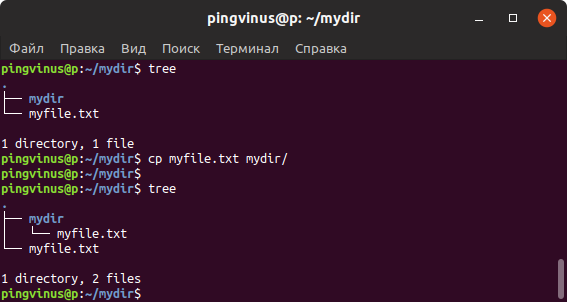
Скачиваем сайты целиком
Содержание:
- Как скопировать сайт на компьютер со всеми папками и изображениями?
- Download From Multiple Sites
- How Do I Download Multiple Files Using wget?
- Cliget
- Retry Options
- Use wget With the Password Protected Sites
- Recursive Download
- Features of the wget Command
- Protocols
- Ожидание между загрузкой файлов
- Загрузка файла с помощью curl
- Расширенное использование
- Просто использование
- Использование wget Linux
- Опции
- GetLeft
- Скачать файл с помощью elinks
- 4 программы для скачивания сайтов
- How to Download a Website Using wget
- Installing wget on a Debian Linux
- How Do I Limit the Download Speed?
Как скопировать сайт на компьютер со всеми папками и изображениями?
Сегодня расскажу как скопировать сайт на свой компьютер для дальнейшей работы с сайтом в оффлайн режиме. Такой вопрос задал мне один из моих клиентов, ему понравилась одна интернет страничка, себе он захотел такую же. Очень долго я ему объяснял как сохранить эту страницу себе на компьютер, чтобы потом поменять все тексты на свои и залить на свой домен, но он категорически не мог меня понять. Было принято решение написать инструкцию.
И так, что мы имеем: у нас есть интернет сайт, который нужно выкачать на компьютер, в моем случае это вот такая страница http://www.mokselle.ru/trainingopbox/. Как вы понимаете нажать в браузере «Сохранить как» не получится, иначе я не писал бы эту статью. Все не так просто, но в то же время и не тяжело.
И так для того чтобы скачать сайт полностью на свой компьютер, вам понадобится программа Wget, скачать её можно по прямой ссылке с моего облачного хранилища
Скачать Wget 1.18(размер файла — 3,3 Mb)
Создайте в папке C:\Program Files\ каталог Wget и разархивируйте содержимое архива в неё
После разархивирования вам нужно настроить переменные среды. Для этого откройте «Свойства компьютера» — «Дополнительные параметры системы»
нажмите на кнопку «Переменные среды»
В открывшемся окне выберите пункт Path и нажмите на кнопку «Изменить»
Добавьте новый параметр, указав в нем полный путь к разархивированной программе Wget, в моем случае это — C:\Program Files\wget
Если у вас Windows 8 или Windows 7, то этот параметр нужно добавить в самый конец через знак ;
После внесения переменной среды, жмите «ОК»,и проверьте все ли правильно сделали. Для проверки, откройте командную строку (Win+R и введите команду cmd), в командной строке введите wget и нажмите Enter, если вы видите подобную картину, значит все вы сделали правильно
Копирование сайта на компьютер с помощью Wget
Вот мы и подошли к самому процессу сохранения сайта целиком на компьютер. Для того, чтобы скачать сайт целиком, нужно в командной строке ввести следующее:
wget -r -k -l 10 -p -E -nc —no-check-certificate https://sidemob.com
Расшифровка:
—page-requisites — ключ для скачивания всех реквизитов (картинки, стили, джава скрипты, шрифты и т.д.)
-r — ключ указывающий на то, что нужно скачать все страницы, а не только главную
-l 10 — ключ указывающий уровень вложенности страниц
после всех ключей указывается ссылка на сайт, который нужно скачать. Жмем Enter и ждем завершение процедуры загрузки
После завершения процедуры скачивания сайта, откройте в проводнике папку со своей учетной записью, у меня она находиться по вот такому пути:
В папке с учетной записью появилась папка с названием сайта, который я только что скачал, захожу в неё и запускаю файл index.html
И вуаля! Открывается полная копия того сайта, который мы хотели скачать
Что делать с скачанным сайтом, вопрос другой. Если вы его скачали для дальнейшего прочтения во время отсутствия интернета, это одно дело. Если вы собираетесь воровать какую то часть сайта, не забывайте, разработчики сайта потратили на него много денег и времени, кто то ночи не досыпал, а кто то хлеба не доедал… Не воруйте в общем.
