Курс hadoop для инженеров данных
Содержание:
- Преимущества и недостатки Флинк
- Cloudera Enterprise Manager: чем CDH отличается от других дистрибутивов Apache Hadoop
- Другие области применения Hadoop
- Что дальше
- О курсе «Администрирование кластера Hadoop»
- Как устроен Tarantool: архитектура и принципы работы
- Как устроена Greenplum: архитектура и принципы работы
- 2014
- Компоненты популярных дистрибутивов Хадуп для проектов Big Data
- 7 главных преимуществ продуктов Arenadata
- Что такое Arenadata DB
- Apache Hive и Cloudera Impala: что это и как используется в SQL для Big Data
Преимущества и недостатки Флинк
Ключевыми достоинствами Apache Flink можно назвать следующие :
- высокая производительность — приложения Флинк могут распараллеливаться в тысячи задач, которые распределяются и выполняются в кластере одновременно, используя практически неограниченное количество процессоров, основной памяти, дискового и сетевого ввода-вывода. Кроме того, Flink легко поддерживает очень большое состояние приложения. Его асинхронный и инкрементный контрольный алгоритм обеспечивает минимальное влияние на задержки обработки, гарантируя точную согласованность состояния за один раз.
- низкое время задержки, достигаемое, в т.ч. за счет собственной подсистемы управления памятью и ее эффективного использования – приложения Флинк оптимизированы для локального доступа. Состояние задачи (stateful) сохраняется в локально памяти или, если его размер превышает доступную память, на жестком диске.
- веб-интерфейс, который отображает граф обработки данных и позволяет посмотреть, сколько данных каждой подзадачи обработал конкретный worker. Благодаря этому можно определить, какой участок кода работает с задержкой, т.е. какой процент данных не успел обработаться и где .
- отказоустойчивость – Flink гарантирует согласованность состояния приложений в случае сбоев, периодически и асинхронно проверяя локальное состояние на необходимость перемещения в долговечное хранилище;
- гибкая работа с потоковыми данными – поддержка временных и неисправных событий, непрерывная потоковая модель передачи с обратным воздействием, реализация концепции «окон» для избирательной обработки данных в определенном временном промежутке (подробно механизм временных окон мы описывали здесь на примере Apache Kafka Streams);
- 2 режима работы с данными в 1 среде – потоковая передача и пакетная обработка;
- специализированная поддержка итерационных вычислений (машинное обучение, анализ графов).
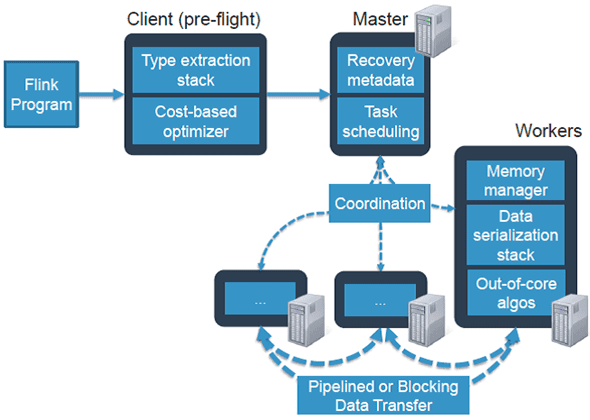 Принцип работы Apache Flink
Принцип работы Apache Flink
При всех вышеперечисленных достоинствах, для Флинк характерны следующие недостатки:
- даже при наличии отказоустойчивого хранилища состояний для приложений (stateful), которое поддерживает механизм контрольных точек (checkpoints), из него нельзя восстановиться при изменении кода ;
- многие библиотеки Flink до сих пор находятся в бета-режиме , что затрудняет его использование в крупных Big Data проектах корпоративного сектора, где требуется высокая надежность .
Сравнению Flink с Apache Spark, другим популярным фреймворком потоковой обработки больших данных мы посвятили отдельную статью.
Источники
- https://ru.bmstu.wiki/Apache_Flink
- https://habr.com/ru/company/ivi/blog/347408/
- https://medium.com/@chandanbaranwal/spark-streaming-vs-flink-vs-storm-vs-kafka-streams-vs-samza-choose-your-stream-processing-91ea3f04675b
Cloudera Enterprise Manager: чем CDH отличается от других дистрибутивов Apache Hadoop
Уникальным отличием CDH от других дистрибутивов Big Data инфраструктуры на основе Apache Hadoop является Cloudera Manager — собственная специализированная подсистема управления кластером. Она включает сценарии развёртывания Hadoop-инфраструктуры и средства Apache Maven, что позволяет автоматизировать создание и модификацию локальных и облачных Hadoop-сред, отслеживать и анализировать эффективность выполнения заданий, настраивать оповещения о наступлении событий, связанных с эксплуатацией инфраструктуры распределённой обработки данных .
