Installing apache spark on ubuntu 17.10
Содержание:
- Введение
- Краткое введение в Scala
- Launching Spark Shell
- Downloading Spark files
- Step4: Installing Scala
- Step7: Verifying the Spark Installation
- Создание Pipeline
- ya.molli
- Навыки для создания маски
- Игры
- Компоненты Spark
- Single-Node Recovery with Local File System
- SparkyLinux 3.4 GameOver — дистрибутив Linux для геймеров
- Заключение
Введение
Из-за ряда трудностей, а также скудного набора готовых методов и решений в SparkML, многие компании пишут свои расширения для Spark. Один из примеров — PravdaML, которую разрабатывают в Одноклассниках и которая, судя по беглой оценке того, что есть в GitHub, выглядит очень перспективно. К сожалению, большая часть подобных решений либо вообще закрыты, либо открыты, но не имеют возможности установки через Maven/sbt и документацию API, что сильно затрудняет работу с ними.
Сегодня мы рассмотрим библиотеку MMLSpark.
Рассматривать будем, как обычно, на примере задачи классификации пассажиров Титаника. Все же цель показать как можно больше возможностей библиотеки MMLSpark, а не выбить SOTA на ImageNet показать крутой Machine Learning. Так что подойдет и Титаник.
Сама библиотека имеет нативный API для Scala (), Python API (документация), а также, судя по некоторым местам в GitHub репозитории, скоро будет иметь API и для R.
В GitHub проекта есть хорошие ноутбуки с примерами (PySpark+Jupyter), но мы пойдем другим путем. Как писал Дмитрий Бугайченко, если разрабатывать для Spark, то есть все основания использовать для этого Scala, более того, Scala позволяет гораздо эффективнее и более гибко определять собственные Transformer и Estimator, чтобы встраивать их в SparkML Pipeline, а про то, как медленно работает numpy/pandas код в UDF (вызываемый на экзекьюторах из JVM), уже много написано.
Краткое введение в Scala
Scala, пожалуй, ― одна из самых заветных тайн Интернета. Scala работает на некоторых из популярнейших Web-сайтах, включая Twitter, LinkedIn и Foursquare (с его платформой Web-приложений Lift). Есть также свидетельства интереса к производительности Scala со стороны финансовых учреждений (например, EDF Trading использует Scala для расчета цен деривативов).
Scala — это мультипарадигмальный язык в том смысле, что он гладко и удобно поддерживает языковые функции, характерные для императивных, функциональных и объектно-ориентированных языков. С точки зрения объектно-ориентированного программирования каждое значение в Scala представляет собой объект. Аналогично, с точки зрения функционального программирования каждая функция — это значение. Кроме того, Scala статически типизируется с помощью выразительной и безопасной типовой системы.
В дополнение к этому Scala представляет собой язык виртуальной машины (VM) и работает непосредственно на Java Virtual Machine (JVM) с использованием Java Runtime Environment версии 2 посредством байт-кодов, генерируемых компилятором Scala. Этот подход позволяет Scala выполнять почти все, что работает на JVM (при наличии дополнительной библиотеки времени выполнения Scala). Таким образом, Scala использовать огромный каталог существующих Java-библиотек наряду с существующими Java-программами.
Наконец, Scala ― расширяемый язык (его название на самом деле означает Scalable Language), ориентированный на добавление простых, гладко интегрируемых расширений.
