Методы массивов
Содержание:
- IMPORTXML – парсим данные с веб-страниц
- ПримерыExamples
- JavaScript
- 5.3 Создание подстрок
- LEN – считаем количество символов в ячейке
- SUBSTITUTE – меняем/удаляем пробелы и спецсимволы
- IF – базовая логическая функция
- IMPORTRANGE – импортируем данные из других таблиц
- Примеры
- Описание
- Outside of a Web Session
- Storyline
- re.sub и re.subn
- VLOOKUP – ищем значения в другом диапазоне данных
- Contribute
IMPORTXML – парсим данные с веб-страниц
«Развесистая» функция для парсинга данных с веб-страниц с помощью XPath.
Синтаксис:
=IMPORTXML(«url»;»xpath-запрос»)
Вот лишь несколько вариантов использования этой функции:
- извлечение метаданных из списка URL (title, description), а также заголовков h1-h6;
- сбор e-mail со страниц;
- парсинг адресов страниц в соцсетях.
Пример. Нам нужно собрать содержимое тегов title для списка URL. Запрос XPath, который мы используем для получения этого заголовка, выглядит так: «//title».
Формула будет такой:
=IMPORTXML(A2;»//title»)

IMPORTXML не работает с ARRAYFORMULA, так что вручную копируем формулу во все ячейки.
Вот другие запросы XPath, которые вам будут полезны:
- выгрузить заголовки H1 (и по аналогии – h2-h6): //h1
- спарсить мета-теги description: //meta/@content
- спарсить мета-теги keywords: //meta/@content
- извлечь e-mail адреса: //a/@href
- извлечь ссылки на профили в соцсетях: //a[contains(href, ‘vk.com/’) or contains(href, ‘twitter.com/’) or contains(href, ‘facebook.com/’) or contains(href, ‘instagram.com/’) or contains(href, ‘youtube.com/’)]/@href
Если вам нужно узнать XPath-запрос для других элементов страницы, откройте ее в Google Chrome, перейдите в режим просмотра кода, найдите элемент, кликните по нему правой кнопкой и нажмите Copy / Copy XPath.

ПримерыExamples
Следующая инструкция анализирует разделенный запятыми список значений и возвращает все непустые токены:Parse a comma-separated list of values and return all non-empty tokens:
Функция STRING_SPLIT вернет пустую строку, если между разделителями ничего нет.STRING_SPLIT will return empty string if there is nothing between separator. Condition RTRIM(value) <> » удаляет пустые токены.Condition RTRIM(value) <> » will remove empty tokens.
Таблица Product содержит столбец с разделенным запятыми списком тегов, как показано в следующем примере:Product table has a column with comma-separate list of tags shown in the following example:
| ProductIdProductId | ИмяName | ТегиTags |
|---|---|---|
| 11 | Full-Finger GlovesFull-Finger Gloves | clothing,road,touring,bikeclothing,road,touring,bike |
| 22 | LL HeadsetLL Headset | bikebike |
| 33 | HL Mountain FrameHL Mountain Frame | bike,mountainbike,mountain |
Следующий запрос преобразовывает каждый список тегов и соединяет его с исходной строкой:Following query transforms each list of tags and joins them with the original row:
Результирующий набор:Here is the result set.
| ProductIdProductId | ИмяName | valuevalue |
|---|---|---|
| 11 | Full-Finger GlovesFull-Finger Gloves | clothingclothing |
| 11 | Full-Finger GlovesFull-Finger Gloves | roadroad |
| 11 | Full-Finger GlovesFull-Finger Gloves | touringtouring |
| 11 | Full-Finger GlovesFull-Finger Gloves | bikebike |
| 22 | LL HeadsetLL Headset | bikebike |
| 33 | HL Mountain FrameHL Mountain Frame | bikebike |
| 33 | HL Mountain FrameHL Mountain Frame | mountainmountain |
Примечание
Порядок вывода может меняться и не обязательно совпадает с порядком подстрок во входной строке.The order of the output may vary as the order is not guaranteed to match the order of the substrings in the input string.
