Python многопроцессорный pool.map для нескольких аргументов
Содержание:
- [Bonus] Multiprocessing is always faster than serial.
- Conclusion
- What Is Parallelism?#
- Terminating processes in Python
- A Simple Example:
- Interpreter Isolation
- Goal
- Resetting an interpreter’s state
- Before moving towards creating threads let me just tell you, When to use Multithreading in Python?
- Resetting __main__
- Terminating Processes¶
- Daemon Processes¶
- Determining the Current Process¶
- Make RunFailedError.__cause__ lazy
- Concerns
- Shared data
- C-extension opt-in/opt-out
- When to Use Concurrency#
- Multiprocessing vs Multithreading
- When Is Concurrency Useful?#
- Importable Target Functions¶
- Conclusions
- Eliminating impact of global interpreter lock (GIL)
- Отладка регулярных выражений
- How subprocesses are started on POSIX (the standard formerly known as Unix)
- API for sharing data
[Bonus] Multiprocessing is always faster than serial.
For example if you have 1000 cpu heavy task and only 4 cores, don’t pop more than 4 processes otherwise they will compete for CPU resources.(compete => competition => concurrency)
Conclusion
- There can only be one thread running at any given time in a python process.
- Multiprocessing is parallelism. Multithreading is concurrency.
- Multiprocessing is for increasing speed. Multithreading is for hiding latency.
- Multiprocessing is best for computations. Multithreading is best for IO.
- If you have CPU heavy tasks, use multiprocessing with and never more. Never!
- If you have IO heavy tasks, use multithreading with with a number bigger than 1 that you can tweak on your own. Try many values and choose the one with the best speedup because there isn’t a general rule. For instance the default value of in is set to 5 [] which honestly feels quite random in my opinion.
That’s it.

What Is Parallelism?#
So far, you’ve looked at concurrency that happens on a single processor. What about all of those CPU cores your cool, new laptop has? How can you make use of them? is the answer.
With , Python creates new processes. A process here can be thought of as almost a completely different program, though technically they’re usually defined as a collection of resources where the resources include memory, file handles and things like that. One way to think about it is that each process runs in its own Python interpreter.
Because they are different processes, each of your trains of thought in a multiprocessing program can run on a different core. Running on a different core means that they actually can run at the same time, which is fabulous. There are some complications that arise from doing this, but Python does a pretty good job of smoothing them over most of the time.
Now that you have an idea of what concurrency and parallelism are, let’s review their differences, and then we can look at why they can be useful:
| Concurrency Type | Switching Decision | Number of Processors |
|---|---|---|
| Pre-emptive multitasking () | The operating system decides when to switch tasks external to Python. | 1 |
| Cooperative multitasking () | The tasks decide when to give up control. | 1 |
| Multiprocessing () | The processes all run at the same time on different processors. | Many |
Terminating processes in Python
We can kill or terminate a process immediately by using the terminate() method. We will use this method to terminate the child process, which has been created with the help of function, immediately before completing its execution.
Example
import multiprocessing
import time
def Child_process():
print ('Starting function')
time.sleep(5)
print ('Finished function')
P = multiprocessing.Process(target = Child_process)
P.start()
print("My Process has terminated, terminating main thread")
print("Terminating Child Process")
P.terminate()
print("Child Process successfully terminated")
Output
My Process has terminated, terminating main thread Terminating Child Process Child Process successfully terminated
The output shows that the program terminates before the execution of child process that has been created with the help of the Child_process() function. This implies that the child process has been terminated successfully.
A Simple Example:
Let’s start by building a really simple Python program that utilizes the
multiprocessing module.
In this example, I’ll be showing you how to spawn multiple processes at once and
each process will output the random number that they will compute using the
random module.
Running this should then print out an array of 4 different decimal numbers
between 0 and 1 like so:
Now, the important thing to note here, is that each of these random numbers was
generated in an entirely separate Python process created with the help of the
multiprocessing module.
Each of these separate processes features it’s own instance of the Global
Interpreter Lock, and each of these can be run across multiple CPU cores. Now,
let’s imagine we were doing something more CPU-intensive than simply generating
a single random number. This is where the multiprocessing module would truly
start to shine.
Interpreter Isolation
CPython’s interpreters are intended to be strictly isolated from each
other. Each interpreter has its own copy of all modules, classes,
functions, and variables. The same applies to state in C, including in
extension modules. The CPython C-API docs explain more.