Мы предлагаем широкий спект услуг по сайтам и компьютерной поддержке
Мы разрабатываем как простые сайты — визитки, так и индивидуальные проекты. Основная система разработки — CMS Drupal.
Одно из основных направлений работы нашей компании — продвижение сайтов в Саратове и области. Мы поможем Вам с SEO — продвижением сайтов и настройкой и ведением контекстной рекламы в Яндекс Директ.
Мы оказываем услуги компаниям и частным лицам в области настройки компьютерного оборудования:
Download From Multiple Sites
You can set up an input file to download from many different sites. Open a file using your favorite editor or the cat command and list the sites or links to download from on each line of the file. Save the file, and then run the following wget command:
wget -i /
Apart from backing up your website or finding something to download to read offline, it is unlikely that you will want to download an entire website. You are more likely to download a single URL with images or download files such as zip files, ISO files, or image files.
With that in mind, you don’t have to type the following into the input file as it is time consuming:
- http://www.myfileserver.com/file1.zip
- http://www.myfileserver.com/file2.zip
- http://www.myfileserver.com/file3.zip
If you know the base URL is the same, specify the following in the input file:
- file1.zip
- file2.zip
- file3.zip
You can then provide the base URL as part of the wget command, as follows:
wget -B http://www.myfileserver.com -i /
How Do I Download Multiple Files Using wget?
Use the following syntax: You can create a shell variable that holds all urls and use the ‘BASH for loop‘ to download all files:
URLS="http://www.cyberciti.biz/download/lsst.tar.gz \ ftp://ftp.freebsd.org/pub/sys.tar.gz \ ftp://ftp.redhat.com/pub/xyz-1rc-i386.rpm \ http://xyz-url/abc.iso" for u in $URLS do wget "$u" done |
How Do I Read URLs From a File?
You can put all urls in a text file and use the -i option to wget to download all files. First, create a text file: Append a list of urls:
http://www.cyberciti.biz/download/lsst.tar.gz ftp://ftp.freebsd.org/pub/sys.tar.gz ftp://ftp.redhat.com/pub/xyz-1rc-i386.rpm http://xyz-url/abc.iso
Type the wget command as follows:
Cliget
There is a Firefox add-on called cliget. To add this to Firefox:
-
Visit https://addons.mozilla.org/en-US/firefox/addon/cliget/ and click the add to Firefox button.
-
Click the install button when it appears and then restart Firefox.
-
To use cliget, visit a page or file you wish to download and right-click. A context menu appears called cliget, and there are options to copy to wget and copy to curl.
-
Click the copy to wget option, open a terminal window, then right-click and choose paste. The appropriate wget command is pasted into the window.
This saves you from having to type the command yourself.
Retry Options
If you set up a queue of files to download in an input file and you leave your computer running to download the files, the input file may become stuck while you’re away and retry to download the content. You can specify the number of retries using the following switch:
wget -t 10 -i /
Use the above command in conjunction with the -T switch to specify a timeout in seconds, as follows:
wget -t 10 -T 10 -i /
The above command will retry 10 times and will connect for 10 seconds for each link in the file.
It is also inconvenient when you download 75% of a 4-gigabyte file on a slow broadband connection only for the connection to drop. To use wget to retry from where it stopped downloading, use the following command:
wget -c www.myfileser
If you hammer a server, the host might not like it and might block or kill your requests. You can specify a wait period to specify how long to wait between each retrieval, as follows:
wget -w 60 -i /
The above command waits 60 seconds between each download. This is useful if you download many files from a single source.