Происхождение Scala
Язык Scala зародился в Федеральном политехническом институте Лозанны. Его разработал Мартин Одерский (Martin Odersky), который до этого работал над языком программирования Funnel, объединявшем идеи функционального программирования и сетей Петри. В 2011 году группа создателей Scala получила 5-летний грант от Европейского совета по исследованиям, и для коммерческой поддержки Scala была учреждена компания Typesafe, получившая надлежащее финансирование.
Scala на примерах
Рассмотрим некоторые примеры языка Scala в действии. У Scala есть собственный интерпретатор, который позволяет экспериментировать с языком в интерактивном режиме. Практическое использование Scala выходит за рамки настоящей статьи, но в разделе приведены ссылки на дополнительные материалы.
Наш краткий обзор языка Scala с его интерпретатором начинается с . После запуска Scala появляется командная строка, с помощью которой можно интерактивно проверять выражения и программы. Начнем с создания двух переменных, неизменяемой (, т.н. переменная с одноразовым присваиванием) и изменяемой (). Заметим, что если попытка изменить (переменную типа ) будет успешной, то при попытке изменить выдается сообщение об ошибке.
Листинг 1. Простые переменные в Scala
$ scala
Welcome to Scala version 2.8.1.final (OpenJDK Client VM, Java 1.6.0_20).
Type in expressions to have them evaluated.
Type :help for more information.
scala> val a = 1
a: Int = 1
scala> var b = 2
b: Int = 2
scala> b = b + a
b: Int = 3
scala> a = 2
<console>6: error: reassignment to val
a = 2
^
Далее, создадим простой метод для возведения числа в квадрат. Определение метода в Scala начинается со слова , за которым следует имя метода и список параметров, после чего ему присваиваются разные значения (в этом примере ― одно). Никакие возвращаемые значения не указываются, так как они вытекают из самого метода. Это аналогично присвоению значения переменной. Я демонстрирую этот процесс на объекте , а результатом служит переменная (которую интерпретатор Scala создает автоматически). Все это показано в .
Листинг 2. Простой метод в Scala
scala> def square(x: Int) = x*x square: (x: Int)Int scala> square(3) res0: Int = 9 scala> square(res0) res1: Int = 81
Теперь рассмотрим создание в Scala простого класса (см. ). Определим простой класс , который принимает аргумент (конструктор имен). Здесь следует отметить, что класс принимает параметр напрямую (без определения параметра class в теле класса). Единственный метод при вызове выдает строку. Создаем новый экземпляр класса и вызываем метод
Обратите внимание, что вертикальные линии вставляет интерпретатор — они не являются частью кода
Листинг 3. Простой метод в Scala
scala> class Dog( name: String ) {
| def bark() = println(name + " barked")
| }
defined class Dog
scala> val stubby = new Dog("Stubby")
stubby: Dog = Dog@1dd5a3d
scala> stubby.bark
Stubby barked
scala>
Когда все готово, просто введите , чтобы выйти из интерпретатора Scala.
Launching Spark Shell
Now when we are right outside the spark directory, run the following command to open apark shell:
.sparkbinspark-shell
We will see that Spark shell is openend now:
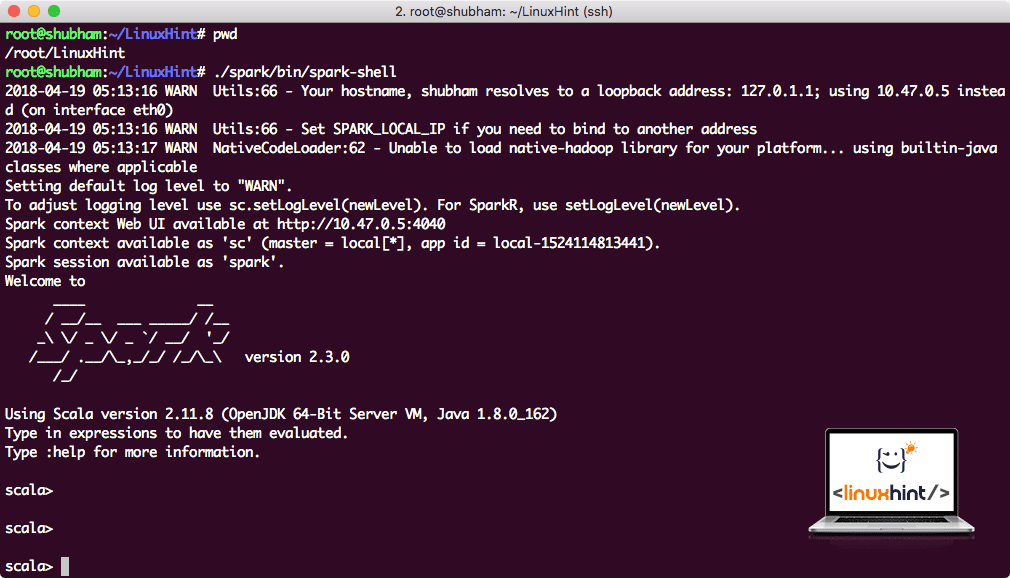
Launching Spark shell
We can see in the console that Spark has also opened a Web Console on port 404. Let’s give it a visit:

