Curl — это просто
Содержание:
- Создание POST запроса на определённый URL
- Как пользоваться curl?
- Web-протоколы
- Почему cURL?
- Множественный cURL
- Команда Curl для Работы с Файлами
- CONNECTION OPTIONS
- Обнаружение перенаправления в зависимости от браузера
- Отправка данных методом POST
- NAMES and PASSWORDS OPTIONS (Authentication)
- Команды Curl для HTTP
- HTTP-клиент на Python
- Загрузка файлов методом POST
Создание POST запроса на определённый URL
При формировании GET запроса передаваемые данные могут быть переданы на URL через “строку запроса”. Например, когда Вы делаете поиск в Google, критерий поиска располагаются в адресной строке нового URL:
http://www.google.com/search?q=ruseller
Для того чтобы сымитировать данный запрос, вам не нужно пользоваться средствами cURL. Если лень вас одолевает окончательно, воспользуйтесь функцией “file_get_contents()”, для того чтобы получить результат.
Но дело в том, что некоторые HTML-формы отправляют POST запросы. Данные этих форм транспортируются через тело HTTP запроса, а не как в предыдущем случае. Например, если вы заполнили форму на форуме и нажали на кнопку поиска, то скорее всего будет совершён POST запрос:
http://codeigniter.com/forums/do_search/
Мы можем написать PHP скрипт, который может сымитировать этот вид URL запроса. Сначала давайте создадим простой файл для принятия и отображения POST данных. Назовём его post_output.php:
print_r($_POST);
Затем мы создаем PHP скрипт, чтобы выполнить cURL запрос:
$url = "http://localhost/post_output.php";
$post_data = array (
"foo" => "bar",
"query" => "Nettuts",
"action" => "Submit"
);
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
// указываем, что у нас POST запрос
curl_setopt($ch, CURLOPT_POST, 1);
// добавляем переменные
curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data);
$output = curl_exec($ch);
curl_close($ch);
echo $output;
При запуске данного скрипта вы должны получить подобный результат:
Таким образом, POST запрос был отправлен скрипту post_output.php, который в свою очередь, вывел суперглобальный массив $_POST, содержание которого мы получили при помощи cURL.
Как пользоваться curl?
Мы рассмотрели все, что касается теории работы с утилитой curl, теперь пришло время перейти к практике, и рассмотреть примеры команды curl.
Загрузка файлов
Самая частая задача — это загрузка файлов linux. Скачать файл очень просто. Для этого достаточно передать утилите в параметрах имя файла или html страницы:
Но тут вас ждет одна неожиданность, все содержимое файла будет отправлено на стандартный вывод. Чтобы записать его в какой-либо файл используйте:
А если вы хотите, чтобы полученный файл назывался так же, как и файл на сервере, используйте опцию -O:
Если загрузка была неожиданно прервана, вы можете ее возобновить:
Если нужно, одной командой можно скачать несколько файлов:
Еще одна вещь, которая может быть полезной администратору — это загрузка файла, только если он был изменен:
Данная команда скачает файл, только если он был изменен после 21 декабря 2017.
Ограничение скорости
Вы можете ограничить скорость загрузки до необходимого предела, чтобы не перегружать сеть с помощью опции -Y:
Здесь нужно указать количество килобайт в секунду, которые можно загружать. Также вы можете разорвать соединение если скорости недостаточно, для этого используйте опцию -Y:
Передача файлов
Загрузка файлов, это достаточно просто, но утилита позволяет выполнять и другие действия, например, отправку файлов на ftp сервер. Для этого существует опция -T:
Или проверим отправку файла по HTTP, для этого существует специальный сервис:
В ответе утилита сообщит где вы можете найти загруженный файл.
Отправка данных POST
Вы можете отправлять не только файлы, но и любые данные методом POST. Напомню, что этот метод используется для отправки данных различных форм. Для отправки такого запроса используйте опцию -d. Для тестирования будем пользоваться тем же сервисом:
Если вас не устраивает такой вариант отправки, вы можете сделать вид, что отправили форму. Для этого есть опция -F:
Здесь мы передаем формой поле password, с типом обычный текст, точно так же вы можете передать несколько параметров.
