Настройка поиска sphinx для интернет-магазина
Содержание:
- Автоматическое содержание¶
- Раздел index в sphinx.conf
- Поиск от Яндекса и его минусы
- 3: Настройка Sphinx
- Как это работает
- Установка и настройка
- Дополнительные конструкции¶
- 6: Тестирование
- MySQL или Sphinx?
- Вставка формул¶
- Быстрый старт¶
- Установка и настройка Sphinx на Linux
- Feature list
- 4: Управление индексом
- Вступление
- Заключение
Автоматическое содержание¶
Стандартная разметка ReST поддерживает создание в отдельных документах автоматического содержания на основе заголовков. Sphinx расширяет данную функцию и позволяет автоматически создавать общее оглавление для группы документов.
Файл обычно содержит автоматическое оглавление, созданное командой :
.. toctree:: maxdepth 2 numbered hidden имя_документа1 имя_документа1 имя_документа1
Команда имеет несколько параметров:
- — уровни заголовков, включаемых в оглавление;
- — нумерация всех пунктов оглавления;
- — позволяет скрыть оглавление.
После параметров через пустую строку, с отступами, идут названия включаемых файлов, без расширения. Данные названия будут автоматически преобразованы в заголовки разделов.
Параметр не распространяется на LaTeX-документы. Глубина оглавления в LaTeX контролируется его внутренним счетчиком, который можно настроить в файле конфигурации Sphinx , указав в преамбуле значение .
Параметр позволяет Sphinx’у быть в курсе структуры документа, но при этом не отображать оглавление. Удобно, если ссылки на разделы будут указаны, например, на боковой панели.
Раздел index в sphinx.conf
morphology = stem_enru
Морфология решает мою первою задачу. Поиск ‘подшипники’, ‘подшипника’, ‘подшипников’ приведет к единому результату.
Стэммы (stem_enru) быстрее, леммы (lemmatize_ru) точнее. Я пробовал только стэммы. Выбор повлияет на ваш словарь замен wordforms. Захотите поменять — придется переписывать.
min_word_len = 1
Индексируем слова любой длины.
html_strip = 1
Удаляем html тэги
min_infix_len = 1
Поиск будет по фрагменту слова. Проиндексируем фрагменты вплоть до 1 буквы. Так как база у меня менее 10000 наименований, то на индексе не экономлю.
expand_keywords = 1
Автоматически приводит запрос к виду «( running | running | =running )». min_infix_len и expand_keywords приведут, к тому что запрос RV 2205 выдаст RV2205. Кстати, тире – это разделитель эквивалентный пробелу. Так что RV-2205 то же выдаст RV2205.
charset_table = 0..9, A..Z->a..z, _, a..z, U+410..U+42F->U+430..U+44F, U+430..U+44F, U+401->U+0435, U+451->U+0435
Приводим латиницу и кириллицу в нижний регистр. Ё заменяем на е.
blend_chars = +, &, U+2C, U+2E
У меня много нецелых чисел. Их надо индексировать полностью. U+2C и U+2E это точка и запятая. Например, 1.25 будет индексирован как ‘1.25’, ‘1’ и ’25’.
regexp_filter = (\d+)\,(\d+) => \1.\2
Десятичные знаки в числах могут быть разделены точками и запятыми: «1,75», «1.75». Приведем все к точке
Синонимы и опечатки
Единицы измерения можно писать по русски или английски: мм-mm, мАч-mAh, мВт-mW. Добавляем в словарь синонимов, путь к которому указан в wordforms: «мач > mah». Язык для индекса выбираю по собственным предпочтениям.
Знак ~ указывает применять замену после обработчика морфологии. Это позволяет не писать все словоформы и вместо правил для ‘корка’, ‘корку’, ‘корки’ написать «~корк > кузов»
Мой список полностью:
Прилипание букв к цифрам
Иногда числа это часть названия (например LCD5208D), но чаще характеристика (100mAh, 10x15x4мм). Отделяем все числа от букв и индексируем.
Это решит несколько задач:
- Кто-то будет искать ‘подшипник 10x15x4’, кто-то ‘подшипник 15x10x4’. Проиндексированные числа приведут к правильной выдаче.
