Elastic
Содержание:
Version Matrix
| Elasticsearch Version | Elasticsearch-PHP Branch |
|---|---|
| >= 7.x | 7.x |
| >= 6.6, < 7.0 | 6.7.x |
| >= 6.0, < 6.6 | 6.5.x |
| >= 5.0, < 6.0 | 5.0 |
| >= 2.0, < 5.0 | 1.0 or 2.0 |
| >= 1.0, < 2.0 | 1.0 or 2.0 |
| <= 0.90.x | 0.4 |
- If you are using Elasticsearch 7.x you can use use Elasticsearch-PHP 7.x branch
- If you are using Elasticsearch 6.6 to 6.7, use Elasticsearch-PHP 6.7.x branch.
- If you are using Elasticsearch 6.0 to 6.5, use Elasticsearch-PHP 6.5.x branch.
- If you are using Elasticsearch 5.x, use Elasticsearch-PHP 5.0 branch.
- If you are using Elasticsearch 1.x or 2.x, prefer using the Elasticsearch-PHP 2.0 branch. The 1.0 branch is compatible however.
- If you are using a version older than 1.0, you must install the Elasticsearch-PHP branch. Since ES 0.90.x and below is now EOL, the corresponding branch will not receive any more development or bugfixes. Please upgrade.
- You should never use Elasticsearch-PHP Master branch, as it tracks Elasticsearch master and may contain incomplete features or breaks in backwards compatibility. Only use ES-PHP master if you are developing against ES master for some reason.
Логирование ошибок
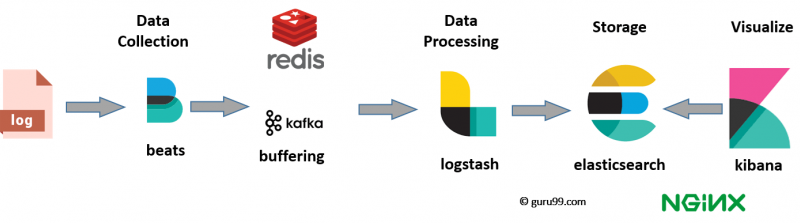
Исторически сложилось, что в нашей компании для сбора и просмотра логов используется стэк технологий Elasticsearch + Logstash + Kibana, сокращённо ELK. Elasticsearch — NoSQL-хранилище документов, с возможностью полнотекстового поиска. Logstash настроен на приём логов по TCP/UDP-протоколам, читает сообщения из Redis и сохраняет в Elasticsearch. Kibana предоставляет визуальный интерфейс для поиска и отображения собранных данных.
Сообщения об ошибках отправляем во время работы приложения по протоколу UDP в формате Graylog Extended Log Format, или сокращенно GELF. Формат хорош тем, что сообщения могут быть сжаты популярными алгоритмами и разделены на части, тем самым снижая объем передаваемого трафика из нашего приложения в Logstash. Протокол UDP пусть и не гарантирует доставку сообщений, но накладывает минимум накладных расходов на время ответа, поэтому такой вариант нас устраивает. В приложении используем библиотеку gelf-php, которая предоставляет возможности по отправке логов в разных форматах и протоколах. Рекомендую использовать её в своих PHP-приложениях.
Вывод — если ваше приложение работает с внешними пользователями и вам нужно искать ответы на возникающие вопросы техподдержки, смело добавляйте информацию, которая поможет идентифицировать клиента и его действия.
Пример нашего сообщения:
Quick start
First of all, require the client and initialize it:
const { Client } = require('@elastic/elasticsearch')
const client = new Client({ node: 'http://localhost:9200' })
You can use both the callback-style API and the promise-style API, both behave the same way.
// promise API
const result = await client.search({
index: 'my-index',
body: {
query: {
match: { hello: 'world' }
}
}
})
// callback API
client.search({
index: 'my-index',
body: {
query: {
match: { hello: 'world' }
}
}
}, (err, result) => {
if (err) console.log(err)
})
The returned value of every API call is formed as follows:
{
body: object | boolean
statusCode: number
headers: object
warnings: string
meta: object
}
Let’s see a complete example!
