5 мин для чтениявсе, что вам нужно знать о жесткой ссылке в linux
Содержание:
Жесткие ссылки
Поскольку индексные дескрипторы представляют собой номера, а файлов в операционной системе обычно очень много, то искать файл по его индексу было бы неудобно: человеку работать с осмысленными словами куда удобнее, чем с длинными числами. Поэтому любому файлу в системе обычно дается осмысленное словесное имя, которое не содержит информации о файле, а лишь указывает, то есть ссылается, на его дескриптор.
Имя файла, ссылающееся на его индексный дескриптор, называется жесткой ссылкой. Механизм жестких ссылок – это основной способ обращаться к файлу в Unix-подобных операционных системах.
Поскольку файл в операционной системе однозначно определяет только номер его дескриптора, а имя файла является лишь указателем-ссылкой на него, то очевидно таких ссылок можно создать множество. Все они будут указывать на один объект. Результатом этого является то, что у файла в Linux может быть несколько имен.
Для образного сравнения, представим придорожные указатели на какую-нибудь бензоколонку: их много, они находятся в разных местах трассы, но указывают на одну и туже точку местности.
Почему бывает недостаточно одного имени файла? Все дело в удобстве доступа из разных мест файловой структуры, а также в предоставлении доступа. Так одно имя файла может быть в одном каталоге, второе – в другом.
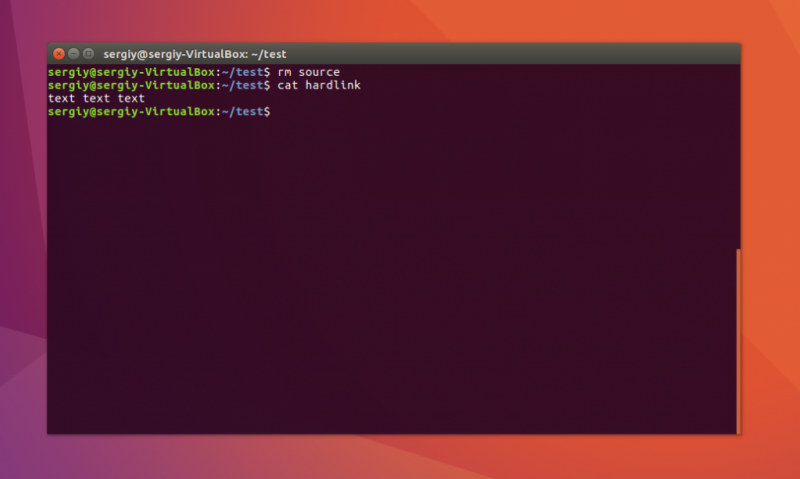
Следствием механизма жестких ссылок Linux является то, что удаление жесткой ссылки на файл не приводит к удалению самого файла из системы при наличии у этого файла других жестких ссылок (имен файла). И это понятно, так как все жесткие ссылки равны между собой, независимо от времени создания, местонахождения в структуре каталогов и др.
Файл будет доступен системе, пока будет существовать хотя бы одна жесткая ссылка на него. В случае удаления всех ссылок, файл удалится из системы, так как станет просто недоступен.
What is in an inode?
Before I said the data blocks contain the contents of the file.
The inode contains the following pieces of information
- Mode/permission (protection)
- Owner ID
- Group ID
- Size of file
- Number of hard links to the file
- Time last accessed
- Time last modified
- Time inode last modified
As I said, a file system is divided into two parts — the inodes and data blocks.
Once created, the number of blocks of each type is fixed.
You can’t increase the number of inodes on a
partition, or increase the number of disk blocks. (See the manual
pages on making and tuning file systems — mkfs.ext2).
Notice something missing? Where is the NAME of the file. Or the Path?
It’s NOT in the inode. It’s NOT in the data blocks. It’s _in_ the
directory. That’s right. A «file» is really in three (or more) places
on the disk.
You see, the directory is just a table that contains the filenames in
the directory, and the matching inode. Think of it as a table, and the
first two entries are always «.» and «..» The first points to the
inode of the current directory, and the second points to the inode of
the parent directory. By Definition. As spoken by the Gods of Unix. Verily.
This inode-magic is how you can create a «hard link» — having two or more names for the same
file. Think of a directory as a table, which contains the name and the inode of each file in the directory.
This is an important point — the name of the file is only used in directory. You can have another directory «containing» the same file, but it can have a different name.