Apache Spark Web Console
Though we will be operating on console itself, web environment is an important place to look at when you execute heavy Spark Jobs so that you know what is happening in each Spark Job you execute.
Check the Spark shell version with a simple command:
sc.version
We will get back something like:
res0: String = 2.3.0
Downloading Spark files
All the necessary packages now exist on our machine. We’re ready to download the required Spark TAR files so that we can start setting them up and run a sample program with Spark as well.
In this guide, we will be installing Spark v2.3.0 available here:

Spark download page
Download the corresponding files with this command:
wget http://www-us.apache.orgdistsparkspark-2.3.0spark-2.3.0-bin-hadoop2.7.tgz
Depending upon the network speed, this can take up to a few minutes as the file is big in size:

Downloading Apache Spark
Now that we have the TAR file downloaded, we can extract in the current directory:
tar xvzf spark-2.3.0-bin-hadoop2.7.tgz
This will take a few seconds to complete due to big file size of the archive:

Unarchived files in Spark
When it comes to upgrading Apache Spark in future, it can create problems due to Path updates. These issues can be avoided by creating a softlink to Spark. Run this command to make a softlink:
ln -s spark-2.3.0-bin-hadoop2.7 spark
Step4: Installing Scala
Follow the below given steps for installing Scala.
Type the following command for extracting the Scala tar file.
$ tar xvf scala-2.11.6.tgz
Move Scala software files
Use the following commands for moving the Scala software files, to respective directory (/usr/local/scala).
$ su – Password: # cd /home/Hadoop/Downloads/ # mv scala-2.11.6 /usr/local/scala # exit
Use the following command for setting PATH for Scala.
$ export PATH = $PATH:/usr/local/scala/bin
Verifying Scala Installation
After installation, it is better to verify it. Use the following command for verifying Scala installation.
$scala -version
If Scala is already installed on your system, you get to see the following response −
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL
Step7: Verifying the Spark Installation
Write the following command for opening Spark shell.
$spark-shell
If spark is installed successfully then you will find the following output.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>
Previous Page
Print Page
Next Page
Создание Pipeline
В Pipeline я бы хотел показать как обычные классы SparkML, так и невероятно удобную вещь из MMLSpark — , которая позволяет применять SparkML-трансформеры ко множеству колонок сразу (для справки, например, StringIndexer и OneHotEncoder принимают на вход ровно одну колонку, что превращает их объявление в боль):
Для начала объявим какие колонки у нас какого типа:
Теперь создадим кодировщик строк:
Замечание: В отличие от scikit-learn в SparkML работает по принципу frequency-encoder, и его можно использовать для задания отношения порядка (т.е. категория 0 < категории 1, и в этом есть смысл) — такой подход часто хорошо работает для решающих деревьев.
Объявим наш :
И , так как классификаторам SparkML удобнее работать с :
Теперь воспользуемся поставляемым с MMLSpark градиентным бустингом — LightGBM, который входит в «большую тройку» лучших реализаций этого алгоритма наравне с XGBoost и CatBoost. Он работает во много раз быстрее, лучше и стабильнее, чем реализация GBM, которая есть в SparkML (даже с учетом того, что JVM-порт все еще в активной разработке):
Замечание: LightGBM поддерживает работу с категориальными переменными (почти как catboost), поэтому мы заранее указали ему, где в нашем векторе признаки категории, а он сам уже разберется, что с ними делать и как их кодировать.
Ну и наконец объявим наш Pipeline:
ya.molli
Навыки для создания маски
2D маски
Средняя стоимость:Необходимые навыки:
- Photoshop для статичных масок
- After Effect для динамичных масок (или другой софт для создания 2д анимации)
3D маски