'use strict'
const { Client } = require('@elastic/elasticsearch')
const client = new Client({ node: 'http://localhost:9200' })
async function run () {
// Let's start by indexing some data
await client.index({
index: 'game-of-thrones',
// type: '_doc', // uncomment this line if you are using Elasticsearch ≤ 6
body: {
character: 'Ned Stark',
quote: 'Winter is coming.'
}
})
await client.index({
index: 'game-of-thrones',
// type: '_doc', // uncomment this line if you are using Elasticsearch ≤ 6
body: {
character: 'Daenerys Targaryen',
quote: 'I am the blood of the dragon.'
}
})
await client.index({
index: 'game-of-thrones',
// type: '_doc', // uncomment this line if you are using Elasticsearch ≤ 6
body: {
character: 'Tyrion Lannister',
quote: 'A mind needs books like a sword needs a whetstone.'
}
})
// here we are forcing an index refresh, otherwise we will not
// get any result in the consequent search
await client.indices.refresh({ index: 'game-of-thrones' })
// Let's search!
const { body } = await client.search({
index: 'game-of-thrones',
// type: '_doc', // uncomment this line if you are using Elasticsearch ≤ 6
body: {
query: {
match: { quote: 'winter' }
}
}
})
console.log(body.hits.hits)
}
run().catch(console.log)
Split brain
Самая пугающая и известная проблема с эластиком — это split brain, когда из-за проблем со связностью нод по сети, или если нода не отвечала долго (потому что застряла в GC например), в кластере может появиться вторая мастер-нода.
В этом случае получается как бы две версии индекса, какие-то документы попадают на индексацию в одну часть кластера, другие — в другую. Неконсистентность будет проявляться при поиске — на один и тот же запрос будут выдаваться разные результаты. Восстановление индекса в таком случае будет сложной задачей, скорее всего, потребуется либо полная переиндексация, либо восстановление из бэкапа и с последующей доливкой изменений до текущего момента.
В ES есть механизм защиты от сплит-брейна, самая важная настройка — , но по-умолчанию discovery.zen.minimum_master_nodes: 1, т.е. никакой защиты нет.
Мы воспроизводили это на тестовом кластере ElasticSearch и по результатам сделали два авто-триггера: один сработает, если увидит более одной мастер ноды в кластере, второй предупредит, если значение параметра discovery.zen.minimum_master_nodes меньше, чем рекомендованное — кворум (N/2+1) от текущего размера кластера. Это нужно именно мониторить, потому что вы можете решить добавить нод и забыть подправить minimum_master_nodes.
Check Cluster State
If everything was configured correctly, your Elasticsearch cluster should be up and running. Before moving on, let’s verify that it’s working properly. You can do so by querying Elasticsearch from any of the Elasticsearch nodes.
From any of your Elasticsearch servers, run this command to print the state of the cluster:
You should see output that indicates that a cluster named “production” is running. It should also indicate that all of the nodes you configured are members:
If you see output that is similar to this, your Elasticsearch cluster is running! If any of your nodes are missing, review the configuration for the node(s) in question before moving on.
Next, we’ll go over some configuration settings that you should consider for your Elasticsearch cluster.
Уровень ноды
Метрики по памяти процесса elastic
- fs.total.total_in_bytes, fs.total.free_in_bytes, fs.total.available_in_bytes — метрики по дисковому пространству, доступному каждой ноде. Если значение приближается к watermark.low — аларм.
- http.current_open, http.total_opened — количество открытых http-подключений к нодам — на момент опроса и общее, накопительный счетчик с момента запуска ноды, из которого легко вычисляется rps.
http.total_rpsthrottle_time_in_millis
- indexing.throttle_time_in_millis — время, которое кластер потратил на ожидание при индексации новых данных. Имеет смысл только на нодах, принимающих данные.
- store.throttle_time_in_millis — время, затраченное кластером, на ожидание при записи новых данных на диск. Аналогично метрике выше — имеет смысл только на нодах куда поступают новые данные.