Существует бесплатная версия Cloudera Manager, которая ограничена 50-ю узлами и не поддерживает мониторинг производительности, управление версиями конфигурации, сетевой протокол аутентификации Kerberos. Коммерческая версия Cloudera считается достаточно дорогой за счет высокой стоимости технического сопровождения (примерно $4 тысяч в год за узел кластера) , поэтому позволить ее себе могут только очень крупные компании.
Платный вариант CDH называется Enterprise и включает Cloudera Manager — инструмент для развертывания, мониторинга и управления кластером, а также Cloudera Support – профессиональная поддержка от компании-разработчика по вопросам CDH и Cloudera Manager .
 Модули Cloudera Enterprise
Модули Cloudera Enterprise
Помимо техподдержки, CDH Enterprise 4.0 включает следующие полезные компоненты :
- Мастер настройки и управления многими кластерами из одной консоли;
- цветовые теплокарты, которые показывают степень исправности кластеров Hadoop;
- поддержка хранения баз метаданных в Oracle 11g, MySQL или PostgreSQL.
Другие области применения Hadoop
Hadoop является на удивление многосторонней платформой для разработки распределенных приложений; для использования всех преимуществ Hadoop нужно всего лишь по-другому взглянуть на проблему. Из видно, что обработка происходит в виде ступенчатых функций, где работа одних компонентов поддерживается другими. Это определенно не является панацеей для разработки приложений, но если вы можете взглянуть на вашу задачу с этой точки зрения, то Hadoop может быть одним из вариантов ее решения.
Hadoop помогает решать широкий круг задач, включая сортировку огромных объемов данных и разбор содержимого чрезвычайно больших файлов. Кроме того, Hadoop используется в качестве ядра различных поисковых систем, например, A9 от Amazon и система поиска информации о винах Vertical от Able Grape. Страница Hadoop Wiki содержит большой список приложений и компаний, использующих Hadoop в самых различных целях (см. раздел ).
В настоящий момент компания Yahoo! имеет самую большую промышленную систему Hadoop под управлением Linux, состоящую из 10 000 ядер и более пяти петабайт дискового пространства, распределенного по узлам DataNode. Web-индекс этой компании содержит приблизительно один триллион ссылок. Однако для ваших задач такой размах может не потребоваться, и в этом случае вы можете использовать Web-сервис Amazon Elastic Compute Cloud (EC2) для построения виртуального кластера из 20 узлов. Например, газета New York Times использовала Hadoop и EC2 для преобразования четырех терабайт TIFF-изображений (включая TIFF-изображения размером в 405 КБ, SGML-статьи размером в 3.3 МБ и XML-файлы размером в 405 КБ) в изображения PNG-формата размером по 800 КБ, и на это ушло 36 часов. Эта концепция, известная как вычислительное облако (cloud computing), является уникальным способом продемонстрировать возможности Hadoop.
Что дальше
В этой статье были рассмотрены установка и первоначальная настройка простого (псевдораспределенного) кластера Hadoop (мы использовали дистрибутив Hadoop от компании Cloudera). Я выбрал этот дистрибутив по той причине, что он упрощает процесс установки и настройки Hadoop. Вы можете найти различные дистрибутивы Hadoop (включая исходный код) на сайте apache.org. Более подробная информация содержится в разделе .
Что, если для выполнения ваших задач вам потребуется масштабировать кластер Hadoop, но ваших аппаратных ресурсов окажется недостаточно? Оказывается, популярность Hadoop обусловлена именно тем, что вы можете легко запускать его в инфраструктуре облачных вычислений на арендованных серверах с использованием предварительно собранных виртуальных машин Hadoop. Компания Amazon предоставляет в ваше распоряжение образы Amazon Machine Images (AMIs), а также вычислительные ресурсы облака Amazon Elastic Compute Cloud (Amazon EC2). В дополнение к этому корпорация Microsoft объявила о том, что ее платформа Windows Azure Services
Platform также будет поддерживать Hadoop.
Прочитав эту статью, легко увидеть, как Hadoop упрощает распределенные вычисления для обработки больших массивов данных. В следующей статье этой серии будет рассказано, как настраивать Hadoop в многоузловой конфигурации, и будут приведены дополнительные примеры. До встречи!
Похожие темы
- Оригинал статьи Distributed data processing with Hadoop, Part 1: Getting started (EN).
