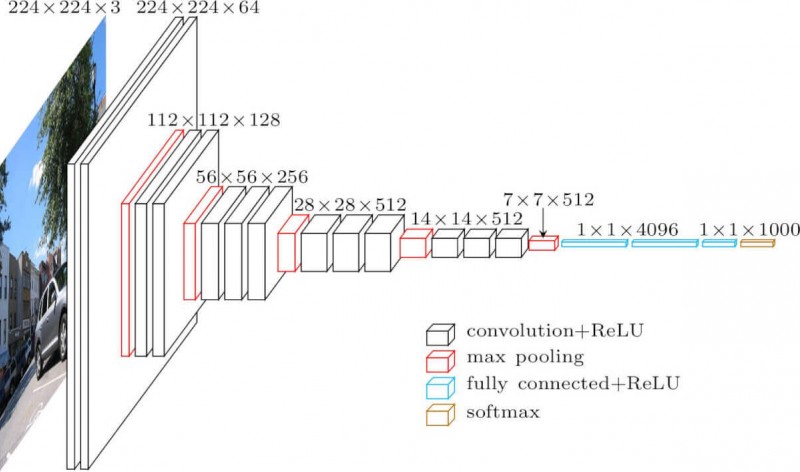
Нейросети и глубокое обучение, глава 1: использование нейросетей для распознавания рукописных цифр
Содержание:
- Оптимизация производительности и ядра CuDNN в TensorFlow 2.0
- Sequence-to-sequence модель
- Фаза прямого распространения нейронной сети
- Предварительная обработка данных
- Неглубокие (shallow) нейронные сети
- Примечания
- What do we need an RNN?
- Тренировка нейронной сети: Стохастический градиентный спуск
- Примечания
- Тренируем нейросеть
- Архитектуры[править]
- Описание проблемы: проект Гутенберг
- История
- Заключение
Оптимизация производительности и ядра CuDNN в TensorFlow 2.0
В TensorFlow 2.0, встроенные слои LSTM и GRU пригодны для использования ядер CuDNN по умолчанию, если доступен графический процессор. С этим изменением предыдущие слои устарели, и вы можете построить свою модель, не беспокоясь об оборудовании, на котором она будет работать.
Поскольку ядро CuDNN построено с некоторыми допущениями, это значит, что слой не сможет использовать слой CuDNN kernel если вы измените параметры по умолчанию встроенных слоев LSTM или GRU. Напр:
- Изменение функции с на что-то другое.
- Изменение функции с на что-то другое.
- Использование > 0.
- Установка равным True, что заставляет LSTM/GRU декомпозировать внутренний в развернутый цикл .
- Установка равным False.
- Использование масок, когда входные данные не выровнены строго справа (если маска соответствует строго выровненным справа данным, CuDNN может быть все еще использовано. Это наиболее распространенный случай).
Создайте экземпляр модели и скомпилируйте его
Мы выбрали в качестве функции потерь. Выходные данные модели имеют размерность . Ответом модели является целочисленный вектор, каждое из чисел находится в диапазоне от 0 до 9.
Постройте новую модель без ядра CuDNN
Как вы можете видеть, модель построенная с CuDNN намного быстрее для обучения чем модель использующая обычное ядро TensorFlow.
Ту же модель с поддержкой CuDNN можно использовать при выводе в однопроцессорной среде. Аннотация просто указывает используемое устройство. Модель выполнится по умолчанию на CPU если не будет доступно GPU.
Вам просто не нужно беспокоиться о железе на котором вы работаете. Разве это не круто?
Sequence-to-sequence модель
Часто Sequence-to-sequence модели состоят из двух рекуррентных сетей: кодировщика, который обрабатывает входные данные, и декодера, который осуществляет вывод.
Читайте: Оценка глубины на изображении при помощи Encoder-Decoder сетей
Sequence-to-Sequence модели часто используются в вопросно-ответных системах, чат-ботах и машинном переводе. Такие многослойные ячейки успешно использовались в sequence-to-sequence моделях для перевода в статье Sequence to Sequence Learning with Neural Networks study.
В Paraphrase Detection Using Recursive Autoencoder представлена новая рекурсивная архитектура автокодировщика, в которой представления — вектора в n-мерном семантическом пространстве, где фразы с похожими значением близки друг к другу.
Фаза прямого распространения нейронной сети
Пришло время для создания рекуррентной нейронной сети. Начнем инициализацию с тремя параметрами веса и двумя смещениями.
