Машинное обучение
Содержание:
- Линейная регрессия
- Алгоритм k-ближайших соседей (K-Nearest Neighbors)
- Об этом курсе
- Шаг второй: данные — какие данные у вас есть?
- Шаг пятый: моделирование — какую модель выбрать? Как вы можете улучшить её? Как вы сравниваете её с другими моделями?
- Процесс машинного обучения
- Какие существуют типы машинного обучения и чем они отличаются
- Классификация
- Примеры задач классификации
- Для чего можно использовать машинное обучение
- Шаг третий: оценка — что определяет успех? Достаточно ли хороша модель машинного обучения с точностью 95 %?
Линейная регрессия
Линейная регрессия — пожалуй, один из наиболее известных и понятных алгоритмов в статистике и машинном обучении.
Прогностическое моделирование в первую очередь касается минимизации ошибки модели или, другими словами, как можно более точного прогнозирования. Мы будем заимствовать алгоритмы из разных областей, включая статистику, и использовать их в этих целях.
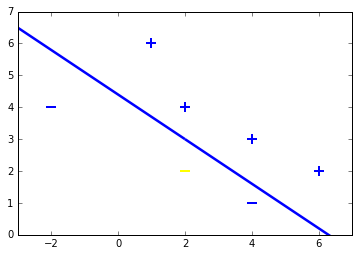
Линейную регрессию можно представить в виде уравнения, которое описывает прямую, наиболее точно показывающую взаимосвязь между входными переменными и выходными переменными . Для составления этого уравнения нужно найти определённые коэффициенты для входных переменных.
Например:
Зная , мы должны найти , и цель линейной регрессии заключается в поиске значений коэффициентов и .
Для оценки регрессионной модели используются различные методы вроде линейной алгебры или метода наименьших квадратов.
Линейная регрессия существует уже более 200 лет, и за это время её успели тщательно изучить. Так что вот пара практических правил: уберите похожие (коррелирующие) переменные и избавьтесь от шума в данных, если это возможно. Линейная регрессия — быстрый и простой алгоритм, который хорошо подходит в качестве первого алгоритма для изучения.
Алгоритм k-ближайших соседей (K-Nearest Neighbors)
Как построить алгоритм К-ближайших соседей
- Соберите все данные
- Вычислите Евклидово расстояние от новой точки данных х до всех остальных точек в множестве данных
- Отсортируйте точки из множества данных в порядке возрастания расстояния до х
- Спрогнозируйте ответ, используя ту же категорию, что и большинство К-ближайших к х данных
Плюсы и минусы алгоритма К-ближайших соседей
Плюсы:
- Алгоритм прост и его легко понять
- Тривиальное обучение модели на новых тренировочных данных
- Работает с любым количеством категорий в задаче классификации
- Легко добавить больше данных в множество данных
- Модель принимает только 2 параметра: К и метрика расстояния, которой вы хотели бы воспользоваться (обычно это Евклидово расстояние)
Минусы:
- Высокая стоимость вычисления, т.к. вам требуется обработать весь объем данных
- Работает не так хорошо с категорическими параметрами
Подведем итог
Пример задачи на классификацию(футболисты или баскетболисты), которую может решить алгоритм
Как данный алгоритм использует Евклидово расстояние до соседних точек для прогнозирования к какой категории принадлежит новая точка данных
Почему значения параметра К важно для прогнозирования
Плюсы и минусы использования алгоритма К-ближайших соседей
Об этом курсе
Недавно просмотрено: 217,666
Обучение на размеченных данных или обучение с учителем – это наиболее распространенный класс задач машинного обучения. К нему относятся те задачи, где нужно научиться предсказывать некоторую величину для любого объекта, имея конечное число примеров. Это может быть предсказание уровня пробок на участке дороги, определение возраста пользователя по его действиям в интернете, предсказание цены, по которой будет куплена подержанная машина.
В этом курсе вы научитесь формулировать и, конечно, решать такие задачи. В центре нашего внимания будут успешно применяемые на практике алгоритмы классификации и регрессии: линейные модели, нейронные сети, решающие деревья и так далее. Особый акцент мы сделаем на такой мощной технике как построение композиций, которая позволяет существенно повысить качество отдельных алгоритмов и широко используется при решении прикладных задач. В частности, мы узнаем про случайные леса и про метод градиентного бустинга.
