Открытый курс машинного обучения. тема 2: визуализация данных c python
Содержание:
- About this Course
- Advanced Visualizations and Geospatial Data
- Важность статистических распределений
- Methodology
- Столбчатые диаграммы (Bar Plots)
- Introduction to Data Visualization Tools
- Гистограммы (Histograms)
- Leather
- Introduction to Data Visualization Tools
- ggplot
- Древовидная диаграмма
- Seaborn
- About this Course
- Диаграммы рассеяния (Scatter Plots)
- Pandas
- Обработка данных
- Лепестковая диаграмма
- 5: Пользовательская настройка графика
About this Course
510,919 recent views
«A picture is worth a thousand words». We are all familiar with this expression. It especially applies when trying to explain the insight obtained from the analysis of increasingly large datasets. Data visualization plays an essential role in the representation of both small and large-scale data.
One of the key skills of a data scientist is the ability to tell a compelling story, visualizing data and findings in an approachable and stimulating way. Learning how to leverage a software tool to visualize data will also enable you to extract information, better understand the data, and make more effective decisions.
The main goal of this Data Visualization with Python course is to teach you how to take data that at first glance has little meaning and present that data in a form that makes sense to people. Various techniques have been developed for presenting data visually but in this course, we will be using several data visualization libraries in Python, namely Matplotlib, Seaborn, and Folium.
LIMITED TIME OFFER: Subscription is only $39 USD per month for access to graded materials and a certificate.
User
Learner Career Outcomes
Career direction
got a pay increase or promotion
Shareable Certificate
Shareable Certificate
Earn a Certificate upon completion
100% online
100% online
Start instantly and learn at your own schedule.
Flexible deadlines
Flexible deadlines
Reset deadlines in accordance to your schedule.
Intermediate Level
Intermediate Level
Hours to complete
Approx. 18 hours to complete
Available languages
English
Subtitles: English, Vietnamese
Advanced Visualizations and Geospatial Data
In this module, you will learn about advanced visualization tools such as waffle charts and word clouds and how to create them. You will also learn about seaborn, which is another visualization library, and how to use it to generate attractive regression plots. In addition, you will learn about Folium, which is another visualization library, designed especially for visualizing geospatial data. Finally, you will learn how to use Folium to create maps of different regions of the world and how to superimpose markers on top of a map, and how to create choropleth maps.
Hours to complete
12 hours to complete
Reading
6 videos (Total 15 min), 3 readings, 5 quizzes
See All
Важность статистических распределений
Я начал изучать статистику (курс Stats 119), учась в Сан-Диего. Этот курс является вводным и включает в себя самые основы статистики, как например, агрегацию данных (визуальную и количественную), концепцию шансов и вероятностей, регрессию, выборки и, самое главное, статистические распределения. В это время мое понимание тех или иных количественных феноменов практически полностью сдвинулось в сторону представления их в виде статистических распределений (как правило, гауссовых).
И по сей день я нахожу потрясающим, как всего две величины, математическое ожидание и дисперсия, могут помочь вам постичь суть явления. Просто зная эти два числа, легко сделать вывод, насколько вероятен тот или иной результат. Мы сразу знаем, в какой области будут основные результаты. Это дает нам возможность быстро выделять статистически значимые явления, не производя при этом сложных вычислений.
В общем, теперь при работе с любыми новыми данными моим первым шагом всегда является попытка визуализировать их статистическое распределение.
Methodology
One quick note on my methodology for this article. I am sure that as soon as people
start reading this, they will point out better ways to use these tools. My goal
was not to create the exact same graph in each example. I wanted to visualize
the data in roughly the same way in each example with roughly the same amount of time
researching the solution.
As I went through this process, the biggest challenge I had was formatting the x and y axes and making the data look
reasonable given some of the large labels. It also took some time to figure out how each
tool wanted the data formatted. Once I figured those parts out, the rest was relatively simple.
Another point to consider is that a bar plot is probably one of the simpler types of graphs to make.
These tools allow you to do many more types of plots with data. My examples focus more on the ease of
formatting than innovative visualization examples. Also, because of the labels, some of the
plots take up a lot of space so I’ve taken the liberty of cutting them off — just to keep
the article length manageable. Finally, I have resized images so any blurriness is an issue of scaling
and not a reflection on the actual output quality.
