5 вопросов по sql, которые часто задают дата-сайентистам на собеседованиях
Содержание:
Альтернатива
Следует различать альтернативы SQL как языка и как альтернативу самой реляционной модели. Ниже предлагаются реляционные альтернативы языку SQL.
См. Навигационную базу данных и NoSQL для альтернатив реляционной модели.
- .QL: Объектно-ориентированный Datalog
- 4D Query Language (4D QL)
- Datalog: Критики предполагают, что Datalog имеет два преимущества перед SQL: он имеет более понятную семантику, что облегчает понимание и обслуживание программ, и это более выразительно, в частности, для рекурсивных запросов.
- HTSQL: Метод запросов на основе URL
- IBM Business System 12 (IBM BS12): Одна из первых полностью реляционных систем управления базами данных, введенная в 1982 году
- ISBL
- jOOQ: SQL, реализованный на Java как внутренний язык, специфичный для домена
- Java Persistence Query Language (JPQL): Язык запросов, используемый API Java Persistence и библиотеку персистентности вспящем режиме
- LINQ: Запускает операторы SQL, написанные как языковые конструкции, для запроса коллекций непосредственно изнутри кода .Net.
- Object Query Language
- QBE (Query By Example), созданный Moshè Zloof, IBM в 1977
- Quel Введенный в 1974 U.C. Berkeley.
- Tutorial D
- XQuery
Инструкция SHOW
Как узнать содержимое той или иной базы данных? Или содержимое конкретной таблицы? Для этого используется инструкция .
Этот полезный инструмент позволяет отслеживать содержимое баз данных, показывать структуру их таблиц.
SHOW DATABASES
Например, команда выводит список баз данных, которые находятся под управлением конкретного сервера.

На протяжении всего курса статей мы будем использовать движок MySQL и работать с обычным терминалом Linux для выполнения SQL запросов.
Самый простой способ создания сервера MySQL — установить бесплатные инструменты, такие как XAMPP или WAMP, которые включают в себя все необходимые утилиты. Но так же можно установить всё вручную.
SHOW TABLES
Для того, чтобы посмотреть все доступные таблицы в выбранной базе данных, используется команда . Она нужна для отображения всех таблиц в текущей выбранной базе данных MySQL.

SHOW COLUMNS
отображает информацию о столбцах в данной таблице.
В следующем примере показаны столбцы в таблице wp_comments:

отображает следующие значения для каждого столбца таблицы:
- Field: имя столбца
- Type: тип данных столбца
- Key: указывает, индексирован ли столбец
- Default: значение по умолчанию для столбца
- Extra: может содержать любую дополнительную информацию о данном столбце
Столбцы для таблицы wp_comments были автоматически созданы WordPress, как и вся база данных моего сайта.
Распределенная обработка SQL
Архитектура распределенной реляционной базы данных (DRDA) была разработана рабочей группой в IBM в период с 1988 по 1994 год. DRDA позволяет связанным с сетью реляционным базам данных взаимодействовать для выполнения запросов SQL.
Интерактивный пользователь или программа может выдавать SQL-запросы локальному RDB и получать таблицы данных и индикаторы состояния в ответ от удаленных RDB. Операторы SQL также могут быть скомпилированы и сохранены в удаленных RDB как пакеты, а затем вызваны именем этого пакета
Это важно для эффективной работы прикладных программ, которые вызывают сложные высокочастотные запросы. Это особенно важно, когда доступ к таблицам находится в удаленных системах.
Сообщения, протоколы и структурные компоненты DRDA определяются архитектурой распределенного управления данными.
PARTITION BY и LAG, LEAD и RANK
PARTITION BY позволяет сгруппировать строки по значению определённого столбца. Это полезно, если данные логически делятся на какие-то категории и нужно что-то сделать с данной строкой с учётом других строк той же группы (скажем, сравнить теннисиста с остальными теннисистами, но не с бегунами или пловцами). Этот оператор работает только с оконными функциями типа LAG, LEAD, RANK и т. д.