- Единицы измерения могут быть или не быть отделены пробелом от числа: «1.75мм», «1.75 мм».
- Для названий это тоже полезно. Правильная выдача будет по трем вариантам записи LCD-5208, LCD 5208 и LCD5208
Прежде чем написать регулярное выражение для отделения чисел, нужно унифицировать разделители
Важно помнить, что регулярные выражения выполняются все и последовательно
Уберем икс, хэ и звезду в размерах типа 10х15х4 M3x10:
Отбросим хвосты:
И головы:
Отбросим «мм», так как они часто не указаны в названии товара.
Сделаем файл stop.txt и пропишем его в stopwords.
Содержимое:
Поиск от Яндекса и его минусы
Позже я узнал про поиск от Яндекса, который без особого труда можно прикрутить к своему сайту используя Yandex XML Search API. К моему движку был написан модуль для осуществления поиска используя Yandex XML Search API и казалось бы все просто супер но со временем меня начали не устраивать некоторые ограничения и неудобства при работе с Yandex XML Search.
Вот что мне показалось неудобным при использовании Yandex XML Search API:
- ограничение на количество запросов в сутки, а потом еще сделали график ограничений для разного времени суток. Хотите уменьшить ограничения…отправьте СМС на номер…шутка, можно стать партнером Яндекса, для аккаунта зарегистрироваться в партнерской сети Яндекс Директ (РСЯ), связаться с поддержкой Яндекса и рассказать им зачем вам нужно большое количество запросов к Yandex XML Search API.
- поиск производится только по контенту, который проиндексирован Яндексом. Если странички нет в индексе Яндекса — ее вы никогда не увидите в поисковой выдаче своего сайта.
- привязка сайта к стороннему сервису, зависимость поиска от него.
3: Настройка Sphinx
Конфигурации Sphinx должны храниться в файле sphinx.conf в каталоге /etc/sphinxsearch. Они состоят из трёх основных блоков: index, searchd и source. Описание каждого из них и общий вид конфигурационного файла можно найти ниже.
Для начала создайте конфигурационный файл:
Примечание: После описания каждого блока настроек можно найти полный код для sphinx.conf.
Блок source содержит тип источника данных, имя пользователя и пароль MySQL. Первый столбец sql_query должен содержать уникальный ID. Запрос SQL будет выполняться для каждого индекса, а затем передавать данные в индексный файл Sphinx. Блок source состоит из таких полей:
- type: тип источника данных. В данном случае это mysql (также система поддерживает типы pgsql, mssql, xmlpipe2, odbc и т.д.).
- sql_host: имя хоста MySQL; в данном случае это localhost. В это поле нужно внести домен или IP-адрес.
- sql_user: имя пользователя MySQL (в данном случае это root).
- sql_pass: пароль MySQL.
- sql_db: имя БД, в которой хранятся нужные данные (в этом руководстве – test).
- sql_query: запрос, который сбрасывает данные в индексный файл.
Блок source выглядит так:
Блок index содержит данные об источнике и путь к местонахождению данных.
- source: имя блока source. В данном случае это src1.
- path: путь к индексному файлу.
Этот блок выглядит так:
Блок searchd содержит порты и переменные для запуска демона Sphinx.
- listen: порт, на котором нужно запустить Sphinx, и используемый протокол (в руководстве – 9306:mysql41). Популярные протоколы Sphinx — sphinx (SphinxAPI) и :mysql41 (SphinxQL).
- query_log: путь к логу запросов.
- pid_file: путь к PID-файлу Sphinx.
- max_matches: максимальное количество совпадений, которое нужно выводить за один раз.
- seamless_rotate: предотвращает останов searchd при кэшировании большого объема данных.
- preopen_indexes: указывает, нужно ли предварительно открывать все индексы.
- unlink_old: указывает, нужно ли отключить старые копии индекс-файлов.
Ниже приведены все конфигурации файла sphinx.conf. Вы можете просто скопировать и вставить их в свой файл. Единственная переменная, которую нужно отредактировать – это sql_pass в блоке source; укажите в ней свой пароль mysql.