Столбчатые диаграммы (Bar Plots)
Столбчатые диаграммы наиболее эффективны тогда, когда вам необходимо визуализировать данные в виде категорий, если их число не превышает 10. Если у нас слишком много категорий, то столбцы будут сильно загромождать график, и его трудно будет понять. Они хороши для данных, разделенных по категориям, потому что вы можете легко увидеть разницу между категориями в зависимости от размера столбца (например, величины); категории также легко можно сформировать и выделить цветом. Есть три разных типа столбчатых диаграмм, которые мы будем рассматривать далее: обычные, сгруппированные и составные. Каждый из этих типов мы рассмотрим по порядку.
Обычная столбчатая диаграмма находится на первом рисунке снизу. В функции задает метки на оси x, а задает высоту столбца по оси y. Строка ошибки представляет собой дополнительную линию, расположенную в центре каждого столбца, которая может быть использована для отображения стандартного отклонения.
Сгруппированные столбчатые диаграммы позволяют сравнивать несколько переменных. Посмотрите на второй график снизу. Первой переменной, которую мы сравниваем, задается то, как оценки варьируются от группы к группе (группы G1, G2, … и так далее). Мы также сравниваем между собой распределение полов, что закодировано цветом. Теперь взгляните на код — вы заметите, что переменная теперь фактически представляет собой список списков, где каждый вложенный список обозначает другую группу. Затем мы проходимся циклом по каждой группе, и для каждой группы рисуем столбец для каждого метки по оси x; все группы также дополнительно окрашиваются.
Составные столбчатые диаграммы отлично подходят для визуализации набора различных переменных. В приведенном ниже рисунке с разбивкой по строкам мы отслеживаем изменение нагрузки на сервер по дням недели. С помощью цветовых наборов мы можем легко видеть и понимать, какие серверы работают больше всего в каждый конкретный день и как в целом распределяется нагрузка по дням на все сервера. Код для этой диаграммы строится по тому же принципу, что и код для сгруппированных столбчатых диаграмм. Мы проходим циклом по каждой группе, с одним единственным исключением: на этот раз мы рисуем новые столбцы поверх старых, а не рядом с ними.
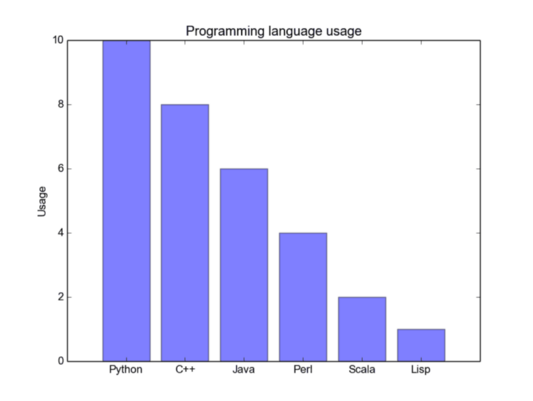
Обычная столбчатая диаграмма. Использование языков программирования
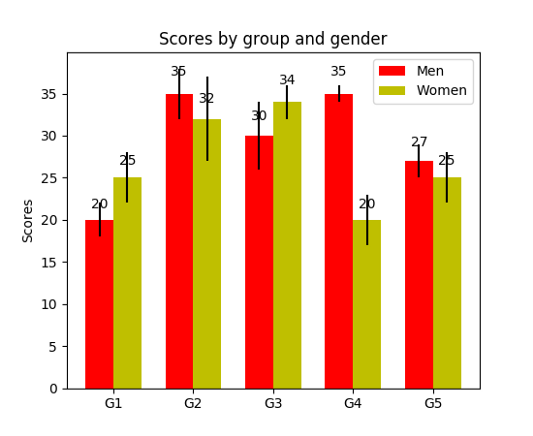
Сгруппированная столбчатая диаграмма. Распределение оценок по полу и возрасту
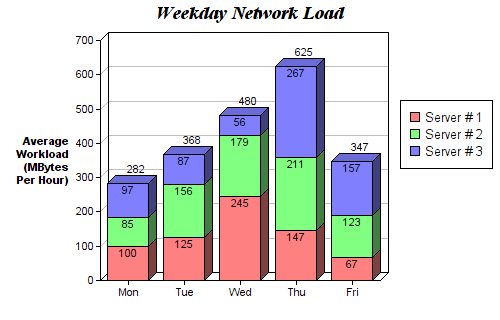
Составная столбчатая диаграмм. Нагрузка на сервер по дням недели
Introduction to Data Visualization Tools
In this module, you will learn about data visualization and some of the best practices to keep in mind when creating plots and visuals. You will also learn about the history and the architecture of Matplotlib and learn about basic plotting with Matplotlib. In addition, you will learn about the dataset on immigration to Canada, which will be used extensively throughout the course. Finally, you will briefly learn how to read csv files into a pandas dataframe and process and manipulate the data in the dataframe, and how to generate line plots using Matplotlib.
