Best free and paid web scraping tools and software in 2020
Содержание:
- Why Python for Web Scraping?
- Онлайн-сервисы для скрейпинга
- Traditional Data Scraping
- Browser-based Scraping
- Избегайте honeypot-ловушек
- Portia
- Parsehub
- Project Setup
- Web Crawling v/s Web Scraping
- Selenium
- How to Scrape a Website
- How is Web Scraping Done?
- How businesses use data through web scraping
- Puppeteer
- Testing with Selenium
- Dataminer
- Scraping with Respect
- Библиотеки для языков программирования
- Additional Possible Roadblocks and Solutions
- Используйте headless-браузер
- Puppeteer
- Progress monitoring
- ScrapeSimple
- Data processing using PostgreSQL
- Arc has top developers available for hire and freelance jobs. Check out our Python developers!
- BeautifulSoup
Why Python for Web Scraping?
Python is a popular tool for implementing web scraping. Python programming language is also used for other useful projects related to cyber security, penetration testing as well as digital forensic applications. Using the base programming of Python, web scraping can be performed without using any other third party tool.
Python programming language is gaining huge popularity and the reasons that make Python a good fit for web scraping projects are as below −
Syntax Simplicity
Python has the simplest structure when compared to other programming languages. This feature of Python makes the testing easier and a developer can focus more on programming.
Inbuilt Modules
Another reason for using Python for web scraping is the inbuilt as well as external useful libraries it possesses. We can perform many implementations related to web scraping by using Python as the base for programming.
Онлайн-сервисы для скрейпинга
Готовые веб-интерфейсы обычно избавляют ото всех хлопот, возникающих во время парсинга веб-страниц. Но по этой же причине большинство из них — платные. Среди примеров:
Scrapeworks — подойдёт тем, кто не знаком с программированием. Позволяет получать данные со страниц в структурированном формате на ваш выбор.
Diggernaut — парсер, создаваемый с помощью визуального инструмента или метаязыка. Может читать данные из HTML, XML, JSON, iCal, JS, XLSX, XLS, CSV, Google Spreadsheets.
ScrapingBee — предоставляет API для работы с Headless Chrome и позволяет сфокусироваться на обработке данных.
Scraper API — ещё один простой API с большим набором настроек: от заголовков запросов до геолокации IP.
Traditional Data Scraping
As most websites produce pages meant for human readability rather than automated reading, web scraping mainly consisted of programmatically digesting a web page’s mark-up data (think right-click, View Source), then detecting static patterns in that data that would allow the program to “read” various pieces of information and save it to a file or a database.

If report data were to be found, often, the data would be accessible by passing either form variables or parameters with the URL. For example:
Python has become one of the most popular web scraping languages due in part to the various web libraries that have been created for it. One popular library, Beautiful Soup, is designed to pull data out of HTML and XML files by allowing searching, navigating, and modifying tags (i.e., the parse tree).
Browser-based Scraping
Recently, I had a scraping project that seemed pretty straightforward and I was fully prepared to use traditional scraping to handle it. But as I got further into it, I found obstacles that could not be overcome with traditional methods.
Three main issues prevented me from my standard scraping methods:
- Certificate. There was a certificate required to be installed to access the portion of the website where the data was. When accessing the initial page, a prompt appeared asking me to select the proper certificate of those installed on my computer, and click OK.
- Iframes. The site used iframes, which messed up my normal scraping. Yes, I could try to find all iframe URLs, then build a sitemap, but that seemed like it could get unwieldy.
- JavaScript. The data was accessed after filling in a form with parameters (e.g., customer ID, date range, etc.). Normally, I would bypass the form and simply pass the form variables (via URL or as hidden form variables) to the result page and see the results. But in this case, the form contained JavaScript, which didn’t allow me to access the form variables in a normal fashion.
So, I decided to abandon my traditional methods and look at a possible tool for browser-based scraping. This would work differently than normal – instead of going directly to a page, downloading the parse tree, and pulling out data elements, I would instead “act like a human” and use a browser to get to the page I needed, then scrape the data — thus, bypassing the need to deal with the barriers mentioned.
