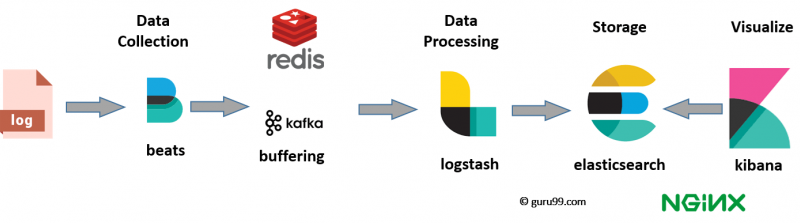
How to create a custom kibana dashboard
Содержание:
- Введение
- Создание index шаблона
- Установка Java 8
- Установка Filebeat для отправки логов в Logstash
- Генерирование SSL-сертификата
- Настройка координатной карты в Kibana
- Kibana Discover
- Add Visualization to Dashboard
- Шаг 4 — Установка и настройка Filebeat
- Установка и конфигурирование
- Focusing on logs and using saved searches
- Установка Elasticsearch
- Установка и настройка Winlogbeat
- Настройка Kibana
- Настройка Dashboard для nginx
- Заключение
Введение
Начнем создание дашборда с самого сложного — настройки гео карты запросов. На официальном сайте есть подробный мануал на тему создания GeoIP карты. В нем вроде бы все понятно. Никаких особых настроек не требуется. Все работает из коробки. Но у меня никак не хотело работать все то, что там описано. Пришлось прилично поковыряться с elasticsearch и его шаблонами, чтобы разобраться в чем причина.
Все дело в том, что описанный в инструкции способ работает из коробки, только если вы используете стандартный шаблон для индексов в формате logstash-*. Скорее всего у вас будет много разных шаблонов и индексов после того, как вы запустите систему в промышленную эксплуатацию.
Основная сложность тут в том, что для работы geoip карты вам нужны в шаблоне поля с типом geo_point. После создания индекса, тип полей уже нельзя поменять. То есть просто преобразовать данные на основе ip в координаты не сложно, это умеет делать модуль geoip в logstash. Но вот дальше вы никак не превратите координаты в виде числа в geo_point данные. Нужно в самом начале создать шаблон с такими полями.
Надеюсь понятно объяснил 🙂 Если не понятно сразу, то сообразите дальше по ходу моего рассказа. Я сам пока разобрался в этой кухне, прилично поковырялся и нагуглился.
В дальнейшем я буду считать, что ваш elasticsearch и kibana настроены примерно как у меня в инструкции. Фильтр logstash, отвечающий за обработку логов nginx выглядит следующим образом:
if == "nginx-ext-access" {
grok {
match =>
overwrite =>
}
mutate {
convert =>
convert =>
convert =>
}
geoip {
source => "clientip"
target => "geoip"
add_tag =>
}
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
remove_field =>
}
useragent {
source => "agent"
}
}
И вот так логи уходят в elasticsearch
if == "nginx-ext-access" {
elasticsearch {
hosts => "localhost:9200"
index => "nginx-ext-%{+YYYY.MM.dd}"
}
}
Создание index шаблона
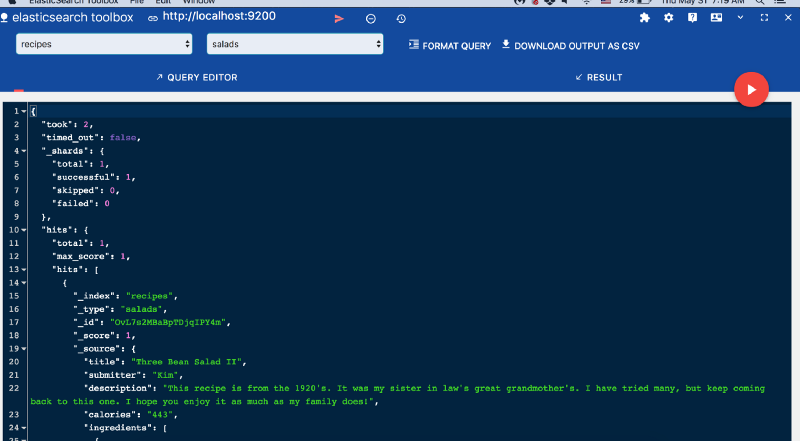
Как я уже сказал выше, для того, чтобы у вас заработала geoip карта, у вас должны быть в шаблоне индекса поля типа geo_point. Если их не будет, то вы сразу при создании визуализации с Coordinate Map получите ошибку:

No Compatible Fields: The "nginx-*" index pattern does not contain any of the following field types: geo_point
Что я только не делал, после того, как получил эту ошибку. Я проверял работу geoip модуля. Смотрел поля с координатами на основе ip адреса. Все было в порядке и все было на месте.

Но geoip карта в Kibana не работала. Погуглив немного эту тему, я потихоньку стал понимать, в чем тут дело.
Для начала посмотрим шаблон нашего индекса с логами nginx. Для этого идем в Management -> Index Management. Выбираем наш индекс и смотрим Mapping. Нас интересует поле location.
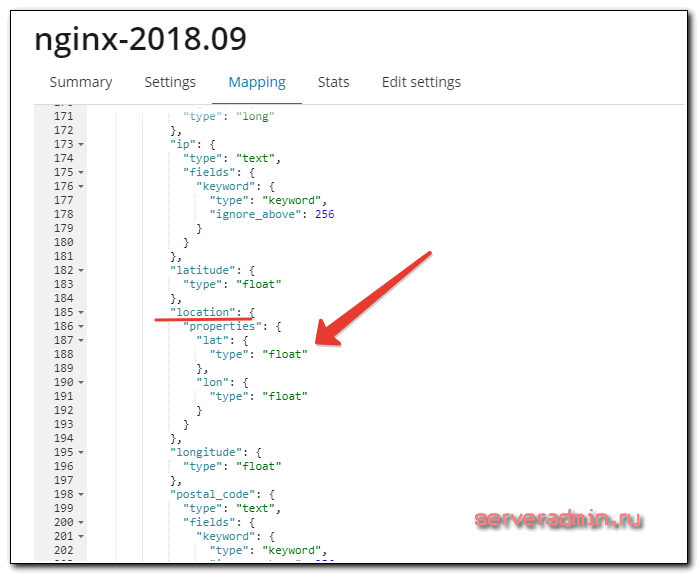
Оно имеет тип float, а нам нужно, судя по статье на сайте, тип geo_point.

