Индексы в postgresql
Содержание:
- What is PostgreSQL?
- Краткий справочник по psql (текстовый интерфейс PostgreSQL)
- Установка и настройка
- Полезные команды PostgreSQL
- Описание БД
- Тюнинг индексов
- Трюки с SQL от DBA. Небанальные советы для разработчиков БД
- Поддержка стандартов, возможности, особенности
- Работа с базами данных глазами разработчика
- Как мы в 2020 году изобретали процесс разработки, отладки и доставки в прод изменений базы данных
- Скрипт изменения владельца базы данных и таблиц postgresql
- Мониторинг
- Моделирование отказоустойчивых кластеров на базе PostgreSQL и Pacemaker
- Введение
- Вывод peзультатов запроса не в строку, а столбцом¶
What is PostgreSQL?
PostgreSQL is a powerful, open source object-relational database system that uses and extends the SQL language combined with many features that safely store and scale the most complicated data workloads. The origins of PostgreSQL date back to 1986 as part of the POSTGRES project at the University of California at Berkeley and has more than 30 years of active development on the core platform.
PostgreSQL has earned a strong reputation for its proven architecture, reliability, data integrity, robust feature set, extensibility, and the dedication of the open source community behind the software to consistently deliver performant and innovative solutions. PostgreSQL runs on all major operating systems, has been ACID-compliant since 2001, and has powerful add-ons such as the popular PostGIS geospatial database extender. It is no surprise that PostgreSQL has become the open source relational database of choice for many people and organisations.
Getting started with using PostgreSQL has never been easier — pick a project you want to build, and let PostgreSQL safely and robustly store your data.
Краткий справочник по psql (текстовый интерфейс PostgreSQL)
24
Dec
В PostgreSQL есть немало интерфейсов. Из графических лично я предпочитаю pgadmin3 (он должен быть в репозитариях большинства Linux дистрибутивов). В этом справочнике будет описан текстовый – psql. Его я нахожу даже более удобным, чем sqlplus для Oracle.
Справочник специально создавался кратким для того, чтобы описать команды, которые наиболее часто используются. Разделим справочник на 3 части:
- Файлы (они же команды) PostgreSQL
- Команды запуска psql
- Команды интерактивной оболочки psql
1. Файлы (они же команды) PostgreSQL
- psql – программа для работы с объектами PostgreSQL
- createdb и dropdb – создание и удаление базы данных (соответственно)
- createuser и dropuser – создание и пользователя (соответственно)
- pg_ctl – программа предназначенная для решения общих задач управления (запуск, останов, настройка параметров и т.д.)
- postmaster – многопользовательский серверный модуль PostgreSQL (настройка уровней отладки, портов, каталогов данных)
- initdb – создание новых кластеровPostgreSQL (не запускайте под root !)
- initlocation – программа для создания каталогов для вторичного хранения баз данных
- vacuumdb – физическое и аналитическое сопровождение БД
- pg_dump – архивация и восстановление данных
- pg_dumpall – оболочка для pg_dump, которая работает сразу со всем кластером БДPostgreSQL
- pg_restore – восстановление БД из архивов (.tar, .tar.gz)
2. Команды запуска psql
- psql -c (или –command) – запуск команды без входа в интерактивный режим
- -f (или –file) – также как и -c , но команда читается с файла
- -l (или –list) – выводит список баз данных, к которым можно подключиться (если появляется ошибка: psql: FATAL: role “_your_userName_” does not exist ), то значит нужно указать имя пользователя явно.