Избегайте honeypot-ловушек
«Honeypot» — это фальшивая ссылка, которая невидима для обычного пользователя, но присутствует в HTML-коде. Как только вы начнёте анализировать сайт, honeypot может перенаправить вас на пустые и бесполезные страницы-приманки. Поэтому всегда проверяйте, установлены ли для ссылки CSS-свойства «display: none», «visibility: hidden» или «color: #fff;» (в последнем случае нужно учитывать цвет фона сайта).
Если вы последуете хотя бы одному совету из этой статьи, ваши шансы быть заблокированным уменьшатся во много раз. Но для верности лучше комбинировать несколько приёмов и всегда следить, чтобы краулер не слишком нагружал чужие веб-серверы.
Portia
Portia is another great open source project from ScrapingHub. It’s a visual abstraction layer on top of the great Scrapy framework.
Meaning it allows to create scrapy spiders without a single line of code, with a visual tool.
Portia itself is a web application written in Python. You can run it easily thanks to the docker image.
Simply run :
Lots of things can be automated with Portia, but when things gets too complicated and custom code/logic needs to be implemented, you can use this tool https://github.com/scrapinghub/portia2code to convert a Portia project to a Scrapy project, in order to add custom logic.
One of the biggest problem of Portia is that it use the Splash engine to render Javascript heavy website. It works great in many cases, but have severe limitation compared to Headless Chrome for example. Websites using React.js aren’t supported for example!
Pros:
- Great “low-code” tool for teams already using Scrapy
- Open-source
Cons:
Limitations regarding Javascript rendering support
Parsehub
ParseHub is a web based data scraping tool which is built to crawl single and multiple websites with the support for JavaScript, AJAX, cookies, sessions, and redirects. The application can analyze and grab data from websites and transform it into meaningful data. Parsehub uses machine learning technology to recognize the most complicated documents and generates the output file in JSON, CSV , Google Sheets or through API.
Parsehub is a desktop app available for Windows, Mac, and Linux users and works as a Firefox extension. The easy user-friendly web app can be built into the browser and has a well written documentation. It has all the advanced features like pagination, infinite scrolling pages, pop-ups, and navigation. You can even visualize the data from ParseHub into Tableau.
Project Setup
To start experimenting, I needed to set up my project and get everything I needed. I used a Windows 10 machine and made sure I had a relatively updated Python version (it was v. 3.7.3). I created a blank Python script, then loaded the libraries I thought might be required, using PIP (package installer for Python) if I didn’t already have the library loaded. These are the main libraries I started with:
- Requests (for making HTTP requests)
- (URL handling)
- Beautiful Soup (in case Selenium couldn’t handle everything)
- Selenium (for browser-based navigation)
I also added some calling parameters to the script (using the argparse library) so that I could play around with various datasets, calling the script from the command line with different options. Those included Customer ID, from- month/year, and to-month/year.
Web Crawling v/s Web Scraping
The terms Web Crawling and Scraping are often used interchangeably as the basic concept of them is to extract data. However, they are different from each other. We can understand the basic difference from their definitions.
Web crawling is basically used to index the information on the page using bots aka crawlers. It is also called indexing. On the hand, web scraping is an automated way of extracting the information using bots aka scrapers. It is also called data extraction.
To understand the difference between these two terms, let us look into the comparison table given hereunder −
| Web Crawling | Web Scraping |
|---|---|
| Refers to downloading and storing the contents of a large number of websites. | Refers to extracting individual data elements from the website by using a site-specific structure. |
| Mostly done on large scale. | Can be implemented at any scale. |
| Yields generic information. | Yields specific information. |
| Used by major search engines like Google, Bing, Yahoo. Googlebot is an example of a web crawler. | The information extracted using web scraping can be used to replicate in some other website or can be used to perform data analysis. For example the data elements can be names, address, price etc. |
Selenium
In general, Selenium is well-known as an open-source testing framework for web applications – enabling QA specialists to perform automated tests, execute playbacks, and implement remote control functionality (allowing many browser instances for load testing and multiple browser types). In my case, this seemed like it could be useful.
My go-to language for web scraping is Python, as it has well-integrated libraries that can generally handle all of the functionality required. And sure enough, a Selenium library exists for Python. This would allow me to instantiate a “browser” – Chrome, Firefox, IE, etc. – then pretend I was using the browser myself to gain access to the data I was looking for. And if I didn’t want the browser to actually appear, I could create the browser in “headless” mode, making it invisible to any user.
