Поиск больших файлов и директорий в linux
Содержание:
- Получение различий между несколькими файлами
- Non-Default Behavior
- Алгоритм
- Запуск ‘diff’
- 3.6 Создание набора команд редактирования
- Использование diff для создания простого патча
- Output Format
- Контекстный патч
- Способ 7. Сравнение файлов с помощью командной строки Windows
- Using diff To Create An Editing Script
Получение различий между несколькими файлами
Наиболее простой способ получить различия между несколькими файлами — это положить их в одну директорию и выполнить команду diff для этой директории целиком. Вы можете просто передать команде diff в качестве параметров имена директорий вместо имен файлов:
$ diff originaldirectory/ updateddirectory/
Обратите внимание: Если в директория есть поддиректории, то надо использовать опцию «-r».
В результате должно получится что-то вроде этого:
diff originaldirectory/file1 updateddirectory/file1 1c1 < This is the first original file. --- > This is the first updated file. diff originaldirectory/file2 updateddirectory/file2 1c1 < This is the second original file. --- > This is the second updated file. 14d13 < We're going to add something in this file and to delete this line. 26a26 > This is line has been added to this updated file.
Обратите внимание: Я создал несколько несколько файлов для примера. Вы можете скачать архив, содержащий эти файлы:http://www.linuxtutorialblog.com/resource/uploads/diffpatchexamplefiles.tar.gz.. Как вы видите, нормальный формат содержит только имена файлов и изменяемые строки.
Как вы видите, нормальный формат содержит только имена файлов и изменяемые строки.
Теперь используем контекстный формат:
diff -c originaldirectory/file1 updateddirectory/file1 *** originaldirectory/file1 2007-02-04 16:17:57.000000000 +0100 --- updateddirectory/file1 2007-02-04 16:18:33.000000000 +0100 *************** *** 1 **** ! This is the first original file. --- 1 ---- ! This is the first updated file. diff -c originaldirectory/file2 updateddirectory/file2 *** originaldirectory/file2 2007-02-04 16:19:37.000000000 +0100 --- updateddirectory/file2 2007-02-04 16:20:08.000000000 +0100 *************** *** 1,4 **** ! This is the second original file. S O --- 1,4 ---- ! This is the second updated file. S O *************** *** 11,17 **** C E - We're going to add something in this file and to delete this line. S O --- 11,16 ---- *************** *** 24,28 **** --- 23,28 ---- C E + This is line has been added to this updated file. Something will be added above this line.
Первая вещь, которую вы должны были заметить — это увеличение размера; контекстный формат содержит больше информации, чем нормальный. Этого не было заметно в первом премере, так как не было контекста. Однако теперь контекст есть, и за счет него размер патча увеличился. Кроме того, вы наверное заметили, что имя файла повторяется дважды. Это возможно сделано для того, чтобы легче было понять когда начался патч следующего файла или для обеспечения лучшего восстановления.
Другой способ получить разницу между между несколькими файлами — это написать скрипт, который выполняет команду diff несколько раз и добавляет результат выполнения в один файл. Мы не будем рассматривать этот способ, так как положить все файлы в одну директорию горазда проще.
Создать патч было легко, но использование директорий ставит следующую проблему: бедут ли патч изменять только соответствующие файлы в текущей директории, или будет использовать соответствующий путь, указанный в файле? Чтобы узнать это, смотрите следующую главу!
Non-Default Behavior
Now that we’ve developed a fair understanding of default behavior exhibited by the diff command, it’s time to explore its wide variety of options.
4.1. Ignore Case Sensitivity
Let’s say we need to compare the list of invited students with the actual list of students who attended the training session.
First, we need help from the marketing team to give us an alphabetically sorted list of students who were invited to the training:
Now, let’s assume that our logistics management team sent us an alphabetically sorted list of student names who actually attended the training in the attendance.txt file:
Notice that attendance.txt has a mix of uppercase and lowercase characters, while our all_inviations.txt file has everything in uppercase. In such a scenario, we might want to use the –ignore-case option:
So, we can see that Rohan was invited, but he didn’t turn up for the training. On the contrary, Kiran wasn’t invited but did attend the session.
