Поиск и замена в pl/sql с использованием регулярных выражений
Содержание:
- Функция CONCAT
- 返回类型Return Types
- Using the Collate function with REPLACE
- 返回类型Return Types
- SQL References
- How to replace multiple patterns in a given string
- SQL Учебник
- SQL Справочник
- 参数Arguments
- 傳回型別Return Types
- Соединения (джойны)
- 5. Агрегирование
- 6. Подзапросы
- Функция SUBSTRING
- SQL Учебник
- Пример совпадения нескольких символов
- Пример совпадение на нескольких альтернативах
- Поиск подстроки в строке средствами sql
Функция CONCAT
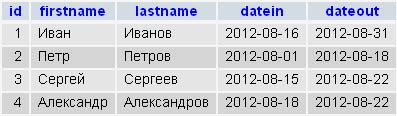
Начнем с функции CONCAT – она используется для объединения значений двух столбцов в один. Допустим у Вас в таблице, «Имя» и «Фамилия» находятся в разных колонках (что логично), а Вам, для какого-нибудь отчета, нужно чтобы они выводились в одной колонке. Вы можете легко использовать данную функцию.
SELECT CONCAT (name, surname) AS FIO FROM table
С помощью данного запроса Вы объедините две колонки в одну, т.е. у Вас получится не вот так
| Иван | Иванов |
| Петр | Петров |
А вот так
| Иван Иванов |
| Петр Петров |
Аналогично этому запросу можно использовать следующую конструкцию (применимо в PostgreSQL).
SELECT name || surname AS FIO FROM table
Или чтобы отделить пробелом введите
SELECT name || ' ' || surname AS FIO FROM table
т.е. две вертикальные черты объединяют два столбца в один, а чтобы отделить их пробелом я поставил между ними пробел (можно использовать любой символ, например тире или двоеточие) в апострофах и объединил также двумя вертикальными чертами (в Transact-SQL вместо двух вертикальных черточек используется знак +).
返回类型Return Types
如果其中的一个输入参数数据类型为 nvarchar,则返回 nvarchar;否则 REPLACE 返回 varchar 。Returns nvarchar if one of the input arguments is of the nvarchar data type; otherwise, REPLACE returns varchar.
如果任何一个参数为 NULL,则返回 NULL。Returns NULL if any one of the arguments is NULL.
如果 string_expression 的类型不是 varchar(max) 或 nvarchar(max),则 REPLACE 将返回值截断为 8000 个字节 。If string_expression is not of type varchar(max) or nvarchar(max), REPLACE truncates the return value at 8,000 bytes. 若要返回大于 8,000 字节的值,则必须将 string_expression 显式转换为大值数据类型 。To return values greater than 8,000 bytes, string_expression must be explicitly cast to a large-value data type.
Using the Collate function with REPLACE
The following SQL uses the case-sensitive collation function to validate the expression within the SQL REPLACE function
| 1 | SELECTREPLACE(‘SQL Server vNext’COLLATELatin1_General_CS_AS,’vnext’,’2017′)SQL2017; |
The output is a direct input of the expression as it fails to validate the input pattern.
The following SQL uses the same example but case-insensitive collation function is used to validate the expression within the function
| 1 | SELECTREPLACE(‘SQL Server vNext’COLLATELatin1_General_CI_AS,’vnext’,’2017′)SQL2017; |
The output shows the values are matched irrespective of cases
返回类型Return Types
如果其中的一个输入参数数据类型为 nvarchar,则返回 nvarchar;否则 REPLACE 返回 varchar 。Returns nvarchar if one of the input arguments is of the nvarchar data type; otherwise, REPLACE returns varchar.
如果任何一个参数为 NULL,则返回 NULL。Returns NULL if any one of the arguments is NULL.
如果 string_expression 的类型不是 varchar(max) 或 nvarchar(max),则 REPLACE 将返回值截断为 8000 个字节 。If string_expression is not of type varchar(max) or nvarchar(max), REPLACE truncates the return value at 8,000 bytes. 若要返回大于 8,000 字节的值,则必须将 string_expression 显式转换为大值数据类型 。To return values greater than 8,000 bytes, string_expression must be explicitly cast to a large-value data type.
SQL References
SQL Keywords
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Functions
String Functions
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Numeric Functions
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Date Functions
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Advanced Functions
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server Functions
String Functions
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Numeric Functions
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Date Functions
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Advanced Functions
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access Functions
String Functions
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Numeric Functions
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Date Functions
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Other Functions
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL Quick Ref
How to replace multiple patterns in a given string
The following example uses the SQL replace function to replace multiple patterns of the expression 3*/{6-8}.
| 1 | SELECTREPLACE(REPLACE(REPLACE(REPLACE(‘3*/{6-8}’,»,’)’),'{‘,'(‘),’}’,’)’); |
We can see that the REPLACE function is nested and it is called multiple times to replace the corresponding string as per the defined positional values within the SQL REPLACE function.
In the aforementioned example, we can use the TRANSLATE, a new SQL Server 2017 function. It’s a good replacement string function for the SQL REPLACE function.
You can refer to the article Top SQL String functions in SQL Server 2017 for more information.
The following query replaces the pattern A, C and D with the values 5, 9 and 4 and generates a new column named GRPCODE
|
1 |
DROPTABLEIFEXISTS#temp; CREATETABLE#temp (nameNVARCHAR(50), GRPNVARCHAR(100) ); INSERTINTO#temp VALUES (‘Prashanth’, ‘AB’ ), (‘Kiki’, ‘ABC’ ), (‘Steven’, ‘ABCD’ ); |
The below SQL REPLACE function undergoes an execution of 3 iterations to get the desired result. The first, input pattern ‘A’ is evaluated and if found, 5 are replaced. The second, B is evaluated. If found the numeric value 9 is replaced. Finally, D is replaced by 4.
|
1 |
SELECTName, GRP, REPLACE (REPLACE (REPLACE(GRP,’A’,’5′),’C’,9),’D’,4)GRPCODE FROM#temp; |
Here is an example to update using the SQL REPLACE function. In this case, GRP column with the GRP CODE, run the following SQL.
|
1 |
UPDATE#temp SET GRP=replace(replace(REPLACE(GRP,’A’,’5′),’C’,9),’D’,4); |
Now, let’s take a look at the data
|
1 |
SELECT* FROM#temp; |
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
SQL Справочник
SQL Ключевые слова
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Функции
Функции строк
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Функции дат
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Функции расширений
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server функции
Функции строк
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Функции дат
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Функции расширений
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access функции
Функции строк
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Функции чисел
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Функции дат
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Другие функции
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL ОператорыSQL Типы данныхSQL Краткий справочник
参数Arguments
string_expression string_expression是要搜索的字符串表达式。Is the string expression to be searched. string_expression 可以是字符或二进制数据类型 。string_expression can be of a character or binary data type.
string_patternstring_pattern是要查找的子字符串。Is the substring to be found. string_pattern 可以是字符或二进制数据类型 。string_pattern can be of a character or binary data type. string_pattern 不能为空字符串 (»),不能超过页容纳的最大字节数 。string_pattern cannot be an empty string (»), and must not exceed the maximum number of bytes that fits on a page.
string_replacementstring_replacement是替换字符串。Is the replacement string. string_replacement 可以是字符或二进制数据类型 。string_replacement can be of a character or binary data type.
傳回型別Return Types
如果其中一個輸入引數是 nvarchar 資料類型,便傳回 nvarchar;否則,REPLACE 會傳回 varchar。Returns nvarchar if one of the input arguments is of the nvarchar data type; otherwise, REPLACE returns varchar.
如果任何一個引數是 NULL,便會傳回 NULL。Returns NULL if any one of the arguments is NULL.
如果 string_expression 的類型不是 varchar(max) 或 nvarchar(max),則 REPLACE 會將傳回值截斷為 8,000 位元組。If string_expression is not of type varchar(max) or nvarchar(max), REPLACE truncates the return value at 8,000 bytes. 若要傳回大於 8,000 位元組的值,string_expression 必須明確轉換成大數值資料類型。To return values greater than 8,000 bytes, string_expression must be explicitly cast to a large-value data type.
Соединения (джойны)
Теперь мы хотим увидеть названия (не обязательно уникальные) всех книг Дэна Брауна, которые были взяты из библиотеки, и когда эти книги нужно вернуть:
Результат:
| Title | Return Date |
|---|---|
| The Lost Symbol | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| The Lost Symbol | 2016-04-19 00:00:00 |
По большей части запрос похож на предыдущий за исключением секции . Это означает, что мы запрашиваем данные из другой таблицы. Мы не обращаемся ни к таблице “books”, ни к таблице “borrowings”. Вместо этого мы обращаемся к новой таблице, которая создалась соединением этих двух таблиц.
— это, считай, новая таблица, которая была сформирована комбинированием всех записей из таблиц «books» и «borrowings», в которых значения совпадают. Результатом такого слияния будет:
А потом мы делаем запрос к этой таблице так же, как в примере выше. Это значит, что при соединении таблиц нужно заботиться только о том, как провести это соединение. А потом запрос становится таким же понятным, как в случае с «простым запросом» из пункта 3.
Давайте попробуем чуть более сложное соединение с двумя таблицами.
Теперь мы хотим получить имена и фамилии людей, которые взяли из библиотеки книги автора “Dan Brown”.
На этот раз давайте пойдем снизу вверх:
Шаг Step 1 — откуда берем данные? Чтобы получить нужный нам результат, нужно соединить таблицы “member” и “books” с таблицей “borrowings”. Секция JOIN будет выглядеть так:
Шаг 2 — какие данные показываем? Нас интересуют только те данные, где автор книги — “Dan Brown”
Шаг 3 — как показываем данные? Теперь, когда данные получены, нужно просто вывести имя и фамилию тех, кто взял книги:
Супер! Осталось лишь объединить три составные части и сделать нужный нам запрос:
Что даст нам:
| First Name | Last Name |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Отлично! Но имена повторяются (они не уникальны). Мы скоро это исправим.
5. Агрегирование
Грубо говоря, агрегирования нужны для конвертации нескольких строк в одну. При этом, во время агрегирования для разных колонок используется разная логика.
Давайте продолжим наш пример, в котором появляются повторяющиеся имена. Видно, что Ellen Horton взяла больше одной книги, но это не самый лучший способ показать эту информацию. Можно сделать другой запрос:
Что даст нам нужный результат:
| First Name | Last Name | Number of books borrowed |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Почти все агрегации идут вместе с выражением . Эта штука превращает таблицу, которую можно было бы получить запросом, в группы таблиц. Каждая группа соответствует уникальному значению (или группе значений) колонки, которую мы указали в . В нашем примере мы конвертируем результат из прошлого упражнения в группу строк. Мы также проводим агрегирование с , которая конвертирует несколько строк в целое значение (в нашем случае это количество строк). Потом это значение приписывается каждой группе.
Каждая строка в результате представляет собой результат агрегирования каждой группы.
Можно прийти к логическому выводу, что все поля в результате должны быть или указаны в , или по ним должно производиться агрегирование. Потому что все другие поля могут отличаться друг от друга в разных строках, и если выбирать их ‘ом, то непонятно, какие из возможных значений нужно брать.
В примере выше функция обрабатывала все строки (так как мы считали количество строк). Другие функции вроде или обрабатывают только указанные строки. Например, если мы хотим узнать количество книг, написанных каждым автором, то нужен такой запрос:
Результат:
| author | sum |
|---|---|
| Robin Sharma | 4 |
| Dan Brown | 6 |
| John Green | 3 |
| Amish Tripathi | 2 |
Здесь функция обрабатывает только колонку и считает сумму всех значений в каждой группе.
6. Подзапросы
Подзапросы это обычные SQL-запросы, встроенные в более крупные запросы. Они делятся на три вида по типу возвращаемого результата.
Функция SUBSTRING
SUBSTRING (<выражение>, <начальная позиция>, <длина> )
Эта функция позволяет извлечь из выражения его часть заданной длины, начиная от заданной начальной позиции. Выражение может быть символьной или бинарной строкой, а также иметь тип text или image. Например, если нам потребуется получить 3 символа в названии корабля, начиная со 2-го символа, то сделать без помощи функции SUBSTRING будет не так просто. А так мы пишем:
| SELECT name, SUBSTRING(name, 2, 3) FROM Ships |
В случае, когда нужно извлечь все символы, начиная с некоторого, мы также можем использовать эту функцию. Например,
| SELECT name, SUBSTRING(name, 2, LEN(name)) FROM Ships |
даст нам все символы в названиях кораблей от второй буквы в имени
Обратите внимание на то, что для указания числа извлекаемых символов я использовал функцию LEN(name), которая возвращает число символов в имени. Понятно, что поскольку мне нужны символы, начиная со второго, то их число будет меньше общего количества символов в имени
Однако это не вызывает ошибки, поскольку если указанное число символов превышает возможное число, то будут извлечены все символы до конца строки. Поэтому я и беру их с запасом, не утруждая себя вычислениями.
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
Пример совпадения нескольких символов
Рассмотрим, как мы будем использовать функцию REGEXP_INSTR для соответствия многосимвольной схеме. Например:
Oracle PL/SQL
SELECT REGEXP_INSTR (‘The example shows how to use the REGEXP_INSTR function’, ‘ow’, 1, 1, 0, ‘i’) FROM dual;
—Результат: 15
|
1 2 |
SELECTREGEXP_INSTR(‘The example shows how to use the REGEXP_INSTR function’,’ow’,1,1,0,’i’)FROMdual; |
В этом примере будет возвращено первое вхождение ‘ow’ в строке. Оно будет соответствовать ‘ow’ в слове shows.
Мы могли бы изменить начальную позицию поиска, чтобы выполнить поиск, начиная с середины строки. Например:
Oracle PL/SQL
SELECT REGEXP_INSTR (‘The example shows how to use the REGEXP_INSTR function’, ‘ow’, 16, 1, 0, ‘i’) FROM dual;
—Результат: 20
|
1 2 |
SELECTREGEXP_INSTR(‘The example shows how to use the REGEXP_INSTR function’,’ow’,16,1,0,’i’)FROMdual; |
В этом примере поиск шаблона ‘ow’ в строке начнется с позиции 16. В этом случае поиска шаблона он пропустит первые 15 символов строки.
Рассмотрим, как мы будем использовать функцию REGEXP_INSTR со столбцом таблицы и искать несколько символов. Например:
Oracle PL/SQL
SELECT REGEXP_INSTR (other_number, ‘the’, 1, 1, 0, ‘i’) FROM contacts;
| 1 | SELECTREGEXP_INSTR(other_number,’the’,1,1,0,’i’)FROMcontacts; |
В этом примере мы будем искать шаблон в поле other_number в таблице contacts.
Пример совпадение на нескольких альтернативах
Давайте начнем с рассмотрения того, как использовать шаблон | оde> с функцией REGEXP_SUBSTR в MariaDB. Например:
PgSQL
SELECT REGEXP_SUBSTR (‘Ball Point Pen’,’P(a|e|i)n’));
—Результат: ‘Pen’
SELECT REGEXP_SUBSTR (‘Eggs and pancakes’,’P(a|e|i)n’);
—Результат: ‘pan’
|
1 2 3 4 5 6 7 |
SELECTREGEXP_SUBSTR(‘Ball Point Pen’,’P(a|e|i)n’)); SELECTREGEXP_SUBSTR(‘Eggs and pancakes’,’P(a|e|i)n’); |
Эти примеры REGEXP_SUBSTR будут возвращать значения, такие как Pan, Pen или Pin. Шаблон | оde> говорит нам искать букву ‘a’, ‘e’ или ‘i’; между буквами ‘P’ и ‘n’. Функция REGEXP_SUBSTR выполняет поиск без учета регистра, поэтому не имеет значения, в каком регистре буквы находятся в строке.
Поиск с учетом регистра
Если мы хотим выполнить поиск с учетом регистра, нам нужно изменить нашу функцию REGEXP_SUBSTR для использования двоичной строки. Это можно сделать одним из двух способов.
PgSQL
SELECT REGEXP_SUBSTR (BINARY ‘Eggs and pancakes’, ‘P(a|e|i)n’);
—Результат: NULL
|
1 2 3 |
SELECTREGEXP_SUBSTR(BINARY’Eggs and pancakes’,’P(a|e|i)n’); —Результат: NULL |
Или
PgSQL
SELECT REGEXP_SUBSTR (‘Eggs and pancakes’ COLLATE utf8_bin, ‘P(a|e|i)n’);
—Результат: NULL
|
1 2 3 |
SELECTREGEXP_SUBSTR(‘Eggs and pancakes’COLLATEutf8_bin,’P(a|e|i)n’); —Результат: NULL |
В первом примере мы использовали ключевое слово BINARY, чтобы преобразовать нашу строку в двоичную строку. Во втором примере мы использовали COLLATE для преобразования нашей строки в двоичную строку. Поскольку мы выполняем поиск с учетом регистра, шаблон не совпадает на ‘pancakes’, потому что ему требуется заглавная буква ‘P’, поэтому функция REGEXP_SUBSTR будет возвращать NULL.
Поиск столбцов таблицы
Теперь давайте покажем, как использовать функцию REGEXP_SUBSTR со столбцом таблицы: Допустим, у нас есть таблица contact со следующими данными:
1000
Андерсон
2000
Смит
3000
Джонсон
оdy>
Теперь запустим следующий запрос:
PgSQL
SELECT cоntact_id, last_name, REGEXP_SUBSTR (last_name, ‘a|e|i|o|u’) AS «First Vowel»
FROM cоntacts;
|
1 2 |
SELECTcоntact_id,last_name,REGEXP_SUBSTR(last_name,’a|e|i|o|u’)AS»First Vowel» FROMcоntacts; |
Это результаты, которые будут возвращены запросом:
1000
Андерсон
A
2000
Смит
и
3000
Джонсон
о
оdy>
Поиск подстроки в строке средствами sql
Для вычисления позиции подстроки в строке в языке sql существует несколько функций. Первая, которую мы рассмотрим, функция POSITION:
integer POSITION(substr string IN str string)
Возвращает номер позиции первого вхождения подстроки substr в строке str и возвращает 0 если подстрока не найдена. Функция POSITION может работать с многобайтовыми символами.
Пример:
SELECT POSITION (‘cd’ IN ‘abcdcde’);
Результат: 3
SELECT POSITION (‘xy’ IN ‘abcdcde’);
Результат: 0
Следующая функция LOCATE позволяет начинать поиск подстроки с определенной позиции:
integer LOCATE(substr string, str string, pos integer)
Возвращает позицию первого вхождения подстроки substr в строке str, начиная с позиции pos. Если параметр pos не задан, то поиск осуществляется с начала строки. Если подстрока substr не найдена, то возвращает 0. Поддерживает многобайтовые символы.
Пример:
SELECT LOCATE (‘cd’, ‘abcdcdde’, 5);
Результат: 5
SELECT LOCATE (‘cd’, ‘abcdcdde’);
Результат: 3
Аналогом функций POSITION и LOCATE является функция INSTR:
integer INSTR(str string, substr string)
Также как и функции выше возвращает позицию первого вхождения подстроки substr в строке str. Единственное отличие от функций POSITION и LOCATE то, что аргументы поменяны местами.
Далее рассмотрим функции, которые помогают получить подстроку.
Первыми рассмотрим сразу две функции LEFT и RIGHT, которые похожи по своему действию:
string LEFT(str string, len integer)string RIGHT(str string, len integer)
Функция LEFT возвращает len первых символов из строки str, а функция RIGHT столько же последних. Поддерживают многобайтовые символы.
Пример:
SELECT LEFT (‘Москва’, 3);
Результат: Мос
SELECT RIGHT (‘Москва’, 3);
Результат: ква
Далее рассмотрим одинаковые по итоговому результату функции SUBSTRING и MID:
string SUBSTRING(str string, pos integer, len integer)string MID(str string, pos integer, len integer)
Функции позволяют получить подстроку строки str длиною len символов с позиции pos. В случае если параметр len не задан, то возвращается вся подстрока начиная с позиции pos.
Пример:
SELECT SUBSTRING (‘г. Москва — столица России’, 4, 6);
Результат: Москва
SELECT SUBSTRING (‘г. Москва — столица России’, 4);
Результат: Москва — столица России
Примеры с функцией MID не привожу, потому что результаты будут аналогичные.
Интересная функция SUBSTRING_INDEX:
string SUBSTRING_INDEX(str string, delim string, count integer)
Функция возвращает подстроку строки str, полученную путем удаления символов, идущих после разделителя delim, находящимся в позиции count. Параметр count может быть как положительным, так отрицательным. Если count положительный, то отсчет позиции разделителя будет вестись слева и удаляться будут символы находящиеся справа от разделителя. Если count отрицательный, то отсчет позиции разделителя ведется справа и удаляются символы находящиеся слева от разделителя. Возможно, описание получилось слишком запутанным, но на примерах станет понятней.
Пример:
SELECT SUBSTRING_INDEX (‘www.mysql.ru’, ‘.’, 1);
Результат: www
В данном примере функция находит, первое вхождения символа точки в строке «www.mysql.ru» и удаляет все символы, идущие после нее, включая сам разделитель.
SELECT SUBSTRING_INDEX (‘www.mysql.ru’, ‘.’, 2);
Результат: www.mysql
Здесь функция ищет второе вхождение точки, удаляет все символы справа от нее и возвращает получившуюся подстроку. И еще один пример с отрицательным значением параметра count:
SELECT SUBSTRING_INDEX (‘www.mysql.ru’, ‘.’, -2);
Результат: mysql.ru
В этом примере функция SUBSTRING_INDEX ищет вторую точку, отсчитывая позицию справа, удаляет символы слева от нее и выдает полученную подстроку.