Python
import numpy as np
from numpy.random import randn
class RNN:
# Классическая рекуррентная нейронная сеть
def __init__(self, input_size, output_size, hidden_size=64):
# Вес
self.Whh = randn(hidden_size, hidden_size) / 1000
self.Wxh = randn(hidden_size, input_size) / 1000
self.Why = randn(output_size, hidden_size) / 1000
# Смещения
self.bh = np.zeros((hidden_size, 1))
self.by = np.zeros((output_size, 1))
|
1 |
importnumpy asnp fromnumpy.randomimportrandn classRNN # Классическая рекуррентная нейронная сеть def__init__(self,input_size,output_size,hidden_size=64) # Вес self.Whh=randn(hidden_size,hidden_size)1000 self.Wxh=randn(hidden_size,input_size)1000 self.Why=randn(output_size,hidden_size)1000 # Смещения self.bh=np.zeros((hidden_size,1)) self.by=np.zeros((output_size,1)) |
Обратите внимание: для того, чтобы убрать внутреннюю вариативность весов, мы делим на 1000. Это не самый лучший способ инициализации весов, но он довольно простой, подойдет для новичков и неплохо работает для данного примера
Для инициализации веса из стандартного нормального распределения мы используем np.random.randn().
Затем мы реализуем прямую передачу рассматриваемой нейронной сети. Помните первые два уравнения, рассматриваемые ранее?
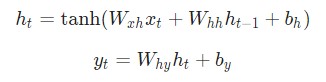
Эти же уравнения, реализованные в коде:
Python
class RNN:
# …
def forward(self, inputs):
»’
Выполнение передачи нейронной сети при помощи входных данных
Возвращение результатов вывода и скрытого состояния
Вывод — это массив одного унитарного вектора с формой (input_size, 1)
»’
h = np.zeros((self.Whh.shape, 1))
# Выполнение каждого шага в нейронной сети RNN
for i, x in enumerate(inputs):
h = np.tanh(self.Wxh @ x + self.Whh @ h + self.bh)
# Compute the output
y = self.Why @ h + self.by
return y, h
|
1 |
classRNN # … defforward(self,inputs) »’ Выполнение передачи нейронной сети при помощи входных данных h=np.zeros((self.Whh.shape,1)) # Выполнение каждого шага в нейронной сети RNN fori,xinenumerate(inputs) h=np.tanh(self.Wxh@x+self.Whh@h+self.bh) # Compute the output y=self.Why@h+self.by returny,h |
Довольно просто, не так ли? Обратите внимание на то, что мы инициализировали для нулевого вектора в первом шаге, так как у нас нет предыдущего , который теперь можно использовать. Давайте попробуем следующее:
Давайте попробуем следующее:
Python
# …
def softmax(xs):
# Применение функции Softmax для входного массива
return np.exp(xs) / sum(np.exp(xs))
# Инициализация нашей рекуррентной нейронной сети RNN
rnn = RNN(vocab_size, 2)
inputs = createInputs(‘i am very good’)
out, h = rnn.forward(inputs)
probs = softmax(out)
print(probs) # , ]
|
1 |
# … defsoftmax(xs) # Применение функции Softmax для входного массива returnnp.exp(xs)sum(np.exp(xs)) rnn=RNN(vocab_size,2) inputs=createInputs(‘i am very good’) out,h=rnn.forward(inputs) probs=softmax(out) print(probs)# , ] |
Наша рекуррентная нейронная сеть работает, однако ее с трудом можно назвать полезной. Давайте исправим этот недочет.
Предварительная обработка данных
Как и в случае с любой другой задачей для машинного обучения, мы начнем с загрузки и подготовки нашего набора данных
После загрузки набора данных, обратите внимание на то, что в папке с данными есть папка под названием names. Она содержит текстовые файлы с фамилиями на восемнадцати разных именах
Чтобы загрузить все файлы одним махом, мы используем модуль Python под названием glob. Модуль glob находит все совпадения названий путей по особому шаблону, в соответствии с правилами, используемыми в оболочке Unix. Результаты возвращаются в произвольном порядке. Мы используем его для загрузки всех файлов с окончанием .txt в папку.