Больше конфигураций можно найти в файле /etc/sphinxsearch/sphinx.conf.sample, который содержит подробное описание всех переменных.
Как это работает
На сервер ставится поисковый демон Sphinx, который индексирует через заданный промежуток времени статьи и контент вашего сайта — создает поисковый индекс.
На вашем сайте подключается Sphinx API, который есть для Java, PHP, Ruby (можно написать реализацию и для других языков), пишется поисковый модуль который делает несложные запросы к демону(сервису) Sphinx — searchd.
При запросе поисковой фразы с поисковой формы сайта через Sphinx API делается обращение к демону searchd, который нам возвращает ID записей с нужной сортировкой и фильтрацией. Дальше имея ID публикаций мы делаем один запрос к БД сайта и получаем всю информацию о наших статьях, остается только красиво вывести список найденных элементов.
Установка и настройка
Установка выполняется в командной строке и не представляет сложностей (см. листинг 3).
Листинг 3. Установка Sphinx
$ easy_install sphinx Searching for sphinx Reading http://pypi.python.org/simple/sphinx/ Reading http://sphinx.pocoo.org/ Best match: Sphinx 1.0.5 Downloading http://pypi.python.org/packages/ Processing Sphinx-1.0.5-py2.5.egg Finished processing dependencies for sphinx
Для краткости в листинге 3 приведена лишь часть вывода, но из него видно, что происходит во время инсталляции Sphinx.
Для хранения исходных (в обычном текстовом формате) и конечных (т. е. сгенерированных в том или ином формате) файлов в Sphinx используются различные директории. Например, если мы создаем в Sphinx PDF-файл из исходного текстового файла, то PDF-файл будет сохранен в директорию build. Эту конфигурацию можно изменить, но во избежание путаницы мы будем использовать настройки по умолчанию.
Давайте сразу приступим к созданию нового проекта (см. листинг 4). В процессе вам будет предложено ответить на несколько вопросов. Нажимайте клавишу Enter, чтобы принять все значения по умолчанию.
Листинг 4. Выполнение команды sphinx-quickstart
$ sphinx-quickstart Welcome to the Sphinx 1.0.5 quickstart utility. Please enter values for the following settings (just press Enter to accept a default value, if one is given in brackets).
В качестве имени проекта я выбрал имя «My Project»; оно несколько раз будет упоминаться в оставшейся части статьи. Вы можете выбрать любое другое имя.
После выполнения команды в вашей рабочей директории должны появиться файлы, аналогичные файлам в листинге 5.
Листинг 5. Содержимое рабочей директории
. ├── Makefile ├── _build ├── _static ├── conf.py └── index.rst
Рассмотрим каждый из этих файлов подробнее.
- Makefile: разработчики, которым приходилось компилировать код, должны быть знакомы с этим файлом. В противном случае просто знайте, что этот файл содержит инструкции для генерации результирующего документа командой .
- _build: это директория, в которую будут помещены файлы в определенном формате после того, как будет запущен процесс их генерации.
- _static: в эту директорию помещаются все файлы, не являющиеся исходным кодом (например, изображения). Позже создаются связи этих файлов с директорией build.
- conf.py: это файл Python, содержащий конфигурационные параметры Sphinx, включая те, которые были выбраны при запуске в окне терминала.
- index.rst: это корень проекта. Он соединяет документацию воедино, если она разделена на несколько файлов.
Дополнительные конструкции¶
Глоссарий
Sphinx позволяет создавать глоссарий с автоматической сортировкой. Элементы глоссария также автоматически попадают в алфавитный указатель.
.. glossary::
sorted
Трансценденция
Философский термин, характеризующий то, что
принципиально недоступно опытному познанию
или не основано на опыте.
Бозон
Частица с целым значением спина.
Результат:
- Бозон
- Частица с целым значением спина.
- Трансценденция
- Философский термин, характеризующий то, что принципиально недоступно опытному познанию или не основано на опыте.
За автоматическую сортировку отвечает параметр .