Построение предсказывающих алгоритмов — это лишь часть работы при решении задачи анализа данных. Мы разберемся и с другими этапами: оценивание обобщающей способности алгоритмов, подбор параметров модели, выбор и подсчет метрик качества.
Видео курса разработаны на Python 2. Задания и ноутбуки к ним адаптированы к Python 3.
User
Карьерные результаты учащихся
Формирование карьерного пути
стал больше зарабатывать или получил повышение
Сертификат, ссылками на который можно делиться с другими людьми
Сертификат, ссылками на который можно делиться с другими людьми
Получите сертификат по завершении
100% онлайн
100% онлайн
Начните сейчас и учитесь по собственному графику.
Специализация
Курс 2 из 6 в программе
Специализация Машинное обучение и анализ данных
Гибкие сроки
Гибкие сроки
Назначьте сроки сдачи в соответствии со своим графиком.
Промежуточный уровень
Промежуточный уровень
Часов на завершение
Прибл. 61 час на выполнение
Доступные языки
Русский
Субтитры: Русский
Шаг второй: данные — какие данные у вас есть?
Данные, которые у вас есть или которые вы соберёте, будут зависеть от задачи, которую вы хотите решить.
Если у вас уже есть данные, скорее всего, они будут в одной из двух форм: структурированные или неструктурированные. Внутри каждой из них есть статические или потоковые данные.
- Структурированные данные — представьте себе таблицу строк и столбцов, электронную таблицу транзакций клиентов, базу данных записей пациентов. Столбцы могут быть числовыми вроде средней частоты сердечных сокращений, категориальными вроде пола человека или порядковыми вроде интенсивности болей в груди.
- Неструктурированные данные — всё, что не может быть сразу помещено в формат строки и столбца: изображения, аудиофайлы, текст на естественном языке.
- Статические данные — существующие исторические данные, которые вряд ли изменятся. Хороший пример — история покупок.
- Потоковые данные — данные, которые постоянно обновляются, старые записи могут быть изменены, новые записи постоянно добавляются.
Стоит отметить, что здесь могут быть перекрещивающиеся типы данных.
Статическая структурированная информационная таблица может иметь столбцы, которые содержат текст на естественном языке и фотографии, и при этом постоянно обновляться.
Для прогнозирования сердечных заболеваний один столбец может содержать пол, другой — средний сердечный ритм, третий — среднее артериальное давление, четвёртый — интенсивность боли в груди.
Для примера со страховым возмещением один столбец в таблице может быть с текстом, отправленным клиентом в заявлении, другой столбец может быть с изображением, которое он отправил вместе с текстом, и в последнем столбце — результат иска. Эта таблица ежедневно обновляется новыми заявками или изменёнными результатами старых заявок.
Принцип сохраняется. Вы хотите использовать данные, которые у вас есть, чтобы получить понимание общей картины или прогноз чего-либо.
Для контролируемого обучения это включает в себя использование переменных особенностей для прогнозирования целевых переменных. Переменной особенностей для прогнозирования заболеваний сердца может быть пол, а целевой — прогноз, есть ли у пациента болезнь сердца.
При неконтролируемом обучении у вас не будет меток. Но всё ещё нужно найти шаблоны. А значит будет использоваться группировка похожих образцов и поиск образцов, которые отличаются.
Трансферное обучение — это то же контролируемое обучение, за исключением того, что вы используете алгоритмы машинного обучения для шаблонов, извлечённых из других источников данных, отличных от ваших собственных.
Помните, что, если вы используете данные о клиентах для улучшения своего бизнеса или для предоставления им более качественного сервиса, важно сообщить им об этом. Вот почему вы часто видите всплывающие окна «этот сайт использует куки»
Веб-сайт собирает информацию о том, как вы просматриваете сайт, вероятно, наряду с этим использует машинное обучение, чтобы улучшить предложение.
Шаг пятый: моделирование — какую модель выбрать? Как вы можете улучшить её? Как вы сравниваете её с другими моделями?
После того как вы определили задачу, подготовили данные, критерии оценки и характеристики, можно начинать моделировать.
Моделирование делится на три части: выбор модели, улучшение модели, сравнение её с другими.
Выбор модели
При выборе модели вы должны принять во внимание следующее: интерпретируемость и простота отладки, объём данных, ограничения на обучение и прогнозирование
- Интерпретируемость и простота отладки — почему модель приняла решение, которое она приняла? Как исправить ошибки?