Передача и прием куки
Куки или Cookie используются сайтами для хранения некой информации на стороне пользователя. Это может быть необходимо, например, для аутентификации. Вы можете принимать и передавать Cookie с помощью curl. Чтобы сохранить полученные Cookie в файл используйте опцию -c:
Затем можно отправить cookie curl обратно:
Передача и анализ заголовков
Не всегда нам обязательно нужно содержимое страницы. Иногда могут быть интересны только заголовки. Чтобы вывести только их есть опция -I:
А опция -H позволяет отправить нужный заголовок или несколько на сервер, например, можно передать заголовок If-Modified-Since чтобы страница возвращалась только если она была изменена:
Аутентификация curl
Если на сервере требуется аутентификация одного из распространенных типов, например, HTTP Basic или FTP, то curl очень просто может справиться с такой задачей. Для указания данных аутентификации просто укажите их через двоеточие в опции -u:
Точно так же будет выполняться аутентификация на серверах HTTP.
Использование прокси
Если вам нужно использовать прокси сервер для загрузки файлов, то это тоже очень просто. Достаточно задать адрес прокси сервера в опции -x:
Web-протоколы
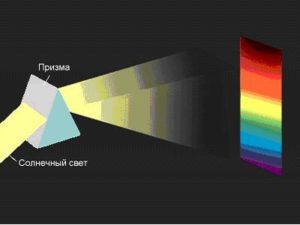
Эти Web-сервисы, как правило, построены поверх уровня сокетов стека сетевых протоколов (рисунок 1).
Уровень сокетов реализует API, который восходит к операционной системе Berkeley Software Distribution (BSD) и изолирует детали нижележащих протоколов транспортного и сетевого уровней.
Рисунок 1.
Стек сетевых протоколов и libcurl
Web-сервисы обеспечивают взаимодействие между протоколами клиента и сервера.
В контексте HTTP сервер – это оконечное устройство, а клиент – браузер в удаленной точке.
Для SMTP сервер – это почтовый шлюз или удаленный пользователь, а клиент – оконечное устройство.
В некоторых случаях взаимодействие протоколов происходит в два этапа (запрос и ответ), а в других для поддержания связи требуется гораздо больше трафика.
Такое взаимодействие может создать значительные трудности, которые преодолеваются с помощью API, таких как libcurl.
Почему cURL?
На самом деле, существует немало альтернативных способов выборки содержания веб-страницы. Во многих случаях, главным образом из-за лени, я использовал простые PHP функции вместо cURL:
$content = file_get_contents("http://www.nettuts.com");
// или
$lines = file("http://www.nettuts.com");
// или
readfile("http://www.nettuts.com");
Однако данные функции не имеют фактически никакой гибкости и содержат огромное количество недостатков в том, что касается обработки ошибок и т.д. Кроме того, существуют определенные задачи, которые вы просто не можете решить благодаря этим стандартным функциям: взаимодействие с cookie, аутентификация, отправка формы, загрузка файлов и т.д.
cURL — это мощная библиотека, которая поддерживает множество различных протоколов, опций и обеспечивает подробную информацию о URL запросах.
Множественный cURL
Одной из самых сильных сторон cURL является возможность создания «множественных» cURL обработчиков. Это позволяет вам открывать соединение к множеству URL одновременно и асинхронно.
В классическом варианте cURL запроса выполнение скрипта приостанавливается, и происходит ожидание завершения операции URL запроса, после чего работа скрипта может продолжиться. Если вы намереваетесь взаимодействовать с целым множеством URL, это приведёт к довольно-таки значительным затратам времени, поскольку в классическом варианте вы можете работать только с одним URL за один раз. Однако, мы можем исправить данную ситуацию, воспользовавшись специальными обработчиками.
Давайте рассмотрим пример кода, который я взял с php.net:
// создаём несколько cURL ресурсов
$ch1 = curl_init();
$ch2 = curl_init();
// указываем URL и другие параметры
curl_setopt($ch1, CURLOPT_URL, "http://lxr.php.net/");
curl_setopt($ch1, CURLOPT_HEADER, 0);
curl_setopt($ch2, CURLOPT_URL, "http://www.php.net/");
curl_setopt($ch2, CURLOPT_HEADER, 0);
//создаём множественный cURL обработчик
$mh = curl_multi_init();
//добавляем несколько обработчиков
curl_multi_add_handle($mh,$ch1);
curl_multi_add_handle($mh,$ch2);
$active = null;
//выполнение
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
while ($active && $mrc == CURLM_OK) {
if (curl_multi_select($mh) != -1) {
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
}
}
//закрытие
curl_multi_remove_handle($mh, $ch1);
curl_multi_remove_handle($mh, $ch2);
curl_multi_close($mh);
Идея состоит в том, что вы можете использовать множественные cURL обработчики. Используя простой цикл, вы можете отследить, какие запросы ещё не выполнились.
