural Earth. Оставьте поле пароль пустым, если будет необходимо его ввести.
Вы увидите основное окно управления: слева вы сможете выбрать таблицы из базы данных, в правой части — узнать информацию о них.
Вкладка Просмотр покажет небольшую карту.
Для примера был выбран слой “Населённые пункты”, карта была приближена к произвольному месту.
- Далее PostGIS Manager будет использован для импорта шейп-файла в базу данных. Мы используем данным о синдроме внезапной смерти у детей
- в Северной Каролине, которые входят в одно из дополнений статистического пакета R.
Из меню Data выберите опцию Load data from shapefile.
Нажмите кнопку ... и загрузите шейпф-айл sids.shp в пакет R maptools:
Не изменяя настроек в появившемся окне, нажмите Load:
Шейп-файл должен быть импортирован в PostGIS без ошибок. Закройте менеджер PostGIS и вернитесь в основное окно QGIS.
Подгрузите данные SIDS с помощью опции “Добавить слой PostGIS”.
Изменив порядок слоёв и заливок, вы сможете создать фоновую картограмму (хороплет),
отображающую количество детей, умерших от синдрома внезапной смерти в Северной Каролине.
PostgreSQL 9.4 Now EOL
This is the last release for PostgreSQL 9.4, which will no longer receive
security updates and bug fixes. PostgreSQL 9.4 introduced new features
such as JSONB support, the command, the ability to stream logical
changes to an output plugin, and more.
While we are very proud of this release, these features are also found in newer
versions of PostgreSQL. Many of these features have also received improvements,
and, per our versioning policy,
it is time to retire PostgreSQL 9.4.
To receive continued support, we suggest that you make plans to upgrade to a
newer, supported version of PostgreSQL. Please see the PostgreSQL
versioning policy for more
information.
Releases
| Version | Current minor | Supported | First Release | Final Release |
|---|---|---|---|---|
| 12 | 12.4 | Yes | October 3, 2019 | November 14, 2024 |
| 11 | 11.9 | Yes | October 18, 2018 | November 9, 2023 |
| 10 | 10.14 | Yes | October 5, 2017 | November 10, 2022 |
| 9.6 | 9.6.19 | Yes | September 29, 2016 | November 11, 2021 |
| 9.5 | 9.5.23 | Yes | January 7, 2016 | February 11, 2021 |
| 9.4 | 9.4.26 | No | December 18, 2014 | February 13, 2020 |
| 9.3 | 9.3.25 | No | September 9, 2013 | November 8, 2018 |
| 9.2 | 9.2.24 | No | September 10, 2012 | November 9, 2017 |
| 9.1 | 9.1.24 | No | September 12, 2011 | October 27, 2016 |
| 9.0 | 9.0.23 | No | September 20, 2010 | October 8, 2015 |
| 8.4 | 8.4.22 | No | July 1, 2009 | July 24, 2014 |
| 8.3 | 8.3.23 | No | February 4, 2008 | February 7, 2013 |
| 8.2 | 8.2.23 | No | December 5, 2006 | December 5, 2011 |
| 8.1 | 8.1.23 | No | November 8, 2005 | November 8, 2010 |
| 8.0 | 8.0.26 | No | January 19, 2005 | October 1, 2010 |
| 7.4 | 7.4.30 | No | November 17, 2003 | October 1, 2010 |
| 7.3 | 7.3.21 | No | November 27, 2002 | November 27, 2007 |
| 7.2 | 7.2.8 | No | February 4, 2002 | February 4, 2007 |
| 7.1 | 7.1.3 | No | April 13, 2001 | April 13, 2006 |
| 7.0 | 7.0.3 | No | May 8, 2000 | May 8, 2005 |
| 6.5 | 6.5.3 | No | June 9, 1999 | June 9, 2004 |
| 6.4 | 6.4.2 | No | October 30, 1998 | October 30, 2003 |
| 6.3 | 6.3.2 | No | March 1, 1998 | March 1, 2003 |
Current Version 42.2.16
This is the current version of the driver. Unless you have unusual
requirements (running old applications or JVMs), this is the driver
you should be using. It supports PostgreSQL 8.2 or newer and
requires Java 6 or newer. It contains support for SSL and the
javax.sql package.
- If you are using Java 8 or newer then you should use the JDBC 4.2 version.