Дальше стал разбираться, как изменить тип поля в шаблоне. Оказалось, что это сделать нельзя. Тип полей можно установить только в момент создания индекса из шаблона. Значит нужно понять, как сделать свой шаблон с нужными полями.
Для начала посмотрим, какие шаблоны у нас сейчас установлены. Для этого идем в Dev Tools и выполняем команду:
GET /_template

Обращаем внимание на шаблон logstash. В нем есть все, что нам нужно
Если ваш индекс будет иметь шаблон logstash-*, то вам ничего настраивать не надо, все заработает из коробки. Мы же добавим новый шаблон nginx* и установим у него параметры полей, необходимые для работы geoip карты.
Выполняем следующий код для создания шаблона nginx по аналогии с шаблоном logstash.
PUT _template/nginx
{
"index_patterns": ,
"settings": {
"index": {
"refresh_interval": "5s"
}
},
"mappings": {
"_default_": {
"dynamic_templates": ,
"properties": {
"@timestamp": {
"type": "date"
},
"@version": {
"type": "keyword"
},
"geoip": {
"dynamic": true,
"properties": {
"ip": {
"type": "ip"
},
"location": {
"type": "geo_point"
},
"latitude": {
"type": "half_float"
},
"longitude": {
"type": "half_float"
}
}
}
}
}
},
"aliases": {}
}
Проверяем список доступных шаблонов.

Все в порядке. Теперь новые индексы, попадающие под этот шаблон, будут содержать необходимые поля. Можете либо удалить текущие индексы, для создания новых, либо подождать, когда они сами создадутся в соответствии с вашими правилами.
Прежде чем двигаться дальше, проверьте, что у вас в шаблоне индекса действительно есть поле geo_point. Идем в Management -> Index Patterns и смотрим поля нашего индекса, предварительно обновив их, нажав Refresh field list.

Если у вас так же, можно двигаться дальше.
На всякий случай расскажу про неправильный путь, по которому я пошел изначально, пытаясь решить проблему с шаблоном. Я узнал, что logstash хранит свои шаблоны в директории /usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-output-elasticsearch-9.2.0-java/lib/logstash/outputs/elasticsearch (пипец какой путь :)). Я решил изменить его шаблон, для этого просто отредактировал файл elasticsearch-template-es6x.json, поменяв шаблон для индекса. Перезапустил logstash, но ничего не изменилось. Этот шаблон был залит в elasticsearch при первом запуске. Потом уже не меняется. Его надо удалить, чтобы он установился заново с моими изменениями. Я не стал это делать, а просто загрузил новый шаблон.
Установка Java 8
Приведенная ниже инструкция по установке Java 8 немного устарела в связи с изменением лицензии Oracle. Про установку Oracle Java на Centos или Ubuntu читайте отдельную, актуальную на сегодняшний день статью.
Все компоненты системы, за исключением агентов на серверах, написаны на java, поэтому нашу настройку начнем с установки Oracle Java 8. Эта версия выбрана, потому что поддерживается всеми версиями Elasticsearch. Подробнее о совместимости программных продуктов смотрите в отдельной из документации.
Если у вас еще нет своего сервера с CentOS 8, то рекомендую мои материалы на эту тему:
- Установка CentOS 8.
- Настройка CentOS.
Если у вас еще не настроен сервер с Debian, рекомендую мои материалы на эту тему:
- Установка Debian на сервер
- Базовая настройка Debian после установки
CentOS
Идем на страницу https://www.oracle.com/technetwork/java/javase/downloads/jre8-downloads-2133155.html, жмем плашку «Accept License Agreement» и скачиваем файл *-linux-x64.rpm. Чтобы его загрузить, придется зарегистрироваться и авторизоваться на сайте oracle.com.
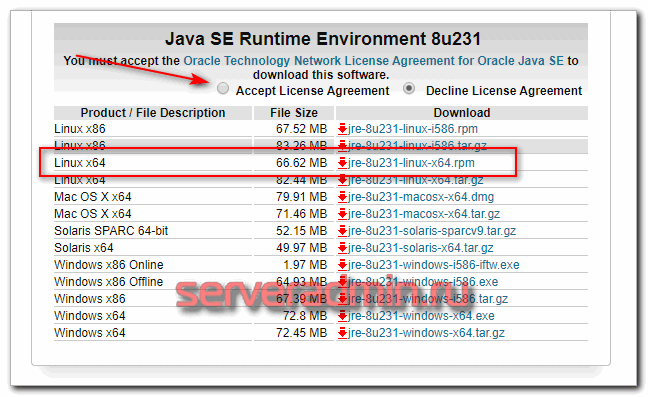
После этого копируем любым удобным для вас способом пакет с java на сервер. Я обычно это делаю через scp. Устанавливаем Java 8.
Проверим установленную версию:
Ubuntu / Debian
Идем на страницу https://www.oracle.com/technetwork/java/javase/downloads/jre8-downloads-2133155.html, жмем плашку «Accept License Agreement» и скачиваем файл *-linux-x64.tar.gz. Чтобы его загрузить, придется зарегистрироваться и авторизоваться на сайте oracle.com.
После загрузки любым удобным для вас способом скопируйте файл на целевой сервер, куда будем устанавливать Java 8. Я для этого использую scp. Копирую файл в домашнюю директорию /root. Создаем директорию для java и распаковываем туда бинарники.
Java машина должна расположиться в директории /usr/lib/jvm/jre1.8.0_231. Теперь нам необходимо создать символьные ссылки на установленную версию java. Делаем это с помощью update-alternatives.
Зададим переменную JAVA_HOME, которую используют некоторые приложения. Для этого добавляем в файл /etc/environment следующую строку.
Сохраняем его и применяем изменение.
Теперь проверим, что у нас получилось.
Установка Filebeat для отправки логов в Logstash
Установим первого агента Filebeat на сервер с nginx для отправки логов веб сервера на сервер с ELK. Ставить можно как из общего репозитория, который мы подключали ранее, так и по отдельности пакеты. Как ставить — решать вам. В первом случае придется на все хосты добавлять репозиторий, но зато потом удобно обновлять пакеты. Если подключать репозиторий не хочется, можно просто скачать пакет и установить его.
Ставим на Centos.
В Debian/Ubuntu ставим так:
Или просто:
После установки рисуем примерно такой конфиг /etc/filebeat/filebeat.yml для отправки логов в logstash.
Некоторые пояснения к конфигу, так как он не совсем дефолтный и минималистичный. Я его немного модифицировал для удобства. Во-первых, я разделил логи access и error с помощью отдельного поля type, куда записываю соответствующий тип лога: nginx_access или nginx_error. В зависимости от типа меняются правила обработки в logstash. Плюс, я включил мониторинг и для этого указал адрес elastichsearch, куда filebeat передает данные мониторинга напрямую. Показываю это для вас просто с целью продемонстрировать возможность. У меня везде отдельно работает мониторинг на zabbix, так что большого смысла в отдельном мониторинге нет. Но вы посмотрите на него, возможно вам он пригодится. Чтобы мониторинг работал, его надо активировать в соответствующем разделе в Kibana — Monitoring. И не забудьте запустить elasticsearch на внешнем интерфейсе. В первоначальной настройке я указал слушать только локальный интерфейс.
Запускаем filebeat и добавляем в автозагрузку.
Проверяйте лог по адресу /var/log/filebeat/filebeat. Он весьма информативен. Если все в порядке, увидите список всех логов в директории /var/log/nginx, которые нашел filebeat и начал готовить к отправке. Если все сделали правильно, то данные уже потекли в elasticsearch. Мы их можем посмотреть в Kibana. Для этого открываем web интерфейс и переходим в раздел Discover. Так как там еще нет индекса, нас перенаправит в раздел Managemet, где мы сможем его добавить.

