Основы указателей для начинающих
Содержание:
- Реализация технологии «клиент—сервер»
- Реализация собственного высокопроизводительного shared-mutex
- Средство выделения памяти Go
- Под конкретные задачи
- Примечания
- Реализация технологии «клиент—сервер»
- Семафоры и очереди сообщений
- Сначала проверим, вдруг уже работаем по Shared Memory! ))).
- Основы атомарных операций
- Висячие указатели
- Реализация технологии «клиент—сервер»
- Динамическое выделение переменных
Реализация технологии «клиент—сервер»
В схеме обмена данными между двумя процессами — (клиентом и сервером), использующими разделяемую память, — должна функционировать группа из двух семафоров. Первый семафор служит для блокирования доступа к разделяемой памяти, его разрешающий сигнал — 1, а запрещающий — 0. Второй семафор служит для сигнализации сервера о том, что клиент начал работу, при этом доступ к разделяемой памяти блокируется, и клиент читает данные из памяти. Теперь при вызове операции сервером его работа будет приостановлена до освобождения памяти клиентом.
Сценарий использования разделяемой памяти
- Сервер получает доступ к разделяемой памяти, используя семафор.
- Сервер производит запись данных в разделяемую память.
- После завершения записи данных сервер освобождает доступ к разделяемой памяти с помощью семафора.
- Клиент получает доступ к разделяемой памяти, запирая доступ к этой памяти для других процессов с помощью семафора.
- Клиент производит чтение данных из разделяемой памяти, а затем освобождает доступ к памяти с помощью семафора.
en.cppreference.com/w/cpp/thread
- C++11: mutex, timed_mutex, recursive_mutex, recursive_timed_mutex
- C++14: shared_timed_mutex
- C++17: shared_mutex
coliru.stacked-crooked.com/a/b78467b7a3885e5b
- Во время разделяемой блокировки не может быть изменений объекта. Эта строка из двух рекурсивных shared-lock показывает это: assert(readonly_safe_map_string->at(«apple») == readonly_safe_map_string->at(«potato»)); — значения обоих строк всегда должны быть равны, т.к. мы меняем 2 строки в std::map под одной eXclusive-блокировкой std::lock_guard
- Во время чтения мы действительно вызываем функцию lock_shared(). Давайте уменьшим цикл до двух итераций, уберем строчки модифицирующие данные, оставим только первые две вставки в std::map в функции main(). Теперь добавим вывод буквы S в функцию lock_shared(), и буквы X в функцию lock(). Видим, что сначала идут две вставки X, а затем только буквы S – значит действительно, при чтениях const-объекта мы вызываем shared_lock(): coliru.stacked-crooked.com/a/515ba092a46135ae
- Во время изменений мы действительно вызываем функцию lock(). Теперь закомментируем чтение и оставим только операции изменения массива, теперь выводятся только буквы X: coliru.stacked-crooked.com/a/882eb908b22c98d6
- Любое количество потоков успешно выполнили lock_shared(), при этом все потоки пытающиеся выполнить lock() должны перейти в ожидание
- Один из потоков успешно выполнил lock(), а все остальные потоки пытающиеся выполнить lock_shared() или lock() должны перейти в ожидание
- T1-read & T2-read: Потоки-читатели блокируют мьютекс используя lock_shared() – эти потоки друг другу не мешают, т.к. пишут состояния о блокировках в отдельные для каждого потока ячейки памяти, и в этом время не должно быть эксклюзивной блокировки потока-писателя (want_x_lock == false). За исключением случаев, когда потоков больше, чем выделенных ячеек – тогда даже потоки-читатели блокируют эксклюзивно, используя CAS-функцию: want_x_lock = true.
- T1-write & T2-write: Потоки-писатели конкурируют друг с другом за один и тот же флаг (want_x_lock) и пытаются установить его в true, используя атомарную CAS-функцию: want_x_lock.compare_exchange_weak(); Здесь все просто, как и в обычном recursive_spinlock_t, который мы рассмотрели выше.
- T1-read & T2-write: Поток-читатель T1 пишет флаг блокировки в свою ячейку, и только после этого проверяет установлен ли флаг (want_x_lock), и если установлен (true), то отменяет свою блокировку, затем ожидает состояния (want_x_lock == false) и повторяет этот алгоритм сначала.
habrastorage.org/getpro/habr/post_images/5b2/3a3/23b/5b23a323b6a1c9e13ade90bbd82ed98b.jpgstd::memory_order_seq_cst
Средство выделения памяти Go
здесьКлассы размеров в GoСтраница размером 8 Кб разделена на блоки, соответствующие классу размера 1 Кб
▍Структура mcache
Взаимодействие между логическим процессором, mcache и mspan в Go
- Объект scan — это объект, который содержит указатель.
