Xxd (1) — linux man pages
Содержание:
Обслуживание системы
- Как освободить место в Linux
- Поиск дубликатов файлов в Linux
- Защита папки паролем в Linux
- Восстановление удаленных файлов Linux
- Настройка iptables для чайников
- Шифрование домашней папки в Ubuntu
- Как удалить старые ядра Ubuntu
- Настройка LightDM в Linux
- Настройка репозиториев Ubuntu
- Очистка системы Ubuntu
- Откат системы Ubuntu
- Восстановление Grub2
- Очистка системы Debian 8
- Настройка сети OpenSUSE
- Установка драйверов в Linux
- Создание и настройка LVM Linux
- Настройка терминала Ubuntu
- Установка обновлений Ubuntu
- Настройка Wifi в Ubuntu
- Управление службами Linux
- Диспетчер устройств в Ubuntu
- Установка пакетов Ubuntu
- Установка загрузчика Grub
- Как освободить память Linux
- Клонирование диска CloneZilla
- Как восстановить файловую систему в fsck
- Установка rpm пакетов в Linux
- Как узнать ip адрес Linux
- Настройка загрузчика Grub
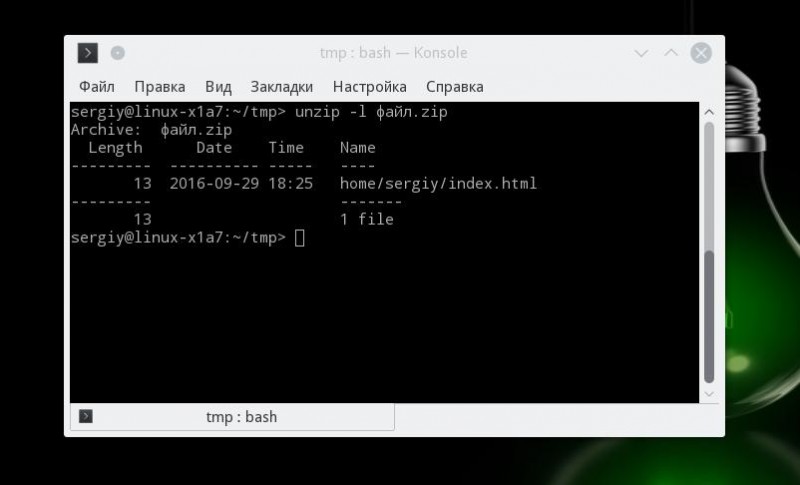
- Как распаковать zip в Linux
- Настройка сети из консоли Ubuntu
- Как сменить пароль в Linux
- Настройка Apparmor в Ubuntu 16.04
- Безопасность сервера Linux
- Настройка gufw Ubuntu 16.04
- Проверка Linux на вирусы
- Настройка SELinux
3. Deepin Linux
В списке «лучший Linux для ноутбука» Deepin Linux занимает одно из главных мест. Это дистрибутив именно для начинающих пользователей, он полностью подходит как для ноутбуков, так и для настольных компьютеров. Его простота и красивый, современный дизайн делают Deepin одним из лучших дистрибутивов 2016 года.

Deepin Linux основан на Debian, но он имеет собственное окружение рабочего стола. Это не KDE, Xfce, LXDE, Gnome или Openbox и другие, здесь используется Deepin Desktop Environment. Это окружение разработано с помощью HTML5 и фреймворка Qt. В Deepin есть три вида рабочего стола: современный — в стиле MacOS X, в стиле Windows 7 и классический минималистичный — в стиле Windows XP. Здесь есть панель запуска приложений, которая ведёт себя так же, как и в MacOS, и похожа на Ubuntu Dash. Таким образом, вы можете получить доступ к любому приложению прямо из рабочего стола, и даже удалить его.