- If you are using Java 7 then you should use the JDBC 4.1 version.
- If you are using Java 6 then you should use the JDBC 4.0 version.
- If you are using a Java version older than 6 then
you will need to use a JDBC3 version of the driver, which will by
necessity not be current, found in .
Updating
All PostgreSQL update releases are cumulative. As with other minor releases,
users are not required to dump and reload their database or use in
order to apply this update release; you may simply shutdown PostgreSQL and
update its binaries.
Users who have skipped one or more update releases may need to run additional,
post-update steps; please see the release notes for earlier versions for
details.
If you had previously executed on a sub-partition of a
partitioned table, and the partitioned table has a foreign-key reference from
another table, you may have to execute the on the other table, or
execute a if you have added rows since running .
The issue that caused this is fixed in this release, but you will have to
perform this step to ensure all of your data is cleaned up.
For more details, please see the
release notes.
Directories
| v13beta3 |
| v13beta2 |
| v13beta1 |
| v12.4 |
| v12.3 |
| v12.2 |
| v12.1 |
| v12.0 |
| v11.9 |
| v11.8 |
| v11.7 |
| v11.6 |
| v11.5 |
| v11.4 |
| v11.3 |
| v11.2 |
| v11.1 |
| v11.0 |
| v10.14 |
| v10.13 |
| v10.12 |
| v10.11 |
| v10.10 |
| v10.9 |
| v10.8 |
| v10.7 |
| v10.6 |
| v10.5 |
| v10.4 |
| v10.3 |
| v10.2 |
| v10.1 |
| v10.0 |
| v9.6.19 |
| v9.6.18 |
| v9.6.17 |
| v9.6.16 |
| v9.6.15 |
| v9.6.14 |
| v9.6.13 |
| v9.6.12 |
| v9.6.11 |
| v9.6.10 |
| v9.6.9 |
| v9.6.8 |
| v9.6.7 |
| v9.6.6 |
| v9.6.5 |
| v9.6.4 |
| v9.6.3 |
| v9.6.2 |
| v9.6.1 |
| v9.6.0 |
| v9.5.23 |
| v9.5.22 |
| v9.5.21 |
| v9.5.20 |
| v9.5.19 |
| v9.5.18 |
| v9.5.17 |
| v9.5.16 |
| v9.5.15 |
| v9.5.14 |
| v9.5.13 |
| v9.5.12 |
| v9.5.11 |
| v9.5.10 |
| v9.5.9 |
| v9.5.8 |
| v9.5.7 |
| v9.5.6 |
| v9.5.5 |
| v9.5.4 |
| v9.5.3 |
| v9.5.2 |
| v9.5.1 |
| v9.5.0 |
| v9.4.26 |
| v9.4.25 |
| v9.4.24 |
| v9.4.23 |
| v9.4.22 |
| v9.4.21 |
| v9.4.20 |
| v9.4.19 |
| v9.4.18 |
| v9.4.17 |
| v9.4.16 |
| v9.4.15 |
| v9.4.14 |
| v9.4.13 |
| v9.4.12 |
| v9.4.11 |
| v9.4.10 |
| v9.4.9 |
| v9.4.8 |
| v9.4.7 |
| v9.4.6 |
| v9.4.5 |
| v9.4.4 |
| v9.4.3 |
| v9.4.2 |
| v9.4.1 |
| v9.4.0 |
| v9.3.25 |
| v9.3.24 |
| v9.3.23 |
| v9.3.22 |
| v9.3.21 |
| v9.3.20 |
| v9.3.19 |
| v9.3.18 |
| v9.3.17 |
| v9.3.16 |
| v9.3.15 |
| v9.3.14 |
| v9.3.13 |
| v9.3.12 |
| v9.3.11 |
| v9.3.10 |
| v9.3.9 |
| v9.3.8 |
| v9.3.7 |
| v9.3.6 |