However, there are ways in which interpreters share some state. First
of all, some process-global state remains shared:
- file descriptors
- builtin types (e.g. dict, bytes)
- singletons (e.g. None)
- underlying static module data (e.g. functions) for
builtin/extension/frozen modules
There are no plans to change this.
Second, some isolation is faulty due to bugs or implementations that did
not take subinterpreters into account. This includes things like
extension modules that rely on C globals. In these
cases bugs should be opened (some are already):
- readline module hook functions (http://bugs.python.org/issue4202)
- memory leaks on re-init (http://bugs.python.org/issue21387)
Finally, some potential isolation is missing due to the current design
of CPython. Improvements are currently going on to address gaps in this
area:
Goal
Analyze time and space usage of multiple Python thread and process pools with increasing job pool sizes.
Pools being tested:
- multiprocessing.pool.ThreadPool
- multiprocessing.pool.Pool
- concurrent.futures.ThreadPoolExecutor
- concurrent.futures.ProcessPoolExecutor
- eventlet.GreenPool
- gevent.pool.Pool
Types of tests:
io-bound tests will run the following on every job:
# Note: Gevent and Eventlet use a monkey-patched version of
# requests during their network-bound tests
import requests
def do_network_work(num: float):
with requests.Session() as s:
adapter = requests.adapters.HTTPAdapter(max_retries=3)
s.mount('http://', adapter)
s.get('http://localhost:8080/')
cpu-bound tests will run the following on every job:
from cmath import sqrt
def do_compute_work(num: float):
return sqrt(sqrt(sqrt(num)))
Resetting an interpreter’s state
It may be nice to re-use an existing subinterpreter instead of
spinning up a new one. Since an interpreter has substantially more
state than just the __main__ module, it isn’t so easy to put an
interpreter back into a pristine/fresh state. In fact, there may
be parts of the state that cannot be reset from Python code.
A possible solution is to add an Interpreter.reset() method. This
would put the interpreter back into the state it was in when newly
created. If called on a running interpreter it would fail (hence the
main interpreter could never be reset). This would likely be more
efficient than creating a new subinterpreter, though that depends on
what optimizations will be made later to subinterpreter creation.
Before moving towards creating threads let me just tell you, When to use Multithreading in Python?
Multithreading is very useful for saving time and improving performance but it cannot be applied everywhere. In the previous Vice-City example, the music threads are independent, the thread that was taking input from the user. In case these threads were interdependent Multithreading could not be used.
In Real Life, you might be calling web service using API or might be waiting for a packet on your network socket so at that time you are waiting and your CPU is not doing anything. Multi-Threading tries to utilize this idle time and during that idle time, you want to see your CPU do some work accomplished.
So, let’s use Multi-threading to improve the time that will execute the program much faster
Resetting __main__
As proposed, every call to Interpreter.run() will execute in the
namespace of the interpreter’s existing __main__ module. This means
that data persists there between run() calls. Sometimes this isn’t
desirable and you want to execute in a fresh __main__. Also,
you don’t necessarily want to leak objects there that you aren’t using
any more.
Note that the following won’t work right because it will clear too much
(e.g. __name__ and the other «__dunder__» attributes:
interp.run('globals().clear()')
Possible solutions include:
- a create() arg to indicate resetting __main__ after each
run call - an Interpreter.reset_main flag to support opting in or out
after the fact - an Interpreter.reset_main() method to opt in when desired
- importlib.util.reset_globals()
Also note that resetting __main__ does nothing about state stored
in other modules. So any solution would have to be clear about the
scope of what is being reset. Conceivably we could invent a mechanism
by which any (or every) module could be reset, unlike reload()
which does not clear the module before loading into it. Regardless,
since __main__ is the execution namespace of the interpreter,
resetting it has a much more direct correlation to interpreters and
their dynamic state than does resetting other modules. So a more
generic module reset mechanism may prove unnecessary.
Terminating Processes¶
Although it is better to use the poison pill method of signaling to
a process that it should exit (see ), if
a process appears hung or deadlocked it can be useful to be able to
kill it forcibly. Calling terminate() on a process object kills
the child process.
import multiprocessing
import time
def slow_worker():
print 'Starting worker'
time.sleep(0.1)
print 'Finished worker'
if __name__ == '__main__'
p = multiprocessing.Process(target=slow_worker)
print 'BEFORE:', p, p.is_alive()
p.start()
print 'DURING:', p, p.is_alive()
p.terminate()
print 'TERMINATED:', p, p.is_alive()
p.join()
print 'JOINED:', p, p.is_alive()
Note
It is important to join() the process after terminating it
in order to give the background machinery time to update the
status of the object to reflect the termination.
