Введение в нейросети
Содержание:
Реализация CNN на PyTorch
Любой достойный фреймворк глубокого обучения может с легкостью справиться с операциями сверточной нейросети. PyTorch является таким фреймворком. В данном разделе будет показано, как создавать CNN с помощью PyTorch шаг за шагом. В идеале вы должны обладать некоторым представлением о PyTorch, но это не обязательно. Мы хотим разработать нейронную сеть для классификации символов в датасете MNIST. Полный код к этому туториалу находится в этом репозитории на GitHub.
Мы собираемся реализовать следующую архитектуру сверточной сети:
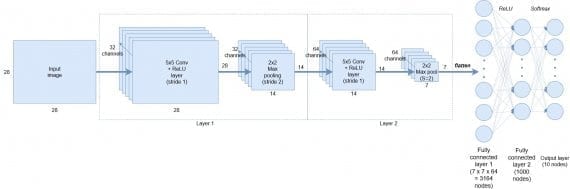
В самом начале на вход подаются черно-белые представления символов размером 28х28 пикселей каждое. Первый слой состоит из 32 каналов сверточных фильтров размера 5х5 + активационная функция ReLU, затем идет 2х2 max pooling с даунсемплингом с шагом 2 (этот слой выводит данные размером 14х14). На следующий слой подается выход с первого слоя размера 14х14, который сканируется снова 5х5 сверточными фильтрами с 64 каналов, затем следует 2х2 max pooling с даунсемплингом для генерирования выхода размером 7х7.
После сверточной части сети следует:
- операция выравнивания, которая создает 7х7х64=3164 узлов
- средний слой из 1000 полносвязных улов
- операция softmax над крайними 10 узлами для генерирования вероятностей классов.
Эти слои представлены в выходном классификаторе.
Примечания
- Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard and L. D. Jackel: Backpropagation Applied to Handwritten Zip Code Recognition, Neural Computation, 1(4):541-551, Winter 1989.
- . DeepLearning 0.1. LISA Lab. Дата обращения 31 августа 2013.
- (2000) «Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit». 405: 947–951.
-
Graham, Benjamin (2014-12-18), Fractional Max-Pooling,
-
Springenberg, Jost Tobias; Dosovitskiy, Alexey; Brox, Thomas & Riedmiller, Martin (2014-12-21), Striving for Simplicity: The All Convolutional Net,
- Jain, V. and Seung, S. H. (2008). Natural image denoising with convolutional networks. In NIPS’2008.
- Lee, H., Grosse, R., Ranganath, R., and Ng, A. Y. (2009a). Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In ICML’2009.
- Zeiler, M., Krishnan, D., Taylor, G., and Fergus, R. (2010). Deconvolutional networks. In CVPR’2010.
Архитектура
Архитектура VGG16 представлена на рисунке ниже.

На вход слоя conv1 подаются RGB изображения размера 224х224. Далее изображения проходят через стек сверточных слоев, в которых используются фильтры с очень маленьким рецептивным полем размера 3х3 (который является наименьшим размером для получения представления о том,где находится право/лево, верх/низ, центр).
В одной из конфигураций используется сверточный фильтр размера 1х1, который может быть представлен как линейная трансформация входных каналов (с последующей нелинейностью). Сверточный шаг фиксируется на значении 1 пиксель. Пространственное дополнение (padding) входа сверточного слоя выбирается таким образом, чтобы пространственное разрешение сохранялось после свертки, то есть дополнение равно 1 для 3х3 сверточных слоев. Пространственный пулинг осуществляется при помощи пяти max-pooling слоев, которые следуют за одним из сверточных слоев (не все сверточные слои имеют последующие max-pooling). Операция max-pooling выполняется на окне размера 2х2 пикселей с шагом 2.
После стека сверточных слоев (который имеет разную глубину в разных архитектурах) идут три полносвязных слоя: первые два имеют по 4096 каналов, третий — 1000 каналов (так как в соревновании ILSVRC требуется классифицировать объекты по 1000 категориям; следовательно, классу соответствует один канал). Последним идет soft-max слой. Конфигурация полносвязных слоев одна и та же во всех нейросетях.