Python
import glob
all_text_files = glob.glob(‘data/names/*.txt’)
print(all_text_files)
|
1 |
importglob all_text_files=glob.glob(‘data/names/*.txt’) print(all_text_files) |

В данный момент, названия находятся в формате Unicode. Однако, нам нужно конвертировать их в стандарт ASCII. Это поможет с удалением диакритиков в словах. Например, французское имя Béringer будет конвертировано в Beringer.
Python
import unicodedata
import string
all_letters = string.ascii_letters + » .,;'»
n_letters = len(all_letters)
def unicode_to_ascii(s):
return ».join(
c for c in unicodedata.normalize(‘NFD’, s)
if unicodedata.category(c) != ‘Mn’
and c in all_letters
)
print(unicode_to_ascii(‘Béringer’))
|
1 |
importunicodedata importstring all_letters=string.ascii_letters+» .,;'» n_letters=len(all_letters) defunicode_to_ascii(s) return».join( cforcinunicodedata.normalize(‘NFD’,s) ifunicodedata.category(c)!=’Mn’ andcinall_letters ) print(unicode_to_ascii(‘Béringer’)) |
Следующий шаг — со списком имен для каждого языка.
Python
category_languages = {}
all_categories = []
def readLines(filename):
lines = open(filename).read().strip().split(‘\n’)
return
for filename in all_text_files:
category = filename.split(‘/’).split(‘.’)
all_categories.append(category)
languages = readLines(filename)
category_languages = languages
no_of_languages = len(all_categories)
print(‘There are {} langauages’.format(no_of_languages))
|
1 |
category_languages={} all_categories= defreadLines(filename) lines=open(filename).read().strip().split(‘\n’) returnunicode_to_ascii(line)forline inlines forfilename inall_text_files category=filename.split(‘/’)-1.split(‘.’) all_categories.append(category) languages=readLines(filename) category_languagescategory=languages no_of_languages=len(all_categories) print(‘There are {} langauages’.format(no_of_languages)) |
Мы можем ознакомиться с первыми 15 именами во французском словаре, как показано ниже.

Неглубокие (shallow) нейронные сети
Неглубокие модели, как и глубокие нейронные сети, тоже популярные и полезные инструменты. Например, word2vec — группа неглубоких двухслойных моделей, которая используется для создания векторных представлений слов (word embeddings). Представленная в Efficient Estimation of Word Representations in Vector Space, word2vec принимает на входе большой корпус текста и создает векторное пространство. Каждому слову в этом корпусе приписывается соответствующий вектор в этом пространстве. Отличительное свойство — слова из общих текстов в корпусе расположены близко друг к другу в векторном пространстве.
В статье описаны архитектуры нейронных сетей: глубокий многослойный перцептрон, сверточная, рекурсивная, рекуррентная сети, нейросети долгой краткосрочной памяти, sequence-to-sequence модели и неглубокие (shallow) сети, word2vec для векторных представлений слов. Кроме того, было показано, как функционируют эти сети, и как различные модели справляются с задачами обработки естественного языка. Также отмечено, что сверточные нейронные сети в основном используются для задач классификации текста, в то время как рекуррентные сети хорошо работают с воспроизведением естественного языка или машинным переводом. В следующих части серии будут описаны существующие инструменты и библиотеки для реализации описанных типов нейросетей.
Интересные статьи:
- Facebook создали алгоритм для перевода с редких языков
- NLP Architect от Intel: open source библиотека моделей обработки естественного языка
- Как создать чат-бота с нуля на Python: подробная инструкция
Примечания
- ↑
-
↑ Li, Xiangang & Wu, Xihong (2014-10-15), «Constructing Long Short-Term Memory based Deep Recurrent Neural Networks for Large Vocabulary Speech Recognition»,
- Page 150 ff demonstrates credit assignment across the equivalent of 1,200 layers in an unfolded RNN.
-
Hannun, Awni; Case, Carl; Casper, Jared; Catanzaro, Bryan; Diamos, Greg; Elsen, Erich; Prenger, Ryan; Satheesh, Sanjeev; et al. (2014-12-17), «Deep Speech: Scaling up end-to-end speech recognition»,
- Bo Fan, Lijuan Wang, Frank K. Soong, and Lei Xie (2015). Photo-Real Talking Head with Deep Bidirectional LSTM. In Proceedings of ICASSP 2015.