- Количество данных — сколько данных у вас есть? Изменится ли их количество?
- Ограничения в обучении и прогнозировании — это связано с вышеизложенным: сколько времени и ресурсов у вас есть для обучения и прогнозирования?
Чтобы решить эти проблемы, начните с простого. Сделать свою модель идеальной — заманчивая цель. Но если для обучения требуется в 10 раз больше вычислительных ресурсов, в 5 раз больше времени прогнозирования, а показатель оценки увеличится на 2 %, это будет не лучшее решение.
Линейные модели, такие как логистическая регрессия, обычно легче интерпретировать, они очень быстро обучаются и прогнозируются быстрее, чем более глубокие модели, такие как нейронные сети.
Но, скорее всего, ваши данные взяты из реального мира. Данные из реального мира не всегда линейны.
Что делать в таком случае?
Наборы деревьев решений и алгоритмов повышения градиента (модные слова, определения, которые пока не важны) обычно лучше всего работают со структурированными данными, такими как таблицы Excel и датафреймы
Обратите внимание на случайные леса, XGBoost и CatBoost
Глубокие модели, такие как нейронные сети, обычно лучше всего работают с неструктурированными данными вроде изображений, аудиофайлов и текстов на естественном языке. Тем не менее, компромисс заключается в том, что они обычно дольше обучаются, их сложнее отлаживать и прогнозирование занимает больше времени. Но это не значит, что вы не должны их использовать.
Трансферное обучение — это подход, который использует преимущества глубоких и линейных моделей. При трансферном обучении берётся предварительно обученная глубокая модель и шаблоны, которые она изучила, используются в качестве входных данных для вашей линейной модели. Это значительно экономит время настройки и позволяет вам экспериментировать быстрее.
Где можно найти предварительно обученные модели?
Такие модели доступны в PyTorch hub, TensorFlow hub, model zoo и в fast.ai framework. Это хорошие ресурсы, которые стоит посмотреть перед созданием вашего прототипа.
Что насчёт других видов моделей?
Для создания прототипа вам вряд ли когда-нибудь понадобится создавать собственную модель машинного обучения. Люди уже написали код для них.
Вам нужно сосредоточиться на подготовке ваших входных и выходных данных таким образом, чтобы их можно было использовать с существующей моделью. Это означает, что ваши данные и метки должны быть строго определены. А вы должны понимать, какую задачу вы пытаетесь решить.
Настройка и улучшение модели
Первые результаты модели не являются финальными. Как и в случае с тюнингом автомобиля, модели машинного обучения можно настраивать для повышения производительности.
Настройка модели включает изменение гиперпараметров вроде скорости обучения или оптимизатора. Или специфические для модели архитектурные факторы, такие как количество деревьев для случайных лесов и количество и тип слоёв для нейронных сетей.
Раньше приходилось настраивать их вручную, но они всё больше автоматизируются. И должны быть автоматизированными везде, где это возможно.
Использование предварительно обученной через трансферное обучение модели часто даёт дополнительное преимущество всех этих шагов.
Приоритетами для настройки и улучшения моделей должны быть воспроизводимость и эффективность. Кто-то должен быть в состоянии воспроизвести шаги, которые вы предприняли для повышения производительности. И поскольку вашим главным узким местом будет время обучения модели, а не новые идеи для улучшения, ваши усилия должны быть направлены на повышение эффективности.
Сравнение моделей
- Модель 1, обученная на данных X, оценена на данных Y.
- Модель 2, обученная на данных X, оценена на данных Y.
Где-то модели 1 и 2 могут отличаться, но не в данных X или Y.
Процесс машинного обучения
Процесс содержит в себе следующие этапы: подготовка данных, создание обучающих наборов, создание классификатора, обучение классификатора, составление прогнозов, оценка производительности классификатора и настройка параметров.
Во-первых, нужно подготовить набор данных для классификатора — преобразовать данные в корректную для классификации форму и обработать любые аномалии в этих данных. Отсутствие значений в данных либо любые другие отклонения — все их нужно обработать, иначе они могут негативно влиять на производительность классификатора. Этот этап называется предварительной обработкой данных (англ. data preprocessing).