| v9.3.5 |
| v9.3.4 |
| v9.3.3 |
| v9.3.2 |
| v9.3.1 |
| v9.3.0 |
| v9.2.24 |
| v9.2.23 |
| v9.2.22 |
| v9.2.21 |
| v9.2.20 |
| v9.2.19 |
| v9.2.18 |
| v9.2.17 |
| v9.2.16 |
| v9.2.15 |
| v9.2.14 |
| v9.2.13 |
| v9.2.12 |
| v9.2.11 |
| v9.2.10 |
| v9.2.9 |
| v9.2.8 |
| v9.2.7 |
| v9.2.6 |
| v9.2.5 |
| v9.2.4 |
| v9.2.3 |
| v9.2.2 |
| v9.2.1 |
| v9.2.0 |
| v9.1.24 |
| v9.1.23 |
| v9.1.22 |
| v9.1.21 |
| v9.1.20 |
| v9.1.19 |
| v9.1.18 |
| v9.1.17 |
| v9.1.16 |
| v9.1.15 |
| v9.1.14 |
| v9.1.13 |
| v9.1.12 |
| v9.1.11 |
| v9.1.10 |
| v9.1.9 |
| v9.1.8 |
| v9.1.7 |
| v9.1.6 |
| v9.1.5 |
| v9.1.4 |
| v9.1.3 |
| v9.1.2 |
| v9.1.1 |
| v9.1.0 |
| v9.0.23 |
| v9.0.22 |
| v9.0.21 |
| v9.0.20 |
| v9.0.19 |
| v9.0.18 |
| v9.0.17 |
| v9.0.16 |
| v9.0.15 |
| v9.0.14 |
| v9.0.13 |
| v9.0.12 |
| v9.0.11 |
| v9.0.10 |
| v9.0.9 |
| v9.0.8 |
| v9.0.7 |
| v9.0.6 |
| v9.0.5 |
| v9.0.4 |
| v9.0.3 |
| v9.0.2 |
| v9.0.1 |
| v9.0.0 |
| v8.4.22 |
| v8.4.21 |
| v8.4.20 |
| v8.4.19 |
| v8.4.18 |
| v8.4.17 |
| v8.4.16 |
| v8.4.15 |
| v8.4.14 |
| v8.4.13 |
| v8.4.12 |
| v8.4.11 |
| v8.4.10 |
| v8.4.9 |
| v8.4.8 |
| v8.4.7 |
| v8.4.6 |
| v8.4.5 |
| v8.4.4 |
| v8.4.3 |
| v8.4.2 |
| v8.4.1 |
| v8.4.0 |
| v8.3.23 |
| v8.3.22 |
| v8.3.21 |
| v8.3.20 |
| v8.3.19 |
| v8.3.18 |
| v8.3.17 |
| v8.3.16 |
| v8.3.15 |
| v8.3.14 |
| v8.3.13 |
| v8.3.12 |
| v8.3.11 |
| v8.3.10 |
| v8.3.9 |
| v8.3.8 |
| v8.3.7 |
| v8.3.6 |
| v8.3.5 |
| v8.3.4 |
| v8.3.3 |
| v8.3.1 |
| v8.3.0 |
| v8.2.23 |
| v8.2.22 |
| v8.2.21 |
| v8.2.20 |
| v8.2.19 |
| v8.2.18 |
| v8.2.17 |
| v8.2.16 |
| v8.2.15 |
| v8.2.14 |
| v8.2.13 |
| v8.2.12 |
| v8.2.11 |
| v8.2.10 |
| v8.2.9 |
| v8.2.7 |
| v8.2.6 |
| v8.2.5 |
| v8.2.4 |
| v8.2.3 |
| v8.2.2 |
| v8.2.1 |
| v8.2.0 |
| v8.1.23 |
| v8.1.22 |
| v8.1.21 |
| v8.1.20 |
| v8.1.19 |
| v8.1.18 |
| v8.1.17 |
| v8.1.16 |
| v8.1.15 |
| v8.1.14 |
| v8.1.13 |
| v8.1.11 |
| v8.1.10 |
| v8.1.9 |
| v8.1.8 |
| v8.1.7 |
| v8.1.6 |
| v8.1.5 |
| v8.1.4 |
| v8.1.3 |
| v8.1.2 |
| v8.1.1 |
| v8.1.0 |
| v8.0.26 |
| v8.0.25 |
| v8.0.24 |
| v8.0.23 |
| v8.0.22 |
| v8.0.21 |
| v8.0.20 |
| v8.0.19 |
| v8.0.18 |
| v8.0.17 |
| v8.0.15 |
| v8.0.14 |
| v8.0.13 |
| v8.0.12 |
| v8.0.11 |
| v8.0.10 |
| v8.0.9 |
| v8.0.8 |
| v8.0.7 |
| v8.0.6 |
| v8.0.5 |
| v8.0.4 |
| v8.0.3 |
| v8.0.2 |
| v8.0.1 |
| v8.0 |
| v7.4.30 |
| v7.4.29 |
| v7.4.28 |
| v7.4.27 |
| v7.4.26 |
| v7.4.25 |
| v7.4.24 |
| v7.4.23 |
| v7.4.22 |
| v7.4.21 |
| v7.4.19 |
| v7.4.18 |
| v7.4.17 |
| v7.4.16 |
| v7.4.15 |
| v7.4.14 |
| v7.4.13 |
| v7.4.12 |
| v7.4.11 |
| v7.4.10 |