Вы должны увидеть индекс, который начал заливать logstash в elasticsearch. В поле Index pattern введите nginx-* и нажмите Next Step. На следующем этапе выберите имя поля для временного фильтра. У вас будет только один вариант — @timestamp, выбирайте его и жмите Create Index Pattern.

Новый индекс добавлен. Теперь при переходе в раздел Discover, он будет открываться по-умолчанию со всеми данными, которые в него поступают.

Получением логов с linux серверов настроили. Теперь сделаем то же самое для журналов windows.
Генерирование SSL-сертификата
Чтобы сервис Filebeat передавал логи клиентов на сервер ELK, нужно создать SSL-сертификат и ключ. С помощью сертификата Filebeat сможет проверить подлинность сервера ELK. Создайте каталоги для хранения сертификата и закрытого ключа:
Теперь у вас есть два варианта: вы можете создать сертификат либо для IP-адреса, либо для доменного имени.
1: Сертификат для IP-адреса
Если у вас нет домена, вы можете указать в сертификате IP-адрес сертификата ELK. Для этого укажите адрес в поле subjectAltName. Откройте конфигурационный файл OpenSSL.
Найдите в нём раздел и добавьте в него строку:
Примечание: Укажите IP своего сервера ELK.
Теперь вы можете сгенерировать SSL-сертификат и ключ в /etc/pki/tls/ с помощью команд:
Файл logstash-forwarder.crt будет скопирован на все серверы, которые отправляют логи в Logstash. После этого нужно завершить настройку Logstash.
2: Сертификат для домена
Если у вас есть доменное имя, направленное на сервер ELK, вы можете указать это имя в сертификате SSL.
Чтобы сгенерировать сертификат, введите команду:
Примечание: Вместо ELK_server_fqdn укажите доменное имя сервера ELK.
Файл logstash-forwarder.crt нужно скопировать на все серверы, которые отправляют логи в Logstash. После этого нужно завершить настройку Logstash.
Настройка координатной карты в Kibana
Теперь создадим географическую карту с распределением запросов nginx по этой карте на основе ip адресов. Идем в раздел Visualize и добавляем Coordinate Map. Выбираем индекс с логами nginx. Указываем в карте поле с координатами — geoip.location.

Запускаете визуализацию и смотрите результат.

