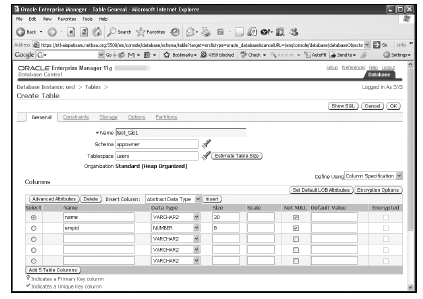
Большие данные: 70 невероятных бесплатных источников данных, которые вы должны знать к 2020 году
Содержание:
- Анализ тональности в русскоязычных текстах, часть 1: введение
- Что написано в Business Analysis Body of Knowledge: краткое содержание
- Анализ производительности запросов в ClickHouse. Доклад Яндекса
- ELK, SIEM из OpenSource, Open Distro: Оповещения (алерты)
- Как данные хранятся и обрабатываются?
- Производительность современной Java при работе с большим объёмом данных, часть 2
- Бенчмарк пакетного конвейера
- Принципы работы с большими данными
- Витрины данных DATA VAULT
- Чем отличается аналитик Big Data от исследователя данных
- С какими технологиями ассоциируется Big Data?
- Кто использует большие данные
- Как мы внедряли искусственный интеллект на металлургическом заводе
- Что такое большие данные
- История вопроса и определение термина
- Как ускорить разжатие LZ4 в ClickHouse
- Главные ИТ-тренды последних 10 лет в России и за рубежом
- Мониторинг производственного оборудования: как с этим дела в России
- На пути к индивидуальному образованию: анализ данных Яндекс.Репетитора
- Как мы организовали высокоэффективное и недорогое DataLake и почему именно так
- Профессиональные направления в мире Big Data
- Заметки Дата Сайентиста: персональный обзор языков запросов к данным
Анализ тональности в русскоязычных текстах, часть 1: введение
Анализ тональности стал мощным инструментом для масштабной обработки мнений, выражаемых в любых текстовых источниках. Практическое применение этого инструмента в английском языке довольно развито, чего не скажешь о русском. В этой серии статей мы рассмотрим, как и для каких целей применялись подходы анализа тональности для русскоязычных текстов, какие результаты удалось достичь, какие проблемы возникали, а также немного поговорим о перспективных направлениях. В отличие от предыдущих работ, я сосредоточился на прикладном применении, а не на самих подходах и их качестве классификации. Первая часть — вводная. Мы рассмотрим, что такое «анализ тональности», какой он бывает и как его за последние 8 лет применяли для анализа русскоязычных текстов. Во второй части (выйдет на следующей неделе) детально рассмотрим каждое из 32 основных исследований, которые мне удалось найти. В третьей и заключительной части (опять же, будет на следующей неделе) поговорим об общих сложностях, с которыми сталкивались исследователи, а также о перспективных направлениях на будущее.
Что написано в Business Analysis Body of Knowledge: краткое содержание
Вообще BABOK 3.0 состоит из 11 глав и 4-х приложений, суть которых состоит в следующем :
- в главах 1 и 2 изложены основные понятия бизнес-анализа, определение работы бизнес-аналитика, структура самого стандарта, базовые термины и ключевые концепции;
- главы 3-8 описывают области знаний бизнес-анализа;
- в главе 9 приведены основные профессиональные компетенции бизнес-аналитика, а в главе 10 –техники, наиболее часто используемые для решения прикладных задач;
- глава 11 рассказывает о перспективах, в рамках которых работает бизнес-аналитик;
- наконец, в приложениях приведен глоссарий терминов, картирование техник по задачам, список экспертов-разработчиков и отличия BABOK v3 от предыдущей версии.
В этой статье мы лишь частично раскроем ключевое содержание стандарта, оставив специфику профессиональных техник и компетенций для следующих публикаций
Важно, что в бизнес-анализе BABOK выделяет 6 областей знаний :
- Планирование и мониторинг бизнес-анализа (Business Analysis Planning and Monitoring) – задачи, необходимые для организации деятельности бизнес-аналитиков и координации их усилий;
- Обследование и взаимодействие (Elicitation and Collaboration) – задачи по подготовке и проведению обследования, а также утверждению результатов, в т.ч. взаимодействие с заинтересованными лицами (стейкхолдерами);
- Управление жизненным циклом требований (Requirements Life Cycle Management) – задачи по управлению и поддержке требований, а также технических проектов (дизайнов) от их возникновения до устаревания;
- Стратегический анализ (Strategy Analysis) – задачи по идентификации бизнес-потребностей, определению способов их удовлетворения и согласования стратегических изменений внутри предприятия;
- Анализ требований и определение дизайнов (Requirements Analysis and Design Definition) — задачи по организации требований и проектов, их определению и моделированию, проверке и подтверждению, разработке вариантов решения и оценки их потенциальной ценности, которая может быть достигнута.