В.C. Объединение по значениямAggregation by values
Пользователю необходимо создать отчет, в котором приводится число продуктов по каждому тегу, причем теги упорядочены по числу продуктов, и отфильтрованы теги с более чем двумя продуктами.Users must create a report that shows the number of products per each tag, ordered by number of products, and to filter only the tags with more than two products.
Г.D. Поиск по значению тегаSearch by tag value
Разработчикам необходимо создать запросы для поиска статей по ключевым словам.Developers must create queries that find articles by keywords. Они могут использовать представленные ниже запросы.They can use following queries:
Поиск продуктов с одним тегом (clothing):To find products with a single tag (clothing):
Поиск продуктов с двумя тегами (clothing и road):Find products with two specified tags (clothing and road):
Д.E. Поиск строк по списку значенийFind rows by list of values
Разработчикам необходимо создать запрос, который находит статьи по списку идентификаторов.Developers must create a query that finds articles by a list of IDs. Они могут использовать следующий запрос:They can use following query:
Предыдущее использование STRING_SPLIT является заменой распространенного антишаблона.The preceding STRING_SPLIT usage is a replacement for a common anti-pattern. Такой антишаблон может включать создание динамической строки SQL на прикладном уровне или в Transact-SQL.Such an anti-pattern can involve the creation of a dynamic SQL string in the application layer or in Transact-SQL. Или антишаблон может осуществляться с помощью оператора LIKE.Or an anti-pattern can be achieved by using the LIKE operator. Смотрите следующий пример инструкции SELECT.See the following example SELECT statement:
JavaScript
JS Array
concat()
constructor
copyWithin()
entries()
every()
fill()
filter()
find()
findIndex()
forEach()
from()
includes()
indexOf()
isArray()
join()
keys()
length
lastIndexOf()
map()
pop()
prototype
push()
reduce()
reduceRight()
reverse()
shift()
slice()
some()
sort()
splice()
toString()
unshift()
valueOf()
JS Boolean
constructor
prototype
toString()
valueOf()
JS Classes
constructor()
extends
static
super
JS Date
constructor
getDate()
getDay()
getFullYear()
getHours()
getMilliseconds()
getMinutes()
getMonth()
getSeconds()
getTime()
getTimezoneOffset()
getUTCDate()
getUTCDay()
getUTCFullYear()
getUTCHours()
getUTCMilliseconds()
getUTCMinutes()
getUTCMonth()
getUTCSeconds()
now()
parse()
prototype
setDate()
setFullYear()
setHours()
setMilliseconds()
setMinutes()
setMonth()
setSeconds()
setTime()
setUTCDate()
setUTCFullYear()
setUTCHours()
setUTCMilliseconds()
setUTCMinutes()
setUTCMonth()
setUTCSeconds()
toDateString()
toISOString()
toJSON()
toLocaleDateString()
toLocaleTimeString()
toLocaleString()
toString()
toTimeString()
toUTCString()
UTC()
valueOf()
JS Error
name
message
JS Global
decodeURI()
decodeURIComponent()
encodeURI()
encodeURIComponent()
escape()
eval()
Infinity
isFinite()
isNaN()
NaN
Number()
parseFloat()
parseInt()
String()
undefined
unescape()
JS JSON
parse()
stringify()
JS Math
abs()
acos()
acosh()
asin()
asinh()
atan()
atan2()
atanh()
cbrt()
ceil()
cos()
cosh()
E
exp()
floor()
LN2
LN10
log()
LOG2E
LOG10E
max()
min()
PI
pow()
random()
round()
sin()
sqrt()
SQRT1_2
SQRT2
tan()
tanh()
trunc()
JS Number
constructor
isFinite()
isInteger()
isNaN()
isSafeInteger()
MAX_VALUE
MIN_VALUE
NEGATIVE_INFINITY
NaN
POSITIVE_INFINITY
prototype
toExponential()
toFixed()
toLocaleString()
toPrecision()
toString()
valueOf()
JS OperatorsJS RegExp
constructor
compile()
exec()
g
global
i
ignoreCase
lastIndex
m
multiline
n+
n*
n?
n{X}
n{X,Y}
n{X,}
n$
^n
?=n
?!n
source
test()
toString()
(x|y)
.