Аббревиатуры вставляются следующим образом, например, LIFO:
:abbr:`LIFO (last-in, first-out)`
Пункты меню
Для обозначения пунктов меню используются команды и :
:menuselection:`Файл --> О&ткрыть` :guilabel:`&Открыть`
- Файл ‣ Открыть
- Открыть
Символ устанавливает в зависити от темы HTML следующему за ним символу нижнее подчеркивание.
Автозамены Sphinx (Подстановки)
Sphinx вводит ряд автозамен, которые не требуют объявления, их значения берутся из конфигурационного файла .
Номер релиза |release| Номер версии |version| Текущая дата |today|
Номер релиза: 1.0
Номер версии: 1.0
Текущая дата: окт. 08, 2017
О настройке этих параметров смотрите в пунктах и .
Боковая врезка
Боковая врезка добавляетяс командой
.. sidebar:: Боковая врезка Оформление врезки зависит от используемой HTML-темы.
Боковая врезка
Оформление врезки зависит от используемой HTML-темы.
Рубрики
Рубрики создаютcя командой и используются для создания заголовков, не включаемых в общее содержание.
.. rubric:: Пример рубрики Текст рубрики
Пример рубрики
Текст рубрики
Горизонтальный список
.. hlist:: columns 3 * A list of * short items * that should be * displayed * horizontally
|
|
Note
Здесь приведен не полный перечень дополнительных конструкций Sphinx, подробнее в разделе Inline markup и Paragraph-level markup официальной документации Sphinx.
6: Тестирование
Теперь попробуйте найти данные с помощью Sphinx. Подключитесь к SphinxQL с помощью интерфейса MySQL (командная строка изменится на mysql>).
Попробуйте найти предложение:
Команда вернёт:
Как видите, система Sphinx обнаружила два совпадения из индекса test1. Команда SHOW META; показывает соответствия каждого ключевого слова в предложении.
Попробуйте выполнить поиск по ключевым словам:
Команда вернёт:
В индексе test1 система Sphinx нашла:
- 5 совпадений в 3 документах для ключа test.
- 2 совпадения в 1 документе для ключа one.
- 0 совпадений в 0 документах для ключа three.
Закройте оболочку MySQL:
MySQL или Sphinx?
Зачем заменять MySQL на Sphinx? Рассмотрим, например, поисковое приложение книготорговца. Пользователь может искать книги по названию, автору, состоянию (новая или букинистическая), изданию (первое или последующие), обложке (жесткая или мягкая), издательству, году издания, наличию автографа, цене и т.п. В MySQL, как правило, не используется более одного индекса (исключение составляет оптимизация со слиянием индексов;см. раздел ), так что единственным способом оптимизировать все возможные виды поиска было бы введение чрезмерного числа многостолбцовых индексов, что не есть хорошо.
Sphinx представляет собой поисковую систему, которая хорошо интегрируется с MySQL и работает в автономном режиме. Она обеспечивает высокую производительность индексации и поиска, позволяя делать запросы с помощью SphinxQL, языка на основе Structured Query Language (SQL). Наконец, Sphinx хорошо масштабируется, позволяя работать с миллиардами документов, охватывающих терабайты данных с возможностью распределенного поиска.
Sphinx работает с документами (которые могут быть простыми записями в таблице базы данных или представлениями), текстовыми полями (которые он индексирует, обеспечивая возможность полнотекстового поиска) и атрибутами (нетекстовыми значениями, которые можно использовать для фильтрации, сортировки и группирования результатов). Для повышения эффективности атрибуты хранятся в оперативной памяти (RAM); формула для расчета фактического размера содержится в документации по Sphinx (см. раздел ).
Для обработки запросов Sphinx использует специальные индексные файлы. Для процедуры индексирования нужно определить источники данных, а затем запустить программу . Другая возможность — использование индексных файлов реального времени, которые можно динамически обновлять ценой некоторого снижения эффективности. Ниже мы рассмотрим это подробнее.
Вставка формул¶
Вставка формул в предложение:
Формула в предложении :math:`a^2 + b^2 = c^2`.
Формула в предложении .
Выравнивание формул относительно знака равно осуществляется с помощью знака . Перенос строк с помощью :
.. math::
(a + b)^2 &= (a + b)(a + b) \\
&= a^2 + 2ab + b^2
Нумерация формул
Для нумерации формул необходимо использовать параметр :
.. math:: e^{i\pi} + 1 = 0
:label: euler
Формула :eq:`euler` представляет собой Тождество Эйлера.