- Оценка решений (Solution Evaluation) — задачи по оценке производительности и ценности решений, разработка рекомендаций по их улучшению.
Все эти работы бизнес-аналитик выполняет в рамках 5 перспектив :
- методологии гибкой разработки (Agile);
- интеллектуальный анализ данных для принятия бизнес-решений (Business Intelligence)
- информационные технологии (Information Technology);
- бизнес-архитектура (Business Architecture);
- управление бизнес-процессами (Business Process Management).
При этом бизнес-аналитик активно пользуется различными техниками системного анализа, управления данными, маркетинговых исследований и проектного менеджмента: структурные диаграммы для формализации процессов, стратегические карты, SWOT-квадранты, методы приоритезации, деревья решений и другие практические инструменты.
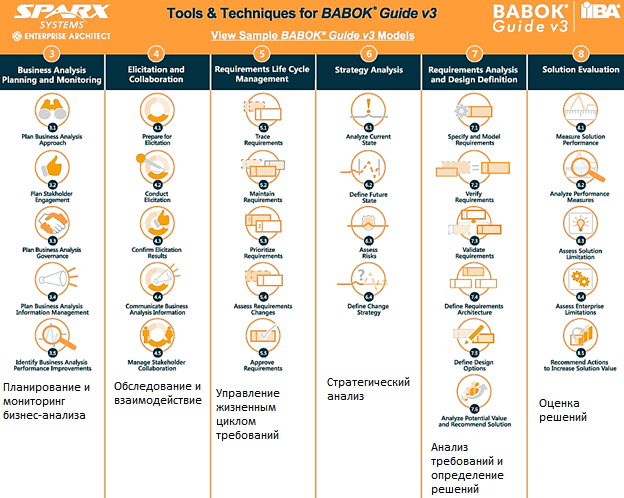 6 областей знаний BABOK и их основные задачи
6 областей знаний BABOK и их основные задачи
Анализ производительности запросов в ClickHouse. Доклад Яндекса
Что делать, если ваш запрос к базе выполняется недостаточно быстро? Как узнать, оптимально ли запрос использует вычислительные ресурсы или его можно ускорить? На последней конференции HighLoad++ в Москве я рассказал об интроспекции производительности запросов — и о том, что даёт СУБД ClickHouse, и о возможностях ОС, которые должны быть известны каждому.
Каждый раз, когда я делаю запрос, меня волнует не только результат, но и то, что этот запрос делает. Например, он работает одну секунду. Много это или мало? Я всегда думаю: а почему не полсекунды? Потом что-нибудь оптимизирую, ускоряю, и он работает 10 мс. Обычно я доволен. Но все-таки я стараюсь в этом случае сделать недовольное выражение лица и спросить: «Почему не 5 мс?» Как можно выяснить, на что тратится время при обработке запроса? Можно ли его в принципе ускорить?
ELK, SIEM из OpenSource, Open Distro: Оповещения (алерты)
Перевод
Здравствуйте и добро пожаловать в нашу новую статью, в которой будет рассказано об оповещениях (алертах) в нашем решении SOCaaS. Как вы все знаете, предупреждения в любом SOC играют жизненно важную роль при уведомлении группы реагирования.
Они могут прервать цепочку кибер-атак или отслеживать эту атаку, в зависимости от политики предприятия и команды. Вы, наверное, задаетесь вопросом, зачем нам нужно включать больше предупреждений. Разве модулей предупреждений Open Distro недостаточно? Это потому, что ему не хватает количества выходов и его интегрируемости с остальной частью нашего решения, например Thehive. Мы познакомим вас с другой альтернативой.
Как данные хранятся и обрабатываются?
Объемы данных растут быстрыми темпами, и для того чтобы их обработать, используются распределённые хранилища и программы. С увеличением количества данных можно просто добавлять новые узлы, а не переписывать текущее решение заново. Ниже в статье будет информация об инструментах, которые используются для работы с Big Data.
Важен вопрос о безопасном хранении данных. Из-за активного развития больших данных и отсутствия устоявшихся методологий по их защите, каждая компания должна сама решить, как подойти к решению этого вопроса.
Разумным шагом будет удалить из кластера конфиденциальные данные вроде паролей и данных банковских карт, это упростит настройку доступа к нему. Далее можно применять различные административные, физические и технические меры обеспечения защиты, требования к которым можно найти в разных сборниках стандартов вроде ISO 27001. Например, можно ограничить сотрудникам доступ к данным до уровня, которого достаточно для выполнения их рабочих задач. Не будет лишним вести логи взаимодействия сотрудника с данными и исключить возможность копирования данных из хранилища. Также можно использовать анонимизацию данных.
