Javascript для начинающих: изучаем регулярные выражения
Содержание:
Замена текста REGEXP_REPLACE
Поиск и замена — одна из лучших областей применения регулярных выражений. Текст замены может включать ссылки на части исходного выражения (называемые обратными ссылками), открывающие чрезвычайно мощные возможности при работе с текстом. Допустим, имеется список имен, разделенный запятыми, и его содержимое необходимо вывести по два имени в строке. Одно из решений заключается в том, чтобы заменить каждую вторую запятую символом новой строки. Сделать это при помощи стандартной функции нелегко, но с функцией задача решается просто. Общий синтаксис ее вызова:
REGEXP_REPLACE (исходная_строка, шаблон ]])
Здесь исходная_строка — строка, в которой выполняется поиск; шаблон — регулярное выражение, совпадение которого ищется в исходной_строке; начальная_позиция — позиция, с которой начинается поиск; модификаторы — один или несколько модификаторов, управляющих процессом поиска. Пример:
DECLARE
names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Jeff,Aaron';
names_adjusted VARCHAR2(61);
comma_delimited BOOLEAN;
extracted_name VARCHAR2(60);
name_counter NUMBER;
BEGIN
-- Искать совпадение шаблона
comma_delimited := REGEXP_LIKE(names,'^(*,)+(*){1}$', 'i');
-- Продолжать, только если мы действительно
-- работаем со списком, разделенным запятыми.
IF comma_delimited THEN
names := REGEXP_REPLACE(
names,
'(*),(*),',
'\1,\2' || chr(10) );
END IF;
DBMS_OUTPUT.PUT_LINE(names);
END;
Результат выглядит так:
Anna,Matt Joe,Nathan Andrew,Jeff Aaron
При вызове функции передаются три аргумента:
- names — исходная строка;
- ‘(*),(*),’ — выражение, описывающее заменяемый текст (см. ниже);
- ‘\1,\2 ‘ || chr(10) — текст замены. \1 и \2 — обратные ссылки, заложенные в основу нашего решения. Подробные объяснения также приводятся ниже.
Выражение, описывающее искомый текст, состоит из двух подвыражений в круглых скобках и двух запятых.
- Совпадение должно начинаться с имени.
- За именем должна следовать запятая.
- Затем идет другое имя.
- И снова одна запятая.
Наша цель — заменить каждую вторую запятую символом новой строки. Вот почему выражение написано так, чтобы оно совпадало с двумя именами и двумя запятыми. Также запятые не напрасно выведены за пределы подвыражений.
Первое совпадение для нашего выражения, которое будет найдено при вызове , выглядит так:
Anna,Matt,
Два подвыражения соответствуют именам «» и «». В основе нашего решения лежит возможность ссылаться на текст, совпавший с заданным подвыражением, через обратную ссылку. Обратные ссылки и в тексте замены ссылаются на текст, совпавший с первым и вторым подвыражением. Вот что происходит:
'\1,\2' || chr(10) -- Текст замены
'Anna,\2' || chr(10) -- Подстановка текста, совпавшего
-- с первым подвыражением
'Anna,Matt' || chr(10) -- Подстановка текста, совпавшего
-- со вторым подвыражением
Вероятно, вы уже видите, какие мощные инструменты оказались в вашем распоряжении. Запятые из исходного текста попросту не используются. Мы берем текст, совпавший с двумя подвыражениями (имена «Anna» и «Matt»), и вставляем их в новую строку с одной запятой и одним символом новой строки.
Но и это еще не все! Текст замены легко изменить так, чтобы вместо запятой в нем использовался символ табуляции (ASCII-код 9):
names := REGEXP_REPLACE( names, '(*),(*),', '\1' || chr(9) || '\2' || chr(10) );
Теперь результаты выводятся в два аккуратных столбца:
Anna Matt Joe Nathan Andrew Jeff Aaron
Поиск и замена с использованием регулярных выражений — замечательная штука. Это мощный и элегантный механизм, с помощью которого можно сделать очень многое.
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Примеры
Разберём скобки на примерах.
Без скобок шаблон означает символ и идущий после него символ , который повторяется один или более раз. Например, или .
Скобки группируют символы вместе. Так что означает , , и т.п.
Сделаем что-то более сложное – регулярное выражение, которое соответствует домену сайта.
Например:
Как видно, домен состоит из повторяющихся слов, причём после каждого, кроме последнего, стоит точка.
На языке регулярных выражений :
Поиск работает, но такому шаблону не соответствует домен с дефисом, например, , так как дефис не входит в класс .