When you create a hard link, it just created a new name in the table, along with the inode,
without moving the file. When you move a file (or rename
it), you don’t copy the data. That would be Slow. You just create the
(name,inode) entry in a new directory, and delete the old entry in the table inside the old directory
entry. In other words, moving a gigabyte file takes very little time.
In the same way, you can move/rename directories very easily.
That’s why «mv /usr /Old_usr» is so fast, even though «/usr» may contain (for example)
57981 files.
You can see this «inode» stuff if you use the «ls -i» option. It lists
the inode number. find(1) can use it as well. Let’s also use the «-d»
option to list information about the directory, rather than the
contents of the directory.
First — let’s make a new directory using
cd /tmp mkdir junk cd junk
If you do a
ls -id ..
cd ..
ls -id .
You will get results that look like this
/tmp/junk$ ls -id .. 327681 .. /tmp/junk$ cd .. /tmp$ ls -id . 327681 .
Now let’s get more information from this directory.
$ ls -lad /tmp/junk drwxrwxr-x 2 barnett barnett 4096 Mar 5 10:42 /tmp/junk
/tmp/junk$ cd /tmp /tmp$ ls -iad junk # look at the file /tmp/junk 435297 junk /tmp$ cd junk /tmp/junk$ ls -iad . # look at the file "." in the /tmp/junk directory 435297 .
Puzzle time! I’m on a system, and I type two commands. Here are the commands and the results:
% cd % ls -ld . .. drwxr-xr-x 66 barnett users 12288 Mar 7 18:43 . drwxr-xr-x 6 root root 4096 Feb 19 2012 ..
You should now know how many directories I have in my home directory,
and how many other users have home directories on my system.
I’ll give you a minute.
Remember, the file «..» always points to the parent directory. And remember that when I create a directory, the kernel creates the files «.» and «..» inside the directory.
Therefore every time I create a directory «underneath» my current
directory, the new directory has an entry «..» — which is the parent
directory.
This means that since I have 66 «copies» or hard links to my home
directory, that I must have 64 sub-directories underneath. We have to
subtract 2 from the total, because we always start with 2 links.
How many other directories are the the /home directory (my parent
directory?) The answer is 3, so there are three other «users» who
have home directories. That’s not quite accurate as users much have an
entry in the /etc/passwd file. In any case, because of the «6»
value for the directory «..» we know there are 4 directories above my
home directory, because we always subtract 2 for the directory itself,
and we subtract one more for my directory — which leaves 3.
Details
File descriptors, file table and inode table in Unix
A file system relies on data structures about the files, as opposed to the contents of that file. The former are called metadata—data that describes data. Each file is associated with an inode, which is identified by an integer, often referred to as an i-number or inode number.
Inodes store information about files and directories (folders), such as file ownership, access mode (read, write, execute permissions), and file type. On many older file system implementations, the maximum number of inodes is fixed at file system creation, limiting the maximum number of files the file system can hold. A typical allocation heuristic for inodes in a file system is one inode for every 2K bytes contained in the filesystem.
The inode number indexes a table of inodes in a known location on the device. From the inode number, the kernel’s file system driver can access the inode contents, including the location of the file, thereby allowing access to the file. A file’s inode number can be found using the command. The command prints the i-node number in the first column of the report.
Some Unix-style file systems such as ReiserFS, btrfs, and APFS omit a fixed-size inode table, but must store equivalent data in order to provide equivalent capabilities. The data may be called stat data, in reference to the system call that provides the data to programs. Common alternatives to the fixed-size table include B-trees and the derived B+ trees.
File names and directory implications:
- Inodes do not contain its hardlink names, only other file metadata.
- Unix directories are lists of association structures, each of which contains one filename and one inode number.
- The file system driver must search a directory looking for a particular filename and then convert the filename to the correct corresponding inode number.
The operating system kernel’s in-memory representation of this data is called in Linux. Systems derived from BSD use the term (the «v» refers to the kernel’s virtual file system layer).