- recovery.throttle_time_in_millis — включает в себя не только время ожидания при восстановлении шард (например, после сбоев), но и время ожидания при перемещении шард с ноды на ноду (например, при ребалансе или миграции шард между зонами hot/warm). Метрика особо актуальна на нодах, где данные хранятся долго.
- merges.total_throttled_time_in_millis — общее время, затраченное кластером на ожидание объединения сегментов на данной ноде. Накопительный счётчик.
search
- search.query_total — всего запросов на поиск, выполненных на ноде с момента её перезагрузки. Из этой метрики вычисляем среднее количество запросов в секунду.
- search.query_time_in_millis — время в миллисекундах, затраченное на все операции поиска с момента перезагрузки ноды.
thread_poolдокументации
- thread_pool.bulk.completed — счётчик, хранящий количество выполненных операций пакетной (bulk) записи данных в кластер с момента перезагрузки ноды. Из него вычисляется rps по записи.
- thread_pool.bulk.active — количество задач в очереди на добавление данных на момент опроса, показывает загруженность кластера по записи на текущий момент времени. Если этот параметр выходит за установленный размер очереди, начинает расти следующий счётчик.
- thread_pool.bulk.rejected — счётчик количества отказов по запросам на добавление данных. Имеет смысл только на нодах осуществляющих приём данных. Суммируется накопительным итогом, раздельно по нодам, обнуляется в момент полной перезагрузки ноды.
Извлечение документа по его id:
В ответе появились новые ключи: и . Вообще, все ключи, начинающиеся с относятся к служебным.
Ключ показывает версию документа. Он нужен для работы механизма оптимистических блокировок. Например, мы хотим изменить документ, имеющий версию 1. Мы отправляем измененный документ и указываем, что это правка документа с версией 1. Если кто-то другой тоже редактировал документ с версией 1 и отправил изменения раньше нас, то ES не примет наши изменения, т.к. он хранит документ с версией 2.
Ключ содержит тот документ, который мы индексировали. ES не использует это значение для поисковых операций, т.к. для поиска используются индексы. Для экономии места ES хранит сжатый исходный документ. Если нам нужен только id, а не весь исходный документ, то можно отключить хранение исходника.
Если нам не нужна дополнительная информация, можно получить только содержимое _source:
Также можно выбрать только определенные поля:
Давайте проиндексируем еще несколько постов и выполним более сложные запросы.
Индексирование
Задача сервиса — непрерывно извлекать новые объекты из очереди и индексировать соответствующие документы. В этом процессе мы используем не объектную модель NEST, а низкоуровневую библиотеку ElasticsearchNet. Она предоставляет интерфейс взаимодействия с базой данных через JSON. Объекты формируем динамически обходом в глубину иерархической структуры документа. Для этого используется всем известная библиотека NewtonsoftJson.
Индексирование реализовано многопоточно с параллельной обработкой каждого документа. Процесс формирования JSON занимает на порядок больше времени, чем его индексирование. Поэтому используется API для индексирования отдельных документов, а не Bulk API, при котором за один вызов в ES загружается массив документов. В таком случае индексирование бы происходило со скоростью формирования JSON для самого большого документа.
Индексирование файлов
Файлы индексируются вместе с остальными данными как часть JSON-объекта. Всё, что для это нужно — преобразовать поток байтов в Base64 строку. Это делается средствами стандартной библиотеки. Кроме того, необходимо, чтобы файлы попали под определение процессора. Иначе магии не произойдет, и они так и останутся обычной Base64 строкой. Чтобы при индексировании использовать конвейер, изменим вызов метода.
Системные метрики
В дополнении к внутренним метрикам эластика, стоит смотреть на него сверху, как на процесс в операционной системе. Сколько он потребляет процессорного времени, сколько памяти, сколько создает нагрузки на диск.
Когда мы затевали обновление ES с версии 1.7.5, то решили обновиться сразу на 2.4 (последнюю, пятёрку, пока побаиваемся). Мажорное обновление elastic по стандартной процедуре нам делать как-то стрёмно, мы обычно поднимаем второй кластер и делаем синхронную копию через наш код — он умеет индексировать в несколько кластеров сразу.