4
Производительность современной Java при работе с большим объёмом данных, часть 2
Перевод
FYI: Первая часть.
Бенчмарк пакетного конвейера
Пакетный конвейер обрабатывает конечный объём сохранённых данных. Здесь нет потока результатов обработки, выходные данные агрегирующей функции нужно применить ко всему набору данных. Это меняет требования к производительности: задержка — ключевой фактор при потоковой обработке — здесь отсутствует, потому что мы обрабатываем данные не в реальном времени. Единственная важная метрика — общее время работы конвейера.
Поэтому мы выбрали Parallel. На первом этапе тестирования, при работе на одной ноде, этот сборщик действительно показал лучшую пропускную способность (но только после настройки). Однако это было получено ценой длительных пауз. Если одна из нод кластера останавливается на сборку мусора, это стопорит весь конвейер. А поскольку ноды собирают мусор в разное время, общее время сборки увеличивается с добавлением каждой ноды к кластеру. Мы проанализировали этот эффект, сравнив результаты тестирования на одной ноде и на кластере из трёх нод.
Кроме того, на этом этапе мы не рассматривали экспериментальные сборщики с низкой задержкой. Их очень короткие паузы не влияют на результаты тестирования, к тому же это достигается за счёт пропускной способности.
Принципы работы с большими данными
Исходя из определения Big Data, можно сформулировать основные принципы работы с такими данными:
1. Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать.
2. Отказоустойчивость. Принцип горизонтальной масштабируемости подразумевает, что машин в кластере может быть много. Например, Hadoop-кластер Yahoo имеет более 42000 машин (по этой ссылке можно посмотреть размеры кластера в разных организациях). Это означает, что часть этих машин будет гарантированно выходить из строя. Методы работы с большими данными должны учитывать возможность таких сбоев и переживать их без каких-либо значимых последствий.
3. Локальность данных. В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом – расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
Все современные средства работы с большими данными так или иначе следуют этим трём принципам. Для того, чтобы им следовать – необходимо придумывать какие-то методы, способы и парадигмы разработки средств разработки данных. Один из самых классических методов я разберу в сегодняшней статье.
Витрины данных DATA VAULT
В предыдущих статьях, мы познакомились с основами DATA VAULT, расширением DATA VAULT до более подходящего для анализа состояния и созданием BUSINESS DATA VAULT. Настало время завершать серию третьей статьей.
Как я анонсировал в предыдущей публикации, эта статья будет посвящена теме BI, а точнее подготовке DATA VAULT в качестве источника данных для BI. Рассмотрим, как создать таблицы фактов и измерений и, тем самым, создать схему звезда.
Когда я начал изучать англоязычные материалы по теме создания витрин данных над DATA VAULT у меня возникло ощущение достаточной сложности процесса
Так как статьи имеют внушительный объем, там присутствуют отсылки к изменениям в формулировках, появившихся в методологии Data Vault 2.0, обозначается важность этих формулировок. Однако, углубившись в перевод, стало понятно, что процесс этот не так уж и сложен
Но, возможно у вас сложится другое мнение.
И так, давайте переходить к сути.
Чем отличается аналитик Big Data от исследователя данных
На первый взгляд может показаться, что Data Scientist ничем не отличается от Data Analyst, ведь их рабочие обязанности и профессиональные компетенции частично пересекаются. Однако, это не совсем взаимозаменяемые специальности. При значительном сходстве, отличия между ними также весьма существенные:
- по инструментарию — аналитик чаще всего работает с ETL-хранилищами и витринами данных, тогда как исследователь взаимодействует с Big Data системами хранения и обработки информации (стек Apache Hadoop, NoSQL-базы данных и т.д.), а также статистическими пакетами (R-studio, Matlab и пр.);
- по методам исследований – Data Analyst чаще использует методы системного анализа и бизнес-аналитики, тогда как Data Scientist, в основном, работает с математическими средствами Computer Science (модели и алгоритмы машинного обучения, а также другие разделы искусственного интеллекта);
- по зарплате – на рынке труда Data Scientist стоит чуть выше, чем Data Analyst (100-200 т.р. против 80-150 т.р., по данным рекрутингового портала HeadHunter в августе 2019 г.). Возможно, это связано с более высоким порогом входа в профессию: исследователь по данным обладает навыками программирования, тогда как Data Analyst, в основном, работает с уже готовыми SQL/ETL-средствами.