Суперблок
| поле | описание |
|---|---|
| s_inodes_count | Число индексных дескрипторов во всей ФС |
| s_blocks_count | Число блоков, отведённых под ФС |
| s_r_blocks_count | Число зарезервированных блоков данных |
| s_free_blocks_count | Число свободных блоков данных |
| s_free_inodes_count | Число свободных индексных дескрипторов |
| s_first_data_block | Адрес первого блока данных |
| s_log_block_size | Размер блока |
| s_log_frag_size | |
| s_blocks_per_group | Число блоков в группе |
| s_frags_per_group | |
| s_inodes_per_group | Число индексных дескрипторов в группе |
| s_mtime | Время последнего монтирования |
| s_wtime | Время последней записи |
| s_mnt_count | Количество монтирований |
| s_max_mnt_count | Количество монтирований без проверки на ошибки |
| s_magic | Магическое число ex2fs |
| s_state | Флаг «чистого» выключения |
| …. | |
| s_reserved | дополнение до 1024 байтов |
Triple Indirect Block Pointers:
Now this triple Indirect Block Pointers can address upto 4G * 1024 = 4TB, of file size. The fifteenth block pointer in the inode will point to the block just after the 4G of data, which intern will point to 1024 Double Indirect Block Pointers.
So after the 12 direct block pointers, 13th block pointer in inode is for Indirect block pointers, and 14th block pointer is for double indirect block pointers, and 15th block pointer is for triple indirect block pointers.
Now this is the main reason why there are limits to the full size of a single file that you can have in a file system.
Now an interesting fact to understand is that the total no of inodes are created at the time of creating a file system. Which means there is an upper limit in the number of inodes you can have in a file system. Now after that limit has reached you will not be able to create any more files on the file system, even if you have space left on the partition.
Суть inode
Индексный дескриптор содержит информацию о расположении данных файла. Поскольку дисковые блоки хранения данных файла в бщем случае располагаются не последовательно, inode, должен хранить физические адреса всех блоков, принадлежащих данному файлу. В индексном дескрипторе эта информация хранится в виде массива, каждый элемент которого содержит физический адрес дискового блока, а индексом массива является номер логического блока файла. Массив имеет фиксированный размер и состоит из 13 элементов. При этом первые 10 элементов адресуют непосредственно блоки хранения данных файла. Одиннадцатый элемент адресует блок, в свою очередь содержащий адреса блоков хранения данных файла. Двенадцатый элемент указывает на дисковый блок, также хранящий адреса блоков, каждый из который адресует блок хранения данных файла. И, наконец, тринадцатый элемент используется для тройной косвенной адресации, когда для нахождения адреса блока хранения данных файлаиспользуются три дополнительных блока.
Такой подход позволяет при относительно небольшом фиксированном размере индексного дескриптора поддерживать работу с файлами, размер которых может изменяться от нескольких байтов до десятка мегабайтов. Для относительно небольших файлов (до 10 Кбайт при размере блока 1024 байтов) используется прямая индексация, обеспечивающая максимальную производительность. Для файлов, размер которых не превышает 266 кбайт (10 кбайт + 256х1024), достаточно простой косвенной адресации. Наконец, при использовании тройной косвенной адресации можно обеспечить доступ к 16777216 блокам (256х256х256).
Indirect Block Pointers:
whenever the size of the data goes above 48k(by considering the block size as 4k), the 13th pointer in the inode will point to the very next block after the data(adjacent block after 48k of data), which inturn will point to the next block address where data is to be copied.
Now as we have took our block size as 4K, the indirect block pointer, can point to 1024 blocks containing data(by taking the size of a block pointer as 4bytes, one 4K block can point to 1024 blocks because 4 bytes * 1024 = 4K).
which means an indirect block pointer can address, upto 4MB of data(4bytes of block pointer in 4K block, can point and address 1024 number of 4K blocks which makes the data size of 4M)
Double indirect Block Pointers:
Now if the size of the file is above 4MB + 48K then the inode will start using Double Indirect Block Pointers, to address data blocks. Double Indirect Block pointer in an inode will point to the block that comes just after 4M + 48K data, which intern will point to the blocks where the data is stored.
Double Indirect block pointer also is inside a 4K block as every blocks are 4K, Now block pointers are 4 bytes in size, as mentioned previously, so Double indirect block pointer can address 1024 Indirect Block pointers(which means 1024 * 4M =4G). So with the help of a double indirect Block Pointer the size of the data can go upto 4G.
CONFORMING TO top
If you need to obtain the definition of the blkcnt_t or blksize_t
types from <sys/stat.h>, then define _XOPEN_SOURCE with the value 500
or greater (before including any header files).
POSIX.1-1990 did not describe the S_IFMT, S_IFSOCK, S_IFLNK, S_IFREG,
S_IFBLK, S_IFDIR, S_IFCHR, S_IFIFO, S_ISVTX constants, but instead
specified the use of the macros S_ISDIR(), and so on. The S_IF*
constants are present in POSIX.1-2001 and later.