Some web hosts might spot the frequency and block you. You can make the wait period random to make it look like you aren’t using a program, as follows:
wget --random-wait -i /
Use wget With the Password Protected Sites
You can supply the http username/password on server as follows: Another way to specify username and password is in the URL itself. Either method reveals your password to anyone who bothers to run ps command: Sample outputs:
vivek 27370 2.3 0.4 216156 51100 ? S 05:34 0:06 /usr/bin/php-cgi vivek 27744 0.1 0.0 97444 1588 pts/2 T 05:38 0:00 wget http://test:test@www.kernel.org/pub/linux/kernel/v2.6/testing/linux-2.6.36-rc3.tar.bz2 vivek 27746 0.5 0.0 97420 1240 ? Ss 05:38 0:00 wget -b http://test:test@www.kernel.org/pub/linux/kernel/v2.6/testing/linux-2.6.36-rc3.tar.bz2
To prevent the passwords from being seen, store them in .wgetrc or .netrc, and make sure to protect those files from other users with “chmod”. If the passwords are really important, do not leave them lying in those files either edit the files and delete them after Wget has started the download.
Recursive Download
When we wish to make a local copy of a website, wget is the tool to use. curl does not provide recursive download, as it cannot be provided for all its supported protocols.
We can download a website with wget in a single command:
This will download the homepage and any resources linked from it. As we can see, www.baeldung.com links to various other resources like:
- Start here
- REST with Spring course
- Learn Spring Security course
- Learn Spring course
wget will follow each of these resources and download them individually:
3.1. Recursive Download with HTTP
The recursive download is one of the most powerful features of wget. This means that wget can follow links in HTML, XHTML, and CSS pages, to create local versions of remote web sites, fully recreating the directory structure of the original site.
Recursive downloading in wget is breadth-first. In other words, it first downloads the requested document, then the documents linked from that document, then the documents linked by those documents, and so on. The default maximum depth is set to five, but it can be overridden using the -l parameter:
In the case of HTTP or HTTPS URLs, wget scans and parses the HTML or CSS. Then, it retrieves the files the document refers to, through markups like href or src.
By default, wget will exclude paths under robots.txt (Robot Exclusion Standard). To switch this off, we can use the -e parameter:
3.2. Recursive Download with FTP
Unlike HTTP recursion, FTP recursion is performed depth-first. This means that wget will retrieve data of the first directory up to the specified depth level, and then move to the next directory in the directory tree.
Features of the wget Command
You can download entire websites using wget, and convert the links to point to local sources so that you can view a website offline. The wget utility also retries a download when the connection drops and resumes from where it left off, if possible, when the connection returns.
Other features of wget are as follows:
- Download files using HTTP, HTTPS, and FTP.
- Resume downloads.
- Convert absolute links in downloaded web pages to relative URLs so that websites can be viewed offline.
- Supports HTTP proxies and cookies.
- Supports persistent HTTP connections.
- Can run in the background even when you aren’t logged on.
- Works on Linux and Windows.
Protocols
2.1. Using the HTTP Protocol
Both curl and wget support HTTP, HTTPS, and FTP protocols. So if we want to get a page from a website, say baeldung.com, then we can run them with the web address as the parameter:
The main difference between them is that curl will show the output in the console. On the other hand, wget will download it into a file.
We can save the data in a file with curl by using the -o parameter:
2.2. Download and Upload Using FTP
We can also use curl and wget to download files using the FTP protocol:
We can also upload files to an FTP server with curl. For this, we can use the -T parameter:
We should note that when uploading to a directory, we must use provide the trailing /, otherwise curl will think that the path represents a file.
2.3. Differences
The difference between the two is that curl supports a plethora of other protocols. This includes DICT, FILE, FTPS, GOPHER, IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMB, SMBS, SMTP, SMTPS, TELNET, and TFTP.
We can treat curl as a general-purpose tool for transferring data to or from a server.
On the other hand, wget is basically a network downloader.
Ожидание между загрузкой файлов
При скачивании большого количества файлов, слишком частое обращение к удаленному серверу с вашей стороны может расцениваться сервером как DDoS атака. Опция -w позволяет задать количество секунд, которое требуется ожидать перед загрузкой очередного файла.