На практике в некоторых компаниях всю работу по данным, включая бизнес-аналитику и построение моделей Machine Learning выполняет один и тот же человек. Однако, в связи с популярностью T-модели компетенций ИТ-специалиста, при наличии широкого круга профессиональных знаний и умений предполагается экспертная концентрация в узкой предметной области. Поэтому сегодня все больше компаний стремятся разделять обязанности Data Analyst и Data Scientist, а также инженера по данным (Data Engineer) и администратора Big Data, о чем мы расскажем в следующих статьях.
 Data Scientist — одна из самых востребованных профессий на современном ИТ-рынке
Data Scientist — одна из самых востребованных профессий на современном ИТ-рынке
В области Big Data ученому по данным пригодятся практические знания по облачным вычислениям и инструментам машинного обучения. Эти и другие вопросы по исследованию данных мы рассматриваем на наших курсах обучения и повышения квалификации ИТ-специалистов в лицензированном учебном центре для руководителей, аналитиков, архитекторов, инженеров и исследователей Big Data в Москве:
- PYML: Машинное обучение на Python
- DPREP: Подготовка данных для Data Mining
- DSML: Машинное обучение в R
- DSAV: Анализ данных и визуализация в R
- AZURE: Машинное обучение на Microsoft Azure
Смотреть расписание
Записаться на курс
С какими технологиями ассоциируется Big Data?
Технологии, применяемые при работе с большими данными, можно условно разбить на три большие группы: для анализа данных (A/B-тестирование, проверка гипотез, машинное обучение), для сбора и хранения данных («облака», базы данных) и для представления результатов (таблицы, графики и так далее). Вот примеры некоторых из них.
Анализ данных
- Apache Spark. Фреймворк с открытым исходным кодом для реализации распределённой обработки данных, входящий в экосистему Hadoop.
- Elasticsearch. Популярный открытый поисковый движок, часто используемый при работе с большими данными.
- Scikit-learn. Бесплатная библиотека машинного обучения для языка программирования Python.
Сбор и хранение
- Apache Hadoop. Фреймворк, который нельзя не упомянуть при разговоре о Big Data. Он позволяет обеспечивать работу распределённых программ на кластерах из сотен и тысяч узлов.
- Apache Ranger. Фреймворк для обеспечения безопасности данных в Hadoop.
- NoSQL базы данных. HBase, Apache Cassandra и другие базы данных, рассчитанные на создание высокомасштабируемых и надёжных хранилищ огромных массивов данных.
- Озёра данных (data lakes). Неструктурированные хранилища для большого количества «сырых» данных, не подвергающихся каким-либо изменениям перед сохранением.
- In-memory базы данных. Например, в Redis данные хранятся в оперативной памяти.
Визуализация
- Google Chart. Многофункциональный набор инструментов для визуализации данных.
- Tableau. Система интерактивной аналитики, позволяющая быстро провести анализ больших массивов информации.
12
Кто использует большие данные

Наибольший прогресс отрасли наблюдается в США и Европе. Вот крупнейшие иностранные компании и ведомства, которые используют Big Data:
• HSBC повышает безопасность клиентов пластиковых карт. Компания утверждает, что в 10 раз улучшила распознавание мошеннических операций и в 3 раза – защиту от мошенничества в целом.
• Суперкомпьютер Watson, разработанный IBM, анализирует финансовые транзакции в режиме реального времени. Это позволяет сократить частоту ложных срабатываний системы безопасности на 50% и выявить на 15% больше мошеннических действий.
• Procter&Gamble проводит с использованием Big Data маркетинговые исследования, более точно прогнозируя желания клиентов и спрос новых продуктов.
• Министерство труда Германии добивается целевого расхода средств, анализируя большие данные при обработке заявок на пособия. Это помогает направить деньги тем, кто действительно в них нуждается (оказалось, что 20% пособий выплачивались нецелесообразно). Министерство утверждает, что инструменты Big Data сокращают затраты на €10 млрд.
Среди российских компаний стоит отметить следующие:
• Яндекс. Это корпорация, которая управляет одним из самых популярных поисковиков и делает цифровые продукты едва ли не для каждой сферы жизни. Для Яндекс Big Data – не инновация, а обязанность, продиктованная собственными нуждами. В компании работают алгоритмы таргетинга рекламы, прогноза пробок, оптимизации поисковой выдачи, музыкальных рекомендаций, фильтрации спама.
• Мегафон
Телекоммуникационный гигант обратил внимание на большие данные примерно пять лет назад. Работа над геоаналитикой привела к созданию готовых решений анализа пассажироперевозок
В этой области у Мегафон есть сотрудничество с РЖД.
