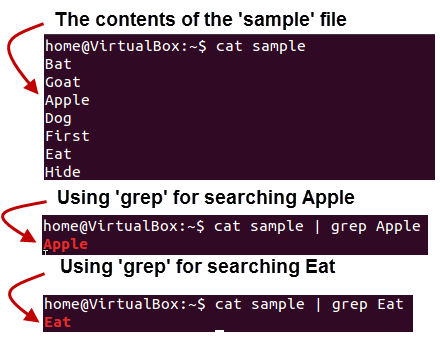
Регулярные выражения в python от простого к сложному. подробности, примеры, картинки, упражнения
Содержание:
Введение в регулярные выражения
Регулярные выражения (RegExp) — это очень эффективный способ работы со строками.
Составив регулярное выражение с помощью специального синтаксиса вы можете:
- искать текст в строке
- заменять подстроки в строке
- извлекать информацию из строки
Почти во всех языках программирования есть регулярные выражения. Есть небольшие различия в реализации, но общие концепции применяются практически везде.
Регулярные выражения относятся к 1950-м годам, когда они были формализованы как концептуальный шаблон поиска для алгоритмов обработки строк.
Регулярные выражения реализованные в UNIX, таких как grep, sed и популярных текстовых редакторах, начали набирать популярность и были добавлены в язык программирования Perl, а позже и в множество других языков.
JavaScript, наряду с Perl, это один из языков программирования в котором поддержка регулярных выражений встроена непосредственно в язык.
Regular Expression Patterns
Brackets are used to find a range of characters:
| Expression | Description | Try it |
|---|---|---|
| Find any of the characters between the brackets | Try it » | |
| Find any of the digits between the brackets | Try it » | |
| (x|y) | Find any of the alternatives separated with | | Try it » |
Metacharacters are characters with a special meaning:
| Metacharacter | Description | Try it |
|---|---|---|
| \d | Find a digit | Try it » |
| \s | Find a whitespace character | Try it » |
| \b | Find a match at the beginning of a word like this: \bWORD, or at the end of a word like this: WORD\b |
Try it » Try it » |
| \uxxxx | Find the Unicode character specified by the hexadecimal number xxxx | Try it » |
Quantifiers define quantities:
| Quantifier | Description | Try it |
|---|---|---|
| n+ | Matches any string that contains at least one n | Try it » |
| n* | Matches any string that contains zero or more occurrences of n | Try it » |
| n? | Matches any string that contains zero or one occurrences of n | Try it » |
str.replace(str|regexp, str|func)
This is a generic method for searching and replacing, one of most useful ones. The swiss army knife for searching and replacing.
We can use it without regexps, to search and replace a substring:
There’s a pitfall though.
When the first argument of is a string, it only replaces the first match.
You can see that in the example above: only the first is replaced by .
To find all hyphens, we need to use not the string , but a regexp , with the obligatory flag:
The second argument is a replacement string. We can use special character in it:
| Symbols | Action in the replacement string |
|---|---|
| inserts the whole match | |
| inserts a part of the string before the match | |
| inserts a part of the string after the match | |
| if is a 1-2 digit number, inserts the contents of n-th capturing group, for details see Capturing groups | |
| inserts the contents of the parentheses with the given , for details see Capturing groups | |
| inserts character |
For instance:
For situations that require “smart” replacements, the second argument can be a function.
It will be called for each match, and the returned value will be inserted as a replacement.
The function is called with arguments :
- – the match,
- – contents of capturing groups (if there are any),
- – position of the match,
- – the source string,
- – an object with named groups.
If there are no parentheses in the regexp, then there are only 3 arguments: .
For example, let’s uppercase all matches:
Replace each match by its position in the string:
In the example below there are two parentheses, so the replacement function is called with 5 arguments: the first is the full match, then 2 parentheses, and after it (not used in the example) the match position and the source string:
If there are many groups, it’s convenient to use rest parameters to access them:
Or, if we’re using named groups, then object with them is always the last, so we can obtain it like this:
Using a function gives us the ultimate replacement power, because it gets all the information about the match, has access to outer variables and can do everything.
