Array.prototype.join()
Содержание:
- Использование обратной итерации
- Более строгая функция интерпретации
- Как всё устроено, Юникод
- Получение подстроки
- Спецсимволы
- Итерируемые объекты и псевдомассивы
- Об уровнях сложности задач
- Сравнение производительности
- Поиск подстроки
- Примеры
- Reverse()
- Reverse(Int32, Int32)
- Примеры
- Browser compatibility
- Использование рекурсии
- Итого
Использование обратной итерации
Сначала преобразовываем данную строку в символьный массив, используя метод CharArray(). После этого просто перебираем данный массив в обратном порядке.
package Edureka;
import java.util.*;
public class StringRev{
// Function to reverse a string in Java
public static String reverseString(String s){
//Converting the string into a character array
char c[]=s.toCharArray();
String reverse="";
//For loop to reverse a string
for(int i=c.length-1;i>=0;i--){
reverse+=c;
}
return reverse;
}
public static void main(String[] args) {
System.out.println(reverseString("Hi All"));
System.out.println(reverseString("Welcome to Edureka Blog"));
}
}
Вывод:
llA iH golB akerudE ot emocleW
Более строгая функция интерпретации
Иногда необходим более строгий способ интерпретации целочисленных значений. В этом могут помочь регулярные выражения:
var filterInt = function (value) {
if (/^(\-|\+)?(+|Infinity)$/.test(value))
return Number(value);
return NaN;
}
console.log(filterInt('421')); // 421
console.log(filterInt('-421')); // -421
console.log(filterInt('+421')); // 421
console.log(filterInt('Infinity')); // Infinity
console.log(filterInt('421e+0')); // NaN
console.log(filterInt('421hop')); // NaN
console.log(filterInt('hop1.61803398875')); // NaN
console.log(filterInt('1.61803398875')); // NaN
Как всё устроено, Юникод
Глубокое погружение в тему
Этот раздел более подробно описывает, как устроены строки. Такие знания пригодятся, если вы намерены работать с эмодзи, редкими математическими символами, иероглифами, либо с ещё какими-то редкими символами.
Если вы не планируете их поддерживать, эту секцию можно пропустить.
Многие символы возможно записать одним 16-битным словом: это и буквы большинства европейских языков, и числа, и даже многие иероглифы.
Но 16 битов — это 65536 комбинаций, так что на все символы этого, разумеется, не хватит. Поэтому редкие символы записываются двумя 16-битными словами — это также называется «суррогатная пара».
Длина таких строк — :
Обратите внимание, суррогатные пары не существовали, когда был создан JavaScript, поэтому язык не обрабатывает их адекватно!
Ведь в каждой из этих строк только один символ, а показывает длину .
и — два редких метода, правильно работающие с суррогатными парами, но они и появились в языке недавно. До них были только String.fromCharCode и str.charCodeAt. Эти методы, вообще, делают то же самое, что , но не работают с суррогатными парами.
Получить символ, представленный суррогатной парой, может быть не так просто, потому что суррогатная пара интерпретируется как два символа:
Части суррогатной пары не имеют смысла сами по себе, так что вызовы в этом примере покажут лишь мусор.
Технически, суррогатные пары возможно обнаружить по их кодам: если код символа находится в диапазоне , то это — первая часть суррогатной пары. Следующий символ — вторая часть — имеет код в диапазоне . Эти два диапазона выделены исключительно для суррогатных пар по стандарту.
В данном случае:
Дальше в главе Перебираемые объекты будут ещё способы работы с суррогатными парами. Для этого есть и специальные библиотеки, но нет достаточно широко известной, чтобы предложить её здесь.
Во многих языках есть символы, состоящие из некоторого основного символа со знаком сверху или снизу.
Например, буква — это основа для . Наиболее используемые составные символы имеют свой собственный код в таблице UTF-16. Но не все, в силу большого количества комбинаций.
Чтобы поддерживать любые комбинации, UTF-16 позволяет использовать несколько юникодных символов: основной и дальше один или несколько особых символов-знаков.
Например, если после добавить специальный символ «точка сверху» (код ), отобразится Ṡ.