Hours to complete
2 hours to complete
Reading
6 videos (Total 27 min), 2 readings, 2 quizzes
See All
Гистограммы (Histograms)
Гистограммы полезны для представления (или даже выявления) распределения данных. Посмотрите на пример ниже, где мы построили гистограмму частоты vs IQ. Мы легко можем заметить концентрацию ближе к центру, а также отчетливо прослеживается медиана значений. Мы также видим, что оно подчиняется гауссовскому распределению. Использование столбцов (а не точек рассеивания, например) действительно дает нам четкую визуализацию относительной разницы между частотой каждого интервала. Использование полос (интервалов = дискретизация) действительно помогает нам увидеть «целостную картину». Если эти же данные представить в виде отдельных точек, без выделения интервалов, то на диаграмме появится слишком много шума, что затруднит понимание тенденции, которая иллюстрируется с помощью этих данных.
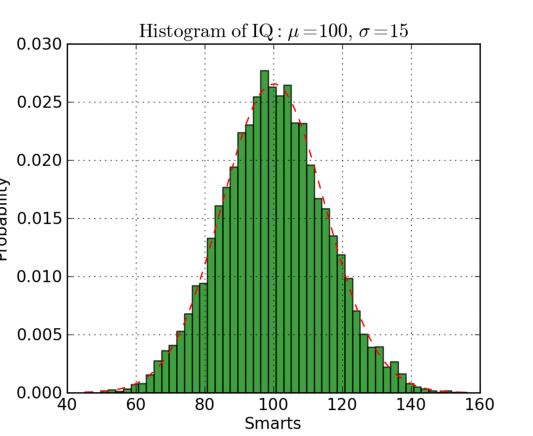
Пример гистограммы
Ниже приведен код гистограммы в Matplotlib
Обратите внимание на два параметра. Во-первых, параметры n_bins определяют, сколько отдельных интервалов нам необходимо поместить на нашей гистограмме
Большее число интервалов даст нам более точную информацию, но может также ввести информационный шум и отвлечь нас от понимания целостной картины; с другой стороны, меньшее число интервалов обеспечивает нам вид с высоты птичьего полёта и целостную картину того, что происходит, при этом не перегружая её мельчайшими деталями. Во-вторых, параметр cumulative является булевым (то есть 1 или 0), что позволяет нам выбрать, является ли наша гистограмма кумулятивной или нет. Другими словами, мы задаем либо плотность вероятности ( Probability Density Function (PDF)) либо функцию интегрального распределения ( Cumulative Density Function (CDF)).
Теперь представьте себе, что мы хотим сравнить распределение двух переменных в наших данных. Первая мысль, которая приходит в голову — это сделать две отдельные гистограммы и расположить их рядом, для наглядности. Но на самом деле есть способ лучше: мы можем накладывать гистограммы с различной прозрачностью. Посмотрите на рисунок, представленный ниже. Равномерное распределение имеет прозрачность 0,5, чтобы мы могли видеть, что расположено за ним. Это позволяет одновременно отобразить два распределения на одном рисунке.
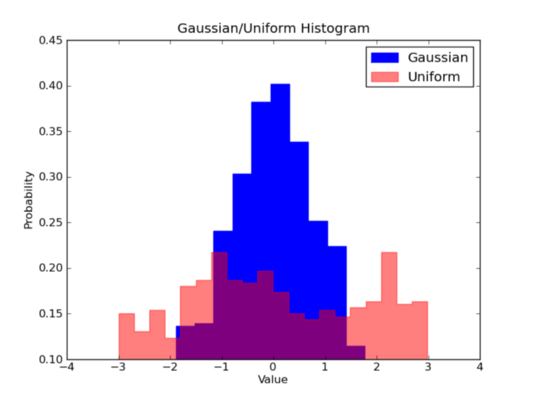
Наложение двух гистограмм: гауссовского и равномерного распределения
Есть несколько параметров, которые необходимо настроить в коде для создания наложенных друг на друга гистограмм. Во-первых, мы устанавливаем горизонтальный диапазон для размещения переменных обоих распределений. В соответствии с этим диапазоном и желаемым количеством интервалов мы можем фактически вычислить ширину каждого интервала, каждой полосы. Наконец, мы строим две гистограммы на одном и том же участке, причем один из них должен быть более прозрачен.