Можно исправить это, заменим на везде, кроме как в конце: .
Итоговый шаблон:
2 Практический раздел. Ссылки
Перед тем, как использовать регулярные выражения, стоит посмотреть в документацию по вашему языку программирования и используемой библиотеке, так как диалекты обладают особенностями. Например в Perl и некоторых версиях php можно описывать рекурсивные регулярные выражения, которые не поддерживаются большинством других реализаций; механизмом флагов отличается JavaScript и так далее. Незначительными отличиями могут обладать даже различные версии одной и той же библиотеки.
Отличаются регулярные выражения не только синтаксисом, но и реализацией. Регулярные выражения — это «не просто так». Строка, задающее выражение, преобразуется в автомат, от реализации которого зависит эффективность. Масштаб проблемы хорошо иллюстрирует график зависимости времени выполнения поиска от длины строки и реализации:
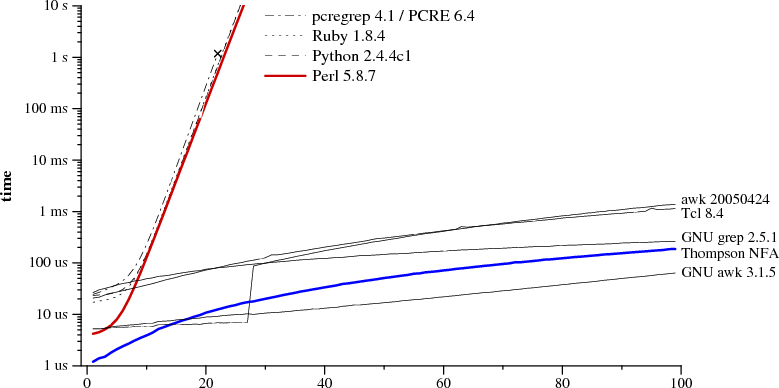
Картинка взята из статьи «Поиск с помощью регулярных выражений может быть простым и быстрым«. В ней можно прочитать про различные реализации выражений, а также о том, как написать выражение так, чтобы оно работало быстрее. Кстати, так как выражение преобразуется в автомат, то зачастую его удобно визуализировать — для этого есть специальные сервисы, например. Для последнего выражения статьи будет построен такой автомат:
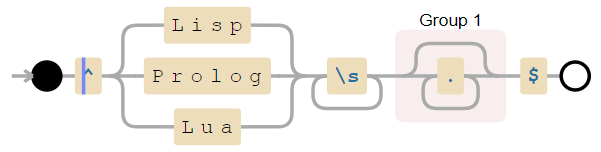
Примеры использования регулярных выражений:
- для валидации вводимых в поля данных: QValidator примеры использования. Ряд библиотек построения графического пользовательского интерфейса позволяют закреплять к полям ввода валидаторы, которые не позволяет ввести в формы некорректные данные. По приведенной выше ссылке можно найти валидацию номера банковской карты и номера телефона с помощью регулярных выражений библиотеки Qt. Аналогичные механизмы есть в других языках, например в Java для этого используется пакет ;
- для парсинга сайтов: Парсер сайта на Qt, использование QRegExp. В примере с сайта-галереи выбираются и скачиваются картинки заданных категорий;
- для валидации данных, передаваемых в формате JSON ряд библиотек позволяет задавать схему. При этом для строковых полей могут быть заданы регулярные выражения. В качестве упражнения можно попробовать составить выражение для пароля — проверить что строка содержит символы в разном регистре и цифры.
В сообществе Программирование и алгоритмы можно посмотреть дополнительную литературу по теме. Книгу Гойвертса и Левитана рекомендую посмотреть особенно, так как в ней по-полочкам разобраны десятки примеров, причем с учетом специфики реализации регулярных выражений в конкретных языках программирования.
str.match(regexp)
Метод ищет совпадения с в строке .
У него есть три режима работы:
-
Если у регулярного выражения нет флага , то он возвращает первое совпадение в виде массива со скобочными группами и свойствами (позиция совпадения), (строка поиска, равна ):
-
Если у регулярного выражения есть флаг , то он возвращает массив всех совпадений, без скобочных групп и других деталей.
-
Если совпадений нет, то, вне зависимости от наличия флага , возвращается .