LAG
Функция LAG берёт строку и возвращает ту, которая шла перед ней. Например, мы хотим найти всех олимпийских чемпионов по теннису (мужчин и женщин отдельно), начиная с 2004 года, и для каждого из них выяснить, кто был предыдущим чемпионом.
Решение этой задачи требует нескольких шагов. Сначала надо создать табличное выражение, которое сохранит результат запроса «чемпионы по теннису с 2004 года» как временную именованную структуру для дальнейшего анализа. А затем разделить их по полу и выбрать предыдущего чемпиона с помощью LAG:
Функция PARTITION BY в таблице вернула сначала всех мужчин, потом всех женщин. Для победителей 2008 и 2012 года приведён предыдущий чемпион; так как данные есть только за 3 олимпиады, у чемпионов 2004 года нет предшественников, поэтому в соответствующих полях стоит null.
LEAD
Функция LEAD похожа на LAG, но вместо предыдущей строки возвращает следующую. Можно узнать, кто стал следующим чемпионом после того или иного спортсмена:
RANK
Оператор RANK похож на ROW_NUMBER, но присваивает одинаковые номера строкам с одинаковыми значениями, а «лишние» номера пропускает. Есть также DENSE_RANK, который не пропускает номеров. Звучит запутанно, так что проще показать на примере. Вот ранжирование стран по числу олимпиад, в которых они участвовали, разными операторами:
- Row_number — ничего интересного, строки просто пронумерованы по возрастанию.
- Rank_number — строки ранжированы по возрастанию, но нет номера 3. Вместо этого, 2 строки делят номер 2, а за ними сразу идёт номер 4.
- Dense_rank — то же самое, что и rank_number, но номер 3 не пропущен. Номера идут подряд, но зато никто не оказался пятым из пяти.
Вот код:
SQL References
SQL Keywords
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
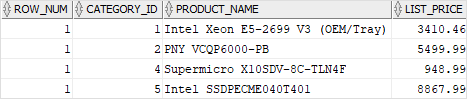
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Functions
String Functions
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Numeric Functions
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Date Functions
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Advanced Functions
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server Functions
String Functions
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Numeric Functions
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Date Functions
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Advanced Functions
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access Functions
String Functions
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Numeric Functions
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Date Functions
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Other Functions
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL OperatorsSQL Data TypesSQL Quick Ref
Time Complexity и Big O
Обратите вниманиеОднако следует отметить
Linear Time: O(n)
- Соединение хэшей (hash join) имеет ожидаемую сложность O(M+N).Классический алгоритм хеш-соединения для внутреннего объединения двух таблиц сначала подготавливает хеш-таблицу меньшей таблицы. Записи хеш-таблицы состоят из атрибута соединения и его строки. Доступ к хеш-таблице осуществляется путем применения хеш-функции к атрибуту соединения. Как только хеш-таблица построена, сканируется большая таблица, и соответствующие строки из меньшей таблицы находятся путем поиска в хеш-таблице.
- Соединение слиянием (merge joins) обычно имеют сложность O(M+N), но оно будет сильно зависеть от индексов столбцов соединения и, в случае отсутствия индекса, от того, отсортированы ли строки в соответствии с ключами, используемыми в соединении:
- Если обе таблицы отсортированы в соответствии с ключами, используемыми в соединении, то запрос будет иметь временную сложность O(M+N).
- Если у обеих таблиц есть индекс для соединенных столбцов, то индекс уже поддерживает эти столбцы упорядочными и сортировка не требуется. Сложность будет O(M+N).
- Если ни одна из таблиц не имеет индекса по соедиенным столбцам, сначала необходимо выполнить сортировку обеих таблиц, так что сложность будет выглядеть как O(M log M + N log N).
- Если только одна из таблиц имеет индекс на соедиенных столбцах, то только та таблица, которая не имеет индекса, должна быть отсортирована, прежде чем произойдет этап соединения, так что сложность будет выглядеть как O(M + N log N).
