Googlebot
Содержание:
- Can Googlebot access all my content and links completely?
- Full robots.txt syntax
- Как определить плохого бота?
- Советы по использованию операторов
- Test your robots.txt file
- Основные рекомендации в отношении файлов robots.txt
- Для чего нужен файл robots.txt?
- Я использую сервис управления хостингом сайта
- Ограничения при использовании файла robots.txt
- General robots questions
- Настройка файла robots.txt: основные директивы
- Sitemaps and Googlebot
- Can Googlebot access all of my page resources?
- В чем состоит ваша задача?
- Начало работы
- О файле robots.txt
- Basic robots.txt guidelines
- Серпхант
- Выводы Incapusla
Can Googlebot access all my content and links completely?
The next step is to ensure Google is seeing your content and links correctly.
Just because Googlebot can see your pages does not mean that Google has a perfect picture of exactly what those pages are.
Google bot does not see a website the same way as humans do. In the above image there is a webpage with one image on it. Humans can see the image, but what Googlebot sees is only the code calling that image.
Googlebot may be able to access that webpage (the html file), but not be able to access the image found on that webpage for various reasons.
In that scenario the Google index will not include that image, meaning that Google has an incomplete understanding of your webpage.
Full robots.txt syntax
You can find the full robots.txt syntax here. Please read the full documentation, as the robots.txt syntax has a few tricky parts that are important to learn.
Useful robots.txt rules
Here are some common useful robots.txt rules:
| Rule | Sample |
|---|---|
| Disallow crawling of the entire website. Keep in mind that in some situations URLs from the website may still be indexed, even if they haven’t been crawled. Note: this does not match the various AdsBot crawlers, which must be named explicitly. |
User-agent: * Disallow: / |
| Disallow crawling of a directory and its contents by following the directory name with a forward slash. Remember that you shouldn’t use robots.txt to block access to private content: use proper authentication instead. URLs disallowed by the robots.txt file might still be indexed without being crawled, and the robots.txt file can be viewed by anyone, potentially disclosing the location of your private content. |
User-agent: * Disallow: /calendar/ Disallow: /junk/ |
| Allow access to a single crawler |
User-agent: Googlebot-news Allow: / User-agent: * Disallow: / |
| Allow access to all but a single crawler |
User-agent: Unnecessarybot Disallow: / User-agent: * Allow: / |
|
Disallow crawling of a single webpage by listing the page after the slash: |
User-agent: * Disallow: /private_file.html |
|
Block a specific image from Google Images: |
User-agent: Googlebot-Image Disallow: /images/dogs.jpg |
|
Block all images on your site from Google Images: |
User-agent: Googlebot-Image Disallow: / |
|
Disallow crawling of files of a specific file type (for example, ): |
User-agent: Googlebot Disallow: /*.gif$ |
|
Disallow crawling of entire site, but show AdSense ads on those pages, disallow all web crawlers other than Mediapartners-Google. This implementation hides your pages from search results, but the Mediapartners-Google web crawler can still analyze them to decide what ads to show visitors to your site. |
User-agent: * Disallow: / User-agent: Mediapartners-Google Allow: / |
| Match URLs that end with a specific string, use . For instance, the sample code blocks any URLs that end with : |
User-agent: Googlebot Disallow: /*.xls$ |
Как определить плохого бота?
Иногда выявить плохих ботов может быть достаточно проблематично: некоторые из них очень сложно устроены, особенно, те, которые имитируют Google. Вот некоторые шаги, которые помогут определить фейковых ботов.
Incapusla исходя из собственного опыта сформулировала 4 шага для выявления фейковых ботов:
Шаг 1. Посмотрите на данные в заголовке
Даже если боты использовали юзер-агент Google, остальные данные заголовка будут совсем «не как у Google». Этого достаточно, чтобы забить тревогу, но не торопитесь блокировать его, потому что зарегистрированы случаи, когда Google отклоняется от обычной структуры заголовка.
Шаг 2. Проверка IP и ASN
Далее проведите проверку IP и ASN
Здесь стоит обратить внимание на несколько моментов, в том числе на личности владельцев IP-адресов и ASN, которые производят подозрительный трафик
В случае с фейковыми гуглботами ни IP, ни ASN не будут связаны с Google. Таким образом, с помощью параллельной проверки этой информации и сомнительных заголовков можно с высокой степенью уверенности сказать, что мы имеем дело с потенциально опасными двойниками.