Deepin поставляется с большим количеством приложений по умолчанию, таких как Google Chrome, Kingsoft Office, Deepin Music, Movie, файловый менеджер Deepin. Также в Deepin есть свой центр приложений, который так и называется — центр приложений Deepin, с помощью него вы можете установить любое программное обеспечение в несколько кликов. А ещё здесь есть свой центр управления, похожий на MacOS, ещё более гибкий и мощный, чем центр управления Ubuntu.
Основные характеристики:
- Основан: Debian
- Архитектура: x86 / 64
- Окружение: DDE
- Формат пакетов: .deb
- Встроенное ПО: Google Chrome, Kingsoft Office
Системные требования:
- Оперативная память: 2 или более гигабайт
- Процессор: двухъядерный AMD / Intel с частотой 2 ГГц
- Место на диске: 10 Гб, но рекомендовано 20 Гб для установки программного обеспечения
- Внешний носитель: USB размером 4 Гб или DVD
- Сеть: доступ к интернет
За и против:
Плюсы:
- Красивый, современный, простой в использовании
- Предустановленно много ПО
- Есть центр приложений
- Центр управления похожий на MacOS
- Быстрая загрузка
Минусы:
- Быстрая разрядка батареи
- Потребляет много ресурсов
- Не поддерживает шифрование
Примеры утилиты dd в Unix/Linux
Начнем с самого простого — получить помощь:
Замечаение: в Unix (например на MacOS) может не работать, по этому — имееться следующее решение:
Узнать версию можно вот так:
Замечание: Работат на Linux. На Unix, возможно не будет работать.
-=== ПРИМЕР 1 ===-
Чтобы записать образ на флешку или диск, можно использовать:
-=== ПРИМЕР 2 ===-
Если необходимо скопировать диск на другой, например, можно сделать это следующим образом:
-=== ПРИМЕР 3 ===-
Так же, иногда полезно сжать данные и записать их куда-то (Проверял только с gzip, bzip2). Например, необходимо сделать бэкап. Используем bzip2 сжатие:
Или, используем gzip:
Не забываем комбинировать опции (можно использовать в этом случае: bs=8m, status=progress, conv=fsync)
PS: для рестора можно заюзать:
Можно удаленно создать бэкап, например:
Как другое решение, можно делать бекап по указанному времени и бэкапить его по сети. Например:
PS: Стоит добавить SSH ключи ssh будет работать такая схема
-=== ПРИМЕР 4 ===-
Чтобы отформатировать накопитель низкоуровневым способом используя dd, пример выглядит вот так:
PS: Можно обнулить только определенное количество байт, например:
Проверить можно тем же dd, но преобразовав данные в hex:
Должны быть 0. Или, можно проверить еще другим методом:
Можно для тестирования, взять и скопировать 10 ГБ нулей и перенаправить их в /dev/null (в никуда):
Уничтожить суперблок можно:
или еще один солюшен:
Чтобы очистить первые 113 МБ раздела:
-=== ПРИМЕР 5 ===-
MBR расположена в первых 512 байтах жесткого диска, и состоит из таблицы разделов, загрузчика и пары дополнительных байт. Иногда, ее приходится бекапить, восстанавливать и т.д. Бекап можно сделать так:
Чтобы восстановить, используем:
Если нужно сделать резервное копирование загрузочных данных MBR, исключая таблицу разделов, то пример вот:
Вернуть назад можно так:
Cкопировать MBR на дискету:
Просмотр MBR-а через dd утилиту:
-=== ПРИМЕР 6 ===-
При помощи dd можно генерировать файлы, а затем использовать их как контейнеры других файловых систем даже в зашифрованном виде. Технология следующая: С помощью dd создается файл, забитый нулями (случайными числами забивать не рационально: долго и бессмысленно):
Заполнить диск рандомными значениями:
Затереть файл\диск n-раз, можно так (в моем случаее, будет перезапись 20 раз):
-=== ПРИМЕР 7 ===-
Создаем ISO из CD/DVD ROM-а на локальное устройство (файл на вашем диске):
Создать DVD образы раздела (полезно для резервного копирования):