4.2. Spaces and Blank Lines
Well, some of the students were not focusing during the session. As a result, they copied code from their friends and added spaces and blank lines to make theirs look unique.
Now, if we’re going to catch plagiarism, then we need to ensure that diff is able to treat the copied solutions as identical.
First, let’s see the script submitted by student-9, who copied the code from script_v1.sh. Further, the script has been altered by adding a blank line and 8 spaces after the echo command to make the script look different from script_v1.sh:
Well, the normal behavior of diff will find the two files to be non-identical:
So, we need to use the –ignore-blank-lines (-B) and –ignore-space-change (-b) options to catch such plagiarism:
We can also note that the use of the –report-identical-files (-s) option made it explicitly clear that both files have the same content.
Moreover, if we want a stricter approach in some cases, then we may even use the –ignore-all-space (-w) option to ignore all spaces.
4.3. Regex
One more plagiarism strategy used by a group of students is the use of comments in their plagiarized copy of the script.
Let’s preview the code in script_v8.sh, which has been copied from script_v1.sh:
Again, we might not be able to catch this plagiarism using the default behavior of the diff command:
Now, to ignore comments beginning with #, we can use the –ignore-matching-lines option with a regex value of ^#:
Алгоритм
Работа diff основана на нахождении наибольшей общей подпоследовательности (англ. longest common subsequence, проблема LCS).
Например, имеются две последовательности элементов:
a b c d f g h j q z
a b c d e f g i j k r x y z
и надо найти наиболее длинную последовательность элементов, которая представлена в обеих последовательностях в одинаковом порядке. Это означает, что необходимо найти новую последовательность, которая может быть получена из первой последовательности удалением некоторых элементов или из второй последовательности удалением других элементов. В данном случае такой последовательностью будет являться
a b c d f g j z
После получения наибольшей общей последовательности остаётся только небольшой шаг до получения похожего на diff вывода:
e h i k q r x y
+ - + + - + + +
Запуск ‘diff’
Формат запуска команды ‘diff’ следующий:
Если FROM-FILE — каталог, а TO-FILE — нет, ‘diff’ сравнивает файл
из FROM-FILE, чье имя совпадает с TO-FILE; и наоборот. В этой
ситуации, файл, не являющийся каталогом, не должен быть ‘-‘.
Если и FROM-FILE, и TO-FILE — каталоги, ‘diff’ сравнивает
соответствующие файлы в этих каталогах, в алфавитном порядке; это
сравнение не является рекурсивным, если не указана опция ‘-r’ или
‘—recursive’. ‘diff’ никогда не сравнивает содержимое каталогов, как
файлов. Файл, заданный полностью, не может быть введен стандартным
вводом, потому что стандартный ввод безымянен и понятие «файл с тем же
именем» неприменимо.
Опции ‘diff’ начинаются с ‘-‘, так что обычно имена FROM-FILE и
TO-FILE не могут начинаться с ‘-‘. Однако, ‘—‘ как аргумент сам по
себе заставляет воспринимать оставшиеся аргументы как имена файлов,
даже если они начинаются с ‘-‘.
Код завершения 0 означает, что различий не найдено, 1 — найдены
некоторые различия, 2 — обнаружена ошибка.
3.6 Создание набора команд редактирования
Несколько режимов вывода создают управляющие файлы для
редактирования FROM-FILE с целью получения TO-FILE.
Командные файлы для ‘ed’
‘diff’ позволяет составлять командный файл, показывающий
текстовому редактору ‘ed’ как изменить первый файл во второй. Раньше
это был единственный формат вывода, позволяющий делать из одного файла
другой автоматически; сегодня, благодаря утилите ‘patch’, он
практичеки устарел. Чтобы задать этот формат используйте опцию ‘-e’
или ‘—ed’.