- Для вложенных соединений (nested joins) сложность обычно составляет O(MN). Это соединение эффективно, когда одна или обе таблицы чрезвычайно малы (например, меньше 10 записей), что является очень распространенной ситуацией при оценке запросов, поскольку некоторые подзапросы записываются для возврата только одной строки.
Помните:
Работа в сервисе sql fiddle
Онлайн проверка sql запросов возможна при помощи сервиса sqlFiddle.
Самый простой способ организации работы состоит из следующих этапов:
- В верхней части рабочей области сервиса выбираем язык: SQLite(WebSQL);
Открывшаяся рабочая область разделена визуально на 3 окна: левое — для кода создания таблиц и заполнения их данными, правое — для кода запросов, нижнее — для отображения результатов запросов. - В левое окно помещается код для создания таблиц и вставки в них данных (пример кода расположен ниже). Затем щелкается кнопка «Build Schema».
После того как схема построена (об этом сигнализирует надпись на зеленом фоне «Schema Ready»), в правое окошко вставляется код запроса и щелкается кнопка Run SQL.
Еще пример:
Теперь некоторые пункты рассмотрим подробнее.Создание таблиц:
Пример: создайте сразу три таблицы (teachers, lessons и courses); добавьте по нескольку значений в каждую таблицу.
* для тех, кто незнаком с синтаксисом — просто скопировать полностью код и вставить в левое окошко сервиса
* урок по созданию таблиц в языке SQL далее
/*teachers*/ CREATE TABLE `teachers` ( `id` INT(11) NOT NULL, `name` VARCHAR(25) NOT NULL, `code` INT(11), `zarplata` INT(11), `premia` INT(11), PRIMARY KEY (`id`) ); INSERT INTO teachers VALUES (1, 'Иванов',1,10000,500), (2, 'Петров',1,15000,1000) ,(3, 'Сидоров',1,14000,800), (4,'Боброва',1,11000,800); /*lessons*/ CREATE TABLE `lessons` ( `id` INT(11) NOT NULL, `tid` INT(11), `course` VARCHAR(25), `date` VARCHAR(25), PRIMARY KEY (`id`) ); INSERT INTO lessons VALUES (1,1, 'php','2015-05-04'), (2,1, 'xml','2016-13-12'); /*courses*/ CREATE TABLE `courses` ( `id` INT(11) NOT NULL, `tid` INT(11), `title` VARCHAR(25), `length` INT(11), PRIMARY KEY (`id`) ); INSERT INTO courses VALUES (1,1, 'php',54), (2,1, 'xml',72), (3,2, 'sql',25); |
В результате получим таблицы с данными:
Отправка запроса:
Для того чтобы протестировать работоспособность сервиса, добавьте в правое окошко код запроса.
Пример: при помощи запроса выберите все данные из таблицы teachers, касаемые учителя с фамилией Иванов
SELECT * FROM `teachers` WHERE `name` = 'Иванов'; |
На дальнейших уроках SQL будет использоваться та же схема, поэтому необходимо будет просто копировать схему и вставлять в левое окно сервиса.
Онлайн визуализации схемы базы данных
Для онлайн визуализации схемы базы данных можно воспользоваться сервисом https://dbdesigner.net/:
- Создать свой аккаунт (войти в него, если уже есть).
- Щелкнуть по кнопке Go to Application.
- Меню Schema -> Import.
- Скопировать и вставить в появившееся окно код создания и заполнения таблиц базы данных
Далее к уроку 0 Язык sql создание таблиц
Работа с таблицами.
Создадим таблицу со столбцами id, user, pass, data. Причем id будет автоматически увеличивать свое значение :
- INT : тип столбца среднее целое число. Подписанный диапазон составляет от -2147483648 до 2147483647 .
- VARCHAR : тип строка переменной длины ,может содержать буквы, цифры и специальные символы(100 , максимально сто символов).