Теперь эту карту можно добавить на дашборд вместе с остальными графиками. Не буду рассказывать, как добавить обычные графики. Там хоть и не совсем все очевидно, но не так сложно. Лучше самим разобраться и порисовать различные графики, чтобы понять, какая визуализация для вас наиболее удобна. Я подобрал по своему вкусу. Много раз перерисовывал и переделывал, пока не удовлетворился результатом.
Kibana Discover
When you first connect to Kibana 4, you will be taken to the Discover page. By default, this page will display all of your ELK stack’s most recently received logs. Here, you can filter through and find specific log messages based on Search Queries, then narrow the search results to a specific time range with the Time Filter.
Here is a breakdown of the Kibana Discover interface elements:
- Search Bar: Directly under the main navigation menu. Use this to search specific fields and/or entire messages
- Time Filter: Top-right (clock icon). Use this to filter logs based on various relative and absolute time ranges
- Field Selector: Left, under the search bar. Select fields to modify which ones are displayed in the Log View
- Date Histogram: Bar graph under the search bar. By default, this shows the count of all logs, versus time (x-axis), matched by the search and time filter. You can click on bars, or click-and-drag, to narrow the time filter
- Log View: Bottom-right. Use this to look at individual log messages, and display log data filtered by fields. If no fields are selected, entire log messages are displayed
This animation demonstrates a few of the main features of the Discover page:
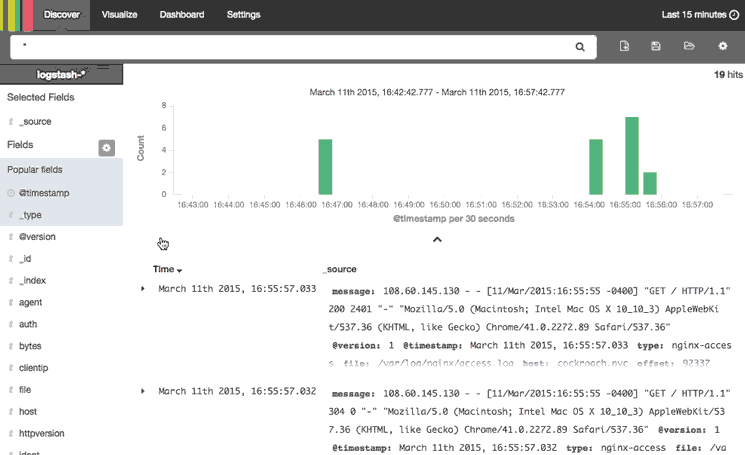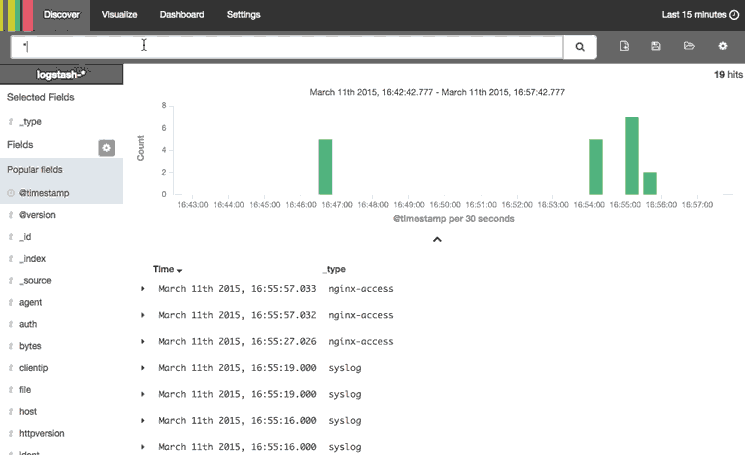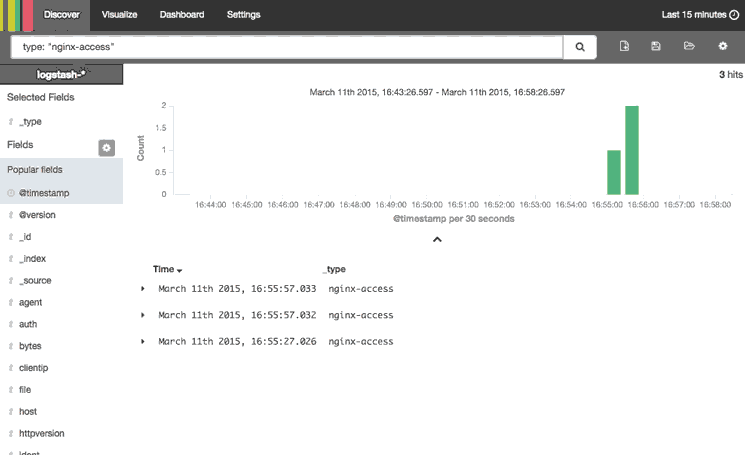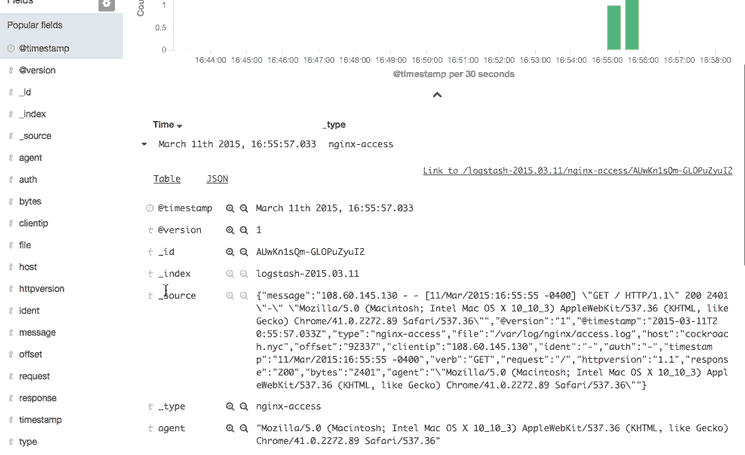
Here is a step-by-step description of what is being performed:
- Selected the “type” field, which limits what is displayed for each log record (bottom-right)—by default, the entire log message is displayed
- Searched for , which only matches Nginx access logs