Шаг 3. Контроль действий
Тем не менее «потенциально опасный» это не всегда «злой». Например, некоторые SEO-инструменты пытаются выдать себя за гуглботов, чтобы получить «гуглоподобное» видение контента сайта и ссылочного профиля.
Именно поэтому следующий пункт поиска — поведение посетителей. Оно поможет нам понять их намерения, ключ к которым часто лежит в самом запросе, так как они представлены в WAF (Web Application Firewall). В этом случае самого показателя посещений достаточно, чтобы завершить картину, сразу определив DDoS-атаки и повысив автоматизированную защиту от них.
Шаг 4. Репутация IP и новая низкоуровневая подпись
Хотя Incapusla регулярно сталкивается с гуглботами, вариант подписи, появившийся во время последней атаки, отраженной системой, не был частью существующей базы данных. После смягчения атаки собранные данные использовались, чтобы создать новую запись низкого уровня, которая затем будет добавлена к десятимиллионному пулу записей и разведена через сеть, чтобы защитить всех клиентов Incapusla.
В результате при следующем посещении этими ботами сайта они будут немедленно заблокированы. Более этого, репутация атакующих IP также будет записана и добавлена в другую базу данных, где хранятся потенциально опасные адреса.
Проще говоря, вы должны знать, что юзер-агенты могут быть фейками, IP-адреса могут быть подделаны, а заголовки реконструированы и т.д. И для обеспечения безопасности, нужно раскрыть «истинное лицо» и намерения посетителей.
Советы по использованию операторов
Как упоминалось выше, широко применяются два оператора: и . С их помощью можно:
1. Заблокировать определённые типы файлов.
User-agent: *
# Блокируем любые файлы с расширением .json
Disallow /*.json$
В примере выше астериск указывает на любые символы в названии файла, а оператор гарантирует, что расширение находится точно в конце адреса, и правило не затрагивает страницы вроде /locations.json.html (вдруг есть и такие).
2. Заблокировать URL с параметром , после которого следуют GET-запросы (метод передачи данных от клиента серверу).
Этот приём активно используется, если у проекта настроено ЧПУ для всех страниц и документы с GET-параметрами точно являются дублями.
User-agent: *
# Блокируем любые URL, содержащие символ ?
Disallow /*?
Заблокировать результаты поиска, но не саму страницу поиска.
User-agent: *
# Блокируем страницу результатов поиска
Disallowsearch.php?query=*
Имеет ли значение регистр?
Определённо да. При указании правил Disallow / Allow, URL адреса могут быть относительными, но обязаны сохранять регистр.
User-agent: *
# /users разрешены для сканирования, поскольку регистр разный
DisallowUsers
Но сами директивы могут объявляться как с заглавной, так и с прописной: или — без разницы. Исключение — всегда указывается с заглавной.
Test your robots.txt file
- Open the tester tool for your site, and scroll through the code to locate the highlighted syntax warnings and logic errors. The number of syntax warnings and logic errors is shown immediately below the editor.
- Type in the URL of a page on your site in the text box at the bottom of the page.
- Select the user-agent you want to simulate in the dropdown list to the right of the text box.
- Click the TEST button to test access.
- Check to see if TEST button now reads ACCEPTED or BLOCKED to find out if the URL you entered is blocked from Google web crawlers.
- Edit the file on the page and retest as necessary. Note that changes made in the page are not saved to your site! See the next step.
- Copy your changes to your robots.txt file on your site. This tool does not make changes to the actual file on your site, it only tests against the copy hosted in the tool.
Limitations of the robots.txt Tester tool:
- Changes you make in the tool editor are not automatically saved to your web server. You need to copy and paste the content from the editor into the file stored on your server.
- The robots.txt Tester tool only tests your with Google user-agents or web crawlers, like Googlebot. We cannot predict how other web crawlers interpret your file.
Основные рекомендации в отношении файлов robots.txt
Ниже представлено несколько советов по работе с файлами robots.txt. Мы рекомендуем вам изучить полный синтаксис этих файлов, так как используемые при их создании синтаксические правила являются неочевидными и вы должны разбираться в них.