habrastorage.org/webt/ri/pl/1l/ripl1ls3fu58ee0_kqacsahacxw.gifЗдесь применяется LUT фильтр для инвертирования цветов и 3д челюсть, которая трекается к лицуСредняя стоимость:Необходимые навыки:
- Photoshop для статичных масок
- Моделирование, текстурирование, риггинг в любом 3D софте
Про текстурирование.Пример моих 3д масок:Siberian_creatorSiberian_creatorПопробовать
Игры
Эти параметры считывает спарк с лица:
- Моргание глазами (boolean)
- Опускание бровей (boolean)
- Поднятие бровей (boolean)
- Счастливое лицо (boolean) (только для facebook)
- Кивок головы (boolean)
- Поворот головы (boolean)
- Поцелуй (только для facebook)
- Левый глаз закрыт (boolean)
- Правый глаз закрыт (boolean)
- Открыт рот (boolean + значение силы открытия от 0 до 1)
- Улыбка (boolean)
- Удивленное лицо (boolean) (только для facebook)
Пример игры:Персонаж прыгает в момент моргания глазамиСредняя стоимость:Необходимые навыки:
Я создал телеграмм группу для публикации заказов и обсуждения вопросов, связанных с разработкой масок.
Компоненты Spark
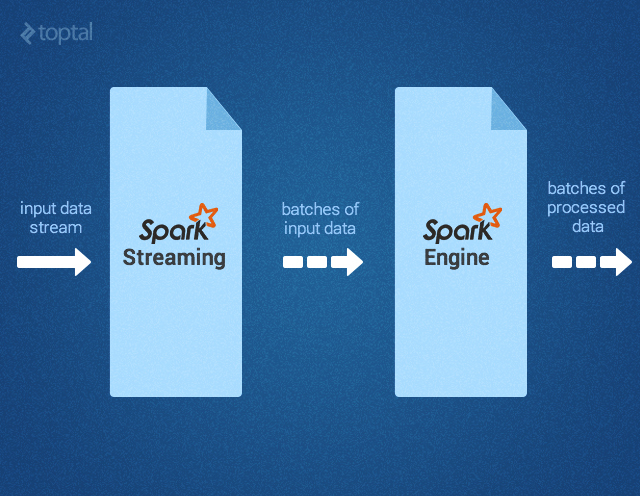
Рисунок 1 – Компоненты Spark Apache
SparkSQL
SparkSQL – это компонент Spark, поддерживающий запрашивание данных либо при помощи SQL, либо посредством Hive Query Language. Библиотека возникла как порт Apache Hive для работы поверх Spark (вместо MapReduce), а сейчас уже интегрирована со стеком Spark. Она не только обеспечивает поддержку различных источников данных, но и позволяет переплетать SQL-запросы с трансформациями кода; получается очень мощный инструмент.
Spark Streaming
MLlib
MLlib — это библиотека для машинного обучения, предоставляющая различные алгоритмы, разработанные для горизонтального масштабирования на кластере в целях классификации, регрессии, кластеризации, совместной фильтрации и т.д. Некоторые из этих алгоритмов работают и с потоковыми данными — например, линейная регрессия с использованием обычного метода наименьших квадратов или кластеризация по методу k-средних (список вскоре расширится). Apache Mahout (библиотека машинного обучения для Apache Hadoop) уже ушла от MapReduce, теперь ее разработка ведется совместно с Spark MLlib.
GraphX
Single-Node Recovery with Local File System
Overview
ZooKeeper is the best way to go for production-level high availability, but if you just want to be able to restart the Master if it goes down, FILESYSTEM mode can take care of it. When applications and Workers register, they have enough state written to the provided directory so that they can be recovered upon a restart of the Master process.
Configuration
In order to enable this recovery mode, you can set SPARK_DAEMON_JAVA_OPTS in spark-env using this configuration:
| System property | Meaning | Since Version |
|---|---|---|
| Set to FILESYSTEM to enable single-node recovery mode (default: NONE). | 0.8.1 | |
| The directory in which Spark will store recovery state, accessible from the Master’s perspective. | 0.8.1 |
Details
- This solution can be used in tandem with a process monitor/manager like monit, or just to enable manual recovery via restart.
- While filesystem recovery seems straightforwardly better than not doing any recovery at all, this mode may be suboptimal for certain development or experimental purposes. In particular, killing a master via stop-master.sh does not clean up its recovery state, so whenever you start a new Master, it will enter recovery mode. This could increase the startup time by up to 1 minute if it needs to wait for all previously-registered Workers/clients to timeout.
- While it’s not officially supported, you could mount an NFS directory as the recovery directory. If the original Master node dies completely, you could then start a Master on a different node, which would correctly recover all previously registered Workers/applications (equivalent to ZooKeeper recovery). Future applications will have to be able to find the new Master, however, in order to register.
SparkyLinux 3.4 GameOver — дистрибутив Linux для геймеров