- Expanded the most recent Nginx access log to look at it in more detail
Note that the results are being limited to the “Last 15 minutes”. If you are not getting any results, be sure that there were logs, that match your search query, generated in the time period specified.
The log messages that are gathered and filtered are dependent on your Logstash and Logstash Forwarder configurations. In our example, we are gathering the syslog and Nginx access logs, and filtering them by “type”. If you are gathering log messages but not filtering the data into distinct fields, querying against them will be more difficult as you will be unable to query specific fields.
Search Syntax
The search provides an easy and powerful way to select a specific subset of log messages. The search syntax is pretty self-explanatory, and allows boolean operators, wildcards, and field filtering. For example, if you want to find Nginx access logs that were generated by Google Chrome users, you can search for . You could also search by specific hosts or client IP address ranges, or any other data that is contained in your logs.
When you have created a search query that you want to keep, you can do that by clicking the Save Search icon then the Save button, like in this animation:
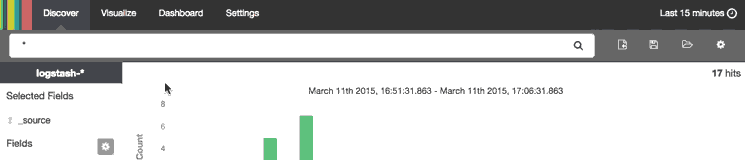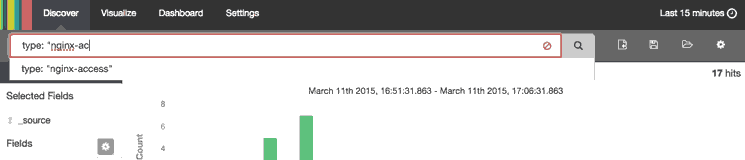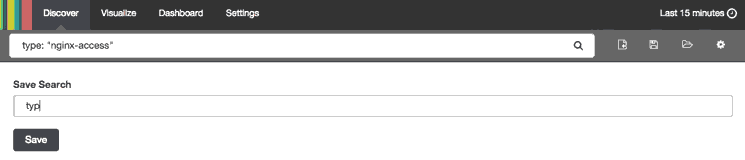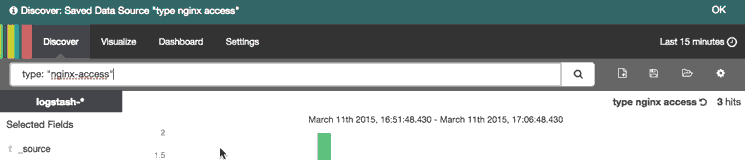
Saved searches can be opened at any time by clicking the Load Saved Search icon, and they can also be used when creating visualizations.
We will save the search as “type nginx access”, and use it to create a visualization.
Add Visualization to Dashboard
When we click the Add button (top left corner), it displays us the visualization we created as shown below −
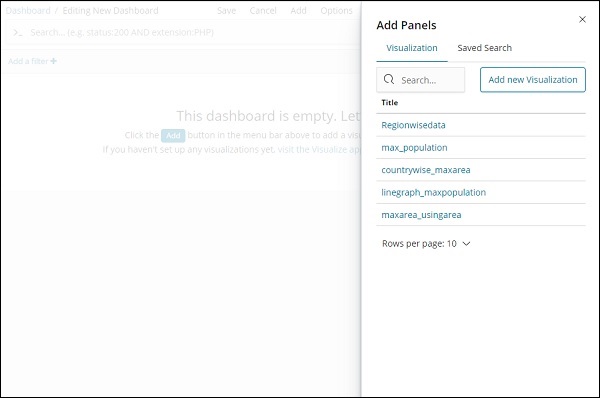
Select the visualization you want to add to your dashboard. We will select the first three visualizations as shown below −
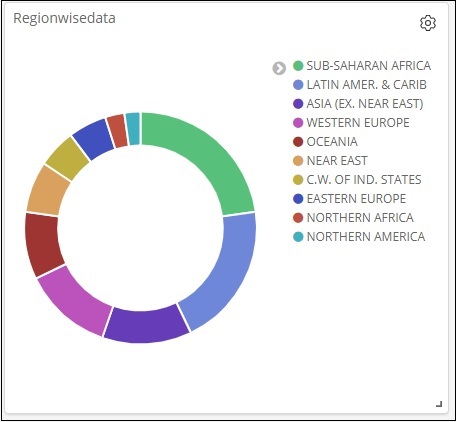
This is how it is seen on the screen together −

