Bash-скрипты, часть 9: регулярные выражения
Содержание:
- Основные блоки построения выражений
- Character Classes and Bracket Expressions
- ngrep
- Technical Description
- Повторение, повторение и еще раз повторение
- Grep OR Operator
- Дик печатает. Джейн вычисляет
- Examples
- The ‘grep’ command
- Регулярные выражения и редактор sed
- Linux поиск по содержимому файлов командой find
- Grep NOT
- File and Directory Selection
- Other Options
- Заключение
Основные блоки построения выражений
В программе GNU grep, входящей в состав большинства дистрибутивов Linux, используются две формы синтаксиса регулярных выражений: основная и расширенная. Функциональность GNU grep не зависит от использования той или иной формы и одинакова в обоих случаях. В этой статье описывается основная форма синтаксиса и приводятся ее отличия от расширенной формы.
Регулярные выражения состоят из символов и операторов, дополняемых метасимволами. Большинство символов соответствуют своим значениям, а большинство метасимволов необходимо отделять символом обратной косой черты (\). Основными операторами являются:
- Конкатенация
- В результате конкатенации (объединения) двух регулярных выражений мы получаем более длинное выражение. Например, в строке abcdcba для регулярного выражения a будет найдено два соответствия (первый и последний символы a); так же дело обстоит и с выражением b. Однако для регулярного выражения ab будет найдено только одно соответствие abcdcba, а для выражения ba – только соответствие abcdcba.
- Повторение
- Оператор Клини *, или оператор повторения соответствует предшествующему регулярному выражению, повторяющемуся 0 или более раз. Так, регулярному выражению a*b будет соответствовать любая строка, содержащая любое количество символов a и оканчивающаяся символом b, в том числе строка, содержащая один только символ b. Оператор Клини * не нужно записывать в виде escape-последовательности, поэтому если вы хотите найти в выражении буквенное значение символа звездочки (*), то этот символ должен быть записан в виде escape-последовательности. Использование символа * в данном случае отличается от его использования при подстановке имен, в которой он соответствует любой строке.
- Чередование
- Оператор чередования (|) определяет соответствие либо для предшествующего, либо для последующего выражения. При использовании основного синтаксиса он должен быть записан в виде escape-последовательности. Так, регулярному выражению a*\|b*c будет соответствовать любая строка, содержащая любое количество символов a или b (но не обоих одновременно) и оканчивающаяся символом c, в том числе строка, содержащая один только символ c.
Чтобы регулярные выражения не обрабатывались командным интерпретатором, часто их необходимо заключать в кавычки.
Character Classes and Bracket Expressions
A bracket expression is a list of characters enclosed by and . It matches any single character in that list; if the first character of the list is the caret ^ then it matches any character not in the list. For example, the regular expression matches any single digit.
Within a bracket expression, a range expression consists of two characters separated by a hyphen. It matches any single character that sorts between the two characters, inclusive, using the locale’s collating sequence and character set. For example, in the default C locale, is equivalent to . Many locales sort characters in dictionary order, and in these locales is typically not equivalent to ; it might be equivalent to , for example. To obtain the traditional interpretation of bracket expressions, you can use the C locale by setting the LC_ALL environment variable to the value C.
Finally, certain named classes of characters are predefined within bracket expressions, as follows. Their names are self explanatory, and they are , , , , , , , , , , and . For example, ] means the character class of numbers and letters in the current locale. In the C locale and ASCII character set encoding, this is the same as . (Note that the brackets in these class names are part of the symbolic names, and must be included in addition to the brackets delimiting the bracket expression.) Most meta-characters lose their special meaning inside bracket expressions. To include a literal place it first in the list. Similarly, to include a literal ^ place it anywhere but first. Finally, to include a literal —, place it last.
ngrep
Еще один заброшенный проект на SourceForge. Программа представляет из-себя гибрид и , причем к первому гораздо ближе, чем ко второму.
Наблюдение за сетевым трафиком по порту и ключевому слову.
Наблюдение за сетевым трафиком по порту и ключевым словам без учета регистра, сравнивать слова целиком.
По-строчный вывод трафика.
А еще есть киллер-фича. Можно задать hex строку, которой сопоставляет бинарные данные пакета. Например, можно задать сигнатуру завирусованной гифки, чтобы затем настроить файрвол на раннее обнаружение.
Жаль, что разработка проекта прекращена, может в итоге получиться вполне годный самоворо-паровозо-вертолет парсер и анализатор сетевого трафика.