Следующим шагом будет разделение данных на обучающие и тестовые наборы. Для этого в Scikit-Learn существует отличная функция traintestsplit.
Как уже было сказано выше, классификатор должен быть создан и обучен на тренировочном наборе данных. После этих шагов модель уже может делать прогнозы. Сравнивая показания классификатора с фактически известными данными, можно делать вывод о точности классификатора.
Вероятнее всего, вам нужно будет «корректировать» параметры классификатора, пока вы не достигните желаемой точности (т. к. маловероятно, что классификатор будет соответствовать всем вашим требованиям с первого же запуска).
Ниже будет представлен пример работы машинного обучения от обработки данных и до оценки.
Какие существуют типы машинного обучения и чем они отличаются
Существует множество моделей для машинного обучения, но они, как правило, относятся к одному из трех типов:
- обучение с учителем (supervised learning);
- обучение без учителя, или самообучение (unsupervised learning);
- обучение с подкреплением (reinforcement learning).
В зависимости от выполняемой задачи, одни модели могут быть более подходящими и более эффективными, чем другие.
Обучение с учителем (supervised learning)
В этом типе корректный результат при обучении модели явно обозначается для каждого идентифицируемого элемента в наборе данных. Это означает, что при считывании данных у алгоритма уже есть правильный ответ. Поэтому вместо поисков ответа он стремится найти связи, чтобы в дальнейшем, при введении необозначенных данных, получались правильные классификация или прогноз.
В контексте классификации алгоритм обучения может, например, снабжаться историей транзакций по кредитным картам, каждая из которых помечена как безопасная или подозрительная. Он должен изучить отношения между этими двумя классификациями, чтобы затем суметь соответствующим образом маркировать новые операции в зависимости от параметров классификации (например, место покупки, время между операциями и т. д.).
В случае когда данные непрерывно связаны друг с другом, как, например, изменение курса акций во времени, регрессионный алгоритм обучения может использоваться для прогнозирования следующего значения в наборе данных.
Обучение без учителя (unsupervised learning)
В этом случае у алгоритма в процессе обучения нет заранее установленных ответов. Его цель — найти смысловые связи между отдельными данными, выявить шаблоны и закономерности. Например, кластеризация — это использование неконтролируемого обучения в рекомендательных системах (например, люди, которым понравилась эта бутылка вина, также положительно оценили вот эту).
Обучение с подкреплением
Этот тип обучения представляет собой смесь первых двух. Обычно он используется для решения более сложных задач и требует взаимодействия с окружающей средой. Данные предоставляются средой и позволяют алгоритму реагировать и учиться.
Область применения такого метода обширна: от контроля роботизированных рук и поиска наиболее эффективной комбинации движений, до разработки систем навигации роботов, где поведенческий алгоритм «избежать столкновения» обучается опытным путем, получая обратную связь при столкновении с препятствием.
Логические игры также хорошо подходят для обучения с подкреплением, так как они традиционно содержат логическую цепочку решений: например, покер, нарды и го, в которую недавно выиграл AlphaGo от Google. Этот метод обучения также часто применяется в логистике, составлении графиков и тактическом планировании задач.
Классификация
Задача классификации — это задача присвоения меток объектам. Например, если объекты — это фотографии, то метками может быть содержание фотографий: содержит ли изображение пешехода или нет, изображен ли мужчина или женщина, какой породы собака изображена на фотографии. Обычно есть набор взаимоисключающих меток и сборник объектов, для которых эти метки известны. Имея такую коллекцию данных необходимо автоматически расставлять метки на произвольных объектах того же типа, что были в изначальной коллекции. Давайте формализуем это определение.
Допустим, есть множество объектов . Это могут быть точки на плоскости, рукописные цифры, фотографии или музыкальные произведения. Допустим также, что есть конечное множество меток . Эти метки могут быть пронумерованы. Мы будем отождествлять метки и их номера. Таким образом в нашей нотации будет обозначаться как . Если , то задача называется задачей бинарной классификации, если меток больше двух, то обычно говорят, что это просто задача классификации. Дополнительно, у нас есть входная выборка . Это те самые размеченные примеры, на которых мы и будем обучаться проставлять метки автоматически. Так как мы не знаем классов всех объектов точно, мы считаем, что класс объекта — это случайная величина, которую мы для простоты тоже будем обозначать . Например, фотография собаки может классифицироваться как собака с вероятностью 0.99 и как кошка с вероятностью 0.01. Таким образом, чтобы классифицировать объект, нам нужно знать условное распределение этой случайной величины на этом объекте .