Это очень важный нюанс. При отсутствии совпадений возвращается не пустой массив, а именно . Если об этом забыть, можно легко допустить ошибку, например:
Если хочется, чтобы результатом всегда был массив, можно написать так:
Экранирование свойств Unicode
Как мы говорили выше, в шаблоне регулярного выражения вы можете использовать чтобы найти совпадение на любую цифру, чтобы найти совпадение на любой символ кроме пробела, чтобы найти совпадение на любой буквенно-числовой символ и т. д.
Экранирование свойств Unicode — это возможность ES2018, которая добавляет очень крутую функцию, расширяя эту концепцию на всех Unicode символы и добавляя и .
У любого Unicode символа есть набор свойств. Например определяет семейство языков, — это логическое значение равное для ASCII символов и т.д. Вы можете положить это свойство в фигурные скобки и регулярное выражение будет проверять чтобы его значение было истинным:
— это ещё одно логическое свойство, которое проверяет содержит ли строка тольк валидные шестнадцатеричные цифры:
Существует много других логических свойств, которые вы можете проверить просто добавив их имя в фигурные скобки, включая , , , , и другие:
В дополнении к этим бинарным свойствам, вы можете проверить любое свойство символа Unicode чтобы соответствовало конкретному значению. В примере ниже я проверяю, записана ли строка в греческом или латинском алфавите:
Прочитать больше обо всех свойствах вы можете здесь.
Захват текста между двойными кавычками
Представим, что у вас есть строка, которая содержит текст заключённый в двойные кавычки и вам нужно извлечь этот текст.
Лучший способ сделать это — использовать захват групп, потому то мы знаем что наше совпадение должно начинаться и заканчиваться символом , поэтому мы можем легко настроить шаблон, но также мы хотим удалить эти кавычки из результата.
Мы найдём то что нам нужно в :
Ещё примеры
Квантификаторы используются очень часто. Они служат основными «строительными блоками» сложных регулярных выражений, поэтому давайте рассмотрим ещё примеры.
Регулярное выражение для десятичных дробей (чисел с плавающей точкой):
В действии:
Регулярное выражение для «открывающего HTML-тега без атрибутов», например, или .
-
Самое простое:
Это регулярное выражение ищет символ , за которым идут одна или более букв латинского алфавита, а затем .
-
Улучшенное:
Здесь регулярное выражение расширено: в соответствие со стандартом, в названии HTML-тега цифра может быть на любой позиции, кроме первой, например .
Регулярное выражение для «открывающего или закрывающего HTML-тега без атрибутов»:
В начало предыдущего шаблона мы добавили необязательный слеш . Этот символ понадобилось заэкранировать, чтобы JavaScript не принял его за конец шаблона.
Чтобы регулярное выражение было точнее, нам часто приходится делать его сложнее
В этих примерах мы видим общее правило: чем точнее регулярное выражение – тем оно длиннее и сложнее.
Например, для HTML-тегов без атрибутов, скорее всего, подошло бы и более простое регулярное выражение: . Но стандарт HTML накладывает более жёсткие ограничения на имя тега, так что более точным будет шаблон .
Подойдёт ли нам или нужно использовать ? А, может быть, нужно ещё его усложнить, добавить атрибуты?
В реальной жизни допустимы разные варианты. Ответ на подобные вопросы зависит от того, насколько реально важна точность и насколько потом будет сложно или несложно отфильтровать лишние совпадения.
Первый тест
testtest()it()it()test()expect()Math.max(1, 5, 10)expect()toBe
- toBe() — подходит, если нам надо сравнивать примитивные значения или является ли переданное значение ссылкой на тот же объект, что указан как ожидаемое значение. Сравниваются значения при помощи Object.is(). В отличие от === это дает возможность отличать 0 от -0, проверить равенство NaN c NaN.
- toEqual() — подойдёт, если нам необходимо сравнить структуру более сложных типов. Он сравнит все поля переданного объекта с ожидаемым. Проверит каждый элемент массива. И сделает это рекурсивно по всей вложенности.
- toContain() — проверят содержит массив или итерируемый объект значение. Для сравнения используется оператор ===.
- toContainEqual() — проверяет или содержит массив элемент с ожидаемой структурой.
- toHaveLength() — проверяет или свойство length у объекта соответствует ожидаемому.
- toBeNull() — проверяет на равенство с null.
- toBeUndefined() — проверяет на равенство с undefined.
- toBeDefined() — противоположность toBeUndefined. Проверяет или значение !== undefined.
- toBeTruthy() — проверяет или в булевом контексте значение соответствует true. Тоесть любые значения кроме false, null, undefined, 0, NaN и пустых строк.