Как и в нормальном формате (см. «Нормальный формат».), этот
формат вывода не показывает контекста; но в отличие от нормального
формата, он не включает информацию, необходимую для обращения
«изменений» (воссоздания первого файла, при наличии второго и
«изменений»).
Если файл ‘d’ содержит результаты работы команды ‘diff -e old
new’, то команда ‘(cat d && echo w) | ed -old’ редактирует файл ‘old’
для создания копии ‘new’. Более общий пример: если ‘d1’, ‘d2’, …,
‘dN’ содержат результаты работы комманд ‘diff -e old new1’, ‘diff -e
new1 new2’, …, ‘diff -e newN-1 newN’ соответственно, то команда
‘(cat d1 d2 … dN && echo w) | ed -old’ редактирует файл для создания
копии ‘newN’.
Подробное описание ‘ed’-формата
‘Ed’-формат вывода состоит из одного или более ханков различий.
Изменения ближайшие к концу файлов идут первыми, так чтобы команды
меняющие номера строк не влияли на интерпретацию ‘ed’ номеров строк в
последующих командах. Ханки в ‘ed’-формате выглядят так:
Существует три типа команд, изменяющих текст. Каждая состоит из
номера строки или раздленного запятыми списка строк первого файла и
символа, показывающего какой вид изменения нужно сделать. Все номера
строк оригинальны для каждого файла. Типы команд следующие:
- ‘La’
-
Добавить текст из второго файла после строки L первого файла.
Например, ‘8a’ значит добавить следующие строки после строки 8
первого файла. - ‘Rc’
-
Заменить строки из промежутка R в первом файле следующими строками.
Команда подобна комбинации удаления и вставки, но более компактна.
Например, ‘5,7c’ значит заменить строки 5-7 первого файла на текст
из второго файла. - ‘Rd’
-
Удалить строки из промежутка R в первом файле. Например, ‘5,7d’
значит удалить строки 5-7 из первого файла.
Пример командного файла для ‘ed’
Далее представлен результат работы команды ‘diff -e lao tzu’ (см.
«Два образца входных файлов», для полного текста этих файлов):
Прямые командные файлы для ‘ed’
‘diff’ позволяет выводить результаты работы в формате командного
файла для ‘ed’, но с прямым (от первого к последнему) порядком ханков.
Формат команд также немного изменен: командные символы предшествуют
списку изменяемых строк, строки в списке разделяются пробелами, и не
делается попыток прояснить строки ханков, состосящие из одного
периода. Подобно ‘ed’-формату, прямой ‘ed’-формат не может отображать
неполные строки.
Прямой ‘ed’-формат не очень полезен, так как ни ‘ed’, ни ‘patch’
не могут применять «изменения» этого формата. Он существует главным
образом для совместимости с более старыми версиями ‘diff’. Чтобы
задать его используйте опцию ‘-f’ или ‘—forward-ed’.
Командный файл для RCS
Формат вывода RCS разработан специально для использования
Системой управления изменениями (Revision Control System — RCS),
представляющей из себя набор свободно распространяемых программ,
используемых для организации хранения разных версий и систем файлов.
Используйте опцию ‘-n’ или ‘—rcs’ для задания этого формата вывода.
Он похож на прямой ‘ed’-формат (см. «Прямые командные файлы для ed».),
но позволяет отображать произвольные изменения в контексте файлов,
потому что избегает проблем прямого ‘ed’-формата со строками,
состоящими из одной точки и неполными строками. Вместо того, чтобы
кончать разделы текста строками, состоящими из одного периода, каждая
команда указывает на номер строки с которой имеет дело; вместо команды
‘c’ используется комбинация из команд ‘a’ и ‘d’. Кроме того, если
второй файл кончается измененной неполной строкой, то выходной файл
также заканчивается неполной строкой.
