Установка, настройка и эксплуатация ceph
Содержание:
- Install pre-requisite rpms
- Вычисление Placement Groups (PG)
- Использование кластера ceph
- Преимущества облачных объектных хранилищ
- Setup
- Проверка надежности и отказоустойчивости
- Adding Keys to the Cluster
- Enable Passwordless SSH
- Как подключиться к S3 хранилищу
- Deploying OSDs
- Adding Capabilities
- Persistent Volume Claim
- Подключение Cephfs
- Отказоустойчивый кластер
- Подготовка настроек
- Удаление Amazonaws
- Заключение
- Онлайн курс «Сетевой инженер»
Install pre-requisite rpms
To get the required rpms to build ceph storage cluster we need to install repo and enable repoInstall the latest available repo on your admin node
# yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
Add the Ceph repository to your yum configuration file at /etc/yum.repos.d/ceph.repo with the following command. Replace {ceph-stable-release} with a stable Ceph release (e.g., mimic.)
# cat /etc/yum.repos.d/ceph.repo name=Ceph noarch packages baseurl=https://download.ceph.com/rpm-mimic/el7/noarch/ enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://download.ceph.com/keys/release.asc
Next install ceph-deploy:
# yum -y install ceph-deploy
Вычисление Placement Groups (PG)
Самая большая трудность в вычислении PG это необходимость соблюсти баланс между количеством групп на OSD и их размером. Чем больше PG на одной OSD, тем больше вам надо памяти для хранения информации об их расположении. А чем больше размер самой PG, тем больше данных будет перемещаться при балансировке.
Получается, что если у вас мало PG, они у вас большого размера, надо меньше памяти, но больше трафика уходит на репликацию. А если больше, то все наоборот. Теоретически считается, что для хранения 1 Тб данных в кластере надо 1 Гб оперативной памяти.
Как я уже кратко сказал выше, примерная формула расчета PG такая — Total PGs = (Number OSD * 100) / max_replication_count. Конкретно в моей установке по этой формуле получается цифра 100, которая округляется до 128. Но если задать такое количество pg, то роль ansible отработает с ошибкой:
Error ERANGE: pg_num 128 size 3 would mean 768 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)
Суть ошибки в том, что максимальное количество pg становится больше, чем возможно, исходя из параметра mon_max_pg_per_osd 250. То есть не более 250 на один OSD. Я не стал менять этот дефолтный параметр, а просто установил количество pg_num 64. Более подробная формула есть на официальном сайте — https://ceph.com/pgcalc/.
Существует проблема выделения pg и состоит она в том, что у нас в кластере обычно несколько пулов. Как распределить pg между ними? В общем случае поровну, но это не всегда эффективно, потому что в каждом пуле может храниться разное количество и типов данных. Поэтому для распределения pg по пулам стараются учитывать их размеры. Для этого тоже есть примерная формула — pg_num_pool = Total PGs * % of SizeofPool/TotalSize.
Количество PG можно изменять динамически. К примеру, если вы добавили новые OSD, то вы можете увеличить и количество PG в кластере. В последней версии ceph, которая еще не lts, появилась возможность уменьшения Placement Groups.
Нужно понимать одну важную вещь — изменение количества PG приводит к ребалансингу всего кластера. Нужно быть уверенным, что он к этому готов.
Использование кластера ceph
Для начала давайте посмотрим, какие пулы у нас уже есть в кластере ceph.
# rados lspools
cephfs_data cephfs_metadata
Это дефолтные пулы для работы cephfs, которые были созданы в момент установки кластера. Сейчас подробнее на этом остановимся. Ceph представляет для клиента различные варианты доступа к данным:
- файловая система cephfs;
- блочное устройство rbd;
- объектное хранилище с доступом через s3 совместимое api.
Я рассмотрю два принципиально разных варианта работы с хранилищем — в виде cephfs и rbd. Основное отличие в том, что cephfs позволяет монтировать один и тот же каталог с данными на чтение и запись множеству клиентов. RBD же подразумевает монопольный доступ к выделенному хранилищу. Начнем с cephfs. Для этого у нас уже все готово.
Преимущества облачных объектных хранилищ
Основными преимуществами в пользу использования объектных хранилищ являются:
Масштабируемость — одно из основных преимуществ. Благодаря тому, что адреса к объектам хранятся в виде ссылок, а не по именам, систему можно легко масштабировать. Такая система практически не ограничена по размеру и может содержать любое количество данных.
Эффективность такого способа хранения обусловлена отсутствием иерархии, что в свою очередь обеспечивает и отсутствие узких мест, которые, как правило, возникают при использовании сложных систем многоуровневых каталогов.
Современные объектные хранилища обеспечивают сохранность целостности данных, производя их репликацию и обновления, что в свою очередь приводит к отсутствию простоев систем.
Отказоустойчивость сервиса обеспечивается тем, что, как правило, данную услугу предоставляют центры обработки данных высокого уровня надежности (Tier II и Tier III) с отказоустойчивой инфраструктурой, благодаря чему обеспечивается бесперебойный доступ к данным.
Setup
To get the source tree ready for use, run this once:
./bootstrap
You can symlink the ceph-deploy script in this somewhere
convenient (like ~/bin), or add the current directory to PATH,
or just always type the full path to ceph-deploy.
ceph-deploy at a minimum requires that the machine from which the script is
being run can ssh as root without password into each Ceph node.
To enable this generate a new ssh keypair for the root user with no passphrase
and place the public key (id_rsa.pub or id_dsa.pub) in:
/root/.ssh/authorized_keys
and ensure that the following lines are in the sshd config:
PermitRootLogin yes PermitEmptyPasswords yes
Проверка надежности и отказоустойчивости
Расскажу, какие проверки отказоустойчивости ceph делал я. Напомню, что у меня кластер состоит всего из трех нод, да еще на sata дисках на двух разных гипервизорах. Многого тут не натестируешь 🙂 Диски собраны в raid1, никакой нагрузки помимо ceph на серверах не было. Я просто выключал одну ноду. При этом в работе кластера не было никаких заметных изменений. С ним можно было нормально работать, писать и читать данные. Самое интересное начиналось, когда я запускал обратно выключенную ноду.
В этот момент запускался ребалансинг кластера и он начинал жутко тормозить. Настолько жутко, что в эти моменты я даже не мог зайти на ноды по ssh или напрямую с консоли, чтобы посмотреть, что именно там тормозит. Виртуальные машины вставали колом. Я пытался их отключать и включать по очереди, но ничего не помогало. В итоге я выключил все 3 ноды и стал включать их по одной. Очевидно, что и нагрузки никакой я не давал, так как кластер был не в состоянии обслуживать внешние запросы.
Включил сначала одну ноду, убедился, что она загрузилась и показывает свой статус. Запустил вторую. Дождался, когда полностью синхронизируются две ноды, потом включил третью. Только после этого все вернулось в нормальное состояние. При этом никаких действий с кластером я не производил. Только следил за статусом. Он сам вернулся в рабочее состояние. Данные все оказались на месте. Меня это приятно удивило, с учетом того, что я жестко выключал зависшие виртуалки несколько раз.
Как я понял, если у вас есть возможность снять с кластера нагрузку, то в момент деградации особых проблем у вас не будет. Это актуально для кластеров с холодными данными, например, под бэкапы или другое долгосрочное хранение. Там можно тормознуть задачи и дождаться ребаланса. Особых проблем с эксплуатацией ceph быть не должно. А вот если у вас идет постоянная работа с кластером, то вам нужно все внимательно проектировать, изучать, планировать, тестировать и т.д. Точно должен быть еще один тестовый кластер и доскональное понимание того, что вы делаете.
Adding Keys to the Cluster
Once the keys are generated and capabilities are added, we can add the keys to the cluster:
:~# ceph -k /etc/ceph/ceph.client.admin.keyring auth add client.radosgw.cph1 -i /etc/ceph/ceph.client.radosgw.keyring:~# ceph -k /etc/ceph/ceph.client.admin.keyring auth add client.radosgw.cph2 -i /etc/ceph/ceph.client.radosgw.keyring:~# ceph -k /etc/ceph/ceph.client.admin.keyring auth add client.radosgw.cph3 -i /etc/ceph/ceph.client.radosgw.keyring:~# ceph -k /etc/ceph/ceph.client.admin.keyring auth add client.radosgw.cph4 -i /etc/ceph/ceph.client.radosgw.keyring
Enable Passwordless SSH
Since will not prompt for a password, you must generate SSH keys on the admin node and distribute the public key to each Ceph node. will attempt to generate the SSH keys for initial monitors.
Generate on the admin node
# ssh-keygen -t rsa
Next copy the public key to the target storage nodes
# ssh-copy-id ceph@storage1 # ssh-copy-id ceph@storage2
Modify the file of your admin node so that can log in to Ceph nodes as the user you created without requiring you to specify {username} each time you execute . This has the added benefit of streamlining ssh and scp usage.
# cat ~/.ssh/config Host storage1 Hostname storage1 User ceph Host storage2 Hostname storage2 User ceph
Как подключиться к S3 хранилищу
Стоит отметить, что объектные хранилища не предназначены для обработки данных внутри себя, поскольку здесь может быть выполнена операция размещения либо получения объектов
Важно понимать, что с такими хранилищами взаимодействуют не сами пользователи, а приложения или отдельные системы, а основой API выступает протокол HTTP
Для того, чтобы выполнить подключение к S3 хранилищу, можно воспользоваться несколькими способами. Какой из них окажется удобным, решать вам. Приведем пример наиболее часто используемых вариантов:
S3Browser
Программа S3Browser позволяет подключиться к хранилищу по протоколу S3, скачать ее можно с официального сайта компании. Процедура стандартная: необходимо задать имя аккаунту, выбрать тип подключения S3 Compatible Storage, указать адрес подключения, ID ключа доступа, значение секретного ключа и активировать в случае необходимости опцию шифрования данных при подключении. Все. После чего можно работать с хранилищем.

Swift API
Подключиться к S3 хранилищу можно с помощью Swift API через программу Cyberduck, скачав ее предварительно с официального сайта разработчика. После установки и запуска приложения, необходимо выполнить новое подключение. Для этого нужно указать, что вы подключаетесь к объектному хранилищу Swift (OpenStack Object Storage), задать название сервера, номер порта 443, ключ доступа и пароль.
| Для каких задач подходит S3 хранилище | |
|---|---|
| Обеспечение работы сайтов и мобильных приложений | ✓ |
| Архивация, анализ больших объемов данных | ✓ |
| Хранение статического контента, мультимедийных файлов | ✓ |
| Хранение пользовательских данных и бэкапов | ✓ |
| Раздача статических файлов | ✓ |
| Хранение данных backend-платформ | ✓ |
| Электронный документооборот | ✓ |
| Хранение историй транзакций и логов | ✓ |
| Хранение резервных копий ИС | ✓ |
| Хранение неструктурированных данных | ✓ |
Deploying OSDs
To prepare a node for running OSDs, run:
ceph-deploy osd create HOST:DISK ...]
After that, the hosts will be running OSDs for the given data disks.
If you specify a raw disk (e.g., /dev/sdb), partitions will be
created and GPT labels will be used to mark and automatically activate
OSD volumes. If an existing partition is specified, the partition
table will not be modified. If you want to destroy the existing
partition table on DISK first, you can include the --zap-disk
option.
If there is already a prepared disk or directory that is ready to become an
OSD, you can also do:
ceph-deploy osd activate HOST:DIR
Adding Capabilities
In this step we are going to add read, write and execute capabilities to the previously created keys:
:~# ceph-authtool -n client.radosgw.cph1 --cap osd 'allow rwx' --cap mon 'allow rwx' /etc/ceph/ceph.client.radosgw.keyring:~# ceph-authtool -n client.radosgw.cph2 --cap osd 'allow rwx' --cap mon 'allow rwx' /etc/ceph/ceph.client.radosgw.keyring:~# ceph-authtool -n client.radosgw.cph3 --cap osd 'allow rwx' --cap mon 'allow rwx' /etc/ceph/ceph.client.radosgw.keyring:~# ceph-authtool -n client.radosgw.cph4 --cap osd 'allow rwx' --cap mon 'allow rwx' /etc/ceph/ceph.client.radosgw.keyring
Persistent Volume Claim
PersistentVolumeClaim (PVC) есть не что иное как запрос к Persistent Volumes на хранение от пользователя. Это аналог создания Pod на ноде. Поды могут запрашивать определенные ресурсы ноды, то же самое делает и PVC. Основные параметры запроса:
- объем pvc
- тип доступа
Типы доступа у PVC могут быть следующие:
- ReadWriteOnce – том может быть смонтирован на чтение и запись к одному поду.
- ReadOnlyMany – том может быть смонтирован на много подов в режиме только чтения.
- ReadWriteMany – том может быть смонтирован к множеству подов в режиме чтения и записи.
Ограничение на тип доступа может налагаться типом самого хранилища. К примеру, хранилище RBD или iSCSI не поддерживают доступ в режиме ReadWriteMany.
Один PV может использоваться только одним PVС. К примеру, если у вас есть 3 PV по 50, 100 и 150 гб. Приходят 3 PVC каждый по 50 гб. Первому будет отдано PV на 50 гб, второму на 100 гб, третьему на 150 гб, несмотря на то, что второму и третьему было бы достаточно и 50 гб. Но если PV на 50 гб нет, то будет отдано на 100 или 150, так как они тоже удовлетворяют запросу. И больше никто с PV на 150 гб работать не сможет, несмотря на то, что там еще есть свободное место.
Из-за этого нюанса, нужно внимательно следить за доступными томами и запросами к ним. В основном это делается не вручную, а автоматически с помощью PV Provisioners. В момент запроса pvc через api кластера автоматически формируется запрос к storage provider. На основе этого запроса хранилище создает необходимый PV и он подключается к поду в соответствии с запросом.
Подключение Cephfs
Как я уже сказал ранее, для работы cephfs у нас уже есть pool, который можно использовать для хранения данных. Я сейчас подключу его к одной из нод кластера, где у меня есть административный доступ к нему и создам в пуле отдельную директорию, которую мы потом смонтируем на другой сервер.
Монтируем pool.
# mount.ceph 10.1.4.32:/ /mnt/cephfs -o name=admin,secret=`ceph auth get-key client.admin`
В данном случае 10.1.4.32 адрес одного из мониторов. Их надо указывать все три, но сейчас я временно подключаю пул просто чтобы создать в нем каталог. Достаточно и одного монитора. Я использую команду:
# ceph auth get-key client.admin
для того, чтобы получить ключ пользователя admin. С помощью такой конструкции он нигде не засвечивается, а сразу передается команде mount. Проверим, что у нас получилось.
# df -h | grep cephfs 10.1.4.32:/ 47G 0 47G 0% /mnt/cephfs
Смонтировали pool. Его размер получился 47 Гб. Напоминаю, что у нас в кластере 3 диска по 50 Гб, фактор репликации 3 и 3 гб заняты под служебные нужды. По факту у нас есть 47 Гб свободного места для использования в кластере ceph. Это место делится поровну между всеми пулами. К примеру, когда у нас появятся rbd диски, они будут делить этот размер вместе с cephfs.
Создаем в cephfs директорию data1, которую будем монтировать к другому серверу.
# mkdir /mnt/cephfs/data1
Теперь нам нужно создать пользователя для доступа к этой директории.
# ceph auth get-or-create client.data1 mon 'allow r' mds 'allow r, allow rw path=/data1' osd 'allow rw pool=cephfs_data' key = AQBLRDBePhITJRAAFpGaJlGmqOj9RCXhMdIQ+w==
На выходе получите ключ от пользователя. Что я сделал в этой команде:
- Создал клиента data1;
- Выставил ему права к разным сущностям кластера (mon, mds, osd);
- Дал права на запись в директорию data1 в cephfs.
Если забудете ключ доступа, посмотреть его можно с помощью команды:
# ceph auth get-key client.data1
Теперь идем на любой другой сервер в сети, который поддерживает работу с cephfs. Это практически все современные дистрибутивы linux. У них поддержка ceph в ядре. Монтируем каталог кластера ceph, указывая все 3 монитора.
# mount -t ceph 10.1.4.32,10.1.4.33,10.1.4.39:/ /mnt -o name=data1,secret='AQBLRDBePhITJRAAFpGaJlGmqOj9RCXhMdIQ+w=='
Проверяем, что получилось.
# df -h | grep mnt 10.1.4.32,10.1.4.33,10.1.4.39:/ 47G 0 47G 0% /mnt
Каталог data1 на файловой системе cephfs подключен. Можете попробовать на него что-то записать. Этот же файл вы должны увидеть с любого другого клиента, к которому подключен этот же каталог.
Теперь настроим автомонтирование диска cephfs при старте системы. Для этого надо создать конфиг файл /etc/ceph/data1.secret следующего содержания.
AQBLRDBePhITJRAAFpGaJlGmqOj9RCXhMdIQ+w==
Это просто ключ пользователя data1. Добавляем в /etc/fstab подключение диска при загрузке.
10.1.4.32,10.1.4.33,10.1.4.39:/ /mnt ceph name=data1,secretfile=/etc/ceph/data1.secret,_netdev,noatime 0 0
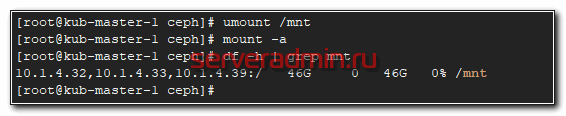
Не забудьте в конце файла fstab сделать переход на новую строку, иначе сервер у вас не загрузится. Теперь проверим, все ли мы сделали правильно. Если у вас уже смонтирован диск, отмонтируйте его и попробуйте автоматически смонтировать на основе записи в fstab.
# umount /mnt # mount -a
На этом по поводу cephfs все. Можно пользоваться. Переходим к блочным устройствам rbd.
Отказоустойчивый кластер
Настроим автоматический перезапуск виртуальных машин на рабочих нодах, если выйдет из строя сервер.
Для настройки отказоустойчивости (High Availability или HA) нам нужно:
- Минимум 3 ноды в кластере. Сам кластер может состоять из двух нод и более, но для точного определения живых/не живых узлов нужно большинство голосов (кворумов), то есть на стороне рабочих нод должно быть больше одного голоса. Это необходимо для того, чтобы избежать ситуации 2-я активными узлами, когда связь между серверами прерывается и каждый из них считает себя единственным рабочим и начинает запускать у себя все виртуальные машины. Именно по этой причине HA требует 3 узла и выше.
- Общее хранилище для виртуальных машин. Все ноды кластера должны быть подключены к общей системе хранения данных — это может быть СХД, подключенная по FC или iSCSI, NFS или распределенное хранилище Ceph или GlusterFS.
1. Подготовка кластера
Процесс добавления 3-о узла аналогичен процессу, — на одной из нод, уже работающей в кластере, мы копируем данные присоединения; в панели управления третьего сервера переходим к настройке кластера и присоединяем узел.
2. Добавление хранилища
Подробное описание процесса настройки самого хранилища выходит за рамки данной инструкции. В данном примере мы разберем пример и использованием СХД, подключенное по iSCSI.
Если наша СХД настроена на проверку инициаторов, на каждой ноде смотрим командой:
cat /etc/iscsi/initiatorname.iscsi
… IQN инициаторов. Пример ответа:
…
InitiatorName=iqn.1993-08.org.debian:01:4640b8a1c6f
* где iqn.1993-08.org.debian:01:4640b8a1c6f — IQN, который нужно добавить в настройках СХД.
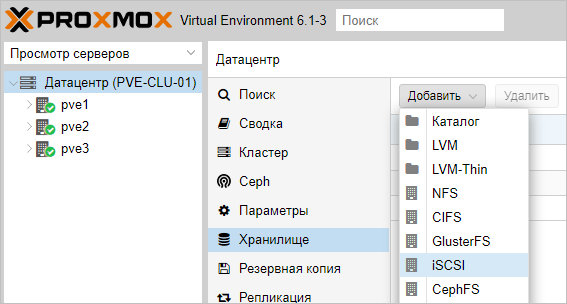
После настройки СХД, в панели управления Proxmox переходим в Датацентр — Хранилище. Кликаем Добавить и выбираем тип (в нашем случае, iSCSI):
В открывшемся окне указываем настройки для подключения к хранилке:
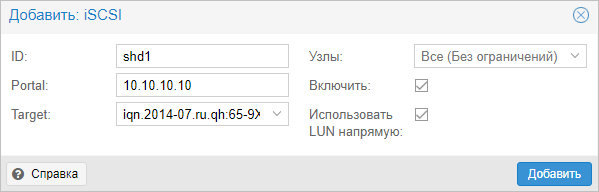
* где ID — произвольный идентификатор для удобства; Portal — адрес, по которому iSCSI отдает диски; Target — идентификатор таргета, по которому СХД отдает нужный нам LUN.
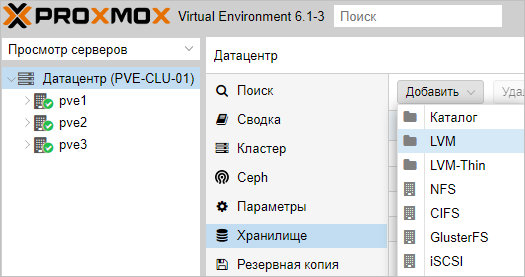
Нажимаем добавить, немного ждем — на всех хостах кластера должно появиться хранилище с указанным идентификатором. Чтобы использовать его для хранения виртуальных машин, еще раз добавляем хранилище, только выбираем LVM:
Задаем настройки для тома LVM:
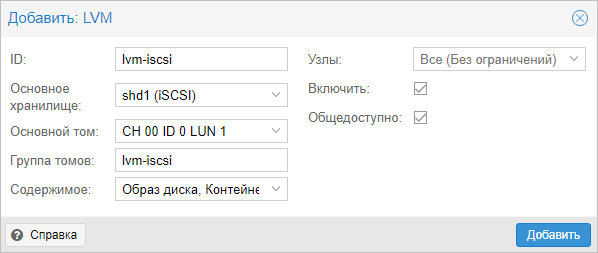
* где было настроено:
- ID — произвольный идентификатор. Будет служить как имя хранилища.
- Основное хранилище — выбираем добавленное устройство iSCSI.
- Основное том — выбираем LUN, который анонсируется таргетом.
- Группа томов — указываем название для группы томов. В данном примере указано таким же, как ID.
- Общедоступно — ставим галочку, чтобы устройство было доступно для всех нод нашего кластера.
Нажимаем Добавить — мы должны увидеть новое устройство для хранения виртуальных машин.
Для продолжения настройки отказоустойчивого кластера создаем виртуальную машину на общем хранилище.
3. Настройка отказоустойчивости
Создание группы
Для начала, определяется с необходимостью групп. Они нужны в случае, если у нас в кластере много серверов, но мы хотим перемещать виртуальную машину между определенными нодами. Если нам нужны группы, переходим в Датацентр — HA — Группы. Кликаем по кнопке Создать:
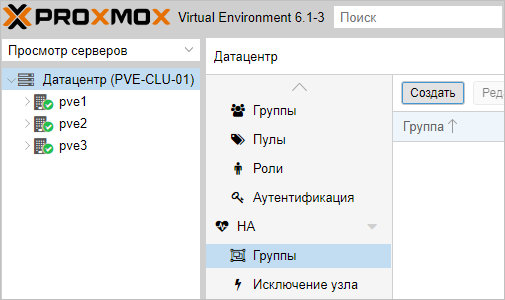
Вносим настройки для группы и выбираем галочками участников группы:
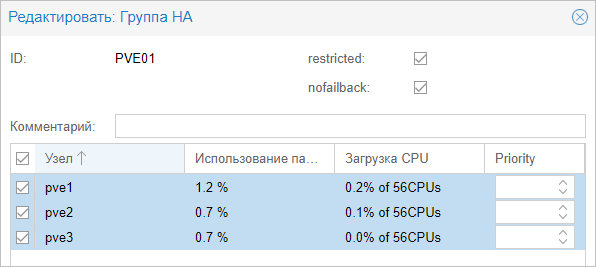
* где:
- ID — название для группы.
- restricted — определяет жесткое требование перемещения виртуальной машины внутри группы. Если в составе группы не окажется рабочих серверов, то виртуальная машина будет выключена.
- nofailback — в случае восстановления ноды, виртуальная машина не будет на нее возвращена, если галочка установлена.
Также мы можем задать приоритеты для серверов, если отдаем каким-то из них предпочтение.
Нажимаем OK — группа должна появиться в общем списке.
Настраиваем отказоустойчивость для виртуальной машины
Переходим в Датацентр — HA. Кликаем по кнопке Добавить:
В открывшемся окне выбираем виртуальную машину и группу:
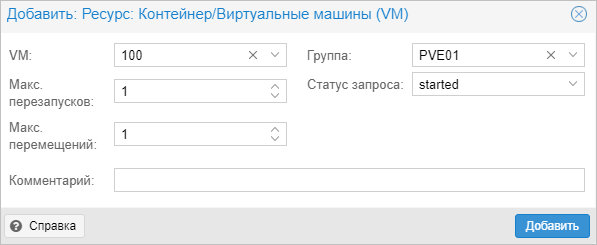
… и нажимаем Добавить.
4. Проверка отказоустойчивости
После выполнения всех действий, необходимо проверить, что наша отказоустойчивость работает. Для чистоты эксперимента, можно выключиться сервер, на котором создана виртуальная машина, добавленная в HA.
Важно учесть, что перезагрузка ноды не приведет к перемещению виртуальной машины. В данном случае кластер отправляет сигнал, что он скоро будет доступен, а ресурсы, добавленные в HA останутся на своих местах
Для выключения ноды можно ввести команду:
systemctl poweroff
Виртуальная машина должна переместиться в течение 1 — 2 минут.
Подготовка настроек
Ну что же, с теоретической частью закончили, начинаем практику. Мы будем устанавливать ceph с помощью официального playbook для ansible. Клонируем к себе репозиторий.
# git clone https://github.com/ceph/ceph-ansible
Переключаемся на последнюю стабильную ветку 3.2.
# cd ceph-ansible # git checkout stable-3.2
Проверяем зависимости в файле requirements.txt:
- ansible~=2.6,<2.7
- netaddr
Установим ansible и модуль питона netaddr через pip. А так же нужен будет модуль notario.
# pip install ansible==2.6.0.0 notario netaddr
И обновим еще пару модулей.
# pip install --upgrade chardet urllib3
Теперь готовим инвентарь для palybook. Создаем в корне репозитория папку inventory.
# mkdir inventory
В ней создаем файл hosts примерно следующего содержания.
kub-ingress-1 monitor_address=10.1.4.39 kub-node-1 monitor_address=10.1.4.32 kub-node-2 monitor_address=10.1.4.33 kub-node-1 kub-node-2 kub-ingress-1 kub-node-1 kub-node-2 kub-ingress-1 kub-node-1 kub-node-2 kub-ingress-1
Для примера я взял 3 рабочие ноды из своей статьи про установку кластера Kubernetes. Я использую ту же тестовую лабу. По сути, это просто 3 виртуальных сервера с двумя жесткими дисками:
- sda под систему
- sdb под данные кластера ceph
В инвентаре несколько групп серверов:
- mons — мониторинг
- osds — демон хранения
- mgrs — менеджер
- mds — сервер метаданных
У меня все сервера равнозначные, поэтому на всех будет стоять все.
Дальше нам нужно указать некоторые параметры кластера. Делаем это в файле all.yml в директории inventory/group_vars.
ceph_origin: repository
ceph_repository: community
ceph_stable_release: luminous
public_network: "10.1.4.0/24"
cluster_network: "10.1.4.0/24"
ntp_service_enabled: true
ntp_daemon_type: ntpd
osd_objectstore: bluestore
osd_scenario: lvm
devices:
- /dev/sdb
ceph_conf_overrides:
global:
osd_pool_default_pg_num: 64
osd_pool_default_pgp_num: 64
osd_journal_size: 5120
osd_pool_default_size: 3
osd_pool_default_min_size: 2
Небольшие пояснения к некоторым переменным:
- ceph_origin — откуда будет выполняться установка. В моем случае из репозитория.
- ceph_repository — название репозитория. В данном случае community, есть еще rhcs от redhat.
- ceph_stable_release — название последнего стабильного релиза.
- public_network — сеть, откуда будут приходить запросы в кластер.
- cluster_network — сеть для общения самого кластера. У меня небольшой тестовый кластер, поэтому сеть общая. Для больших кластеров cluster_network надо делать отдельной с хорошей пропускной способностью.
- osd_objectstore — тип хранения данных, bluestore — общая рекомендация для использования.
- osd_scenario — как будут храниться данные, в данном случае в lvm томах.
- devices — устройства, которые будет использовать ceph. Если их не указать, будут использованы все незадействованные диски.
- osd_pool_default_pg_num — кол-во placement groups. Стандартная формула для расчета этой штуки — (OSD * 100) / кол-во реплик. Результат должен быть округлён до ближайшей степени двойки. Если получилось 700, округляем до 512.
- osd_pool_default_pgp_num — настройка для размещения pg, служебная штука, рекомендуется ее выставлять такой же, как количество pg.
- osd_journal_size — размер журнала в мегабайтах. Я оставил дефолтное значение в 5 Гб, но если у вас маленький тестовый кластер можно уменьшить, или наоборот увеличить в больших кластерах.
- osd_pool_default_size — количество реплик данных в нашем кластере, 3 — минимально необходимое для отказоустойчивости.
- osd_pool_default_min_size — количество живых реплик, при которых пул еще работает. Если будет меньше, запись блокируется.
С инвентарем и параметрами разобрались. У нас почти все готово для установки ceph. Осталось создать файл site.yml в корневой папке репозитория, скопировав site.yml.sample.
# cp site.yml.sample site.yml
В файле оставляем все значения дефолтными.
Удаление Amazonaws
Теперь, когда вы знаете, что вы имеете дело с, вы должны удалить Amazonaws adware. Это может быть сделано двумя способами: вручную и автоматически. Первый метод предполагает вы делаете всё сами, но если вы не уверены где начать, вы можете использовать ниже получают инструкции, чтобы помочь вам. В противном случае можно получить анти шпионского программного обеспечения и он позаботится обо всем за вас. Это будет метод проще, особенно для тех, кто имеет мало опыта, когда речь заходит о компьютерах.
Offers
Скачать утилитуto scan for s3.amazonaws.comUse our recommended removal tool to scan for s3.amazonaws.com. Trial version of WiperSoft provides detection of computer threats like s3.amazonaws.com and assists in its removal for FREE. You can delete detected registry entries, files and processes yourself or purchase a full version.
More information about WiperSoft and Uninstall Instructions. Please review WiperSoft EULA and Privacy Policy. WiperSoft scanner is free. If it detects a malware, purchase its full version to remove it.
-
WiperSoft обзор детали
WiperSoft является инструментом безопасности, который обеспечивает безопасности в реальном в … -
Это MacKeeper вирус?MacKeeper это не вирус, и это не афера. Хотя существуют различные мнения о программе в Интернете, мн …
-
Хотя создатели антивирусной программы MalwareBytes еще не долго занимаются этим бизнесом, они восполняют этот нед …
Site Disclaimer
2-remove-virus.com is not sponsored, owned, affiliated, or linked to malware developers or distributors that are referenced in this article. The article does not promote or endorse any type of malware. We aim at providing useful information that will help computer users to detect and eliminate the unwanted malicious programs from their computers. This can be done manually by following the instructions presented in the article or automatically by implementing the suggested anti-malware tools.
The article is only meant to be used for educational purposes. If you follow the instructions given in the article, you agree to be contracted by the disclaimer. We do not guarantee that the artcile will present you with a solution that removes the malign threats completely. Malware changes constantly, which is why, in some cases, it may be difficult to clean the computer fully by using only the manual removal instructions.
Заключение
Надеюсь, моя статья про описание, установку и эксплуатацию ceph была полезна. Постарался объяснять все простым языком для тех, кто как и я, только начинает знакомство с ceph. Мне система очень понравилась именно тем, что ее можно так легко разворачивать и масштабировать. Берешь обычные серверы, раскатываешь ceph, ставишь фактор репликации 3 и не переживаешь за свои данные. Думаю, использовать его под бэкапы, docker registry или некритичное видеонаблюдение.
Переживать начинаешь, когда в кластер идет непрерывная высокая нагрузка. Но тут, как и в любых highload проектах, нет простых решений. Надо во все вникать, во всем разбираться и быть всегда на связи. Меня не привлекают такие перспективы 🙂
Онлайн курс «Сетевой инженер»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные сети, рекомендую познакомиться с онлайн-курсом «Сетевой инженер» в OTUS. Это авторская программа в сочетании с удалённой практикой на реальном оборудовании и академическим сертификатом Cisco! Студенты получают практические навыки работы на оборудовании при помощи удалённой онлайн-лаборатории, работающей на базе партнёра по обучению — РТУ МИРЭА: маршрутизаторы Cisco 1921, Cisco 2801, Cisco 2811; коммутаторы Cisco 2950, Cisco 2960.
Особенности курса:
- Курс содержит две проектные работы.;
- Студенты зачисляются в официальную академию Cisco (OTUS, Cisco Academy, ID 400051208) и получают доступ ко всем частям курса «CCNA Routing and Switching»;
- Студенты могут сдать экзамен и получить вместе с сертификатом OTUS ещё сертификат курса «CCNA Routing and Switching: Scaling Networks»;
Проверьте себя на вступительном тесте и смотрите программу детальнее по .