-
Jozefowicz, Rafal; Vinyals, Oriol; Schuster, Mike; Shazeer, Noam & Wu, Yonghui (2016-02-07), «Exploring the Limits of Language Modeling»,
-
Gillick, Dan; Brunk, Cliff; Vinyals, Oriol & Subramanya, Amarnag (2015-11-30), «Multilingual Language Processing From Bytes»,
-
Vinyals, Oriol; Toshev, Alexander; Bengio, Samy & Erhan, Dumitru (2014-11-17), «Show and Tell: A Neural Image Caption Generator»,
- Seppo Linnainmaa (1970). The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors. Master’s Thesis (in Finnish), Univ. Helsinki, 6-7.
- Griewank, Andreas. / Andreas Griewank, Walther. — Second. — SIAM, 2008. — ISBN 978-0-89871-776-1.
- Journal |date=1988 |title=Bidirectional associative memories |journal=IEEE Transactions on Systems, Man, and Cybernetics |volume=18 |issue=1 |pages=49–60 |doi=10.1109/21.87054 |last1=Kosko |first1=B.}}
- ↑
- W. Maass, T. Natschläger, and H. Markram. A fresh look at real-time computation in generic recurrent neural circuits. Technical report, Institute for Theoretical Computer Science, TU Graz, 2002.
- ↑
- Fernández, Santiago (2007). «Sequence labelling in structured domains with hierarchical recurrent neural networks». Proc. 20th Int. Joint Conf. on Artificial In℡ligence, Ijcai 2007: 774–779.
- Graves, Alex (2006). «Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks». In Proceedings of the International Conference on Machine Learning, ICML 2006: 369–376.
-
Chung, Junyoung; Gulcehre, Caglar; Cho, KyungHyun & Bengio, Yoshua (2014), «Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling»,
What do we need an RNN?
The structure of an Artificial Neural Network is relatively simple and is mainly about matrice multiplication. During the first step, inputs are multiplied by initially random weights, and bias, transformed with an activation function and the output values are used to make a prediction. This step gives an idea of how far the network is from the reality.
The metric applied is the loss. The higher the loss function, the dumber the model is. To improve the knowledge of the network, some optimization is required by adjusting the weights of the net. The stochastic gradient descent is the method employed to change the values of the weights in the rights direction. Once the adjustment is made, the network can use another batch of data to test its new knowledge.
The error, fortunately, is lower than before, yet not small enough. The optimization step is done iteratively until the error is minimized, i.e., no more information can be extracted.
The problem with this type of model is, it does not have any memory. It means the input and output are independent. In other words, the model does not care about what came before. It raises some question when you need to predict time series or sentences because the network needs to have information about the historical data or past words.
To overcome this issue, a new type of architecture has been developed: Recurrent Neural network (RNN hereafter)
In this tutorial, you will learn.
Тренировка нейронной сети: Стохастический градиентный спуск
У нас есть все необходимые инструменты для тренировки нейронной сети. Мы используем алгоритм оптимизации под названием стохастический градиентный спуск (SGD), который говорит нам, как именно поменять вес и смещения для минимизации потерь. По сути, это отражается в следующем уравнении:
является константой под названием оценка обучения, что контролирует скорость обучения. Все что мы делаем, так это вычитаем из :
- Если положительная, уменьшится, что приведет к уменьшению .
- Если отрицательная, увеличится, что приведет к уменьшению .
Если мы применим это на каждый вес и смещение в сети, потеря будет постепенно снижаться, а показатели сети сильно улучшатся.
Наш процесс тренировки будет выглядеть следующим образом:
- Выбираем один пункт из нашего набора данных. Это то, что делает его стохастическим градиентным спуском. Мы обрабатываем только один пункт за раз;
- Подсчитываем все частные производные потери по весу или смещению. Это может быть , и так далее;
- Используем уравнение обновления для обновления каждого веса и смещения;
- Возвращаемся к первому пункту.
Давайте посмотрим, как это работает на практике.
Примечания
- ↑
-
↑ Li, Xiangang & Wu, Xihong (2014-10-15), «Constructing Long Short-Term Memory based Deep Recurrent Neural Networks for Large Vocabulary Speech Recognition»,
- Page 150 ff demonstrates credit assignment across the equivalent of 1,200 layers in an unfolded RNN.
-
Hannun, Awni; Case, Carl; Casper, Jared; Catanzaro, Bryan; Diamos, Greg; Elsen, Erich; Prenger, Ryan; Satheesh, Sanjeev; et al. (2014-12-17), «Deep Speech: Scaling up end-to-end speech recognition»,
- Bo Fan, Lijuan Wang, Frank K. Soong, and Lei Xie (2015). Photo-Real Talking Head with Deep Bidirectional LSTM. In Proceedings of ICASSP 2015.