Далее представлен результат работы команды ‘diff -n lao tzu’ (см.
«Два образца входных файлов» , для полного текста этих файлов):
Использование diff для создания простого патча
Наиболее простой пример использования команды diff — получение различий между двумя файлами, оригинальным и обновленным. Можете, например, написать насколько слов обычного текста, сделать какие-нибудь изменения, и сохранить измененния во второй файл. Теперь вы можете сравнить эти эти два файла, используя команду diff:
$ diff originalfile updatedfile
Конечно, надо заменить originalfile и updatedfile соответствующими именами файлов. В результате должно получиться что-то вроде этого:
1c1 < These are a few words. \ No newline at end of file --- > These still are just a few words. \ No newline at end of file
Обратите внимание: Чтобы продемонстрировать создание простого патча, я использовал оригинальный файл, содержащий строку «These are a few words.», и измененный файл, содержащий строку «These still are just a few words.»
Вы можете создать эти файлы сами, если хотите запустить команду из статьи и получить тот же результат.
1c1 показывает номер строки и то, что с ней надо сделать
Обратите внимание, что может быть сразу несколько строк(например, 12,15, что означает со строки 12 до строки 15). Символ «c» означает, что патч заменит эту строку
Есть еще два других символа: «a» и «d». Они означают «добавить»(add) и «удалить»(delete) соответственно. Таким образом, синтаксис следующий: (номер строки или диапазон строк)(c,a или d)(номер строки или диапазон строк), хотя когда используются «a» или «d», одна из частей (номер строки или диапазон строк) может содержать только номер одной строки.
- Когда используется «c», номера строк слева — это строки в оригинальном файле, которые надо заменить строками, находящимися в патче, а номера строк справа — это строки, которые должны быть в пропатченном файле.
- Когда используется «a», номер слева может быть только номером одной строки, который показывает, где надо добавить строку в пропатченном файле, а номера строк справа — это строки, которые должны быть в пропатченном файле.
- Когда используется «d», номера строк слева — это строки, которые надо удалить, чтобы получить пропатченную версию файла, а номер строки справа может быть только номером одной строки, который показывает где будут строки в пропатченном файле, если они не будут удалены. Вы можете подумать, что последний номер не нужен, но не забывайте, что патч можно применить для восстаноления исходного файла. Это будет объяснено позже.
Знак «<» означает, что патч должен удалить символы после этого знака, а знак «>» означает, что символы после этого знака надо добавить. Когда надо заменить строки («c» между номерами строк), вы увидите оба знака: и «<«, и «>». Когда надо добавить строку («a» между номерами строк), вы увидите только знак «>», а когда надо удалить строку («d» между номерами строк), вы увидите только знак «<«.
Строка «\ No newline at end of file» появилась из-за того, что я не не нажал enter после того как набрал слова. Считается хорошим тоном заканчивать текстовый файл пустой строкой. Некоторым программам она необходима для работы. Поэтому эта строка появилась после работы команды diff. Добавим пустые строки в конец файлов, и получим более короткий вывод команды diff:
1c1 < These are a few words. --- > These still are just a few words.
Как вы возможно заметили, я не объяснил что означают 3 знака «-«. Они означают конец строк, которые надо заменить и начало строк на которые надо заменить. Разделение старых и новых строк. Вы увидите это знак только при замене («c» между номерами строк).
Если мы хотим создать патч, мы должны поместить вывод команды diff в файл. Конечно это можно сделать, скопировав его из консоли и вставив в вашем любимом текстовом редакторе, а затем сохранив этот файл, но есть способ проще. Мы можем с помощью bash направить вывод команды diff в текстовый файл:
$ diff originalfile updatedfile > patchfile.patch
Опять же не забудьте заменить originalfile и updatedfile на соответствующие имена файлов. Вы наверное знаете, что опция bash «>» работает со всеми командами. Это очень полезное свойство.
Output Format
By now, we’ve already used a few output formats such as –side-by-side, –normal (default), and –unified. Let’s learn how we can further control the output format.