Leather
Сетка диаграммы с согласованными шкалами; создана при помощи Leather
Наилучшим образом библиотеку Leather описал ее создатель, Кристофер Гроскопф: «Leather — это библиотека Python для создания графиков. Она отлично подойдет тем, кому нужен график прямо сейчас и безразлично, насколько он совершенен».
Leather работает с любыми данными. Графики
производятся в формате SVG, так что у вас
не возникнет проблем с изменением их
размера. Поскольку эта библиотека
относительно новая, над некоторыми
частями документации еще ведется работа.
Графики, которые можно создать при
помощи Leather, самые базовые, но это и было
целью автора библиотеки.
Introduction to Data Visualization Tools
In this module, you will learn about data visualization and some of the best practices to keep in mind when creating plots and visuals. You will also learn about the history and the architecture of Matplotlib and learn about basic plotting with Matplotlib. In addition, you will learn about the dataset on immigration to Canada, which will be used extensively throughout the course. Finally, you will briefly learn how to read csv files into a pandas dataframe and process and manipulate the data in the dataframe, and how to generate line plots using Matplotlib.
Hours to complete
2 hours to complete
Reading
6 videos (Total 27 min), 2 readings, 2 quizzes
See All
ggplot
Графики, созданные при помощи библиотеки ggplot
В основе библиотеки ggplot лежит ggplot2 — система для декларативного создания графиков, применяемая в сообществе языка R.
Работа ggplot отличается от работы
Matplotlib: график создается при помощи
нескольких слоев. То есть, вы можете
добавить слой с осями координат, затем
добавить точки, затем провести линию и
т. д. В основе этого подхода лежат
идеи из книги «The Grammar of Graphics». Задумывалось
все как интуитивно понятный метод
создания графиков, но разработчикам,
привыкшим работать с Matplotlib, может
понадобиться некоторое время, чтобы
перестроиться.
Следует отметить, что если вы планируете
создавать сложные графики, библиотека
ggplot вам вряд ли подойдет. Здесь возможная
сложность графиков принесена в жертву
простоте их создания.
Ggplot тесно интегрирована с pandas, так что
при использовании этой библиотеки лучше
хранить данные в DataFrame.
Проходите тест по Python и поймите, готовы ли вы идти на курсы
Древовидная диаграмма
Древовидные диаграммы мы используем с начальной школы! Они естественные и интуитивно-понятные. Соединенные напрямую узлы тесно связаны друг с другом. А узлы, которые расположены друг от друга на расстоянии многих других соединений, отличаются между собой. В приведенной ниже визуализации я указал небольшую часть набора данных о покемонах (Pokemon with stats от Kaggle) с учетом следующих критериев:
Здоровье, нападение, защита, особое нападение, особая защита, скорость
Таким образом, получается, что покемоны, данные которых не сильно отличаются друг от друга, будут иметь более прямую связь. Например, как мы видим, на самом верху покемоны Арбок и Фироу соединены напрямую, и если проверить данные, у Арбока общее значение всех умений составляет 438 баллов, а у Фироу — 442. Очень близко. Но если посмотреть на Ратикейта, то у него общее значение составляет 413. То есть оно уже довольно сильно отличается от Арбока и Фироу, и поэтому они разделены. Если посмотреть на более высокие значения, то можно увидеть, что покемоны начинают группироваться на основе сходств. Покемоны в зеленой группе имеют больше общего между собой, чем с покемонами из красной группы.