\w
\W
\d
\D
\s
\S
\b
\B
\0
\n
\f
\r
\t
\v
\xxx
\xdd
\uxxxx
JS Statements
break
class
continue
debugger
do…while
for
for…in
for…of
function
if…else
return
switch
throw
try…catch
var
while
JS String
charAt()
charCodeAt()
concat()
constructor
endsWith()
fromCharCode()
includes()
indexOf()
lastIndexOf()
length
localeCompare()
match()
prototype
repeat()
replace()
search()
slice()
split()
startsWith()
substr()
substring()
toLocaleLowerCase()
toLocaleUpperCase()
toLowerCase()
toString()
toUpperCase()
trim()
valueOf()
5.3 Создание подстрок
Кроме сравнения строк и поиска подстрок, есть еще одно очень популярное действие — получение подстроки из строки. В предыдущем примере вы как раз видели вызов метода , который возвращал часть строки.
Вот список из 8 методов получения подстрок из текущей строки:
| Методы | Описание |
|---|---|
| Возвращает подстроку, заданную интервалом символов . | |
| Повторяет текущую строку n раз | |
| Возвращает новую строку: заменяет символ на символ | |
| Заменяет в текущей строке подстроку, заданную регулярным выражением. | |
| Заменяет в текущей строке все подстроки, совпадающие с регулярным выражением. | |
| Преобразует строку к нижнему регистру | |
| Преобразует строку к верхнему регистру | |
| Удаляет все пробелы в начале и конце строки |
Вот краткое описание существующих методов:
Метод
Метод возвращает новую строку, которая состоит из символов текущей строки, начиная с символа под номером и заканчивая . Как и во всех интервалах в Java, символ с номером в интервал не входит. Примеры:
| Код | Результат |
|---|---|
Если параметр не указывается (а так можно), подстрока берется от символа beginIndex и до конца строки.
Метод
Метод repeat просто повторяет текущую строку раз. Пример:
| Код | Результат |
|---|---|
Метод
Метод возвращает новую строку, в которой все символы заменены на символ . Длина строки при этом не меняется. Пример:
| Код | Результат |
|---|---|
Методы и
Метод заменяет все вхождения одной подстроки на другую. Метод заменяет первое вхождение переданной подстроки на заданную подстроку. Строка, которую заменяют, задается регулярным выражением. Разбирать регулярные выражения мы будем в квесте Java Multithreading.
Примеры:
| Код | Результат |
|---|---|
Методы
С этими методами мы познакомились, когда только в первый раз учились вызывать методы класса .
Метод
Метод удаляет у строки пробелы с начала и с конца строки. Пробелы внутри строки никто не трогает. Примеры:
| Код | Результат |
|---|---|
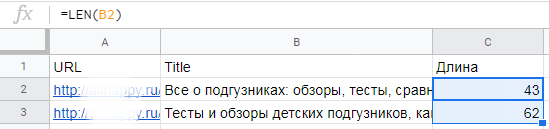
LEN – считаем количество символов в ячейке
Эта функция особенно полезна при составлении объявлений контекстной рекламы – когда важно не заступать за отведенное количество символов для заголовков, описаний, отображаемых URL, быстрых ссылок и уточнений

В SEO функция LEN применяется, например, при составлении мета-тегов title и description. Символы функция считает с пробелами.
Синтаксис:
=LEN(ячейка с текстом)
Пример. Нам нужно составить тайтлы для всех страниц сайта. Мы знаем, что в результатах поиска отображается около 55 символов. Наша задача – составить тайтлы так, чтобы самая важная информация была в первых 55 символах. Прописываем формулу LEN для заполняемых ячеек. Теперь мы точно знаем, когда приближаемся к отображаемым 55 символам.
SUBSTITUTE – меняем/удаляем пробелы и спецсимволы
Универсальная функция замены/удаления символов в ячейках.