В этом примере есть два основных цикла. Первый цикл do-while вызывает функцию curl_multi_exec(). Эта функция не блокируемая. Она выполняется с той скоростью, с которой может, и возвращает состояние запроса. Пока возвращенное значение является константой ‘CURLM_CALL_MULTI_PERFORM’, это означает, что работа ещё не завершена (например, в данный момент происходит отправка http заголовков в URL); Именно поэтому мы продолжаем проверять это возвращаемое значение, пока не получим другой результат.
В следующем цикле мы проверяем условие, пока переменная $active = ‘true’. Она является вторым параметром для функции curl_multi_exec(). Значение данной переменной будет равно ‘true’, до тех пор, пока какое-то из существующих изменений является активным. Далее мы вызываем функцию curl_multi_select(). Её выполнение ‘блокируется’, пока существует хоть одно активное соединение, до тех пор, пока не будет получен ответ. Когда это произойдёт, мы возвращаемся в основной цикл, чтобы продолжить выполнение запросов.
А теперь давайте применим полученные знания на примере, который будет реально полезным для большого количества людей.
Команда Curl для Работы с Файлами
Команды Curl могут загружать файлы из удалённой локации. Есть два способа это сделать:
- -O сохранит файл в текущем рабочем каталоге с тем же именем, что и у удалённого;
- -o позволяет указать другое имя файла или местоположение.
Вот пример:
curl -O http://testdomain.com/testfile.tar.gz
Приведённая выше команда сохранит файл как testfile.tar.gz.
curl -o newtestfile.tar.gz http://testdomain.com/testfile.tar.gz
А эта команда сохранит его как newtestfile.tar.gz.
Если по какой-либо причине загрузка будет прервана, вы можете возобновить её с помощью следующей команды:
curl -C - -O http://testdomain.com/testfile.tar.gz
Curl также позволяет загрузить несколько файлов одновременно. Пример:
curl -O http://testdomain.com/testfile.tar.gz -O http://mydomain.com/myfile.tar.gz
Если вы хотите загрузить несколько файлов с нескольких URL, перечислите их все в файле. Команды Curl могут быть объединены с xargs для загрузки различных URL-адресов.
Например, если у нас есть файл allUrls.txt, который содержит список всех URL-адресов для загрузки, то приведённый ниже пример выполнит загрузку всех файлов с этих URL.
xargs –n 1 curl -O < allUrls.txt
CONNECTION OPTIONS
CURLOPT_TIMEOUT
Timeout for the entire request. See CURLOPT_TIMEOUT
CURLOPT_TIMEOUT_MS
Millisecond timeout for the entire request. See CURLOPT_TIMEOUT_MS
CURLOPT_LOW_SPEED_LIMIT
Low speed limit to abort transfer. See CURLOPT_LOW_SPEED_LIMIT
CURLOPT_LOW_SPEED_TIME
Time to be below the speed to trigger low speed abort. See CURLOPT_LOW_SPEED_TIME
CURLOPT_MAX_SEND_SPEED_LARGE
Cap the upload speed to this. See CURLOPT_MAX_SEND_SPEED_LARGE
CURLOPT_MAX_RECV_SPEED_LARGE
Cap the download speed to this. See CURLOPT_MAX_RECV_SPEED_LARGE
CURLOPT_MAXCONNECTS
Maximum number of connections in the connection pool. See CURLOPT_MAXCONNECTS
CURLOPT_FRESH_CONNECT
Use a new connection. CURLOPT_FRESH_CONNECT
CURLOPT_FORBID_REUSE
Prevent subsequent connections from re-using this. See CURLOPT_FORBID_REUSE
CURLOPT_MAXAGE_CONN
Limit the age of connections for reuse. See CURLOPT_MAXAGE_CONN
CURLOPT_CONNECTTIMEOUT
Timeout for the connection phase. See CURLOPT_CONNECTTIMEOUT
CURLOPT_CONNECTTIMEOUT_MS
Millisecond timeout for the connection phase. See CURLOPT_CONNECTTIMEOUT_MS
CURLOPT_IPRESOLVE
IP version to resolve to. See CURLOPT_IPRESOLVE
CURLOPT_CONNECT_ONLY
Only connect, nothing else. See CURLOPT_CONNECT_ONLY
CURLOPT_USE_SSL
Use TLS/SSL. See CURLOPT_USE_SSL
CURLOPT_RESOLVE