После такого копирования, можно развернуть все назад следующим образом:
Создать ISO из флопика можно вот так:
-=== ПРИМЕР 8 ===-
Преобразовать формат данных файла( пример с EBCDIC в ASCII):
Преобразовать формат данных файла( пример с ASCII в EBCDIC):
-=== ПРИМЕР 9 ===-
Например у вас есть файл с текстом:
Если нужно сконвертировать содержимое файл в верхний регистр:
Еще пример:
Если нужно сконвертировать содержимое файла в нижний регистр:
-=== ПРИМЕР 10 ===-
Для просмотра вашей виртуальной памяти служит команда:
-=== ПРИМЕР 11 ===-
Чтобы проверить какие файловые системы установлены, выполните:
-=== ПРИМЕР 12 ===-
Проверить все загруженные модули с помощью dd:
-=== ПРИМЕР 13 ===-
Для посмотра таблицы прерываний, есть команда:
-=== ПРИМЕР 14 ===-
Проверить сколько секунд работала система:
-=== ПРИМЕР 15 ===-
Чтобы проверить разделы и так же, их размеры (в кб), используем:
-=== ПРИМЕР 16 ===-
Вывод статистики памяти:
-=== ПРИМЕР 17 ===-
Хороший способ проверить наличие бэдов на устройстве с командой dd:
-=== ПРИМЕР 17 ===-
Так же, можно с данной утилитой проверить файл на вирусы (но нужен для этого, нужно установить ClamAV):
Ссылка на ClamAV:
-=== ПРИМЕР 18 ===-
Тестируем скорость чтения/записи жестких дисков:
-=== ПРИМЕР 19 ===-
Вывести файл на стандартный вывод можно вот так:
-=== ПРИМЕР 20 ===-
Нашел еще пример, с которым можно выполнить поиск какой-то строки по всему разделу (Даже если наложена секьюрити), то можно использовать LiveCD и загрузиться с ним и выполнить:
-=== ПРИМЕР 21 ===-
Чтобы считать BIOS, выполните:
-=== ПРИМЕР 22 ===-
Нашел забавный пример:
-=== ПРИМЕР 23 ===-
Убрать/проигнорировать первые 111 байтов стандартного ввода:
-=== ПРИМЕР 24 ===-
Делаем быстрое резервное копирование по сети с использованием Netcat:
-=== ПРИМЕР 25 ===-
Создаем временное пространство подкачки:
-=== ПРИМЕР 26 ===-
Определите скорость последовательного ввода-вывода вашего привода. Чтение 1 ГБ файла:
-=== ПРИМЕР 27 ===-
Можно добавить прогресс бар, например:
Или:
-=== ПРИМЕР 28 ===-
Генерируем рандомную строку с 32 символами ( задали их):
Или:
На этом у меня все, статья «Утилита dd в Unix/Linux» завершена.
Команда hexdump
Команда hexdump предназначена для вызова одноименной утилиты, осуществляющей вывод содержимого бинарных файлов. При этом помимо стандартного формата вывода, знакомого по hex-редакторам, утилита поддерживает различные экзотические форматы вывода, а также позволяет пользователю самому описывать необходимый ему формат вывода. При установке пакета с утилитой в системе создается символьная ссылка с именем hd, позволяющая вывести содержимое бинарного файла в классическом формате.
Базовый синтаксис команды выглядит следующим образом:
Утилита позволяет задать длину исследуемого фрагмента файла в байтах с помощью параметра -n, сдвиг от начала файла в байтах с помощью параметра -s, задать строку форматирования с помощью параметра -e, а также выбрать формат вывода с помощью одного из описанных ниже параметров. Чтобы было понятнее, для начала создадим текстовый файл со строкой «linux-faq.ru» с помощью следующей команды:
Проверим содержимое этого файла:
Теперь используем команду hexdump без каких-либо параметров для исследования этого файла:
Это используемый по умолчанию, неудобный формат вывода. Очевидно, что в столбце слева приведены 32-битные адреса, а после них следуют шестнадцатеричные представления пар байтов. Эквивалентный результат будет выведен при использовании параметра -x, правда с немного измененным форматированием:
Используем параметр -b для исследования файла:
В этом формате после шестнадцатеричных значений сдвигов выводятся восьмеричные значения каждого из байтов файла.