Technical Description
grep searches the named input FILEs (or standard input if no files are named, or if a single dash («—«) is given as the file name) for lines containing a match to the given PATTERN. By default, grep prints the matching lines.
Also, three variant programs egrep, fgrep and rgrep are available:
- egrep is the same as running grep -E. In this mode, grep evaluates your PATTERN string as an extended regular expression (ERE). Nowadays, ERE does not «extend» very far beyond basic regular expressions, but they can still be very useful. For more information about extended regular expressions, see , below.
- fgrep is the same as running grep -F. In this mode, grep evaluates your PATTERN string as a «fixed string» — every character in your string is treated literally. For example, if your string contains an asterisk («*«), grep will try to match it with an actual asterisk rather than interpreting this as a wildcard. If your string contains multiple lines (if it contains newlines), each line will be considered a fixed string, and any of them can trigger a match.
- rgrep is the same as running grep -r. In this mode, grep will perform its search recursively. If it encounters a directory, it will traverse into that directory and continue searching. (Symbolic links are ignored; if you want to search directories that are symbolically linked, you should use the -R option instead).
In older operating systems, egrep, fgrep and rgrep were distinct programs with their own executables. In modern systems, these special command names are shortcuts to grep with the appropriate flags enabled. They are functionally equivalent.
Повторение, повторение и еще раз повторение
Ранее мы узнали о буквенных, позиционных и двух видах операторов выбора. Используя их, можно создать шаблоны предсказуемой длины. Возвращаясь к именам пользователей, можно проверить, что каждое пользовательское имя начинается с буквы, за которой имеет ровно семь букв или цифр, используя следующее регулярное выражение:
Однако такой способ чересчур громоздкий. Кроме того, он подходит только для имен, содержащих ровно восемь символов. Этот способ не подходит для нахождения имен, содержащих от трех до восьми символов, которые также обычны для корректных имен пользователей.
Регулярные выражения могут включать модификаторы повторения. Модификатор повторения может означать число включений, равное а) нулю, одному или более; б) одному или более; в) от пяти до десяти; г) ровно трем. Модификаторы повторения должны быть объединены с другими шаблонами, они ничего не означают в отдельности.
Например, регулярное выражение
^{2,7}$
осуществляет фильтрацию имени пользователя с ограничениями, описанными раньше. Имя пользователя — это строка, начинающаяся с буквы, за которой следует как минимум две, но не более семи букв или чисел, и замыкаемая символом конца строки.
Операторы положения также необходимы здесь. Без двух этих операторов пользовательские имена произвольной длины будут ошибочно считаться корректными. Почему? Рассмотрим регулярное выражение:
^{2,7}
Оно задает вопрос: «Начинается ли строка с буквы, за которой следует от двух до семи букв или цифр?» Но оно не упоминает об условиях завершения строки. Таким образом, строка удовлетворит регулярному выражению, но очевидно слишком длинна, чтобы быть корректным именем пользователя. Также, если пропустить начинающий выражение оператор или оба оператора положения, корректными будут признаны строки, оканчивающиеся или содержащие соответственно. Если искомая строка должна быть определенной длины, то необходимо включить в регулярное выражение операторы начала и окончания строки.
Вот еще несколько примеров:
- Можно использовать , чтобы найти два или более повторений. Регулярное выражение найдет , , и так далее.
- Модификаторы повторения , и найдут ни одного или одно, одно или более, ноль и более вхождений шаблона соответственно. (Можно считать короткой записью выражения ).
Регулярное выражение найдет или ; регулярное выражение найдет или .
Регулярное выражение найдет , и так далее.
Конструкция найдет , , и так далее.
- Можно применять модификаторы повторения для отдельных букв, как это было показано только что, а также и для более сложных комбинаций. Используйте скобки и (как это делается в математике), чтобы применить модификатор для выражения. Вот еще один пример: имея следующий файл test.txt:
The rain in Spain falls mainly on the the plain. It was the best of of times; it was the worst of times.
Команда выведет:
on the the plain. It was the best of of times;
- Оператор регулярного выражения является шаблоном границы слова или (). Регулярное выражение читается как «Найти последовательность, состоящую из целого слова ‘the’ или ‘of’, за которым следует небуквенный символ». Поясню, почему так необходим оператор — это пустая строка в начале или конце слова. Необходимо поставить одну или несколько букв между словами, иначе регулярное выражение не найдет совпадения.
