Работа с hdd через терминал на ubuntu/debian
Содержание:
Подключение Яндекс Диска
Статью с настройкой дисков завершу описанием подключения Яндекс.Диска. Я лично давно и интенсивно его использую. У меня есть статья по созданию резервной копии сайта на яндекс.диск. Статья хоть и старая, но актуальная. Я продолжаю использовать предложенные там решения.
Яндекс диск можно подключить как системный диск по webdav. Скажу сразу, что работает это так себе, я давно им не пользуюсь в таком виде. Мне больше нравится работать с ним через консольный клиент linux.
Устанавливаем консольный клиент yandex-disk на Debian.
# echo "deb http://repo.yandex.ru/yandex-disk/deb/ stable main" | tee -a /etc/apt/sources.list.d/yandex-disk.list > /dev/null # apt install gnupg # wget http://repo.yandex.ru/yandex-disk/YANDEX-DISK-KEY.GPG -O- | apt-key add - # apt update && apt install yandex-disk
Дальше запускаете начальную настройку.
# yandex-disk setup
После этого яндекс диск подключен к системе и готов к работе. Посмотреть его статус можно командой.
# yandex-disk status
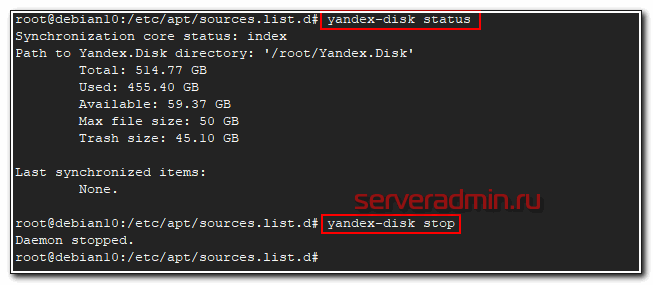
Остановить или запустить Яндекс.Диск можно командами.
# yandex-disk stop # yandex-disk start
Файл конфигурации находится по адресу /root/.config/yandex-disk/config.cfg. Туда, к примеру, можно добавить список папок исключений, которые не нужно синхронизировать.
exclude-dirs="dir1,exclude/dir2,path/to/another/exclude/dir"
Консольный клиент поддерживает символьные ссылки. Я много где использовал его. В основном в скриптах по автоматизации бэкапов. К примеру, я останавливал сервис яндекс диска, готовил бэкапы к отправке. Упаковывал их архиватором с разбивкой архивов по размеру. Потом создавал символьные ссылки в папке яндекс диска и запускал синхронизацию. Когда она заканчивалась, удалял локальные файлы и останавливал синхронизацию.
Яндекс диск сильно тормозит и падает, если у вас много мелких файлов. Мне доводилось хранить в нем бэкапы с сотнями тысяч файлов. Передать их в облако напрямую было невозможно. Я паковал их в архивы по 2-10 Гб и заливал через консольный клиент. Сразу могу сказать, что это решение в пользу бедных. Этот облачный диск хорош для домашних нужд пользователей и хранения семейных фоток и видео. Когда у вас большие потоки данных, которые нужно постоянно обновлять, работа с яндекс диском становится сложной.
Во-первых, трудно мониторить такие бэкапы. Во-вторых, тяжело убедиться в том, что то, что ты залил в облако, потом нормально скачается и распакуется из бэкапа. Как запасной вариант для архивов, куда они будут складываться раз в неделю или месяц, подойдет. Но как основное резервное хранилище точно нет. Какие только костыли я не придумывал для Яндекс.Диска в процессе промышленной эксплуатации. В итоге все равно почти везде отказался. Да, это очень дешево, но одновременно и очень ненадежно. Он иногда падает. Это хорошо, что упал, можно отследить и поднять. Так же он может зависнуть и просто ничего не синхронизировать, при этом служба будет работать. Все это я наблюдал, когда пытался синхронизировать сотни гигабайт данных. Иногда у меня это получалось 🙂
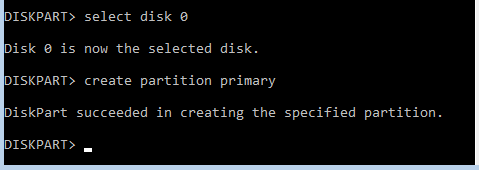
3: Удаление и уменьшение размеров компонентов LVM
Уменьшение размера логического тома
Чтобы уменьшить логический том, сначала создайте резервную копию данных (поскольку в случае ошибки при работе с логическим томом данные могут быть утеряны).
Запросите объём используемого пространства.
В данном случае используется около 512 М пространства. Теперь вы можете оптимизировать размер тома.
Демонтируйте файловую систему.