Используем параметр -c для исследования файла:
В этом формате после шестнадцатеричных значений выводятся непосредственно символы.
Используем параметр -d для исследования файла:
В этом формате после шестнадцатеричных значений сдвигов приводятся десятичные представления пар байтов.
Используем параметр -o для исследования файла:
В этом формате после шестнадцатеричных значений сдвигов приводятся восьмеричные представления пар байтов.
Наконец, используем параметр -C для исследования файла:
Это классический формат hex-редакторов, который предусматривает вывод шестнадцатеричных значений всех байтов файла с соответствующими им символами.
Примечание: существует команда hd, реализованная в виде символьной ссылки на бинарный файл утилиты hexdump с параметром -C. Ее удобно использовать для исследования бинарных файлов, так как не приходится запоминать необходимый параметр утилиты hexdump.
Исследование заголовка бинарного файла
Для исследования заголовка бинарного файла следует использовать параметр -n, позволяющий задать длину этого заголовка, а также параметр -C, активирующий удобный формат вывода:
В выводе несложно обнаружить имя находящегося в архиве файла hexdump.txt.
Исследование завершающей секции бинарного файла
Для исследования завершающей секции бинарного файла следует использовать параметр -s, позволяющий указать длину сдвига от начала файла в байтах, а также параметр -C, активирующий удобный формат вывода:
В выводе ясно виден идентификатор нового формата файла TGA.
Options
infileinfile—outfile—
Note that a «lazy» parser is used which does not check for more than the first option letter, unless the option is followed by a parameter. Spaces between a
single option letter and its parameter are optional. Parameters to options can be specified in decimal, hexadecimal or octal notation. Thus -c8, -c
8, -c 010 and -cols 8 are all equivalent.
- -a | -autoskip
- toggle autoskip: A single ‘*’ replaces nul-lines. Default off.
- -b | -bits
- Switch to bits (binary digits) dump, rather than hexdump. This option writes octets as eight digits «1»s and «0»s instead of a normal hexadecimal dump.
Each line is preceded by a line number in hexadecimal and followed by an ascii (or ebcdic) representation. The command line switches -r, -p, -i do not work
with this mode. - -c cols | -cols cols
- format <cols> octets per line. Default 16 (-i: 12, -ps: 30, -b: 6). Max 256.
- -E | -EBCDIC
- Change the character encoding in the righthand column from ASCII to EBCDIC. This does not change the hexadecimal representation. The option is meaningless
in combinations with -r, -p or -i. - -g bytes | -groupsize bytes
- separate the output of every <bytes> bytes (two hex characters or eight bit-digits each) by a whitespace. Specify -g 0 to suppress
grouping. <Bytes> defaults to 2 in normal mode and 1 in bits mode. Grouping does not apply to postscript or include style. - -h | -help
- print a summary of available commands and exit. No hex dumping is performed.
- -i | -include
- output in C include file style. A complete static array definition is written (named after the input file), unless xxd reads from stdin.
- -l len | -len len
- stop after writing <len> octets.
- -p | -ps | -postscript | -plain
- output in postscript continuous hexdump style. Also known as plain hexdump style.
- -r | -revert
- reverse operation: convert (or patch) hexdump into binary. If not writing to stdout, xxd writes into its output file without truncating it. Use the
combination -r -p to read plain hexadecimal dumps without line number information and without a particular column layout. Additional Whitespace and
line-breaks are allowed anywhere. - -seek offset
- When used after -r: revert with <offset> added to file positions found in hexdump.