How to Scrape a Website
Now, let’s walk you through your very first web scraping project.
For this example, we are going to keep it simple. We will scrape listings from Amazon’s search result page for the term “tablet”. We will be scraping the product name, listing URL, price, review score, number of reviews and image URL.
- Make sure to download and open ParseHub.
- Click on New Project and submit the Amazon URL we’ve selected. The website will now be rendered inside the application.

- Scroll past the sponsored listings and click on the product name of the first search result.
- The product name will be highlighted in green to indicate that is has been selected. Click on the second product name to select all the listings on the page. All product names will now be highlighted in green.

- On the left sidebar, rename your selection to product.
- ParseHub is now extracting both the product name and URL. Now we will tell it to extract the product’s price.
- First, click on the PLUS(+) sign next to the product selection you created and choose the Relative Select command.

- Using the Relative Select command, click on the first product name and then on its price. An arrow will appear to connect the two data points.

- Rename your new selection to price.
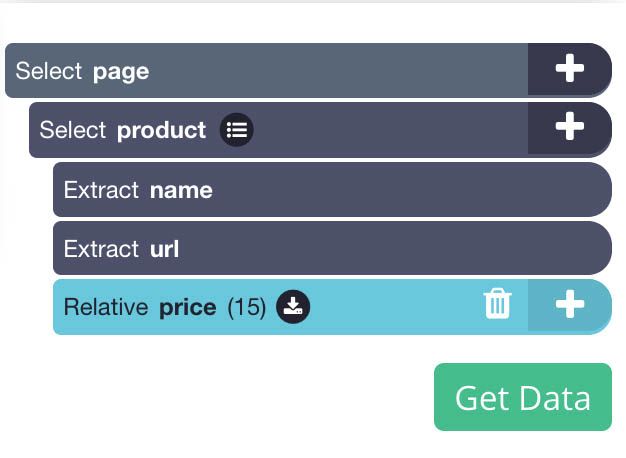
- Using the icon next to your price selection, expand your selection and remove the URL extraction.
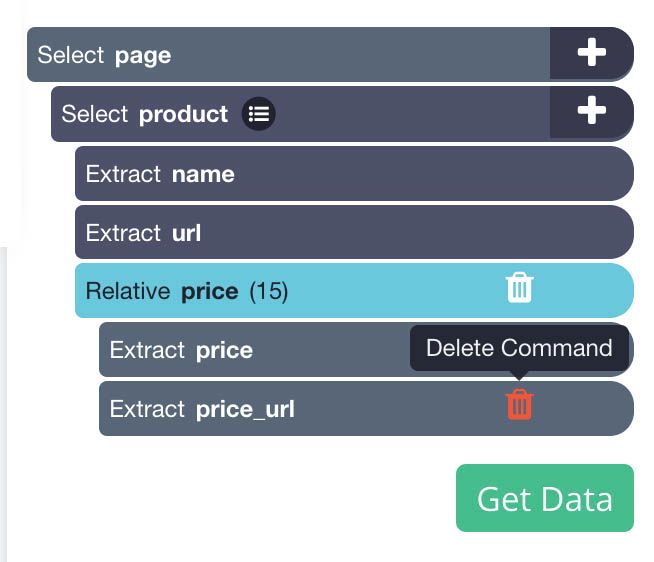
- Next, repeat steps 7-10 to also extract the product’s star rating, number of reviews and image URL. Remember to name your selection accordingly as you create them.