Thus, as a user you are able to get the overall details about the data we have uploaded – country wise with fields country-name, regionname, area and population.
So now we know all the regions available, the max population country wise in descending order, the max area etc.
This is just the sample data visualization we uploaded, but in real world it becomes very easy to track the details of your business like for example you have a website which gets millions of hits monthly or daily, you want to keep a track on the sales done every day, hour, minute, seconds and if you have your ELK stack in place Kibana can show you your sales visualization right in front of your eyes every hour, minute, seconds as you want to see. It displays the real time data as it is happening in the real world.
Kibana, on the whole, plays a very important role in extracting the accurate details about your business transaction day wise, hourly or every minute, so the company knows how the progress is going on.
Шаг 4 — Установка и настройка Filebeat
Комплекс Elastic Stack использует несколько компактных элементов транспортировки данных (Beats) для сбора данных из различных источников и их транспортировки в Logstash или Elasticsearch. Ниже перечислены компоненты Beats, доступные в Elastic:
- Filebeat: собирает и отправляет файлы журнала.
- Metricbeat: собирает метрические показатели использования систем и служб.
- Packetbeat: собирает и анализирует данные сети.
- Winlogbeat: собирает данные журналов событий Windows.
- Auditbeat: собирает данные аудита Linux и отслеживает целостность файлов.
- Heartbeat: отслеживает доступность услуг посредством активного зондирования.
В этом обучающем модуле мы используем Filebeat для перенаправления локальных журналов в комплекс Elastic Stack.
Установите Filebeat с помощью :
Затем настройте Filebeat для подключения к Logstash. Здесь мы изменим образец файла конфигурации, входящий в комплектацию Filebeat.
Откройте файл конфигурации Filebeat:
Примечание. Как и в Elasticsearch, файл конфигурации Filebeat имеет формат YAML. Это означает, что в файле учитываются отступы, и вы должны использовать точно такое количество пробелов, как указано в этих инструкциях.
Filebeat поддерживает разнообразные выводы, но обычно события отправляются только напрямую в Elasticsearch или в Logstash для дополнительной обработки. В этом обучающем модуле мы будем использовать Logstash для дополнительной обработки данных, собранных Filebeat. Filebeat не потребуется отправлять данные в Elasticsearch напрямую, поэтому мы отключим этот вывод. Для этого мы найдем раздел и поставим перед следующими строками значок комментария :
/etc/filebeat/filebeat.yml
Затем настроим раздел . Уберите режим комментариев для строк и , удалив значки . Так мы настроим Filebeat для подключения к Logstash на сервере комплекса Elastic Stack через порт , который мы ранее задали для ввода Logstash:
/etc/filebeat/filebeat.yml
Сохраните и закройте файл.
Функции Filebeat можно расширить с помощью модулей Filebeat. В этом обучающем модуле мы будем использовать модуль system, который собирает и проверяет данные журналов, созданных службой регистрации систем в распространенных дистрибутивах Linux.
Давайте активируем его:
Вы увидите список включенных и отключенных модулей с помощью следующей команды:
Вы увидите примерно следующий список:
Filebeat по умолчанию настроен для использования путей по умолчанию для системных журналов и журналов авторизации. Для целей данного обучающего модуля вам не нужно ничего изменять в конфигурации. Вы можете посмотреть параметры модуля в файле конфигурации .
Затем загрузите в Elasticsearch шаблон индекса. — это коллекция документов со сходными характеристиками. Индексы идентифицируются по имени, которое используется для ссылки на индекс при выполнении различных операций внутри него. Шаблон индекса применяется автоматически при создании нового индекса.
Используйте следующую команду для загрузки шаблона:
В комплект Filebeat входят образцы информационных панелей Kibana, позволяющие визуализировать данные Filebeat в Kibana. Прежде чем вы сможете использовать информационные панели, вам нужно создать шаблон индекса и загрузить информационные панели в Kibana.
При загрузке информационных панелей Filebeat подключается к Elasticsearch для проверки информации о версиях. Для загрузки информационных панелей при включенном Logstash необходимо отключить вывод Logstash и активировать вывод Elasticsearch:
Вы получите следующий результат:
Теперь вы можете запустить и активировать Filebeat:
Если вы правильно настроили комплекс Elastic, Filebeat начнет отправлять системный журнал и журналы авторизации в Logstash, откуда эти данные будут загружаться в Elasticsearch.
Чтобы подтвердить получение этих данных в Elasticsearch необходимот отправить в индекс Filebeat запрос с помощью следующей команды:
Вы увидите примерно следующий результат:
Если в результатах показано 0 совпадений, Elasticsearch не выполняет загрузку журналов в индекс, который вы искали, и вам нужно проверить настройки на ошибки. Если вы получили ожидаемые результаты, перейдите к следующему шагу, где мы увидим, как выполняется навигация по информационным панелям Kibana.
Установка и конфигурирование
Перед установкой Metricbeat следует удостовериться, что уже установлены и настроены:
- Elasticsearch для хранения и индексирования данных
- Kibana для отображения данных
- Logstash (опционально) для парсинга и обработки данных
После установки стека Elastic следует выполнить следующие шаги:
Установка Metricbeat
Для загрузки и установки Metricbeat используйте команды, соответствующие используемой вами системе:
deb:
curl -L -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-6.4.0-amd64.deb sudo dpkg -i metricbeat-6.4.0-amd64.deb
rpm:
curl -L -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-6.4.0-x86_64.rpm sudo rpm -vi metricbeat-6.4.0-x86_64.rpm
mac:
curl -L -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-6.4.0-darwin-x86_64.tar.gz tar xzvf metricbeat-6.4.0-darwin-x86_64.tar.gz
docker:
docker pull docker.elastic.co/beats/metricbeat:6.4.0
Настройка Metricbeat
Для настройки Metricbeat следует редактировать файл конфигурации. В случае установки из rpm или deb-пакета, файл конфигурации можно будет найти по следующему пути: /etc/pack metricbeat/metricbeat.yml. В случае с Docker, путь будет иметь вид: /usr/share/metricbeat/metricbeat.yml. Для mac или windows, файл будет находиться в папке, куда вы извлекли содержимое архива.
Для настройки Metricbeat:
1. Выберите модули, которые следует активировать:
Следующие примеры помещают конфигурации apache и mysql в папку modules.d
deb и rpm:
metricbeat modules enable apache mysql
mac:
./metricbeat modules enable apache mysql
2. Настройка вывода
Metricbeat поддерживает множество способов вывода, но чаще всего используется передача в Elasticsearch или в Logstash для дополнительной обработки
Для отправки данных в Elasticsearch напрямую (без использования Logstash), укажите путь к установленной копии Elasticsearch:
cloud.id: "staging:dXMtZWFzdC0xLmF3cy5mb3VuZC5pbyRjZWM2ZjI2MWE3NGJmMjRjZTMzYmI4ODExYjg0Mjk0ZiRjNmMyY2E2ZDA0MjI0OWFmMGNjN2Q3YTllOTYyNTc0Mw="
в случае использования Elastic Cloud или
output.elasticsearch: hosts:
для локально установленного Elasticsearch
3. Если вы планируете использовать встроенные в Metricbeat панели Kibana, следует указать endpoint установленного Kibana
setup.kibana: host: "mykibanahost:5601"
Этот шаг можно пропустить, если Kibana работает на том же хосте, что и Elasticsearch.
4. Если Elasticsearch и Kibana защищены паролем, следует добавить в файл конфигурации metricbeat.yml данные авторизации:
output.elasticsearch: hosts: username: "metricbeat_internal" password: "YOUR_PASSWORD" setup.kibana: host: "mykibanahost:5601" username: "my_kibana_user" password: "YOUR_PASSWORD"
или
cloud.auth: "elastic:YOUR_PASSWORD"
при использовании Elastic Cloud
Загрузка шаблона в Elasticsearch
Рекомендуемый шаблон уже поставляется в комплекте с Metricbeat. Если вы согласны с конфигурацией metricbeat.yml по умолчанию, Metricbeat автоматически загрузит шаблон при успешном соединении с Elasticsearch. Если шаблон уже существует, он не будет перезаписан.
Автоматическую подгрузку шаблона можно отключить или загрузить собственный шаблон, настроив опции загрузки шаблонов в файле конфигурации metricbeat.yml:
setup.template.name: "your_template_name" setup.template.fields: "path/to/fields.yml" setup.template.overwrite: true setup.template.enabled: false
Настройка панелей Kibana
В комплекте с Metricbeat уже поставляются предустановленные панели для Kibana и визуализации. Перед их использованием требуется создать шаблон индекса, metricbeat-*, и загрузить панели в Kibana. Для этого требуется вызвать следующие команды:
deb и rpm:
metricbeat setup --dashboards
mac:
./metricbeat setup --dashboards
docker:
docker run docker.elastic.co/beats/metricbeat:6.4.0 setup --dashboards
Перед запуском удостоверьтесь, что Kibana запущена.
Запуск Metricbeat
Для запуска Metricbeat следует использовать команды, соответствующие установленной операционной системе:
deb:
sudo service metricbeat start
rpm:
sudo service metricbeat start
docker:
docker pull docker.elastic.co/beats/metricbeat:6.4.0 docker run \ --mount type=bind,source="$(pwd)"/metricbeat.yml,target=/usr/share/metricbeat/metricbeat.yml \ docker.elastic.co/beats/metricbeat:6.4.0
mac:
sudo chown root metricbeat.yml sudo chown root modules.d/system.yml sudo ./metricbeat -e -c metricbeat.yml -d "publish"
Focusing on logs and using saved searches
You know what you want to visualize, and you know what log type and corresponding fields you most likely need to use. What next?
A recommended way to proceed is to use the Discover page in Kibana to search for the data you’re interested in and then saving your search. Once saved, this search will provide you with a starting point for single or multiple visualizations for building a dashboard. If you decide you want to analyze a different set of data, changing the saved search will change all the linked visualizations accordingly instead of having to change all of them individually.
Saved searches can also be inserted into dashboards, allowing you to embed the Discover tab within a dashboard, giving you good visibility into relevant logs.