-
Jozefowicz, Rafal; Vinyals, Oriol; Schuster, Mike; Shazeer, Noam & Wu, Yonghui (2016-02-07), «Exploring the Limits of Language Modeling»,
-
Gillick, Dan; Brunk, Cliff; Vinyals, Oriol & Subramanya, Amarnag (2015-11-30), «Multilingual Language Processing From Bytes»,
-
Vinyals, Oriol; Toshev, Alexander; Bengio, Samy & Erhan, Dumitru (2014-11-17), «Show and Tell: A Neural Image Caption Generator»,
- Seppo Linnainmaa (1970). The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors. Master’s Thesis (in Finnish), Univ. Helsinki, 6-7.
- Griewank, Andreas. / Andreas Griewank, Walther. — Second. — SIAM, 2008. — ISBN 978-0-89871-776-1.
- Journal |date=1988 |title=Bidirectional associative memories |journal=IEEE Transactions on Systems, Man, and Cybernetics |volume=18 |issue=1 |pages=49–60 |doi=10.1109/21.87054 |last1=Kosko |first1=B.}}
- ↑
- W. Maass, T. Natschläger, and H. Markram. A fresh look at real-time computation in generic recurrent neural circuits. Technical report, Institute for Theoretical Computer Science, TU Graz, 2002.
- ↑
- Fernández, Santiago (2007). «Sequence labelling in structured domains with hierarchical recurrent neural networks». Proc. 20th Int. Joint Conf. on Artificial In℡ligence, Ijcai 2007: 774–779.
- Graves, Alex (2006). «Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks». In Proceedings of the International Conference on Machine Learning, ICML 2006: 369–376.
-
Chung, Junyoung; Gulcehre, Caglar; Cho, KyungHyun & Bengio, Yoshua (2014), «Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling»,
Тренируем нейросеть
Python
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader): # Загрузка партии изображений с индексом, данными, классом
images = Variable(images.view(-1, 28*28)) # Конвертация тензора в переменную: изменяем изображение с вектора, размером 784 на матрицу 28 x 28
labels = Variable(labels)
optimizer.zero_grad() # Инициализация скрытых масс до нулей
outputs = net(images) # Передний пропуск: определение выходного класса, данного изображения
loss = criterion(outputs, labels) # Определение потерь: разница между выходным классом и предварительно заданной меткой
loss.backward() # Обратный проход: определение параметра weight
optimizer.step() # Оптимизатор: обновление параметров веса в скрытых узлах
if (i+1) % 100 == 0: # Логирование
print(‘Epoch [%d/%d], Step [%d/%d], Loss: %.4f’
%(epoch+1, num_epochs, i+1, len(train_dataset)//batch_size, loss.data))
|
1 |
forepoch inrange(num_epochs) fori,(images,labels)inenumerate(train_loader)# Загрузка партии изображений с индексом, данными, классом images=Variable(images.view(-1,28*28))# Конвертация тензора в переменную: изменяем изображение с вектора, размером 784 на матрицу 28 x 28 labels=Variable(labels) optimizer.zero_grad()# Инициализация скрытых масс до нулей outputs=net(images)# Передний пропуск: определение выходного класса, данного изображения loss=criterion(outputs,labels)# Определение потерь: разница между выходным классом и предварительно заданной меткой loss.backward()# Обратный проход: определение параметра weight optimizer.step()# Оптимизатор: обновление параметров веса в скрытых узлах if(i+1)%100==# Логирование print(‘Epoch [%d/%d], Step [%d/%d], Loss: %.4f’ %(epoch+1,num_epochs,i+1,len(train_dataset)batch_size,loss.data)) |
Архитектуры[править]
Полностью рекуррентная сетьправить
Это базовая архитектура, разработанная в 1980-х. Сеть строится из узлов, каждый из которых соединён со всеми другими узлами. У каждого нейрона порог активации меняется со временем и является вещественным числом. Каждое соединение имеет переменный вещественный вес. Узлы разделяются на входные, выходные и скрытые.
Рекурсивная сетьправить
Рекурсивные нейронные сети представляют собой более общий случай рекуррентных сетей, когда сигнал в сети проходит через структуру в виде дерева (обычно бинарные деревья). Те же самые матрицы весов используются рекурсивно по всему графу в соответствии с его топологией.