Синтаксис:
=SUBSTITUTE(где искать;»что искать»;»на что менять»;номер соответствия)
Номер соответствия – порядковый номер встреченного значения на замену, например, первое встреченное заменить, остальные оставить. Опциональный параметр.
Пример. У нас есть выгрузка ключевых фраз из Яндекс.Вордстат. Многие ключи содержат плюсики. Нам нужно их удалить.
Формула будет иметь вид:
=SUBSTITUTE(B12;»+»;»»;)
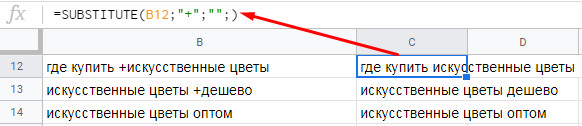
Что мы сделали:
- где искать – указали ячейку с данными;
- «что искать» – указали плюсик, который нужно удалить;
- «на что менять» – поскольку символ нужно удалить, мы указали кавычки без символов внутри; если бы нам нужна была замена, здесь бы мы прописали текст, на который нужно заменить плюсик;
- номер соответствия – здесь мы ничего не указали, и функция удалит все плюсы в фразе; если бы мы указали 1, то функция удаляла бы только первый плюсик, если 2 – второй и т. д.
IF – базовая логическая функция
Это одна из базовых функций, знакомых вам по Excel. Она помогает при решении разных SEO-задач. Формула IF выводит одно значение, если логическое выражение истинное, и другое – если оно ложное.
Синтаксис:
=IF(логическое_выражение;»значение_истина»;»значение_ложь»)
Пример. Есть список ключей с частотностями. Наша цель – занять ТОП-3. При этом мы хотим выбрать только такие ключи, каждый из которых приведет нам минимум 300 посетителей в месяц.
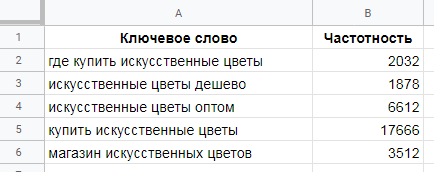
Определяем, какая доля трафика приходится на третью позицию в органике. Для этого заходим в сервис Advanced webranking и видим, что третья позиция приводит около 10% трафика из органики (конечно, эта цифра неточная, но это лучше, чем ничего).

Составляем выражение IF, которое будет возвращать значение 1 для ключей, который приведут минимум 300 посетителей, и 0 – для остальных ключей:
=IF(B2*0.1>=300;»1″;»0″)
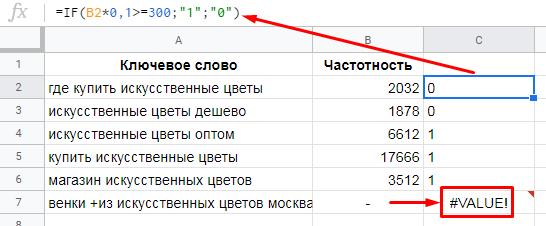
Обратите внимание, в строке 7 формула выдала ошибку, поскольку значение частотности задано в неверном формате. Для подобных ситуаций есть продвинутая версия функции IF – IFERROR
Важно: использование в формуле запятой или точки для десятичных дробей определено в настройках ваших таблиц
IMPORTRANGE – импортируем данные из других таблиц
Функция позволяет вставить в текущий файл данные из других таблиц.
Синтаксис:
=IMPORTRANGE(«ссылка на документ»;»ссылка на диапазон данных»)
Пример:
=IMPORTRANGE(«https://docs.google.com/spreadsheets/d/ХХХХХХХХ/»,»имя листа!A2:A25″)
Пример. Вы продвигаете сайт клиента. Над проектом работает три специалиста: линкбилдер, SEO-специалист и копирайтер. Каждый ведет свой отчет. Клиент заинтересован отслеживать процесс в режиме онлайн. Вы формируете для него один отчет с вкладками: «Ссылки», «Позиции», «Тексты». На эти вкладки с помощью функции IMPORTRANGE подтягиваются данные по каждому направлению.