Provide fixed/fake name resolves. See CURLOPT_RESOLVE
CURLOPT_DNS_INTERFACE
Bind name resolves to this interface. See CURLOPT_DNS_INTERFACE
CURLOPT_DNS_LOCAL_IP4
Bind name resolves to this IP4 address. See CURLOPT_DNS_LOCAL_IP4
CURLOPT_DNS_LOCAL_IP6
Bind name resolves to this IP6 address. See CURLOPT_DNS_LOCAL_IP6
CURLOPT_DNS_SERVERS
Preferred DNS servers. See CURLOPT_DNS_SERVERS
CURLOPT_DNS_SHUFFLE_ADDRESSES
Shuffle addresses before use. See CURLOPT_DNS_SHUFFLE_ADDRESSES
CURLOPT_ACCEPTTIMEOUT_MS
Timeout for waiting for the server’s connect back to be accepted. See CURLOPT_ACCEPTTIMEOUT_MS
CURLOPT_HAPPY_EYEBALLS_TIMEOUT_MS
Timeout for happy eyeballs. See CURLOPT_HAPPY_EYEBALLS_TIMEOUT_MS
CURLOPT_UPKEEP_INTERVAL_MS
Sets the interval at which connection upkeep are performed. See CURLOPT_UPKEEP_INTERVAL_MS
Обнаружение перенаправления в зависимости от браузера
В этом первом примере мы напишем код, который сможет обнаружить перенаправления URL, основанные на различных настройках браузера. Например, некоторые веб-сайты перенаправляют браузеры сотового телефона, или любого другого устройства.
Мы собираемся использовать опцию CURLOPT_HTTPHEADER для того, чтобы определить наши исходящие HTTP заголовки, включая название браузера пользователя и доступные языки. В конечном итоге мы сможем определить, какие сайты перенаправляют нас к разным URL.
// тестируем URL
$urls = array(
"http://www.cnn.com",
"http://www.mozilla.com",
"http://www.facebook.com"
);
// тестируем браузеры
$browsers = array(
"standard" => array (
"user_agent" => "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6 (.NET CLR 3.5.30729)",
"language" => "en-us,en;q=0.5"
),
"iphone" => array (
"user_agent" => "Mozilla/5.0 (iPhone; U; CPU like Mac OS X; en) AppleWebKit/420+ (KHTML, like Gecko) Version/3.0 Mobile/1A537a Safari/419.3",
"language" => "en"
),
"french" => array (
"user_agent" => "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; GTB6; .NET CLR 2.0.50727)",
"language" => "fr,fr-FR;q=0.5"
)
);
foreach ($urls as $url) {
echo "URL: $url\n";
foreach ($browsers as $test_name => $browser) {
$ch = curl_init();
// указываем url
curl_setopt($ch, CURLOPT_URL, $url);
// указываем заголовки для браузера
curl_setopt($ch, CURLOPT_HTTPHEADER, array(
"User-Agent: {$browser}",
"Accept-Language: {$browser}"
));
// нам не нужно содержание страницы
curl_setopt($ch, CURLOPT_NOBODY, 1);
// нам необходимо получить HTTP заголовки
curl_setopt($ch, CURLOPT_HEADER, 1);
// возвращаем результаты вместо вывода
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($ch);
curl_close($ch);
// был ли HTTP редирект?
if (preg_match("!Location: (.*)!", $output, $matches)) {
echo "$test_name: redirects to $matches\n";
} else {
echo "$test_name: no redirection\n";
}
}
echo "\n\n";
}
Сначала мы указываем список URL сайтов, которые будем проверять. Точнее, нам понадобятся адреса данных сайтов. Далее нам необходимо определить настройки браузера, чтобы протестировать каждый из этих URL. После этого мы воспользуемся циклом, в котором пробежимся по всем полученным результатам.
Приём, который мы используем в этом примере для того, чтобы задать настройки cURL, позволит нам получить не содержание страницы, а только HTTP-заголовки (сохраненные в $output). Далее, воспользовавшись простым regex, мы можем определить, присутствовала ли строка “Location:” в полученных заголовках.
Когда вы запустите данный код, то должны будете получить примерно следующий результат:
Отправка данных методом POST
Команда ниже отправляет POST запрос на сервер аналогично тому, как пользователь, заполнив HTML форму, нажал бы кнопку «Отправить». Данные будут отправлены в формате .