Your final project should look like this:
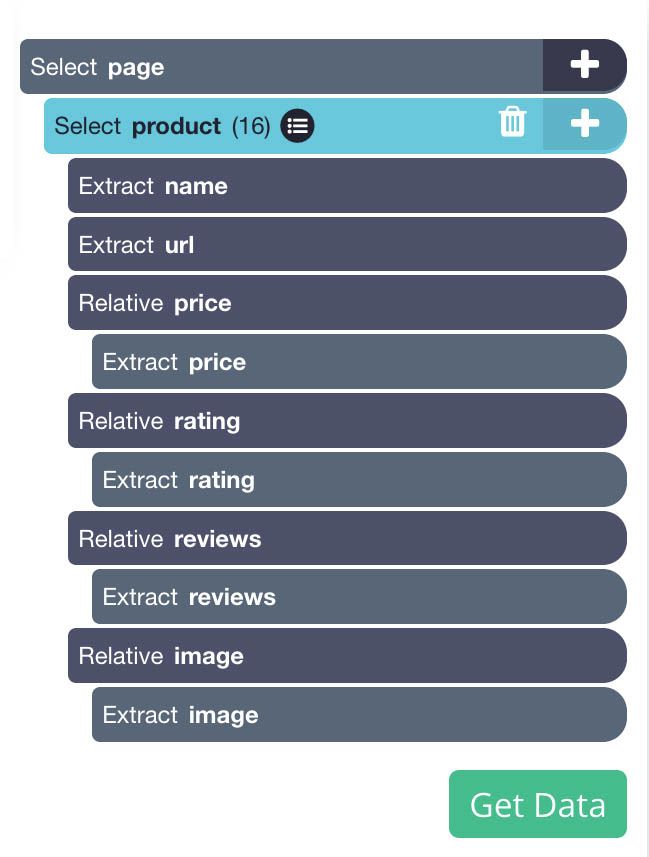
Dealing with Pagination
We want to keep this project simple, but we could not pass up the chance to showcase one of ParseHub’s best features. We will now tell ParseHub to navigate beyond the first page of results and keep scraping further pages of results.
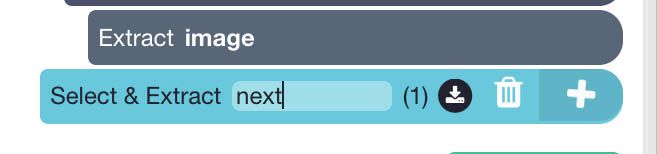
- Click on the PLUS(+) sign next to your page selection and choose the Select command.

- Now scroll all the way down to the bottom of the page and click on the “Next” page link. It will be highlighted in green to show it has been selected.

- Rename your selection to next.
- Expand your selection and remove the extract commands under it.
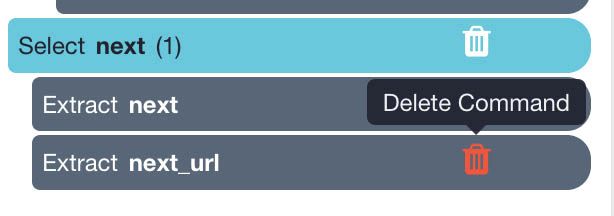
- Now use the PLUS(+) sign next to the next command and select the Click command.

How is Web Scraping Done?
Before we move to the things that can make scraping tricky, let’s break down the process of web scraping into broad steps:
- Visual inspection: Figure out what to extract
- Make an HTTP request to the webpage
- Parse the HTTP response
- Persist/Utilize the relevant data
The first step involves using built-in browser tools (like Chrome DevTools and Firefox Developer Tools) to locate the information we need on the webpage and identifying structures/patterns to extract it programmatically.
The following steps involve methodically making requests to the webpage and implementing the logic for extracting the information, using the patterns we identified. Finally, we use the information for whatever purpose we intended to.
For example, let’s say we want to extract the number of subscribers of PewDiePie and compare it with T-series. A simple Google search leads me to Socialblade’s Real-time Youtube Subscriber Count Page.
From visual inspection, we find that the subscriber count is inside a tag with ID .
Let’s write a simple Python function to get this value. We’ll use BeautifulSoup for parsing the HTML.
Let’s see the counts now:
Seems like an easy process, right? What could go wrong?
The answer to this mostly depends upon the way the site is programmed and the intent of the website owner. They can deliberately introduce complexities to make the scraping process tricky. Some complexities are easy to get around with, and some aren’t.
Let’s list down these complexities one by one, and see the solutions for them in the next section.
How businesses use data through web scraping
Stock Market and Financial Data
Gather data about global financial markets, stock markets, trading, commodity and economic
indicators. Enhance and augment
the data available to analysts and internal financial models to make them perform better.