Преимущество функции в том, что вы открываете доступ только к конкретным листам. При этом внутренние части отчетов специалистов остаются недоступны для клиентов.
Примеры
Пример: использование метода
В следующем примере определяется функция, которая разбивает строку на массив строк, используя указанный разделитель. После разбиения строки, функция отображает сообщения, показывающие оригинальную строку (до разбиения), используемый разделитель, количество элементов в массиве и сами эти элементы.
function splitString(stringToSplit, separator) {
var arrayOfStrings = stringToSplit.split(separator);
console.log('Оригинальная строка: "' + stringToSplit + '"');
console.log('Разделитель: "' + separator + '"');
console.log('Массив содержит ' + arrayOfStrings.length + ' элементов: ' + arrayOfStrings.join(' / '));
}
// Строчка из «Бури» Шекспира. Перевод Миxаила Донского.
var tempestString = 'И как хорош тот новый мир, где есть такие люди!';
var monthString = 'Янв,Фев,Мар,Апр,Май,Июн,Июл,Авг,Сен,Окт,Ноя,Дек';
var space = ' ';
var comma = ',';
splitString(tempestString, space);
splitString(tempestString);
splitString(monthString, comma);
Пример сгенерирует следующий вывод:
Оригинальная строка: "И как хорош тот новый мир, где есть такие люди!" Разделитель: " " Массив содержит 10 элементов: И / как / хорош / тот / новый / мир, / где / есть / такие / люди! Оригинальная строка: "И как хорош тот новый мир, где есть такие люди!" Разделитель: "undefined" Массив содержит 1 элементов: И как хорош тот новый мир, где есть такие люди! Оригинальная строка: "Янв,Фев,Мар,Апр,Май,Июн,Июл,Авг,Сен,Окт,Ноя,Дек" Разделитель: "," Массив содержит 12 элементов: Янв / Фев / Мар / Апр / Май / Июн / Июл / Авг / Сен / Окт / Ноя / Дек
Пример: удаление пробелов из строки
В следующем примере метод ищет 0 или более пробелов, за которыми следует точка с запятой, за которой снова следуют 0 или более пробелов, и, если этот шаблон найден, удаляет пробелы из строки. Переменная является массивом, возвращённым в результате работы метода .
var names = 'Гарри Трамп ;Фрэд Барни; Хелен Ригби ; Билл Абель ;Крис Ханд '; console.log(names); var re = /\s*;\s*/; var nameList = names.split(re); console.log(nameList);
Пример напечатает две строки; на первой строке напечатана оригинальная строчка, а на второй — получившийся массив.
Гарри Трамп ;Фред Барни; Хелен Ригби ; Билл Абель ;Крис Ханд Гарри Трамп,Фред Барни,Хелен Ригби,Билл Абель,Крис Ханд
Пример: возврат ограниченного числа подстрок
В следующем примере метод ищет 0 или более пробелов в строке и возвращает первые три найденных подстроки.
var myString = 'Привет, мир. Как дела?';
var splits = myString.split(' ', 3);
console.log(splits);
Вывод скрипта будет следующим:
Привет,мир.,Как
Пример: захват подгрупп
Если параметр содержит подгруппы, сопоставившиеся результаты также будут присутствовать в возвращённом массиве.
var myString = 'Привет 1 мир. Предложение номер 2.'; var splits = myString.split(/(\d)/); console.log(splits);
Вывод скрипта будет следующим:
Привет ,1, мир. Предложение номер ,2,.
Пример: обращение строки при помощи метода
var str = 'фывапролд';
var strReverse = str.split('').reverse().join(''); // 'длорпавыф'
// split() возвращает массив, к которому применяются методы reverse() и join()
Описание
Метод split() используется для разбиения строки на массив подстрок и возвращает новый массив.
Если разделитель separator найден, он удаляется из строки, а подстроки возвращаются в массиве. Следует
отметить, что если разделитель separator соответствует началу строки, первый элемент возвращаемого массива будет пустой строкой – текстом, присутствующим перед разделителем separator. Аналогично, если разделитель соответствует концу строки, последний элемент массива (если это не противоречит значению аргумента limit) будет пустой строкой.