Установка Elasticsearch
Чтобы установить Elasticsearch, добавьте файл sources.list для этого пакета.
Чтобы добавить GPG-ключ Elasticsearch, введите:
Если на этом этапе командная строка зависла, введите пароль текущего пользователя.
Чтобы создать sources.list для Elasticsearch, введите:
Обновите индекс пакетов:
Установите Elasticsearch:
Отредактируйте конфигурационный файл Elasticsearch:
Ограничьте внешний доступ к Elasticsearch (порт 9200), чтобы посторонние пользователи не смогли прочитать данные или отключить Elasticsearch с помощью HTTP API. Найдите строку network.host и измените её значение на localhost.
Сохраните и закройте elasticsearch.yml. Запустите Elasticsearch:
Чтобы настроить автозапуск Elasticsearch, введите:
Установка и настройка Winlogbeat
Для настройки централизованного сервера сбора логов с Windows серверов, установим сборщика системных логов winlogbeat. Для этого скачаем его и установим в качестве службы. Идем на страницу загрузок и скачиваем версию под вашу архитектуру — 32 или 64 бита.
Распаковываем скачанный архив и копируем его содержимое в директорию C:\Program Files\Winlogbeat. Сразу же создаем там папку logs для хранения логов самого winlogbeat.

Запускаем консоль Powershell от администратора и выполняем команды:
У меня был такой вывод:
Служба установилась и в данный момент она остановлена. Правим конфигурационный файл winlogbeat.yml. Я его привел к такому виду:
В принципе, по тексту все понятно. Я беру 3 системных лога Application, Security, System (для русской версии используются такие же названия) и отправляю их на сервер с logstash. Настраиваю хранение логов и включаю мониторинг по аналогии с filebeat
Отдельно обращаю внимание на tags: . Этим тэгом я помечаю все отправляемые сообщения, чтобы потом их обработать в logstash и отправить в elasticsearch с отдельным индексом
Я не смог использовать поле type, по аналогии с filebeat, потому что в winlogbeat в поле type жестко прописано wineventlog и изменить его нельзя. Если у вас данные со всех серверов будут идти в один индекс, то можно tag не добавлять, а использовать указанное поле type для сортировки. Если же вы данные с разных среверов хотите помещать в разные индексы, то разделяйте их тэгами.
После настройки можно запустить службу winlogbeat, которая появится в списке служб windows. Но для того, чтобы логи виндовых журналов пошли в elasticsearch не в одну кучу вместе с nginx логами, нам надо настроить для них отдельный индекс в logstash в разделе output. Идем на сервер с logstash и правим конфиг output.conf.
Думаю, по тексту понятен смысл. Я разделил по разным индексам логи nginx, системные логи виндовых серверов и добавил отдельный индекс unknown_messages, в который будет попадать все то, что не попало в предыдущие. Это просто задел на будущее, когда конфигурация будет более сложная, можно будет ловить сообщения, которые по какой-то причине не попали ни в одно из приведенных выше правил.
Я не смог в одно правило поместить оба типа nginx_error и nginx_access, потому что не понял сходу, как это правильно записать, а по документации уже устал лазить, выискивать информацию. Так получился рабочий вариант. После этого перезапустил logstash, подождал немного, пока появятся новые логи на виндовом сервере, зашел в kibana и добавил новые индексы. Напомню, что делается это в разделе Management -> Kibana -> Index Patterns.

Можно идти в раздел Discover и просматривать логи с Windows серверов.
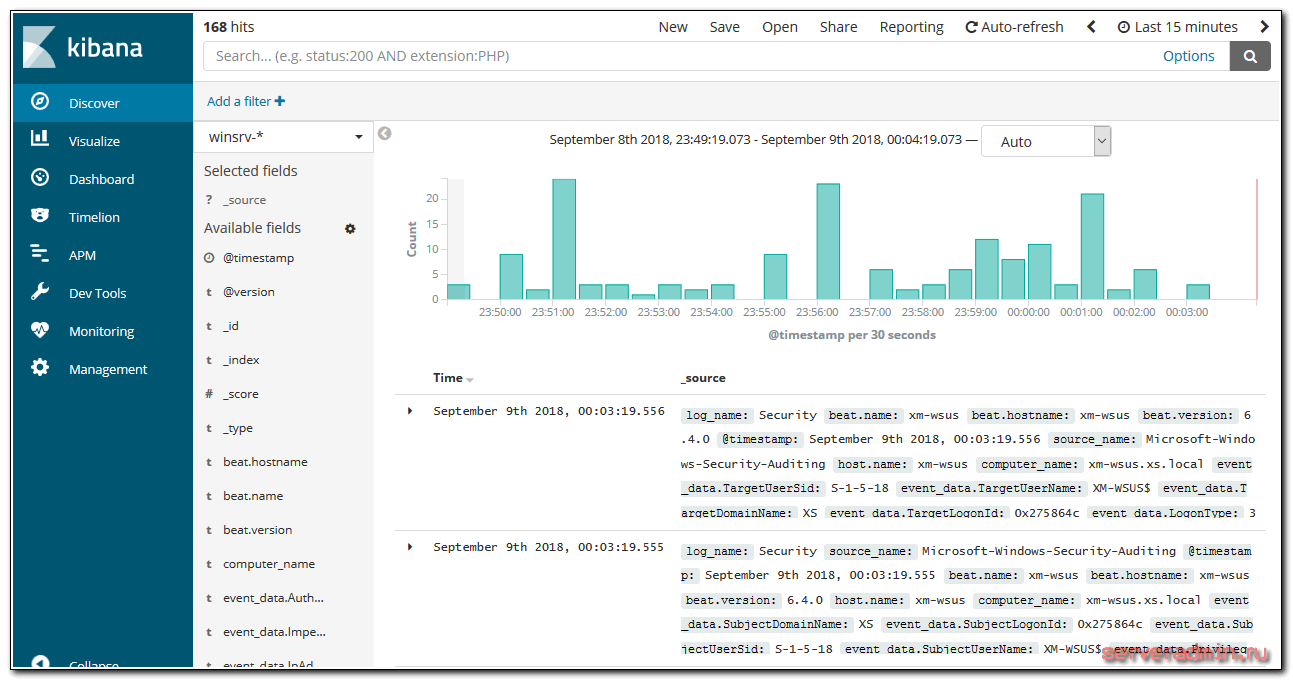
У меня без проблем все заработало на серверах с русской версией Windows. Все логи, тексты в сообщениях на русском языке нормально обрабатываются и отображаются. Проблем не возникло нигде.
На этом я закончил настройку стека Elasticsearch, Logstash, Kibana, Filebeat и Winlogbeat. Описал основной функционал по сбору логов. Дальше с ними уже можно работать по ситуации — строить графики, отчеты, собирать дашборды и т.д. Возможно, опишу это отдельно.
Настройка Kibana
Файл с настройками Кибана располагается по пути — /etc/kibana/kibana.yml. На начальном этапе можно вообще ничего не трогать и оставить все как есть. По-умолчанию kibana слушает только localhost и не позволяет подключаться удаленно. Это нормальная ситуация, если у вас будет на этом же сервере установлен nginx в качестве reverse proxy, который будет принимать подключения и проксировать их в кибана. Так и нужно делать в продакшене, когда системой будут пользоваться разные люди из разных мест. С помощью nginx можно будет разграничивать доступ, использовать сертификат, настраивать нормальное доменное имя и т.д.
Если же у вас это тестовая установка, то можно обойтись без nginx. Для этого надо разрешить Кибана слушать внешний интерфейс и принимать подключения. Измените параметр server.host, указав ip адрес сервера, например вот так:
Если хотите, чтобы она слушала все интерфейсы, укажите в качестве адреса 0.0.0.0. После этого Kibana надо перезапустить:
Теперь можно зайти в веб интерфейс по адресу http://10.1.4.114:5601.