Формат и расположение
Создать файл robots.txt можно почти в любом текстовом редакторе с поддержкой кодировки UTF-8. Не используйте текстовые процессоры, поскольку зачастую они сохраняют файлы в проприетарном формате и добавляют в них недопустимые символы, например фигурные кавычки, которые не распознаются поисковыми роботами.
При создании и тестировании файлов robots.txt используйте инструмент проверки. Он позволяет проанализировать синтаксис файла и узнать, как он будет функционировать на вашем сайте.
Правила в отношении формата и расположения файла
- Файл должен носить название robots.txt.
- На сайте должен быть только один такой файл.
- Файл robots.txt нужно разместить в корневом каталоге сайта. Например, чтобы контролировать сканирование всех страниц сайта , файл robots.txt следует разместить по адресу . Он не должен находиться в подкаталоге (например, по адресу ). В случае затруднений с доступом к корневому каталогу обратитесь к хостинг-провайдеру. Если у вас нет доступа к корневому каталогу сайта, используйте альтернативный метод блокировки, например метатеги.
- Файл robots.txt можно добавлять по адресам с субдоменами (например, ) или нестандартными портами (например, ).
- Комментарием считается любой текст после символа #.
Синтаксис
- Файл robots.txt должен представлять собой текстовый файл в кодировке UTF-8 (которая включает коды символов ASCII). Другие наборы символов использовать нельзя.
- Файл robots.txt состоит из групп.
- Каждая группа может содержать несколько правил, по одному на строку. Эти правила также называются директивами.
- Группа включает следующую информацию:
- К какому агенту пользователя применяются директивы группы.
- К каким каталогам или файлам у этого агента есть доступ.
- К каким каталогам или файлам у этого агента нет доступа.
- Инструкции групп считываются сверху вниз. Робот будет следовать правилам только одной группы с наиболее точно соответствующим ему агентом пользователя.
- По умолчанию предполагается, что если доступ к странице или каталогу не заблокирован правилом , то агент пользователя может их обрабатывать.
- Правила чувствительны к регистру. Так, правило применимо к URL , но не к .
Директивы, которые используются в файлах robots.txt
Другие правила игнорируются.
Ещё один пример
Файл robots.txt состоит из групп. Каждая из них начинается со строки , определяющей робота, который должен следовать правилам. Ниже приведен пример файла с двумя группами и с поясняющими комментариями к обеим.
# Блокировать доступ робота Googlebot к каталогам example.com/directory1/... и example.com/directory2/... # но разрешить доступ к каталогу directory2/subdirectory1/... # Доступ ко всем остальным каталогам разрешен по умолчанию. User-agent: googlebot Disallow: /directory1/ Disallow: /directory2/ Allow: /directory2/subdirectory1/ # Блокировать доступ ко всему сайту другой поисковой системе. User-agent: anothercrawler Disallow: /
Для чего нужен файл robots.txt?
Файл robots.txt используется в первую очередь для управления трафиком поисковых роботов на вашем сайте. Как правило, он позволяет избежать показа контента в результатах поиска Google (это зависит от типа файла). Более подробные сведения представлены ниже.
Тип контента
Управление трафиком
Блокировка в результатах поиска Google
Описание
Веб-страница
Файл robots.txt может использоваться для управления сканированием веб-страниц в форматах, которые не относятся к медийным и которые робот Googlebot может обработать (например, HTML или PDF). Эта функция позволяет сократить количество запросов, которые поступают на ваш веб-сервер от Google, или предотвратить сканирование неинформативных или одинаковых страниц на вашем сайте.
Файл robots.txt не предназначен для блокировки показа веб-страниц в результатах поиска Google. Если на других сайтах есть ссылки на вашу страницу, содержащие ее описание, то она все равно может быть проиндексирована, даже если роботу Googlebot запрещено ее посещать. Чтобы исключить страницу из результатов поиска, следует использовать другой метод, например защиту паролем или директиву noindex.
Медиафайл
Файл robots.txt может использоваться как для управления трафиком поисковых роботов, так и для блокировки показа изображений, видео- и аудиофайлов в результатах Google Поиска
При этом обратите внимание, что другие страницы могут по-прежнему ссылаться на ваш контент.