При включении нового кластера в индексацию, обнаружилось, что новый ES пишет на диск ~350 раз в секунду, в то время как старый всего ~25:
es101 — это нода из старого кластера, а es106 — из нового. Плюс на новые ноды не стали ставить SSD (посчитали, что всё влезет в память), поэтому такое io уронило производительность очень сильно.
Пошли перечитывать все новинки версии 2 эластика и нашли . Он по умолчанию стал request, при таком значении translog синкается на диск после каждого запроса на индексацию. Поменяли на async со стандартныйм sync_interval в 5 секунд и стало почти как раньше.
Помимо системных метрик для ES полезно смотреть за метриками JVM — gc, memory пулы и прочее. Наш агент автоматически подцепит всё это через jmx, и так же автоматически появятся графики.
Getting Started
First of all, DON’T PANIC. It will take 5 minutes to get the gist of what Elasticsearch is all about.
Indexing
First, index some sample JSON documents. The first request automatically creates
the index.
curl -X POST 'http://localhost:9200/my-index-000001/_doc?pretty' -H 'Content-Type: application/json' -d '
{
"@timestamp": "2099-11-15T13:12:00",
"message": "GET /search HTTP/1.1 200 1070000",
"user": {
"id": "kimchy"
}
}'
curl -X POST 'http://localhost:9200/my-index-000001/_doc?pretty' -H 'Content-Type: application/json' -d '
{
"@timestamp": "2099-11-15T14:12:12",
"message": "GET /search HTTP/1.1 200 1070000",
"user": {
"id": "elkbee"
}
}'
curl -X POST 'http://localhost:9200/my-index-000001/_doc?pretty' -H 'Content-Type: application/json' -d '
{
"@timestamp": "2099-11-15T01:46:38",
"message": "GET /search HTTP/1.1 200 1070000",
"user": {
"id": "elkbee"
}
}'
Search
Next, use a search request to find any documents with a of .
curl -X GET 'http://localhost:9200/my-index-000001/_search?q=user.id:kimchy&pretty=true'
curl -X GET 'http://localhost:9200/my-index-000001/_search?pretty=true' -H 'Content-Type: application/json' -d '
{
"query" : {
"match" : { "user.id": "kimchy" }
}
}'
You can also retrieve all documents in .
curl -X GET 'http://localhost:9200/my-index-000001/_search?pretty=true' -H 'Content-Type: application/json' -d '
{
"query" : {
"match_all" : {}
}
}'
During indexing, Elasticsearch automatically mapped the field as a
date. This lets you run a range search.
curl -X GET 'http://localhost:9200/my-index-000001/_search?pretty=true' -H 'Content-Type: application/json' -d '
{
"query" : {
"range" : {
"@timestamp": {
"from": "2099-11-15T13:00:00",
"to": "2099-11-15T14:00:00"
}
}
}
}'
Multiple indices
Elasticsearch supports multiple indices. The previous examples used an index
called . You can create another index, , to
store additional data when reaches a certain age or size. You
can also use separate indices to store different types of data.
You can configure each index differently. The following request
creates with two primary shards rather than the default of
one. This may be helpful for larger indices.
curl -X PUT 'http://localhost:9200/my-index-000002?pretty' -H 'Content-Type: application/json' -d '
{
"settings" : {
"index.number_of_shards" : 2
}
}'
You can then add a document to .
curl -X POST 'http://localhost:9200/my-index-000002/_doc?pretty' -H 'Content-Type: application/json' -d '
{
"@timestamp": "2099-11-16T13:12:00",
"message": "GET /search HTTP/1.1 200 1070000",
"user": {
"id": "kimchy"
}
}'
You can search and perform other operations on multiple indices with a single
request. The following request searches and .
curl -X GET 'http://localhost:9200/my-index-000001,my-index-000002/_search?pretty=true' -H 'Content-Type: application/json' -d '
{
"query" : {
"match_all" : {}
}
}'
You can omit the index from the request path to search all indices.
curl -X GET 'http://localhost:9200/_search?pretty=true' -H 'Content-Type: application/json' -d '
{
"query" : {
"match_all" : {}
}
}'
Distributed, highly available
Let’s face it, things will fail….