7.1. Line Type and Group Type
While comparing two files, diff breaks the entire text segments from two files into sequences of identical lines and non-identical lines called . Eventually, diff gives us information about these hunks as a measure of dissimilarity between the two files.
Generally speaking, even single lines fall into this category with a group of size one, where starting and ending line numbers are equal.
As such, the diff command is capable of finding out changes within the two groups. And as a result, it can categorize groups into four types: old, new, unchanged, and changed.
Further, diff iterates within these groups to make a line-wise comparison. So, when it comes to individual lines, it can internally categorize them into three types: old, new, and unchanged.
In short, line types and group types are known as LTYPE and GTYPE.
7.2. Line Format and Group Format
Output generated by diff is a collection of information of each line within different group types. Further, it gives three options – namely, –line-format, –LTYPE-line-format, and –GTYPE-group-format – for fine control of the output format.
Now, if we replace LTYPE and GTYPE by their possible values, then we’ll get a bunch of options such as –old-line-format, –new-line-format, –unchanged-line-format, –old-group-format, –new-group-format, –unchanged-group-format, and –changed-group-format.
Naturally, lines and groups have different characteristics. So, diff has two categories for formatting, namely Line Format (LFMT) and . Let’s take a look at different GFMT symbols for identifying the boundaries of line groups belonging to the first and second file:
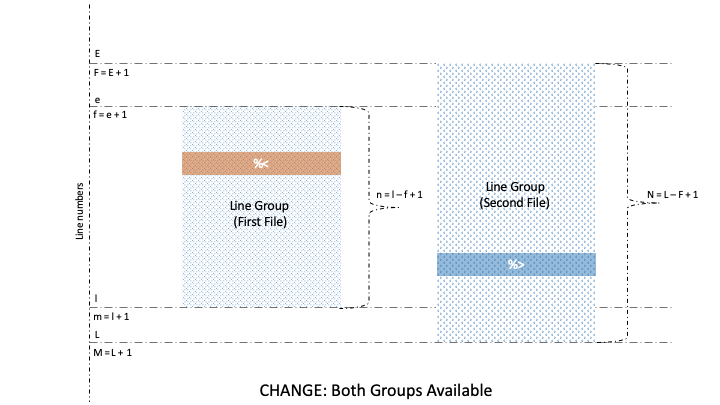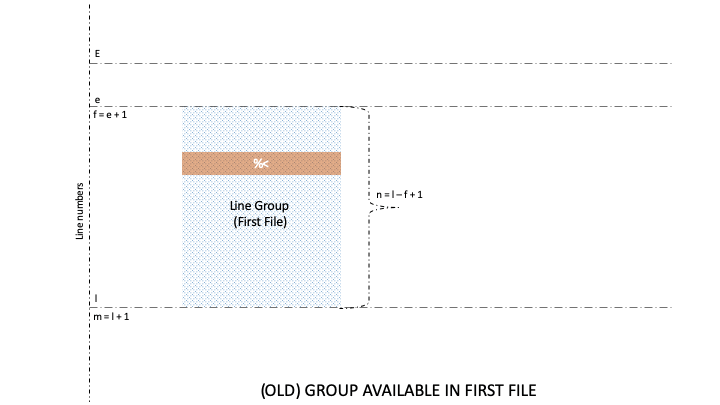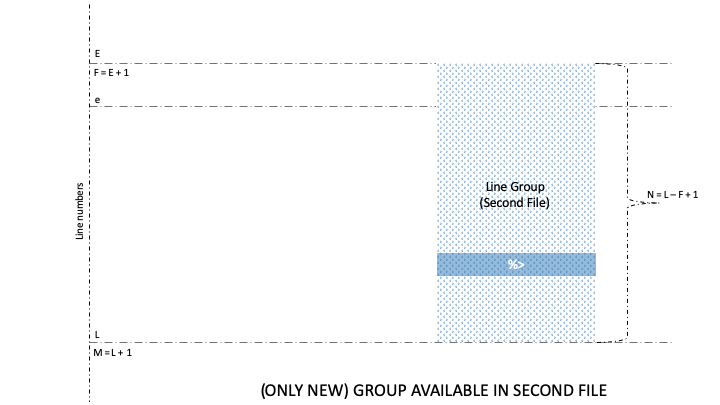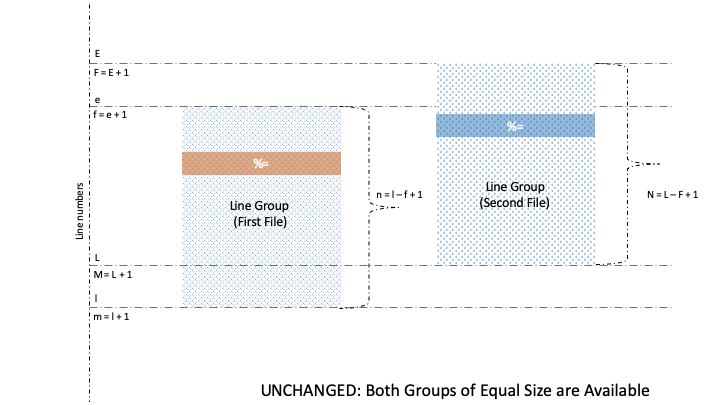
After visualizing the meaning of line number and line content symbols in GFMT, it is also important to understand the process of formatting for the line content clearly. So, let’s see the connection between GFMT and LFMT formatting for lines:

Well, there are three GFMT symbols, namely %<, %=, and %>, that identify the values of non-identical or identical lines from the two files. Further, each of these symbols is formatted by LTYPE formatting rules, after which the output is rendered on stdout.
7.3. Customization
Now, let’s apply the LFMT and GFMT rules of diff to simulate a custom, side-by-side output format.
First, let’s take a look at the trainers’ data from 2019 and 2020:
Now, let’s use –LTYPE-line-format and –GTYPE-group-format options to generate our own version of the side-by-side output format:
Though our command contains a lot of familiar symbols from LFMT and GFMT, if we look closely, we might be able to see a few patterns:
- Tab characters are used to simulate a column-view
- The %d prefix gives the intended numeric meaning to line number symbols such f, l, F, and L
- Line formatting symbols %L and %l print the content of a line with or without a trailing newline
- %(<condition>? <value1>:<value2>) demonstrates the functionality of a ternary operator
- Symbols ️, +, and – spell out to Noop, Add, and Delete instructions, respectively
- indicates that a corresponding group is absent in one of the files
Finally, let’s see a nice-and-neat, side-by-side diff generated by our last command:
We created our customized output format from a demo perspective, therefore, it might not be handling all the edge cases. So, for production code, we must either improve its reliability by handling edge cases, or we may use the –side-by-side option.
Контекстный патч
В первой главе мы создали патч, используя нормальный формат команды diff. Однако этот формат не обеспечивает контекстной зависимости, а использует строки целиком. Создадим патч для того же файла, но используя контектсный формат:
$ diff -c originalfile updatedfile
Результат получится следующий:
*** originalfile 2007-02-03 22:15:48.000000000 0100 --- updatedfile 2007-02-03 22:15:56.000000000 0100 *************** *** 1 **** ! These are a few words. --- 1 ---- ! These still are just a few words.
Как вы видите, здесь включено имя файла. Это значит, что нам не придется набирать его во время применения патча. Далее идет дата и время последнего изменения файла. строка с 15 “*” показывает начало изменений. Они показывают, что надо сделать со следующим блоком текста. Два номера 1 — это номера строк (здесь тоже может быть сразу несколько строк), а “!” означает, что строки надо заменить. Строка с “!” перед тремя “-” должна быть заменена второй строкой с “!”, которая идет после трех “-”(конечно сам ! не будет включен; это синтаксис контекстного формата). Как вы можете видеть, здесь нет знаков “c”, “a” и “d”.Действие, которое нужно сделать, определяется символом в начале строки. “!” означает замену. Другие символы — “+”, “-” и ” ” (пробел). “+” означает добавление, “-” означает удаление, а ” ” означает ничего не делать: патч использует его чтобы убедиться, что он изменяет правильную часть файла.