Если надо добавить сверху (или снизу) ещё один знак — без проблем, просто добавляем соответствующий символ.
Например, если добавить символ «точка снизу» (код ), отобразится S с точками сверху и снизу: .
Добавляем два символа:
Это даёт большую гибкость, но из-за того, что порядок дополнительных символов может быть различным, мы получаем проблему сравнения символов: можно представить по-разному символы, которые ничем визуально не отличаются.
Например:
Для решения этой проблемы есть алгоритм «юникодной нормализации», приводящий каждую строку к единому «нормальному» виду.
Его реализует метод str.normalize().
Забавно, но в нашем случае «схлопывает» последовательность из трёх символов в один: — S с двумя точками.
Разумеется, так происходит не всегда. Просто Ṩ — это достаточно часто используемый символ, поэтому создатели UTF-16 включили его в основную таблицу и присвоили ему код.
Подробнее о правилах нормализации и составлении символов можно прочитать в дополнении к стандарту Юникод: Unicode Normalization Forms. Для большинства практических целей информации из этого раздела достаточно.
Получение подстроки
В JavaScript есть 3 метода для получения подстроки: , и .
-
Возвращает часть строки от до (не включая) .
Например:
Если аргумент отсутствует, возвращает символы до конца строки:
Также для можно задавать отрицательные значения. Это означает, что позиция определена как заданное количество символов с конца строки:
-
Возвращает часть строки между и .
Это — почти то же, что и , но можно задавать больше .
Например:
Отрицательные значения , в отличие от , не поддерживает, они интерпретируются как .
-
Возвращает часть строки от длины .
В противоположность предыдущим методам, этот позволяет указать длину вместо конечной позиции:
Значение первого аргумента может быть отрицательным, тогда позиция определяется с конца:
Давайте подытожим, как работают эти методы, чтобы не запутаться:
| метод | выбирает… | отрицательные значения |
|---|---|---|
| от до (не включая ) | можно передавать отрицательные значения | |
| между и | отрицательные значения равнозначны | |
| символов, начиная от | значение может быть отрицательным |
Какой метод выбрать?
Все эти методы эффективно выполняют задачу. Формально у метода есть небольшой недостаток: он описан не в собственно спецификации JavaScript, а в приложении к ней — Annex B. Это приложение описывает возможности языка для использования в браузерах, существующие в основном по историческим причинам. Таким образом, в другом окружении, отличном от браузера, он может не поддерживаться. Однако на практике он работает везде.
Из двух других вариантов, более гибок, он поддерживает отрицательные аргументы, и его короче писать. Так что, в принципе, можно запомнить только его.
Спецсимволы
Многострочные строки также можно создавать с помощью одинарных и двойных кавычек, используя так называемый «символ перевода строки», который записывается как :
В частности, эти две строки эквивалентны, просто записаны по-разному:
Есть и другие, реже используемые спецсимволы. Вот список:
| Символ | Описание |
|---|---|
| Перевод строки | |
| Возврат каретки: самостоятельно не используется. В текстовых файлах Windows для перевода строки используется комбинация символов . | |
| , | Кавычки |
| Обратный слеш | |
| Знак табуляции | |
| , , | Backspace, Form Feed и Vertical Tab — оставлены для обратной совместимости, сейчас не используются. |
| Символ с шестнадцатеричным юникодным кодом , например, — то же самое, что . | |
| Символ в кодировке UTF-16 с шестнадцатеричным кодом , например, — юникодное представление знака копирайта, . Код должен состоять ровно из 4 шестнадцатеричных цифр. | |
| (от 1 до 6 шестнадцатеричных цифр) | Символ в кодировке UTF-32 с шестнадцатеричным кодом от U+0000 до U+10FFFF. Некоторые редкие символы кодируются двумя 16-битными словами и занимают 4 байта. Так можно вставлять символы с длинным кодом. |
Примеры с Юникодом:
Все спецсимволы начинаются с обратного слеша, — так называемого «символа экранирования».
Он также используется, если необходимо вставить в строку кавычку.
К примеру:
Здесь перед входящей в строку кавычкой необходимо добавить обратный слеш — — иначе она бы обозначала окончание строки.