Elasticsearch is a highly available and distributed search engine. Each index is broken down into shards, and each shard can have one or more replicas. By default, an index is created with 1 shard and 1 replica per shard (1/1). There are many topologies that can be used, including 1/10 (improve search performance), or 20/1 (improve indexing performance, with search executed in a map reduce fashion across shards).
In order to play with the distributed nature of Elasticsearch, simply bring more nodes up and shut down nodes. The system will continue to serve requests (make sure you use the correct http port) with the latest data indexed.
Building from source
In order to create a distribution, simply run the command in the cloned directory.
The distribution for each project will be created under the directory in that project.
See the TESTING for more information about running the Elasticsearch test suite.
Архитектура
В базе данных Elasticsearch таблицы называются индексами, а процесс загрузки документов — индексированием. Для индексирования данных из основного хранилища в Elasticsearch был написан специальный сервис. Он представляет собой Windows-службу, в дополнение к которой идет утилита администратора. В утилите устанавливаются необходимые настройки, создаются индексы и запускается загрузка документов в базу данных.
Однако, на этапе индексирования данных мы столкнулись с проблемой. Система динамична, и ежеминутно в документах происходят тысячи изменений. Сервис индексирования должен поддерживать данные Elasticsearch в состоянии, максимально близком к текущему положению дел. Поэтому в SQL базе данных появляется новая сущность — очередь документов для индексирования. Каждые N минут специальный job находит все документы, которые были изменены после предыдущего выполнения и добавляет их идентификаторы в очередь. Как следствие, сервис обновит в индексах только требующие того документы.
Технологический стек
Поисковый движок. Elasticsearch 5.5Плагины. analysis-morphology и ingest-attachmentСервис. Написан на C#. Библиотеки для взаимодействия с движком: NEST и ElasticsearchNET.Frontend. Angular 4
Поиск
Теперь необходимо определиться с механизмами поиска. Данные организованы в виде документов. Как мы привыкли осуществлять поиск по документу?
Типичным примером документа будет веб-страница. Если мы попытаемся поискать по всей странице в браузере, поиск будет осуществляться по всему содержащемуся тексту. И это удобно для большинства кейсов.
Примерно так же работают многие поисковые системы, поиск происходит по всему тексту проиндексированных страниц, а не по отдельным полям, тегам или заголовкам. Это называется полнотекстовым поиском.
Искать предстоит по огромному количеству документов и было бы разумно запомнить что в каком документе лежит. В реляционных СУБД мы привыкли оптимизировать подобный поиск индексами.
Что такое индекс на самом деле? Если не вдаваться в детали, индекс это сбалансированное дерево, то есть дерево, в котором длина путей(количество шагов межу узлами) не будет отличаться больше чем на один шаг.
Например если бы мы проиндексировали наш пост, то у нас бы получилось дерево, листьями которого, являлись бы используемые в нем слова. Простыми словами, мы будем знать заранее, какие слова находятся в документе и как их быстро в нем найти. Не смотря на такую удобную структуризацию данных, обход дерева звучит как не самое лучшее решение для максимально быстрого поиска.
А что если сделать все наоборот — собрать список всех используемых слов и узнать, в каких документах они встречаются. Да, индексация займет больше времени, но нас в первую очередь интересует именно скорость поиска, а не индексации.
Такой индекс называется обратным индексом и используется для полнотекстового поиска.