Убедитесь, что файловая система в рабочем состоянии. Для этого введите:
После этого можно уменьшить размер файловой системы с помощью встроенных инструментов. Файловая система Ext4 предоставляет инструмент resize2fs. Укажите новый размер файловой системы.
Примечание: Уменьшая размер системы или тома, всегда оставляйте буферное пространство и своевременно создавайте бэкап данных.
Затем можно изменить размер логического тома. Для этого введите:
LVM предупредит вас о риске потери данных. Чтобы продолжить, введите y.
После уменьшения логического тома снова проверьте файловую систему:
Затем можно снова смонтировать файловую систему:
Удаление логического тома
Чтобы удалить логический том, используйте lvremove.
Демонтируйте логический том:
Затем удалите его с помощью команды:
Чтобы подтвердить операцию, введите y.
Удаление группы томов
Чтобы удалить группу томов вместе со всеми её логическими томами, используйте vgremove.
Прежде чем удалить группу томов, нужно удалить все зависимые от неё логические тома. Как минимум нужно демонтировать их.
Затем можно удалить группу томов:
Подтвердите операцию. Если в этой группе томов остался хотя бы один используемый логический том, команда запросит подтверждения на его удаление.
Удаление физического тома
Процедура удаления физического тома зависит от того, используется ли он в LVM.
Если том используется, нужно переместить его физические экстенты в другое место. При этом группа томов должна иметь достаточно места, чтобы обработать эти физические экстенты.
Если вы используете сложные типы логических томов, вам могут потребоваться дополнительные физические тома, даже если у вас достаточно свободного места.
Если в группе томов достаточно физических томов для обработки экстентов, переместите экстенты в другой физический том:
Этот процесс займёт некоторое время.
Переместив экстенты, удалите физический том из группы.
Команда удалит освободившийся физический том. Затем вы можете удалить метку физического тома с устройства хранения:
LVMUbuntuUbuntu 18.04
fdisk -l
Команда, близкая по функциональности к parted -l, однако, предоставляющая более обширный вывод разделов (с дисками /dev/ram*), что может затруднять восприятие. В целом также позволяет просмотреть размеры дисков и разделов.
# fdisk -l Disk /dev/xvda: 5 GiB, 5368709120 bytes, 10485760 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0xfb148422 Device Boot Start End Sectors Size Id Type /dev/xvda1 2048 8388607 8386560 4G 83 Linux /dev/xvda2 8390654 10483711 2093058 1022M 5 Extended /dev/xvda5 8390656 10483711 2093056 1022M 82 Linux swap / Solaris Disk /dev/xvdb: 5 GiB, 5368709120 bytes, 10485760 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x6b14d070 Device Boot Start End Sectors Size Id Type /dev/xvdb1 2048 10485759 10483712 5G 83 Linux
Посмотреть свободное место на диске
Рассмотрим теперь вопрос, как удобнее всего смотреть свободное место на диске. Тут особо вариантов нет — используется известная и популярная утилита df.
# df -h
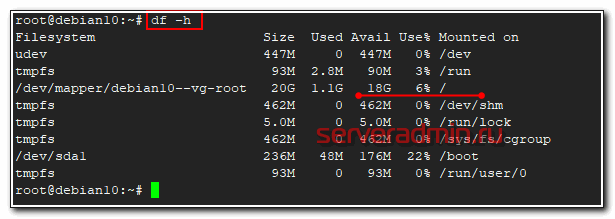
Команда показывает информацию и заполнении всех примонтированных дисков, в том числе и сетевых, если они присутствуют в системе. Нужно понимать, что эта информация не всегда достоверная. Вот пример такой ситуации — Диск занят на 100% и не понятно чем, df и du показывают разные значения.
Сразу же покажу удобную комбинацию команд, чтобы посмотреть, кто в данной директории занимает больше всего места. Директории выстроятся в список, начиная с самой объемной и далее. В моем примере будут выведены 10 самых больших папок в каталоге.
# du . --max-depth=1 -ah | sort -rh | head -10
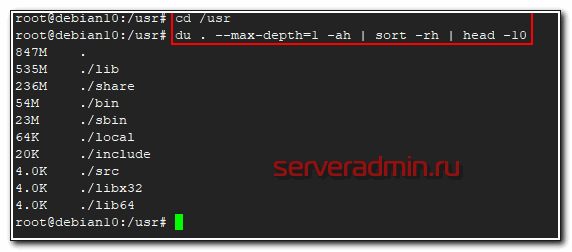
В первой строке будет объем самой директории /usr, а далее вложенные в нее. Привожу пример небольшого скрипта, который я люблю использовать, чтобы оценить размер директорий, к примеру, в архиве бэкапов и сохранить информацию в текстовый файл. Актуально, если у вас не настроен мониторинг бэкапов в zabbix.
echo "==================================" >> dir_size.txt echo "Dirs size `date +"%Y-%m-%d_%H-%M"`" >> dir_size.txt echo "==================================" >> dir_size.txt du -s *| sort -nr | cut -f 2- | while read a;do du -hs $a >> dir_size.txt ;done
На выходе останется файл dir_size.txt следующего содержания.