• Билайн. Этот мобильный оператор анализирует массивы информации для борьбы со спамом и мошенничеством, оптимизации линейки продуктов, прогнозирования проблем у клиентов. Известно, что корпорация сотрудничает с банками – оператор помогает анонимно оценивать кредитоспособность абонентов.
• Сбербанк. В крупнейшем банке России супермассивы анализируются для оптимизации затрат, грамотного управления рисками, борьбы с мошенничеством, а также расчёта премий и бонусов для сотрудников. Похожие задачи с помощью Big Data решают конкуренты: Альфа-банк, ВТБ24, Тинькофф-банк, Газпромбанк.
И за границей, и в России организации в основном пользуются сторонними разработками, а не создают инструменты для Big Data сами. В этой сфере популярны технологии Oracle, Teradata, SAS, Impala, Apache, Zettaset, IBM, Vowpal.
Читайте: Что такое интернет вещей, как он работает и чем полезен
Как мы внедряли искусственный интеллект на металлургическом заводе
Технотекст 2020
Искусственный интеллект в промышленности
Часто люди, работающие в области технологий искусственного интеллекта, представляют себе металлургический завод как нечто монструозное по форме и консервативное по внутренним процессам – примерно так, как описано в романе 1901 года «Труд» Эмиля Золя: «…окутанный клубами белого пылавшего в электрических лучах дыма, завод казался грозным видением. Порой сквозь широко раскрытые двери видны были огненные пасти плавильных печей, слепящие потоки расплавленного металла, огромные багровые очаги – все пламя этого потаенного ада, этого алчного, бушующего мира, порожденного чудовищем». Надо сказать, мои начальные представления о металлургическом производстве были такими же метафоричными.
Погрузившись в актуальные проблемы настоящего металлургического завода, я сформировал представление о реальном положении вещей.
Для любого металлургического производства одной из самых актуальных проблем является снижение себестоимости продукции без потери качества или с его повышением. Те подходы к решению проблем, которые использовались на протяжении десятков лет – капитальный ремонт оборудования или техническое перевооружение – очень дорогие, долгие и не всегда приносят ожидаемого эффекта.
Что такое большие данные

Большие данные – современное технологическое направление, связанное с обработкой крупных массивов данных, которые постоянно растут. Big Data – это сама информация, методы её обработки и аналитики. Перспективы, которые может принести Big Data интересны бизнесу, маркетингу, науке и государству.
В первую очередь большие данные – это всё-таки информация. Настолько большая, что ей сложно оперировать с помощью обычных программных средств. Она бывает структурированной (обработанной), и неструктурированной (разрозненной). Вот некоторые её примеры:
• Данные с сейсмологических станций по всей Земле.
• База пользовательских аккаунтов Facebook.
• Геолокационная информация всех фотографий, выложенных за сегодня в Instagram.
• Базы данных операторов мобильной связи.
Для Big Data разрабатываются свои алгоритмы, программные инструменты и даже машины. Чтобы придумать средство обработки, постоянно растущей информации, необходимо создавать новые, инновационные решения. Именно поэтому большие данные стали отдельным направлением в технологической сфере.
История вопроса и определение термина
Термин Big Data появился сравнительно недавно. Google Trends показывает начало активного роста употребления словосочетания начиная с 2011 года (ссылка):
При этом уже сейчас термин не использует только ленивый. Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и освятить вопрос – необходимо определиться с понятием.
В своей практике я встречался с разными определениями:
· Big Data – это когда данных больше, чем 100Гб (500Гб, 1ТБ, кому что нравится)
· Big Data – это такие данные, которые невозможно обрабатывать в Excel
· Big Data – это такие данные, которые невозможно обработать на одном компьютере
И даже такие:
· Вig Data – это вообще любые данные.
· Big Data не существует, ее придумали маркетологи.
В этом цикле статей я буду придерживаться определения с wikipedia:
Большие данные (англ. big data) — серия подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети, сформировавшихся в конце 2000-х годов, альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence.
Таким образом под Big Data я буду понимать не какой-то конкретный объём данных и даже не сами данные, а методы их обработки, которые позволяют распредёлено обрабатывать информацию. Эти методы можно применить как к огромным массивам данных (таким как содержание всех страниц в интернете), так и к маленьким (таким как содержимое этой статьи).
Приведу несколько примеров того, что может быть источником данных, для которых необходимы методы работы с большими данными:
· Логи поведения пользователей в интернете
· GPS-сигналы от автомобилей для транспортной компании
· Данные, снимаемые с датчиков в большом адронном коллайдере
· Оцифрованные книги в Российской Государственной Библиотеке
· Информация о транзакциях всех клиентов банка
· Информация о всех покупках в крупной ритейл сети и т.д.