Игра больше не является необязательным аспектом операционной системы — теперь это необходимо. К счастью, Linux добился больших успехов в этом отношении, особенно благодаря Steam. Сегодня SparkyLinux 3.4 «Game Over» становится доступным, и это очень интригует — настольная операционная система на базе Linux с акцентом на игры.
- Предлагаются следующие игровые функции:
- Доступ к играм, скомпилированным для платформы Linux;
- Доступ к «популярным» и «современным» играм через платформы Steam и Desura;
- Доступ ко многим играм, созданным для платформы MS Windows через Wine и PlayOnLinux;
- Доступ к «старым» играм, созданным для прекращенных машин и систем с помощью эмуляторов.
-
- Доступны следующие эмуляторы:
- DeSmuME — эмулятор для игр Nintendo DS;
- DOSBox — эмулятор системы DOS;
- MAME — эмулятор аркадных игр + графический интерфейс GUI (Graphical User Interface);
- NEStopia — эмулятор развлекательной системы Nintendo;
- PCSX-Reloaded — эмулятор Sony PlayStation;
- Stella — эмулятор Atari 2600;
- Visual Boy Advance — Gameboy, Gameboy Advance и Gameboy Color emulator;
- Yabause — эмулятор Sega Saturn;
- ZSNES — эмулятор развлекательной системы Super Nintendo.
Как вы можете видеть, игры, безусловно, в центре внимания дистрибутива