- NOT NULL : столбец не может не содержать значение ( не может быть пустым).
- AUTO_INCREMENT : создает уникальный идентификатор при вставке новой записи в таблицу.
- PRIMARY KEY ( id ) : данное ограничение позволяет однозначно идентифицировать каждую запись в таблице. Первичный ключ должен содержать уникальные значения. Первичный ключ не может содержать NULL значений. Каждая таблица должна иметь первичный ключ, и каждая таблица может иметь только один первичный ключ.
- DATA : тип дата. Формат: гггг-ММ-ДД.
Простомтр таблиц в базу :
Просмотра сведений о таблице :
Добавление данных в таблицу :
Если заполняем все столбцы, можно просто перечислить значения :
Обновление данных в таблице. Скажем заменим поля user и pass для id 1 :
WHERE это условие при котором будет произведена замена.
Удаление всех данных из таблице :
Удаление таблицы :
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
Пример с несколькими выражениями
Затем давайте посмотрим, как имитировать запрос INTERSECT в MySQL, который возвращает более одного столбца.
Во-первых, так вы должны использовать оператор INTERSECT для возврата нескольких выражений.
MySQL
SELECT contact_id, last_name, first_name
FROM contacts
WHERE contact_id < 100
INTERSECT
SELECT customer_id, last_name, first_name
FROM customers
WHERE last_name <> ‘Johnson’;
|
1 2 3 4 5 6 7 |
SELECTcontact_id,last_name,first_name FROMcontacts WHEREcontact_id<100 SELECTcustomer_id,last_name,first_name FROMcustomers WHERElast_name<>’Johnson’; |
Опять же, поскольку вы не можете использовать оператор INTERSECT в MySQL, вы можете использовать предложение EXISTS в более сложных ситуациях для имитации запроса INTERSECT следующим образом:
MySQL
SELECT contacts.contact_id, contacts.last_name, contacts.first_name
FROM contacts
WHERE contacts.contact_id < 100
AND EXISTS (SELECT *
FROM customers
WHERE customers.last_name <> ‘Markoski’
AND customers.customer_id = contacts.contact_id
AND customers.last_name = contacts.last_name
AND customers.first_name = contacts.first_name);
|
1 2 3 4 5 6 7 8 9 |
SELECTcontacts.contact_id,contacts.last_name,contacts.first_name FROMcontacts WHEREcontacts.contact_id<100 ANDEXISTS(SELECT* FROMcustomers WHEREcustomers.last_name<>’Markoski’ ANDcustomers.customer_id=contacts.contact_id ANDcustomers.last_name=contacts.last_name ANDcustomers.first_name=contacts.first_name); |
В этом более сложном примере вы можете использовать предложение EXISTS для возврата нескольких выражений, которые существуют как в таблице contacts, где contact_id меньше 100, так и в таблице customers, где last_name не равно ‘Markoski’.
Поскольку вы выполняете INTERSECT, вам необходимо соединить пересекающиеся поля следующим образом:
AND customers.customer_id = contacts.contact_id AND customers.last_name = contacts.last_name AND customers.first_name = contacts.first_name
Это соединение выполняется для того, чтобы поля customer_id, last_name и first_name из таблицы customers пересекались бы с полями contact_id, last_name и first_name из таблицы contacts.
Инструкция USE
Для того, чтобы начать взаимодействие с какой-либо базой данных, необходимо подключиться к ней. Для этого существует команда . Посмотрим пример:
INI
MariaDB > USE lexone.ru;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
|
1 2 3 4 |
MariaDB>USElexone.ru; Readingtableinformationforcompletionoftableandcolumnnames Youcanturnoffthisfeaturetogetaquickerstartupwith-A Databasechanged |
Но перед тем, как подключаться к базам данных, нужно узнать, какие-же вообще есть базы данных на нашем сервере. Нельзя подключиться к тому, сам не знаю к чему. Для этого используется инструкция .