Задача нахождения при данном множестве меток и данном наборе размеченных примеров называется задачей классификации.
Примеры задач классификации
Задача классификации — эта любая задача, где нужно определить тип объекта из двух и более существующих классов. Такие задачи могут быть разными: определение, кошка на изображении или собака, или определение качества вина на основе его кислотности и содержания алкоголя.
В зависимости от задачи классификации вы будете использовать разные типы классификаторов. Например, если классификация содержит какую-то бинарную логику, то к ней лучше всего подойдёт логистическая регрессия.
По мере накопления опыта вам будет проще выбирать подходящий тип классификатора. Однако хорошей практикой является реализация нескольких подходящих классификаторов и выбор наиболее оптимального и производительного.
Для чего можно использовать машинное обучение
Описательное применение относится к записи и анализу статистических данных для расширения возможностей бизнес-аналитики. Руководители получают описание и максимально информативный анализ результатов и последствий прошлых действий и решений. Этот процесс в настоящее время обычен для большинства крупных компаний по всему миру — например, анализ продаж и рекламных проектов для определения их результатов и рентабельности.
Второе применение машинного обучения — прогнозирование. Сбор данных и их использование для прогнозирования конкретного результата позволяет повысить скорость реакции и быстрее принимать верные решения. Например, прогнозирование оттока клиентов может помочь его предотвратить. Сегодня этот процесс применяется в большинстве крупных компаний.
Третье и наиболее продвинутое применение машинного обучения внедряется уже существующими компаниями и совершенствуется усилиями недавно созданных. Простого прогнозирования результатов или поведения уже недостаточно для эффективного ведения бизнеса. Понимание причин, мотивов и окружающей ситуации — вот необходимое условие для принятия оптимального решения. Этот метод наиболее эффективен, если человек и машина объединяют усилия. Машинное обучение используется для поиска значимых зависимостей и прогнозирования результатов, а специалисты по данным интерпретируют результат, чтобы понять, почему такая связь существует. В результате становится возможным принимать более точные и верные решения.
Кроме того, я бы добавил еще одно применение машинного обучения, отличное от прогнозного: автоматизация процессов. Прочесть об этом можно .
Вот несколько примеров задач, которые решает машинное обучение.
Логистика и производство
- В Rethink Robotics используют машинное обучение для обучения манипуляторов и увеличения скорости производства;
- В JaybridgeRobotics автоматизируют промышленные транспортные средства промышленного класса для более эффективной работы;
- В Nanotronics автоматизируют оптические микроскопы для улучшения результатов осмотра;
- Netflix и Amazon оптимизируют распределение ресурсов в соответствии с потребностями пользователей;
- Другие примеры: прогнозирование потребностей ERP/ERM; прогнозирование сбоев и улучшение техобслуживания, улучшение контроля качества и увеличение мощности производственной линии.
Продажи и маркетинг
- 6sense прогнозирует, какой лид и в какое время наиболее склонен к покупке;
- Salesforce Einstein помогает предвидеть возможности для продаж и автоматизировать задачи;
- Fusemachines автоматизирует планы продаж с помощью AI;
- AirPR предлагает пути повышения эффективности PR;
- Retention Science предлагает кросс-канальное вовлечение;
- Другие примеры: прогнозирование стоимости жизненного цикла клиента, повышение точности сегментации клиентов, выявление клиентских моделей покупок, и оптимизация опыта пользователя в приложениях.
Финансы
- Cerebellum Capital and Sentient используют машинное обучение для улучшения процесса принятия инвестиционных решений;
- Dataminr может помочь с текущими финансовыми решениями, заранее оповещая о социальных тенденциях и последних новостях;
- Другие примеры: выявление случаев мошенничества и прогнозирование цен на акции.
Здравоохранение
- Atomwise использует прогнозные модели для уменьшения времени производства лекарств;
- Deep6 Analytics определяет подходящих пациентов для клинических испытаний;
- Другие примеры: более точная диагностика заболеваний, улучшение персонализированного ухода и оценка рисков для здоровья.
Больше примеров использования машинного обучения, искусственного интеллекта и других связанных с ними ресурсов вы найдете в списке, созданном Sam DeBrule.