- -s seek
- start at <seek> bytes abs. (or rel.) infile offset. + indicates that the seek is relative to the current stdin file position
(meaningless when not reading from stdin). — indicates that the seek should be that many characters from the end of the input (or if combined with
+: before the current stdin file position). Without -s option, xxd starts at the current file position. - -u
- use upper case hex letters. Default is lower case.
- -v | -version
- show version string.
EXAMPLES
Print everything but the first three lines (hex 0x30 bytes) of
file.
% xxd -s 0x30 file
Print 3 lines (hex 0x30 bytes) from the end of
file.
% xxd -s -0x30 file
Print 120 bytes as continuous hexdump with 20 octets per line.
% xxd -l 120 -ps -c 20 xxd.1
2e54482058584420312022417567757374203139
39362220224d616e75616c207061676520666f72
20787864220a2e5c220a2e5c222032317374204d
617920313939360a2e5c22204d616e2070616765
20617574686f723a0a2e5c2220202020546f6e79
204e7567656e74203c746f6e79407363746e7567
Hexdump the first 120 bytes of this man page with 12 octets per line.
% xxd -l 120 -c 12 xxd.1
0000000: 2e54 4820 5858 4420 3120 2241 .TH XXD 1 «A
000000c: 7567 7573 7420 3139 3936 2220 ugust 1996″
0000018: 224d 616e 7561 6c20 7061 6765 «Manual page
0000024: 2066 6f72 2078 7864 220a 2e5c for xxd»..\
0000030: 220a 2e5c 2220 3231 7374 204d «..\» 21st M
000003c: 6179 2031 3939 360a 2e5c 2220 ay 1996..\»
0000048: 4d61 6e20 7061 6765 2061 7574 Man page aut
0000054: 686f 723a 0a2e 5c22 2020 2020 hor:..\»
0000060: 546f 6e79 204e 7567 656e 7420 Tony Nugent
000006c: 3c74 6f6e 7940 7363 746e 7567 <tony@sctnug
Display just the date from the file xxd.1
% xxd -s 0x36 -l 13 -c 13 xxd.1
0000036: 3231 7374 204d 6179 2031 3939 36 21st May 1996
Copy
input_file
to
output_file
and prepend 100 bytes of value 0x00.
% xxd input_file | xxd -r -s 100 > output_file
Patch the date in the file xxd.1
% echo «0000037: 3574 68» | xxd -r — xxd.1
% xxd -s 0x36 -l 13 -c 13 xxd.1
0000036: 3235 7468 204d 6179 2031 3939 36 25th May 1996
Create a 65537 byte file with all bytes 0x00,
except for the last one which is ‘A’ (hex 0x41).
% echo «010000: 41» | xxd -r > file
Hexdump this file with autoskip.
% xxd -a -c 12 file
0000000: 0000 0000 0000 0000 0000 0000 …………
*
000fffc: 0000 0000 40 ….A
Create a 1 byte file containing a single ‘A’ character.
The number after ‘-r -s’ adds to the linenumbers found in the file;
in effect, the leading bytes are suppressed.
% echo «010000: 41» | xxd -r -s -0x10000 > file
Use xxd as a filter within an editor such as
vim(1)
to hexdump a region marked between `a’ and `z’.
:’a,’z!xxd
Use xxd as a filter within an editor such as
vim(1)
to recover a binary hexdump marked between `a’ and `z’.