Применять этот патч легче: при тех же условиях, что и для предыдущего патча (записываем вывод команды diff в файл, затем копируем патч и оригинал в одно и то же место), надо выполнить следующую команду:
$ patch -i patchfile.patch -o updatedfile
Вы возможно сейчас думаете: зачем нам надо указывать имя нового файла? Это надо сделать из-за того, что патч старается изменить существующий файл, а не создает новый. Это удобно при создании патча для нескольких файлов сразу. Это приводит нас к следующей цели: создание патча для дерева файлов. Рассмотрим это в следующей главе.
Способ 7. Сравнение файлов с помощью командной строки Windows
Сравнение с помощью командной строки Windows (cmd.exe) не позволяет редактировать файлы, но просто сравнить содержимое файлов, используя этот способ, вы можете.
Для вызова командной строки Windows перейдите «Пуск» — «Все программы» — «Стандартные» — «Командная строка» или нажмите клавиш «Windows+R», введите cmd и нажмите клавишу Enter.
В командной строке введите команду:
Иногда возникает необходимость сравнить несколько файлов между собой. Это может понадобиться при анализе разницы между несколькими версиями конфигурационного файла или просто для сравнения различных файлов. В Linux для этого есть несколько утилит, как для работы через терминал, так и в графическом интерфейсе.
В этой статье мы рассмотрим как выполняется сравнение файлов Linux. Разберем самые полезные способы, как для терминала, так и в графическом режиме. Сначала рассмотрим как выполнять сравнение файла linux с помощью утилиты diff.
Утилита diff linux — это программа, которая работает в консольном режиме. Ее синтаксис очень прост. Вызовите утилиту, передайте нужные файлы, а также задайте опции, если это необходимо:
$ diff
опции
файл1
файл2
Можно передать больше двух файлов, если это нужно. Перед тем как перейти к примерам, давайте рассмотрим опции утилиты:
-
-q
— выводить только отличия файлов; -
-s
— выводить только совпадающие части; -
-с
— выводить нужное количество строк после совпадений; -
-u
— выводить только нужное количество строк после отличий; -
-y
— выводить в две колонки; -
-e
— вывод в формате ed скрипта; -
-n
— вывод в формате RCS; -
-a
— сравнивать файлы как текстовые, даже если они не текстовые; -
-t
— заменить табуляции на пробелы в выводе; -
-l
— разделить на страницы и добавить поддержку листания; -
-r
— рекурсивное сравнение папок; -
-i
— игнорировать регистр; -
-E
— игнорировать изменения в табуляциях; -
-Z
— не учитывать пробелы в конце строки; -
-b
— не учитывать пробелы; -
-B
— не учитывать пустые строки.
Это были основные опции утилиты, теперь давайте рассмотрим как сравнить файлы Linux. В выводе утилиты кроме, непосредственно, отображения изменений, выводит строку в которой указывается в какой строчке и что было сделано. Для этого используются такие символы:
-
a
— добавлена; -
d
— удалена; -
c
— изменена.
К тому же, линии, которые отличаются, будут обозначаться символом .