Несмотря на то, что вы можете вручную добавить все эти вещи в почти любой дистрибутив по вашему выбору, важно, чтобы все было собрано для пользователя. Однако, этот дистрибутив не просто игра, это полноценная операционная система, которая может служить для работы в веб-браузере в офисе или для чего то еще
Более того, он имеет современное ядро 3.14. Кроме того, он использует легкую среду LXDE для минимизации системных требований.
Установка
Создаем виртуальную машину
1) Создаем виртуальную машину SparkyLinux, выбираем ОП Linux
2) Выделяем память для виртуальной машины
3) Создаем виртуальный диск
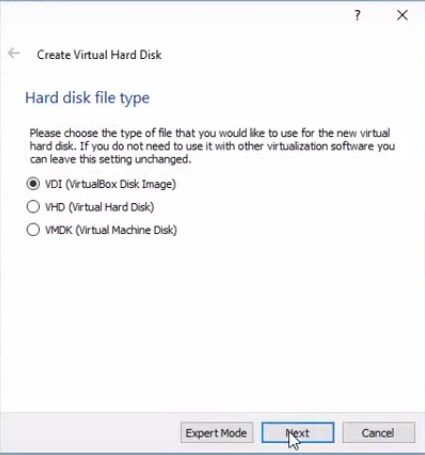
4) Выбираем тип жесткого диска (VDI)
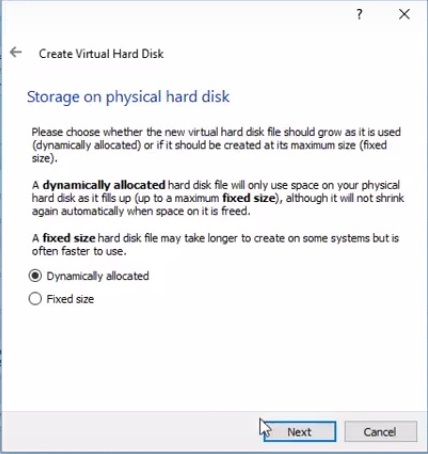
Выбираем динамически распределенный VDI
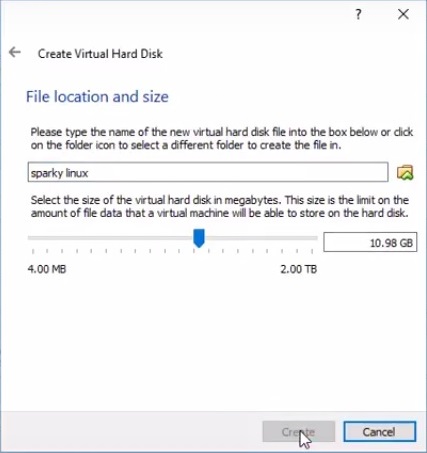
6) Определяем размер VDI
Настройки виртуальной машины
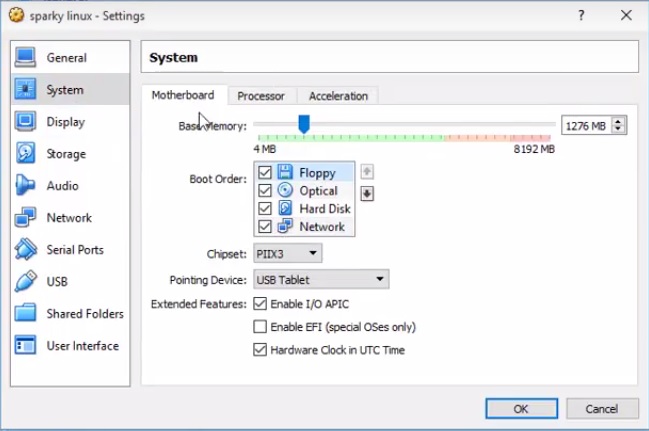
7) В разделе «система» ставим галочку напротив «сеть»
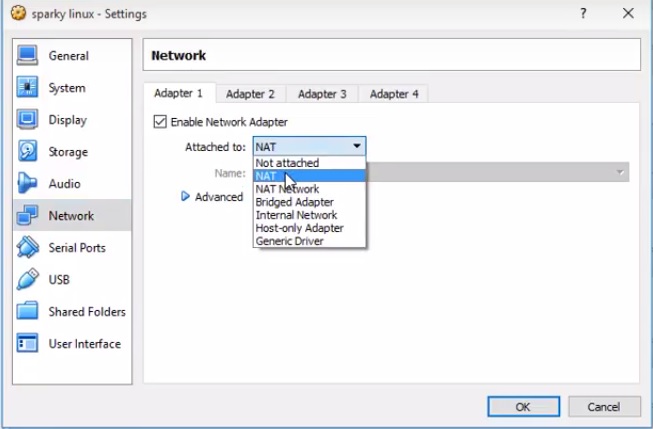
8) Выбираем сеть NAT
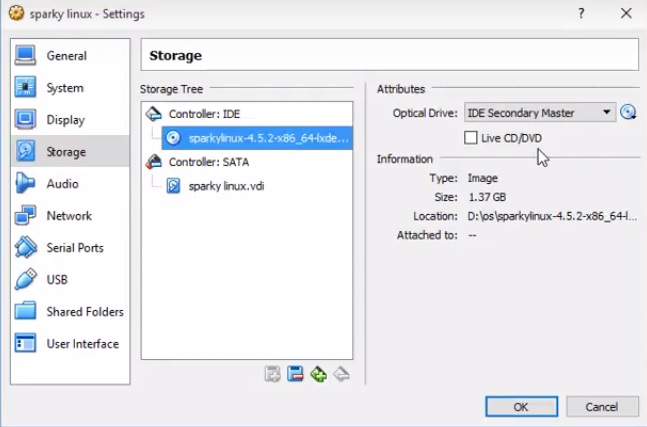
9) В разделе хранилище (storage) добавляем образ диска sparkylinux-4.5.2-x86_64-lxde
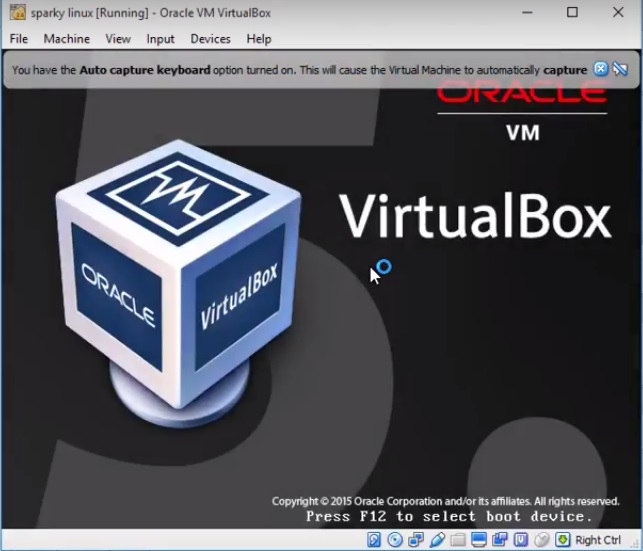
10) Запускаем нашу ВМ (виртуальную машину) на VirtualBox
Процесс установки