Подробнее о том, как исключить изображения из Google Поиска…
Файл ресурсов
При помощи файла robots.txt можно запрещать сканирование файлов ресурсов, например неинформативных изображений, скриптов или файлов стилей, если вы считаете, что эти ресурсы не оказывают существенное влияние на содержание страницы. Однако не следует блокировать доступ к ним, если это может затруднить поисковому роботу интерпретацию контента
В противном случае анализ страницы в Google будет неэффективным.
Я использую сервис управления хостингом сайта
Если вы используете сервис управления хостингом сайта, например WIX, Drupal или Blogger, вам обычно не нужно редактировать файл robots.txt напрямую (а в некоторых случаях вы не сможете это сделать). Вместо этого ваш провайдер может использовать страницу настроек поиска или какой-либо другой механизм, который запрещает или разрешает сканирование.
Чтобы узнать, доступна ли ваша страница в Google, попробуйте ввести ее URL в строке поиска Google.
Если вы хотите запретить или разрешить поисковым системам обработку вашей страницы, реализуйте на ней вход с использованием учетных данных или откажитесь от использования этой функции. Затем попробуйте найти в сервисе управления хостингом сайта информацию о том, как контролировать видимость представленного на сайте контента в поисковых системах. Пример запроса: wix как скрыть страницу от поисковых систем.
Ограничения при использовании файла robots.txt
Прежде чем создавать или изменять файл , примите во внимание риски, связанные с этим методом. Иногда для запрета индексирования определенных URL лучше применять другие решения
-
Директивы robots.txt поддерживаются не всеми поисковыми системами
Директивы в файлах не имеют обязывающей силы. Googlebot и большинство других поисковых роботов следуют инструкциям , однако некоторые системы могут игнорировать их. Чтобы надежно защитить информацию от поисковых роботов, воспользуйтесь другими способами – например, парольной защитой файлов на сервере. -
Каждый поисковый робот использует собственный алгоритм обработки файла robots.txt
Большинство поисковых систем следуют директивам в , однако конкретная интерпретация директив будет зависеть от настроек робота. Поэтому ознакомьтесь с синтаксисом для других систем. -
Страница, заблокированная для поисковых роботов, все же может быть обработана, если на других сайтах есть ссылки на нее
Googlebot не будет напрямую индексировать контент, указанный в файле , однако сможет найти страницы с ним по ссылкам с других сайтов. Таким образом, URL, а также другие общедоступные сведения, например текст ссылок на страницу, могут появиться в результатах поиска Google. Чтобы предотвратить появление URL в результатах поиска Google, необходимо защитить файлы на сервере паролем или использовать директиву noindex в метатеге или HTTP-заголовке ответа (либо полностью удалить страницу).
Обратите внимание: одновременное применение нескольких методов может привести к конфликтам. Подробнее о настройке этих параметров можно узнать в на сайте Google Developers.
General robots questions
Does my website need a robots.txt file?
No. When Googlebot visits a website, we first ask for permission to crawl by attempting to retrieve the robots.txt file. A website without a robots.txt file, robots meta tags or X-Robots-Tag HTTP headers will generally be crawled and indexed normally.
Which method should I use?
It depends. In short, there are good reasons to use each of these methods:
- robots.txt: Use it if crawling of your content is causing issues on your server. For example, you may want to disallow crawling of infinite calendar scripts. You should not use the robots.txt to block private content (use server-side authentication instead), or handle canonicalization (see our Help Center). If you must be certain that a URL is not indexed, use the robots meta tag or X-Robots-Tag HTTP header instead.
- robots meta tag: Use it if you need to control how an individual HTML page is shown in search results (or to make sure that it’s not shown).
- X-Robots-Tag HTTP header: Use it if you need to control how non-HTML content is shown in search results (or to make sure that it’s not shown).
Can I use these methods to remove someone else’s site?
No. These methods are only valid for sites where you can modify the code or add files. If you want to remove content from a third-party site, you need to contact the webmaster to have them remove the content.
Настройка файла robots.txt: основные директивы
Чтобы правильно настроить файл robots.txt, необходимо знать директивы – команды, которые воспринимают роботы поисковых систем. Ниже рассмотрим основные директивы для настройки индексации сайта в файле robots.txt:
| Директива | Назначение |
| User-agent: | Указывает робота поисковой системы, для которого предназначены команды ниже. Названия роботов можно посмотреть в справочной информации, которую предоставляют поисковые системы. |
Директива User-agent: * обозначает, что команды ниже предназначены для всех роботов, для которых нет персональных команд в файле.