- -U (или –username) – указываем имя пользователя (например postgres)
- -W (или –password) – приглашение на ввод пароля
- -d – имя базы данных
- -h – имя хоста (сервера)
- -s – пошаговый режим, то есть, нужно будет подтверждать все команды
- –S – одно-строчный режим, то есть, переход на новую строку будет выполнять запрос (когда надоело вводить “;” после каждой SQL команды! )
- -V – (не строчная v) – версия PostgreSQL без входа в интерактивный режим
Примечание: Ключи можно комбинировать, например, psql -U postgres -c “select current_date”
3. Комманды интерактивной оболочки psql (Примечание: после этих команд точку с запятой ставить (как при выполнении SQL-запросов ) не нужно)
- \connect db_name – подключиться к базе с именем db_name
- \du – список пользователей
- \dp (или \z) – список таблиц, представлений, последовательностей, прав доступа к ним
- \di – индексы
- \ds – последовательности
- \dt – таблицы
- \dv – представления
- \dS – системные таблицы
- \d+ – описание таблицы
- \o – пересылка результатов запроса в файл (Пример: а) \o today.txt б) select select current_date ; и тогда все результаты будут записываться в today.txt. Чтобы все запросы снова выводились не в файл, а на консоль необходимо еще раз ввести \o (без указания параметров)
- \l – список баз данных
- \i – читать входящие данные из файла
- \e – открывает текущее содержимое буфера запроса в редакторе (если не указана в окружении переменная EDITOR, то будет использоваться по умолчанию vi)
- \d “table_name” – описание таблицы (вместо table_name указать свою таблицу)
- \i запуск команды из внешнего файла, например \i /home/user/query.sql
- \pset – команда настройки параметров форматирования
- \echo – выводит сообщение
- \set – устанавливает значение переменной среды. Эта команда без параметров выводит список текущих переменных (\unset – удаляет). Полезный пример: а) echo “‘one’,’two’, ‘three’” > test.sql (создаем файл с данными test.sql)
- б) \set data `cat test.sql` (в psql устанавливаем переменную data, которая получает результат от команды cat test.sql)
- в) \echo :data (результат проверки переменной – ‘one’,’two’, ‘three’ )
- г) select :data ; (используем переменную). Можно использовать любую SQL команду.
- Вот так вот легко можно использовать параметры команд с внешних файлов!
- \? – справочник psql
- \help – справочник SQL
- \q (или Ctrl+D) – выход с программы
Примечание: Рекомендую называть таблицы и поля строчными символами.PostgreSQL чувствителен к региструв названиях объектов, но не к командам (select и SELECT – не имеет значения). Но если уже есть такие объекты БД, то тогда их нужно указывать в кавычках, например, SELECT * FROM “MyTable“. Иначе будете удивлены почему выводится сообщение типа:ERROR: relation “myTableName” does not exist
Успехов!
Posted by realitman on December 24, 2008 in Database
Установка и настройка
В данном разделе представлена инструкция по установки и настройке PostgreSQL для разных ОС
Установка
Если установка происходит на macOS, то процесс установки можно запустить командой:
brew install postgresql
На Linux СУБД устанавливается так:
sudo apt-get install postgresql postgresql-contrib
После того, как все загружено и установлено, можно проверить, все ли в порядке, и какая стоит версия PostgreSQL. Для этого выполните следующую команду:
postgres --version
Инструкция по установке в цифровом формате
Настройка
Работа с PostgreSQL может быть произведена через командную строку (терминал) с использованием утилиты psql – инструмент командной строки PostgreSQL.
Необходимо ввести следующую команду:
psql postgres (для выхода из интерфейса используйте \q)
Этой командой запускается утилита psql. Хотя есть много сторонних инструментов для администрирования PostgreSQL, нет необходимости их устанавливать, т. к. psql удобен и отлично работает.
Если нужна помощь, введите (или ) в psql-терминале. Появится список всех доступных параметров справки. Вы можете ввести , если вам нужна помощь по конкретной команде. Например, если ввести в консоли psql, отобразится синтаксис команды .
1 Description update rows of a table
2 WITH RECURSIVE with_query [,
3 UPDATE ONLY table_name * AS alias
4 SET { column_name = { expression | DEFAULT } |
5 ( column_name [, ) = ( { expression | DEFAULT } [, ) |
6 ( column_name [, ) = ( sub-SELECT )
7 } [,
8 FROM from_list
9 WHERE condition | WHERE CURRENT OF cursor_name
10 RETURNING * | output_expression AS output_name [,
Для начала необходимо проверить наличие существующих пользователей и баз данных. Выполните следующую команду, чтобы вывести список всех баз данных:
\list или \l
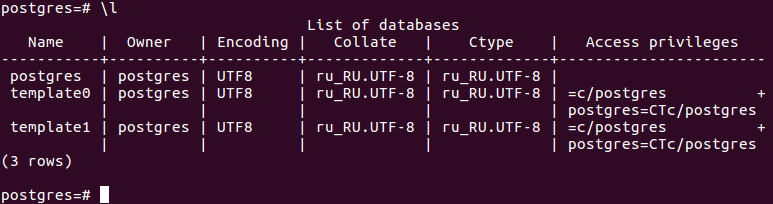 Рисунок 1 — Результат выполнения операции \l
Рисунок 1 — Результат выполнения операции \l
На рисунке выше вы видите три базы данных по умолчанию и суперпользователя postgres, которые создаются при установке PostgreSQL.