Количество источников данных стремительно растёт, а значит технологии их обработки становятся всё более востребованными.
Как ускорить разжатие LZ4 в ClickHouse
При выполнении запросов в ClickHouse можно обратить внимание, что в профайлере на одном из первых мест часто видна функция LZ_decompress_fast. Почему так происходит? Этот вопрос стал поводом для целого исследования по выбору лучшего алгоритма разжатия
Здесь я публикую исследование целиком, а короткую версию можно узнать из моего доклада на HighLoad++ Siberia.
Данные в ClickHouse хранятся в сжатом виде. А во время выполнения запросов ClickHouse старается почти ничего не делать — использовать минимум ресурсов CPU. Бывает, что все вычисления, на которые могло тратиться время, уже хорошо оптимизированы, да и запрос хорошо написан пользователем. Тогда остаётся выполнить разжатие.
Вопрос — почему разжатие LZ4 может быть узким местом? Казалось бы, LZ4 — очень лёгкий алгоритм: скорость разжатия, в зависимости от данных, обычно составляет от 1 до 3 ГБ/с на одно процессорное ядро. Это уже существенно больше скорости работы дисковой подсистемы. Более того, мы используем все доступные ядра, а разжатие линейно масштабируется по всем физическим ядрам.
Главные ИТ-тренды последних 10 лет в России и за рубежом
В первое 10-летие 21 века облачные вычисления (Cloud Computing) и основанные на них SaaS/PaaS/IaaS-решения успешно заняли свое место в ландшафте корпоративной инфраструктуры. NoSQL-СУБД, BI-системы и технологии контейнеризации (виртуализации) перестали быть игрушкой для гиков и активно используются как крупными игроками, так и малым бизнесом. IP-телефония, онлайн ERP- и CRM-продукты с модулями предиктивной аналитики – это must-have любого предприятия. На место локальных решений приходят облачные сервисы, а ИТ-гиганты открывают исходные коды своих программ, поддерживая свободное ПО и получая прибыль с коммерческих консультаций и заказных разработок.
2010-е можно по праву назвать эпохой Больших Данных (Big Data), как наиболее обсуждаемой темой в мире ИТ. Вместе с интернетом вещей (Internet of Things), цифровизацией, искусственным интеллектом и машинным обучением (Machine Learning, ML), технологии Big Data считаются основой 4-ой промышленной революции (Industry 4.0, I4.0).
Напомним, суть I4.0 состоит в объединении данных, инструментов и процессов из разных прикладных областей с целью сокращения общих затрат, снижения рисков и повышения эффективности производства и других сфер человеческой жизни с помощью киберфизических систем. Однако, любые технологии, в т.ч. Big Data (Hadoop, Kafka, Spark, Cassandra, NiFi, HBase и пр.) – это всего лишь инструменты оптимизации прикладной деятельности. Сегодня, когда искусственный интеллект активно внедряется в жизнь, заменяя людей в выполнении рутинных операций и быстрой обработке огромных объемов информации, выигрывает не тот, кто быстро решает типовые задачи, а тот, кто придумывает новые.
Проанализировав популярность наиболее известных технологий I4.0 с помощью Google Trends, можно сделать выводы, что во всем мире за последние 10 лет сформировался устойчивый интерес к следующим ИТ-понятиям:
- Большие данные, как на уровне технологий (Apache Hadoop, Kafka, Spark, HBase, Cassandra и другие NoSQL-СУБД, Java, R, Python и другие языки программирования для разработки Big Data приложений), так и практические примеры использования всех этих инструментов в прикладных областях (от маркетинга до нефтегазовой промышленности).
- Data Science, включая анализ данных, машинное обучение (Machine Learning) и другие методы искусственного интеллекта, направленные на извлечение полезных для бизнеса сведений из огромных объемов информации, распознавание образов и прогнозирование событий.
- Agile-подходы к организации совместной работы, перешедшие из ИТ-сферы в разряд лучших практик управления проектами для любой области деятельности.
- Интернет вещей (Internet Of Things, IoT), в т.ч. промышленный (Industrial IoT, IIoT), в рамках которого все больше устройств оснащаются Wi-Fi-модулями, запускаются 5G-сети, дроны летают все быстрее, дома и города становятся умнее, а каждое производственное предприятие стремится стать data-driven компанией.