(1)
Формула представляет собой Тождество Эйлера.
Расположение номера относительно формулы зависит от настроек HTML-темы.
Подробнее смотрите главу официальной документации Sphinx.
Быстрый старт¶
Sphinx доступен для всех основных операционных систем, которые поддерживает язык программирования Python.
Установка
С помощью pip:
pip install sphinx
С помощью easy_install:
easy_install sphinx
В стандартном репозитории Ubuntu 14.10 есть пакеты и .
sudo apt-get install python3-sphinx
Другие способы установки описаны в разделе Installing Sphinx официальной документации Sphinx.
Создание нового проекта
Создадим директорию для нового проекта и перейдем в неё. Для этого в ОС Linux необходимо выполнить следующие команды в терминале:
mkdir MyProject cd MyProject
Для инициализации проекта необходимо выполнить команду :
sphinx-quickstart
Программа задаст ряд вопросов. Все настройки можно будет позже изменить в файле .
> Корневой каталог документации. По умолчанию текущий каталог. > Root path for the documentation : > Сделать ли раздельные папки исходников и готовых страниц - Да > Separate source and build directories (y/N) : y > Префикс для директорий с шаблонами и статическими файлами. > Name prefix for templates and static dir : > Название проекта. Для начала лучше вводить на латинице. > Project name: > Имя автора/авторов. Для начала лучше вводить на латинице. > Author name(s): > Версия проекта > Project version: > Номер релиза проекта > Project release : > Расширение исходного файла. По умолчанию .rst. > Source file suffix : > Имя мастер-документа. По умолчанию index.rst. > Name of your master document (without suffix) : > Генерировать ePub версию документации? > Do you want to use the epub builder (y/n) : > Автоматически вставлять docstrings из модулей > autodoc: automatically insert docstrings from modules (y/n) : > > doctest: automatically test code snippets in doctest blocks (y/n) : > > intersphinx: link between Sphinx documentation of different projects (y/n) : > > todo: write "todo" entries that can be shown or hidden on build (y/n) : > > coverage: checks for documentation coverage (y/n) : > Использовать модуль pngmath для вставки формул в формате png > pngmath: include math, rendered as PNG images (y/n) : > Использовать модуль mathjax для вставки формул в формате MathJax > mathjax: include math, rendered in the browser by MathJax (y/n) : y > > ifconfig: conditional inclusion of content based on config values (y/n) : > > viewcode: include links to the source code of documented Python objects (y/n) : > Создать Makefile - да > Create Makefile? (y/n) : > Сделать ли файл .bat, - нет, если у вас Linux > Create Windows command file? (Y/n) : n ()
После ответа на вопросы будут созданы файлы , , , , , .
. ├── Makefile ├── _build ├── _templates ├── _static ├── conf.py └── index.rst
Makefile — содержит инструкции для генерации результирующего документа командой make.
_build — директория, в которую будут помещены файлы в определенном формате после того, как будет запущен процесс их генерации.
_static — в эту директорию помещаются все файлы, не являющиеся исходным кодом (например, изображения). Позже создаются связи этих файлов с директорией build.
conf.py — содержит конфигурационные параметры Sphinx, включая те, которые были выбраны при запуске sphinx-quickstart в окне терминала.
index.rst — это корень проекта. Он соединяет документацию воедино, если она разделена на несколько файлов .
| IBM developerWorks Россия: Простое и удобное создание документации в Sphinx |
Генерация документа
Для генерации документации в HTML формат необходимо выполнить в командной строке команду . Аналогичным образом можно выполнить генерацию в другие форматы, например, .
cd MyProject make html
Произойдет сборка HTML, выходные файлы будут помещены в директорию . Перейдем в неё и откроем файл в браузере.