Некоторые веб-сайты умеют распознавать автоматические запросы к сайту, которые происходят с заданной периодичностью. Поэтому даже использование опции -w не всегда помогает. В таких случаях можно воспользоваться дополнительной опцией —random-wait. При ее использовании ожидание перед загрузкой очередного файла составляет случайное количество секунд от 0.5*wait до 1.5*wait. Пример использования (ожидание будет в диапазоне от 15 до 45 секунд):
Загрузка файла с помощью curl
Утилита curl предназначена для решения задач другого типа задач. Она больше подходит для отладки приложений и просмотра заголовков. Но иногда применяется и для загрузки файлов. По умолчанию, curl будет отправлять полученные данные сразу в стандартный вывод, поэтому она более удобна для загрузки скриптов:
 Если же вы хотите записать загруженные данные в файл, то нужно использовать опцию -O и обязательно в верхнем регистре:
Если же вы хотите записать загруженные данные в файл, то нужно использовать опцию -O и обязательно в верхнем регистре:

Когда загрузка файла в linux будет завершена, он будет находится в текущей папке. Вывод утилиты состоит из нескольких колонок, по которым можно детально отследить как происходит процесс загрузки:
- % — показывает на сколько процентов загрузка завершена на данный момент;
- Total — полный размер файла;
- Reсeived — количество полученных данных;
- Xferd — количество отправленных на сервер данных, работает только при выгрузке файла;
- Average Speed Dload — средняя скорость загрузки;
- AVerage Speed Upload — скорость отдачи для выгрузки файлов;
- Time Total — отображает время, которое уйдет на загрузку всего файла;
- Time Spend — сколько времени потрачено на загрузку файла;
- Time Left — время, которое осталось до конца загрузки файла;
- Current Speed — отображает текущую скорость загрузки или отдачи.
Если вы хотите скачать файл из командной строки linux и сохранить его с произвольным именем, используйте опцию -o в нижнем регистре:
Например, если для этого файла не задать имя, то он запишется с именем скрипта, а это не всегда удобно. Если остановиться на отличиях curl от wget, то здесь поддерживается больше протоколов: FTP, FTPS, HTTP, HTTPS, SCP, SFTP, TFTP, TELNET, DICT, LDAP, LDAPS, FILE, POP3, IMAP, SMTP, RTMP и RTSP, а также различные виды шифрования SSL.
Расширенное использование
- *
- Если у Вас есть файл с URL, которые вы хотите загрузить, то используйте параметр -i:
Если вы укажете – вместо имени файла, то URL будут читаться из стандартного ввода (stdin).
- *
- Создать пятиуровневую копию сайта GNU со структурой папок оригинала, с одной попыткой загрузки, сохранить сообщения в gnulog:
- *
- Как и в примере выше, но с конвертированием ссылки в файлах HTML в локальные, для последующего автономного просмотра:
- *
- Загрузить одну страницу HTML и все файлы, требуемые для отображения последней (напр. рисунки, файлы каскадных стилей и т. д.). Также сконвертировать все ссылки на эти файлы:
Страница HTML будет сохранена в www.server.com/dir/page.html и рисунки, каскадные стили и прочее будет сохранено в папке www.server.com/, кроме случая, когда файлы будут загружаться с других серверов.
- *
- Как и в примере выше, но без папки www.server.com/. Также все файлы будут сохранены в подпапках download/.
- *
- Загрузить index.html с www.lycos.com, отображая заголовки сервера:
- *
- Сохранить заголовки в файл для дальнейшего использования.
- *
- Загрузить два высших уровня wuarchive.wustl.edu в /tmp.
- *
- Загрузить файлы GIF папки на HTTP сервере. Команда wget http://www.server.com/dir/*.gif не будет работать, так как маскировочные символы не поддерживаются при загрузке по протоколу HTTP. Используйте:
-r -l1 включает рекурсивную загрузку с максимальной глубиной 1. ––no-parent выключает следование по ссылкам в родительскую папку, имеющую верхний уровень, -A.gif разрешает загружать только файлы с расширением .GIF. -A “*.gif” также будет работать.
- *
- Предположим, что во время рекурсивной загрузки вам нужно было срочно выключить/перезагрузить компьютер. Чтобы не загружать уже имеющиеся файлы, используйте:
- *
- Если вы хотите указать имя пользователя и пароль для сервера HTTP или FTP, используйте соответствующий синтаксис URL:
- *
- Вы хотите, чтобы загружаемые документы шли в стандартный вывод, а не в файлы?