Daemon Processes¶
By default the main program will not exit until all of the children
have exited. There are times when starting a background process that
runs without blocking the main program from exiting is useful, such as
in services where there may not be an easy way to interrupt the
worker, or where letting it die in the middle of its work does not
lose or corrupt data (for example, a task that generates “heart beats”
for a service monitoring tool).
To mark a process as a daemon, set its daemon attribute with a
boolean value. The default is for processes to not be daemons, so
passing True turns the daemon mode on.
import multiprocessing
import time
import sys
def daemon():
p = multiprocessing.current_process()
print 'Starting:', p.name, p.pid
sys.stdout.flush()
time.sleep(2)
print 'Exiting :', p.name, p.pid
sys.stdout.flush()
def non_daemon():
p = multiprocessing.current_process()
print 'Starting:', p.name, p.pid
sys.stdout.flush()
print 'Exiting :', p.name, p.pid
sys.stdout.flush()
if __name__ == '__main__'
d = multiprocessing.Process(name='daemon', target=daemon)
d.daemon = True
n = multiprocessing.Process(name='non-daemon', target=non_daemon)
n.daemon = False
d.start()
time.sleep(1)
n.start()
The output does not include the “Exiting” message from the daemon
process, since all of the non-daemon processes (including the main
program) exit before the daemon process wakes up from its 2 second
sleep.
$ python multiprocessing_daemon.py Starting: daemon 13866 Starting: non-daemon 13867 Exiting : non-daemon 13867
Determining the Current Process¶
Passing arguments to identify or name the process is cumbersome, and
unnecessary. Each Process instance has a name with a default
value that can be changed as the process is created. Naming processes
is useful for keeping track of them, especially in applications with
multiple types of processes running simultaneously.
import multiprocessing
import time
def worker():
name = multiprocessing.current_process().name
print name, 'Starting'
time.sleep(2)
print name, 'Exiting'
def my_service():
name = multiprocessing.current_process().name
print name, 'Starting'
time.sleep(3)
print name, 'Exiting'
if __name__ == '__main__'
service = multiprocessing.Process(name='my_service', target=my_service)
worker_1 = multiprocessing.Process(name='worker 1', target=worker)
worker_2 = multiprocessing.Process(target=worker) # use default name
worker_1.start()
worker_2.start()
service.start()
The debug output includes the name of the current process on each
line. The lines with Process-3 in the name column correspond to
the unnamed process worker_1.
Make RunFailedError.__cause__ lazy
An uncaught exception in a subinterpreter (from run()) is copied
to the calling interpreter and set as __cause__ on a
RunFailedError which is then raised. That copying part involves
some sort of deserialization in the calling intepreter, which can be
expensive (e.g. due to imports) yet is not always necessary.
So it may be useful to use an ExceptionProxy type to wrap the
serialized exception and only deserialize it when needed. That could
be via ExceptionProxy__getattribute__() or perhaps through
RunFailedError.resolve() (which would raise the deserialized
exception and set RunFailedError.__cause__ to the exception.
Concerns
Some have argued that subinterpreters do not add sufficient benefit
to justify making them an official part of Python. Adding features
to the language (or stdlib) has a cost in increasing the size of
the language. So an addition must pay for itself. In this case,
subinterpreters provide a novel concurrency model focused on isolated
threads of execution. Furthermore, they provide an opportunity for
changes in CPython that will allow simultaneous use of multiple CPU
cores (currently prevented by the GIL).
Alternatives to subinterpreters include threading, async, and
multiprocessing. Threading is limited by the GIL and async isn’t
the right solution for every problem (nor for every person).
Multiprocessing is likewise valuable in some but not all situations.
Direct IPC (rather than via the multiprocessing module) provides
similar benefits but with the same caveat.
Notably, subinterpreters are not intended as a replacement for any of
the above. Certainly they overlap in some areas, but the benefits of
subinterpreters include isolation and (potentially) performance. In
particular, subinterpreters provide a direct route to an alternate
concurrency model (e.g. CSP) which has found success elsewhere and
will appeal to some Python users. That is the core value that the
interpreters module will provide.