- Объект noscan — это объект, в котором нет указателя.
▍Структура mcentral
- Список объектов mspan, в которых нет свободных объектов, или тех mspan, которые имеются в mcache.
- Список объектов mspan, в которых есть свободные объекты.
Структура mcentral
▍Структура mheap
Структура mheap
- — это массив spanList. Структура mspan в каждом spanList состоит из 1 ~ 127 (_MaxMHeapList - 1) страниц. Например, free — это связанный список структур mspan, содержащих 3 страницы. Слово «free» в данном случае указывает на то, что речь идёт о пустом списке, память в котором не выделена. Список может быть, в противоположность пустому, списком, в котором память выделена (busy).
- — это список свободных структур mspan. Количество страниц на элемент (то есть, mspan) более 127. Для поддержки такого списка используется структура данных mtreap. Список занятых структур mspan называется busylarge.
Под конкретные задачи
При создании системы, разработчик как никто иной должен знать, какие данные и как он будет обрабатывать. На основе этого он сможет выбрать ту стратегию выделения памяти и работы с ней, которая наилучшим (в рамках задачи) образом подходит ему. Как было сказано ранее, библиотечные функции malloc/free не знают, как и для чего вы их вызвали, поэтому полагаться на их производительность при решении весьма специфических задач не стоит.
Что требуется брать в расчет? Вы можете определить, сколько памяти вам потребуется (нижняя/верхняя граница), в какие моменты работы программы, какие задачи потребуют множество аллокаций, а какие нет. Можно порассуждать о том, можно ли часть аллокаций убрать, разместить данные на стеке, перенести запросы на выделение из нагруженных частей программы в менее нагруженные.
СryEngine Sandbox: как пример среды для разработки игр
Крупные игровые движки, такие как Unreal, Unity, CryEngine и т.д, ничего не знают о том, какую игру вы делаете. Да, они могут быть заточены под определенные механики, жанры, но в общем случае — только вы сможете настроить систему таким образом, что она будет в состоянии удовлетворить ваши запросы на размещение тех или иных ресурсов в памяти компьютера.
Примечания
- ↑ . pubs.opengroup.org. Дата обращения 3 января 2016.
- ↑ . pubs.opengroup.org. Дата обращения 3 января 2016.
- . pubs.opengroup.org. Дата обращения 3 января 2016.
- ↑ . pubs.opengroup.org. Дата обращения 3 января 2016.
- ↑ . pubs.opengroup.org. Дата обращения 3 января 2016.
- . pubs.opengroup.org. Дата обращения 3 января 2016.
- . pubs.opengroup.org. Дата обращения 3 января 2016.
- . pubs.opengroup.org. Дата обращения 3 января 2016.
- . pubs.opengroup.org. Дата обращения 3 января 2016.
- .
- .
- . www.boost.org. Дата обращения 4 января 2016.
- . doc.qt.io. Дата обращения 4 января 2016.
- . man7.org. Дата обращения 4 января 2016.
- . docs.oracle.com. Дата обращения 4 января 2016.
- .
Реализация технологии «клиент—сервер»
В схеме обмена данными между двумя процессами — (клиентом и сервером), использующими разделяемую память, — должна функционировать группа из двух семафоров. Первый семафор служит для блокирования доступа к разделяемой памяти, его разрешающий сигнал — 1, а запрещающий — 0. Второй семафор служит для сигнализации сервера о том, что клиент начал работу, при этом доступ к разделяемой памяти блокируется, и клиент читает данные из памяти. Теперь при вызове операции сервером его работа будет приостановлена до освобождения памяти клиентом.
Сценарий использования разделяемой памяти
- Сервер получает доступ к разделяемой памяти, используя семафор.
- Сервер производит запись данных в разделяемую память.
- После завершения записи данных сервер освобождает доступ к разделяемой памяти с помощью семафора.
- Клиент получает доступ к разделяемой памяти, запирая доступ к этой памяти для других процессов с помощью семафора.
- Клиент производит чтение данных из разделяемой памяти, а затем освобождает доступ к памяти с помощью семафора.