JS Tutorial
JS HOMEJS IntroductionJS Where ToJS OutputJS StatementsJS SyntaxJS CommentsJS VariablesJS OperatorsJS ArithmeticJS AssignmentJS Data TypesJS FunctionsJS ObjectsJS EventsJS StringsJS String MethodsJS NumbersJS Number MethodsJS ArraysJS Array MethodsJS Array SortJS Array IterationJS DatesJS Date FormatsJS Date Get MethodsJS Date Set MethodsJS MathJS RandomJS BooleansJS ComparisonsJS ConditionsJS SwitchJS Loop ForJS Loop WhileJS BreakJS Type ConversionJS BitwiseJS RegExpJS ErrorsJS ScopeJS HoistingJS Strict ModeJS this KeywordJS LetJS ConstJS Arrow FunctionJS DebuggingJS Style GuideJS Best PracticesJS MistakesJS PerformanceJS Reserved WordsJS VersionsJS Version ES5JS Version ES6JS JSON
Применение регулярных выражений
Рассмотрим случаи, в которых используются регулярные выражения:
Поиск конкретных элементов в большом наборе текста. Например, вы можете выделить только адреса электронной почты из большого количества связанного (или несвязанного) текста.
Заменить одни символы на другие. Например, вы можете очистить плохо отформатированные файлы с HTML разметкой, заменив все теги, написанные в верхнем регистре, эквивалентами в нижнем регистре, используя текстовой редактор.
Проверка ввода. Например, вы можете проверить, соответствует ли пароль заданным критериям, таким как сочетание прописных и строчных букв, наличие цифр, знаков препинания и т.д.
Координация действий. Например, вы можете обрабатывать определённые файлы в каталоге только в том случае, если они удовлетворяют заданным критериям, описанным в командной строке.
И это не весь список применений регулярных выражений.
Давайте рассмотрим один простой пример. Следующее регулярное выражение выделит каждый экземпляр символа , за которым следуют либо символ , либо символ :
Да, это не что-то сверхъестественное или мегаполезное. Но, по мере того, как мы будем углубляться в regex, примеры станут более практичными.
regexp.exec(str)
The method method returns a match for in the string . Unlike previous methods, it’s called on a regexp, not on a string.
It behaves differently depending on whether the regexp has flag .
If there’s no , then returns the first match exactly as . This behavior doesn’t bring anything new.
But if there’s flag , then:
- A call to returns the first match and saves the position immediately after it in the property .
- The next such call starts the search from position , returns the next match and saves the position after it in .
- …And so on.
- If there are no matches, returns and resets to .
So, repeated calls return all matches one after another, using property to keep track of the current search position.
In the past, before the method was added to JavaScript, calls of were used in the loop to get all matches with groups:
This works now as well, although for newer browsers is usually more convenient.
We can use to search from a given position by manually setting .
For instance:
If the regexp has flag , then the search will be performed exactly at the position , not any further.
Let’s replace flag with in the example above. There will be no matches, as there’s no word at position :
That’s convenient for situations when we need to “read” something from the string by a regexp at the exact position, not somewhere further.
Metacharacters
Metacharacters are characters with a special meaning:
| Metacharacter | Description |
|---|---|
| . | Find a single character, except newline or line terminator |
| \w | Find a word character |
| \W | Find a non-word character |
| \d | Find a digit |
| \D | Find a non-digit character |
| \s | Find a whitespace character |
| \S | Find a non-whitespace character |
| \b | Find a match at the beginning/end of a word, beginning like this: \bHI, end like this: HI\b |
| \B | Find a match, but not at the beginning/end of a word |
| \0 | Find a NULL character |
| \n | Find a new line character |
| \f | Find a form feed character |
| \r | Find a carriage return character |
| \t | Find a tab character |
| \v | Find a vertical tab character |
| \xxx | Find the character specified by an octal number xxx |
| \xdd | Find the character specified by a hexadecimal number dd |
| \udddd | Find the Unicode character specified by a hexadecimal number dddd |
Сравнение с другими решениями
- matches.js — схожий функционал, близкая производительность, но шаблоны задаются строкой — следовательно ни тебе подсветки, ни вынесения общих частей в переменные
- идейный наследник sparkler — судя по всему имеет схожий функционал, но для синтаксиса использует макросы sweet.js, т.е. код придется дополнительно компилировать. В целом проблемы те же, хотя и выглядят шаблоны симпатичнее
- pun.js — синтаксис похож (только в шаблонах вместо @a предлагается писать $(‘a’)), однако возможностей меньше (например не поддерживаются массивы переменной длины) и производительность ниже — видимо они не выполняют компиляцию.