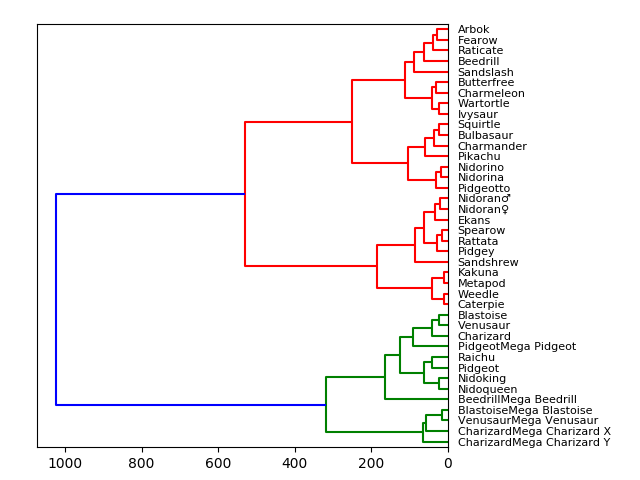
Для древовидной диаграммы используется Scipy. Ознакомившись с набором данных, мы избавляемся от обычной таблицы. Это необходимо для того, чтобы визуализировать данные. На практике лучше преобразовывать строки в категориальные переменные для более точного сравнения. Нужно также добавить индексный кадр для того, чтобы мы могли использовать его в качестве столбца и ссылаться на каждый узел. И наконец, Scipy исполнит простой код в одну строку для вычисления и создания древовидной диаграммы.
# Import libs
import pandas as pd
from matplotlib import pyplot as plt
from scipy.cluster import hierarchy
import numpy as np
# Read in the dataset
# Drop any fields that are strings
# Only get the first 40 because this dataset is big
df = pd.read_csv('Pokemon.csv')
df = df.set_index('Name')
del df.index.name
df = df.drop(, axis=1)
df = df.head(n=40)
# Calculate the distance between each sample
Z = hierarchy.linkage(df, 'ward')
# Orientation our tree
hierarchy.dendrogram(Z, orientation="left", labels=df.index)
plt.show()
Перевод статьи George Seif4 More Quick and Easy Data Visualizations in Python with Code
Seaborn
Seaborn is a visualization library based on matplotlib. It seeks to make
default data visualizations much more visually appealing. It also has the goal
of making more complicated plots simpler to create. It does integrate well with pandas.
My example does not allow seaborn to significantly differentiate itself. One thing
I like about seaborn is the various built in styles which allows you to quickly
change the color palettes to look a little nicer. Otherwise, seaborn
does not do a lot for us with this simple chart.
Standard imports and read in the data:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
budget = pd.read_csv("mn-budget-detail-2014.csv")
budget = budget.sort('amount',ascending=False)[:10
One thing I found out is that I explicitly had to set the order of the
items on the x_axis using
This section of code sets the order, and styles the plot and bar chart colors:
sns.set_style("darkgrid")
bar_plot = sns.barplot(x=budget"detail"],y=budget"amount"],
palette="muted",
x_order=budget"detail".tolist())
plt.xticks(rotation=90)
plt.show()
About this Course
515,060 recent views
In the capstone, students will build a series of applications to retrieve, process and visualize data using Python. The projects will involve all the elements of the specialization. In the first part of the capstone, students will do some visualizations to become familiar with the technologies in use and then will pursue their own project to visualize some other data that they have or can find. Chapters 15 and 16 from the book “Python for Everybody” will serve as the backbone for the capstone. This course covers Python 3.
User
Learner Career Outcomes
Career direction
started a new career after completing these courses
Career Benefit
got a pay increase or promotion
Shareable Certificate
Shareable Certificate
Earn a Certificate upon completion
100% online
100% online
Start instantly and learn at your own schedule.
Specialization
Course 5 of 5 in the
Python for Everybody Specialization
Flexible deadlines
Flexible deadlines
Reset deadlines in accordance to your schedule.
Hours to complete
Approx. 9 hours to complete
Available languages
English
Subtitles: English, Korean
Диаграммы рассеяния (Scatter Plots)
Используйте их, если хотите показать связь между двумя переменными, так как они позволяют отображать грубое распределение данных. На нем также можно показать соотношение между различными группами данных за счет окрашивания их разными цветами. Нужно показать взаимосвязь между тремя переменным? Ноу проблем! Просто добавьте дополнительные параметры, такие как размер точек, чтобы закодировать эту третью переменную, как это сделано на втором графике снизу.