> curl -d "key1=value1&key2=value2" http://www.example.com
> curl --data "key1=value1&key2=value2" http://www.example.com
Параметр аналогичен , для отправки двоичных данных необходимо использовать параметр . Для URL-кодирования полей формы нужно использовать .
> curl --data-urlencode "name=Василий" --data-urlencode "surname=Пупкин" http://www.example.com
Если значение опции начинается с , то после него должно быть имя файла с данными (или дефис — тогда будут использованы данные из стандартного ввода). Пример получения данных из файла для отправки POST-запроса:
> curl --data @data.txt http://www.example.com
Содержимое файла :
key1=value1&key2=value2
Массив , который будет содержать данные этого запроса:
Array
(
=> value1
=> value2
)
Пример URL-кодирования данных из файла перед отправкой POST-запроса:
> curl --data-urlencode name@username.txt http://www.example.com
Содержимое файла :
Иванов Иван Иванович
Массив , который будет содержать данные этого запроса:
Array
(
= Иванов Иван Иванович
)
NAMES and PASSWORDS OPTIONS (Authentication)
CURLOPT_NETRC
Enable .netrc parsing. See CURLOPT_NETRC
CURLOPT_NETRC_FILE
.netrc file name. See CURLOPT_NETRC_FILE
CURLOPT_USERPWD
User name and password. See CURLOPT_USERPWD
CURLOPT_PROXYUSERPWD
Proxy user name and password. See CURLOPT_PROXYUSERPWD
CURLOPT_USERNAME
User name. See CURLOPT_USERNAME
CURLOPT_PASSWORD
Password. See CURLOPT_PASSWORD
CURLOPT_LOGIN_OPTIONS
Login options. See CURLOPT_LOGIN_OPTIONS
CURLOPT_PROXYUSERNAME
Proxy user name. See CURLOPT_PROXYUSERNAME
CURLOPT_PROXYPASSWORD
Proxy password. See CURLOPT_PROXYPASSWORD
CURLOPT_HTTPAUTH
HTTP server authentication methods. See CURLOPT_HTTPAUTH
CURLOPT_TLSAUTH_USERNAME
TLS authentication user name. See CURLOPT_TLSAUTH_USERNAME
CURLOPT_PROXY_TLSAUTH_USERNAME
Proxy TLS authentication user name. See CURLOPT_PROXY_TLSAUTH_USERNAME
CURLOPT_TLSAUTH_PASSWORD
TLS authentication password. See CURLOPT_TLSAUTH_PASSWORD
CURLOPT_PROXY_TLSAUTH_PASSWORD
Proxy TLS authentication password. See CURLOPT_PROXY_TLSAUTH_PASSWORD
CURLOPT_TLSAUTH_TYPE
TLS authentication methods. See CURLOPT_TLSAUTH_TYPE
CURLOPT_PROXY_TLSAUTH_TYPE
Proxy TLS authentication methods. See CURLOPT_PROXY_TLSAUTH_TYPE
CURLOPT_PROXYAUTH
HTTP proxy authentication methods. See CURLOPT_PROXYAUTH
CURLOPT_SASL_AUTHZID
SASL authorisation identity (identity to act as). See CURLOPT_SASL_AUTHZID
CURLOPT_SASL_IR
Enable SASL initial response. See CURLOPT_SASL_IR
CURLOPT_XOAUTH2_BEARER
OAuth2 bearer token. See CURLOPT_XOAUTH2_BEARER
CURLOPT_DISALLOW_USERNAME_IN_URL
Don’t allow username in URL. See CURLOPT_DISALLOW_USERNAME_IN_URL
Команды Curl для HTTP
Curl также можно использовать c прокси-сервером. Если вы находитесь за прокси-сервером, прослушивающим порт 8090 на sampleproxy.com, загрузите файлы, как показано ниже:
curl -x sampleproxy.com:8090 -U username:password -O http:// testdomain.com/testfile.tar.gz
В приведённом выше примере вы можете выбросить -U username:password, если прокси-сервер не требует метода аутентификации.
Типичный HTTP-запрос всегда содержит заголовок. Заголовок HTTP отправляет дополнительную информацию об удалённом веб-сервере вместе с фактическим запросом. С помощью инструментов разработчика в браузере вы можете посмотреть сведения о заголовке, а проверить их можно с помощью команды curl.