Семафоры и очереди сообщений
Разделяемая память требует синхронизации действий процессов из-за эффекта гонки (race), возникающего между конкурентными, выполняющимися параллельно процессами. Для синхронизации процессов при совместном доступе к разделяемой памяти и прочим разделяемым ресурсам предназначено еще одно специализированное средство их взаимодействия — семафоры.
В большинстве случаев семафорами System V или POSIX пользуются многопроцессные сервисы, такие как, например, SQL-сервер postgres, который синхронизует доступ своих параллельных процессов к сегментам их общей памяти.
Семафоры (System V IPC)
fitz@ubuntu:~$ sudo ipcs -s
——- Сегменты совм. исп. памяти ——
ключ shmid владелец права байты nattch состояние
0х0052е2с1 378241026 postgres 600 30482432 4
—— Массивы семафоров ——
ключ shmid владелец права nsems
0х0052е2с1 1081344 postgres 600 17
0х0052е2с2 1114113 postgres 600 17
0х0052е2сЗ 1146882 postgres 600 17
0х0052е2с4 1179651 postgres 600 17
0х0052е2с5 1212420 postgres 600 17
0х0052е2с6 1245189 postgres 600 17
0х0052е2с7 1277958 postgres 600 17
Очереди сообщений являются средствами взаимодействия между процессами, реализующими еще один интерфейс передачи сообщений (message passing inerface), подобно каналам и сокетам. По своей природе они похожи на дейтаграммный SOCK_DGRAM режим передачи поверх именованных локальных сокетов unix.
Основное отличие очередей сообщений от сокетов заключается в том, что время их жизни не ограничивается временем существования процессов, которые их создали. На практике очереди сообщений являются настолько малораспространенными, что их иллюстрация на среднестатистической инсталляции Linux практически невозможна.
Способ 1
Используя SQL Server Management Studio (SSMS) выполним такой запрос:
| 1 | selectprogram_name,net_transportfromsys.dm_exec_sessionsast1leftjoinsys.dm_exec_connectionsASt2ONt1.session_id=t2.session_idwherenott1.program_nameisnull |
или такой запрос:
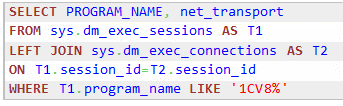
Если видим в колонке «program_name» – 1СV83 Server, а напротив Shared Memory, значит уже работает протокол Shared Memory!
Если там «TCP» – значит, Shared Memory не работает!
Способ 2
Используя SQL Profiler
- Заходим в базу 1С (для установления соединения с СУБД).
- Запускаем SQL Profiler и подключаемся к нашему серверу СУБД.
- Включаем сбор события ExistingConnection, выполняя следующее:
- На закладке «Выбор событий» включаем флаги «Показать все столбцы» и «Показать все события».
- Выбираем класс событий «Sessions» и включаем событие «ExistingConnection».
- По кнопке «Фильтры столбцов» устанавливаем фильтр на имя приложения.
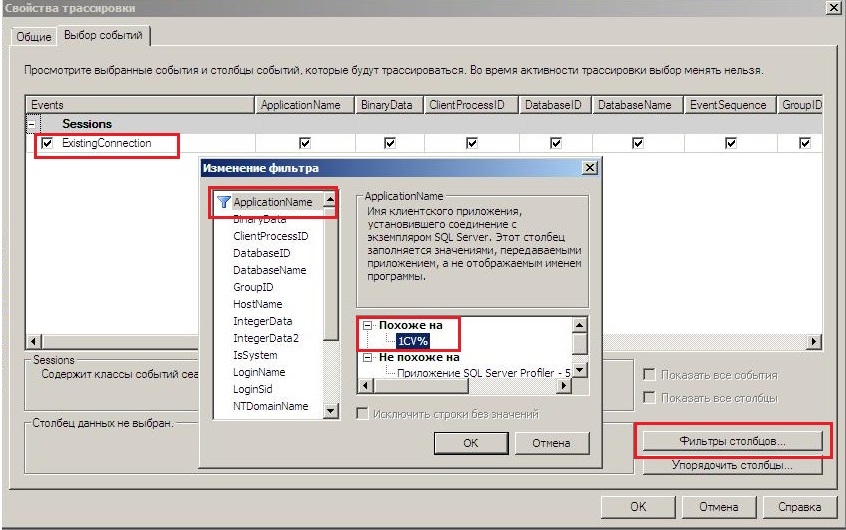
При трассировке увидим следующее:
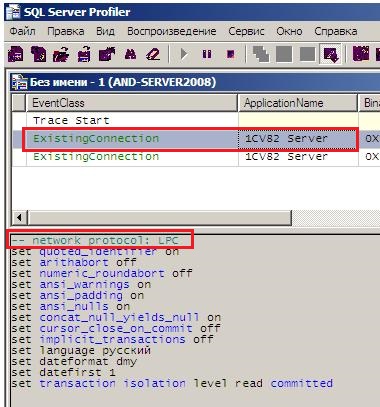
В нижней части окна должна отображаться надпись: «network protocol: LPC», расшифровывается как «Local Procedure Call».