«stdlib support for subinterpreters adds extra burden
on C extension authors»
In the section below we identify ways in
which isolation in CPython’s subinterpreters is incomplete. Most
notable is extension modules that use C globals to store internal
state. PEP 3121 and PEP 489 provide a solution for most of the
problem, but one still remains. Until that is resolved
(see PEP 573), C extension authors will face extra difficulty
to support subinterpreters.
Consequently, projects that publish extension modules may face an
increased maintenance burden as their users start using subinterpreters,
where their modules may break. This situation is limited to modules
that use C globals (or use libraries that use C globals) to store
internal state. For numpy, the reported-bug rate is one every 6
months.
Ultimately this comes down to a question of how often it will be a
problem in practice: how many projects would be affected, how often
their users will be affected, what the additional maintenance burden
will be for projects, and what the overall benefit of subinterpreters
is to offset those costs. The position of this PEP is that the actual
extra maintenance burden will be small and well below the threshold at
which subinterpreters are worth it.
«creating a new concurrency API deserves much more thought and
experimentation, so the new module shouldn’t go into the stdlib
right away, if ever»
Introducing an API for a a new concurrency model, like happened with
asyncio, is an extremely large project that requires a lot of careful
consideration. It is not something that can be done a simply as this
PEP proposes and likely deserves significant time on PyPI to mature.
(See Nathaniel’s post on python-dev.)
However, this PEP does not propose any new concurrency API. At most
it exposes minimal tools (e.g. subinterpreters, channels) which may
be used to write code that follows patterns associated with (relatively)
new-to-Python . Those tools could
also be used as the basis for APIs for such concurrency models.
Again, this PEP does not propose any such API.
- «there is no point to exposing subinterpreters if they still share
the GIL» - «the effort to make the GIL per-interpreter is disruptive and risky»
A common misconception is that this PEP also includes a promise that
subinterpreters will no longer share the GIL. When that is clarified,
the next question is «what is the point?». This is already answered
at length in this PEP. Just to be clear, the value lies in:
* increase exposure of the existing feature, which helps improve the code health of the entire CPython runtime * expose the (mostly) isolated execution of subinterpreters * preparation for per-interpreter GIL * encourage experimentation
«data sharing can have a negative impact on cache performance
in multi-core scenarios»
(See .)
Subinterpreters are inherently isolated (with caveats explained below),
in contrast to threads. So the same communicate-via-shared-memory
approach doesn’t work. Without an alternative, effective use of
concurrency via subinterpreters is significantly limited.
The key challenge here is that sharing objects between interpreters
faces complexity due to various constraints on object ownership,
visibility, and mutability. At a conceptual level it’s easier to
reason about concurrency when objects only exist in one interpreter
at a time. At a technical level, CPython’s current memory model
limits how Python objects may be shared safely between interpreters;
effectively objects are bound to the interpreter in which they were
created. Furthermore the complexity of object sharing increases as
subinterpreters become more isolated, e.g. after GIL removal.
Consequently,the mechanism for sharing needs to be carefully considered.
There are a number of valid solutions, several of which may be
appropriate to support in Python. This proposal provides a single basic
solution: «channels». Ultimately, any other solution will look similar
to the proposed one, which will set the precedent. Note that the
implementation of Interpreter.run() will be done in a way that
allows for multiple solutions to coexist, but doing so is not
technically a part of the proposal here.
Regarding the proposed solution, «channels», it is a basic, opt-in data
sharing mechanism that draws inspiration from pipes, queues, and CSP’s
channels.
As simply described earlier by the API summary,
channels have two operations: send and receive. A key characteristic
of those operations is that channels transmit data derived from Python
objects rather than the objects themselves. When objects are sent,
their data is extracted. When the «object» is received in the other
interpreter, the data is converted back into an object owned by that
interpreter.
To make this work, the mutable shared state will be managed by the
Python runtime, not by any of the interpreters. Initially we will
support only one type of objects for shared state: the channels provided
by create_channel(). Channels, in turn, will carefully manage
passing objects between interpreters.