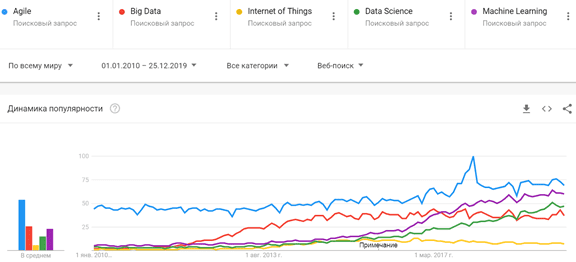 Главные ИТ-тренды мира 2019-2020
Главные ИТ-тренды мира 2019-2020
Россия не отстает от мировых тенденций, однако, наряду к вышеуказанным терминам, в нашей стране также существенно возрос интерес к цифровизации. Сегодня тема цифровой трансформации захватила почти все отечественные индустрии, от банков до рекламы. Однако, чтобы цифровизация не стала очередным модным словом (buzzword), за фасадом которого старые проблемы так и останутся нерешенными, необходимо четко понимать, чем именно она выгодна бизнесу. Эффективное применение Big Data, Machine Learning, IoT и других технологий Industry 4.0 реализуемо только при условии адекватного понимания возможностей этих инструментов у руководителей предприятий, менеджеров и прочих лиц, принимающих решения. Вероятнее всего, демистификация терминов Big Data, Data Science, Machine Learning, IoT и станет главным трендом наступившего года.
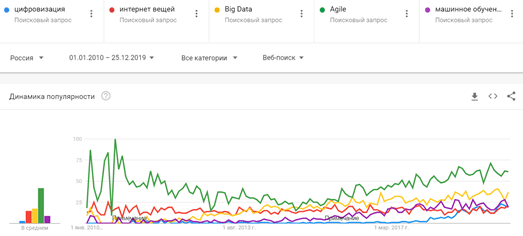 Самые популярные ИТ-тренды в России 2019-2020
Самые популярные ИТ-тренды в России 2019-2020
Мониторинг производственного оборудования: как с этим дела в России
Recovery Mode
Привет, Хабр! Наша команда занимается мониторингом станков и разных установок по всей стране. По сути, мы обеспечиваем возможность производителю не гонять лишний раз инженера, когда «ой, оно всё сломалось», а на деле надо нажать одну кнопку. Или когда сломалось не на оборудовании, а рядом.
Базовая проблема следующая. Вот вы производите установку для крекинга нефти, либо станок для машиностроения, либо какое-то другое устройство для завода. Как правило, продажа сама по себе крайне редко возможна: обычно это контракт на поставку и обслуживание. То есть вы гарантируете, что железяка будет работать лет 10 без перебоев, а за перебои отвечаете либо финансово, либо обеспечиваете жёсткие SLA, либо что-то подобное.
По факту это означает, что вам нужно регулярно отправлять инженера на объект. Как показывает наша практика, от 30 до 80 % выездов — лишние. Первый случай — можно было бы разобраться, что случилось, удалённо. Либо попросить оператора нажать пару кнопок — и всё заработает. Второй случай — «серые» схемы. Это когда инженер выезжает, ставит в регламент замену или сложные работы, а сам делит компенсацию пополам с кем-то с завода. Или просто наслаждается отдыхом с любовницей (реальный случай) и поэтому любит выезжать почаще. Завод не против.
Установка мониторинга требует модификации железа устройством передачи данных, самой передачи, какого-то озера данных для их накопления, разбора протоколов и среды обработки с возможностью всё посмотреть и сопоставить. Ну и с этим всем есть нюансы.
На пути к индивидуальному образованию: анализ данных Яндекс.Репетитора
Наверняка почти каждый мечтает о персонализированном образовании: двигаться к своей образовательной цели максимально коротким путём, решать только те задачи, состав и сложность которых подстраиваются под тебя, с пользой проводить любой отрезок времени независимо от длительности и структуры
Неважно, будь то пятиминутный перерыв от работы или ежевечерние занятия на протяжении месяцев
Такой инструмент позволил бы экономить огромное количество времени и при этом добиваться значительно лучших результатов. Эффективность обмена знаниями значительно повысилась бы, а вслед за этим ускорился бы и прогресс.
Но пока человечество совершает лишь робкие попытки подобраться к пониманию, как создавать такой инструмент. Свою попытку осуществила и команда Яндекс.Репетитора. Сервис, запущенный менее двух лет назад, накопил данные о ста миллионах решений различных задач, и этого достаточно для интересной аналитики. Понятно, что образование состоит не только из задач, но сегодня мы сфокусируемся на них.
В статье я расскажу, какую аналитику мы научились строить на базе собранных данных и благодаря каким свойствам сервиса она оказывается возможной. В самом конце вас ждёт небольшой отчёт о нашей первой попытке построить сервис для персонализированного образования и о результатах этого эксперимента.