| v7.4.9 |
| v7.4.8 |
| v7.4.7 |
| v7.4.6 |
| v7.4.5 |
| v7.4.4 |
| v7.4.3 |
| v7.4.2 |
| v7.4.1 |
| v7.4 |
| v7.3.21 |
| v7.3.20 |
| v7.3.19 |
| v7.3.18 |
| v7.3.17 |
| v7.3.16 |
| v7.3.15 |
| v7.3.14 |
| v7.3.13 |
| v7.3.12 |
| v7.3.11 |
| v7.3.10 |
| v7.3.9 |
| v7.3.8 |
| v7.3.7 |
| v7.3.6 |
| v7.3.5 |
| v7.3.4 |
| v7.3.3 |
| v7.3.2 |
| v7.3.1 |
| v7.3 |
| v7.2.8 |
| v7.2.7 |
| v7.2.6 |
| v7.2.5 |
| v7.2.4 |
| v7.2.3 |
| v7.2.2 |
| v7.2.1 |
| v7.2 |
| v7.1.3 |
| v7.1.2 |
| v7.1.1 |
| v7.1 |
| v7.0.3 |
| v7.0.2 |
| v7.0.1 |
| v7.0 |
| v6.5 |
| v6.4 |
| v6.3 |
| v6.2 |
| v6.1 |
| v6.0 |
| v1.09 |
| v1.08 |
Простые запросы¶
Все самые обычные операторы SQL могут быть использованы для выбора данных из таблицы PostGIS:
demo=# SELECT * FROM cities; id | name | the_geom ----+-----------------+---------------------------------------------------- 1 | London, England | 0101000020E6100000BBB88D06F016C0BF1B2FDD2406C14940 2 | London, Ontario | 0101000020E6100000F4FDD478E94E54C0E7FBA9F1D27D4540 3 | East London,SA | 0101000020E610000040AB064060E93B4059FAD005F58140C0 (3 строки)
Это возвращает нам бессмысленные значения координат в шестнадцатеричной системе.
Если вы хотите увидеть вашу геометрию в текстовом формате WKT, используйте функцию ST_AsText(the_geom) или ST_AsEwkt(the_geom).
Вы также можете использовать функции ST_X(the_geom), ST_Y(the_geom), чтобы получить числовые значения координат.
Пространственные запросы¶
Мы уже увидели, как получить геометрию из текстовых данных WKT с помощью функции ST_GeomFromText.
Большинство таких функций начинаются с ST (“пространственный тип”) и описаны в документации PostGIS.
Мы используем одну из них, чтобы ответить на практический вопрос: на каком расстоянии в метрах
друг от другах находятся три города с названием Лондон, учитывая сферичность земли?
demo=# SELECT p1.name,p2.name,ST_Distance_Sphere(p1.the_geom,p2.the_geom) FROM cities AS p1, cities AS p2 WHERE p1.id > p2.id;
name | name | st_distance_sphere
-----------------+-----------------+--------------------
London, Ontario | London, England | 5875766.85191657
East London,SA | London, England | 9789646.96784908
East London,SA | London, Ontario | 13892160.9525778
(3 строки)
Этот запрос возвращает расстояние в метрах между каждой парой городов
Обратите внимание как часть ‘WHERE’
предотвращает нас от получения расстояния от города до самого себя (расстояние всегда будет равно нулю) и расстояния в обратном порядке
(расстояние от Лондона, Англия до Лондона, Онтарио будет таким же как от Лондона, Онтарио до Лондона, Англия).