:’a,’z!xxd -r
Use xxd as a filter within an editor such as
vim(1)
to recover one line of a hexdump. Move the cursor over the line and type:
!!xxd -r
Read single characters from a serial line
% xxd -c1 < /dev/term/b &
% stty < /dev/term/b -echo -opost -isig -icanon min 1
% echo -n foo > /dev/term/b
Команда df linux
Утилита df поставляется по умолчанию во всех дистрибутивах Linux и имеет очень простой синтаксис. Фактически вы можете просто набрать df и уже получить результат, но чтобы сделать вывод более читаемым используются дополнительные опции. Вот основной синтаксис:
$ df опции устройство
Устройство указывать необязательно, но можно указать раздел диска, о котором мы хотим посмотреть информацию. А теперь рассмотрим основные опции утилиты:
- -a, —all — отобразить все файловые системы, в том числе виртуальные, псевдо и недоступные;
- -B — изменить размер одного блока перед выводом данных, например, можно использовать BM, чтобы вывести все данные в мегабайтах;
- -h — выводить размеры в читаемом виде, в мегабайтах или гигабайтах;
- -H — выводить все размеры в гигабайтах;
- -i — выводить информацию об inode;
- -k — выводить размеры в килобайтах;
- —output — использовать специальный формат вывода, если не задано, выводит все поля. Доступны такие варианты: ‘source’, ‘fstype’, ‘itotal’, ‘iused’, ‘iavail’, ‘ipcent’, ‘size’, ‘used’, ‘avail’, ‘pcent’, ‘file’ и ‘target’;
- -P — использовать формат вывода POSIX;
- —total — выводить всю информацию про использованное и доступное место;
- -t, —type — выводить информацию только про указанные файловые системы;
- -x — выводить информацию обо всех, кроме указанных файловых систем;
Теперь, после основных опций рассмотрим подробнее как примеры df linux.
CrunchBang++
CrunchBang++ также известен, как CBPP или #!++ или CrunchBang Plus Plus. CrunchBang++ является клоном мертвого дистрибутива, под названием CrunchBang Linux, известного своей простотой и легким весом. CrunchBang++ поддерживает старое оборудование и работает без каких-либо проблем. Он основан на Debian 9 и использует минималистичный дизайн интерфейса. Также в его основе лежит оконный менеджер Openbox.
Данный проект продолжает ту же цель, что и CrunchBang Linux: предоставить пользователям простой в использовании и легкий дистрибутив Linux, с хорошей функциональностью. Вот почему Crunchbang++ включает в себя минималистичный дизайн, простой и элегантный интерфейс.
Некоторые из стандартный приложений: Geany IDE, эмулятор терминала Terminator, файловый менеджер Thunar, Gimp для редактирования изображений, Viewnior для просмотра изображений, VLC Media Player для музыки, Xfburn для записи CD/DVD дисков, Iceweasel в качестве браузера, Transmission в качестве BitTorrent-клиента, Gnumeric для таблиц, Evince для PDF файлов, gFTP — клиент для передачи файлов, Xchat — IRC клиент, AbiWord в качестве альтернативы Microsoft Word.
Минимальные системные требования для CrunchBang++:
Официальных системных требования для CrunchBang++ нет. В идеале он должен работать с 512 МБ оперативной памяти и процессором (CPU) Pentium 4.
Openbox не совсем подходит для новичков, но это не значит, что вы должны бояться его попробовать.
Скачать дистрибутив вы можете здесь.
OPTIONS
infileinfile—outfile—
Note that a «lazy» parser is used which does not check for more than the first
option letter, unless the option is followed by a parameter.
Spaces between a single option letter and its parameter are optional.
Parameters to options can be specified in decimal, hexadecimal or octal
notation.
Thus
-c8,
-c 8,
-c 010
and
-cols 8
are all equivalent.
- -a | -autoskip
- Toggle autoskip: A single ‘*’ replaces nul-lines. Default off.
- -b | -bits
-
Switch to bits (binary digits) dump, rather than hexdump.
This option writes octets as eight digits «1»s and «0»s instead of a normal
hexadecimal dump. Each line is preceded by a line number in hexadecimal and
followed by an ascii (or ebcdic) representation. The command line switches
-r, -p, -i do not work with this mode. - -c cols | -cols cols
-
Format
<cols>octets per line. Default 16 (-i: 12, -ps: 30, -b: 6). Max 256.
- -C | -capitalize
- Capitalize variable names in C include file style, when using -i.