Разумеется, требование экранировать относится только к таким же кавычкам, как те, в которые заключена строка. Так что мы можем применить и более элегантное решение, использовав для этой строки двойные или обратные кавычки:
Заметим, что обратный слеш служит лишь для корректного прочтения строки интерпретатором, но он не записывается в строку после её прочтения. Когда строка сохраняется в оперативную память, в неё не добавляется символ . Вы можете явно видеть это в выводах в примерах выше.
Но что, если нам надо добавить в строку собственно сам обратный слеш ?
Это можно сделать, добавив перед ним… ещё один обратный слеш!
Итерируемые объекты и псевдомассивы
Есть два официальных термина, которые очень похожи, но в то же время сильно различаются. Поэтому убедитесь, что вы как следует поняли их, чтобы избежать путаницы.
- Итерируемые объекты – это объекты, которые реализуют метод , как было описано выше.
- Псевдомассивы – это объекты, у которых есть индексы и свойство , то есть, они выглядят как массивы.
При использовании JavaScript в браузере или других окружениях мы можем встретить объекты, которые являются итерируемыми или псевдомассивами, или и тем, и другим.
Например, строки итерируемы (для них работает ) и являются псевдомассивами (они индексированы и есть ).
Но итерируемый объект может не быть псевдомассивом. И наоборот: псевдомассив может не быть итерируемым.
Например, объект из примера выше – итерируемый, но не является псевдомассивом, потому что у него нет индексированных свойств и .
А вот объект, который является псевдомассивом, но его нельзя итерировать:
Что у них общего? И итерируемые объекты, и псевдомассивы – это обычно не массивы, у них нет методов , и т.д. Довольно неудобно, если у нас есть такой объект и мы хотим работать с ним как с массивом. Например, мы хотели бы работать с , используя методы массивов. Как этого достичь?
Об уровнях сложности задач
На данном сайте мы условно относим любую задачу к одному из трех уровней сложности (простому, среднему и сложному) и понимаем под этим следующее.
Простая задача не содержит в себе сложной логики и не предполагает знаний по математике и другим предметам, которые изучаются примерно с 8-го класса. Поэтому простые задачи доступны для понимания обучающимся 5-7 классов, либо для того, чтобы они стали понятны, требуется минимум пояснений.
Задача средней сложности может содержать в себе более сложную логику, т. е. вложенные конструкции (условие в цикле, вложенный цикл), функции, сложные выражения и др. Также если задача требует от обучающегося знаний по математике и другим предметам, которые изучаются в 7-8 классе и старше, то даже если ее логика проста, она также будет отнесена к задачам средней сложности. Отсюда не следует, что средние задачи не предназначены для 5-7 классов. Однако для их решения скорее всего потребуются дополнительные разъяснения, более детальный разбор алгоритма решения.
Сложные задачи предполагают неоднозначный алгоритм решения, сложные логические конструкции, относительно длинный код программы. Это задачи близкие по сложности к олимпиадным и к задачам C3-C4 ЕГЭ по информатике, а также все виды сортировок.
Сравнение производительности
После реализации всех трех подходов к переворачиванию строк, показанных в этом руководстве, мне стало любопытна их относительная производительность.
Так что я провел небольшой бенчмаркинг:
Python
>>> import timeit
>>> s = ‘abcdefghijklmnopqrstuvwxyz’ * 10
>>> timeit.repeat(lambda: reverse_string1(s))
>>> timeit.repeat(lambda: reverse_string2(s))
>>> timeit.repeat(lambda: reverse_string3(s))
|
1 |
>>>importtimeit >>>s=’abcdefghijklmnopqrstuvwxyz’*10 >>>timeit.repeat(lambdareverse_string1(s)) 0.6848115339962533,0.7366074129968183,0.7358982900041156 >>>timeit.repeat(lambdareverse_string2(s)) 5.514941683999496,5.339547180992668,5.319950777004124 >>>timeit.repeat(lambdareverse_string3(s)) 48.74324739299482,48.637329410004895,49.223478018000606 |
Хорошо, это интересно… вот результаты в форме таблицы:
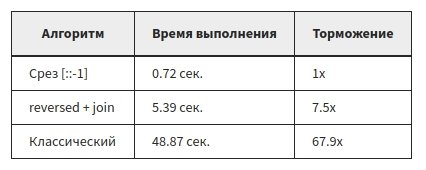
Как вы видите, есть огромная разница в производительности между этими тремя реализациями.