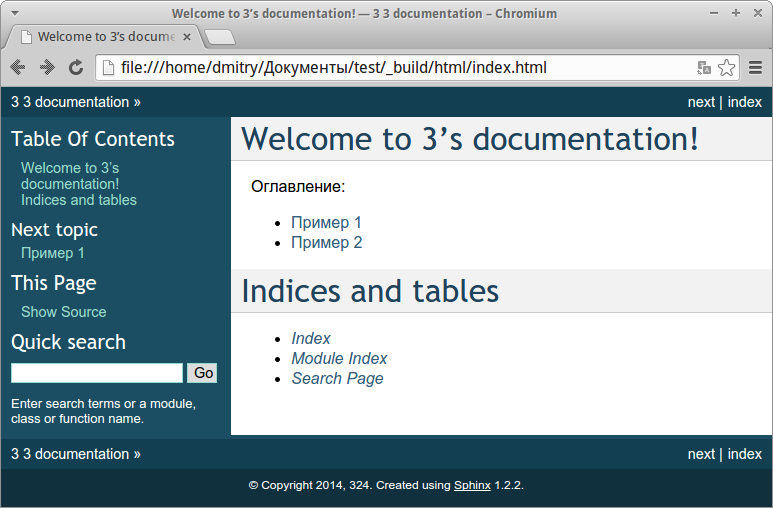
Получив совсем немного исходных данных, Sphinx сумел создать нечто большее. Мы получили несложную компоновку, содержащую информацию о документации проекта, раздел поиска, содержание, заметки об авторских правах, включая имя и дату, а также нумерацию страниц.
Обратите внимание на раздел поиска: Sphinx проиндексировал все файлы и с помощью JavaScript создал статический сайт, на котором можно искать нужную информацию. На снимке показана стандартная тема оформления документации
Она может быть изменена. Также можно настроить локализацию и прочие параметры
На снимке показана стандартная тема оформления документации. Она может быть изменена. Также можно настроить локализацию и прочие параметры.
Файл конфигурации позволяет настроить много дополнительных параметров генерации документации.
Добавление иллюстраций
Для добавления изображений в документы, необходимо предварительно поместить изображения в папку . В файл изображения добавляются директивой или :
.. image:: _staticfavicon.png
Подробнее смотрите раздел .
Установка и настройка Sphinx на Linux
Предполагается что у вас уже установлена ОС Linux, на которой будет работать (или уже работает ) сайт или сервис, на котором нужно будет использовать Sphinx Search API.
Обновляем источники пакетов и ставим нужный софт:
Теперь компилируем наш Сфинкс с поддержкой MySQL (есть поддержка и других БД, смотри док.), поскольку весь полезный контент сайта хранится в БД MySQL:
Копируем шаблон файла с настройками и редактируем его содержимое под наши нужды:
В конфигурационном файле достаточно много настроек и все они заключены в секции где для каждого источника индексируемых данных описываются свои специфические опции и данные для доступа.
Приводить полное описание всех настроек я не буду, в шаблонном файле все хорошо документировано, а также в официальной документации (смотри ссылки в конце статьи) все понятно изложено. Чтобы все изначально прояснить приведу здесь текст своего конфигурационного файла с подробными комментариями:
Запускаем индексацию наших данных:
В случае успешного индексирования получим примерно вот такие строки:
Запускаем поискового демона:
В случае успешного запуска должны увидеть примерно вот такой вывод:
Делаем тестовый поисковый запрос, где YOUR_QUERY_STRING — ваша поисковая фраза:
После запуска будет выведена длинная простыня записей что отвечают критериям поиска.
Проверяем работу поиска с использованием PHP API
Внимание: PHP должен быть установлен на сервере! «YOUR_QUERY_STRING» — ваш поисковый запрос. Надеюсь у вас все получилось
Надеюсь у вас все получилось.
Feature list
- Batch and incremental (soft real-time) full-text indexing.
- Support for non-text attributes (scalars, strings, sets, JSON).
- Direct indexing of SQL databases. Native support for MySQL, MariaDB, PostgreSQL, MSSQL, plus ODBC connectivity.
- XML document indexing support.
- Distributed searching support out-of-the-box.
- Integration via access APIs.
- SQL-like syntax support via MySQL protocol (since 0.9.9)
- Full-text searching syntax.
- Database-like result set processing.
- Relevance ranking utilizing additional factors besides standard BM25.