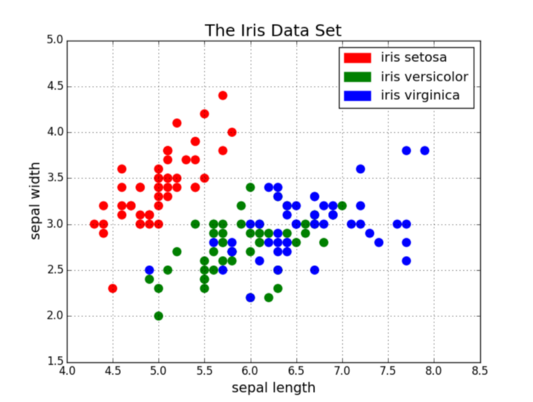
Диаграмма рассеяния с группировкой по цветам
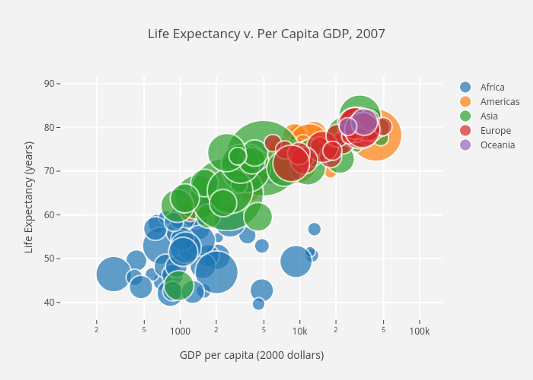
Диаграмма рассеяния с группировкой по цветам и по размерам для отображения -го параметра — размера страны
Теперь что касается кода. Сначала мы импортируем в Python библиотеку Matplotlib, а точнее её модуль pyplot, для краткости используя аббревиатуру «plt». Чтобы создать новый график, мы вызываем функцию . Затем передаем данные оси x и оси y в функцию, а затем уже всё вместе передаем функции для построения диаграммы рассеяния. Мы также можем установить размер точки, цвет точки и альфа-прозрачность. Можно даже использовать логарифмическую шкалу для оси y. Затем задаем заголовок и метки для осей. Это простая в использовании функция позволяет с нуля создать и отрисовать диаграмму рассеяния!
Pandas
I am using a pandas DataFrame as the starting point for all the various plots.
Fortunately, pandas does supply a built in plotting capability for us which is a layer
over matplotlib. I will use that as the baseline.
First, import our modules and read in the data into a budget DataFrame. We also want
to sort the data and limit it to the top 10 items.
import pandas as pd
import matplotlib.pyplot as plt
budget = pd.read_csv("mn-budget-detail-2014.csv")
budget = budget.sort('amount',ascending=False)[:10
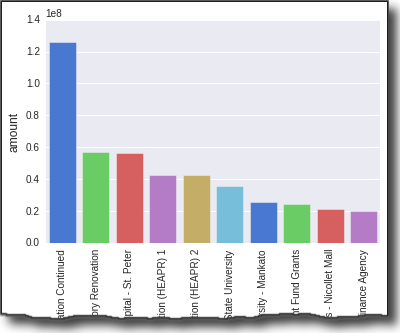
We will use the same budget lines for all of our examples. Here is what the top 5 items look like:
| category | detail | amount | |
|---|---|---|---|
| 46 | ADMINISTRATION | Capitol Renovation and Restoration Continued | 126300000 |
| 1 | UNIVERSITY OF MINNESOTA | Minneapolis; Tate Laboratory Renovation | 56700000 |
| 78 | HUMAN SERVICES | Minnesota Security Hospital — St. Peter | 56317000 |
| UNIVERSITY OF MINNESOTA | Higher Education Asset Preservation and Replac… | 42500000 | |
| 5 | MINNESOTA STATE COLLEGES AND UNIVERSITIES | Higher Education Asset Preservation and Replac… | 42500000 |
Now, setup our display to use nicer defaults and create a bar plot:
pd.options.display.mpl_style = 'default'
budget_plot = budget.plot(kind="bar",x=budget"detail"],
title="MN Capital Budget - 2014",
legend=False)
This does all of the heavy lifting of creating the plot using the “detail” column as
well as displaying the title and removing the legend.