Вот содержимое наших тестовых файлов:
Теперь давайте выполним сравнение файлов diff:
diff file1 file2

В результате мы получим строчку: 2,3c2,4. Она означает, что строки 2 и 3 были изменены. Вы можете использовать опции для игнорирования регистра:
diff -i file1 file2
Можно сделать вывод в две колонки:
diff -y file1 file2

А с помощью опции -u вы можете создать патч, который потом может быть наложен на такой же файл другим пользователем:
diff -u file1 file2

Чтобы обработать несколько файлов в папке удобно использовать опцию -r:
diff -r ~/tmp1 ~/tmp2

Для удобства, вы можете перенаправить вывод утилиты сразу в файл:
diff -u file1 file2 > file.patch

Как видите, все очень просто. Но не очень удобно. Более приятно использовать графические инструменты.
Using diff To Create An Editing Script
The -e option tells diff to output a script, which can be used by the editing programs ed or ex, that contains a sequence of commands. The commands are a combination of c (change), a (add), and d (delete) which, when executed by the editor, will modify the contents of file1 (the first file specified on the diff command line) so that it matches the contents of file2 (the second file specified).
Let’s say we have two files with the following contents:
file1.txt:
Once upon a time, there was a girl named Persephone. She had black hair. She loved her mother more than anything. She liked to sit outside in the sunshine with her cat, Daisy. She dreamed of being a painter when she grew up.
file2.txt
Once upon a time, there was a girl named Persephone. She had red hair. She loved chocolate chip cookies more than anything. She liked to sit outside in the sunshine with her cat, Daisy. She would look up into the clouds and dream of being a world-famous baker.
We can run the following command to analyze the two files with diff and produce a script to create a file identical to file2.txt from the contents of file1.txt:
diff -e file1.txt file2.txt
…and the output will look like this:
5c She would look up into the clouds and dream of being a world-famous baker. . 2,3c She had red hair. She loved chocolate chip cookies more than anything. .
Notice that the changes are listed in reverse order: the changes closer to the end of the file are listed first, and changes closer to the beginning of the file are listed last. This order is to preserve line numbering; if we made the changes at the beginning of the file first, that might change the line numbers later in the file. So the script starts at the end, and works backwards.
Here, the script is telling the editing program: «change line 5 to (the following line), and change lines 2 through 3 to (the following two lines).»
Next, we should save the script to a file. We can redirect the diff output to a file using the > operator, like this:
diff -e file1.txt file2.txt > my-ed-script.txt
This command will not display anything on the screen (unless there is an error); instead, the output is redirected to the file my-ed-script.txt. If my-ed-script.txt doesn’t exist, it will be created; if it exists already, it will be overwritten.
If we now check the contents of my-ed-script.txt with the cat command…
cat my-ed-script.txt
…we will see the same script we saw displayed above.
There’s still one thing missing, though: we need the script to tell ed to actually write the file. All that’s missing from the script is the w command, which will write the changes. We can add this to our script by echoing the letter «w» and using the >> operator to add it to our file. (The >> operator is similar to the > operator. It redirects output to a file, but instead of overwriting the destination file, it appends to the end of the file.) The command looks like this:
echo "w" >> my-ed-script.txt
Now, we can check to see that our script has changed by running the cat command again:
cat my-ed-script.txt
5c She would look up into the clouds and dream of being a world-famous baker. . 2,3c She had red hair. She loved chocolate chip cookies more than anything. . w
Now our script, when issued to ed, will make the changes and write the changes to disk.
So how do we get ed to do this?
We can issue this script to ed with the following command, telling it to overwrite our original file. The dash («—«) tells ed to read from the standard input, and the < operator directs our script to that input. In essence, the system enters whatever is in our script as input to the editing program. The command looks like this:
ed - file1.txt < my-ed-script.txt
This command displays nothing, but if we look at the contents of our original file…
cat file1.txt
Once upon a time, there was a girl named Persephone. She had red hair. She loved chocolate chip cookies more than anything. She liked to sit outside in the sunshine with her cat, Daisy. She would look up into the clouds and dream of being a world-famous baker.
…we can see that file1.txt now matches file2.txt exactly.
Warning! In this example, ed overwrote the contents of our original file, file1.txt. After running the script, the original text of file1.txt disappears, so make sure you understand what you’re doing before running these commands!