This approach, including keeping the API minimal, helps us avoid further
exposing any underlying complexity to Python users. Along those same
lines, we will initially restrict the types that may be passed through
channels to the following:
- None
- bytes
- str
- int
- channels
C-extension opt-in/opt-out
By using the PyModuleDef_Slot introduced by PEP 489, we could easily
add a mechanism by which C-extension modules could opt out of support
for subinterpreters. Then the import machinery, when operating in
a subinterpreter, would need to check the module for support. It would
raise an ImportError if unsupported.
Alternately we could support opting in to subinterpreter support.
However, that would probably exclude many more modules (unnecessarily)
than the opt-out approach. Also, note that PEP 489 defined that an
extension’s use of the PEP’s machinery implies support for
subinterpreters.
When to Use Concurrency#
You’ve covered a lot of ground here, so let’s review some of the key ideas and then discuss some decision points that will help you determine which, if any, concurrency module you want to use in your project.
The first step of this process is deciding if you should use a concurrency module. While the examples here make each of the libraries look pretty simple, concurrency always comes with extra complexity and can often result in bugs that are difficult to find.
Hold out on adding concurrency until you have a known performance issue and then determine which type of concurrency you need. As Donald Knuth has said, “Premature optimization is the root of all evil (or at least most of it) in programming.”
Once you’ve decided that you should optimize your program, figuring out if your program is CPU-bound or I/O-bound is a great next step. Remember that I/O-bound programs are those that spend most of their time waiting for something to happen while CPU-bound programs spend their time processing data or crunching numbers as fast as they can.
As you saw, CPU-bound problems only really gain from using . and did not help this type of problem at all.
For I/O-bound problems, there’s a general rule of thumb in the Python community: “Use when you can, when you must.” can provide the best speed up for this type of program, but sometimes you will require critical libraries that have not been ported to take advantage of . Remember that any task that doesn’t give up control to the event loop will block all of the other tasks.
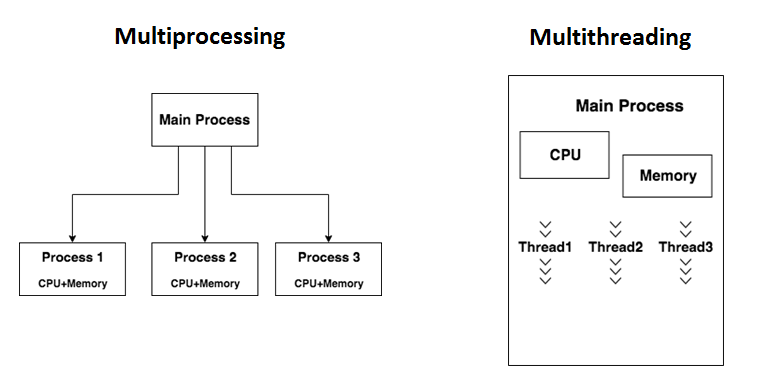
Multiprocessing vs Multithreading
Often a lot of people get confused with the ideas of multiprocessing and multithreading.
Below are some key differences,
-
Multiprocessing launches different processes which are independent to each other. On the other hand, multithreading launches threads which are still dependent on the parent process.
-
Each Process in Multiprocessing has its own CPU Power and memory which is distinct to each process. Whereas, in multithreading the individual threads utilize the same resources(CPU + Memory) present in the parent process.
-
If any process fails due to an exception, the other processes would still be running in case of Multiprocessing. On the contrary, if any thread fails, all the other threads/tasks are terminated.
-
Multiprocessing requires some special objects or some sort of shared memory to access objects in different processes. In contrast to this, sharing objects/data between threads are much easier since they share the same memory space.
-
Multiprocessing is more suitable for CPU intensive applications, wheras Multithreading is the best fit when your applications are I/O bound.
For more details on MultiThreading in Python, click here.
When Is Concurrency Useful?#
Concurrency can make a big difference for two types of problems. These are generally called CPU-bound and I/O-bound.
I/O-bound problems cause your program to slow down because it frequently must wait for input/output (I/O) from some external resource. They arise frequently when your program is working with things that are much slower than your CPU.
Examples of things that are slower than your CPU are legion, but your program thankfully does not interact with most of them. The slow things your program will interact with most frequently are the file system and network connections.
Let’s see what that looks like:

In the diagram above, the blue boxes show time when your program is doing work, and the red boxes are time spent waiting for an I/O operation to complete. This diagram is not to scale because requests on the internet can take several orders of magnitude longer than CPU instructions, so your program can end up spending most of its time waiting. This is what your browser is doing most of the time.