Here is the additional code needed to save the image as a png.
fig = budget_plot.get_figure()
fig.savefig("2014-mn-capital-budget.png")
Here is what it looks like (truncated to keep the article length manageable):
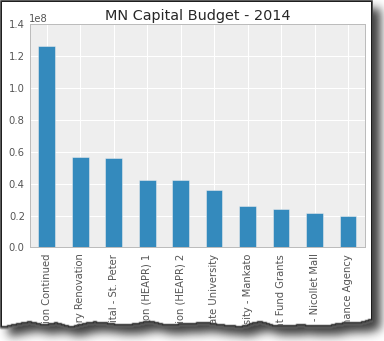
Обработка данных
Теперь удалим символы новой строки из текстовых данных:
Из первых пяти строк таблицы стало ясно, что колонка имеет вещественный тип. А ведь именно это и является нашей «целью». Приведём их к целочисленному типу и сохраним в отдельную переменную.
Теперь про обработку текста. Мы могли бы создать кучу функций, которые бы разбивали текст на слова, подсчитывали их кол-во, частоту и т. д. Однако Keras обладает улучшенным программным интерфейсом (хотя отдельные функции в том же подмодуле так же имеются) в виде класса . Создадим его экземпляр:
Кратко пройдёмся по параметрам:
- — кол-во фиксируемых слов (самых часто встречающихся)
- — последовательность символов, которые будут удаляться.
- — булевый параметр, отвечающий за то, будет ли переведён текст в нижний регистр
- — основной символ разбиения предложения
- — указывает на то, будет ли считаться отдельный символ словом.
Документацию по этому классу можно найти здесь.
Теперь преобразуем наш набор текста с помощью этого класса:
14 тысяч строк (образцов) и 30000 столбцов — признаков. Метод имеет параметр , который может принимать 4 значения:
- — вернёт массив, состоящий из 0 и 1, где каждый флаг будет отвечать за то, присутствует определённое слово в тексте.
- — простой счетчик слов
- — текстовая обратная оценка частоты документа (TF-IDF) для каждого слова
- — частота каждого слова в соответствии с другими
Теперь построим модель из двух слоёв: и . Про оба эти слоя рассказывалось в предыдущих статья, советую их прочитать, если не ознакомлены с материалом.
Нормализируем нашу матрицу и разобьём данные на тестовые и тренировочные:
Лепестковая диаграмма
Лепестковую диаграмму лучше всего использовать для отображения связи «один-ко-многим». Например, составив такую диаграмму можно увидеть значения нескольких переменных по отношению к другой одной переменной или целой категории. На лепестковой диаграмме сразу видно возвышение одной переменной над другой, так как площадь и длина увеличиваются в этом конкретном направлении. Укажите несколько категорий рядом друг с другом для того, чтобы посмотреть, как они связаны по отношению к тем переменным. На приведенных ниже диаграммах можно легко сравнить умения мстителей и увидеть, по каким критериям каждый из них лучше другого
(Обратите внимание, что эти характеристики были выставлены случайно. Я не отношусь предвзято ни к одному из мстителей )
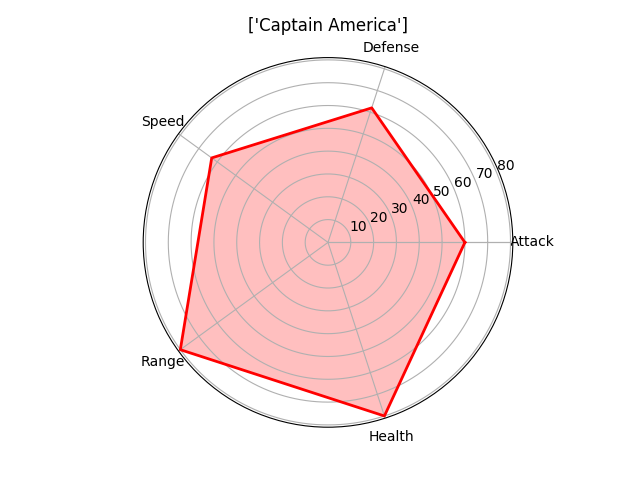