Product, Pricing and Review Data
Scrape eCommerce websites to extract product prices, availability, reviews, prominence, brand
reputation and more. Monitor your distribution chain, and analyze customer reviews to improve
your
products and profits with this data.
Job Data and Human Capital
Find the best candidates for your company or keep tabs on who your competition is hiring.
Aggregate jobs from job boards or company websites — all this can be accomplished through web
scraping.
Travel, Hotel and Airline Data
Extract data from travel websites to accurately analyze hotel reviews, pricing, room
availability and
airline ticket prices using our advanced web scraping services. Stay competitive through the use
of data.
Dark and Deep Web Data
The Dark web and the Deep web is a gold mine ready to be exploited. Data around cybersecurity,
threats and crime related trends can be gathered for value-added analysis.
Data for Research and Journalism
Power your next research project or news story with data from the web — Environmental Data,
Third World Development Data, Crime Data, Local and Global trends etc.
Social Media Data
Gather data from social media — Facebook, Twitter and Instagram. Collect historical data or get
alerts from these sites.
Monitor your reach and measure the effectiveness of your campaigns.
Puppeteer
Website: https://github.com/GoogleChrome/puppeteer
Who is this for: Puppeteer is a headless Chrome API for NodeJS developers who want very granular control over their scraping activity.
Why you should use it: As an open source tool, Puppeteer is completely free. It is well supported and actively being developed and backed by the Google Chrome team itself. It is quickly replacing Selenium and PhantomJS as the default headless browser automation tool. It has a well thought out API, and automatically installs a compatible Chromium binary as part of its setup process, meaning you don’t have to keep track of browser versions yourself. While it’s much more than just a web crawling library, it’s often used to scrape website data from sites that require javascript to display information, it handles scripts, stylesheets, and fonts just like a real browser. Note that while it is a great solution for sites that require javascript to display data, it is very CPU and memory intensive, so using it for sites where a full blown browser is not necessary is probably not a great idea. Most times a simple GET request should do the trick!
Testing with Selenium
Let us discuss how to use Python Selenium for testing. It is also called Selenium testing.
Both Python unittest and Selenium do not have much in common. We know that Selenium sends the standard Python commands to different browsers, despite variation in their browser’s design. Recall that we already installed and worked with Selenium in previous chapters. Here we will create test scripts in Selenium and use it for automation.
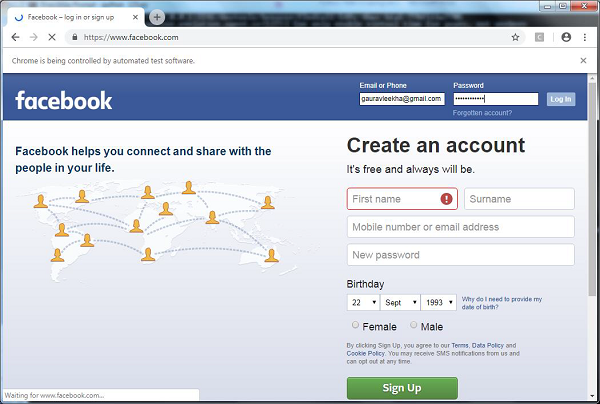
Example
With the help of next Python script, we are creating test script for the automation of Facebook Login page. You can modify the example for automating other forms and logins of your choice, however the concept would be same.
First for connecting to web browser, we will import webdriver from selenium module −
from selenium import webdriver
Now, we need to import Keys from selenium module.
from selenium.webdriver.common.keys import Keys
Next we need to provide username and password for login into our facebook account
user = "gauravleekha@gmail.com" pwd = ""
Next, provide the path to web driver for Chrome.
Now we will verify the conditions by using assert keyword.
assert "Facebook" in driver.title
element = driver.find_element_by_id("email")
element.send_keys(user)
With the help of following line of code we are sending values to the password section. Here we are searching it by its id but we can do it by searching it by name as driver.find_element_by_name(«pass»).
element = driver.find_element_by_id("pass")
element.send_keys(pwd)
element.send_keys(Keys.RETURN)
Now we will close the browser.
driver.close()
Dataminer

Dataminer is one of the most famous Chrome extension for webscraping (186k installation and counting). What is very unique about dataminer is that it has a lot of feature compared to other extension.