Чтобы вывести список всех пользователей, выполните команду . Атрибуты пользователя postgres говорят нам, что он суперпользователь.
 Рисунок 2 — Результат выполнения операции \du
Рисунок 2 — Результат выполнения операции \du
Полезные команды PostgreSQL
Выйти из клиента PostgreSQL:
\q
Показать список баз данных PostgreSQL:
\l
Показать список таблиц:
\dt
Показать список пользователей (ролей):
\du
Показать структуру таблицы:
\d table_name
Переименовать базу данных:
ALTER DATABASE db RENAME TO newdb;
Удалить базу данных:
drop database db_name;
Изменить текущую базу данных в PostgreSQL (вы не сможете переименовать или удалить текущую базу данных):
\connect db_name или более короткий alias: \c db_name
Удалить роль (пользователя):
DROP ROLE user_name;
Роль не будет удалена, если у нее есть привелегии — возникнет ошибка ERROR: role cannot be dropped because some objects depend on it.
Нужно удалить привелегии у роли, например если нужно удалить роль admin2, нужно выполнить последовательность комманд с Drop Owned:
db=# REASSIGN OWNED BY admin2 TO postgres; REASSIGN OWNED db=# DROP OWNED BY admin2; DROP OWNED db=# drop role admin2; DROP ROLE
Дать права пользователю/роли на логин (role is not permitted to log in):
ALTER ROLE admin2 WITH login;
Описание БД
psql имеет достаточное количество специальных команд, которые помогают проще ориентироваться в базе данных. Для списка таблиц наберите , для списка индексов — , представлений — и т.д. Приятно, что все эти команды параметром принимают шаблон, по которому будет производиться фильтрация. Т.е. если вас интересуют только таблицы, начинающиеся на user, то выполните .
Там, где я работаю, частенько используются схемы. Грубо говоря это пространство имён для таблиц. По умолчанию есть только одна схема public. Когда вы создаёте там таблицу foo, обратиться к ней можно будет через public.foo. В нашей же компании для каждого клиента используется своя схема.
Иногда мне нужно проверить есть ли в схеме клиента определённая таблица (например, users). Для этого мне достаточно набрать , и я получу список всех таблиц с указанием схем.
Для получения информации о конкретном объекте таблицы или представления служит команда . Она показывает следующие вещи,
- список столбцов вместе с их типами и значениями по умолчанию
- индексы
- ограничения
- внешние ключи
- триггеры
Для функций есть подобная команда \df. При вызове без аргументов, она покажет список всех функций. У меня их слишком много, так что с вашего позволения воспользуюсь фильтром:
Когда работаете со своими собственными функциями, то простого вывода сигнатуры оказывается мало. Тут на помощь приходит команда для редактирования. Передайте ей имя редактируемой функции в качестве первого параметра, и она откроется в $EDITOR. Если определение функции было задано с помощью , то после сохранения и закрытия редактора она будет обновлена.
Если же вам нужно только посмотреть описание функции, то закройте редактор с помощью ненулевого кода возврата (для vim это ). Таким образом она не будет обновлена и выполнена. psql в таком случае понимает, что что-то пошло не так, и не будет ничего делать.
Тюнинг индексов
Postgres Statistics Collectorpg_stat_…
Примечание о статистике сред разработки
- когда у машины меньше памяти, PostgreSQL может быть не в состоянии выполнить Hash Join, в противном случае он сможет и сделает это быстрее.