Это говорит о том, что протокол Shared Memory включен и используется.
Основы атомарных операций
- Загрузить значение переменной «a» в регистр процессора
- Прибавить 1 к значению в регистре
- Записать значение регистра обратно в переменную «a»
- Использовать атомарные инструкции над атомарными переменными – но есть один минус, количество атомарных функций очень мало – поэтому реализовать сложную логику с помощью них затруднительно: en.cppreference.com/w/cpp/atomic/atomic
- Разрабатывать собственные сложные lock-free алгоритмы для каждого нового контейнера.
- Использовать блокировки (std::mutex, std::shared_timed_mutex, spinlock…) – они допускают к заблокированному коду по очереди по 1 потоку, поэтому проблемы data-races не возникает и мы можем использовать сколь угодно сложную логику, используя любые обычные потоко-небезопасные объекты.
en.cppreference.com/w/cpp/atomic/atomic
- load() и store() – тоже самое что operator T и operator= и
- fetch_add() и fetch_sub() – тоже самое что operator+= и operator-=
- Sequential Consistency (std::memory_order_seq_cst) – это барьер памяти по умолчанию (самый строгий и надежный, но и самый медленный относительно других).
std::atomicvolatile www.drdobbs.com/parallel/volatile-vs-volatile/212701484
-
Оптимизации: Для std::atomic<T> a; возможны две оптимизации, которые невозможны для volatile T a;
• Оптимизация слияния: a = 10; a = 20; может быть заменена компилятором на a = 20;
• Оптимизация замены константой: a = 1; local = a; может быть заменена компилятором a = 1; local = 1; - Переупорядочивание: Операции над std::atomic<T> a; могут ограничивать переупорядочивание вокруг себя для операций с обычными переменными и операций с другими атомарными переменными в соответствии с используемым барьером памяти std::memory_order_… Напротив, volatile T a; не влияет на порядок обычных переменных (non-atomic/non-volatile), но обращения ко всем volatile-переменным всегда сохраняют строгий взаимный порядок, т.е. порядок выполнения любых двух volatile-операций не может быть изменен компилятором, но не процессором.
- Spilling: Барьеры памяти std::memory_order_release, std::memory_order_acq_rel, std::memory_order_seq_cst указываемые для операций над std::atomic<T> a; инициируют spilling всех обычных переменных до исполнения атомарной операции. Т.е. эти барьеры выгружают обычные переменные из регистров процессора в оперативную память/кэш, за исключением случаев, когда компилятор может на 100% гарантировать, что эта локальная переменная не может использоваться в других потоках.
- Атомарность / выравнивание: Операции над std::atomic<T> a; видны другим потокам либо полностью, либо не видны вовсе. Для интегральных типов T это достигается за счет выравнивания расположения атомарных переменных в памяти компилятором — по крайней мере переменная должна лежать в одной кэш-линии, таким образом, атомарная переменная может быть изменена или прочитана всего одной операцией CPU. И наоборот, компилятор не гарантирует выравнивание volatile-переменных и атомарность операций над ними. Volatile-переменные обычно используются для доступа к памяти устройств или , но не для обмена данными между потоками. API драйвера устройства возвращает указатель на volatile-переменные, и при необходимости этот API обеспечивает выравнивание.
- Атомарность RMW-операций (read-modify-write): Операции над std::atomic<T> a; такие как ( ++, —, +=, -=, *=, /=, CAS, exchange) выполняются атомарно, т.е. если два потока выполняют операцию ++a; то эта переменная гарантированно будет увеличена на 2. Это достигается за счет блокировки кэш-линий (x86_64) или за счет маркировки отсутствия изменений в кэш-линии на процессорах поддерживающих LL/SC (ARM, PowerPC) на все время выполнения RMW-операции. Volatile-переменные не обеспечивают атомарность составных RMW-операций.
Висячие указатели
Язык C++ не предоставляет никаких гарантий относительно того, что произойдет с содержимым освобожденной памяти или со значением удаляемого указателя. В большинстве случаев память, возвращаемая операционной системе, будет содержать те же значения, которые были у неё до освобождения, а указатель так и останется указывать на только что освобожденную (удаленную) память.
Указатель, указывающий на освобожденную память, называется висячим указателем. Разыменование или удаление висячего указателя приведет к неожиданным результатам. Рассмотрим следующую программу:
#include <iostream>
int main()
{
int *ptr = new int; // динамически выделяем целочисленную переменную
*ptr = 8; // помещаем значение в выделенную ячейку памяти
delete ptr; // возвращаем память обратно в операционную систему. ptr теперь является висячим указателем
std::cout << *ptr; // разыменование висячего указателя приведет к неожиданным результатам
delete ptr; // попытка освободить память снова приведет к неожиданным результатам также
return 0;
}
|
1 |
#include <iostream> intmain() { int*ptr=newint;// динамически выделяем целочисленную переменную *ptr=8;// помещаем значение в выделенную ячейку памяти delete ptr;// возвращаем память обратно в операционную систему. ptr теперь является висячим указателем std::cout<<*ptr;// разыменование висячего указателя приведет к неожиданным результатам delete ptr;// попытка освободить память снова приведет к неожиданным результатам также return; } |
В программе, приведенной выше, значение , которое ранее было присвоено динамической переменной, после освобождения может и далее находиться там, а может и нет. Также возможно, что освобожденная память уже могла быть выделена другому приложению (или для собственного использования операционной системы), и попытка доступа к ней приведет к тому, что операционная система автоматически прекратит выполнение вашей программы.
Процесс освобождения памяти может также привести и к созданию нескольких висячих указателей. Рассмотрим следующий пример:
#include <iostream>
int main()
{
int *ptr = new int; // динамически выделяем целочисленную переменную
int *otherPtr = ptr; // otherPtr теперь указывает на ту же самую выделенную память, что и ptr
delete ptr; // возвращаем память обратно в операционную систему. ptr и otherPtr теперь висячие указатели
ptr = 0; // ptr теперь уже nullptr
// Однако otherPtr по-прежнему является висячим указателем!
return 0;
}
|
1 |
#include <iostream> intmain() { int*ptr=newint;// динамически выделяем целочисленную переменную int*otherPtr=ptr;// otherPtr теперь указывает на ту же самую выделенную память, что и ptr delete ptr;// возвращаем память обратно в операционную систему. ptr и otherPtr теперь висячие указатели ptr=;// ptr теперь уже nullptr // Однако otherPtr по-прежнему является висячим указателем! return; } |
Есть несколько рекомендаций, которые могут здесь помочь:
Во-первых, старайтесь избегать ситуаций, когда несколько указателей указывают на одну и ту же часть выделенной памяти. Если это невозможно, то выясните, какой указатель из всех «владеет» памятью (и отвечает за её удаление), а какие указатели просто получают доступ к ней.
Во-вторых, когда вы удаляете указатель, и, если он не выходит из области видимости сразу же после удаления, то его нужно сделать нулевым, т.е. присвоить значение (или nullptr в С++11). Под «выходом из области видимости сразу же после удаления» имеется в виду, что вы удаляете указатель в самом конце блока, в котором он объявлен.
Правило: Присваивайте удаленным указателям значение 0 (или nullptr в C++11), если они не выходят из области видимости сразу же после удаления.
Реализация технологии «клиент—сервер»
В схеме обмена данными между двумя процессами — (клиентом и сервером), использующими разделяемую память, — должна функционировать группа из двух семафоров. Первый семафор служит для блокирования доступа к разделяемой памяти, его разрешающий сигнал — 1, а запрещающий — 0. Второй семафор служит для сигнализации сервера о том, что клиент начал работу, при этом доступ к разделяемой памяти блокируется, и клиент читает данные из памяти. Теперь при вызове операции сервером его работа будет приостановлена до освобождения памяти клиентом.
Сценарий использования разделяемой памяти
- Сервер получает доступ к разделяемой памяти, используя семафор.
- Сервер производит запись данных в разделяемую память.
- После завершения записи данных сервер освобождает доступ к разделяемой памяти с помощью семафора.
- Клиент получает доступ к разделяемой памяти, запирая доступ к этой памяти для других процессов с помощью семафора.
- Клиент производит чтение данных из разделяемой памяти, а затем освобождает доступ к памяти с помощью семафора.
Динамическое выделение переменных
Как статическое, так и автоматическое распределение памяти имеют два общих свойства:
Размер переменной/массива должен быть известен во время компиляции.
Выделение и освобождение памяти происходит автоматически (когда переменная создается/уничтожается).
В большинстве случаев с этим всё ОК. Однако, когда дело доходит до работы с пользовательским вводом, то эти ограничения могут привести к проблемам.
Например, при использовании строки для хранения имени пользователя, мы не знаем наперед насколько длинным оно будет, пока пользователь его не введет. Или нам нужно создать игру с непостоянным количеством монстров (во время игры одни монстры умирают, другие появляются, пытаясь таким образом убить игрока).
Если нам нужно объявить размер всех переменных во время компиляции, то самое лучшее, что мы можем сделать — это попытаться угадать их максимальный размер, надеясь, что этого будет достаточно:
char name; // будем надеяться, что пользователь введет имя длиной менее 30 символов!
Monster monster; // 30 монстров максимум
Polygon rendering; // этому 3D-рендерингу лучше состоять из менее чем 40000 полигонов!
|
1 |
charname30;// будем надеяться, что пользователь введет имя длиной менее 30 символов! Monster monster30;// 30 монстров максимум Polygon rendering40000;// этому 3D-рендерингу лучше состоять из менее чем 40000 полигонов! |
Это плохое решение, по крайней мере, по трем причинам:
Во-первых, теряется память, если переменные фактически не используются или используются, но не все. Например, если мы выделим 30 символов для каждого имени, но имена в среднем будут занимать по 15 символов, то потребление памяти получится в два раза больше, чем нам нужно на самом деле. Или рассмотрим массив : если он использует только 20 000 полигонов, то память для других 20 000 полигонов фактически тратится впустую (т.е. не используется)!
Во-вторых, память для большинства обычных переменных (включая фиксированные массивы) выделяется из специального резервуара памяти — стека. Объем памяти стека в программе, как правило, невелик: в Visual Studio он по умолчанию равен 1МБ. Если вы превысите это значение, то произойдет переполнение стека, и операционная система автоматически завершит выполнение вашей программы.
В Visual Studio это можно проверить, запустив следующий фрагмент кода:
int main()
{
int array; // выделяем 1 миллиард целочисленных значений
}
|
1 |
intmain() { intarray1000000000;// выделяем 1 миллиард целочисленных значений } |
Лимит в 1МБ памяти может быть проблематичным для многих программ, особенно где используется графика.
В-третьих, и самое главное, это может привести к искусственным ограничениям и/или переполнению массива. Что произойдет, если пользователь попытается прочесть 500 записей с диска, но мы выделили память максимум для 400? Либо мы выведем пользователю ошибку, что максимальное количество записей — 400, либо (в худшем случае) выполнится переполнение массива и затем что-то очень нехорошее.
К счастью, эти проблемы легко устраняются с помощью динамического выделения памяти. Динамическое выделение памяти — это способ запроса памяти из операционной системы запущенными программами по мере необходимости. Эта память не выделяется из ограниченной памяти стека программы, а выделяется из гораздо большего хранилища, управляемого операционной системой — кучи. На современных компьютерах размер кучи может составлять гигабайты памяти.
Для динамического выделения памяти одной переменной используется оператор new:
new int; // динамически выделяем целочисленную переменную и сразу же отбрасываем результат (так как нигде его не сохраняем)
| 1 | newint;// динамически выделяем целочисленную переменную и сразу же отбрасываем результат (так как нигде его не сохраняем) |
В примере, приведенном выше, мы запрашиваем выделение памяти для целочисленной переменной из операционной системы. Оператор new возвращает указатель, содержащий адрес выделенной памяти.
Для доступа к выделенной памяти создается указатель:
int *ptr = new int; // динамически выделяем целочисленную переменную и присваиваем её адрес ptr, чтобы затем иметь доступ к ней
| 1 | int*ptr=newint;// динамически выделяем целочисленную переменную и присваиваем её адрес ptr, чтобы затем иметь доступ к ней |
Затем мы можем разыменовать указатель для получения значения:
*ptr = 8; // присваиваем значение 8 только что выделенной памяти
| 1 | *ptr=8;// присваиваем значение 8 только что выделенной памяти |
Вот один из случаев, когда указатели полезны. Без указателя с адресом на только что выделенную память у нас не было бы способа получить доступ к ней.