Все скрытые слои снабжены ReLU. Отметим также, что сети (за исключением одной) не содержат слоя нормализации (Local Response Normalisation), так как нормализация не улучшает результата на датасете ILSVRC, а ведет к увеличению потребления памяти и времени исполнения кода.
Локальные особенности
Итак:
- Ядра объединяют пиксели только из небольшой локальной области для формирования выхода. То есть выходные признаки видят только входные признаки из небольшой локальной области;
- Ядро применяется глобально по всему изображению для создания матрицы выходных значений.
Таким образом, с backpropagation (метод обратного распространения ошибки), идущим во всех направлениях от узлов классификации сети, ядра имеют интересную задачу изучения весов для создания признаков только из локального набора входов. Кроме того, поскольку само ядро применяется по всему изображению, признаки, которые изучает ядро, должны быть достаточно общими, чтобы поступать из любой части изображения.
Если это были какие-то другие данные, например, данные об установках приложений по категориям, то это стало бы катастрофой, потому что количество столбцов установки приложений и типов приложений рядом друг с другом не означает, что у них есть «локальные общие признаки», общие с датами установки приложений и временем использования. Конечно, у нескольких могут быть основные признаки более высокого уровня, которые могут быть найдены, но это не дает нам никаких оснований полагать, что параметры для первых двух точно такие же, как параметры для последних двух. Эти несколько могли быть в любом (последовательном) порядке и по-прежнему оставаться подходящими!
Пиксели, однако, всегда отображаются в последовательном порядке, а соседние пиксели влияют на пиксель рядом, например, если все соседние пиксели красные, довольно вероятно, что пиксель рядом также красный. Если есть отклонения, это интересная аномалия, которая может быть преобразована в признак, и все это можно обнаружить при сравнении пикселя со своими соседями, с другими пикселями в своей местности.
Эта идея — то, на чем были основаны более ранние методы извлечения признаков компьютерным зрением. Например, для обнаружения граней можно использовать фильтр обнаружения граней Sobel — ядро с фиксированными параметрами, действующее точно так же, как стандартная одноканальная свертка:
 Применение ядра, детектирующего грани
Применение ядра, детектирующего грани
Для сетки, не содержащей граней (например, неба на заднем фоне), большинство пикселей имеют одинаковое значение, поэтому общий вывод ядра в этой точке равен 0. Для сетки с вертикальными гранями существует разница между пикселями слева и справа от грани, и ядро вычисляет эту ненулевую разницу, находя ребра. Ядро за раз работает только с сетками 3*3, обнаруживая аномалии в определенных местах, но применения ко всему изображению достаточно для обнаружения определенного признака в любом месте изображения!
Но могут ли полезные ядра быть изучены? Для ранних слоев, работающих с необработанными пикселями, мы могли бы ожидать детекторы признаков низкого уровня, таких как ребра, линии и т.д.
Существует целое направление исследований глубокого обучения, ориентированная на то, чтобы сделать модели нейронных сетей интерпретируемыми. Один из самых мощных инструментов для этого — визуализация признаков с помощью оптимизации. Идея в корне проста: оптимизируйте изображение (обычно инициализированное случайным шумом), чтобы активировать фильтр как можно сильнее. Такой способ интуитивно понятен: если оптимизированное изображение полностью заполнено гранями, то это убедительное доказательство того, что фильтр активирован и занят поиском. Используя это, мы можем заглянуть в изученные фильтры, и результаты будут ошеломляющими:
Визуализация признаков для 3 каналов после первого сверточного слоя
Обратите внимание, что, хотя они обнаруживают разные типы ребер, они все еще являются низкоуровневыми детекторами. После 2-й и 3-й свертки
 После 2-й и 3-й свертки
После 2-й и 3-й свертки
Важно обратить внимание на то, что конвертированные изображения остаются изображениями. Выход, получаемый от небольшой сетки пикселей в верхнем левом углу, будет тоже расположен в верхнем левом углу. Таким образом, можно применять один слой поверх другого (как два слева на картинке) для извлечения более грубоких признаков, которые мы визуализируем
Таким образом, можно применять один слой поверх другого (как два слева на картинке) для извлечения более грубоких признаков, которые мы визуализируем.