Generally Chrome extension are easier to use than desktop app like Octoparse or Parsehub, but lacks lots of feature.
Dataminer fits right in the middle. It can handle infinite scroll, pagination, custom Javascript execution, all inside your browser.
One of the great thing about dataminer is that there is a public recipe list that you can search to speed up your scraping. A recipe is a list of steps and rules to scrape a website.
For big websites like Amazon or Ebay, you can scrape the search results with a single click, without having to manually click and select the element you want.
Cons:
It is by far the most expensive tool in our list ($200/mo for 9000 pages scraped per month)
Scraping with Respect
In this post, we covered typical complexities involved in scraping websites, their possible workarounds, and the tools and libraries that we can use with Python in mind.
As mentioned in the beginning, scraping is like a cat-and-mouse game operating in a legal gray area, and can cause trouble to both the sides if not done respectfully. Violation of copyrights and abuse of information may invite legal consequences. A couple of instances that sparked controversies are the OK Cupid data release by researchers and HIQ labs using Linkedin data for HR products.
Robots exclusion standard was designed to convey the intent of the site owners towards being indexed/crawled. Ideally, our web scraper should obey the instructions in the file. Even if the allows scraping, doing it aggresively can overwhelm the server, causing performance issues or resource crunch on the server-end (even failures).
It’s good to include a back-off time if the server is starting to take longer to respond. Also, a less popular opinion is contacting the site-owners directly for APIs and data-dumps before scraping so that both sides are happy.
Библиотеки для языков программирования
Python
Библиотеки на Python предоставляют множество эффективных и быстрых функций для парсинга. Многие из этих инструментов можно подключить к готовому приложению в формате API для создания настраиваемых краулеров. Все перечисленные ниже проекты имеют открытый исходный код.
BeautifulSoup
Пакет для анализа документов HTML и XML, преобразующий их в синтаксические деревья. Он использует HTML и XML-парсеры, такие как html5lib и Lxml, чтобы извлекать нужные данные.
Для поиска конкретного атрибута или текста в необработанном HTML-файле в BeautifulSoup есть удобные функции find(), find_all(), get_text() и другие. Библиотека также автоматически распознаёт кодировки.
Установить последнюю версию BeautifulSoup можно через easy_install или pip:
Selenium
Инструмент, который работает как веб-драйвер: открывает браузер, выполняет клики по элементам, заполняет формы, прокручивает страницы и многое другое. Selenium в основном используется для автоматического тестирования веб-приложений, но его вполне можно применять и для скрейпинга. Перед началом работы необходимо установить драйверы для взаимодействия с конкретным браузером, например ChromeDriver для Chrome и Safari Driver для Safari 10.
Установить Selenium можно через pip:
Lxml
Библиотека с удобными инструментами для обработки HTML и XML файлов. Работает с XML чуть быстрее, чем Beautiful Soup, при этом используя аналогичный метод создания синтаксических деревьев. Чтобы получить больше функциональности, можно объединить Lxml и Beautiful Soup, так как они совместимы друг с другом. Beautiful Soup использует Lxml как парсер.
Ключевые преимущества библиотеки — высокая скорость анализа больших документов и страниц, удобная функциональность и простое преобразование исходной информации в типы данных Python.
Установить Lxml:
JavaScript
Для JavaScript тоже можно найти готовые библиотеки для парсинга с удобными функциональными API.
Cheerio
Шустрый парсер, который создаёт DOM-дерево страницы и позволяет удобно с ним работать. Cheerio анализирует разметку и предоставляет функции для обработки полученных данных.
API Cheerio будет особенно понятен тем, кто работает с jQuery. Парсер позиционирует себя как инструмент, позволяющей сконцентрироваться на работе с данными, а не на их извлечении.
Установить Cheerio:
Osmosis
По функциональности скрейпер похож на Cheerio, но имеет куда меньше зависимостей. Osmosis написан на Node.js и поддерживает селекторы CSS 3.0 и XPath 1.0. Также он умеет загружать и искать AJAX-контент, записывать логи URL-адресов, редиректов и ошибок, заполнять формы, проходить базовую аутентификацию и многое другое.