- если в таблице не так много строк (как в базе данных разработки), PostgresSQL может предпочесть выполнять последовательное сканирование таблицы, а не использовать доступный индекс. Когда размеры таблиц невелики, Seq Scan может быть быстрее. (Примечание: вы можете запустить в сеансе, чтобы оптимизатор предпочел использовать индексы, даже если последовательное сканирование может быть быстрее. Это полезно при работе с базами данных разработки, в которых нет большого количества данных)
Трюки с SQL от DBA. Небанальные советы для разработчиков БД
- Перевод
- Tutorial
Когда я начинал свою карьеру разработчика, моей первой работой стала DBA (администратор базы данных, АБД). В те годы, ещё до AWS RDS, Azure, Google Cloud и других облачных сервисов, существовало два типа АБД:
- АБД инфраструктуры отвечали за настройку базы данных, конфигурирование хранилища и заботу о резервных копиях и репликации. После настройки БД инфраструктурный администратор время от времени «настраивал экземпляры», например, уточнял размеры кэшей.
- АБД приложения получал от АБД инфраструктуры чистую базу и отвечал за её архитектуру: создание таблиц, индексов, ограничений и настройку SQL. АБД приложения также реализовывал ETL-процессы и миграцию данных. Если команды использовали хранимые процедуры, то АБД приложения поддерживал и их.
АБД приложений обычно были частью команд разработки. Они обладали глубокими познаниями по конкретной теме, поэтому обычно работали только над одним-двумя проектами. Инфраструктурные администраторы баз данных обычно входили в ИТ-команду и могли одновременно работать над несколькими проектами.
Поддержка стандартов, возможности, особенности
PostgreSQL
PostgreSQL поддерживает большинство возможностей стандарта SQL: 2011, ACID-совместимая и транзакционная (включая большинство DDL утверждения) избегает проблемы блокировки с помощью механизма Многоверсионное управление параллельным доступом (MVCC), обеспечивает иммунитет к «грязному» чтению и полую сериализационность; управляет комплексными SQL запросами используя множество индексированных методов, которые недоступны в других базах данных; имеет обновляемые представления и материализованные представления, триггеры, внешние ключи; поддерживает функции и хранимые процедуры, и другие возможности расширения, и имеет множество расширений, написанных третьими лицами. В дополнение к возможности работы с основными фирменными и с открытым исходным кодом базами данных, PostgreSQL поддерживает миграцию из них, путем своей обширной поддержки стандарта SQL и доступных инструментов миграции. Фирменные расширения в базах данных, таких как Oracle можно эмулировать с помощью встроенных и сторонних расширений совместимости с открытым исходным кодом. Последние версии также обеспечивают репликацию самой базы данных для доступности и масштабируемости.
PostgreSQL является кросплотформенной и работает на множестве операционных систем, включая Linux, FreeBSD, macOS, Solaris, и Microsoft Windows. Начиная с Mac OS X 10.7 Lion Server, PostgreSQL это стандартная база данных по умолчанию, и клиентские инструменты PostgreSQL идут в комплекте с настольной версией. Подавляющее большинство дистрибутивов Linux имеет PostgreSQL доступным в поддерживаемых пакетах.
PostgreSQL разработан PostgreSQL Global Development Group, разнообразной группой из многих компаний и отдельных вкладчиков. Это свободное и открытое программное обеспечение, распространяемое по условиям Лицензии PostgreSQL, разрешительной лицензии свободного программного обеспечения.
Поскольку СУБД PostgreSQL выпускается под либеральной лицензией, её можно бесплатно использовать, модифицировать и распространять для любых целей, включая личные, коммерческие или академические.
На данный момент (версия 9.4.5), в PostgreSQL имеются следующие ограничения:
| Максимальный размер базы данных | Нет ограничений |
| Максимальный размер таблицы | 32 Тбайт |
| Максимальный размер записи | 1,6 Тбайт |
| Максимальный размер поля | 1 Гбайт |
| Максимум записей в таблице | Нет ограничений |
| Максимум полей в записи | 250—1600, в зависимости от типов полей |
| Максимум индексов в таблице | Нет ограничений |
Сильными сторонами PostgreSQL считаются:
- высокопроизводительные и надёжные механизмы транзакций и репликации;
- расширяемая система встроенных языков программирования: в стандартной поставке поддерживаются PL/pgSQL, [PL/Perl, PL/Python и PL/Tcl; дополнительно можно использовать PL/Java, PL/PHP, PL/Py, PL/R, PL/Ruby, PL/Scheme, PL/sh и PL/V8, а также имеется поддержка загрузки C-совместимых модулей ;
- поддержка со стороны многих языков программирования: C\C++, Java, Perl, Python, Ruby, ECPG, Tcl, PHP и других.
