2 лайфхака: альтернативы классическому поиску в microsoft sql server
Содержание:
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Разные базы — разные правила
Внутри каждой базы данных и её управляющей системы свои строгие правила:
- какие данные могут храниться: текст, цифры, фото, видео или всё вместе;
- какие свойства есть у этих данных: дата записи, кто записал, кто может прочитать;
- что делать, если с базой хотят работать одновременно несколько человек: разрешать только одному или пусть все вместе работают.
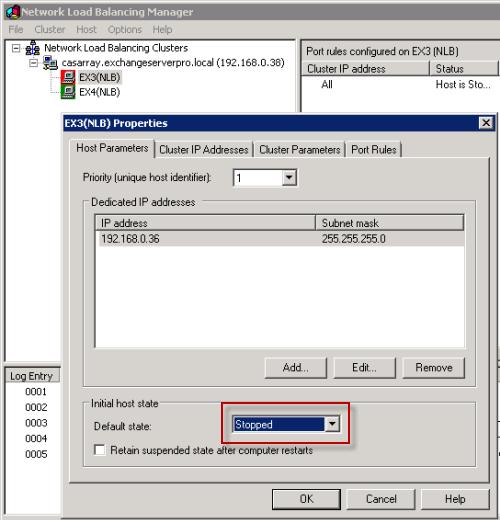
Рабочая ситуация: допустим, вы работаете в банке и открыли карточку клиента, чтобы поменять ему кредитный лимит. В этот же момент другой сотрудник из соседнего офиса тоже хочет поменять лимит этому же клиенту, но уже на другую сумму. Как база отреагирует на такое? Должна ли она разрешать второму сотруднику открывать карточку или её нужно заблокировать, пока первый не закончит? А если она разрешит открыть карточку, то что будет, если двое сотрудников напишут там разный лимит — какой из них сохранять в итоге? СУБД задаёт эти правила и следит за их выполнением.
Реляционные
Реляционные базы данных ещё называют табличными, потому что все данные в них можно представить в виде разных таблиц. Одни таблицы связаны с другими, а другие — с третьими. Например, база данных покупок в магазине может выглядеть так:
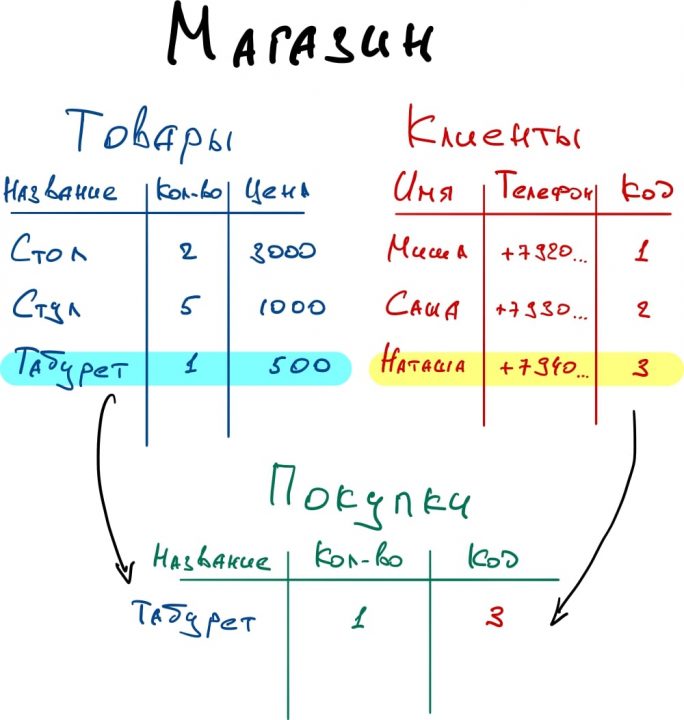
Смотрите, у магазина есть две таблицы — с товарами и покупателями. Но когда один из них что-то покупает, то данные попадают в третью таблицу. В ней есть своя информация (количество купленных товаров) и ссылки на покупателя и сам товар. Если нужно, можно по этим связям попасть в нужную таблицу и узнать подробности о той или другой записи.
Если у покупателя поменяется номер телефона, то нам достаточно будет поменять это в одной таблице «Клиенты». Благодаря тому, что в «Покупки» записывается только код покупателя, нам не нужно менять имя больше нигде — данные сами обновятся автоматически, когда мы захотим посмотреть, кто именно купил табурет.
Наивно используем полнотекстовый поиск
Как гласит документация, для полнотекстового поиска требуется использовать типы и . Первый хранит текст документа в оптимизированном для поиска виде, второй — хранит полнотекстовый запрос.
Для поиска в PostgreSQL есть функции , , . Для ранжирования результатов есть . Их использование интуитивно понятно и они хорошо описаны в документации, поэтому на подробностях их использования останавливаться не будем.
Традиционный поисковый запрос с помощью них будет выглядеть так:
Мы вывели id-ы документов, в тексте которых есть слово «запрос», и отсортировали их по убыванию релевантности. Кажется, всё хорошо? Нет.
У подхода выше есть много недостатков:
- Мы не используем индекс для поиска.
- Функция ts_vector вызывается для каждой строки таблицы.
- Функция ts_rank вызывается для каждой строки таблицы.
Это все приводит к тому, что поиск выполняется реально долго. Результаты на боевой базе:
420 секунд! На один запрос!
Ещё база генерит множество ворнингов вида . В этом ничего страшного нет. Причина в том, что в моей базе лежат документы, созданные в WYSIWYG-редакторе. Он вставляет множество всюду, где можно, и их бывает по 54 тысячи штук подряд. Postgres слова такой длины игнорирует и пишет ворнинг, который нельзя отключить.
Попробуем исправить все замеченные проблемы и ускорить поиск.