Для наглядности можно посмотреть пример парсинга сайтов с помощью Osmosis.
Установить парсер:
Apify SDK
Библиотека Node.js, которую можно использовать вместе с Chrome Headless и Puppeteer.
Apify позволяет выполнять глубокий обход всего веб-сайта, используя очередь URL-адресов. Также с ней можно запускать код парсера для множества URL в CSV-файле, не теряя никаких данных при сбое программы.
Для безопасного скрейпинга Apify использует прокси и отключает распознавание фингерпринта браузера на веб-сайтах.
Установить Apify SDK:
Java
В Java реализованы различные инструменты и библиотеки, а также внешние API, которые можно использовать для парсинга.
Jsoup
Проект с открытым исходным кодом для извлечения и анализа данных с HTML-страниц. Основные функции в целом не отличаются от тех, что предоставляют другие парсеры. К ним относятся загрузка и анализ HTML-страниц, манипулирование HTML-элементами, поддержка прокси, работа с CSS-селекторами и прочее.
Jsoup не поддерживает парсинг на основе XPath.
Jaunt
Библиотека, которую можно использовать для извлечения данных из HTML-страниц или данных JSON с помощью headless-браузера. Jaunt может выполнять и обрабатывать отдельные HTTP-запросы и ответы, а также взаимодействовать с REST API для извлечения данных.
В целом функциональность Jaunt похож на Jsoup за исключением того, что вместо CSS-селекторов Jaunt использует собственный синтаксис.
HTMLUnit
Инфраструктура, которая позволяет моделировать события браузера, (щелчки, прокрутка, отправка форм) и поддерживает JavaScript. Это улучшает процесс автоматизации получения и обработки информации. HTMLUnit поддерживает парсинг на основе XPath, в отличие от JSoup. Ещё его можно использовать для модульного тестирования веб-приложений.
Additional Possible Roadblocks and Solutions
Numerous other obstacles might be presented while scraping modern websites with your own browser instance, but most can be resolved. Here are a few:
Trying to find something before it appears
While browsing yourself, how often do you find that you are waiting for a page to come up, sometimes for many seconds? Well, the same can occur while navigating programmatically. You look for a class or other element – and it’s not there!
Luckily, Selenium has the ability to wait until it sees a certain element, and can timeout if the element doesn’t appear, like so:
Getting through a Captcha
Some sites employ Captcha or similar to prevent unwanted robots (which they might consider you). This can put a damper on web scraping and slow it way down.
For simple prompts (like “what’s 2 + 3?”), these can generally be read and figured out easily. However, for more advanced barriers, there are libraries that can help try to crack it. Some examples are 2Captcha, Death by Captcha, and Bypass Captcha.
Website structural changes
Websites are meant to change – and they often do. That’s why when writing a scraping script, it’s best to keep this in mind. You’ll want to think about which methods you’ll use to find the data, and which not to use. Consider partial matching techniques, rather than trying to match a whole phrase. For example, a website might change a message from “No records found” to “No records located” – but if your match is on “No records,” you should be okay. Also, consider whether to match on XPATH, ID, name, link text, tag or class name, or CSS selector – and which is least likely to change.
Используйте headless-браузер
Особо хитроумные сайты могут отслеживать веб-шрифты, расширения, файлы cookie, цифровые отпечатки (фингерпринты). Иногда они даже встраивают JavaScript-код, открывающий страницу только после его запуска — так зачастую можно определить, поступает ли запрос из браузера. Для обхода таких ресурсов вам потребуется headless-браузер. Он эмулирует поведение настоящего браузера и поддерживает программное управление. Чаще всего для этих целей выбирают Chrome Headless.
Если ресурс отслеживает цифровой отпечаток браузера, то даже многократная смена IP и очистка cookie не всегда помогают, так как вас всё равно могут узнать по фингерпринту. За частую смену IP при одном и том же отпечатке вполне могут заблокировать, и одна из задач Chrome Headless — не допустить этого.
Самый простой способ работать с Chrome Headless — использовать фреймворк, который объединяет все его функции в удобный API. Наиболее известные решения можно найти тут. Но некоторые веб-ресурсы пытаются отслеживать и их: идёт постоянная гонка между сайтами, пытающимися обнаружить headless-браузеры, и headless-браузерами, которые выдают себя за настоящие.