Grep OR Operator
Use any one of the following 4 methods for grep OR. I prefer method number 3 mentioned below for grep OR operator.
1. Grep OR Using \|
If you use the grep command without any option, you need to use \| to separate multiple patterns for the or condition.
grep 'pattern1\|pattern2' filename
For example, grep either Tech or Sales from the employee.txt file. Without the back slash in front of the pipe, the following will not work.
$ grep 'Tech\|Sales' employee.txt 100 Thomas Manager Sales $5,000 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 500 Randy Manager Sales $6,000
2. Grep OR Using -E
grep -E option is for extended regexp. If you use the grep command with -E option, you just need to use | to separate multiple patterns for the or condition.
grep -E 'pattern1|pattern2' filename
For example, grep either Tech or Sales from the employee.txt file. Just use the | to separate multiple OR patterns.
$ grep -E 'Tech|Sales' employee.txt 100 Thomas Manager Sales $5,000 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 500 Randy Manager Sales $6,000
3. Grep OR Using egrep
egrep is exactly same as ‘grep -E’. So, use egrep (without any option) and separate multiple patterns for the or condition.
egrep 'pattern1|pattern2' filename
For example, grep either Tech or Sales from the employee.txt file. Just use the | to separate multiple OR patterns.
$ egrep 'Tech|Sales' employee.txt 100 Thomas Manager Sales $5,000 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 500 Randy Manager Sales $6,000
4. Grep OR Using grep -e
Using grep -e option you can pass only one parameter. Use multiple -e option in a single command to use multiple patterns for the or condition.
grep -e pattern1 -e pattern2 filename
For example, grep either Tech or Sales from the employee.txt file. Use multiple -e option with grep for the multiple OR patterns.
$ grep -e Tech -e Sales employee.txt 100 Thomas Manager Sales $5,000 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 500 Randy Manager Sales $6,000
Дик печатает. Джейн вычисляет
Набираемую в командной строке UNIX команду можно представить как предложение:
- выполняемые файлы, такие как и , — это глаголы, действия;
- данные, выводимые на экран в результате работы программы, — это существительные, данные, которые должны быть внимательно изучены или использованы;
- операторы командной оболочки, такие как (конвейер) или (перенаправление стандартного вывода), — это союзы, соединяющие простые предложения.
Например, команда , которая подсчитывает число файлов и каталогов в текущем каталоге (исключая специальные объекты и ), состоит из двух предложений. Первое предложение — это глагол, перечисляющий содержимое текущей папки; второе предложение — это другой глагол, считающий строки. Первое предложение производит данные, которые используются вторым, а союз — конвейер — объединяет оба предложения.
Большинство команд, описанных в предыдущих статья, действуют таким же образом и имеют подобную предложению структуру.
Но без некоторого грамматического соуса, команда становится похожей на что-то типа «Дик печатает. Джейн вычисляет». Конечно, в этом примере первое предложение выполняет свою работу, но оно не так красиво, как текст «Гамлета». Решение многих сложных проблем требует использования прилагательных.
Практически все нетривиальные проблемы требуют выделять нужные данные. Число и вид атрибутов может меняться очень сильно, но с другой стороны, каждое решение (явно или неявно) описывает форму и структуру информации, которую оно ищет и обрабатывает, производя новую информацию в новой форме.
В командной строке регулярные выражения действуют как прилагательные — описания или уточнения. Когда они применяются к входным данным, регулярные выражения позволяют отличать полезные данные от бесполезных.
Examples
Tip
If you haven’t already see our section we suggest reviewing that section first.
grep chope /etc/passwd
Search /etc/passwd for user chope.
grep "May 31 03" /etc/httpd/logs/error_log
Search the Apache error_log file for any error entries that happened on May 31st at 3AM. By adding quotes around the string this allows you to place spaces in the grep search.
grep -r "computerhope" /www/
Recursively search the directory /www/, and all subdirectories, for any lines of any files which contain the string «computerhope«.
grep -w "hope" myfile.txt
Search the file myfile.txt for lines containing the word «hope«. Only lines containing the distinct word «hope» will be matched. Lines in which «hope» is part of a word will not be matched.
grep -cw "hope" myfile.txt
Same as previous command, but displays a count of how many lines were matched, rather than the matching lines themselves.
grep -cvw "hope" myfile.txt
Inverse of previous command: displays a count of the lines in myfile.txt which do not contain the word «hope».
grep -l "hope" /www/*
Display the filenames (but not the matching lines themselves) of any files in /www/ (but not its subdirectories) whose contents include the string «hope«.