Важно соблюдать последовательность команд в файле. В начале прописываются команды для конкретных роботов (Yandex, Googlebot и т.д.), потом – для всех остальных.. Существуют другие директивы, которые используется реже
Посмотреть информацию обо всех директивах, которые можно настроить в файле robots.txt, можно здесь
Disallow:
Данная директива в файле robots.txt закрывает индексацию определенной страницы или раздела на сайте. Сама страница или раздел указываются от корневой папки сайта, без домена (см. скриншот в начале статьи).
Allow:
Разрешает индексацию определенной страницы или раздела на сайте. Директивы Allow необходимо располагать ниже директив Disallow.
Host:
Указывает главное зеркало сайта (либо с www, либо без www). Учитывается только Яндексом.
Sitemap:
В данной директиве необходимо прописать путь к карте сайта, если она имеется на сайте.
Существуют другие директивы, которые используется реже. Посмотреть информацию обо всех директивах, которые можно настроить в файле robots.txt, можно здесь.
Частные случаи команд в файле robots.txt
Разберем некоторые команды, которые потребуются Вам в работе:
| Команда | Что обозначает |
| User-agent: Yandex | Начало блока команд для основного робота поисковой системы Яндекс. |
| User-agent: Googlebot | Начало блока команд для основного робота поисковой системы Google. |
| User-agent: *Disallow: / | Данная команда в файле robots.txt полностью закрывает сайт от индексации всеми поисковыми системами. |
| User-agent: *Disallow: /Allow: /test.html | Данные команды закрывают все документы на сайте от индексации, кроме страницы /test.html |
| Disallow: /*.doc | Данная команда запрещает индексировать файлы MS Word на сайте. Если на сайте содержится конфиденциальная информация в файлах определенного типа, имеет смысл закрыть такие файлы от индексации. |
| Disallow: /*.pdf | Данная команда в robots.txt запрещает индексировать на сайте файлы в формате PDF. Если Вы выкладываете на сайте какие-либо файлы, доступные для скачивания после оплаты или после авторизации, имеет смысл закрыть их от индексации. В ином случае данные файлы смогут найти в поисковых системах. |
| Disallow: /basket/ | Команда запрещает индексировать все документы в разделе /basket/. |
| Host: www.yandex.ru | Команда задает для сайта yandex.ru основным зеркалом адрес сайта с www. Соответственно, в поиске с высокой вероятностью будут выводиться адреса страниц с www. |
| Host: yandex.ru | Данная команда задает для сайта yandex.ru в качестве основного зеркала адрес yandex.ru (без www). |
Sitemaps and Googlebot
Sitemaps are a way that you can help Googlebot understand your website, or as Google says…
«A sitemap is a file where you can list the web pages of your site to tell Google and other search engines about the organization of your site content. Search engine web crawlers like Googlebot read this file to more intelligently crawl your site.»
Google states that sitemaps are best used in certain scenarios, specifically…
- Your site is really large.
- Your site has a large archive of content pages that are isolated or well not linked to each other.
- Your site is new and has few external links to it.
- Your site uses rich media content, is shown in Google News, or uses other sitemaps-compatible annotations.
Sitemaps are being used for many things now, but as far as Googlebot goes, sitemaps basically create a list of urls and other data that Googlebot may use as guidance when visiting your webpages.
Google explains how to build sitemaps here.
Can Googlebot access all of my page resources?
If CSS and javascript files are blocked by your robots.txt file then it can cause some severe misunderstandings about your webpage content (much worse than just a missing image).
It is increasingly true that a webpage may actually be different, or have different content if the page resources are not loaded.
An example to illustrate this would be a mobile page that uses CSS or javascript to determine what to show depending on what device is looking at the page. If Googlebot can not access the CSS or Javascript of that page, it may not realize the page can be mobile.
In this scenario and others like it, Google will «see» your page, and may even understand it, but it may not know it enough to realize that it can be ranked in many other scenarios than what the HTML alone is presenting.
This can also be checked for using the Google guidelines tool.
В чем состоит ваша задача?
У меня не очень много времени на управление сайтом
Если ваш сайт размещен на автоматизированной платформе веб-хостинга, такой как Blogger, Wix или Squarespace, или масштабы вашей деятельности невелики и у вас нет времени на управление сайтом, то сервис Search Console не принесет вам существенной пользы.