Документация индексов
Следующим шагом является хранение фактических данных или документов.
def store_record(elastic_object, index_name, record):
try:
outcome = elastic_object.index(index=index_name, doc_type='salads', body=record)
except Exception as ex:
print('Error in indexing data')
print(str(ex))
Запускаем и вот что мы увидим:
Error in indexing data TransportError(400, 'strict_dynamic_mapping_exception', 'mapping set to strict, dynamic introduction of within is not allowed')
Знаете, почему это происходит? Так как мы не добавляли в наш мэппинг компонентов, ES решил не разрешать нам хранить документ, не содержащий, по сути, ничего. Если вы не назначите компоненты мэппингу — произойдет повреждение данных. Теперь давайте немного подправим наш мэппинг и посмотрим, что произойдет:
"mappings": {
"salads": {
"dynamic": "strict",
"properties": {
"title": {
"type": "text"
},
"submitter": {
"type": "text"
},
"description": {
"type": "text"
},
"calories": {
"type": "integer"
},
"ingredients": {
"type": "nested",
"properties": {
"step": {"type": "text"}
}
},
}
}
}
Мы добавили ingredients типу nested, а затем назначили тип данных внутреннему полю. В нашем случае это text.
Вложенный тип данных (nested) позволяет установить тип вложенных объектов JSON. Запустите снова и взгляните на результат:
{
'_index': 'recipes',
'_type': 'salads',
'_id': 'OvL7s2MBaBpTDjqIPY4m',
'_version': 1,
'result': 'created',
'_shards': {
'total': 1,
'successful': 1,
'failed': 0
},
'_seq_no': 0,
'_primary_term': 1
}
_idElasticsearch Toolbox
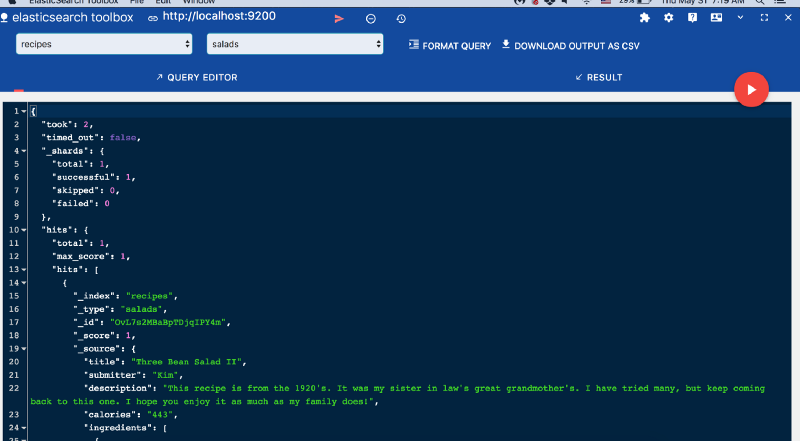
Прежде чем двигаться дальше, отправим строку в поле calories и посмотрим, как развернутся события. Вспомним тот факт, что мы присвоили ему тип integer. Учитывая это, при индексировании он выдаст следующую ошибку:
TransportError(400, ‘mapper_parsing_exception’, ‘failed to parse ’)
Итак, теперь вы знаете преимущества назначения мэппинга для ваших документов. Если вы этого не сделаете, все равно все будет работать, поскольку Elasticsearch назначит свой собственный мэппинг во время среды выполнения.
Quickstart
Index a document
In elasticsearch-php, almost everything is configured by associative arrays. The REST endpoint, document and optional parameters — everything is an associative array.
To index a document, we need to specify three pieces of information: index, id and a document body. This is done by
constructing an associative array of key:value pairs. The request body is itself an associative array with key:value pairs
corresponding to the data in your document:
$params = ]; $response = $client->index($params); print_r($response);
The response that you get back indicates the document was created in the index that you specified. The response is an
associative array containing a decoded version of the JSON that Elasticsearch returns:
Array
(
=> my_index
=> _doc
=> my_id
=> 1
=> created
=> Array
(
=> 1
=> 1
=>
)
=>
=> 1
)
Get a document
Let’s get the document that we just indexed. This will simply return the document:
$params = ; $response = $client->get($params); print_r($response);
The response contains some metadata (index, version, etc.) as well as a field, which is the original document
that you sent to Elasticsearch.