The ‘grep’ command
Suppose you want to search a particular information the postal code from a text file.
You may manually skim the content yourself to trace the information. A better option is to use the grep command. It will scan the document for the desired information and present the result in a format you want.
Syntax:
grep search_string
Let’s see it in action —
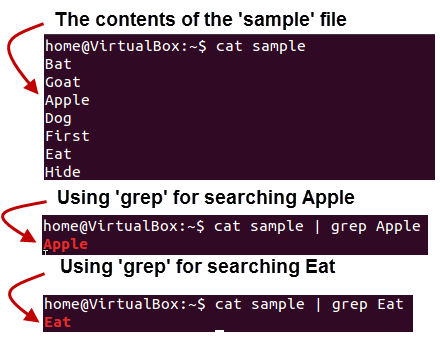
Here, grep command has searched the file ‘sample’, for the string ‘Apple’ and ‘Eat’.
Following options can be used with this command.
| Option | Function |
|---|---|
| -v | Shows all the lines that do not match the searched string |
| -c | Displays only the count of matching lines |
| -n | Shows the matching line and its number |
| -i | Match both (upper and lower) case |
| -l | Shows just the name of the file with the string |
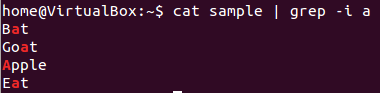
Let us try the first option ‘-i’ on the same file use above —
Using the ‘i’ option grep has filtered the string ‘a’ (case-insensitive) from the all the lines.
Регулярные выражения и редактор sed
В статье «Изучаем Linux 101: текстовые потоки и фильтры» мы рассказывали о потоковом редакторе sed и упоминали о том, что sed использует регулярные выражения. Регулярные выражения могут использоваться как в адресных выражениях, так и в выражениях замены.
Если вы просто что-то ищете, то, вероятно, вам подойдет команда. Если же вам необходимо извлечь строку поиска (или связанную с ней строку) из списка всех найденных строк для дальнейшей обработки, то для этого можно использовать редактор . Итак, давайте выясним, как это работает. Для начала напомним вам, что наши файлы text1 и text2 содержали номера и имена фруктов, разделенные пробелами и символами табуляции, а файл text3 – повторяющееся предложение. Содержимое этих трех файлов представлено в листинге 10.
Листинг 10. Содержимое файлов text1, text2 и text3
ian@attic4:~/lpi103-7$ cat text 1 apple 2 pear 3 banana 9 plum 3 banana 10 apple This is a sentence. This is a sentence. This is a sentence.
Сначала мы используем команды и для извлечения строк, начинающихся с одной или нескольких цифр, после которых следует символ-разделитель (пробел или табуляция). В обычном режиме выводит все строки, поэтому мы используем его опцию , чтобы избежать этого, а затем используем команду редактора для вывода только тех строк, которые соответствуют нашему регулярному выражению. Чтобы быть уверенными, что мы используем в обоих случаях одно и то же регулярное выражение, мы присвоили его переменной.
Листинг 11. Поиск с использованием grep и sed
ian@attic4:~/lpi103-7$ grep "$oursearch" text text1:1 apple text1:2 pear text1:3 banana text2:9 plum text2:3 banana text2:10 apple ian@attic4:~/lpi103-7$ cat text | sed -ne "/$oursearch/p" 1 apple 2 pear 3 banana 9 plum 3 banana 10 apple
Заметим, что команда отображает имена файлов только в тех случаях, когда поиск выполняется в нескольких файлах. Поскольку для передачи входных данных редактору мы использовали команду , то ничего не знает об именах исходных файлов. Тем не менее, совпадения строк идентичны в обоих случаях, как мы и ожидали.
Теперь предположим, что нас интересует только первое слово из каждой найденной строки. В нашем случае этим словом является название фрукта, но мы могли бы искать URL-адреса, имена файлов или что-нибудь еще. В нашем примере нам будет достаточно удалить из строк те фрагменты, которую будут соответствовать нашему поиску. Давайте сделаем это, как показано в листинге 12.