- -E | -EBCDIC
-
Change the character encoding in the righthand column from ASCII to EBCDIC.
This does not change the hexadecimal representation. The option is
meaningless in combinations with -r, -p or -i. - -e
-
Switch to little-endian hexdump.
This option treats byte groups as words in little-endian byte order.
The default grouping of 4 bytes may be changed using
-g.This option only applies to hexdump, leaving the ASCII (or EBCDIC)
representation unchanged.
The command line switches
-r, -p, -i do not work with this mode. - -g bytes | -groupsize bytes
-
Separate the output of every
<bytes>bytes (two hex characters or eight bit-digits each) by a whitespace.
Specify
-g 0to suppress grouping.
<Bytes> defaults to 2in normal mode, 4 in little-endian mode and 1 in bits mode.
Grouping does not apply to postscript or include style. - -h | -help
- Print a summary of available commands and exit. No hex dumping is performed.
- -i | -include
-
Output in C include file style. A complete static array definition is written
(named after the input file), unless xxd reads from stdin. - -l len | -len len
-
Stop after writing
<len>octets.
- -o offset
-
Add
<offset>to the displayed file position.
- -p | -ps | -postscript | -plain
-
Output in postscript continuous hexdump style. Also known as plain hexdump
style. - -r | -revert
-
Reverse operation: convert (or patch) hexdump into binary.
If not writing to stdout, xxd writes into its output file without truncating
it. Use the combination
-r -pto read plain hexadecimal dumps without line number information and without a
particular column layout. Additional Whitespace and line-breaks are allowed
anywhere. - -seek offset
-
When used after
-r:revert with
<offset>added to file positions found in hexdump.
- -s seek
-
Start at
<seek>bytes abs. (or rel.) infile offset.
+ indicates that the seek is relative to the current stdin file position
(meaningless when not reading from stdin). — indicates that the seek
should be that many characters from the end of the input (or if combined with
+: before the current stdin file position).
Without -s option, xxd starts at the current file position. - -u
- Use upper case hex letters. Default is lower case.
- -v | -version
- Show version string.
Устранение неполадок при открытии файлов XXD
Общие проблемы с открытием файлов XXD
Brixx не установлен
Дважды щелкнув по файлу XXD вы можете увидеть системное диалоговое окно, в котором сообщается «Не удается открыть этот тип файла». В этом случае обычно это связано с тем, что на вашем компьютере не установлено Brixx для %%os%%. Так как ваша операционная система не знает, что делать с этим файлом, вы не сможете открыть его дважды щелкнув на него.
Совет: Если вам извстна другая программа, которая может открыть файл XXD, вы можете попробовать открыть данный файл, выбрав это приложение из списка возможных программ.
Установлена неправильная версия Brixx
В некоторых случаях у вас может быть более новая (или более старая) версия файла Brixx Planner Calendar, не поддерживаемая установленной версией приложения. При отсутствии правильной версии ПО Brixx (или любой из других программ, перечисленных выше), может потребоваться загрузить другую версию ПО или одного из других прикладных программных средств, перечисленных выше. Такая проблема чаще всего возникает при работе в более старой версии прикладного программного средства с файлом, созданным в более новой версии, который старая версия не может распознать.
Совет: Иногда вы можете получить общее представление о версии файла XXD, щелкнув правой кнопкой мыши на файл, а затем выбрав «Свойства» (Windows) или «Получить информацию» (Mac OSX).
Резюме: В любом случае, большинство проблем, возникающих во время открытия файлов XXD, связаны с отсутствием на вашем компьютере установленного правильного прикладного программного средства.