Нейронная сеть Хопфилдаправить
Тип рекуррентной сети, когда все соединения симметричны. Изобретена Джоном Хопфилдом в 1982 году и гарантируется, что динамика такой сети сходится к одному из положений равновесия.
Двунаправленная ассоциативная память (BAM)править
Вариацией сети Хопфилда является двунаправленная ассоциативная память (BAM). BAM имеет два слоя, каждый из которых может выступать в качестве входного, находить (вспоминать) ассоциацию и генерировать результат для другого слоя.
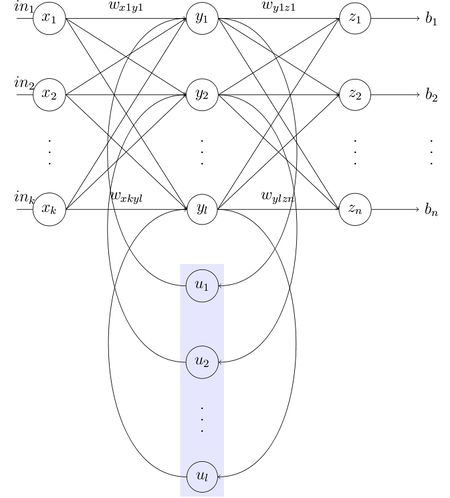
Сеть Элмана
Сеть Элманаправить
Нейронная сеть Элмана состоит из трёх слоев: x, y, z (см рис. Сеть Элмана). Дополнительно к сети добавлен набор «контекстных блоков»: u (см рис. Сеть Элмана). Средний (скрытый) слой соединён с контекстными блоками с фиксированным весом, равным единице. С каждым шагом времени на вход поступает информация, которая проходит прямой ход к выходному слою в соответствии с правилами обучения. Фиксированные обратные связи сохраняют предыдущие значения скрытого слоя в контекстных блоках (до того как скрытый слой поменяет значение в процессе обучения). Таким способом сеть сохраняет своё состояние, что может использоваться в предсказании последовательностей, выходя за пределы мощности многослойного перцептрона.
,
,
Обозначения переменных и функций:
- : вектор входного слоя;
- : вектор скрытого слоя;
- : вектор выходного слоя;
- : матрица и вектор параметров;
- : функция активации.
Сеть Джорданаправить
Нейронная сеть Джордана подобна сети Элмана, но контекстные блоки связаны не со скрытым слоем, а с выходным слоем. Контекстные блоки таким образом сохраняют своё состояние. Они обладают рекуррентной связью с собой.
,
,
Эхо-сетиправить
Эхо-сеть (англ. Echo State Network, ESN) характеризуется одним скрытым слоем (который называется резервуаром) со случайными редкими связями между нейронами. При этом связи внутри резервуара фиксированы, но связи с выходным слоем подлежат обучению. Состояние резервуара (state) вычисляется через предыдущие состояния резервуара, а также предыдущие состояния входного и выходного сигналов. Так как эхо-сети обладают только одним скрытым слоем, они обладают достаточно низкой вычислительной сложностью.
Нейронный компрессор историиправить
Нейронный компрессор исторических данных — это блок, позволяющий в сжатом виде хранить существенные исторические особенности процесса, который является своего рода стеком рекуррентной нейронной сети, формируемым в процессе самообучения.
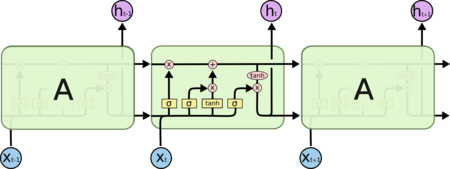
Сети долго-краткосрочной памятиправить
Сеть долго-краткосрочной памяти (англ. Long short-term memory, LSTM) является самой популярной архитектурой рекуррентной нейронной сети на текущий момент, такая архитектура способна запоминать данные на долгое время.
Управляемые рекуррентные блокиправить
Управляемые рекуррентные блоки (англ. Gated Recurrent Units, GRU) — обладает меньшим количеством параметров, чем у LSTM, и в ней отсутствует выходное управление. При этом производительность в моделях речевого сигнала или полифонической музыки оказалась сопоставимой с LSTM.
Описание проблемы: проект Гутенберг
Многие из классических текстов больше не защищены авторским правом.