Тем не менее, как бы глубоки ни заходили наши детекторы признаков, без каких-либо дальнейших изменений они все равно будут работать на очень маленьких участках изображения. Независимо от того, насколько глубоки ваши детекторы, вы не сможете обнаружить лица в сетке 3*3. И вот здесь возникает идея рецептивного поля (receptive field).
Связываем всё воедино
Теперь, когда мы уже неплохо разбираемся в основных структурных элементах свёрточной нейронной сети, уверен, у вас появились более детальные вопросы. Самые важные, которые могли возникнуть, касаются фильтров: “Как решить, какие фильтры использовать?”, “Сколько фильтров использовать?” и т. п.
Давайте отдельно ответим на каждый из этих вопросов.
Как решить, какие фильтры использовать?
Ответ на этот вопрос простой. Мы устанавливаем фильтры со случайными значениями на основе нормального или какого-либо другого распределения. Эта идея может казаться немного неоднозначной и трудной для понимания, однако она хорошо работает. В процессе обучения нейронная сеть постепенно изучает лучшие фильтры, которые помогают извлекать максимум информации, необходимой для точного прогноза метки. Здесь-то и случается магия: мы, строго говоря, избавляемся от необходимости создавать признаки самостоятельно. При достаточном обучении и объёме данных нейросеть сама создаёт подходящие фильтры для извлечения наиболее значимых признаков.
Сколько фильтров использовать в каждом сегменте свёртки?
Здесь нет никаких стандартов. Размер и количество фильтров — настраиваемые гиперпараметры. Универсальное правило — использовать фильтры с нечётными размерами (3×3, 5×5, 7×7). Также крупным фильтрам обычно предпочитают маленькие, но возможны и компромиссные соотношения, которые надо вычислять эмпирически.
Как обучается сеть?
Процесс похож на обучение нейросетей прямого распространения, которые мы обсуждали в предыдущей статье. Мы используем алгоритм обратного распространения ошибки, для того чтобы сеть меняла веса фильтров и изучала основные признаки изображения. Обучение позволяет нейросети находить оптимальные фильтры для извлечения максимального объёма информации из изображений на входе.
Изображение выше было обычным 2D, в то время как большинство изображений представляют собой 3D. Как нейросеть работает с 3D?
2D-изображения демонстрировались для простоты. Большинство используемых изображений — 3D с цветовыми каналами (RGB). В этом случае ничего не меняется, кроме измерений ядра. Ядра будут трёхмерными, где третье измерение равно количеству каналов: например, 5x5x3 для 3 цветовых каналов (R, G и B) в изображении на входе.
Какая разница между свёрточными нейронными сетями и глубокими свёрточными нейронными сетями?
Это одно и то же. Слово “глубокий” здесь относится к количеству слоёв в архитектуре. Большинство современных СНС содержит от 30 до 100 слоёв.
Нужны ли для обучения СНС графические процессоры (GPU)?
Не обязательны, но желательны. Эффективное использование GPU позволяет увеличить скорость обработки изображений при обучении нейросетей примерно в 50 раз. Платформы Kaggle и Google Colab предоставляют бесплатные (с ограниченной частотой использования в неделю) окружения с поддержкой GPU.
CenterNet
CenterNet моделирует объект, как одну точку, которая находится в центре ограничительной рамки. Размер объекта, его ориентация, 3D-форма, направление, поза и т.д. извлекаются в последствии через характеристики изображения (image features) около полученной точки. Авторы подают входное изображение в полносвязную сверточную сеть, которая генерирует тепловую карту (heatmap). Пики на этой тепловой карте соответствуют центрам объектов. Характеристики изображения в каждом пике тепловой карты предсказывают размеры ограничительной рамки вокруг объекта. С помощью CenterNet авторы статьи экспериментируют с определением 3D размеров объектов и оценкой позы человека по двумерному изображению.