Если разделитель separator опущен, строка вообще не разбивается, и возвращаемый массив содержит только один строковый элемент, представляющий собой строку целиком.
Если разделитель представляет собой пустую строку «» или регулярное выражение, соответствующее пустой строке, то строка разбивается между каждым символом, а возвращаемый массив имеет ту же длину, что и исходная строка.
Если разделитель separator – это регулярное выражение, содержащее подвыражения в скобках, то подстроки, соответствующие этим подвыражениям (кроме текста, соответствующего регулярному выражению в целом), включаются в возвращаемый массив.
Примечание: Если строка является пустой строкой, метод split() вернёт массив, состоящий из одной пустой строки, а не пустой массив.
Outside of a Web Session
Split provides the Helper module to facilitate running experiments inside web sessions.
Alternatively, you can access the underlying Metric, Trial, Experiment and Alternative objects to
conduct experiments that are not tied to a web session.
# create a new experiment
experiment = Split::ExperimentCatalog.find_or_create('color', 'red', 'blue')
# create a new trial
trial = Split::Trial.new(:experiment => experiment)
# run trial
trial.choose!
# get the result, returns either red or blue
trial.alternative.name
# if the goal has been achieved, increment the successful completions for this alternative.
if goal_achieved?
trial.complete!
end
Storyline
Though Kevin (James McAvoy) has evidenced 23 personalities to his trusted psychiatrist, Dr. Fletcher (Betty Buckley), there remains one still submerged who is set to materialize and dominate all of the others. Compelled to abduct three teenage girls led by the willful, observant Casey, Kevin reaches a war for survival among all of those contained within him — as well as everyone around him — as the walls between his compartments shatter.
Written by
alexanderfire-00074
Plot Summary
|
Plot Synopsis
Plot Keywords:
multiple personality disorder
|
psychological thriller
|
kidnapping
|
teenage girl
|
villain played by lead actor
| See All (336) »
re.sub и re.subn
Следующий метод
re.sub(pattern,
repl, string, count, flags)
-
pattern
– регулярное
выражение; -
repl – строка или
функция для замены найденного выражения; -
string
– анализируемая
строка; -
count – максимальное
число замен (если не указано, то неограниченно); -
flags – набор флагов
(по умолчанию не используются).
Выполняет замену
в строке найденных совпадений строкой или результатом работы функции repl и возвращает
преобразованную строку.
В качестве
примера с помощью метода sub преобразуем вот такой текст:
text = """Москва Казань Тверь Самара Уфа"""
в список формата
HTML:
<option>Москва</option> <option>Казань</option> <option>Тверь</option> <option>Самара</option> <option>Уфа</option>
Для этого
запишем вот такой шаблон и следующим параметром порядок замены найденных
вхождений:
list = re.sub(r"\s*(\w+)\s*", r"<option>\1</option>\n", text) print(list)
Обратите
внимание, в строке замены repl мы можем использовать ссылки на
сохраняющие группы. В данном случае ссылка \1 содержит выделенный город из
текста
Затем эта строка окаймляется тегами \1 и
получается искомый список.
Но, кроме строки
можно передавать ссылку на функцию, которая должна возвращать строку,
подставляемую вместо найденного вхождения. Например, добавим тегам option
атрибут
value:
<option
value=’1′>Москва</option>
<option
value=’2′>Казань</option>
<option value=’3′>Тверь</option>
<option
value=’4′>Самара</option>
<option
value=’5′>Уфа</option>
Для этого
вначале определим функцию:
count =
def replFind(m):
global count
count += 1
return f"<option value='{count}'>{m.group(1)}</option>\n"
В качестве
параметра она принимает ссылку на объект re.Match, в котором
хранится информация о найденном совпадении. И далее формируется строка с
атрибутом value, причем,
значение этого атрибута каждый раз увеличивается на 1.
Укажем ссылку на
эту функцию в методе sub:
list2 = re.sub(r"\s*(\w+)\s*", replFind, text)
Все, теперь при
каждой замене будет вызываться функция replFind и возвращать
сформированную строку.