Если вы хотите устроить конвейер и загрузить все сайты, ссылки на которые указаны на одной странице:
Просто использование
- *
- Если вам нужно загрузить URL, то введите:
- *
- Но что же будет, если соединение медленное, а файл длинный? Есть возможность обрыва связи перед завершением загрузки. В этом случае Wget будет продолжать попытки нового соединения, пока не кончится число попыток (по умолчанию 20). Можно изменить это число, например до 45:
- *
- Теперь оставим Wget работать в фоновом режиме, а его сообщения будем записывать в журнал log. Долго набирать ––tries, так что используем -t.
Символ амперсанда в конце указывает командному интерпретатору продолжать работу, не дожидаясь завершения работы Wget. Чтобы программа делала повторы бесконечно – используйте -t inf.
- *
- Использовать FTP также очень просто. Wget берет на себя все заботы по авторизации.
- *
- Если вы укажите адрес папки, то Wget загрузит листинг этой папки (т.е. файлы и подкаталоги, содержащиеся в ней) и сконвертирует его в формат HTML. Например:
Использование wget Linux
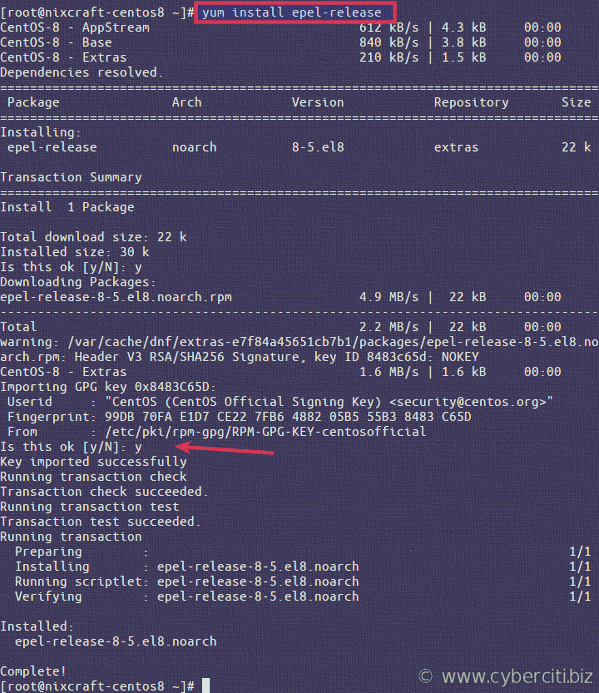
Команда wget linux, обычно поставляется по умолчанию в большинстве дистрибутивов, но если нет, ее можно очень просто установить. Например установка с помощью yum будет выглядеть следующим образом:
А в дистрибутивах основанных на Debian:
Теперь перейдем непосредственно к примерам:
1. Загрузка файла
Команда wget linux скачает один файл и сохранит его в текущей директории. Во время загрузки мы увидим прогресс, размер файла, дату его последнего изменения, а также скорость загрузки:

Опция -О позволяет задать имя сохраняемому файлу, например, скачать файл wget с именем wget.zip:

Вы можете скачать несколько файлов одной командой даже по разным протоколам, просто указав их URL:

4. Взять URL из файла
Вы можете сохранить несколько URL в файл, а затем загрузить их все, передав файл опции -i. Например создадим файл tmp.txt, со ссылками для загрузки wget, а затем скачаем его:

5. Продолжить загрузку
Утилита wget linux рассчитана на работу в медленных и нестабильных сетях. Поэтому если вы загружали большой файл, и во время загрузки было потеряно соединение, то вы можете скачать файл wget с помощью опции -c.