================================== Dirs size 2019-09-04_18-16 ================================== 3.2T resad 2.0T winshare 1.7T mail 1.2T doc 957G share 43G web 17G hyperv 6.5G zabbix 5.2G onlyoffice 525M databases
В целом, по свободному месту на дисках все. Утилит df и du достаточно, чтобы закрыть этот вопрос.
Проверка диска на колоченные секторы в linux с помощью badblocks
Badblocks — стандартная утилита Linuх для проверки (Тестирование Инвентаризация Допинг-контроль Проверка подлинности Служебная проверка Проверка орфографии Проверка на дорогах Камеральная налоговая проверка Выездная налоговая проверка Проверка) на колоченные секторы. Она устанавливается по-умолчанию практически в любой дистрибутив и с ее помощью можно проверить как твердый диск, так и внешний накопитель. Для начала давайте посмотрим, какие накопители подключены к ушей системе и какие на них имеются разделы. Для этого нам нужна еще одна стандартная утилита Linux — fdisk.
Собрать список битых секторов можно с помощью команды badblocks.
Делается это так:
Где /dev/hda1 — это разоблачил диска, что вы хотите проверить.
Желательно делать проверку в однопользовательском режиме, когда это не внешний диск. Тогда его просто стоит отмонтировать. После этого мы можем швырнуть утилиту fsck, явно указав ей список битых секторов для того, чтобы она их подметить как «битые» и попыталась восстановить с них данные. Делается это так:
Где ext4 — это тип файловой системы нашего разоблачила диска, а /dev/hda1 — сам раздел диска.
Метеопараметром -l мы говорим утилите fdisk, что нам нужно показать список разделов и выйти. Теперь, когда мы знаем, какие разделы у нас есть, мы можем проверить их на битые секторы. Для этого мы станем использовать утилиту badblocks следующим образом:
Если же в итоге были найдены битые секторы, то нам надо дать указание операционной системе не вписывать в них информацию в будущем. Для этого нам понадобятся утилиты Linux для работы с файловыми системами:
Проверка диска на ошибки и bad blocks
С выходом файловых систем ext4 и xfs я практически забыл, что такое проверка диска на ошибки. Сейчас прикинул и ни разу не вспомнил, чтобы у меня были проблемы с файловой системой. Раньше с ext3 или ufs на freebsd проверка диска на ошибки было обычным делом после аварийного выключения или еще каких бед с сервером. Ext4 и xfs в этом плане очень надежны.
В основном ошибки с диском вызваны проблемами с железом. Как посмотреть параметры smart я уже показал выше. Но если у вас все же появились какие-то проблемы с файловой системой, то решить их можно с помощью fsck (File System Check). Обычно она входит в базовый состав системы. Запустить проверку можно либо указав непосредственно раздел или диск, либо точку монтирования. Раздел при этом должен быть отмонтирован.
# umount /dev/sdb1 # fsck /dev/sdb1 fsck from util-linux 2.33.1 e2fsck 1.44.5 (15-Dec-2018) /dev/sdb1: clean, 11/1310720 files, 109927/5242619 blocks
Проверка завершена, ошибок у меня не обнаружено. Так же у fsck есть необычная опция, которая не указана в документации или man. Запустив fsck с ключем -c можно проверить диск на наличие бэд блоков.
# fsck -c /dev/sdb1
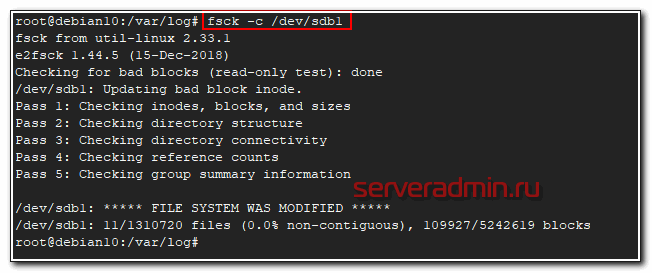
Насколько я понимаю, проверка выполняет посекторное чтение и просто сообщает о том, что найден бэд блок. Теоретически, можно собрать все эти блоки в отдельный файл и затем передать их утилите e2fsck, которая сможет запомнить эти бэды и исключить из использования.