Листинг 12. Удаление нумерации строк с помощью sed
ian@attic4:~/lpi103-7$ cat text | sed -ne "/$oursearch/s/$oursearch//p" apple pear banana plum banana apple
В нашем последнем примере предположим, что после имени фрукта в наших строках могут содержаться другие данные. Мы добавим строку «lemon pie» (лимонный пирог) к нашим данным и посмотрим, как можно избавиться от лимона. Также мы отсортируем вывод и избавимся от повторяющихся значений. В итоге мы получим список найденных фруктов, не содержащий повторений.
В листинге 13 представлены два способа решения этой задачи. В первом из них мы удалили из каждой строки нумерацию и символы-разделители, а затем удалили все данные после первого пробела (или символа табуляции) и напечатали все, что осталось. Во втором примере мы использовали круглые скобки, чтобы разбить всю строку на три части (число и следующий за ним знак-разделитель, второе слово и все остальное). Затем мы используем команду для замены всей строки одним только вторым словом и выводим результат. Вы можете попробовать самостоятельно выполнить этот пример, опустив третью часть, \(.*\), и попытаться объяснить полученный результат.
Листинг 13. Окончательный список фруктов
ian@attic4:~/lpi103-7$ echo "7 lemon pie" | cat - text | > sed -ne "/$oursearch/s/\($oursearch\)\(]*\)\(.*\)/\2/p" | > sort | uniq apple banana lemon pear
Некоторые более ранние версии не поддерживают использование расширенной формы синтаксиса регулярных выражений. Если вы работаете с такой версией, то используйте опцию , чтобы указать на то, что вы используете расширенную форму синтаксиса. В листинге 14 показано, что необходимо изменить в переменной и команде для выполнения тех же действий с расширенными регулярными выражениями, что были выполнены в листинге 13 с основными регулярными выражениями.
Листинг 14. Использование расширенной формы синтаксиса регулярных выражений в sed
ian@attic4:~/lpi103-7$ echo "7 lemon pie" | cat - text | > sed -nre "/$oursearchx/s/($oursearchx)(]*)(.*)/\2/p" | > sort | uniq apple banana lemon pear plum
Эта статья лишь частично затронула вопросы работы с регулярными выражениями в командной строке Linux с использованием и . Если вы хотите узнать больше об этих неоценимых инструментах, обратитесь к соответствующим man-страницам.
Linux поиск по содержимому файлов командой find
Своего рода швейцарским ножом в розыске файлов является команда find. Отметим, что она имеет множество опций, которые смогут кардинально изменять механизм поиска. Мы изложим лишь основные принципы, а с остальными способностями ознакомьтесь в справке по команде. Базовый принцип использования find состоит в указании папки поиска и опций. Например, выражение «find ~/ -name *.cpp» осуществит поиск файлов, имеющих продолжение «cpp» по всем каталогам, находящимся в личной директории пользователя.
Значение, указанное после опции -name, задает шаблон соотношения имени файла. Вы можете использовать опцию -type для указания типа файла, где в свойстве значений нужно использовать специальные буквы: d — директория, f — файл, l — символическая ссылка и т. д. Функции -user, -group и -size также довольно полезны. Их значениями являются имя пользователя, имя категории и размер файла в байтах.
С поддержкою опции -exec каждому файлу, предназначенному для установки соответствия, можно добавить случайную обработку. Таким образом, появляется возможность осуществления поиска, как по имени файла, так и по охватываемому. Ниже приводится пример комбинирования команды find и grep за счет использования функции -exec.
А возможно и еще проще
Grep NOT
7. Grep NOT using grep -v
Using grep -v you can simulate the NOT conditions. -v option is for invert match. i.e It matches all the lines except the given pattern.
grep -v 'pattern1' filename
For example, display all the lines except those that contains the keyword “Sales”.
$ grep -v Sales employee.txt 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 400 Nisha Manager Marketing $9,500
You can also combine NOT with other operator to get some powerful combinations.
For example, the following will display either Manager or Developer (bot ignore Sales).
$ egrep 'Manager|Developer' employee.txt | grep -v Sales 200 Jason Developer Technology $5,500 400 Nisha Manager Marketing $9,500
If you enjoyed this article, you might also like..