Тем не менее мы рекомендуем вам ознакомиться с приведенными здесь рекомендациями, позволяющими влиять на то, как ваш сайт будет представлен в результатах поиска, и привлекать на него больше пользователей. На прочтение этих материалов у вас уйдет всего 20 мин.
- Как работает Google Поиск. По этой ссылке приведено краткое описание принципов работы поисковой системы Google.
- Как добавить свой контент в результаты поиска Google. Узнайте больше о том, как разместить сведения о вас и вашей компании в продуктах Google, таких как Карты, Поиск и YouTube.
- Как оптимизировать свой сайт для поисковых систем. Ознакомьтесь с руководством из шести пунктов, следуя которому, вы улучшите позиции своего сайта в результатах поиска и сделаете его более интересным для пользователей.
- Как получать статистику по эффективности ваших ресурсов в Google Поиске. Представлен ли ваш сайт в Google? Скольким пользователям удается его найти? Какой у него рейтинг в результатах поиска? Что искали посетители, которые увидели ссылку на ваш сайт? Узнайте, как получить ответы на эти вопросы.
- Не знаете, как улучшить свой сайт? Наймите профессионального консультанта по поисковой оптимизации.
- Изучив эти документы, вы можете также посмотреть серию обучающих видео для начинающих.
Я начинающий пользователь, и мне нужна дополнительная информация
Если вы хотите улучшить позиции своего сайта в Google Поиске и готовы потратить немного времени на изучение поисковой оптимизации и сервиса Search Console, ознакомьтесь с этим руководством по началу работы.
Навыки программирования или работы с HTML не обязательны, но вам предстоит узнать больше о том, как устроен ваш сайт. Будьте готовы внести в него изменения. Вам понадобится совсем немного усилий, чтобы улучшить его позиции в Google Поиске.
Я продвинутый пользователь, и у меня есть основные навыки поисковой оптимизации
Вы готовы досконально разобраться в принципах работы Google Поиска и наших отчетах, а также переработать свой сайт, чтоб вывести его эффективность в Поиске на новый уровень? Пройдите учебную программу ниже. Она подразумевает, что у вас уже есть базовые знания о поисковой оптимизации.
Начать
Я веб-разработчик
Если вы создаете сайт или управляете им, реализуете структурированные данные или выполняете большую часть своей работы в редакторе кода, Search Console пригодится вам для мониторинга, тестирования и отладки. Вот что мы рекомендуем:
Узнайте, как работает Google Поиск
Для решения проблем, связанных с представлением сайта в Google, важно понимать принципы сканирования, индексации и подбора результатов.
Отслеживайте ошибки и колебания показателей с помощью отчетов об индексировании, эффективности и удобстве просмотра на мобильных устройствах. Изучайте отчеты о статусе AMP-страниц и расширенных результатов, если они есть на вашем сайте.
Чтобы оценить эффективность определенной страницы, разверните в нужном отчете подробные сведения о ней и нажмите Проверить или воспользуйтесь инструментом проверки URL
В интерфейсе этого инструмента можно получить данные обо всех типах ошибок, в том числе связанных с индексированием, AMP, удобством просмотра на мобильных устройствах, HTML и скриптами.
Ознакомьтесь с документацией по Google Поиску для разработчиков. В ней вы найдете информацию о структурированных данных, представлении AMP-страниц в результатах поиска, оптимизации контента для мобильных устройств, доступе к инструментам и отчетам Search Console через API и о многом другом.
Начало работы
Файл robots.txt находится в корневом каталоге вашего сайта. Например, на сайте www.example.com адрес файла robots.txt будет выглядеть как www.example.com/robots.txt. Файл robots.txt представляет собой обычный текстовый файл, который соответствует стандарту исключений для роботов, и включает одно или несколько правил, каждое из которых запрещает или разрешает тому или иному поисковому роботу доступ к определенному пути на сайте.
Вот пример простого файла robots.txt с двумя правилами. Ниже приведены пояснения.
# Группа 1 User-agent: Googlebot Disallow: /nogooglebot/ # Группа 2 User-agent: * Allow: / Sitemap: http://www.example.com/sitemap.xml
Пояснения
- Агент пользователя с названием Googlebot не должен сканировать каталог и его подкаталоги.