- toBeFalsy() — противоположность toBeTruthy(). Проверяет или в булевом контексте значение соответствует false.
- toBeGreaterThan() и toBeGreaterThanOrEqual() — первый метод проверяет или переданное числовое значение больше, чем ожидаемое >, второй проверяет больше или равно ожидаемому >=.
- toBeLessThan() и toBeLessThanOrEqual() — противоположность toBeGreaterThan() и toBeGreaterThanOrEqual()
- toBeCloseTo() — удобно использовать для чисел с плавающей запятой, когда вам не важна точность и вы не хотите, чтобы тест зависел от незначительной разницы в дроби. Вторым аргументом можно передать до какого знака после запятой необходима точность при сравнении.
- toMatch() — проверяет соответствие строки регулярному выражению.
- toThrow() — используется в случаях, когда надо проверить исключение. Можно проверить как сам факт ошибки, так и проверить на выброс исключения определенного класса, либо по сообщению ошибки, либо по соответствию сообщения регулярному выражению.
- not — это свойство позволяет сделать проверки на НЕравенство. Оно предоставляет объект, который имеет все методы перечисленные выше, но работать они будут наоборот.
areacircumferencetoBeCloseTotoBeNaN
byRangePricetoContainEqualtoContainEqualtoEqualtoBeGreaterThanOrEqualtoBeLessThanOrEqualnot.toContainEqual
Как исправить?
Есть два основных подхода, как это исправить.
Первый – уменьшить количество возможных комбинаций.
Перепишем регулярное выражение так: – то есть, будем искать любое количество слов с пробелом , после которых идёт (но не обязательно) обычное слово .
Это регулярное выражение эквивалентно предыдущему (ищет то же самое), и на этот раз всё работает:
Почему же проблема исчезла?
Теперь звёздочка стоит после вместо . Стало невозможно разбить одно слово на несколько разных . Исчезли и потери времени на перебор таких комбинаций.
Например, с предыдущим шаблоном слово могло быть представлено как два подряд :
Предыдущий шаблон из-за необязательности допускал варианты , , и т.п.
С переписанным шаблоном , такое невозможно: может быть или , но не . Так что общее количество комбинаций сильно уменьшается.
Выражения особых потребностей
- Электронная почта:
^+\.+$
- URL или доменное имя:
^(([^:/?#]+):)?(//([^/?#]*))?(*)(\?(*))?(#(.*))?
- Дата (MM/DD/YYYY)/(MM-DD-YYYY)/(MM.DD.YYYY)/(MM DD YYYY):
^(0?|1)[- /.](0?||3)[- /.](19|20)?{2}$ - 12 месяцев в году(01~09和1~12):
^(0?|1)$
- 31 день в месяц(01~09和1~31):
^(0||3)$
- Пароль:
^.*(?=.{6,})(?=.*d)(?=.*)(?=.*)(?=.*#$%^&*? ]).*$ - Номера телефонов в США
\b\d{3}?\d{3}?\d{4}\b - Индекс США
^{5}(?:-{4})?$ - Слаг
^+$
- Все специальные символы должны быть экранированы
/\/\\\{\}\(\)\*\+\?\.\^\$\|]/ - xml файл:
^(+-?)++\\.$
- Регулярные выражения для китайских иероглифов:
- Двухбайтовые символы:
- Пустая строка:
\n\s*\r (используется для удаления пустых строк)
- HTML теги:
<(\S*?)*>.*?|<.*? />
- Ведущий и конечный символ пробела:
^\s*|\s*$ или (^\s*)|(\s*$)
- IP-адрес:
((?:(?:25|2\d|((1\d{2})|(?\d)))\.){3}(?:25|2\d|((1\d{2})|(?\d))))
Итого
Опережающая и ретроспективная проверки удобны, когда мы хотим искать шаблон по дополнительному условию на контекст, в котором он находится.
Для простых регулярных выражений мы можем сделать похожую вещь «вручную». То есть, найти все совпадения, независимо от контекста, а затем в цикле отфильтровать подходящие.
Как мы помним, (без флага ) и (всегда) возвращают совпадения со свойством , которое содержит позицию совпадения в строке, так что мы можем посмотреть на контекст.
Но обычно регулярные выражения удобнее.
Виды проверок:
| Шаблон | Тип | Совпадение |
|---|---|---|
| Позитивная опережающая | , если за ним следует | |
| Негативная опережающая | , если за ним НЕ следует | |
| Позитивная ретроспективная | , если следует за | |
| Негативная ретроспективная | , если НЕ следует за |