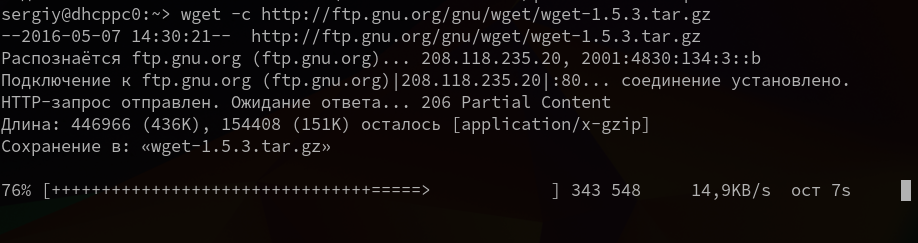
6. Загрузка файлов в фоне
Опция -b заставляет программу работать в фоновом режиме, весь вывод будет записан в лог файл, для настройки лог файла используются специальные ключи wget:

7. Ограничение скорости загрузки
Команда wget linux позволяет не только продолжать загрузку файлов, но и ограничивать скорость загрузки. Для этого есть опция —limit-rate. Например ограничим скорость до 100 килобит:

Здесь доступны, как и в других подобных командах индексы для указания скорости — k — килобит, m — мегабит, g — гигабит, и так далее.
8. Подключение по логину и паролю
Некоторые ресурсы требуют аутентификации, для загрузки их файлов. С помощью опций —http-user=username, –http-password=password и —ftp-user=username, —ftp-password=password вы можете задать имя пользователя и пароль для HTTP или FTP ресурсов.
Или:
9. Загрузить и выполнить
Вы, наверное, уже видели такие команды. wget позволяет сразу же выполнять скачанные скрипты:
Если опции -O не передать аргументов, то скачанный файл будет выведен в стандартный вывод, затем мы его можем перенаправить с интерпретатор bash, как показано выше.
По умолчанию wget сохраняет файл в текущую папку, но это поведение очень легко изменить с помощью опции -P:

11. Передать информацию о браузере
Некоторые сайты фильтруют ботов, но мы можем передать фальшивую информацию о нашем браузере (user-agent) и страницу с которой мы пришли (http-referer).

12. Количество попыток загрузки
По умолчанию wget пытается повторить загрузку 20 раз, перед тем как завершить работу с ошибкой. Количество раз можно изменить с помощью опции —tries:
13. Квота загрузки
Если вам доступно только ограниченное количество трафика, вы можете указать утилите, какое количество информации можно скачивать, например разрешим скачать файлов из списка только на десять мегабайт:
Здесь работают те же индексы для указания размера — k, m, g, и т д.
14. Скачать сайт
Wget позволяет не только скачивать одиночные файлы, но и целые сайты, чтобы вы могли их потом просматривать в офлайне. Использование wget, чтобы скачать сайт в linux выглядит вот так:
Опции
Синтаксис опций очень свободный. У каждой опции, как правило есть как длинное, так и короткое имя. Их можно записывать как до URL, так и после. Между опцией и ее значением не обязательно ставить пробел, например вы можете написать -o log или -olog. Эти значения эквивалентны. Также если у опций нет параметров, не обязательно начинать каждую с дефиса, можно записать их все вместе: -drc и -d -r -c. Эти параметры wget тоже эквивалентны.
А теперь давайте перейдем к списку опций. У wget слишком много опций, мы разберем только основные.
- -V (—version) — вывести версию программы
- -h (—help) — вывести справку
- -b (—background) — работать в фоновом режиме
- -o файл (—out-file) — указать лог файл
- -d (—debug) — включить режим отладки
- -v (—verbose) — выводить максимум информации о работе утилиты
- -q (—quiet) — выводить минимум информации о работе
- -i файл (—input-file) — прочитать URL из файла
- —force-html — читать файл указанный в предыдущем параметре как html
- -t (—tries) — количество попыток подключения к серверу
- -O файл (—output-document) — файл в который будут сохранены полученные данные
- -с (—continue) — продолжить ранее прерванную загрузку
- -S (—server-response) — вывести ответ сервера
- —spider — проверить работоспособность URL
- -T время (—timeout) — таймаут подключения к серверу
- —limit-rate — ограничить скорость загрузки
- -w (—wait) — интервал между запросами
- -Q (—quota) — максимальный размер загрузки
- -4 (—inet4only) — использовать протокол ipv4
- -6 (—inet6only) — использовать протокол ipv6
- -U (—user-agent)- строка USER AGENT отправляемая серверу
- -r (—recursive)- рекурсивная работа утилиты
- -l (—level) — глубина при рекурсивном сканировании
- -k (—convert-links) — конвертировать ссылки в локальные при загрузке страниц
- -P (—directory-prefix) — каталог, в который будут загружаться файлы
- -m (—mirror) — скачать сайт на локальную машину
- -p (—page-requisites) — во время загрузки сайта скачивать все необходимые ресурсы
Кончено это не все ключи wget, но здесь и так слишком много теории, теперь давайте перейдем к практике. Примеры wget намного интереснее.