Как мы организовали высокоэффективное и недорогое DataLake и почему именно так
Мы живем в удивительное время, когда можно быстро и просто состыковать несколько готовых открытых инструментов, настроить их с «отключенным сознанием» по советам stackoverflow, не вникая в «многобукв», запустить в коммерческую эксплуатацию. А когда нужно будет обновляться/расширяться или кто-то случайно перезагрузит пару машин — осознать, что начался какой-то навязчивый дурной сон наяву, все резко усложнилось до неузнаваемости, пути назад нет, будущее туманно и безопаснее, вместо программирования, разводить пчел и делать сыр.
Не зря же, более опытные коллеги, с посыпанной багами и от этого уже седой головой, созерцая неправдоподобно быстрое развертывание пачек «контейнеров» в «кубиках» на десятках серверов на «модных языках» со встроенной поддержкой асинхронно-неблокирующего ввода-вывода — скромно улыбаются. И молча продолжают перечитывать «man ps», вникают до кровоточения из глаз в исходники «nginx» и пишут-пишут-пишут юнит-тесты. Коллеги знают, что самое интересное будет впереди, когда «всё это» однажды станет ночью колом под Новый год. И им поможет только глубокое понимание природы unix, заученной таблицы состояний TCP/IP и базовых алгоритмов сортировки-поиска. Чтобы под бой курантов возвращать систему к жизни.
Профессиональные направления в мире Big Data
Под термином «большие данные» скрывается множество понятий: от непосредственно самих информационных массивов до технологий по их сбору, обработке, анализу и хранению. Поэтому, прежде чем пытаться объять необъятное в стремлении изучить все, что относится к Big Data, выделим в этой области знаний следующие направления:
- инженерия – создание, настройка и поддержка программно-аппаратной инфраструктуры для систем сбора, обработки, аналитики и хранения информационных потоков и массивов, включая конфигурирование локальных и облачных кластеров. За эти процессы отвечают администратор и инженер Big Data. Чем отличается работа администратора больших данных от деятельности сисадмина, мы писали в этом материале. Какие именно навыки, знания и умения нужны специалистам по инженерии больших данных, а также сколько они за это получают, мы описываем в отдельных материалах.
На стыке вышеуказанных 2-х направлений находятся программист Big Data и DevOps-инженер, а также специалист по сопровождению жизненного цикла корпоративных данных (DataOps) и директор по данным (CDO, Chief Data Officer), который курирует на предприятии все вопросы, связанные с информацией. О роли каждого профессионала в Agile-команде мы немного рассказывали здесь.
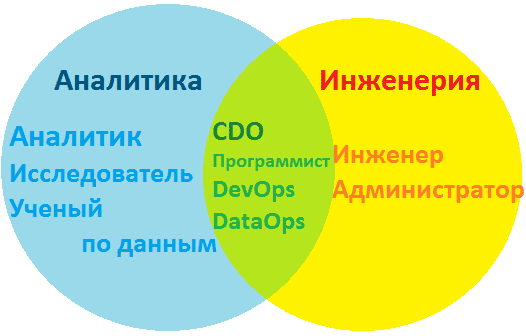 Профессиональные направления и специальности Big Data
Профессиональные направления и специальности Big Data
Заметки Дата Сайентиста: персональный обзор языков запросов к данным
Рассказываю из личного опыта, что где и когда пригодилось
Обзорно и тезисно, чтобы понятно было, что и куда можно копать дальше — но тут у меня исключительно субъективный личный опыт, у вас, может быть, все совсем по-другому.
Почему важно знать и уметь обращаться с языками запросов? По своей сути в Data Science есть несколько важнейших этапов работы и самый первый и важнейший (без него уж точно ничего работать не будет!) — это получение или извлечение данных. Чаще всего данные в каком-то виде где-то сидят и их нужно оттуда «достать».
Языки запросов как раз и позволяют эти самые данные извлечь! И сегодня я расскажу, о тех языках запросов, которые мне пригодились и расскажу-покажу, где и как именно — зачем оно нужно для изучения.
Всего будет три основных блока типов запросов к данным, которые мы разберем в данной статье:
- «Стандартные» языки запросов — то, что обычно понимают, когда говорят о языке запросов, как, например, реляционная алгебра или SQL.
- Скриптовые языки запросов: например, питоновские штучки pandas, numpy или shell scripting.
- Языки запросов к графам знаний и графовым базам данных.
Все написанное здесь — это просто персональный опыт, что пригодилось, с описанием ситуаций и «зачем оно было нужно» — каждый может примерить, насколько подобные ситуации могут встретиться вам и попробовать подготовиться к ним заранее, разобравшись с этими языками до того, как придется их в (срочном порядке) применять на проекте или вообще попасть на проект, где они нужны.