- Даг Каттинг (Doug Cutting) (EN) – бывший сотрудник Yahoo! (теперь работает в Cloudera), разработавший фреймворк Hadoop для поддержки распространения поискового механизма Nutch.
- Основной сайт Apache Project, посвященный разработкам Hadoop (EN).
- На сайте компании Cloudera (EN) вы можете найти предварительно собранные пакеты и виртуальные машины Hadoop, упрощающие начало работы.
- Ознакомьтесь с лицензией (EN), официально делегированной компанией Google проекту Hadoop, благодаря которой вы можете безопасно использовать Hadoop, не беспокоясь о нарушении авторских прав. Компания Google является владельцем патента концепции Hadoop (эффективная, широко масштабируемая обработка данных, фигурирующая в патенте 7,650,331).
- Прочитайте статьи Распределенные вычисления с помощью Linux и Hadoop (developerWorks, апрель 2009 г.) и Облачные вычисления с помощью Linux и Apache Hadoop (EN) (developerWorks, октябрь 2009), чтобы узнать больше о Hadoop и его архитектуре.
- MapReduce: упрощенная обработка данных на больших кластерах (EN) – основополагающий документ Google, описывающий этот функциональный стиль программирования.
- Прочитайте введение в концепцию MapReduce на Wikipedia (EN).
- Ознакомьтесь со списком команд для утилиты Hadoop (EN) на сайте Apache.
- Загляните в раздел Hadoop
on the horizon (EN) и познакомьтесь с группой IBM jStart (подразделение развивающихся технологий). На странице jStart вы также узнаете о BigSheets (EN) – технологии IBM, предназначенной для расширения интеллектуальных ресурсов предприятия через Web-данные. - Компания Cloudera предлагает вам ряд бесплатных (и рабочих!) дистрибутивов Hadoop. Вы можете загрузить дистрибутивы для различных версий Linux, виртуальную машину и даже виртуальную машину для Amazon EC2 (EN).
- Облако Windows Azure готовится к предоставлению Hadoop в качестве виртуальной машины (EN); Amazon предоставляет образы виртуальных машин Hadoop в рамках своей масштабируемой инфраструктуры Amazon EC2 (EN).
- Оцените продукты IBM (EN) любым удобным для вас способом: вы можете загружать пробные версии продуктов, работать с ними в онлайновом режиме, использовать их в облачной среде или же потратить несколько часов на изучение SOA Sandbox (EN) и узнать, как можно эффективно применять сервис-ориентированную архитектуру при разработке программного обеспечения.
О курсе «Администрирование кластера Hadoop»
Продолжительность: 5 дней, 40 академических часов.
Соотношение теории к практике 40/60
Сегодня Apache Hadoop является самой популярной открытой платформой для распределенных вычислений и главной технологией больших данных (Big Data). Данный курс для администраторов Big Data содержит всю необходимую теоретическую информацию по планированию и развертыванию распределенных вычислительных кластеров на базе дистрибутивов Hadoop. Рассматриваются процессы мониторинга и оптимизации производительности системы, резервному копированию и аварийному восстановлению узлов кластера и отдельных компонент
Особое внимание уделено настройкам безопасности системы Kerberos (Active Directory и MIT/FreeIPA) на базе Hadoop
Курс администрирование кластера Hadoop построен на сквозных практических примерах развертывания и администрирования распределенной вычислительной среды: локально и в облачной инфраструктуре. Вы изучите особенности использования компонент Hadoop для запуска задач распределенных вычислений с тестовыми данными. Практические занятия выполняются в кластерной среде Amazone Web Services с использованием дистрибутивов Cloudera Distributed Hadoop/ HortonWorks и Arenadata Hadoop (российский дистрибутив Hadoop в рамках программы импортозамещения), а также программного обеспечения управления кластером Cloudera Manager/ Arenadata Hadoop / HortonWorks.
Примечание: с 1 января 2019 года данный курс «Администрирование кластера Hadoop» проводится в объединенном формате по дистрибутивам Hadoop версии 2 компаний Cloudera/HortonWorks/Arenadata на выбор для пользователей. Для корпоративного формата обучения возможна выделенная программа по одной версии дистрибутива Hadoop (уточняйте у менеджера).