- У всех остальных агентов пользователя есть доступ ко всему сайту (можно опустить, результат будет тем же, так как полный доступ предоставляется по умолчанию).
- Файл Sitemap этого сайта находится по адресу http://www.example.com/sitemap.xml.
Далее представлен более подробный пример.
О файле robots.txt
Файл robots.txt это текстовой файл, в котором прописываются правила для поисковых машин для сканирования, а значит индексации папок и файлов сайта. Находится файл robots.txt должен в корневом каталоге сайта. Файл robots.txt наряду с картой сайта Sitemap это основные документы SEO оптимизации блогов сделанных на CMS WordPress.
Важно! Недопустимо пустые переводы строк между директивами и (), а также между директивами и. Важно! URL файла robots.txt чувствителен к регистру
Важно! URL файла robots.txt чувствителен к регистру. На базовой версии файл robots.txt для wordpress выглядит следующим образом:
На базовой версии файл robots.txt для wordpress выглядит следующим образом:
- User-agent это обращение к поисковикам. звезда, означает, что следующие директивы группы обращены ко всем поисковикам;
- Директива Disallow запрещает поисковикам индексировать только то, что находится в папках /wp-admin/ и /wp-includes/.
Файл robots.txt составляется из строк, каждая из которых является отдельной директивой. Директива, а проще говоря, правило, пишется для поисковиков. Весь файл robots.txt пишется по специальному несложному синтаксису.
Basic robots.txt guidelines
Here are some basic guidelines for robots.txt files. We recommend that you read the full syntax of robots.txt files because the robots.txt syntax has some subtle behavior that you should understand.
Format and location
You can use almost any text editor to create a robots.txt file. The text editor should be able to create standard UTF-8 text files. Don’t use a word processor; word processors often save files in a proprietary format and can add unexpected characters, such as curly quotes, which can cause problems for crawlers.
Use the robots.txt Tester tool to write or edit robots.txt files for your site. This tool enables you to test the syntax and behavior against your site.
Format and location rules:
- The file must be named robots.txt
- Your site can have only one robots.txt file.
- The robots.txt file must be located at the root of the website host to which it applies. For instance, to control crawling on all URLs below , the robots.txt file must be located at . It cannot be placed in a subdirectory (for example, at ). If you’re unsure about how to access your website root, or need permissions to do so, contact your web hosting service provider. If you can’t access your website root, use an alternative blocking method such as meta tags.
- A robots.txt file can apply to subdomains (for example, ) or on non-standard ports (for example, ).
- Comments are any content after a # mark.
Syntax
- robots.txt must be an UTF-8 encoded text file (which includes ASCII). Using other character sets is not possible.
- A robots.txt file consists of one or more group.
- Each group consists of multiple rules or directives (instructions), one directive per line.
- A group gives the following information:
- Who the group applies to (the user agent)
- Which directories or files that agent can access, and/or
- Which directories or files that agent cannot access.
- Groups are processed from top to bottom, and a user agent can match only one rule set, which is the first, most-specific rule that matches a given user agent.
- The default assumption is that a user agent can crawl any page or directory not blocked by a rule.
- Rules are case-sensitive. For instance, applies to , but not .
The following directives are used in robots.txt files:
-
The name of a search engine robot (web crawler software) that the rule applies to. This is the first line for any rule. Most Google user-agent names are listed in the Web Robots Database or in the Google list of user agents. Supports the * wildcard for a path prefix, suffix, or entire string. Using an asterisk () as in the example below will match all crawlers except the various AdsBot crawlers, which must be named explicitly. (See the list of Google crawler names.) Examples:
# Example 1: Block only Googlebot User-agent: Googlebot Disallow: / # Example 2: Block Googlebot and Adsbot User-agent: Googlebot User-agent: AdsBot-Google Disallow: / # Example 3: Block all but AdsBot crawlers User-agent: * Disallow: /
- A directory or page, relative to the root domain, that should not be crawled by the user agent. If a page, it should be the full page name as shown in the browser; if a directory, it should end in a / mark. Supports the * wildcard for a path prefix, suffix, or entire string.