Попробуйте ещё раз без ‘WHERE’ и посмотрите, что произойдёт
Мы также можем рассчитать расстояния на сфере, используя различные функции и указывая называния сфероида,
параметры главных полуосей и коэффициента обратного сжатия:
Завязка
Я поддерживаю относительно большой проект, в котором есть публичный поиск по документам. В базе лежит ~500 тысяч документов общим объемом ~3,6 Гб. Суть поиска такова: пользователь заполняет форму, в которой есть и полнотекстовый запрос, и фильтрация по множеству полей в БД, в том числе и с join-ами.
Поиск работает (точнее, работал) через Sphinx, и работал не очень хорошо. Основные проблемы были такими:
- Индексирование отъедало порядка 8 Гб оперативной памяти. На сервере с 8 Гб ОЗУ это проблема. Память свопилась, это приводило к ужасной производительности.
- Индекс строился примерно 40 минут. Ни о какой консистентности поисковых результатов речи не шло, индексирование запускалось раз в день.
- Поиск работал долго. Особенно долго осуществлялись запросы, которым соответствовало большое количество документов: огромное количестов id-шников приходилось передавать из сфинкса в базу, и сортировать по релевантности на бэкэнде.
Из-за этих проблем возникла задача — оптимизировать полнотекстовый поиск. У этой задачи есть два решения:
- Подтюнить Sphinx: настроить realtime-индекс, хранить в индексе атрибуты для фильтрации.
- Использовать встроенный FTS PostgreSQL.
Решено было реализовывать второе решение: так можно нативно обеспечить автообновление индекса, избавиться от долгого общения между двумя сервисами и мониторить один сервис вместо двух.
Казалось бы, хорошее решение. Но проблемы поджидали впереди.
Начнем с самого начала.
Bug Fixes and Improvements
This update also fixes over 75 bugs that were reported in the last several
months. Some of these issues affect only version 12, but may also affect all
supported versions.
Some of these fixes include:
- Fix for partitioned tables with foreign-key references where
would not remove all data. If you have previously used
on a partitioned table with foreign-key references
please see the «Updating» section for verification and cleanup steps. - Fix failure to add foreign key constraints to table with sub-partitions (aka a
multi-level partitioned table). If you have previously used this functionality,
you can fix it by either detaching and re-attaching the affected partition, or
by dropping and re-adding the foreign key constraint to the parent table. You
can find more information on how to perform these steps in the
ALTER TABLE
documentation. - Fix performance issue for partitioned tables introduced by the fix for
CVE-2017-7484 that now allows the planner to use statistics on a child table for
a column that the user is granted access to on the parent table when the query
contains a leaky operator. - Several other fixes and changes for partitioned tables, including disallowing
partition key expressions that return pseudo-types, such as . - Fix for logical replication subscribers for executing per-column
triggers. - Fix for several crashes and failures for logical replication subscribers and
publishers. - Improve efficiency of logical replication with .
- Ensure that calling on a physical replication
slot will persist changes across restarts. - Several fixes for the walsender processes.
- Improve performance of hash joins with very large inner relations.
- Fix placement of «Subplans Removed» field in EXPLAIN output by placing it with
its parent Append or MergeAppend plan. - Several fixes for parallel query plans.
- Several fixes for query planner errors, including one that affected joins to
single-row subqueries. - Several fixes for MCV extend statistics, including one for incorrect
estimation for OR clauses. - Improve efficiency of parallel hash join on CPUs with many cores.
- Ignore the option when performing an index creation, drop, or
reindex on a temporary table. - Fall back to non-parallel index builds when a parallelized CREATE INDEX has no
free dynamic shared memory slots. - Several fixes for GiST & GIN indexes.
- Fix possible crash in BRIN index operations with , and
data types. - Fix support for BRIN hypothetical indexes.
- Fix failure in when a column referenced in a
expression is added or changed in type earlier in the same
statement. - Fix handling of multiple triggers on a foreign table.
- Fix off-by-one result for for BC dates.
- Prevent unwanted lowercasing and truncation of RADIUS authentication
parameters in the file. - Several fixes for GSSAPI support, including having libpq accept all
GSS-related connection parameters even if the GSSAPI code is not compiled in. - Several fixes for and when run in parallel mode.
- Fix crash with when trying to execute a remote query on the
remote server such as . - Disallow NULL category values in the function of
to prevent crashes. - Several fixes for Windows, including a race condition that could cause timing
oddities with . - Several ecpg fixes.