- наследование;
- легкая расширяемость.
Работа с базами данных глазами разработчика
Когда вы разрабатываете новый функционал с использованием базы данных, цикл разработки обычно включает следующие этапы (но не ограничивается ими):
Написание SQL миграции → написание кода → тестирование → релиз → мониторинг.
В этой статье я хочу поделиться некоторыми практическими советами как можно сократить время этого цикла на каждом из этапов, при этом не снизив качество, а скорее даже повысив его.
Поскольку мы в компании работаем с PostgreSQL, а серверный код пишем на Java, то примеры будут основаны на этом стеке, хотя большинство идей не зависят от используемой БД и языка программирования.
Как мы в 2020 году изобретали процесс разработки, отладки и доставки в прод изменений базы данных
На дворе 2020 год и фоновым шумом вы уже привыкли слышать: «Кубернетес — это ответ!», «Микросервисы!», «Сервис меш!», «Сесурити полиси!». Все вокруг бегут в светлое будущее.
Подходы в том, что касается баз данных, в нашей компании более консервативны, чем в прикладных приложениях. Крутится база данных у нас не в кубернетесе, а на железе или в виртуалке. Для изменений базы данных процессинга платежных сервисов у нас есть устоявшийся процесс, который включает в себя множество автоматических проверок, большое ревью и релиз с участием DBA. Количество проверок и привлекаемых людей в этом случае негативно влияет на time-to-market. С другой стороны, он отлажен и позволяет надежно вносить изменения в продакшен, минимизируя вероятность что-то сломать. А если что-то сломалось, то нужные люди уже включены в процесс починки. Этот подход делает работу основного сервиса компании стабильнее.
Большинство новых реляционных баз данных для микросервисов мы заводим на PostgreSQL. Отлаженный процесс для Oracle хоть и надёжный, но несет с собой избыточную сложность для маленьких БД. Тащить тяжёлые процессы из прошлого в светлое будущее никто не хочет. Проработкой процесса для светлого будущего заранее никто не занялся. В итоге получили отсутствие стандарта и разножопицу.
Если хотите узнать, к каким проблемам это привело и как мы их порешали, — добро пожаловать под кат.
Скрипт изменения владельца базы данных и таблиц postgresql
#!/bin/bash
usage()
{
cat << EOF
usage: 0 options
This script set ownership for all table, sequence and views for a given database
Credit: Based on https://stackoverflow.com/a/2686185/305019 by Alex Soto
Also merged changes from @sharoonthomas
OPTIONS:
-h Show this message
-d Database name
-o Owner
EOF
}
DB_NAME="web"
NEW_OWNER="postgres"
while getopts "hd:o:" OPTION
do
caseOPTION in
h)
usage
exit 1
;;
d)
DB_NAME=OPTARG
;;
o)
NEW_OWNER=OPTARG
;;
esac
done
if ] || ]
then
usage
exit 1
fi
for tbl in `psql -qAt -c "select tablename from pg_tables where schemaname = 'public';" {DB_NAME}` \
`psql -qAt -c "select sequence_name from information_schema.sequences where sequence_schema = 'public';"{DB_NAME}` \
`psql -qAt -c "select table_name from information_schema.views where table_schema = 'public';" {DB_NAME}` ;
do
psql -c "alter table \"tbl\" owner to {NEW_OWNER}"{DB_NAME} ;
done
Отправка postgresql в rsyslog > fluentd > kibana
Макет для rsyslog.d
ModLoad imfileInputFileName /var/log/postgresql/postgresql-9.4-main.log InputFileTag postgresql-9.4-main.logInputFileStateFile postgresql-9.4-main.log.state InputFileFacility local6InputRunFileMonitor $template simple, " %msg%" local6.* @;simple
Мониторинг
-
Monitoring Database Activity
-
pgFouine — a PostgreSQL log analyzer
- bucardo.org check_postgres — Perl cкрипт для мониторинга более 20 параметров, определяющих состояние СУБД PostgreSQL.