- A directory or page, relative to the root domain, that should be crawled by the user agent just mentioned. This is used to override Disallow to allow crawling of a subdirectory or page in a disallowed directory. If a page, it should be the full page name as shown in the browser; if a directory, it should end in a / mark. Supports the * wildcard for a path prefix, suffix, or entire string.
-
The location of a sitemap for this website. Must be a fully-qualified URL; Google doesn’t assume or check http/https/www.non-www alternates. Sitemaps are a good way to indicate which content Google should crawl, as opposed to which content it can or cannot crawl. Learn more about sitemaps. Example:
Sitemap: https://example.com/sitemap.xml Sitemap: http://www.example.com/sitemap.xml
Other rules are ignored.
Another example file
A robots.txt file consists of one or more groups, each beginning with a line that specifies the target of the groups. Here is a file with two group; inline comments explain each group:
# Block googlebot from example.com/directory1/... and example.com/directory2/... # but allow access to directory2/subdirectory1/... # All other directories on the site are allowed by default. User-agent: googlebot Disallow: /directory1/ Disallow: /directory2/ Allow: /directory2/subdirectory1/ # Block the entire site from anothercrawler. User-agent: anothercrawler Disallow: /
Серпхант
Недавно открыл для себя интересный онлайн сервис с помощью которого можно проверить индексацию страницы. Все очень просто, вводите списком ссылки на необходимые страницы и нажимаете кнопку Начать проверку.
Проверка индексации сервисом Серпхант
По истечению непродолжительного времени вым выдаются результаты проверки индексации в Яндексе и Google запрошенных страниц.
Результат проверки индексации
Описанный способ наверное самый простой и быстрый чтобы проверить индексацию страницы.
Я описал способы, которыми пользуюсь сам для быстрой проверки индексации страницы в поисковых системах. На самом деле похожих сервисов довольно много, есть бесплатные и платные, хорошие и не очень.
В данной статье я специально не упомянул сервисы Вебмастера от Яндекс и Google. У каждого из перечисленных поисковиков есть свой инструментарий, который дает полную картину о сайте, но чтобы ими воспользоваться ты должен быть хозяином сайта, а вышеперечисленные методы подходят абсолютно для любого сайта, будь он чужим или своим.
Дмитрий Леонов | leonov-do.ru
Выводы Incapusla

Когда Incapusla обратили внимание на стандартного гуглбота, то заметили некоторые интересные моменты. Для начала следует отметить, что гуглботы сканируют больше страниц, чем роботы всех других поисковых систем вместе взятые, — 60,5%
Для начала следует отметить, что гуглботы сканируют больше страниц, чем роботы всех других поисковых систем вместе взятые, — 60,5%.
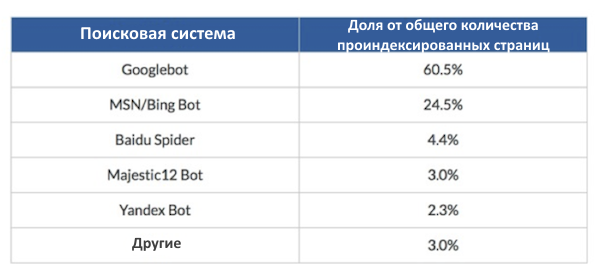
То, что Incapusla обнаружили при анализе этих посещений, также было немного неожиданно:
- Yahoo выбыл из топ 5 поисковых роботов.
- Majestic 12 Bot, или бот WebCrawler Majestic SEO, занял четвертое место.
- Google не оказывает никому покровительства.
- Нет практически никакой разницы между размером площадки и:
- Частотой индексации,
- Показателем индексации,
- Глубиной индексации,
- SEO-продуктивностью.
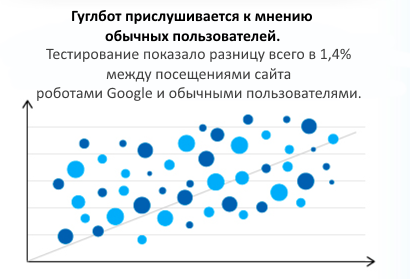
Известно, что Google — крупнейший генератор посещений ботов и что эти посещения инициируются чем-то иным, нежели активностью сайта или SEO, и что он прислушивается к мнению пользователей.
В целом, довольно неплохо. Но беспокойство вызывает не Google, а его «злые» близнецы, с которыми следует быть осторожнее (их очень много — и некоторые их них отлично сделаны).