Как устроен Tarantool: архитектура и принципы работы
Прежде всего отметим наиболее важные концепции Tarantool с точки зрения разработчика Big Data приложений :
- поддержка SQL и документо-ориентированных запросов на скриптовом мультипарадигмальном языке Lua;
- поддержка ACID-транзакций (Atomicity, Consistency, Isolation, Durability – атомарность, согласованность, изоляция, стойкость);
- индексация по первичным ключам, с поддержкой неограниченного числа вторичных ключей и составными ключами в индексах;
- разделение доступа на основе ACL-модели (Access Control List);
- единый механизм упреждающей записив журнал (WAL, Write Ahead Log), который обеспечивает согласованность и сохранность данных в случае сбоя – изменения не считаются завершенными, пока не проходит запись в WAL;
- синхронная и асинхронная репликация локально и на удаленных серверах, когда сразу несколько узлов могут обрабатывать входящие данные и получать информацию от других узлов.
Основными программными компонентами Tarantool являются следующие :
- JIT (Just In Time) Lua-компилятор – LuaJIT;
- Lua-библиотеки для самых распространенных приложений;
- сервер документоориентированной NoSQL-СУБД Tarantool с 2-мя движками – резидентным (In-memory, memtx), который хранит все данные в оперативной памяти, и дисковый (vinyl), который эффективно сохраняет данные на жесткий диск, используя разделение на диапазоны, журнально-структурированные деревья со слиянием (log-structured merge trees) и классические B-деревья.
Перейдем к архитектуре: распределенный кластер Tarantool состоит из подкластеров, которые называются шарды (shard). Каждый шард хранит некоторую часть данных и представляет собой набор реплик, одна из которых является ведущим узлом, обрабатывающим все запросы на чтение и запись. При разделении (шардинге) данных они распределяются на заданное количество виртуальных сегментов с уникальными номерами. Рекомендуется задавать количество сегментов в 100-1000 раз больше, чем потенциальное число кластерных узлов с учетом масштабирования кластера в перспективе. Однако, слишком большое число сегментов может потребовать дополнительную память для хранения информации о маршрутизации, а слишком маленькое – привести к снижению степени детализации балансировки.
Итак, каждый шард хранит уникальное подмножество сегментов, причем один сегмент не может относиться к нескольким шардам одновременно. Таким образом, с архитектурной точки зрения сегментированный кластер Tarantool включает следующие компоненты :
- хранилище (storage) – узел, который хранит подмножество набора данных. Несколько реплицируемых хранилищ составляют набор реплик (шард, shard). У каждого хранилища в наборе реплик есть роль: мастер или реплика. Мастер обрабатывает запросы на чтение и запись. Реплика обрабатывает запросы только на чтение.
- Роутер (router) – автономный компонент, который обеспечивает маршрутизацию запросов чтения и записи от клиентского приложения к шардам. В зависимости от функций приложения, роутер работает на его уровне или на уровне хранилища. Он сохраняет топологию сегментированного кластера прозрачной для приложения, скрывая такие детали, как номер и местоположение шардов, процесс балансировки данных, отказы реплики и восстановление после них. Роутер может сам идентифицировать сегмент, если приложение четко определяет правила вычисления идентификатора сегмента на основе запроса. Для этого роутеру необходимо знать схему данных. У роутера нет постоянного статуса, он не хранит топологию кластера и не выполняет балансировку данных. Роутер поддерживает постоянный пул соединений со всеми хранилищами, созданными при запуске, что помогает избежать ошибок конфигурации.
- Балансировщик – фоновый процесс равномерного распределения сегментов по шардам, во время которого выполняется миграция сегментов по наборам реплик. Балансировщик запускает периодически, перераспределяя данные из наиболее загруженных узлов в менее загруженные, когда предел дисбаланса в наборе реплик превышает показатель, указанный в конфигурации.
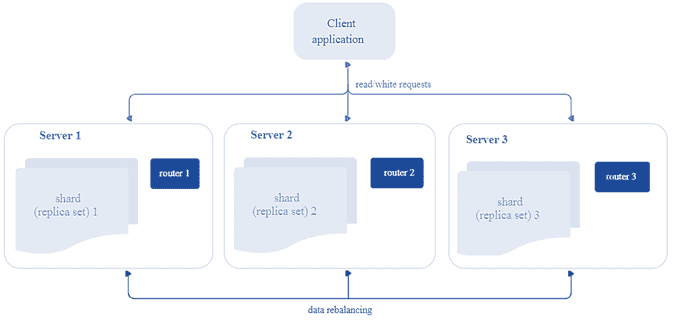 Архитектура СУБД Tarantool
Архитектура СУБД Tarantool
Как устроена Greenplum: архитектура и принципы работы
СУБД Greenplum представляет собой несколько взаимосвязанных экземпляров базы данных PostgreSQL, объединенных в кластер по принципу массивно-параллельной архитектуры (Massive Parallel Processing, MPP) без разделения ресурсов (Shared Nothing). При этом каждый узел кластера, взаимодействующий с другими для выполнения вычислительных операций, имеет собственную память, операционную систему и жесткие диски.