Срез — самый быстрый подход, reversed() медленнее среза в 8 раз, и «классический» алгоритм медленнее в 71 раз в этой проверке!
Поиск подстроки
Существует несколько способов поиска подстроки.
Первый метод — str.indexOf(substr, pos).
Он ищет подстроку в строке , начиная с позиции , и возвращает позицию, на которой располагается совпадение, либо при отсутствии совпадений.
Например:
Необязательный второй аргумент позволяет начать поиск с определённой позиции.
Например, первое вхождение — на позиции . Для того, чтобы найти следующее, начнём поиск с позиции :
Чтобы найти все вхождения подстроки, нужно запустить в цикле. Каждый раз, получив очередную позицию, начинаем новый поиск со следующей:
Тот же алгоритм можно записать и короче:
Также есть похожий метод str.lastIndexOf(substr, position), который ищет с конца строки к её началу.
Он используется тогда, когда нужно получить самое последнее вхождение: перед концом строки или начинающееся до (включительно) определённой позиции.
При проверке в условии есть небольшое неудобство. Такое условие не будет работать:
Мы ищем подстроку , и она здесь есть, прямо на позиции . Но не показывается, т. к. возвращает , и решает, что тест не пройден.
Поэтому надо делать проверку на :
Существует старый трюк с использованием — . Он преобразует число в 32-разрядное целое со знаком (signed 32-bit integer). Дробная часть, в случае, если она присутствует, отбрасывается. Затем все биты числа инвертируются.
На практике это означает простую вещь: для 32-разрядных целых чисел значение равно .
В частности:
Таким образом, равняется 0 только при (для любого , входящего в 32-разрядные целые числа со знаком).
Соответственно, прохождение проверки означает, что результат отличен от , совпадение есть.
Это иногда применяют, чтобы сделать проверку компактнее:
Обычно использовать возможности языка каким-либо неочевидным образом не рекомендуется, но этот трюк широко используется в старом коде, поэтому его важно понимать. Просто запомните: означает «если найдено»
Просто запомните: означает «если найдено».
Впрочем, если быть точнее, из-за того, что большие числа обрезаются до 32 битов оператором , существуют другие числа, для которых результат тоже будет , самое маленькое из которых — . Поэтому такая проверка будет правильно работать только для строк меньшей длины.
На данный момент такой трюк можно встретить только в старом коде, потому что в новом он просто не нужен: есть метод (см. ниже).
Более современный метод str.includes(substr, pos) возвращает , если в строке есть подстрока , либо , если нет.
Это — правильный выбор, если нам необходимо проверить, есть ли совпадение, но позиция не нужна:
Необязательный второй аргумент позволяет начать поиск с определённой позиции:
Методы str.startsWith и str.endsWith проверяют, соответственно, начинается ли и заканчивается ли строка определённой строкой:
Примеры
В следующем примере демонстрируются обе перегрузки Reverse метода.The following example demonstrates both overloads of the Reverse method. В примере создается List<T> строка из строк и добавляется шесть строк.The example creates a List<T> of strings and adds six strings. Перегрузка метода используется для обращения к списку, а затем перегрузка метода используется для обращения к середине списка, начиная с элемента 1 и охватывающего четыре элемента.The method overload is used to reverse the list, and then the method overload is used to reverse the middle of the list, beginning with element 1 and encompassing four elements.
Reverse()
Изменяет порядок элементов во всем списке List<T> на обратный.Reverses the order of the elements in the entire List<T>.
Комментарии
Этот метод использует Array.Reverse , чтобы изменить порядок элементов на обратный.This method uses Array.Reverse to reverse the order of the elements.
Этот метод является операцией O (n), где n — Count .This method is an O(n) operation, where n is Count.
Reverse(Int32, Int32)
Изменяет порядок элементов в указанном диапазоне.Reverses the order of the elements in the specified range.
Параметры
-
index
- Int32
Отсчитываемый от нуля индекс начала диапазона, порядок элементов которого требуется изменить.The zero-based starting index of the range to reverse.
-
count
- Int32
Число элементов в диапазоне, порядок сортировки в котором требуется изменить.The number of elements in the range to reverse.
Исключения
ArgumentOutOfRangeException
Значение параметра меньше 0. is less than 0.
-или—or-
Значение параметра меньше 0. is less than 0.
ArgumentException
Параметры и не указывают допустимый диапазон элементов в списке List<T>. and do not denote a valid range of elements in the List<T>.
Комментарии
Этот метод использует Array.Reverse , чтобы изменить порядок элементов на обратный.This method uses Array.Reverse to reverse the order of the elements.
Этот метод является операцией O (n), где n — Count .This method is an O(n) operation, where n is Count.
Примеры
Пример: Использование
Все следующие примеры возвращают :
parseInt(" 0xF", 16);
parseInt(" F", 16);
parseInt("17", 8);
parseInt(021, 8);
parseInt("015", 10); //parseInt(015, 10); вернёт 15
parseInt(15.99, 10);
parseInt("FXX123", 16);
parseInt("1111", 2);
parseInt("15*3", 10);
parseInt("15e2", 10);
parseInt("15px", 10);
parseInt("12", 13);
Все следующие примеры возвращают :
parseInt("Hello", 8); // Не является числом
parseInt("546", 2); // Неверное число в двоичной системе счисления
Все следующие примеры возвращают :
parseInt("-F", 16);
parseInt("-0F", 16);
parseInt("-0XF", 16);
parseInt(-15.1, 10)
parseInt(" -17", 8);
parseInt(" -15", 10);
parseInt("-1111", 2);
parseInt("-15e1", 10);
parseInt("-12", 13);
Все следующие примеры возвращают :
Следующий пример возвращает :
parseInt("0e0", 16);
Browser compatibility
The compatibility table on this page is generated from structured data. If you’d like to contribute to the data, please check out https://github.com/mdn/browser-compat-data and send us a pull request.
Update compatibility data on GitHub
| Chrome | Edge | Firefox | Internet Explorer | Opera | Safari | Android webview | Chrome для Android | Firefox для Android | Opera для Android | Safari on iOS | Samsung Internet | Node.js | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Chrome Полная поддержка 46 |
Edge Полная поддержка 12 |
Firefox Полная поддержка 16 |
IE Нет поддержки Нет |
Opera Полная поддержка 37 |
Safari Полная поддержка 8 |
WebView Android Полная поддержка 46 |
Chrome Android Полная поддержка 46 |
Firefox Android Полная поддержка 16 |
Opera Android Полная поддержка 37 |
Safari iOS Полная поддержка 8 |
Samsung Internet Android Полная поддержка 5.0 |
nodejs Полная поддержка 5.0.0 |
|
|
Chrome Полная поддержка 46 |
Edge Полная поддержка 12 |
Firefox Полная поддержка 27 |
IE Нет поддержки Нет |
Opera Полная поддержка 37 |
Safari Полная поддержка 8 |
WebView Android Полная поддержка 46 |
Chrome Android Полная поддержка 46 |
Firefox Android Полная поддержка 27 |
Opera Android Полная поддержка 37 |
Safari iOS Полная поддержка 8 |
Samsung Internet Android Полная поддержка 5.0 |
nodejs Полная поддержка 5.0.0 |
|
| Spread in destructuring |
Chrome Полная поддержка 49 |
Edge Полная поддержка 79 |
Firefox Полная поддержка 34 |
IE Нет поддержки Нет |
Opera Полная поддержка 37 |
Safari Полная поддержка 10 |
WebView Android Полная поддержка 49 |
Chrome Android Полная поддержка 49 |
Firefox Android Полная поддержка 34 |
Opera Android Полная поддержка 37 |
Safari iOS Полная поддержка 10 |
Samsung Internet Android Полная поддержка 5.0 |
nodejs Полная поддержка 6.0.0 |
| Экспериментальная |
Chrome Полная поддержка 60 |
Edge Полная поддержка 79 |
Firefox Полная поддержка 55 |
IE Нет поддержки Нет |
Opera Полная поддержка 47 |
Safari Полная поддержка 11.1 |
WebView Android Полная поддержка 60 |
Chrome Android Полная поддержка 60 |
Firefox Android Полная поддержка 55 |
Opera Android Полная поддержка 44 |
Safari iOS Полная поддержка 11.3 |
Samsung Internet Android Полная поддержка 8.2 |
nodejs Полная поддержка 8.3.0 |
Использование рекурсии
Рекурсия – это не что иное, как функция, которая вызывает сама себя.