On the flip side, there are classes of programs that do significant computation without talking to the network or accessing a file. These are the CPU-bound programs, because the resource limiting the speed of your program is the CPU, not the network or the file system.
Here’s a corresponding diagram for a CPU-bound program:

As you work through the examples in the following section, you’ll see that different forms of concurrency work better or worse with CPU-bound and I/O-bound programs. Adding concurrency to your program adds extra code and complications, so you’ll need to decide if the potential speed up is worth the extra effort. By the end of this article, you should have enough info to start making that decision.
Here’s a quick summary to clarify this concept:
| I/O-Bound Process | CPU-Bound Process |
|---|---|
| Your program spends most of its time talking to a slow device, like a network connection, a hard drive, or a printer. | You program spends most of its time doing CPU operations. |
| Speeding it up involves overlapping the times spent waiting for these devices. | Speeding it up involves finding ways to do more computations in the same amount of time. |
You’ll look at I/O-bound programs first. Then, you’ll get to see some code dealing with CPU-bound programs.
Importable Target Functions¶
One difference between the and
examples is the extra protection for __main__ used in the
examples. Due to the way the new processes are
started, the child process needs to be able to import the script
containing the target function. Wrapping the main part of the
application in a check for __main__ ensures that it is not run
recursively in each child as the module is imported. Another approach
is to import the target function from a separate script.
For example, this main program:
import multiprocessing
import multiprocessing_import_worker
if __name__ == '__main__'
jobs = []
for i in range(5):
p = multiprocessing.Process(target=multiprocessing_import_worker.worker)
jobs.append(p)
p.start()
uses this worker function, defined in a separate module:
def worker():
"""worker function"""
print 'Worker'
return
and produces output like the first example above:
Conclusions
Among all 6 different kinds of pools and both workload types, the multiprocessing process pool is the overall winner.
Following very closely behind were the standard library’s ThreadPoolExecutor and gevent’s pool.
Eventlet’s pool and the multiprocessing thread pool were evenly matched overall.
The standard library’s process pool failed miserably on completion time for compute, even though it outperformed on time in I/O bound tests; thus, it received last place.
Each pool has a particular function that was performance tested, the IO-bound performance, and the CPU-bound performance. The performance ratings are out of 5 for average performance relative to one another across all tests, higher is better.
These ratings are very general and should not be considered performance metrics, merely a quick and potentially opinionated judgement to compare the pools.
Overall Ranks
The multiprocessing process pool performed the best overall. It wasn’t always the fastest pool but it consistently performed on or above-par relative to the other pools. This process pool really shone when run with large quantities of jobs in a I/O-bound environment. Unfortunately, the memory usage could not be tracked correctly and this was taken into account in the below ratings.
Eventlet and gevent often ran their tests very similarly, but differed in a few significant ways. Their test outputs are similar in that they have nearly-equivalent completion times and they also have incredibly stable completion times. These would be good pools to use if one wants deterministic completion times. The first difference is that eventlet consistently used much less memory during the I/O-bound tests. The second major difference is that gevent typically had the faster completion time performance.
The standard library’s thread pool fared pretty well in these tests. Its execution time was on-par with several other thread pools’ times and its memory usage was similar to those as well. It performed quite similarly to the multiprocessing thread pool, but it did not have the same memory issues present in the multiprocessing thread pool.
The multiprocessing thread pool performed well enough, but suffered from memory issues during the compute-bound tests. Its completion time performance is on-par with most of the other thread pools.
The standard library’s process pool seriously underperformed in this kind of compute-bound test. Though not present in the graphs, I observed the pool had been locking up on a single core with 100% utilization during its tests while only some of the compute work was being spread out to its workers. If not for its bad completion times in compute, this process pool may have done very well overall. Its completion times were simply a large multiple longer than most of the other pools. Its memory usage, on the other hand, measured quite low.