11) Запускаем SparkyInstaller
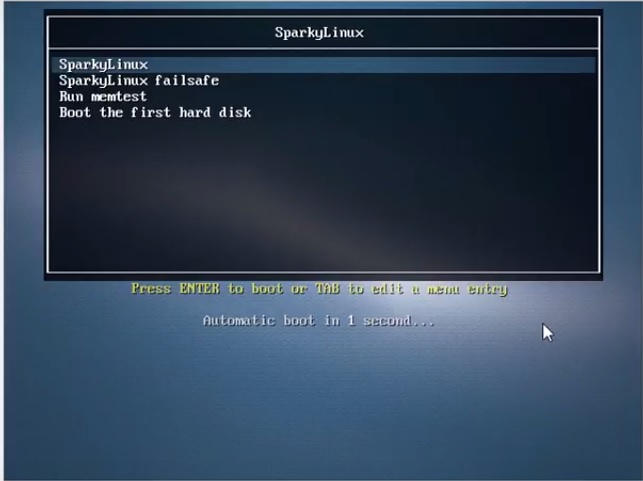
12) В появившемся меню выбираем SparkyLinux
13) Выбираем язык (English)

14) Выбираем свой часовой пояс (timezone)

15) Выбираем раскладку клавиатуры и ее расположение

16) Заполняем поля username, пароля и hostname

17) Подтверждаем согласие на разбиение по частям жесткого диска

18) Проверяем, что это именно нужный нам диск sda2

19) Загружаем Grub для загрузки ядра Linux

20) Проверяем заданные параметры в общей сводке (summary) и соглашаемся, нажимая «apply»

21) После завершении установки SparkyLinux перезапускаем компьютер
Заключение
Поэкспериментируйте со Spark
В практикуме Data analysis and performance with Spark (Анализ данных с помощью Spark и его производительность) исследуются характеристики многопоточных и многоузловых вычислений с помощью Spark и Mesos, а также параметры их настройки.(М. Tim Jones, developerWorks, февраль 2012 г.).
Spark ― интересное пополнение в растущем семействе платформ анализа больших объемов данных. Это эффективная и удобная (благодаря простым и четким сценариям на языке Scala) платформа для обработки распределенных наборов данных. Как Spark, так и Scala находятся в стадии активной разработки. Однако освоение того и другого ключевыми интернет-ресурсами переводит их из разряда интересных проектов ПО с открытым исходным кодом в разряд основных Web-технологий.
- Оригинал статьи
- В практикуме Data analysis and performance with Spark (Анализ данных с помощью Spark и его производительность) исследуются характеристики многопоточных и многоузловых вычислений с помощью Spark и Mesos, а также параметры их настройки. (М. Tim Jones, developerWorks, февраль 2012 г.).
- EDF Trading: реализация проблемно-ориентированного языка для оценки цены деривативов на языке Scala: Scala находит применение в самых разнообразных областях, включая биржевую торговлю. Познакомьтесь с одним из примеров, просмотрев эту видеозапись.
- Application virtualization, past and future (M. Tim Jones, developerWorks, май 2011 г.): введение в языки виртуальных машин и их реализацию.
- Первые шаги к Scala: великолепное введение в язык Scala (написанное при участии создателя языка Мартина Одерского). Это основательное введение 2007 года охватывает многие аспекты языка. Еще один полезный учебник: Примеры кода для программирования на Scala с большим количеством примеров кода.
- Distributed computing with Linux and Hadoop (Ken Mann and M. Tim Jones, developerWorks, декабрь 2008 г.): введение в архитектуру Hadoop, включая основы парадигмы распределенной обработки больших объемов данных MapReduce.
- Distributed data processing with Hadoop (M. Tim Jones, developerWorks 2010): практическое введение в Hadoop, включая создание и использование Hadoop-кластера с одним узлом и многоузлового кластера, а также способы разработки приложений для преобразования и сокращения данных в среде Hadoop.
- developerWorks в Твиттере: следите за последними новостями. В Twitter можно следить также за автором этой статьи: M. Tim Jones.
- Простой инструмент сборки: решение для сборки, принятое для языка Scala. Содержит простой метод для небольших проектов и расширенные функции для сложных сборок.
- Lift: платформа Web-приложений для Scala, аналогичная платформе Rails для Ruby. Lift в действии можно увидеть в Twitter и Foursquare.
- Проект Mesos: Spark изначально не поддерживают распределение задач, но опирается на этот менеджер кластера, который обеспечивает изоляцию ресурсов и их распределение по сети.
- (реализация на базе сценариев Bash), GraphLab (ориентирован на машинное обучение) и Storm (приобретенная Twitter у BackType система распределенной обработки потоков реального времени, написанная на Clojure): Hadoop вызвал к жизни целый ряд платформ для анализа больших объемов данных. Помимо Spark, архитектуры параллельных вычислений можно реализовать с помощью этих трех предложений.