Даже если на вашем компьютере уже установлено Brixx или другое программное обеспечение, связанное с XXD, вы все равно можете столкнуться с проблемами во время открытия файлов Brixx Planner Calendar. Если проблемы открытия файлов XXD до сих пор не устранены, возможно, причина кроется в других проблемах, не позволяющих открыть эти файлы. Такие проблемы включают (представлены в порядке от наиболее до наименее распространенных):
DESCRIPTION
Gzip reduces the size of the named files using Lempel-Ziv coding (LZ77). Whenever possible, each file is replaced by one with the extension .gz, while keeping the same ownership modes, access and modification times. (The default extension is -gz for VMS, z for MSDOS, OS/2 FAT, Windows NT FAT and Atari.) If no files are specified, or if a file name is «-«, the standard input is compressed to the standard output. Gzip will only attempt to compress regular files. In particular, it will ignore symbolic links.
If the compressed file name is too long for its file system, gzip truncates it. Gzipattempts to truncate only the parts of the file name longer than 3 characters. (A part is delimited by dots.) If the name consists of small parts only, the longest parts are truncated. For example, if file names are limited to 14 characters, gzip.msdos.exe is compressed to gzi.msd.exe.gz. Names are not truncated on systems which do not have a limit on file name length.
By default, gzip keeps the original file name and timestamp in the compressed file. These are used when decompressing the file with the -N option. This is useful when the compressed file name was truncated or when the time stamp was not preserved after a file transfer.
Compressed files can be restored to their original form using gzip -d or gunzip or zcat. If the original name saved in the compressed file is not suitable for its file system, a new name is constructed from the original one to make it legal.
OPTIONS
If no infile is given, standard input is read. If infile is specified
as a `-' character, then input is taken from standard input. If no
outfile is given (or a `-' character is in its place), results are sent
to standard output.
Note that a "lazy" parser is used which does not check for more than
the first option letter, unless the option is followed by a parameter.
Spaces between a single option letter and its parameter are optional.
Parameters to options can be specified in decimal, hexadecimal or octal
notation. Thus -c8, -c 8, -c 010 and -cols 8 are all equivalent.
-a | -autoskip
toggle autoskip: A single '*' replaces nul-lines. Default off.
-b | -bits
Switch to bits (binary digits) dump, rather than hexdump. This
option writes octets as eight digits "1"s and "0"s instead of a
normal hexadecimal dump. Each line is preceded by a line number
in hexadecimal and followed by an ascii (or ebcdic) representa-
tion. The command line switches -r, -p, -i do not work with this
mode.
-c cols | -cols cols
format <cols> octets per line. Default 16 (-i: 12, -ps: 30, -b:
6). Max 256.
-E | -EBCDIC
Change the character encoding in the righthand column from ASCII
to EBCDIC. This does not change the hexadecimal representation.
The option is meaningless in combinations with -r, -p or -i.
-g bytes | -groupsize bytes
separate the output of every <bytes> bytes (two hex characters
or eight bit-digits each) by a whitespace. Specify -g to sup-
press grouping. <Bytes> defaults to 2 in normal mode and 1 in
bits mode. Grouping does not apply to postscript or include
style.
-h | -help
print a summary of available commands and exit. No hex dumping
is performed.
-i | -include
output in C include file style. A complete static array defini-
tion is written (named after the input file), unless xxd reads
from stdin.
-l len | -len len
stop after writing <len> octets.
-p | -ps | -postscript | -plain
output in postscript continuous hexdump style. Also known as
plain hexdump style.
-r | -revert
reverse operation: convert (or patch) hexdump into binary. If
not writing to stdout, xxd writes into its output file without
truncating it. Use the combination -r -p to read plain hexadeci-
mal dumps without line number information and without a particu-
lar column layout. Additional Whitespace and line-breaks are
allowed anywhere.
-seek offset
When used after -r: revert with <offset> added to file positions
found in hexdump.
-s seek
start at <seek> bytes abs. (or rel.) infile offset. + indicates
that the seek is relative to the current stdin file position
(meaningless when not reading from stdin). - indicates that the
seek should be that many characters from the end of the input
(or if combined with +: before the current stdin file position).
Without -s option, xxd starts at the current file position.
-u use upper case hex letters. Default is lower case.
-v | -version
show version string.