Можно продолжать настройку и тестирование, а когда все будет закончено, запустить nginx и настроить проксирование. Я настройку nginx оставлю на самый конец. В процессе настройки буду подключаться напрямую к Kibana.
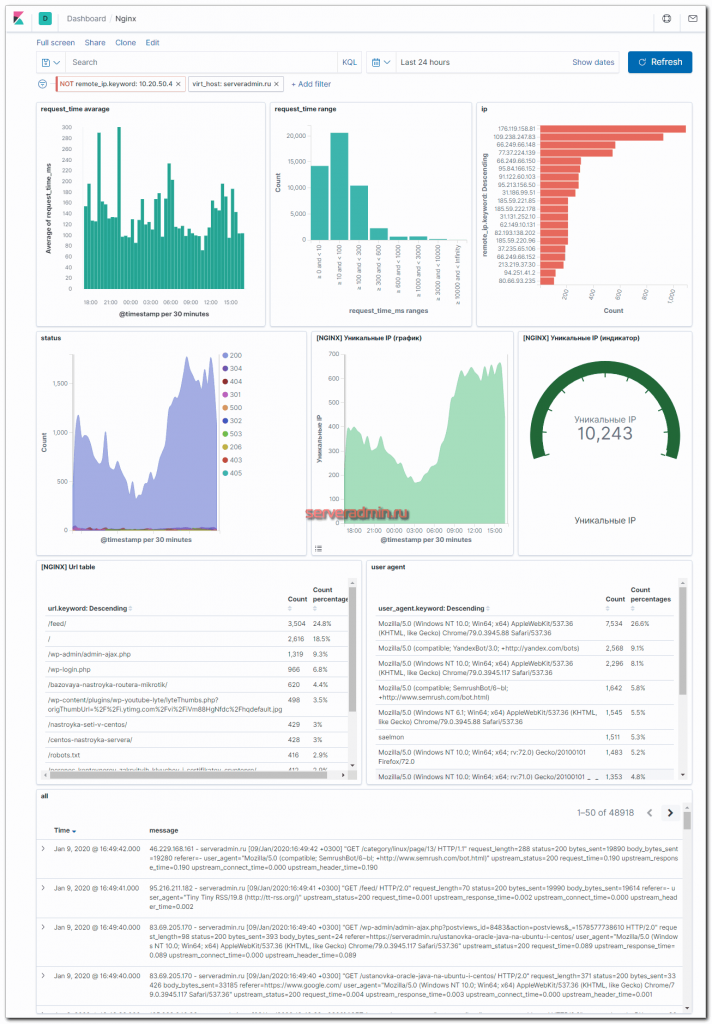
Настройка Dashboard для nginx
Я настроил вот такой дашборд в Kibana для логов Nginx (кликабельно, большая картинка, откройте в отдельной вкладке, чтобы рассмотреть).

Здесь представлена следующая информация:
- Geoip карта
- Распределение запросов по странам.
- Список самых популярных урлов.
- Список самых активных IP.
- Распределение запросов по типам ответов.
- Траффик.
- Непосредственно логи nginx в чистом виде.
С таким дашбордом очень удобно расследовать инциденты и просто смотреть статистику. Выбираем, к примеру, код ошибки и смотрим всю информацию по нему. Сразу подсвечиваются ip, которые спамят запросы. По ним тут же можно получить всю информацию — откуда они и по каким урлам спамят. И так далее. В общем, очень удобно. Я уже не представляю большой веб проект без такого дашборда. Раньше анализ логов для меня был гораздо сложнее. И как я раньше админил без такого инструмента 🙂 Век живи — век учись.
Заключение
Я постарался рассказать подробно и понятно о полной настройке ELK Stack. Информацию в основном почерпнул в официальной документации. Мне не попалось более ли менее подробных статей ни в рунете, ни в буржунете, хотя искал я основательно. Вроде бы такой популярный и эффективный инструмент, но статей больше чем просто дефолтная установка я почти не видел. Буквально одна на хабре попалась с какой-то более ли менее кастомизацией.
Какие-то проверенные моменты я не стал описывать в статье, так как посчитал их неудобными и не стал использовать сам. Например, если отказаться от logstash и отправлять данные с beats напрямую в elasticsearch, то на первый взгляд все становится проще. Штатные модули beats сами парсят вывод, устанавливают готовые визуализации и дашборды в Kibana. Вам остается только зайти и любоваться красотой 🙂 Но на деле все выходит не так красиво, как хотелось бы. Кастомизация конфигурации усложняется. Изменение полей в логах приводит к более сложным настройкам по вводу этих изменений в систему. Все настройки поступающей информации переносятся на каждый beats, изменяются в конфигах отдельных агентов. Это неудобно.
В то же время, при использовании logstash, вы просто отправляете данные со всех beats на него и уже в одном месте всем управляете, распределяете индексы, меняете поля и т.д. Все настройки перемещаются в одно место. Это более удобный подход. Плюс, при большой нагрузке вы можете вынести logstash на отдельную машину.
Я не рассмотрел в своей статье такие моменты как создание визуализаций и дашбордов в Кибана. Возможно, сделаю это отдельно, так как материал уже и так получился объемный, я устал писать эту статью 🙂 Надо еще подумать над подачей, много картинок надо, чтобы было понятно. Там все не очень наглядно, так что надо внимательно разбираться.
Так же я не рассмотрел такой момент. Logstash может принимать данные напрямую через syslog. Вы можете, к примеру, в nginx настроить отправку логов в syslog, минуя файлы и beats. Это может быть более удобно, чем описанная мной схема. Особенно это актуально для сбора логов с различных сетевых устройств, на которые невозможно поставить агента. Syslog поток так же можно парсить на ходу с помощью grok. Отдельно надо рассмотреть автоочистку старых индексов в elasticsearch.
Подводя итог скажу, что с этой системой хранения логов нужно очень вдумчиво и внимательно разбираться. С наскока ее не осилить. Чтобы было удобно пользоваться, нужно много всего настроить. Я описал только немного кастомизированный сбор данных, их визуализация — отдельный разговор. Сам я в настоящее время изучаю систему, поэтому буду рад любым советам, замечаниям, интересным ссылкам и всему, что поможет освоить тему.
Все статьи раздела elk stack — https://serveradmin.ru/category/elk-stack/.