Пример ниже демонстрирует, как получить информацию о заголовке с веб-сайта.
curl -I www.testdomain.com
Используя curl, вы можете сделать запрос GET и POST. Запрос GET будет выглядеть следующим образом:
curl http://mydomain.com
А вот пример запроса POST
curl –data “text=Hello” https://myDomain.com/firstPage.jsp
Здесь text=Hello — это параметр запроса POST. Такое поведение похоже на HTML-формы.
Вы также можете указать несколько методов HTTP в одной команде curl. Сделайте это, используя опцию –next, например:
curl –data “text=Hello” https://myDomain.com/firstPage.jsp --next https://myDomain.com/displayResult.jsp
Команда содержит запрос POST, за которым следует запрос GET.
Каждый HTTP-запрос содержит агент пользователя, который отправляется как часть запроса. Он указывает информацию о браузере клиента. По умолчанию запрос содержит curl и номер версии в качестве информации об агенте пользователя. Пример вывода показан ниже:
“GET / HTTP/1.1” 200 “_” ”curl/7/29/0”
Вы можете изменить дефолтную информацию об агенте пользователя, используя следующую команду:
curl -I http://mydomain.com –-user-agent “My new Browser”
Теперь вывод будет выглядеть так:
“GET / HTTP/1.1” 200 “_” ”My new Browser”
HTTP-клиент на Python
В этом разделе приводится пример, подобный HTTP-клиенту на языке С, но на этот раз написанный на Python.
Python – это полезный объектно-ориентированный язык сценариев, который отлично подходит для создания прототипов и коммерческого программного обеспечения.
В примере предполагается, что вы немного знакомы с Python, но он используется очень мало, так что глубокие знания не потребуются.
Код простого HTTP-клиента, написанный на языке Python с использованием, приведен в листинге 4.
Листинг 4.
HTTP-клиент на Python с использованием интерфейса из libcurl
import sys import pycurl wr_buf = '' def write_data( buf ): global wr_buf wr_buf += buf def main(): c = pycurl.Curl() c.setopt( pycurl.URL, 'http://www.exampledomain.com' ) c.setopt( pycurl.WRITEFUNCTION, write_data ) c.perform() c.close() main() sys.stdout.write(wr_buf)
Создание прототипа на Python
Здесь иллюстрируется одно из преимуществ языка Python при создании прототипов.
Довольно широкая функциональность достигается при небольшом количестве кода.
На С можно получить более высокую производительность, но если вашей целью является быстрое создание кода для проверки идеи, лучше воспользоваться высокоуровневыми языками сценариев, такими как Python.
Этот код значительно проще, чем версия на C
Он начинается с импортирования необходимых модулей (стандартного системного модуля и модуля ).
Далее определяется буфер записи ().
Как и в программе на C, я декларирую функцию .
Обратите внимание, что эта функция принимает один аргумент:
буфер данных, считанных с сервера HTTP. Я просто взял этот буфер и добавил его к глобальному буферу записи
Функция начинает с создания указателя , затем использует для записи методы для определения и .
Она вызывает метод для запуска передачи и закрывает указатель.
Наконец, она вызывает функцию и передает буфер записи в .
Обратите внимание, что в данном случае указатель ошибки контекста не нужен, поскольку используется конкатенация строк Python, а значит, не нужно использовать строку со статически заданным размером.
Загрузка файлов методом POST
Для HTTP запроса типа POST существует два варианта передачи полей из HTML форм, а именно, используя алгоритм и . Алгоритм первого типа создавался давным-давно, когда в языке HTML еще не предусматривали возможность передачи файлов через HTML формы.
Со временем возникла необходимость через формы отсылать еще и файлы. Тогда консорциум W3C взялся за доработку формата POST запроса, в результате чего появился документ RFC 1867. Форма, которая позволяет пользователю загрузить файл, используя алгоритм , выглядит примерно так:
<form action="/upload.php" method="POST" enctype="multipart/form-data">
<input type="file" name="upload">
<input type="submit" name="submit" value="OK">
</form>
Чтобы отправить на сервер данные такой формы:
> curl -F upload=@image.jpg -F submit=OK http://www.example.com/upload.php
Скрипт , который принимает данные формы:
<?php print_r($_POST); print_r($_FILES); move_uploaded_file($_FILES'upload''tmp_name', 'image.jpg');
Ответ сервера:
Array
(
=> OK
)
Array
(
=> Array
(
=> image.jpg
=> image/jpeg
=> D:\work\temp\phpB02F.tmp
=> 0
=> 2897
)
)