For the full list of changes available, please review the
release notes.
Наивно оптимизируем поиск
Играться с боевой базой мы не будем, конечно — создадим тестовую базу. В ней ~12 тысяч документов. Запрос из примера там выполняется ~35 секунд. Непростительно долго!
Индекс
В первую очередь, конечно, надо добавить индекс. Самый простой способ: функциональный индекс.
Создаваться такой индекс будет долго — на тестовой базе ему понадобилось ~26 секунд. Ему надо пройтись по базе и вызвать функцию to_tsvector для каждой записи. Хотя поиск он всё же ускоряет до 12 секунд, это всё ещё непростительно долго!
Многократный вызов
Для решения этой проблемы нужно хранить в базе. При изменении данных в таблице с документами, конечно, надо обновлять его — через триггеры в БД, с помощью бэкэнда.
Сделать это можно двумя способами:
- Добавить колонку типа в таблицу с документами.
- Создать отдельную таблицу с one-to-one связью с таблицей документов, и хранить там вектора.
Плюсы первого подхода: отсутствие join-ов при поиске.
Плюсы второго подхода: отсутствие лишних данных в таблице с документами, она остается такого же размера, как и раньше. При бэкапе не придется тратить время и место на , которые бэкапить вообще не нужно.
Оба похода ведут к тому, что данных на диске становится вдвое больше: хранятся тексты документов и их вектора.
Я для себя выбрал второй подход, его преимущества для меня весомей.
Добавим данные в связанную таблицу и создадим индекс. Добавление данных заняло 24 секунды на тестовой базе, а создание индекса — всего 2,7 секунды. Обновление индекса и данных, как видим, существенно не ускорилось, но сам индекс теперь можно обновить очень быстро.
А во сколько раз ускорился сам поиск?
Невероятно! И это несмотря на join и . Уже вполне приемлемый результат, большую часть времени отнимет не поиск, а вычисление для каждой из строк.
Многократный вызов
Кажется, мы успешно решили все наши проблемы, кроме этой. 44 миллисекунды — вполне достойное время выполнения. Кажется, хэппи-энд близок? Не тут-то было!
Запустим тот же самый запрос без и сравним результаты.
1,7 мс! В тридцать раз быстрее! Для боевой базы результаты ~150 мс и 1,5 секунды. Разница в любом случае на порядок, и 1,5 секунды — не то время, которое хочется ждать ответа от базы. Что же делать?
Выключить сортировку по релевантности нельзя, сократить количество строк для подсчета — нельзя (база должна вычислить для всех совпавших документов, иначе их нельзя отсортировать).
Кое-где в интернете рекомендуют кэшировать наиболее частые запросы (и, соответственно, вызов ts_rank). Но мне подобный подход не нравится: правильно отобрать нужные запросы довольно сложно, и поиск все равно будет тормозить на запросах неправильных.
Очень хотелось бы, чтобы после прохода по индексу данные приходили в уже отсортированном виде, как это делает тот же Sphinx. К сожалению, из коробки в PostgreSQL ничего такого сделать не получится.
Но нам повезло — так умеет делать индекс RUM. Подробно о нём можно почитать, например, в презентации его авторов. Он хранит дополнительную информацию о запросе, которая позволяет прямо в индексе оценивать т.н. «расстояние» между и и выдавать сортированный результат сразу после сканирования индекса.
Но выкидывать GIN и устанавливать RUM сразу не стоит. У него есть минусы, плюсы и границы применения — об этом я напишу в следующей статье.
Texcaller
| Description | License | Pricing | Publisher | |
|---|---|---|---|---|
|
Texcaller is a convenient interface to the TeX command line tools that handles all kinds of errors without much fuzz. It is written in plain C, is fairly portable, and has no external dependencies besides TeX. These PostgreSQL functions are simple wrappers around the Texcaller C interface library functions, bringing TeX typesetting into the world of relational databases. Invalid TeX documents are handled gracefully by simply returning NULL rather than aborting with an error. On failure as well as on success, additional processing information is provided via NOTICEs. |
Open source | Volker Grabsch | View |
Note: The PostgreSQL Global Development Group do not endorse or
recommend any products listed, and cannot vouch for the quality or reliability
of any of them.