Для повышения надежности к типовой топологии master-slave добавлен резервный главный сервер. Так в состав кластера Greenplum входят следующие компоненты :
- Мастер-сервер(Master host), где развернут главный инстанс PostgreSQL (Master instance). Это точка входа в Greenplum, куда подключаются клиенты, отправляя SQL-запросы. Мастер координирует свою работу с сегментами – другими экземплярами базы данных PostgreSQL. Мастер распределяет нагрузку между сегментами, но сам не содержит никаких пользовательских данных – они хранятся только на сегментах.
- Резервный мастер(Secondary master instance) — инстанс PostgreSQL, включаемый вручную при отказе основного мастера.
- Сервер-сегмент (Segment host), где хранятся и обрабатываются данные. На одном хост-сегменте содержится 2-8 сегментов Greenplum – независимых экземпляров PostgreSQL с частью данных. Сегменты Гринплам бывают основные (primary) и зеркальные (mirror). Primary-сегментобрабатывает локальные данные и отдает результаты мастеру. Каждому primary-сегменту соответствует свое зеркало (Mirror segment instance), которое автоматически включается в работу при отказе primary.
- Интерконнект (interconnect) – быстрое обособленное сетевое соединение для связи между отдельными экземплярами PostgreSQL.
Мастер взаимодействует с сегментами Гринплам следующим образом :
- пользователь подключается к базе данных с помощью клиентских программ: psql или через API-интерфейсы типа JDBC и ODBC;
- мастер аутентифицирует клиентские соединения и обрабатывает входящие SQL-запросы;
- каждый сегмент для обработки запроса создает соответствующие процессы;
- после выполнения вычислений над локальными данными сегмент возвращает результаты мастеру;
- мастер координирует результаты от сегментов и представляет конечный итог клиентской программе.
 Архитектура кластера Greenplum
Архитектура кластера Greenplum
Подробнее архитектуру Greenplum и основные принципы работы этой MPP-СУБД мы рассматриваем здесь. Зеркалирование сегментов обусловливает повышенную надежность, однако приводит к избыточному потреблению ресурсов и удорожанию кластера. О других достоинствах и недостатках Гринплам читайте в нашей отдельной статье.
2014
HDP 2.0
22 января 2014 года компания Microsoft сообщила о выходе Hortonworks Data Platform 2.0 для Windows. Продукт сертифицирован для Windows Server 2008 R2/Windows Server 2012/2012 R2.
В обновленной платформе разработчикам доступен удобный Windows-инсталлятор для развёртывания Hadoop 2.0 на одном компьютере. В наличии «песочница» (sandbox), эмулирующая кластер из нескольких узлов.
В рамках выхода HDP 2.0 для Windows компания Hortonworks сообщила об обновлении NoSQL СУБД Apache HBase до версии 0.96 (теперь можно делать слепки БД).
Начата вторая фаза проекта Stinger — ускорителя для движка Apache Hive, поддерживающего SQL-запросы к Hadoop. На фоне недавней публикации фирмой Cloudera результатов тестирования аналогичного движка Impala, опередившего Hive в десятки раз, этот анонс ускорения Hive в 100 раз на петабайтных объёмах весьма актуален.
Apache Hadoop 2.0
Главным новшеством платформы станет механизм управления задачами Yarn, призванный упростить разработку приложений Hadoop. До сих пор обработка задач в Hadoop, осуществляемая с помощью механизма MapReduce, была возможна только в поочередном режиме. Yarn же позволит выполнять задачи параллельно. Новый механизм создает контейнеры для приложений, следит за их потребностями в ресурсах и выделяет дополнительные по необходимости. Если MapReduce одновременно отвечал за планирование задач и управление ресурсами, то Yarn разграничивает эти функции.
По мнению экспертов, благодаря новому механизму планирования задач для Hadoop может появиться целая волна новых аналитических приложений. Этот процесс уже начался: например, средствами Yarn пользуется Apache Tez, система анализа данных в режиме реального времени, ускоряющая выполнение запросов за счет обработки в оперативной памяти.
В Hadoop 2.0 появился еще ряд новых компонентов, в том числе средства обеспечения высокой готовности и расширения масштаба индивидуальных кластеров (среды Hadoop могут состоять из нескольких кластеров): каждый из них теперь может содержать до 4 тыс. серверов.
Платформа Hadoop станет стандартом индустрии в 2015 году
1 декабря 2014 года аналитики компании Forrester Research озвучили прогноз, согласно которому платформа Hadoop от Apache станет стандартом де-факто для ИТ-инфраструктуры всех крупных компаний в 2015 году. Предполагается, заметный рост числа специалистов и скорости внедрения систем на платформе Hadoop.
На рынке наблюдается соответствующая тенденция к обязательной интеграции Hadoop, которую аналитики назвали «хадупономика» (Hadooponomics), она должна обеспечивать способность линейного масштабирования как хранения, так и обработки данных. «Хадупономика» тесно связана с возможностью дальнейшего активного применения облачных решений на крупных предприятиях.
Согласно отчету аналитиков, не все предприятия активно применяют Hadoop, однако важность платформы доказали многие лидирующие в своих отраслях индустрии компании: WalMart, Fidelity Investments, Sears, Verizon, USAA, Cardinal Health, Wells Fargo, Procter & Gamble, Cablevision, Nasdaq, AutoTrader, Netflix и Yelp.
Ожидается, что ANSI-совместимые возможности SQL на платформе Hadoop предоставят Hadoop все возможности для того, чтобы стать полезной платформой данных для предприятий, так как эти опции будут знакомы профессионалам в сфере управления данными и доступны на существующих системах. Все это позволит создать песочницу для анализа данных, которая не была доступна ранее.
«Облачная эластичность», возможность синхронизации вычислительных и сетевых мощностей с хранимыми данными станет одним из ключевых факторов для снижения расхода средств, считают эксперты. Поэтому, ожидается, что платформа Hadoop будет все более активно применяться в облачных решениях на фоне растущего спроса на специализированную аналитику.
Весьма вероятным видится появление новых дистрибутивов Hadoop из аналогов от HP, Oracle, SAP, Software AG и Tibco. Microsoft, Red Hat, VMware и другие вендоры операционных систем могут не найти причин для отказа от интеграции платформы в собственные ОС.
Важный фактор влияния — наличие квалифицированных кадров, способных работать с платформой Hadoop. Они должны появиться, считают эксперты. Благодаря их участию станет возможной быстрая и более эффективная реализация проектов Hadoop.
Компоненты популярных дистрибутивов Хадуп для проектов Big Data
В таблице показан компонентный состав экосистемы каждого из анализируемых дистрибутивов Hadoop с учетом их функционального назначения.
|
Дистрибутив |
Общие компоненты |
Файловая система |
Управление кластером, координация, планирование |
Управление интеграцией и потоками данных |
Обеспечение безопасности |
SQL СУБД |
NoSQL СУБД |
Потоковая обработка данных |
Брокер сообщений |
|
|
Hadoop Common, MapReduse, Yarn, Tez,полнотекстовый поиск Solr, язык запросов к слабоструктурированным данным Pig |
Cloudera Manager |
Sqoop, Flume |
Cloudera Navigator Encrypt, Sentry, RecordService |
Hive, Impala, |
Spark Streaming |
Mahout |
||||
|
Hadoop Common, MapReduse, Yarn, Tez,полнотекстовый поиск Solr, язык запросов к слабоструктурированным данным Pig |
Oozie, ZooKeeper, Ambari |
Sqoop, Flume, Falcon, NFC, WebHDFS |
Kerberos, Ranger, Knox |
Hive, HCatalog, |
HBase, Accumlo, |
MLLib |
||||
|
Hadoop Common, MapReduse, Yarn, Tez,полнотекстовый поиск Solr, язык запросов к слабоструктурированным данным Pig |
MapR-FS |
Oozie, ZooKeeper, Sahara |
Sqoop, Flume, Hue, HttpFS |
Kerberos, MapR Native Security |
Drill, Hive, Impala, Spark SQL |
Mahout, GraphX, MLLib |
MapR Event Store |
|||
|
Hadoop Common, MapReduse, Yarn, Tez,полнотекстовый поиск Solr, язык запросов к слабоструктурированным данным Pig |
Oozie, ZooKeeper, Ambari |
Sqoop, Flume, NFC, WebHDFS, |
Atlas, Ranger, Knox |
NiFi, NFC, Flink |
Mahout, Giraph, MLLib |
Вышеприведенная таблица позволяет сделать следующие выводы:
- Практически все дистрибутивы, кроме MapR, содержат 4 основных модуля Apache Hadoop (HDFS, MapReduce, Yarn и Hadoop Common). MapR использует MapR-FS – свою распределенную файловую систему вместо HDFS;
- В состав каждого дистрибутива входит Apache Tez – фреймворк, работающий поверх Hadoop YARN для быстрой обработки групповых и интерактивных данных, которым нужна интеграция с Hadoop YARN, Apache Solr – продукт полнотекстового и фасетного поиска, динамической кластеризации, интеграции с базами данных и обработка документов со сложным форматом, а также Apache Pig – высокоуровневый язык программирования запросов к большим слабоструктурированным наборам данных.
- Каждый дистрибутив содержит средства управления потоками данных Sqoop и Flume, координаторы и планировщики задач (Zookeeper и Oozie), а также реляционную СУБД Hive и NoSQL
- Дистрибутивы отличаются средствами обеспечения безопасности, потоковой обработки данных, машинного обучения и системами распределенных брокеров программных сообщений. Для потоковой обработки MapR и Hortonworks используют Apache Storm, Cloudera — Spark Streaming, а ArenaData — NiFi, NFC, Flink. Инструменты Machine Learning в Cloudera представлены в виде Apache Mahout, в Hortonworks – Apache Spark MLLib, а MapR и ArenaData используют оба этих продукта. Наконец, почти все дистрибутивы, кроме MapR, применяют Apache Kafka для быстрой обработки программных сообщений между приложениями. MapR использует собственную альтернативу — MapR Event Store.
 Использовать уже готовый дистрибутив Apache Hadoop — отличное решение
Использовать уже готовый дистрибутив Apache Hadoop — отличное решение
Подводя итог сходствам и различиям наиболее популярных дистрибутивов Hadoop, следует отметить, что каждый из них может успешно применяться в качестве основы для локальной инфраструктуры Big Data проектов. А, поскольку все они распространяются бесплатно, при выборе следует учитывать стоимость технической поддержки и сопровождения на вашем кластере, а также полноту программной документации
Впрочем, если вы хотите собрать свой Хадуп самостоятельно, обратите внимание на проект Apache Bigtop, о котором мы рассказываем здесь
Как работать со всеми этими и другими инфраструктурными решениями Hadoop для больших данных (развертывание, настройка, администрирование, обеспечение безопасности и использование кластера) узнайте в нашем учебном центре – практические курсы обучения пользователей, инженеров, администраторов и аналитиков Big Data в Москве
- INTR: Основы Hadoop
- HADM: Администрирование кластера Hadoop
- DSEC: Безопасность озера данных Hadoop
- HDDE: Hadoop для инженеров данных
- BAHU: Основы Hadoop для пользователей
Смотреть расписание
Записаться на курс
Источники
- https://ru.wikipedia.org/wiki/Cloudera
- https://m.habr.com/ru/post/151062/
- https://mapr.com/blog/kafka-vs-mapr-streams-why-mapr/
- https://mapr.com/docs/61/MapROverview/c_security.html
- https://arenadata.tech/products/hadoop/
7 главных преимуществ продуктов Arenadata
- Полная локализация: для российских пользователей предлагается поддержка в России и на русском языке, с полным набором возможностей по автоматическому развертыванию в облаке и on-premises, оригинальную документацию на русском языке, а также удаленную или on-site поддержку .
- Возможность offline-установки: пакет утилит для развертывания без доступа к сети Интернет ;
- Автоматизация процессов развертывания как на «голом железе», так и на виртуальных машинах (в «облаке»). В частности, для Arenadata Hadoop средства мониторинга и управления конфигурацией кластера позволяют оптимизировать производительность каждого компонента системы. Apache Ambari обеспечивает интерфейсы для интеграции с существующими системами управления (Microsoft System Center и Teradata ViewPoint) .
- Отсутствие зависимости от производителя («вендор-лог») — дистрибутивы собраны на основе открытых проектов Apache Software Foundation без использования проприетарных компонентов.
- Адаптация для корпоративного использования — продукты ориентированы на эксплуатацию в условиях высоких нагрузок, включают широкие возможности по обеспечению информационной безопасности и защиты данных, а также содержат средства интеграции с другими популярными Big Data решениями, корпоративными информационными системами, база и хранилищами данных.
- Российское программное обеспечение: в 2017 году Минкомсвязь РФ включило Arenadata Hadoop в Единый реестр российских программ для электронных вычислительных машин и баз данных . В 2018 и 2019 аналогичным образом были зарегистрированы ADB и ADS.
- Гибкая ценовая политика — каждый продукт компании Arenadata доступен в двух версиях: бесплатной (community) и платной (enterprise), которые отличаются друг от друга составом компонентов и функциональными возможностями. Бесплатный пакет включает ядро проекта и небольшую часть собственных разработок компании Arenadata. Enterprise-версия представляет собой максимально полное решение, созданное вендором .
Где используются некоторые продукты Аренадата, читайте в отдельной статье.
Источники
- Сайт компании производителя Arenadata
- https://www.ibs.ru/media/news/distributiv-arenadata-hadoop-vklyuchen-v-reestr-rossiyskogo-po/
Что такое Arenadata DB
Arenadata DB (ADB) – это масштабируемая кластерная СУБД на базе аналитической массивно-параллельной системы с открытым исходным кодом Greenplum. Концепция MPP (massively parallel processing, массивно-параллельные вычисления) позволяет надежно хранить и быстро анализировать большие объемы структурированных и слабоструктурированных данных (до сотен терабайт).
В ADB используется полиморфное хранение данных, когда одну таблицу можно разделить на вертикальные разделы (partitions), часть из которых будет храниться в виде строк, а часть – как колоночные объекты. При этом для пользователя такая таблица остается одним объектом .
Информационная безопасность хранения и передачи данных в ADB обеспечивается поддержкой защищенного протокола SSL и шифрованием с помощью ключей PGP (на уровне таблиц или колонок в таблицах), а также ролевой модели доступа к данным (Role Based Access Control, RBAC). Гибкость и производительность при обмене данными с внешними системами реализуется за счет протокола параллельного обмена PXF (Platform eXtension Framework), который обеспечивает взаимодействие с внешней системой одновременно всех сегментов кластера. Отказоустойчивость распределенной СУБД достигается за счет настраиваемой системы резервирования .

Apache Hive и Cloudera Impala: что это и как используется в SQL для Big Data
Прежде всего отметим, что Hive и Impala не конкурируют, а, скорее эффективно дополняют друг друга. Между этими системами довольно много общего, но есть некоторые различия . Прежде всего, отметим их основное назначение и некоторые аспекты, особенно важные для практического использования.
Обе рассматриваемые платформы свободно распространяются под лицензией Apache Software Foundation и относятся к SQL-средствам работы с данными, хранящимися в кластере Hadoop. Помимо распределенной файловой системы Apache Hadoop, HDFS, Hive и Импала обеспечивают интерактивные SQL-запросы к данным, хранящимся в HBase или Amazon Simple Storage Service (S3).
Как правило, Hive используется инженерами данных (Data Engineer) в ETL-процессах (Extract, Transform, Load), например, для длительных пакетных заданий на больших наборах данных, в частности, веб-журналах. В этом случае ключевыми преимуществами Hive являются его масштабируемость (расширяется динамически при добавлении машины к кластеру Hadoop), расширяемость за счет MapReduce и определяемых пользователем функций (UDF/UDAF/UDTF), отказоустойчивость и способность работать с различными форматами входных данных (TEXTFILE, Sequence, ORC и RCFILE, а также Parquet с помощью специального плагина в версиях позже 0.10). При этом Hive не поддерживает интерактивное выполнение запросов в режиме реального времени, а потому не может использоваться в OLTP-задачах .
В свою очередь, Cloudera Impala, предназначенная, главным образом, для аналитиков и ученых по данным (Data Analyst, Data Scientist), представляет собой открытую базу данных для Apache Hadoop. Импала обеспечивает быстрые интерактивные SQL-запросы с низкой временной задержкой (low latency) на лету. В отличие от Hive, где поддерживается вычислительная модель MapReduce, Impala основана на массивно-параллельной архитектуре (MPP, Massively Parallel Processing). MPP активно используется в других аналитических СУБД стека Big Data (Greenplum Database, Arenadata DB, Teradata и др.). Импала работает со многими форматами данных (LZO, Avro, RCFile, Parquet), реализуя распределенные SQL-запросы в кластерной среде, что обусловливает ее высокую скорость работы по сравнению с Хайв . Подробнее про сходства и различия Apache Hive и Impala мы расскажем в следующей статье, а сейчас рассмотрим несколько практических примеров эффективного сочетания этих двух SQL-инструментов в разных Big Data проектах.
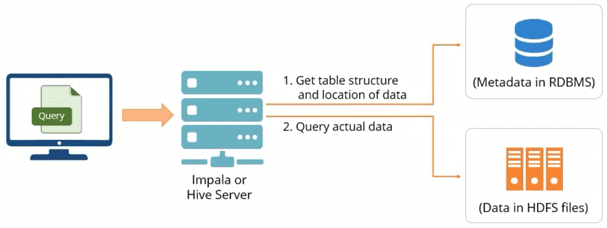 Обработка SQL-запросов в экосистеме Hadoop
Обработка SQL-запросов в экосистеме Hadoop