Текущую активность базы данных легко оценить с помощью команды ps, для вывода в реальном времени (с задержкой 1 секунда) можно использовать утилиту watch:
# watch -n 1 'ps auxww | grep ^postgres' postgres 14164 0.0 0.0 188492 5296 ? S Dec13 0:46 /usr/bin/postmaster -p 5432 -D /var/lib/pgsql/data postgres 14166 0.0 0.0 159904 1264 ? Ss Dec13 0:05 postgres: logger process postgres 14168 0.0 0.1 188636 27208 ? Ss Dec13 0:49 postgres: writer process postgres 14169 0.0 0.0 188492 1348 ? Ss Dec13 0:23 postgres: wal writer process postgres 14170 0.0 0.0 188804 1752 ? Ss Dec13 0:17 postgres: autovacuum launcher process postgres 14171 0.0 0.0 160176 1468 ? Ss Dec13 0:45 postgres: stats collector process postgres 21596 0.0 0.1 190228 30476 ? Ss Dec27 0:58 postgres: postgres mbill 127.0.0.1(37047) idle postgres 21597 0.0 0.0 189716 5672 ? Ss Dec27 0:00 postgres: postgres mbill 127.0.0.1(37048) idle
Так как для каждого клиента создаётся своя копия процесса postmaster, то это позволяет подсчитать число активных клиентов. Статусная строка даёт информацию о состоянии клиента. Фразы writer process, stats buffer process и stats collector process соответствуют системным процессам, запущенным самим PostgreSQL при старте. Пользовательские процессы имеют статусную строку вида:
postgres: «пользователь» «база» «хост» «статус»
«пользователь», «база» и «хост» соответствуют имени пользователя «пользователь» подсоединявшегося к базе «база» с компьютера «хост». «статус» может принимать следующие параметры:
- idle — ожидание команды от клиента,
- idle in transaction — ожидание команды от клиента внутри транзакции (между BEGIN и окончанием транзакции),
- SQL- команда — выполняется эта команда, например, SELECT,
- waiting — ждём когда разблокируется занятая другим процессом таблица. Для уточнения из-за чего возникла блокировка, нужно анализировать представление pg_locks.
Моделирование отказоустойчивых кластеров на базе PostgreSQL и Pacemaker
Введение
К этому решению возник резонный вопрос: насколько отказоустойчивым будет отказоустойчивый кластер? Чтобы это исследовать, я разработал тестовый стенд, который имитирует различные отказы на узлах кластера, ожидает восстановления работоспособности, восстанавливает отказавший узел и продолжает тестирование в цикле. Изначально этот проект назывался hapgsql, но со временем мне наскучило название, в котором только одна гласная. Поэтому отказоустойчивые базы данных (и float IP, на них указывающие) я стал именовать krogan (персонаж из компьютерной игры, у которого все важные органы дублированы), а узлы, кластеры и сам проект — tuchanka (планета, где живут кроганы).
Вывод peзультатов запроса не в строку, а столбцом¶
Ключ \x
Покажу на примере, как это выглядит (это очень хорошо работает на запросах со множеством столбцов и «узким» экраном)
denis=# select * from pg_stat_activity; datid | datname | procpid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | xact_start | query_start | waiting | current_query --------+---------+---------+----------+---------+------------------+-------------+-----------------+-------------+-------------------------------+------------------------------+------------------------------+---------+--------------------------------- 629830 | denis | 13205 | 629829 | denis | psql | | | -1 | 2012-11-10 11:57:05.634017+06 | 2012-11-10 11:59:11.27402+06 | 2012-11-10 11:59:11.27402+06 | f | select * from pg_stat_activity; (1 row) -- Включаю альтернативный режим отображения результатов запроса denis=# \x Expanded display is on. denis=# select * from pg_stat_activity; -----+-------------------------------- datid | 629830 datname | denis procpid | 20187 usesysid | 629829 usename | denis application_name | psql client_addr | client_hostname | client_port | -1 backend_start | 2012-11-07 23:29:00.264029+06 xact_start | 2012-11-07 23:29:47.653051+06 query_start | 2012-11-07 23:29:47.653051+06 waiting | f current_query | select * from pg_stat_activity;