тут
Опережающая проверка
Синтаксис опережающей проверки: .
Он означает: найди при условии, что за ним следует . Вместо и здесь может быть любой шаблон.
Для целого числа, за которым идёт знак , шаблон регулярного выражения будет :
Обратим внимание, что проверка – это именно проверка, содержимое скобок не включается в результат. При поиске движок регулярных выражений, найдя , проверяет есть ли после него
Если это не так, то игнорирует совпадение и продолжает поиск дальше
При поиске движок регулярных выражений, найдя , проверяет есть ли после него . Если это не так, то игнорирует совпадение и продолжает поиск дальше.
Возможны и более сложные проверки, например означает:
- Найти .
- Проверить, идёт ли сразу после (если нет – не подходит).
- Проверить, идёт ли сразу после (если нет – не подходит).
- Если обе проверки прошли – совпадение найдено.
То есть, этот шаблон означает, что мы ищем при условии, что за ним идёт и и .
Такое возможно только при условии, что шаблоны и не являются взаимно исключающими.
Например, ищет при условии, что за ним идёт пробел, и где-то впереди есть :
В нашей строке это как раз число .
Советы
Старайтесь составлять простые регулярные выражения, чтобы другим пользователям было легче интерпретировать и изменять их.
Используйте обратную косую черту (\) для обозначения метасимволов регулярных выражений, которые нужно интерпретировать буквально. Например, если вы используете точку в качестве десятичного разделителя в IP-адресе, исключите ее с помощью обратной косой черты (\.), чтобы она не читалась как подстановочный знак.
Регулярные выражения не обязательно должны содержать метасимволы. Например, вы можете создать сегмент для всех данных из Индии со следующими условиями фильтрации: Страна соответствует регулярному выражению Индия.
Регулярные выражения по умолчанию имеют максимально возможный охват. Если явные ограничения не заданы, то будет найдена указанная последовательность символов в окружении любых смежных с ними. Например, регулярному выражению site соответствуют слова mysite, yoursite, theirsite, parasite (то есть любые строки, где содержится site). Если вы ищете конкретную строку, задайте регулярное выражение с соответствующими ограничениями. Чтобы найти именно слово site, обозначьте, что оно должно стоять одновременно в начале и конце строки: ^site$.
Захват групп
До сих пор мы видели, как тестировать строки и проверять, содержат ли они определенный шаблон.
Крутая возможность регулярных выражений заключается в том, что можно захватывать определённые части строки и складывать их в массив.
Вы можете делать это с помощью групп, а точнее с помощью захвата групп.
По умолчанию, группы итак захватываются. Теперь вместо использования , который просто возвращает логическое значение, мы будем использовать один из следующих методов:
Они абсолютно одинаковые и оба возвращают массив с проверяемой строкой в качестве первого элемента, а в остальных элементах совпадения для каждой найденной группы.
Если совпадений не найдено, то он возвращает .
Когда группа совпадает несколько раз, то только последнее найденное значение будет добавлено в возвращаемый массив.
Опциональные группы
Захват групп можно сделать опциональным с помощью . Если ничего не будет найдено, то в возвращаемый массив будет добавлен элемент :
Ссылка на найденную группу
Каждой найденной группе присваивается число. ссылается на первый элемент, на второй, и так далее. Это полезно, когда мы будет говорить о замене части строки.
Заключение
тут
- Разбиение массивов на «голову» и «хвост» полезно для рекурсивных алгоритмов, но без оптимизации хвостовой рекурсии могут возникнуть проблемы с производительностью и переполнением стека на больших объемах.Решение: пока не придумал
- В шаблонах не получится использовать функции — вернее, использовать-то можно, однако вызовутся они только один раз при компиляции шаблона.Решение: использовать guards
- Из-за этого подмены контекста не получится привязать функции-действия к вашему контексту. С другой стороны, если уж мы пишем в функциональном стиле, то вызовы методов нам вроде бы и не нужны.Решение: по старинке, self = this
- По той же причине скорее всего не получится использовать arrow-functions из ecmascript 6 — они намертво привязывают контекст так, что даже вызовы через call/apply на них не влияют.Решение: пока не придумал