|
|
File and Directory Selection
| -a, —text | Process a binary file as if it were text; this is equivalent to the —binary-files=text option. |
| —binary-files=TYPE | If the first few bytes of a file indicate that the file contains binary data, assume that the file is of type TYPE. By default, TYPE is binary, and grep normally outputs either a one-line message saying that a binary file matches, or no message if there is no match. If TYPE is without-match, grep assumes that a binary file does not match; this is equivalent to the -I option. If TYPE is text, grep processes a binary file as if it were text; this is equivalent to the -a option. Warning: grep —binary-files=text might output binary garbage, which can have nasty side effects if the output is a terminal and if the terminal driver interprets some of it as commands. |
| -D ACTION, —devices=ACTION | If an input file is a device, FIFO or socket, use ACTION to process it. By default, ACTION is read, which means that devices are read just as if they were ordinary files. If ACTION is skip, devices are silently skipped. |
| -d ACTION, —directories=ACTION | If an input file is a directory, use ACTION to process it. By default, ACTION is read, i.e., read directories just as if they were ordinary files. If ACTION is skip, silently skip directories. If ACTION is recurse, read all files under each directory, recursively, following symbolic links only if they are on the command line. This is equivalent to the -r option. |
| —exclude=GLOB | Skip files whose base name matches GLOB (using wildcard matching). A file-name glob can use *, ?, and as wildcards, and \ to quote a wildcard or backslash character literally. |
| —exclude-from=FILE | Skip files whose base name matches any of the file-name globs read from FILE (using wildcard matching as described under —exclude). |
| —exclude-dir=DIR | Exclude directories matching the pattern DIR from recursive searches. |
| -I | Process a binary file as if it did not contain matching data; this is equivalent to the —binary-files=without-match option. |
| —include=GLOB | Search only files whose base name matches GLOB (using wildcard matching as described under —exclude). |
| -r, —recursive | Read all files under each directory, recursively, following symbolic links only if they are on the command line. This is equivalent to the -d recurse option. |
| -R, —dereference-recursive | Read all files under each directory, recursively. Follow all symbolic links, unlike -r. |
Other Options
| —line-buffered | Use line buffering on output. This can cause a performance penalty. |
| —mmap | If possible, use the mmap system call to read input, instead of the default read system call. In some situations, —mmap yields better performance. However, —mmap can cause undefined behavior (including core dumps) if an input file shrinks while grep is operating, or if an I/O error occurs. |
| -U, —binary | Treat the file(s) as binary. By default, under MS-DOS and MS-Windows, grep guesses the file type by looking at the contents of the first 32 KB read from the file. If grep decides the file is a text file, it strips the CR characters from the original file contents (to make regular expressions with ^ and $ work correctly). Specifying -U overrules this guesswork, causing all files to be read and passed to the matching mechanism verbatim; if the file is a text file with CR/LF pairs at the end of each line, this will cause some regular expressions to fail. This option has no effect on platforms other than MS-DOS and MS-Windows. |
| -z, —null-data | Treat the input as a set of lines, each terminated by a zero byte (the ASCII NUL character) instead of a newline. Like the -Z or —null option, this option can be used with commands like sort -z to process arbitrary file names. |
Заключение
Множество инструментальных средств и методов доступны на UNIX-системах для создания регулярных выражений. Вы ознакомились с лучшими из них.
Эти инструментальные средства предоставляют прекрасные возможности для создания, тестирования и улучшения регулярных выражений. Использование этих инструментальных средств и приемов в UNIX-системах возможно лучший путь, чтобы научиться создавать сложные регулярные выражения.
Похожие темы
-
Know your regular expressions:
ознакомьтесь с оригиналом статьи (EN). -
«Hone your regexp pattern-building skills»
(Michael Stutz, developerWorks, июль 2006): эта статья описывает несколько регулярных выражений для системного администрирования, которые вы, возможно, найдете полезными для себя. -
Speaking UNIX, Part 9: Regular expressions (EN)
(Martin Streicher, developerWorks, апрель 2007): эта статья представляет собой короткий учебник для начинающих создавать регулярные выражения. - Ознакомьтесь с другими статьями, написанными Михаэлем Штутцом (Michael Stutz):
- Разделы библиотеки информации по AIX и UNIX:(EN)
- Системное администрирование
- Разработка приложений
- Производительность
- Переносимость
- Безопасность
- Подсказки
- Инструментальные средства и утилиты
- Java-технологии
- Linux
- Open source
- Podcasts: оставайтесь на связи с техническими экспертами IBM.(EN)
- GNU Project Web site: загрузите бесплатную копию GNU для вашей операционной системы.(EN)
- PCRE: загрузите бесплатную копию PCRE.(EN)
- txt2regex script: загрузите бесплатную копию программы txt2regex.(EN)
- regex: загрузите бесплатную копию библиотек регулярных выражений Генри Спенсера (Henry Spencer’s regular expression libraries).(EN)