package Edureka;
import java.util.*;
public class StringRecursion{
String rev(String str) {
if(str.length() == 0)
return " ";
return str.charAt(str.length()-1) + rev(str.substring(0,str.length()-1)); }
public static void main(String args) {
StringRecursion r=new StringRecursion();
Scanner sc=new Scanner(System.in);
System.out.print("Enter the string : ");
String s=sc.nextLine();
System.out.println("Reversed String: "+r.rev(s)); }
}
Вывод:
Enter the string : Java is the blooming technology since its existence Reversed String: ecnetsixe sti ecnis ygolonhcet gnimoolb eht si avaJ
В приведенном выше коде создан объект для класса StringRecursion r. Затем прочитана введенная строка с помощью sc.nextLine() и сохранена в строковую переменную s. Наконец, вызван обратный метод, как r.rev (s).
Итого
Шпаргалка по методам массива:
-
Для добавления/удаления элементов:
- – добавляет элементы в конец,
- – извлекает элемент с конца,
- – извлекает элемент с начала,
- – добавляет элементы в начало.
- – начиная с индекса , удаляет элементов и вставляет .
- – создаёт новый массив, копируя в него элементы с позиции до (не включая ).
- – возвращает новый массив: копирует все члены текущего массива и добавляет к нему . Если какой-то из является массивом, тогда берутся его элементы.
-
Для поиска среди элементов:
- – ищет , начиная с позиции , и возвращает его индекс или , если ничего не найдено.
- – возвращает , если в массиве имеется элемент , в противном случае .
- – фильтрует элементы через функцию и отдаёт первое/все значения, при прохождении которых через функцию возвращается .
- похож на , но возвращает индекс вместо значения.
-
Для перебора элементов:
forEach(func) – вызывает func для каждого элемента. Ничего не возвращает.
-
Для преобразования массива:
- – создаёт новый массив из результатов вызова для каждого элемента.
- – сортирует массив «на месте», а потом возвращает его.
- – «на месте» меняет порядок следования элементов на противоположный и возвращает изменённый массив.
- – преобразует строку в массив и обратно.
- – вычисляет одно значение на основе всего массива, вызывая для каждого элемента и передавая промежуточный результат между вызовами.
-
Дополнительно:
Array.isArray(arr) проверяет, является ли arr массивом.
Обратите внимание, что методы , и изменяют исходный массив. Изученных нами методов достаточно в 99% случаев, но существуют и другие
Изученных нами методов достаточно в 99% случаев, но существуют и другие.
-
arr.some(fn)/arr.every(fn) проверяет массив.
Функция вызывается для каждого элемента массива аналогично . Если какие-либо/все результаты вызовов являются , то метод возвращает , иначе .
-
arr.fill(value, start, end) – заполняет массив повторяющимися , начиная с индекса до .
-
arr.copyWithin(target, start, end) – копирует свои элементы, начиная со и заканчивая , в собственную позицию (перезаписывает существующие).
Полный список есть в справочнике MDN.
На первый взгляд может показаться, что существует очень много разных методов, которые довольно сложно запомнить. Но это гораздо проще, чем кажется.
Внимательно изучите шпаргалку, представленную выше, а затем, чтобы попрактиковаться, решите задачи, предложенные в данной главе. Так вы получите необходимый опыт в правильном использовании методов массива.
Всякий раз, когда вам будет необходимо что-то сделать с массивом, а вы не знаете, как это сделать – приходите сюда, смотрите на таблицу и ищите правильный метод. Примеры помогут вам всё сделать правильно, и вскоре вы быстро запомните методы без особых усилий.