Это означает, что вы можете скачать весь текст этих книг бесплатно и использовать их в экспериментах, например, при создании генеративных моделей. Возможно, лучшее место для получения доступа к бесплатным книгам, которые больше не защищены авторским правом, этоПроект Гутенберг,
В этом уроке мы собираемся использовать любимую книгу из детства в качестве набора данных:Приключения Алисы в Стране Чудес Льюиса Кэрролла,
Мы собираемся изучить зависимости между символами и условные вероятности символов в последовательностях, чтобы мы могли, в свою очередь, генерировать совершенно новые и оригинальные последовательности символов.
Это очень весело, и я рекомендую повторить эти эксперименты с другими книгами из проекта Гутенберга,вот список самых популярных книг на сайте,
Эти эксперименты не ограничиваются текстом, вы также можете поэкспериментировать с другими данными ASCII, такими как компьютерный исходный код, размеченные документы в LaTeX, HTML или Markdown и другие.
Вы можетескачать полный текст в формате ASCII(Обычный текст UTF-8) для этой книги бесплатно и поместите ее в свой рабочий каталог с именем файлаwonderland.txt,
Теперь нам нужно подготовить набор данных к моделированию.
Project Gutenberg добавляет стандартный колонтитул к каждой книге, и это не является частью исходного текста. Откройте файл в текстовом редакторе и удалите верхний и нижний колонтитулы.
Заголовок очевиден и заканчивается текстом:
Нижний колонтитул — весь текст после строки текста, которая говорит:
Вы должны остаться с текстовым файлом, который содержит около 3330 строк текста.
Нужна помощь с LSTM для прогнозирования последовательности?
Пройдите мой бесплатный 7-дневный курс по электронной почте и откройте для себя 6 различных архитектур LSTM (с кодом).
Нажмите, чтобы зарегистрироваться, а также получите бесплатную PDF-версию курса Ebook.
История
Джон Хопфилд в 1982 предложил Сеть Хопфилда. В 1993 нейронная система запоминания и сжатия исторических данных смогла решить задачу «очень глубокого обучения», в которой в рекуррентной сети разворачивалось более 1000 последовательных слоёв.
Долгая краткосрочная память (LSTM)
Сеть с долговременной и кратковременной памятью (англ. Long short term memory, LSTM); LSTM). нашла применение в различных приложениях.
Начиная с 2007 года LSTM приобрела популярность и смогла вывести на новый уровень распознавание речи, показав существенное улучшение по сравнению с традиционными моделями. В 2009 году появился подход классификации по рейтингу (Connectionist Temporal Classification, (CTC)). Этот метод позволил рекуррентным сетям подключить анализ контекста при распознавании рукописного текста. В 2014 году китайская энциклопедия и поисковая система Baidu, используя рекуррентные сети с обучением по CTC смогли поднять на новый уровень показатели Switchboard Hub5’00, опередив традиционные методы.
LSTM привела также к улучшению распознавания речи с большими словарями и улучшения синтеза речи по тексту, и нашла также применение в операционной системе Google Android. В 2015 году распознавание речи у Google значительно повысило показатели вплоть до 49 %, причиной того стало использование специальной системы обучения LSTM на базе CTC в системе Google voice search.
LSTM вывело на новый уровень качество машинного перевода,, построения языковых моделей и обработки многоязычного текста. Сочетание LSTM со свёрточными нейронными сетями (CNN) позволило усовершенствовать автоматическое описание изображений.
Заключение
Представленные как набор уравнений, LSTM выглядят довольно устрашающе. Надеюсь, проход всей схемы шаг за шагом в этом посте сделало их немного более доступными.
LSTM были большим шагом в развитии РНС. Естественно задаться вопросом: а что, можно пойти дальше? Общее для исследователей мнение: «Да! Cледующий шаг заключается в использовании механизма внимания!» Идея состоит в том, чтобы РНС на каждом шаге выбирала информацию для просмотра из некого большего количества данных. Например, если вы используете РНС для создания описания изображения, сеть может выбрать часть изображения для просмотра каждого выводимого слова. Именно это и было проделано в и станет отправной точкой для изучения механизма внимания.
Интересные статьи:
- Как работает сверточная нейронная сеть: архитектура, примеры, особенности
- Генеративно-состязательная нейросеть (GAN). Руководство для новичков
- Как создать собственную нейронную сеть с нуля на языке Python