Читать еще: «10 типов структур данных, которые нужно знать»
Шаг третий: оценка — что определяет успех? Достаточно ли хороша модель машинного обучения с точностью 95 %?
Допустим, вы определили задачу своего бизнеса в терминах машинного обучения и у вас есть данные. Теперь нужно выяснить, что определяет успех.
Существуют различные метрики оценки для задач классификации, регрессии и рекомендаций. Какую из них вы выберете, будет зависеть от вашей цели.
Перефразируем.
«Чтобы этот проект был успешным, модель должна быть точной более чем на 95 % в том, что кто-то виноват в аварии или нет.»
Модель с точностью 95 % может показаться довольно хорошей для предсказания виноватого в страховом иске. Но для прогнозирования сердечно-сосудистых заболеваний вы, вероятно, захотите более точных результатов.
Есть и другие вещи, которые нужно принять во внимание при классификации задач
- Ложное отрицательное срабатывание — модель прогнозирует отрицательный вариант, а на самом деле он положительный. В некоторых случаях, таких как прогнозирование спама в электронной почте, ложные срабатывания не так уж и страшны. Но будет гораздо хуже, если система компьютерного зрения для автомобилей с автопилотом не распознает пешехода, когда на самом деле он есть.
- Ложное положительное срабатывание — модель предсказывает положительный вариант, а на самом он отрицательный. Если человеку предскажут болезнь сердца, от которой он на самом деле не страдает, может показаться не таким уж страшным. Лучше перестраховаться, верно? Нет, если это отрицательно влияет на образ жизни человека или устанавливает для него план лечения, в котором он не нуждается.
- Истинное отрицательное срабатывание — модель прогнозирует отрицательный вариант, который на самом деле таковым и является. Это хорошо.
- Истинное положительное срабатывание — модель предсказывает положительный вариант, который на самом деле таковым и является. Это тоже хорошо.
- Точность — какая доля положительных прогнозов была правильной? Модель, которая не даёт ложных срабатываний, имеет точность 1.0.
- Полнота — какая доля фактических положительных вариантов была предсказана правильно? Модель, которая не даёт ложных отрицательных вариантов, имеет отзыв 1.0.
- Оценка F1 — сочетание точности и полноты. Чем ближе к 1.0, тем лучше.
- Кривая рабочих характеристик приёмника (ROC) и площадь под этой кривой (AUC) — кривая ROC представляет собой график, сравнивающий соотношение истинных положительных и ложных положительных вариантов. Метрика AUC — это площадь под кривой ROC. Модель, чьи прогнозы на 100 % неверны, имеет AUC 0.0, а модель, чьи прогнозы являются 100 % правильными, имеет AUC 1.0.
Для задач регрессии (где необходимо предсказать число), допустим, если вы хотите минимизировать разницу между тем, что предсказывает ваша модель, и тем, что является фактическим значением. Если вы пытаетесь предсказать цену, по которой дом будет продаваться, вы захотите, чтобы ваша модель максимально приблизилась к фактической цене. Для этого используйте MAE или RMSE.
Средняя абсолютная ошибка (MAE) — средняя разница между предсказаниями вашей модели и фактическими числами.
Среднеквадратичная ошибка (RMSE) — квадратный корень из среднего квадратов разностей между предсказаниями вашей модели и фактическими числами.
Проблемы с рекомендациями сложнее проверить экспериментально. Один из способов сделать это — взять часть ваших данных и спрятать их. Когда ваша модель построена, используйте её, чтобы предсказать рекомендации для скрытых данных и посмотреть, как они выстраиваются.
Однако традиционные метрики классификации не лучший вариант для задач с рекомендациями. Точность и полнота не имеют понятия порядка.
Если ваша модель машинного обучения вернула список из 10 рекомендаций, которые будут показаны клиенту на вашем веб-сайте, вы бы хотели, чтобы лучшие из них отображались первыми, верно?
— то же, что и обычная точность, однако вы выбираете отсечение k вариантов. Например, точность 5 означает, что вам важны только 5 лучших рекомендаций. У вас может быть 10 000 продуктов, но вы не можете рекомендовать их всем своим клиентам.
Для начала у вас может не быть точной цифры для каждого из них
Но зная, на какие метрики вы должны обращать внимание, вы получите представление о том, как оценить ваш проект машинного обучения