GetLeft
Этот граббер с открытым исходным кодом существует уже давно, и на это есть веские причины. GetLeft — это небольшая утилита, позволяющая загружать различные компоненты сайта, включая HTML и изображения.
GetLeft очень удобен для пользователя, что и объясняет его долговечность. Для начала просто запустите программу и введите URL-адрес сайта, затем GetLeft автоматически анализирует веб-сайт и предоставит вам разбивку страниц, перечисляя подстраницы и ссылки. Затем вы можете вручную выбрать, какие части сайта вы хотите загрузить, установив соответствующий флажок.
После того, как вы продиктовали, какие части сайта вы хотите зазрузить, нажмите на кнопку. GetLeft загрузит сайт в выбранную вами папку. К сожалению, GetLeft не обновлялся какое-то время.
Спасибо, что читаете! Подписывайтесь на мой канал в Telegram и . Только там последние обновления блога и новости мира информационных технологий.
Скачать файл с помощью elinks
Еще одна ситуация, когда вам нужно скачать файл из командной строки linux, вы знаете где его найти, но у вас нет прямой ссылки. Тогда все ранее описанные утилиты не помогут. Но вы можете использовать один из консольных браузеров, например, elinks. Если эта программа еще не установлена, то вы можете найти ее в официальных репозиториях своих дистрибутивов.
Запустите браузер, например, с помощью команды:
В первом окне нажмите Enter:

Затем введите URL страницы, например, не будем далеко ходить и снова скачаем ядро с kernel.org:

Когда вы откроете сайт, останется только выбрать URL для загрузки:

Далее выберите что нужно сделать с файлом, например, сохранить (save), а также выберите имя для нового файла:


В следующем окне вы увидите информацию о состоянии загрузки:

4 программы для скачивания сайтов
4 программы для скачивания сайтов
Эти четыре программы помогут вам загрузить практически любой сайт к себе на компьютер. Очень полезно, если вы боитесь потерять доступ к любимым статьям, книгам, инструкциям и всему остальному, что могут удалить или заблокировать.
HTTrack позволяет пользователям загружать сайт из интернета на жесткий диск. Программа работает путем копирования содержимого всего сайта, а затем загружает все каталоги, HTML, изображения и другие файлы с сервера сайта на ваш компьютер.
При просмотре скопированного сайта HTTrack поддерживает исходную структуру ссылок сайта. Это позволяет пользователям просматривать его в обычном браузере. Кроме того, пользователи могут нажимать на ссылки и просматривать сайт точно так же, как если бы они смотрели его онлайн.
HTTrack также может обновлять ранее загруженные сайты, а также возобновлять любые прерванные загрузки. Приложение доступно для Windows, Linux и даже для устройств на базе Android.
Если вы твердо придерживаетесь экосистемы Apple и имеете доступ только к Mac, вам нужно попробовать SiteSucker. Программа, получившая такое название, копирует все файлы веб-сайта на жесткий диск. Пользователи могут начать этот процесс всего за несколько кликов, что делает его одним из самых простых в использовании инструментов. Кроме того, SiteSucker довольно быстро копирует и сохраняет содержимое сайта. Однако помните, что фактическая скорость загрузки будет зависеть от пользователя.
К сожалению, SiteSucker не лишен недостатков. Во-первых, SiteSucker — платное приложение. На момент написания этой статьи SiteSucker стоит $4.99 в App Store. Кроме того, SiteSucker загружает каждый файл на сайте, который может быть найден. Это означает большую загрузку с большим количеством потенциально бесполезных файлов.