Puppeteer
Puppeteer is a Node library which provides a powerful but simple API that allows you to control Google’s headless Chrome browser. A headless browser means you have a browser that can send and receive requests but has no GUI. It works in the background, performing actions as instructed by an API. You can simulate the user experience, typing where they type and clicking where they click.
The best case to use Puppeteer for web scraping is if the information you want is generated using a combination of API data and Javascript code. Puppeteer can also be used to take screenshots of web pages visible by default when you open a web browser.
Progress monitoring
In the scraping job table views you can track the progress of each scraping job:
* Scraped pages — scraped page count and total scheduled page count.
* Scraped record count — data rows extracted.
* Failed pages — pages that loaded with 4xx or 5xx response code or didn’t load at all.
* Empty pages — pages that loaded successfully but selectors didn’t extract any data.
Our built-in fail-over system automatically re-scrapes any empty and failed pages. If empty and/or failed pages are
still present after the scraping job has finished, it can be continued manually from the scraping job dropdown
menu.
ScrapeSimple
Website: https://www.scrapesimple.com
Who is this for: ScrapeSimple is the perfect service for people who want a custom scraper built for them. Web scraping is made as simple as filling out a form with instructions for what kind of data you want.
Why you should use it: ScrapeSimple lives up to its name with a fully managed service that builds and maintains custom web scrapers for customers. Just tell them what information you need from which sites, and they will design a custom web scraper to deliver the information to you periodically (could be daily, weekly, monthly, or whatever) in CSV format directly to your inbox. This service is perfect for businesses that just want a html scraper without needing to write any code themselves. Response times are quick and the service is incredibly friendly and helpful, making this service perfect for people who just want the full data extraction process taken care of for them.
Data processing using PostgreSQL
PostgreSQL, developed by a worldwide team of volunteers, is an open source relational database Management system (RDMS). The process of processing the scraped data using PostgreSQL is similar to that of MySQL. There would be two changes: First, the commands would be different to MySQL and second, here we will use psycopg2 Python library to perform its integration with Python.
If you are not familiar with PostgreSQL then you can learn it at
https://www.tutorialspoint.com/postgresql/. And with the help of following command we can install psycopg2 Python library −
pip install psycopg2
Previous Page
Print Page
Next Page
Arc has top developers available for hire and freelance jobs. Check out our Python developers!
Martijn Pieters
I breathe, eat and live software development. I’ve built software solutions ranging from digital camera movement synchronisation for a TV series production to web applica…
PythonRelational databasesJavaScriptData visualizationCode reviewDockerFlaskJavaPythonHTML/CSS
Hire Now
John Simons
I am a full stack software engineer and entrepreneur with between 1 and 10 years professional experience working with the technologies listed.
Current focus lies in the …
PythonJavaScriptServerPHPMySQLSQLC#DevOpsNode.jsAsp.netPythonMeteorjQueryApache HadoopMongoDBAmazon web servicesAzureMqttAngularJSWordPressCordovaRedisArduinoTypescriptVpnDockerReactCouchbaseElectronAngular2Web scrapingFull-StackLinuxMicroservicesNginxJavascript / typescriptInternet of thingsContinuous deployment
Hire Now
Matt Tanguay-Carel
I do consulting and web development. I’ve worn many hats but these days I tend to work with startups and coach other developers.
PythonRubyRuby on RailsJavaScriptReactHTML/CSSCode reviewHerokuBrowser testingPythonCordovaBootstrapJavaMongoDBRedisAmazon web servicesDockerCoffeeScriptRelational databasesAngularJSVue
Hire Now
BeautifulSoup
Website: https://www.crummy.com/software/BeautifulSoup/
Who is this for: Python developers who just want an easy interface to parse HTML, and don’t necessarily need the power and complexity that comes with Scrapy.
Why you should use it: Like Cheerio for NodeJS developers, Beautiful Soup is by far the most popular HTML parser for Python developers. It’s been around for over a decade now and is extremely well documented, with many web parsing tutorials teaching developers to use it to scrape various websites in both Python 2 and Python 3. If you are looking for a Python HTML parsing library, this is the one you want.