- Text processing support for SBCS and UTF-8 encodings, stopwords, indexing of words known not to appear in the database («hitless»), stemming, word forms, tokenizing exceptions, and «blended characters» (dual-indexing as both a real character and a word separator).
- Supports UDF (since 2.0.1).
4: Управление индексом
В данном разделе показано, как добавить данные в индекс Sphinx.
Для этого используется только что созданный конфигурационный файл.
Команда должна вернуть:
В среде производства нужно постоянно поддерживать индекс в актуальном состоянии. Для этого создайте cronjob. Откройте crontab:
Команда может предложить вам выбрать текстовый редактор (в руководстве используется nano).
Этот cronjob будет запускаться каждый час и добавлять данные в индекс, обращаясь к созданному ранее конфигурационному файлу. Скопируйте и вставьте в конец файла следующее правило:
Теперь поисковая система Sphinx готова к запуску.
Вступление
С самого начала, когда только начинал программировать на PHP и писал несложные сайты, я использовал собственный самописный поисковый движок с простой логикой. Он воспринимал одно и несколько слов в поисковой фразе и выдавал те записи в которых было обнаружено вхождение. Сначала делал с индексированием контента и кешированием индекса, потом делал полнотекстовый поиск на PHP.
Конечно же данная реализация не лишена недостатков, основной недостаток — это не достаточно релевантная поисковая выдача поскольку мой движок не учитывал морфологию слов, а искал только прямые вхождения поисковых фраз с простым анализом распределенности по статье. Писать мощный поисковый модуль со сложной логикой и оптимизациями «на стероидах» у меня не было ни времени ни особого желания.
Заключение
В этой статье мы рассмотрели основы работы с Sphinx, но возможности этого инструмента гораздо шире. Sphinx позволяет экспортировать документацию в различные форматы; для этого необходимо устанавливать дополнительные библиотеки и программное обеспечение. Вот лишь некоторые форматы, в которых можно сохранять документацию: PDF, epub, man (man-страницы UNIX) и LaTeX.
Для работы со сложными диаграммами имеется подключаемый модуль, который позволяет добавлять в проекты диаграммы Graphviz. Однажды мне потребовалось создать схему небольшой офисной сети, и с помощью этого инструмента все получилось даже лучше, чем я мог себе представить – я выполнил всю работу, используя единственный инструмент. Помимо Graphviz, существует и множество других подключаемых модулей для Sphinx (также называемых расширениями). Некоторые из них (например, interSphinx, позволяющий связывать несколько отельных проектов) входят в комплект самого Sphinx.
Если созданный вами проект выглядит не совсем так, как вам бы хотелось, то вы можете использовать одну из многочисленных тем Sphinx, полностью изменяющих вид конечных HTML-файлов. Некоторые важные Open Source-проекты (например, Celery и Lettuce) позволяют очень сильно изменять вид HTML путем модификации CSS и расширения шаблонов. В разделе вы найдете ссылки на эти проекты и на документацию, в которой объясняется, как расширять и модифицировать CSS и схемы по умолчанию.
Sphinx изменил мое представление о создании документации. Я был в полном восторге, когда понял, что могу легко создать документацию для нескольких внутрикорпоративных и своих собственных open source-проектов. Используйте Sphinx, чтобы легко находить забытую информацию в своих собственных документах.
Похожие темы
- Оригинал статьи: Easy and beautiful documentation with Sphinx (EN).
- Документация по проекту Sphinx (EN).
- Расширения Sphinx (EN): здесь вы найдете полный список расширений, а также ссылки на расширения сторонних авторов.
- Работа с темами и шаблонами (EN): в этом разделе объясняется, как расширять уже имеющиеся темы или применять новые.
- Документация по проекту Celery (EN) использует Sphinx для изменения существующих значений CSS и шрифтов.
- Документация по языку программирования Python (EN) полностью применима к Sphinx, который основан на Python.
- Lettuce (EN) – другой замечательный Open Source-проект, изменяющий (причем существенно) вид сгенерированного HTML в Sphinx.
-
Pacha: System
Configuration Engine (EN) – один из моих Open Source-проектов, использующий Sphinx.