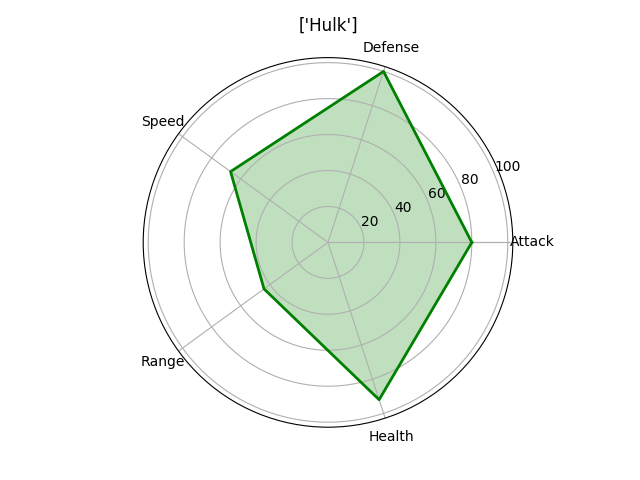
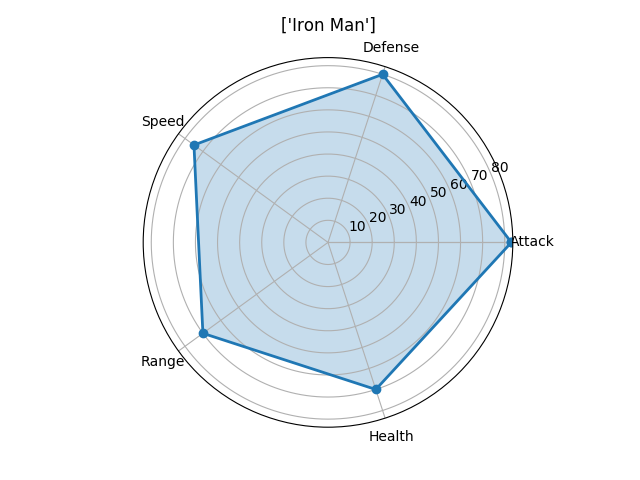
На этот раз для создания нашей визуализации лучше использовать matplotlib, а не seaborn. Нам нужно вычислить угол, под которым будет находиться каждое умение, так как мы хотим, чтобы они были равномерно распределены по всей окружности. Разместим названия умений под каждым вычисленным углом, а затем каждое значение отметим точкой. Расстояние точки от центра зависит от ее значения/величины. Наконец, соединив все точки, для наглядности зальем получившуюся фигуру прозрачным цветом.
# Import libs
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# Get the data
df=pd.read_csv("avengers_data.csv")
print(df)
"""
# Name Attack Defense Speed Range Health
0 1 Iron Man 83 80 75 70 70
1 2 Captain America 60 62 63 80 80
2 3 Thor 80 82 83 100 100
3 3 Hulk 80 100 67 44 92
4 4 Black Widow 52 43 60 50 65
5 5 Hawkeye 58 64 58 80 65
"""
# Get the data for Iron Man
labels=np.array()
stats=df.loc.values
# Make some calculations for the plot
angles=np.linspace(0, 2*np.pi, len(labels), endpoint=False)
stats=np.concatenate((stats,]))
angles=np.concatenate((angles,]))
# Plot stuff
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.plot(angles, stats, 'o-', linewidth=2)
ax.fill(angles, stats, alpha=0.25)
ax.set_thetagrids(angles * 180/np.pi, labels)
ax.set_title(])
ax.grid(True)
plt.show()
5: Пользовательская настройка графика
При работе с уникальными наборами данных нужно кастомизировать график. Для этого библиотека matplotlib предлагает огромное множество функций, различные цвета, символы и т.п. Вы можете самостоятельно ознакомиться со всеми возможностями библиотеки. Для примера можно изменить параметры графика по умолчанию, назначив новые диапазоны осей:
Точки на графике маленькие, отмеченные синим цветом. Это не всегда удобно. Вместо кружков можно использовать треугольники. Чтобы изменить цвет, размер или форму, вызовите функцию plt.scatter(). Попробуйте изменить такие параметры:
- s: размер точки, по умолчанию =20.
- c: цвет, последовательность, по умолчанию b.
- marker: форма, по умолчанию круг (о).
Точка графика может иметь форму шестиугольника, звёздочки, треугольника и т.д. Также доступны различные цвета: синий, зелёный, красный, пурпурный и т.д. Для настройки цвета в HTML можно использовать числа в шестнадцатеричном коде.
Примечание: Списки маркеров и цветов можно найти в документации matplotlib.
Чтобы график было проще читать, увеличьте размер точки в три раза (s=60), смените стандартный синий на красный цвет(c=’r’), а форму точки на треугольник (marker=’^’).
Убедитесь, что код не содержит ошибок. После обновления сценарий выглядит так: