Начинаем работу с google sheets на python. от регистрации до чтения данных
Содержание:
- Pandas pivot_table() function
- 4 Конвертация одного типа коллекции в другой
- Taking It One Step Further
- Stop and Think
- Создание таблицы
- Everything you’ve always wanted to know about pandas Pivot but were too afraid to ask.
- What is a pivot table?
- How can I pivot a table in pandas?
- Why do I get a value error when pivoting?
- What operations do actually happen when pivoting?
- How can I set missing values to 0?
- Can I calculate multiple statistics at the same time?
- Can I aggregate multiple values at the same time?
- Can I do a breakdown of rows/columns even further?
- Before you go
Pandas pivot_table() function
Pandas pivot_table() function is used to create pivot table from a DataFrame object. We can generate useful information from the DataFrame rows and columns. The pivot_table() function syntax is:
- data: the DataFrame instance from which pivot table is created.
- values: column to aggregate.
- index: the column to group by on the pivot table index.
- columns: the column to group by on the pivot table column.
- aggfunc: the aggregate function to run on the data, default is numpy.mean
- fill_value: value to replace null or missing value in the pivot table.
- margins: add all rows/columns. It’s useful in generating grand total of the records.
- dropna: don’t include columns whose entries are all NaN.
- margins_name: Name of the row / column that will contain the totals when margins is True.
- observed: This only applies if any of the groupers are Categoricals. If True: only show observed values for categorical groupers. If False: show all values for categorical groupers.
4 Конвертация одного типа коллекции в другой
Обратите внимание, что при преобразовании одной коллекции в другую возможна потеря данны:
При преобразовании в множество теряются дублирующие элементы, так как множество содержит только уникальные элементы! Собственно, проверка на уникальность, обычно и является причиной использовать множество в задачах, где у нас есть в этом потребность.
При конвертации индексированной коллекции в неиндексированную теряется информация о порядке элементов, а в некоторых случаев она может быть критически важной!
После конвертации в не изменяемый тип, мы больше не сможем менять элементы коллекции — удалять, изменять, добавлять новые. Это может привести к ошибкам в наших функциях обработки данных, если они были написаны для работы с изменяемыми коллекциями.
Дополнительные детали:
- Способом выше не получится создать словарь, так как он состоит из пар ключ: значение.
Это ограничение можно обойти, создав словарь комбинируя ключи со значениями с использованием zip(): - Создаем строку из другой коллекции:
- Возможная ошибка: Если Ваша коллекция содержит изменяемые элементы (например список списков), то ее нельзя конвертировать в не изменяемую коллекцию, так как ее элементы могут быть только не изменяемыми!
Примечаниев четвертой части циклаShashkovS
- TimeComplexity (aka «Big O» or «Big Oh») (на английском)
- Complexity of Python Operations (на английском)
| Часть 1 | Часть 2 | Часть 3 | Часть 4 |
|---|
Приглашаю к обсуждению:
Если я где-то допустил неточность или не учёл что-то важное — пишите в комментариях, важные комментарии будут позже добавлены в статью с указанием вашего авторства.
Если какие-то моменты не понятны и требуется уточнение — пишите ваши вопросы в комментариях — или я или другие читатели дадут ответ, а дельные вопросы с ответами будут позже добавлены в статью.
Taking It One Step Further
In some cases, you might want to generate separate files per manager or
do some other manipulation. It should be pretty simple to understand
how to do so given the examples above.
To close out this discussion, I decided I would wrap things up with a fully functional
program that utilizes additional python functions to make this script a
truly useful program that utilizes good python programming practices so
that you can scale it up for your own needs:
"""
Sample report generation script from pbpython.com
This program takes an input Excel file, reads it and turns it into a
pivot table.
The output is saved in multiple tabs in a new Excel file.
"""
import argparse
import pandas as pd
import numpy as np
def create_pivot(infile, index_list="Manager", "Rep", "Product"],
value_list="Price", "Quantity"]):
"""
Read in the Excel file, create a pivot table and return it as a DataFrame
"""
df = pd.read_excel(infile)
table = pd.pivot_table(df, index=index_list,
values=value_list,
aggfunc=np.sum, np.mean], fill_value=)
return table
def save_report(report, outfile):
"""
Take a report and save it to a single Excel file
"""
writer = pd.ExcelWriter(outfile)
for manager in report.index.get_level_values().unique():
temp_df = report.xs(manager, level=)
temp_df.to_excel(writer, manager)
writer.save()
if __name__ == "__main__"
parser = argparse.ArgumentParser(description='Script to generate sales report')
parser.add_argument('infile', type=argparse.FileType('r'),
help="report source file in Excel")
parser.add_argument('outfile', type=argparse.FileType('w'),
help="output file in Excel")
args = parser.parse_args()
# We need to pass the full file name instead of the file object
sales_report = create_pivot(args.infile.name)
save_report(sales_report, args.outfile.name)
Stop and Think
As you sit back and think about this code, just take a second to revel in how
much we are doing with 7 lines of code (plus 2 imports):
import pandas as pd
import numpy as np
df = pd.read_excel("sales-funnel.xlsx")
table = pd.pivot_table(df,index="Manager","Rep","Product"], values="Price","Quantity"],aggfunc=np.sum,np.mean],fill_value=)
writer = pd.ExcelWriter('output.xlsx')
for manager in table.index.get_level_values().unique():
temp_df = table.xs(manager, level=)
temp_df.to_excel(writer,manager)
writer.save()
We have just read in an Excel file, created a powerful summary of data, then
broken the data up into an output Excel file with separate tabs for each manager.
Just by using 9 lines of code!
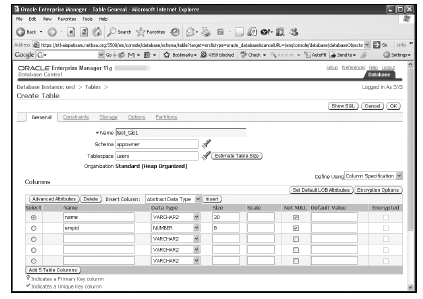
Создание таблицы
Чтобы создать таблицу в SQLite3, выполним запрос Create Table в методе execute(). Для этого выполним следующую последовательность шагов:
- Создание объекта подключения
- Объект Cursor создается с использованием объекта подключения
- Используя объект курсора, вызывается метод execute с запросом create table в качестве параметра.
Давайте создадим таблицу Employees со следующими колонками:
Код будет таким:
В приведенном выше коде определено две функции: первая устанавливает соединение; а вторая — используя объект курсора выполняет SQL оператор create table.
Метод commit() сохраняет все сделанные изменения. В конце скрипта производится вызов обеих функций.
Для проверки существования таблицы воспользуемся браузером БД для sqlite.
Everything you’ve always wanted to know about pandas Pivot but were too afraid to ask.
Roman OracFollow
Apr 15 · 5 min read
Photo by Christian Fregnan on Unsplash
Pandas pivot is an essential tool of every Data Scientist. Some use it daily and others avoid it because it seems complex. I was in the latter group for quite a while. After I took the time and did some research, I felt like I wasted a lot of time writing unnecessary code. To my surprise, I already knew the main building blocks of pandas. It is all simpler than it may seem.

Meme generated with imgflip
I write extensively about Data Analysis with pandas. Take a look at my series:
What is a pivot table?
A pivot table is a table of statistics that summarizes the data of a more extensive table. In practical terms, a pivot table calculates a statistic on a breakdown of values. For the first column, it displays values as rows and for the second column as columns.
Let’s look at the example of a pivot table that calculates sum statistic on a breakdown by fruits and customers:

The left table is the base table for the pivot table on the right.
How can I pivot a table in pandas?
Pandas has a pivot_table function that applies a pivot on a DataFrame. It also supports aggfunc that defines the statistic to calculate when pivoting (aggfunc is np.mean by default, which calculates the average). I use the sum in the example below.
Let’s define a DataFrame and apply the pivot_table function.
df = pd.DataFrame( { "fruit": , "customer": , "quantity": , })
I would like to have a breakdown with fruits in rows (specify index) and customers in columns (specify columns). For each entry, I would like to calculate the summation of quantities. The result is the same as in the table above.
df.pivot_table(index="fruit", columns="customer", values="quantity", aggfunc=np.sum)
Why do I get a value error when pivoting?

Gif from giphy
The most likely reason is that you’ve used the pivot function instead of pivot_table. This confused me many times. Pandas pivot function is a less powerful function that does pivot without aggregation that can handle non-numeric data.
The error “The ValueError: Index contains duplicate entries, cannot reshape” occurred because there are duplicates entries in your DataFrame. If I would pivot the DataFrame above, I would get the same error as apple and ben are duplicated and pivot function doesn’t aggregate.

It helped me to understand this problem when I went through . Basically it does the same as the command below:
df.set_index().unstack()
What operations do actually happen when pivoting?

Gif from giphy
At first, pivoting may seem to you like a hard-to-understand concept. But what if I told you that you were using it all along — at least the commands that are at the core of pivoting in pandas. Let’s look at the command below:
df.groupby().quantity.sum().unstack()
Have you ever used groupby function in pandas? What about the sum command? Yes? I thought so. The output of the above command is the same as of pivot_table.
I haven’t use unstack many times but it basically unpacks multi-index to columns like in the image below

Unstack operation
How can I set missing values to 0?
Say no more! pivot_table has a fill_value argument to replace missing values with. It is None by default. Let’s try it.
df.pivot_table(index="fruit", columns="customer", values="quantity", aggfunc=np.sum, fill_value=0)

Can I calculate multiple statistics at the same time?
The argument aggfunc of pivot_table function takes a list of functions. Let’s try it with sum and mean.
df.pivot_table(index="fruit", columns="customer", values="quantity", aggfunc=, fill_value=0)

Can I aggregate multiple values at the same time?
Gif from giphy
You can! Similar to aggfunc argument, values argument takes a list of column names. Let’s add a price column to the DataFrame.
df =

Now that we have two columns with values, let’s apply pivot_table function:
df.pivot_table(index="fruit", columns="customer", values=, aggfunc=np.mean, fill_value=0)

Can I do a breakdown of rows/columns even further?
The answer is yes yet again. Arguments index and column both take lists. Let’s add column origin of fruit to the DataFrame.
df =

Now, let’s do a breakdown of fruit and origin by rows and customers by column.

It works like a charm!
Before you go
I am building an online business focused on Data Science. I tweet about how I’m doing it. Follow me there to join me on my journey.
These are a few links that might interest you:
- Data Science Nanodegree Program- AI for Healthcare- Autonomous Systems- Your First Machine Learning Model in the Cloud- 5 lesser-known pandas tricks- How NOT to write pandas code- Parallels Desktop 50% off