Рисунок – Диаграмма CenterNet
CornerNet является предшественником CenterNet. CornerNet обнаруживает объект, как пару точек: верхний левый и правый нижний углы ограничительной рамки (bounding box). Таким образом распознавание по набору фиксированных рамкок (anchor box), как у нейросетей SSD и YOLO, заменяется на определение пары точек верхнего левого и правого нижнего углов ограничительной рамки вокруг объекта. Также авторы предлагают архитектуру на основе последовательности нескольких нейросетей типа «песочные часы», которые до этого не использовались для определения объектов.
В CornerNet применяется механизм «corner pooling» для определения углов ограничительной рамки вокруг объектов. В CenterNet добавляется механизм «center pooling» для определения центра рамки.
Рисунок – Механизм «corner pooling» для верхнего левого угла. Сканирование проходит справа налево для горизонтального «max-pooling» и снизу вверх для вертикального «max-pooling». Затем две карты характеристик (feature maps) слаживаются.
Архитектура U-Net
 Рисунок 1. Архитектура U-net (пример изображения с разрешением 32×32 пикселя — самым низким). Каждый синий квадрат соответствует многоканальной карте свойств. Количество каналов приведено в верхней части квадрата. Размер x-y приведен в нижнем левом краю квадрата. Белые квадраты представляют собой копии карты свойств. Стрелки обозначают различные операции.
Рисунок 1. Архитектура U-net (пример изображения с разрешением 32×32 пикселя — самым низким). Каждый синий квадрат соответствует многоканальной карте свойств. Количество каналов приведено в верхней части квадрата. Размер x-y приведен в нижнем левом краю квадрата. Белые квадраты представляют собой копии карты свойств. Стрелки обозначают различные операции.
Архитектура сети приведена на рисунке 1. Она состоит из сужающегося пути (слева) и расширяющегося пути (справа). Сужающийся путь — типичная архитектуре сверточной нейронной сети. Он состоит из повторного применения двух сверток 3×3, за которыми следуют инит ReLU и операция максимального объединения (2×2 степени 2) для понижения разрешения.
На каждом этапе понижающей дискретизации каналы свойств удваиваются. Каждый шаг в расширяющемся пути состоит из операции повышающей дискретизации карты свойств, за которой следуют:
- свертка 2×2, которая уменьшает количество каналов свойств;
- объединение с соответствующим образом обрезанной картой свойств из стягивающегося пути;
- две 3×3 свертки, за которыми следует ReLU.
Обрезка необходима из-за потери граничных пикселей при каждой свертке.
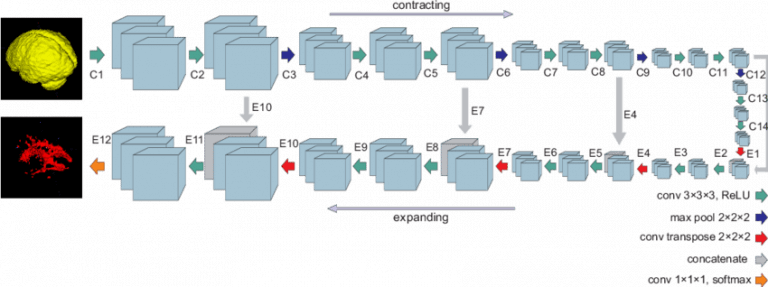 Схема сети U-net
Схема сети U-net
На последнем слое используется свертка 1×1 для сопоставления каждого 64-компонентного вектора свойств с желаемым количеством классов. Всего сеть содержит 23 сверточных слоя.
Объединение (Pooling)
Основными преимуществами для пулинга в сверточной нейронной сети являются:
- Уменьшение количества параметров в вашей модели благодаря процессу даунсемплинга (down-sampling).
- Детектирование признаков становится более правильным при изменении ориентации или размера объекта.