The S_ISLNK() and S_ISSOCK() macros were not in POSIX.1-1996, but
both are present in POSIX.1-2001; the former is from SVID 4, the
latter from SUSv2.
UNIX V7 (and later systems) had S_IREAD, S_IWRITE, S_IEXEC, where
POSIX prescribes the synonyms S_IRUSR, S_IWUSR, S_IXUSR.
Inlining
It can make sense to store very small files in the inode itself to save both space (no data block needed) and lookup time (no further disk access needed). This file system feature is called inlining. The strict separation of inode and file data thus can no longer be assumed when using modern file systems.
If the data of a file fits in the space allocated for pointers to the data, this space can conveniently be used. For example, ext2 and its successors store the data of symlinks (typically file names) in this way if the data is no more than 60 bytes («fast symbolic links»).
Ext4 has a file system option called that allows ext4 to perform inlining if enabled during file system creation. Because an inode’s size is limited, this only works for very small files.
COLOPHON top
This page is part of release 5.08 of the Linux man-pages project. A
description of the project, information about reporting bugs, and the
latest version of this page, can be found at
https://www.kernel.org/doc/man-pages/.
Linux 2020-08-13 INODE(7)
Pages that refer to this page:
chmod(2),
creat(2),
fchmod(2),
fchmodat(2),
fdatasync(2),
fstat(2),
fstat64(2),
fstatat(2),
fstatat64(2),
fsync(2),
ftruncate(2),
ftruncate64(2),
getdents(2),
getdents64(2),
lstat(2),
lstat64(2),
mkdir(2),
mkdirat(2),
mknod(2),
mknodat(2),
newfstatat(2),
oldfstat(2),
oldlstat(2),
oldstat(2),
open(2),
openat(2),
stat(2),
stat64(2),
statx(2),
truncate(2),
truncate64(2),
umask(2),
utime(2),
utimensat(2),
utimes(2),
futimens(3),
systemd.exec(5)
Заключение
Несмотря на то, что реализация файловой системы отнюдь не тривиальна, она является отличным примером расширяемой и масштабируемой архитектуры. Архитектура файловой системы развивалась годами, при этом поддерживая множество типов файловых систем и множество типов устройств хранения. Будет интересно посмотреть на развитие в ближайшем будущем файловой системы Linux, использующей архитектуру дополнений с несколькими уровнями преобразования функций.
Похожие темы
- Оригинал статьи «Anatomy of the Linux file system» (EN).
- Файловая система proc предоставляет новую схему связи пространства пользователя и ядра посредством виртуальной файловой системы. В статье «Доступ к ядру Linux посредством файловой системы /proc» (EN) (developerWorks, март 2006 г.) описывается виртуальная файловая система /proc и демонстрируются примеры ее использования.
-
Интерфейс системных вызовов Linux предоставляет средства управления переходом между пространством пользователя и ядром для вызова функций API ядра. В статье
«Команды ядра с использованием системных вызовов Linux» (EN)
(developerWorks, 2007) описывается интерфейс системных вызовов Linux. - На сайте
Yolinux.com ведется огромный список файловых систем Linux, кластерных файловых систем и высокопроизводительных вычислительных кластеров. Кроме того, полный список файловых систем Linux можно найти в
File systems
HOWTO. На сайте
Xenotime представлены описания множества файловых систем. - Более подробную информацию о программировании Linux в пространстве пользователя можно найти в книге Разработка приложений GNU/Linux (EN)
, написанной автором этой статьи. (EN) -
В
разделе Linux сайта developerWorks можно найти дополнительные ресурсы для разработчиков Linux, а также познакомиться с самыми популярными статьями и руководствами. (EN) -
Файловая система
Filesystem in Userspace (FUSE) является модулем ядра, который позволяет разрабатывать файловые системы в пространстве пользователя. Реализация драйвера файловой системы направляет вызовы VFS обратно в пространство пользователя. Это отличный способ для проведения экспериментов с разработкой файловой системы без разработки ядра. Если вы используете Python, вы можете создавать файловые системы с помощью этого языка и с помощью
LUFS-Python. (EN) -
Ознакомьтесь со всеми
советами Linux ируководствами Linux на developerWorks.
-
Загрузите
ознакомительные версии продуктов IBM
и получите инструменты разработки и системное программное обеспечение от
DB2, Lotus, Rational, Tivoli, and WebSphere.(EN)