Array
(
=> my_index
=> _doc
=> my_id
=> 1
=>
=> 1
=> 1
=> Array
(
=> abc
)
)
If you want to retrieve the field directly, there is the method:
$params = ; $source = $client->getSource($params); print_r($source);
The response will be just the value:
Array
(
=> abc
)
Search for a document
Searching is a hallmark of Elasticsearch, so let’s perform a search. We are going to use the Match query as a demonstration:
$params =
]
]
];
$response = $client->search($params);
print_r($response);
The response is a little different from the previous responses. We see some metadata (, , etc.) and
an array named . This represents your search results. Inside of is another array named , which contains
individual search results:
Array
(
=> 33
=>
=> Array
(
=> 1
=> 1
=>
=>
)
=> Array
(
=> Array
(
=> 1
=> eq
)
=> 0.2876821
=> Array
(
[] => Array
(
=> my_index
=> _doc
=> my_id
=> 0.2876821
=> Array
(
=> abc
)
)
)
)
)
Delete a document
Alright, let’s go ahead and delete the document that we added previously:
$params = ; $response = $client->delete($params); print_r($response);
You’ll notice this is identical syntax to the syntax. The only difference is the operation: instead of
. The response will confirm the document was deleted:
Array
(
=> my_index
=> _doc
=> my_id
=> 2
=> deleted
=> Array
(
=> 1
=> 1
=>
)
=> 1
=> 1
)
Delete an index
Due to the dynamic nature of Elasticsearch, the first document we added automatically built an index with some default settings. Let’s delete that index because we want to specify our own settings later:
$deleteParams = ; $response = $client->indices()->delete($deleteParams); print_r($response);
The response:
Array
(
=> 1
)
Create an index
Now that we are starting fresh (no data or index), let’s add a new index with some custom settings:
$params =
]
];
$response = $client->indices()->create($params);
print_r($response);
Elasticsearch will now create that index with your chosen settings, and return an acknowledgement:
Array
(
=> 1
)
Unit Testing using Mock a Elastic Client
use GuzzleHttp\Ring\Client\MockHandler;
use Elasticsearch\ClientBuilder;
// The connection class requires 'body' to be a file stream handle
// Depending on what kind of request you do, you may need to set more values here
$handler = new MockHandler(,
'body' => fopen('somefile.json'),
'effective_url' => 'localhost'
]);
$builder = ClientBuilder::create();
$builder->setHosts();
$builder->setHandler($handler);
$client = $builder->build();
// Do a request and you'll get back the 'body' response above
Contributing
Never send PR to unless you want to contribute to the development version of the client ( represents the next major version).
Wrap up
That was just a crash-course overview of the client and its syntax. If you are familiar with Elasticsearch, you’ll notice that the methods are named just like REST endpoints.
You’ll also notice that the client is configured in a manner that facilitates easy discovery via the IDE. All core actions are available under the object (indexing, searching, getting, etc.). Index and cluster management are located under the and objects, respectively.
Кэши
Для обеспечения скорости выполнения запросов в эластике есть кэши:
- query_cache (раньше назывался filter_cache) — битсеты документов, которые матчатся на конкретный фильтр в запросе
- fielddata_cache — используется при аггрегациях
- request_cache — шард кэширует ответ на запрос целиком
Подробнее что кешируется, когда кешируется, когда инвалидируется, как тюнить, лучше читать в документации.
Наш мониторинговый агент снимет для каждого из этих кэшей: размер, хиты, миссы, эвикшены (вытестения).
Вот, например, был случай — эластики у нас упали по OutOfMemory. По логам разобраться сложно, но потом, когда уже подняли, заметили на графике резкий рост использования памяти fielddata кэшем:
Вообще-то мы не используем агрегации elasticsearch, мы вообще используем только самый базовый функционал. Нам нужно без скоринга найти все документы, в которых у заданных полей заданные значения. Почему же так выросло использование fielddata кэша?
Оказалось, что это был тоже контролируемый эксперимент 🙂 Вручную curl’ом дёргали тяжелые запросы на агрегацию, и от этого всё попадало. По идее от этого можно было защититься правильной настройкой лимитов памяти для fielddata. Но или они не сработали, или баги эластика (мы тогда сидели на старой версии 1.7).