Пулинг — другой тип техники скользящего окна, где вместо применения обучаемых весов используется статистическая функция некоторого типа по содержимому этого окна. Наиболее частый тип пулинга — max pooling, который применяет функцию max(). Есть и другие варианты — mean pooling (который применяет функцию усреднения по содержимому окна), которые применяются в особых случаях. В этом туториале мы будем концентрироваться на max pooling. На рисунке ниже показано, как работает операция max pooling:
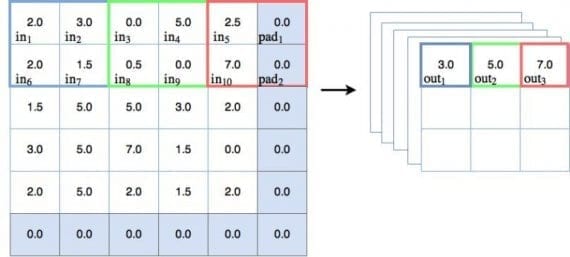
Давайте пройдемся по некоторым пунктам, связанным с диаграммой:
Основы
На диаграмме можно наблюдать действие max pooling. Для первого окна голубого цвета max pooling выдает значение 3.0, которое является максимальным значением узла в 2х2 окне. Таким же образом зеленое окно выводит максимальное значение, равно 5.0, а для красного окна максимальное значение — 7.0. Здесь всё просто и понятно.
Шаги и даунсемплинг
На диаграмме сверху можно заметить, что пулинговое окно каждый раз перемещается на 2 места. Можем говорить, что шаг равен 2. На диаграмме показаны шаги только вдоль оси x, но для задачи предотвращения перекрытия окна, шаг должен быть также равен 2 и в направлении y. Другими словами, шаг обозначается как . Следует упомянуть, если во время пулинга шаг больше 1, тогда размер выхода будет уменьшен. Как можно видеть на диаграмме, входной объект размера 5×5 уменьшается до 3х3 на выходе. И это хорошо — такое явление называется даунсемплингом и уменьшает количество обучаемых параметров в модели.
Padding
Важно отметить также, что в пулинговой диаграмме есть дополнительный столбец и строка, добавленные к входу размера 5х5, делающие эффективный размер пулингового пространства равным 6х6. Это делается для того, чтобы пулинговое окно размером 2х2 корректно работало с шагом
Такой прием называется padding. Padding-узлы зачастую фиктивные, так как значения на них равны 0, и операция max pooling их не видит. Этот факт нужно будет учитывать при создании нашей сверточной сети на PyTorch.
Теперь мы разобрались в механизме работы пулинга в CNN, выяснили его полезность в осуществлении даунсемплинга. Рассмотрим еще его некоторые функции и ответим на вопрос, почему max pooling используется так часто.
Использование пулинга в сверточных нейронных сетях
В дополнении к функции даунсемплинга пулинг используется в CNN, чтобы детектировать определенные признаки, инвариантные к изменениям размера или ориентации. Другой способ представить действие пулинга — он обобщает низкоуровневую, сложно структурированную информацию. Представим случай, когда у нас есть сверточный фильтр, который во время тренировки обучается распознавать знак «9» в различных положениях на входном изображении. Чтобы сверточная сеть научилась корректно классифицировать появление «9» на картинке, требуется каким-то образом активировать сеть каждый раз, когда эта цифра появляется на изображении независимо от размера и ориентации (кроме случая, когда «9» напоминает «9»). Пулинг может помочь в такой задаче выбора высокоуровневых, обобщенных признаков. Этот процесс иллюстрирован ниже:
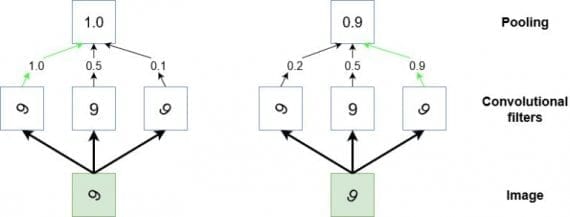
Диаграмма — стилизованное представление операции пулинга. Если мы считаем, что маленький участок входного изображения содержит цифру 9 (зеленый квадрат), и предполагаем, что пытаемся детектировать эту цифру на изображении. В таком случае несколько сверточных фильтров обучаются активироваться с помощью ReLU функции каждый раз, когда они видят «9» на картинке. Однако, они будут активироваться более или менее сильно в зависимости от того, как она расположена. Мы хотим научить сеть обнаруживать цифру на изображении независимо от ее ориентации. Здесь наступает черед пулинга. Он«смотрит» на выходы трех фильтров и берет настолько высокое значение, насколько высокий порог функций активации этих фильтров.