Аналогично
работает и метод
subn(pattern,
repl, string, count, flags)
Только он
возвращает не только преобразованную строку, но и число произведенных замен:
list, total = re.subn(r"\s*(\w+)\s*", r"<option>\1</option>\n", text) print(list, total)
VLOOKUP – ищем значения в другом диапазоне данных
Функция выполняет поиск ключа в первом столбце диапазона и возвращает значение указанной ячейки в найденной строке.
Синтаксис:
=VLOOKUP(запрос;диапазон;номер_столбца;)
Пример 1. Есть два массива ключевых фраз, полученных из разных источников. Нужно найти ключи в первом массиве, которые не встречаются во втором массиве. Для этого используем формулу:
=VLOOKUP(A2:A;B2:B;1;false)

Что мы сделали:
- задали диапазон A2:A, из которого берем ключи для сравнения;
- задали диапазон B2:B, с которым сравниваем ключи из столбца А;
- задали номер столбца (1), из которого подтягиваем ключи при совпадениях;
- false – указали, что сортировка нам не нужна.
Функция VLOOKUP часто используется при поиске данных на разных листах или в разных документах.
Пример 2. Мы выгрузили данные из Яндекс.Вебмастера и Google Search Console об индексации страниц сайта. Наша задача – сопоставить данные и определить, какие страницы индексируются в одном поисковике, но не индексируются в другом.
Заносим результаты выгрузок в файл Google Sheets. На одном листе – URL из Google, на втором – из Яндекса.

В ячейке C2 прописываем функцию VLOOKUP. Сразу заключаем в функцию в ARRAYFORMULA для автоматического протягивания вниз:
=ARRAYFORMULA(VLOOKUP(A2:A;Yandex!A2:A;1;false))

Теперь мы сразу видим, какие страницы проиндексированы в Google, но не проиндексированы в Яндексе.
Что мы сделали:
- задали диапазон A2:A текущего листа, из которого берем значение для сравнения;
- задали диапазон Yandex!A2:A листа с выгрузкой из Яндекса, с которым будем сравнивать значения URL из Google;
- указали номер столбца листа с выгрузкой из Яндекса, значения из которого подтягиваем при совпадении значений из сравниваемых диапазонов;
- false – указали, что сортировка нам не нужна.
Если же вам нужно проверить одновременно индексацию конкретных страниц в Яндексе и Google, воспользуйтесь инструментом от PromoPult. Загрузите список URL и запустите проверку. Если страница проиндексирована в поисковике, в столбце будет цифра 1, если нет – 0.
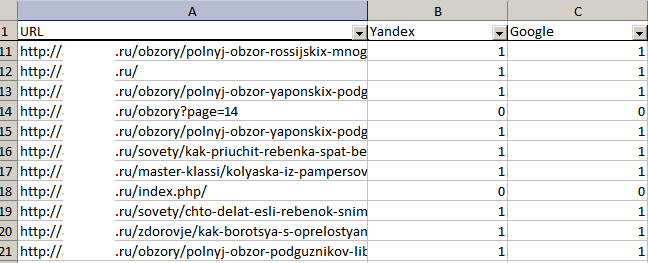
Каким пользоваться этим инструментом и в каких ситуациях он полезен, читайте в этом гайде.
Contribute
Please do! Over 70 different people have contributed to the project, you can see them all here: https://github.com/splitrb/split/graphs/contributors.
The source code is hosted at GitHub.
Report issues and feature requests on GitHub Issues.
A Note on Patches and Pull Requests
- Fork the project.
- Make your feature addition or bug fix.
- Add tests for it. This is important so I don’t break it in a
future version unintentionally. - Add documentation if necessary.
- Commit. Do not mess with the rakefile, version, or history.
(If you want to have your own version, that is fine. But bump the version in a commit by itself, which I can ignore when I pull.) - Send a pull request. Bonus points for topic branches.
Code of Conduct
Please note that this project is released with a Contributor Code of Conduct. By participating in this project you agree to abide by its terms.