# fsck -c /dev/sdb1 > badblocks.txt # e2fsck -l badblocks.txt /dev/sdb1
На практике я не проверял как это работает и имеет ли вообще смысл в таких действиях. Если с диском замечены хоть малейшие проблемы, я его сразу меняю.
Block devices
provide buffered access to hardware devices and allow reading and writing blocks of any size and alignment.
Block device names
The beginning of the device name specifies the kernel’s used driver subsystem to operate the block device.
Warning: Kernel name descriptors for block devices are not persistent and can change each boot, they should not be used in configuration files.
This article or section needs expansion.
SCSI
Storage devices, like hard disks, SSDs and flash drives, that support the SCSI command (SCSI, SAS, UASP), ATA (PATA, SATA) or USB mass storage connection are handled by the kernel’s SCSI driver subsystem. They all share the same naming scheme.
The name of these devices starts with . It is then followed by a lower-case letter starting from for the first discovered device (), for the second discovered device (), and so on. Existing partitions on each device will be listed with the number that is assigned to them in the partition table, e.g. for the partition , for partition , and so on.
Summary:
- — device , the first discovered device.
- — partition on device .
- — device , the fifth discovered device.
- — partition on device .
NVMe
The name of storage devices, like SSDs, that are attached via NVM Express (NVMe) starts with . It is then followed by a number starting from for the device controller, for the first discovered NVMe controller, for the second, and so on. Next is the letter «n» and a number starting from expressing the device on a controller, i.e. for first discovered device on first discovered controller, for second discovered device on first discovered controller, and so on. Existing partitions on each device will be listed with the letter «p» and the number that is assigned to them in the partition table. For example, for the partition with number on first discovered device on first discovered controller, for partition , and so on.
Summary:
- — device on controller , the first discovered device on the first discovered controller.
- — partition on device on controller .
- — device on controller , the fifth discovered device on the third discovered controller.
- — partition on device on controller .
MMC
This article or section needs expansion.
SD cards, MMC cards and are handled by the kernel’s driver and name of those devices start with . It is then followed by a number starting from for the device, i.e. for first discovered device, for second discovered device and so on. Existing partitions on each device will be listed with the letter «p» and the number that is assigned to them in the partition table. The partition with number in the partition table would be , partition with number would be , and so on.
Summary:
- — device , the first discovered device.
- — partition on device .
- — device , the fifth discovered device.
- — partition on device .
SCSI optical disc drive
The name of optical disc drives (ODDs), that are attached using one of the interfaces supported by the driver subsystem, start with . The name is then followed by a number starting from for the device, ie. for the first discovered device, for the second discovered device, and so on.
Udev also provides that is a symbolic link to . The name will always be regardless of the drive’s supported disc types or the inserted media.
Summary:
- — optical disc drive , the first discovered optical disc drive.
- — optical disc drive , the fifth discovered optical disc drive.
- — a symbolic link to .
Utilities
lsblk
The package provides the utility which lists block devices, for example:
$ lsblk -f
NAME FSTYPE LABEL UUID MOUNTPOINT sda ├─sda1 vfat C4DA-2C4D /boot ├─sda2 swap 5b1564b2-2e2c-452c-bcfa-d1f572ae99f2 └─sda3 ext4 56adc99b-a61e-46af-aab7-a6d07e504652 /
In the example above, only one device is available (), and that device has three partitions ( to ), each with a different file system.
wipefs
This article or section needs expansion.
wipefs can list or erase file system, RAID or partition-table signatures (magic strings) from the specified device to make the signatures invisible for . It does not erase the file systems themselves nor any other data from the device.
See for more information.
For example, to erase all signatures from the device and create a signature backup file for each signature:
# wipefs --all --backup /dev/sdb
Заключение
Напоминаю, что данная статья является частью единого цикла статьей про сервер Debian.
Онлайн курс Основы сетевых технологий
Теоретический курс с самыми базовыми знаниями по сетям. Курс подходит и начинающим, и людям с опытом. Практикующим системным администраторам курс поможет упорядочить знания и восполнить пробелы. А те, кто только входит в профессию, получат на курсе базовые знания и навыки, без воды и избыточной теории. После обучения вы сможете ответить на вопросы:
- На каком уровне модели OSI могут работать коммутаторы;
- Как лучше организовать работу сети организации с множеством отделов;
- Для чего и как использовать технологию VLAN;
- Для чего сервера стоит выносить в DMZ;
- Как организовать объединение филиалов и удаленный доступ сотрудников по vpn;
- и многое другое.
Уже знаете ответы на вопросы выше? Или сомневаетесь? Попробуйте пройти тест по основам сетевых технологий. Всего 53 вопроса, в один цикл теста входит 10 вопросов в случайном порядке. Поэтому тест можно проходить несколько раз без потери интереса. Бесплатно и без регистрации. Все подробности на странице .