- Overall
- : 4.25/5
- : 4/5
- : 4/5
- : 3.5/5
- : 3.5/5
- : 3/5
- CPU-bound tasks
- : 5/5
- : 4.5/5
- : 4/5
- : 4/5
- : 3/5
- : 1/5
- IO-bound tasks
- : 5/5
- : 4.5/5
- : 4/5
- : 4/5
- : 3/5
- : 3/5
Multiprocessing Process Pool
- Pool type: process pool
- Function:
- CPU-bound time: 4/5
- CPU-bound space: 3/5
- IO-bound time: 5/5
- IO-bound space: N/A (test inconclusive)
Eliminating impact of global interpreter lock (GIL)
While working with concurrent applications, there is a limitation present in Python called the GIL (Global Interpreter Lock). GIL never allows us to utilize multiple cores of CPU and hence we can say that there are no true threads in Python. GIL is the mutex – mutual exclusion lock, which makes things thread safe. In other words, we can say that GIL prevents multiple threads from executing Python code in parallel. The lock can be held by only one thread at a time and if we want to execute a thread then it must acquire the lock first.
With the use of multiprocessing, we can effectively bypass the limitation caused by GIL −
-
By using multiprocessing, we are utilizing the capability of multiple processes and hence we are utilizing multiple instances of the GIL.
-
Due to this, there is no restriction of executing the bytecode of one thread within our programs at any one time.
Отладка регулярных выражений
А вот тут оказалось, что в мире питоне нет инструмента для интерактивной отладки регулярных выражений аналогичного прекрасному перловому модулю Regexp::Debugger (видеопрезентация), конечно есть куча онлайн-инструментов, есть какие-то виндовопроприетарные решения, но для меня это всё не то, возможно стоит использовать перловый инструмент, ибо питонные регэксы не особо отличаются от перловых, напишу инструкцию для невладеющих перловым инструментарием:
Думаю даже человек незнакомый с перлом поймёт где тут надо вписать строку, а где регулярное выражение, это флаг аналогичный питонному re.VERBOSE.
Нажимаем и шагаем по регулярному выражению, подробное описание доступных команд в документации.
How subprocesses are started on POSIX (the standard formerly known as Unix)
To understand what’s going on you need to understand how you start subprocesses on POSIX (which is to say, Linux, BSDs, macOS, and so on).
- A copy of the process is created using the system call.
- The child process replaces itself with a different program using the system call (or one of its variants, e.g. ).
The thing is, there’s nothing preventing you from just doing .
For example, here we and then print the current process’ process ID (PID):
When we run it:
As you can see both parent (PID 3619) and child (PID 3620) continue to run the same Python code.
Here’s where it gets interesting: -only is how Python creates process pools by default on Linux, and on macOS on Python 3.7 and earlier.
API for sharing data
Subinterpreters are less useful without a mechanism for sharing data
between them. Sharing actual Python objects between interpreters,
however, has enough potential problems that we are avoiding support
for that here. Instead, only mimimum set of types will be supported.
Initially this will include None, bytes, str, int,
and channels. Further types may be supported later.
The interpreters module provides a function that users may call
to determine whether an object is shareable or not:
is_shareable(obj) -> bool: Return True if the object may be shared between interpreters. This does not necessarily mean that the actual objects will be shared. Insead, it means that the objects' underlying data will be shared in a cross-interpreter way, whether via a proxy, a copy, or some other means.
This proposal provides two ways to share such objects between
interpreters.
First, channels may be passed to run() via the channels
keyword argument, where they are effectively injected into the target
interpreter’s __main__ module. While passing arbitrary shareable
objects this way is possible, doing so is mainly intended for sharing
meta-objects (e.g. channels) between interpreters. It is less useful
to pass other objects (like bytes) to run directly.
Second, the main mechanism for sharing objects (i.e. their data) between
interpreters is through channels. A channel is a simplex FIFO similar
to a pipe. The main difference is that channels can be associated with
zero or more interpreters on either end. Like queues, which are also
many-to-many, channels are buffered (though they also offer methods
with unbuffered semantics).
Python objects are not shared between interpreters. However, in some
cases data those objects wrap is actually shared and not just copied.
One example might be PEP 3118 buffers. In those cases the object in the
original interpreter is kept alive until the shared data in the other
interpreter is no longer used. Then object destruction can happen like
normal in the original interpreter, along with the previously shared
data.
The interpreters module provides the following functions related
to channels:
create_channel() -> (RecvChannel, SendChannel): Create a new channel and return (recv, send), the RecvChannel and SendChannel corresponding to the ends of the channel. Both ends of the channel are supported "shared" objects (i.e. may be safely shared by different interpreters. Thus they may be passed as keyword arguments to "Interpreter.run()". list_all_channels() -> : Return a list of all open channel-end pairs.
The module also provides the following channel-related classes: