Кассандра и комплекс кассандры. что значит «пророчество кассандры»?
Содержание:
- In a nutshell
- Features of Cassandra
- Usuarios Conocidos
- NoSQLDatabase
- History
- Using Cassandra from the Java environment
- Модель данных
- 2013
- Что общего между Apache Cassandra и HBase: 5 главных сходств
- Что такое комплекс Кассандры
- Apache Cassandra
- NoSQL vs. Relational Database
- Cassandra architecture
- В искусстве
- Modelo de Datos
In a nutshell
If you are to make a choice between Apache Cassandra and HDFS, the first thing to take into account is the nature of your raw data. If you have to store and process large data sets, you can consider HDSF, if multiple small records – Cassandra may be a better option. Besides, you should form your requirements towards data consistency, availability and partition tolerance. To make a final decision, it’s critical to understand the exact use of big data storage.
Even if Cassandra seems to outperform HDFS in most cases described, this does not mean that HDFS is weak. Based on your business needs, a professional Hadoop consulting team may suggest a combination of frameworks and technologies with HDFS and Hive or HBase at core that would enable great and seamless performance.
Big Data Consulting Services
Need professional advice on big data and dedicated technologies? Get it from the vendor with 30 years of experience in data analytics.
Features of Cassandra
Cassandra has become so popular because of its outstanding technical features.
Given below are some of the features of Cassandra:
-
Elastic scalability − Cassandra is highly scalable; it allows to add more hardware to accommodate more customers and more data as per
requirement. -
Always on architecture − Cassandra has no single point of failure and it is continuously available for business-critical applications that cannot afford a failure.
-
Fast linear-scale performance − Cassandra is linearly scalable, i.e., it increases your throughput as you increase the number of nodes in the cluster. Therefore it maintains a quick response time.
-
Flexible data storage − Cassandra accommodates all possible data formats including: structured, semi-structured, and unstructured. It can dynamically accommodate changes to your data structures according to your need.
-
Easy data distribution − Cassandra provides the flexibility to distribute data where you need by replicating data across multiple data centers.
-
Transaction support − Cassandra supports properties like Atomicity, Consistency, Isolation, and Durability (ACID).
-
Fast writes − Cassandra was designed to run on cheap commodity hardware. It performs blazingly fast writes and can store hundreds of terabytes of data, without sacrificing the read efficiency.
Usuarios Conocidos
- WalmartLabs (anteriormente Kosmix) usa Cassandra con SSD
- Apple usa 75,000 nodos de Cassandra, como se reveló en el Cassandra Summit San Francisco 2014.
- AppScale usa Cassandra como back-end para aplicaciones de Google App Engine
- CERN usa un prototipo basado en Cassandra para el experimento ATLAS para archivar su sistema de monitoreo en línea.
- Cisco WebEx usa Cassandra para almacenar la retroalimentación y actividades de los usuarios en tiempo real.
- Cloudkick usa Cassandra para almacenar métricas de los servidores de sus usuarios.
- Constant Contact usa Cassandra en sus aplicaciones de email y redes sociales.
- Digg, un gran sitio web de noticias, anunció el 9 de setiembre de 2009 que empezó a usar Cassandra
- usa Cassandra para su sistema de búsquedas en la bandeja de entrada, con una implemetanción de más de 200 nodos.
- Formspring usa Cassandra para contar respuestas, así como para almacenar datos como seguidores, usuarios bloqueados, etc.
- IBM realizó investigaciones para desarrollar un sistema de email basado en Cassandra.
- Mahalo.com usa Cassandra para guardar la actividad de sus usuarios y temas para su sitio Q&A
- Netflix usa Cassandra como base de datos de back-end para su servicio de streaming
- Nutanix usa Cassandra para almacenar metadatos y estadísticas.
- Openwave usa Cassandra como base de datos distribuida y como mecanismo de almacenamiento para si plataforma de mensajes de próxima generación
- OpenX tiene más de 130 nodos de Cassandra para OpenX Enterprise, donde almacena y replica anuncios y datos para propaganda
- PostRank usa Cassandra como base de datos de backend
- Rackspace usa Cassandra internamente.
- Reddit se cambió a Cassandra de memcacheDB el 12 de marzo de 2010 y experimentó algunos problemas en mayo por comenzar con pocos nodos.
- RockYou usa Cassandra para grabar cada canción
- SoundCloud usa Cassandra para almacenar el dashboard de sus usuarios
- Talentica Software usa Cassandra como back-end para hacer análisis de datos, con más de 30 nodos insertando alrededor de 200GB de datos diariamente.
- anunció que está planificando cambiar MySQL por Cassandra
- Urban Airship usa Cassandra con el servicio de almacenamiento movie, con más de 160 millones de aplicaciones instaladas en más de 80 millones de dispositivos
- Wikimedia usa Cassandra como base de datos de backend.
- Zoho usa Cassandra para una pre-visualización de su bandeja de entrada de Zoho Mail.
cambió su desarrollo de la versión preliminar de Apache Cassandra a finales de 2010, cuando reemplazaron la búsqueda en la bandeja de entrada por su plataforma de mensajería. En 2012, Facebook comenzó a usar Apache Cassandra en Instagram.
NoSQLDatabase
A NoSQL database (sometimes called as Not Only SQL) is a database that provides a mechanism to store and retrieve data other than the tabular relations used in relational databases. These databases are schema-free, support easy replication, have simple API, eventually consistent, and can handle huge amounts of data.
The primary objective of a NoSQL database is to have
- simplicity of design,
- horizontal scaling, and
- finer control over availability.
NoSql databases use different data structures compared to relational databases. It makes some operations faster in NoSQL. The suitability of a given NoSQL database depends on the problem it must solve.
History
Avinash Lakshman, one of the authors of Amazon’s Dynamo, and Prashant Malik initially developed Cassandra at to power the Facebook inbox search feature. Facebook released Cassandra as an open-source project on Google code in July 2008. In March 2009 it became an Apache Incubator project. On February 17, 2010 it graduated to a top-level project.
Facebook developers named their database after the Trojan mythological prophet Cassandra, with classical allusions to a curse on an oracle.
Releases
Releases after graduation include
- 0.6, released Apr 12 2010, added support for integrated caching, and Apache Hadoop MapReduce
- 0.7, released Jan 08 2011, added secondary indexes and online schema changes
- 0.8, released Jun 2 2011, added the Cassandra Query Language (CQL), self-tuning memtables, and support for zero-downtime upgrades
- 1.0, released Oct 17 2011, added integrated compression, leveled compaction, and improved read-performance
- 1.1, released Apr 23 2012, added self-tuning caches, row-level isolation, and support for mixed ssd/spinning disk deployments
- 1.2, released Jan 2 2013, added clustering across virtual nodes, inter-node communication, atomic batches, and request tracing
- 2.0, released Sep 4 2013, added lightweight transactions (based on the Paxos consensus protocol), triggers, improved compactions
- 2.1 released Sep 10 2014
- 2.2 released July 20, 2015
- 3.0 released November 11, 2015
- 3.1 through 3.10 releases were monthly releases using a tick-tock-like release model, with even-numbered releases providing both new features and bug fixes while odd-numbered releases will include bug fixes only.
- 3.11 released June 23, 2017 as a stable 3.11 release series and bug fix from the last tick-tock feature release.
| Version | Original release date | Latest version | Release date | Status |
|---|---|---|---|---|
| Old version, no longer maintained: 0.6 | 2010-04-12 | 0.6.13 | 2011-04-18 | No longer supported |
| Old version, no longer maintained: 0.7 | 2011-01-10 | 0.7.10 | 2011-10-31 | No longer supported |
| Old version, no longer maintained: 0.8 | 2011-06-03 | 0.8.10 | 2012-02-13 | No longer supported |
| Old version, no longer maintained: 1.0 | 2011-10-18 | 1.0.12 | 2012-10-04 | No longer supported |
| Old version, no longer maintained: 1.1 | 2012-04-24 | 1.1.12 | 2013-05-27 | No longer supported |
| Old version, no longer maintained: 1.2 | 2013-01-02 | 1.2.19 | 2014-09-18 | No longer supported |
| Old version, no longer maintained: 2.0 | 2013-09-03 | 2.0.17 | 2015-09-21 | No longer supported |
| Older version, yet still maintained: 2.1 | 2014-09-16 | 2.1.22 | 2020-08-31 | Still supported, critical fixes only |
| Older version, yet still maintained: 2.2 | 2015-07-20 | 2.2.18 | 2020-08-31 | Still supported |
| Older version, yet still maintained: 3.0 | 2015-11-09 | 3.0.22 | 2020-08-31 | Still supported |
| Current stable version: 3.11 | 2017-06-23 | 3.11.8 | 2020-08-31 | Latest release |
| Latest preview version of a future release: 4.0 | n/a | 4.0-beta2 | 2020-08-31 | Beta preview |
|
|
Using Cassandra from the Java environment
Cassandra has many clients written in different languages. This article
focuses on the Hector client (see ), which is the most widely used Java client for Cassandra.
Users can add to their application by adding the Hector JARs to the
application classpath. shows a sample
Hector client.
First, connect to a Cassandra cluster. Use the instructions in the
Cassandra Getting Started Page (see ) to set up a Cassandra node. Unless its configuration has
been changed, it typically runs on port 9160. Next, define a keyspace.
This can be done either through the client or through the
conf/cassandra.yaml configuration file.
Listing 4. Sample Hector client code for
Cassandra
Cluster cluster = HFactory.createCluster('TestCluster',
new CassandraHostConfigurator("localhost:9160"));
//define a keyspace
Keyspace keyspace = HFactory.createKeyspace("BooksRating", cluster);
//Now let's add a new column.
String rowID = "Foundation";
String columnFamily = "Books";
Mutator<String>
mutator = HFactory.createMutator(keyspace, user);
mutator.insert(rowID, columnFamily,
HFactory.createStringColumn("author", "Asimov"));
//Now let's read the column back
ColumnQuery<String, String, String>
columnQuery = HFactory.createStringColumnQuery(keyspace);
columnQuery.setColumnFamily(columnFamily).setKey(”wso2”).setName("address");
QueryResult<HColumn<String, String>
result = columnQuery.execute();
System.out.println("received "+ result.get().getName() + "= "
+ result.get().getValue() + " ts = "+ result.get().getClock());
Find the complete code for the book rating example in . It includes samples for slice
queries and other complex operations.
Модель данных
Конкретное значение, хранимое в кассандре идентифицируется(см. рисунок 2):
- пространством ключей — это привязка к приложению (предметной области). Позволяет на одном кластере размещать данные разных приложений;
- колоночным семейством — это привязка к запросу;
- ключом — это привязка к узлу кластера. От ключа зависит на какие узлы попадут сохранённые колонки;
- именем колонки — это привязка к атрибуту в записи. Позволяет в одной записи хранить несколько значений.
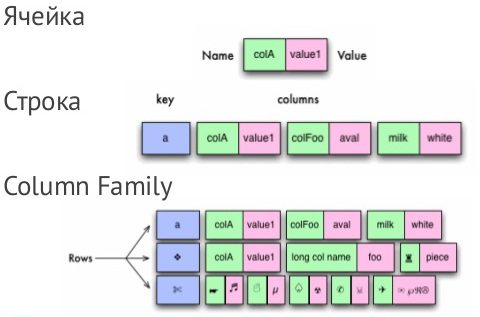
Рисунок 2 — Структура Cassandra
Структура данных при этом выглядит так:
- Keyspace
- ColumnFamily
- Row
- Key
- Column
- Name
- Value
- Column
- …
- …
- Row
- ColumnFamily
С каждым значением связана метка времени — задаваемое пользователем число, которое используется для разрешения конфликтов во время записи: чем больше число, тем колонка считается новее, а при сравнении перетирает старые колонки.
По типам данных: пространство ключей и колоночное семейство — это строки (имена); метка времени — это 64-битное число; а ключ, имя колонки и значение колонки — это массив байтов. Также кассандра имеет понятие типов данных (data type). Эти типы могут по желанию разработчика (опционально) задаваться при создании колоночного семейства. Для имён колонок это называется сравнителем (comparator), для значений и ключей — валидатором (validator). Первый определяет какие байтовые значения допустимы для имён колонок и как их упорядочить. Второй — какие байтовые значение допустимы для значений колонок и ключей. Если эти типы данных не заданы, то кассандра хранит значения и сравнивает их как байтовые строки (BytesType) так как, по сути, они сохраняются внутри.
Типы данных бывают такими:
- BytesType: любые байтовые строки (без валидации)
- AsciiType: ASCII строка
- UTF8Type: UTF-8 строка
- IntegerType: число с произвольным размером
- Int32Type: 4-байтовое число
- LongType: 8-байтовое число
- UUIDType: UUID 1-ого или 4-ого типа
- TimeUUIDType: UUID 1-ого типа
- DateType: 8-байтовое значение метки времени
- BooleanType: два значения: true = 1 или false = 0
- FloatType: 4-байтовое число с плавающей запятой
- DoubleType: 8-байтовое число с плавающей запятой
- DecimalType: число с произвольным размером и плавающей запятой
- CounterColumnType: 8-байтовый счётчик
В кассандре все операции записи данных это всегда операции перезаписи, то есть, если в колоночную семью приходит колонка с таким же ключом и именем, которые уже существуют, и метка времени больше, чем та которая сохранена, то значение перезаписывается. Записанные значения никогда не меняются, просто приходят более новые колонки с новыми значениями.
Запись в кассандру работает с большей скоростью, чем чтение. Это меняет подход, который применяется при проектировании. Если рассматривать кассандру с точки зрения проектирования модели данных, то проще представить колоночное семейство не как таблицу, а как материализованное представление (materialized view) — структуру, которая представляет данные некоторого сложного запроса, но хранит их на диске. Вместо того, чтобы пытаться как-либо скомпоновать данные при помощи запросов, лучше постараться сохранить в коночное семейство все, что может понадобиться для этого запроса. То есть, подходить необходимо не со стороны отношений между сущностями или связями между объектами, а со стороны запросов: какие поля требуются выбрать; в каком порядке должны идти записи; какие данные, связанные с основными, должны запрашиваться совместно — всё это должно уже быть сохранено в колоночное семейство. Количество колонок в записи ограничено теоретически 2 миллиардами. А теперь давайте углубимся в процесс сохранения данных в кассандру и их чтения.
2013
Apache Cassandra 2.0
Самыми важными нововведениями NoSQL-СУБД Cassandra 2.0, выпущенной в сентябре 2013 года фондом Apache, названы `лёгкие` транзакции, язык запросов CQL, напоминающий SQL, и триггеры. Джонотан Эллис, вице-президент проекта, особо отметил, что Cassandra теперь упрощает переход с РСУБД, однако технологию такого упрощения не уточнил.
В новой версии `легкие` транзакции решают конфликты попыток модификации данных одновременными запросами. Триггеры позволяют выполнять прикладной код при изменении информации в базе, а за счёт распределённой архитектуры скорость выполнения запроса, вызвавшего срабатывание триггера, не ухудшается. Повышена компактность БД, снижена вероятность таймаутов запросов. Использовать функциональность Cassandra в прикладных задачах теперь можно не только через программный API, но и через язык запросов CQL, который официально добавился в январе, но только сейчас доступен в зрелом виде. Хотя Cassandra поддерживает модель `ключ-значение`, однако её конкретная реализация напоминает работу с таблицами, поэтому CQL сохранил привычный SQL-кодировщикам синтаксис: можно использовать команды SELECT, INSERT, CREATE TABLE и т. д.
Что общего между Apache Cassandra и HBase: 5 главных сходств
Прежде всего отметим, чем похожи HBase и Кассандра. Проанализировав главные достоинства и недостатки этих нереляционных СУБД, мы выделили следующие их общие качества:
- История разработки – обе рассматриваемые СУБД написаны на языке программирования Java примерно в одно время: Cassandra создана в 2008 в Facebook, а HBase – в 2007 в Powerset. Проектами верхнего уровня Apache Software Foundation эти продукты стали в 2009 и 2010 гг. соответственно.
- Модель данных – обе системы основаны на концепциях Google Big Table и являются колоночно-ориентированными хранилищами, где информация хранится хранятся в ячейках, сгруппированных в столбцы, а не в строки данных . При этом сами столбцы (колонки) группируются в семейства (Column Family), а в общем хранилища относятся к типу «ключ-значение» (key-value). Несмотря на общие термины, их реализация в рассматриваемых системах немного отличается: столбец Кассандры больше похож на ячейку в HBase, а семейство столбцов – на таблицу соответственно. Также в модели данных Cassandra реализуется понятие «пространство ключей» (keyspace), чего нет в другой СУБД. В свою очередь, в HBase есть концепция региона — диапазона записей, соответствующих определенному диапазону подряд идущих первичных ключей, что позволяет балансировать размером таблицы и распределением по узлам кластера. Однако, обе модели являются гибкими, поддерживают маркирование данных метками времени (timestamp) и отлично подходят для хранения больших объемов разреженных данных, допуская отсутствующие значения в определенной ячейке или столбце и не занимая при этом места для хранения. В обоих случаях необходимо указывать семейства столбцов при разработке схемы данных, которая потом не изменяется, тогда как в определении столбцов допустима гибкость в любое время .
- Высокая скорость работы – при том, что обе СУБД работают быстро, практически в режиме реального времени, в плане производительности операций чтения и записи они отличаются. В частности, благодаря своим архитектурным особенностям, о которых мы рассказывали здесь, Кассандра работает быстрее своего конкурента . Однако, в случае произвольного доступа к данным в виде множества согласованных операций чтения HBase может работать эффективнее Cassandra благодаря блочному кэшу HDFS, Bloom-фильтрам и собственной системе индексов .
- Информационная безопасность – обе базы данных поддерживают аутентификацию, авторизацию и шифрование между узлами, обеспечивая не только общее управление доступом, но и детализацию на уровне отдельных элементов модели данных. В частности, Cassandra обеспечивает доступ на уровне строк, а HBase – даже на уровне отдельных ячеек. При этом Кассандра позволяет определять роли пользователей, устанавливая для них условия видимости данных. В HBase, наоборот, администратор назначают метку видимости для наборов данных, в последствие распространяя их на группы пользователей и отдельных клиентов .
- Масштабируемость и отказоустойчивость – HBase и Cassandra линейно масштабируются, позволяя добавлять новые серверы и наращивать таким образом кластеры до сотни узлов. При этом обе системы гарантируют сохранность информации, даже при сбое отдельных узлов за счет репликации данных .
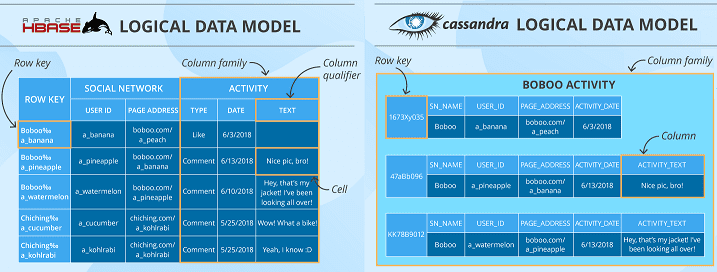 Сравнение моделей данных Apache Cassandra и HBase
Сравнение моделей данных Apache Cassandra и HBase
Что такое комплекс Кассандры
Комплекс или феномен Кассандры — это метафора для обозначения ситуации, где достоверное предсказание или предчувствие упускают из виду. В результате человек, как и мифическая Кассандра, не может убедить других в своей правоте и предотвратить негативное развитие событий.
В психологии комплексом Кассандры называют явление, когда человек постоянно испытывает недоверие окружающих.
В политике и бизнесе об эффекте Кассандры говорят, когда не получается использовать заранее полученную информацию о грядущих проблемах. Например, незадолго до 22 июня 1941 года в СССР проигнорировали отдельные сообщения о скором нападении нацистской Германии. Правильные предсказания затерялись среди других противоречивых донесений и не были приняты на веру.
Apache Cassandra
Cassandra is a NoSQL Column family implementation supporting the Big Table
data model using the architectural aspects introduced by Amazon Dynamo.
Some of the strong points of Cassandra are:
- Highly scalable and highly available with no single point of
failure - NoSQL column family implementation
- Very high write throughput and good read throughput
- SQL-like query language (since 0.8) and support search through
secondary indexes - Tunable consistency and support for replication
- Flexible schema
These positive points make it easy to recommend Cassandra, but it is
crucial for a developer to delve into the details and tricky points of
Cassandra to grasp the intricacies of this program.
Cassandra stores data according to the column family data model, depicted
in .
What is a Column?
Column is bit of a misnomer, and possibly the name
cell would have been easier to understand. I will stick
with column as that is the common usage.
Cassandra data model consists of columns, rows, column families, and
keyspace. Let’s look at each part in detail.
- Column – the most basic unit in the Cassandra data model, and each
column consists of a name, a value, and a timestamp. For this
discussion, ignore the timestamp, and then you can represent a column
as a name value pair (such as author=»Asimov»). - Row – a collection of columns labeled with a name. For example, shows how a row might be represented:
Listing 1. Example of a
rowCassandra
consists of many storage nodes and stores each row within a single
storage node. Within each row, Cassandra always stores columns
sorted by their column names. Using this sort order, Cassandra
supports slice queries where given a row, users can retrieve a
subset of its columns falling within a given column name range.
For example, a slice query with range tag0 to tag9999 will get all
the columns whose names fall between tag0 and tag9999. - Column family – a collection of rows labeled with a name. shows how sample data might look:
Listing 2. Example of a column
familyBooks->{ "Foundation"->{author="Asimov", publishedDate=".."}, "Second Foundation"->{author="Asimov", publishedDate=".."}, … }It
is often said that a column family is like a table in a relational
model. As shown in the following example, the similarities end
there. - Keyspace – a group of many column families together. It is only a
logical grouping of column families and provides an isolated scope for
names.
Finally, super columns reside within a column family that groups several
columns under a one key. As developers discourage the use of super
columns, I do not discuss them here.
NoSQL vs. Relational Database
The following table lists the points that differentiate a relational database from a NoSQL database.
| Relational Database | NoSql Database |
|---|---|
| Supports powerful query language. | Supports very simple query language. |
| It has a fixed schema. | No fixed schema. |
| Follows ACID (Atomicity, Consistency, Isolation, and Durability). | It is only “eventually consistent”. |
| Supports transactions. | Does not support transactions. |
Besides Cassandra, we have the following NoSQL databases that are quite popular −
-
Apache HBase − HBase is an open source, non-relational, distributed database modeled after Google’s BigTable and is written in Java. It is developed as a part of Apache Hadoop project and runs on top of HDFS, providing BigTable-like capabilities for Hadoop.
-
MongoDB − MongoDB is a cross-platform document-oriented database system that avoids using the traditional table-based relational database structure in favor of JSON-like documents with dynamic schemas making the integration of data in certain types of applications easier and faster.
Cassandra architecture
Having looked at the data model of Cassandra, let’s return to its
architecture to understand some of its strengths and weaknesses from a
distributed systems point of view.
shows the architecture of a Cassandra cluster.
The first observation is that Cassandra is a distributed system. Cassandra
consists of multiple nodes, and it distributes the data across those nodes
(or shards them, in the database terminology).
Figure 3. Cassandra cluster
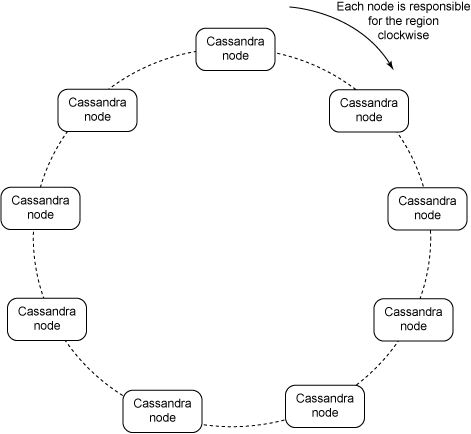
Cassandra uses consistent hashing to assign data items to nodes. In simple
terms, Cassandra uses a hash algorithm to calculate the hash for keys of
each data item stored in Cassandra (for example, column name, row ID). The
hash range or all possible hash values (also known as keyspace) is divided
among the nodes in the Cassandra cluster. Then Cassandra assigns each data
item to the node, and that node is responsible for storing and managing
the data item. The paper «Cassandra — A Decentralized Structured Storage
System» (see ) provides a
detailed discussion about Cassandra architecture.
The resulting architecture provides the following properties:
- Cassandra distributes data among its nodes transparently to the
users. Any node can accept any request (read, write, or delete) and
route it to the correct node even if the data is not stored in that
node. - Users can define how many replicas are needed, and Cassandra handles
replica creation and management transparently. - Tunable consistency: When storing and reading data, users can choose
the expected consistency level per each operation. For example, if the
«quorum» consistency level is used while writing or reading, data is
written and read from more than half of the nodes in the cluster.
Support for tunable consistency enables users to choose the
consistency level best suited to the use case. - Cassandra provides very fast writes, and they are actually faster
than reads where it can transfer data about 80-360MB/sec per node. It
achieves this using two techniques.- Cassandra keeps most of the data within memory at the
responsible node, and any updates are done in the memory and
written to the persistent storage (file system) in a lazy
fashion. To avoid losing data, however, Cassandra writes all
transactions to a commit log in the disk. Unlike updating data
items in the disk, writes to commit logs are append-only and,
therefore, avoid rotational delay while writing to the disk.
For more information on disk-drive performance
characteristics, see . - Unless writes have requested full consistency, Cassandra
writes data to enough nodes without resolving any data
inconsistencies where it resolves inconsistencies only at the
first read. This process is called «read repair.»
- Cassandra keeps most of the data within memory at the
The resulting architecture is highly scalable. You can build a Cassandra
cluster that has 10s of 100s of nodes that is capable of handling
terabytes to petabytes of data. There is a trade-off with distributed
systems, and scale almost never comes for free. As mentioned before, a
user might face many surprises moving from a relational database to
Cassandra. The next section discusses some of them.
В искусстве
Римская фреска из атриума Дома Менандра в Помпеях со сценой Кассандры у палладиума
Аякс оттаскивает Кассандру от статуи богини. Роспись килики ок. 440—430 годов до н. э. Лувр
Одна из сцен на ларце Кипсела показывала, как Аякс оттаскивает Кассандру от статуи Афины, и включала приводимую Павсанием стихотворную строку об этом. На картине Полигнота, находившейся в Дельфах, был изображён следующий эпизод: Аякс приносит присягу на жертвеннике, а Кассандра сидит на земле с ксоаном Афины, который держит в руках. Насилие Аякса над Кассандрой были также сюжетом картины Панэна, находившейся в Олимпии. Согласно Плинию, живописец Теор (или Теон; конец IV — начало III века до н. э.) создал картину «Кассандра», которую позднее можно было увидеть в римском храме Согласия. Поэт Христодор описал статую Кассандры, изображённой молчащей.
В литературе
Драматургия
Действующее лицо трагедии Эсхила «Агамемнон», трагедий Еврипида «Александр» и «Троянки», трагедии неизвестного автора «Кассандра», трагедии Акция «Клитемнестра», Сенеки «Агамемнон». Монодрама Ликофрона «Александра» почти целиком состоит из монолога пророчицы, загадочным языком предсказывающей грядущие события вплоть до походов Александра Великого.
- Трагедия Г. Эйленберга «Кассандра».
- Трагедия Леси Украинки «Кассандра».
- Трагедия П. Эрнста «Кассандра».
Поэзия
- Ф. Шиллер, баллада «Кассандра».
- В. К. Кюхельбекер, поэма «Кассандра».
- Мережковский, «Кассандра» (1922)
Переделки из Эсхила:
- А. Ф. Мерзляков, «Кассандра в чертогах Агамемнона».
- А. Н. Майков, «Кассандра».
Проза
- 1947 — повесть Ганса Эриха Носсака «Кассандра»
- 1984 (рус. 1988) — повесть Кристы Вольф «Кассандра (нем.)», где изложение ведётся от первого лица.
- 1986 — роман М. З. Брэдли «Головня (англ.)» (The Firebrand). В произведениях Вольф и Брэдли возлюбленным Кассандры выступает Эней.
- 2005 — роман Линдсея Кларка (англ.) «Возвращение из-под Трои».
- 2005—2007 — Трилогия Дэвида Геммела «Троя (англ.)».
- 2006 — повесть З. Юрьева «Рука Кассандры».
В.А. Жуковский.«Кассандра».
Произведения, использующие имя или образ Кассандры:
- 1978 — Рассказ Кэролайн Черри «Кассандра» (Cassandra)
- 1996 — Роман Чингиза Айтматова «Тавро Кассандры».
- 2007 — Мечта Кассандры (фильм).
- 2009 — роман Бернара Вербера «Зеркало Кассандры» (фр. Le Miroir de Cassandre)
- 2011 — Ю.Н. Вознесенская. Путь Кассандры, или Приключения с макаронами. Изд. «Лепта Книга»
В музыке
- 1982 — шведская группа ABBA записала песню «Cassandra», в которой главная героиня, жительница Трои, обращается к ней[уточнить]; песня на В-side их последнего сингла «The Day Before You Came»
- 1967 — Владимир Высоцкий «Песня о Вещей Кассандре»
- 1974 — сочинение английского композитора Брайана Фернихоу «Песнь сновидения (мечты) Кассандры»
- 1993 — сочинение Микаэля Жарреля «Кассандра»
- 1998 — альбом норвежской рок-группы Theatre of Tragedy «Aégis» начинается композицией «Cassandra»
- 2001 — песня немецкой группы Blind Guardian «And then there was Silence» о Кассандре, Троянской войне, гибели Гектора и разорении Трои
- 2008 — российская рок-группа Оригами выпустила альбом-пластинку «Синдром Кассандры» с одноимённой песней
- 2008 — российская рок-группа Би-2 выпустила сингл «Муза», в который вошла композиция с названием «Кассандра»
- 2015 — pyrokinesis «kassandra»
- 2020—Miyagi & Andy Panda — Кассандра (Kosandra)
В кинематографе
- 1253 — «Елена Троянская» Роберта Вайса; Кассандра — Джанетт Скотт
- 1961 — «Троянская война» Джорджо Феррони; Кассандра — Лидия Альфонси
- 1965 — В сериале «Доктор Кто» Кассандра появилась в эпизоде «Создатели мифов» (The Myth Makers)
- 1971 — «Троянки» Михалиса Какоянниса; Кассандра — Женевьев Бюжо
- 1995 — « 12 обезьян» Терри Гиллиама; упоминание комплекса Кассандры
- 2003 — мини-сериал «Елена Троянская» Джона Кента Харрисона; Кассандра — Эмилия Фокс
- 2018 — мини-сериал «Падение Трои»; Кассандра — Эйми-Фион Эдвардс
В честь Кассандры назван астероид (114) Кассандра, открытый 23 июля 1871 года германо-американским астрономом К. Г. Ф. Петерсом в Клинтоне, США
Modelo de Datos
Cassandra es esencialmente un híbrido entre un modelo Clave-Valor y una base de datos Tabular (Orientado a columnas).
La familia de columnas (llamada “Tabla” desde CQL3) se asemeja a una tabla en un RDBMS. Estas contienen filas y columnas. Cada fila tiene múltiples columnas, cada una de estas tiene a su vez un nombre, un valor y un timestamp. A diferencia de una tabla en un RDBMS, diferentes filas en una misma familia de columnas, no tiene por qué compartir el mismo conjunto de columnas, y además, una columna puede ser añadida a una o a múltiples filas en cualquier momento.
Cada clave en Cassandra, corresponde a un valor que es a su vez un objeto. Cada clave tiene valores como columnas, y las columnas son agrupadas en sets que son llamados familias de columnas. Así, cada clave identifica una fila con un número variable de elementos.
Estas familias de columnas, pueden ser consideradas como tablas. Una tabla en Cassandra es un mapa multi-dimensional distribuido, indexado por una clave. Además, las aplicaciones pueden especificar el orden de las columnas dentro de una Súper Columna, o una Familia de Columnas Simples.