Следовательно, пулинг выступает в качестве механизма обобщения низкоуровневых данных и позволяет нейросети переходить от данных с высоким разрешением до информации с более низким разрешением. Другими словами, пулинг в паре со сверточными фильтрами делают возможным детектирование объекта на изображении.
Параметры в сверточной нейронной сети
Свертка — это по-прежнему линейное преобразование
Даже с уже описанной механикой работы сверточного слоя, все еще сложно связать это с нейронной сетью прямого распространения (feed-forward network), и это все еще не объясняет, почему свертки масштабируются и работают намного лучше с изображениями.
Предположим, что у нас есть вход 4*4, и мы хотим преобразовать его в сетку 2*2. Если бы мы использовали feed-forward network, мы бы переделали вход 4*4 в вектор длиной 16 и передали его через полносвязный слой с 16 входами и 4 выходами. Можно было бы визуализировать весовую матрицу W для слоя по типу:

И хотя сверточные операции с ядрами могут вначале показаться немного странными, это по-прежнему линейные преобразования с эквивалентной матрицей перехода.
Если мы использовали ядро K размера 3 на видоизмененным входом размера 4*4, чтобы получить выход 2*2, эквивалентная матрица перехода будет выглядеть так:
 Примечание: в то время как приведенная матрица является эквивалентной матрицей перехода, фактическая операция обычно реализуется как совсем иное матричное умножение
Примечание: в то время как приведенная матрица является эквивалентной матрицей перехода, фактическая операция обычно реализуется как совсем иное матричное умножение
Свертка, в целом, все еще является линейным преобразованием, но в то же время она также представляет собой совершенно иной вид преобразования. Для матрицы с 64 элементами существует всего 9 параметров, которые повторно используются несколько раз. Каждый выходной узел получает только определенное количество входов (те, что находятся внутри ядра). Нет никакого взаимодействия с другими входами, так как вес для них равен 0.
Полезно представлять сверточные операции как hard prior для весовых матриц. В данном контексте, под prior я подразумеваю предопределенные параметры сети. Например, когда вы используете предварительно обработанную модель для классификации изображений, вы используете предварительные параметры сети как prior как экстрактор образов для вашего окончательного полносвязного слоя.
Transfer learning эффективнее на порядок по сравнению со случайной инициализацией, потому что вам только нужно оптимизировать параметры конечного полностью связанного слоя, а это означает, что вы можете иметь фантастическую производительность всего лишь с несколькими десятками изображений в классе.
Вам не нужно оптимизировать все 64 параметра, потому большинство из них установлено на ноль (и они останутся такими), а остальные мы преобразуем в общие параметры и в результате получим только 9 параметров для оптимизации. Эта эффективность имеет значение, потому что, когда вы переходите от 784 входов MNIST к реальным изображениям 224*224*3, это более 150 000 входов. Слой, пытающийся вдвое уменьшить вход до 75 000 входных значений, по-прежнему потребует более 10 миллиардов параметров. Для сравнения, ResNet-50 имеет около 25 миллионов параметров.
Таким образом, фиксирование некоторых параметров равными нулю и их связывание повышает эффективность, но в отличие от случая с transfer learning, где мы знаем, что prior работает грамотно, потому что он хорошо работает с большим общим набором изображений, откуда мы знаем, что это будет работать хоть сколько-то хорошо в нашем случае?
Ответ заключается в комбинациях образов, изучаемых параметрами за счет prior.