Cyotek WebCopy — инструмент, позволяющий пользователям копировать полные версии сайтов или только те части, которые им нужны. К сожалению, приложение WebCopy доступно только для Windows, но зато оно является бесплатным. Использовать WebCopy достаточно просто. Откройте программу, введите целевой URL-адрес и все.
Кроме того, WebCopy имеет большое количество фильтров и опций, позволяющих пользователям скачивать только те части сайта, которые им действительно нужны. Эти фильтры могут пропускать такие вещи, как изображения, рекламу, видео и многое другое, что может существенно повлиять на общий размер загрузки.
Этот граббер с открытым исходным кодом существует уже давно, и на это есть веские причины. GetLeft — это небольшая утилита, позволяющая загружать различные компоненты сайта, включая HTML и изображения.
GetLeft очень удобен для пользователя, что и объясняет его долговечность. Для начала просто запустите программу и введите URL-адрес сайта, затем GetLeft автоматически анализирует веб-сайт и предоставит вам разбивку страниц, перечисляя подстраницы и ссылки. Затем вы можете вручную выбрать, какие части сайта вы хотите загрузить, установив соответствующий флажок.
После того, как вы продиктовали, какие части сайта вы хотите зазрузить, нажмите на кнопку. GetLeft загрузит сайт в выбранную вами папку. К сожалению, GetLeft не обновлялся какое-то время.
Респект за пост! Спасибо за работу!
Хотите больше постов? Узнавать новости технологий? Читать обзоры на гаджеты? Для всего этого, а также для продвижения сайта, покупки нового дизайна и оплаты хостинга, мне необходима помощь от вас, преданные и благодарные читатели. Подробнее о донатах читайте на специальной странице.
На данный момент есть возможность стать патроном, чтобы ежемесячно поддерживать блог донатом, или воспользоваться Яндекс.Деньгами, WebMoney, QIWI и
PayPal:
Спасибо! Все собранные средства будут пущены на развитие сайта. Поддержка проекта является подарком владельцу сайта.
How to Download a Website Using wget
wget www.ever
Before you begin, create a folder on your machine using the mkdir command, and then move into the folder using the cd command.
For example:
mkdir everydaylinuxusercd everydaylinuxuserwget www.ever
The result is a single index.html file that contains the content pulled from Google. The images and stylesheets are held on Google.
To download the full site and all the pages, use the following command:
wget -r www.ever
This downloads the pages recursively up to a maximum of 5 levels deep. Five levels deep might not be enough to get everything from the site. Use the -l switch to set the number of levels you wish to go to, as follows:
wget -r -l10 www.ever
If you want infinite recursion, use the following:
wget -r -l inf www.ever
You can also replace the inf with , which means the same thing.
There is one more problem. You might get all the pages locally, but the links in the pages point to the original place. It isn’t possible to click locally between the links on the pages.
To get around this problem, use the -k switch to convert the links on the pages to point to the locally downloaded equivalent, as follows:
wget -r -k www.ever
If you want to get a complete mirror of a website, use the following switch, which takes away the necessity for using the -r, -k, and -l switches.
wget -m www.ever
If you have a website, you can make a complete backup using this one simple command.
Installing wget on a Debian Linux
You need to use the apt-get command/apt command to install any package including wget. You can search for package name using the apt-cache command. The syntax is: Sample outputs: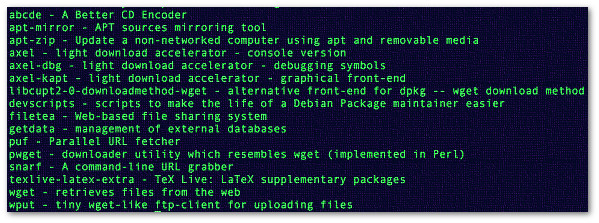
Fig.01: apt-cache search command search performs a full text search on all available package lists
Finding information about wget
Package: wget Architecture: amd64 Version: 1.20.3-1ubuntu1 Multi-Arch: foreign Priority: standard Section: web Origin: Ubuntu Maintainer: Ubuntu Developers <ubuntu-devel-discuss@lists.ubuntu.com> Original-Maintainer: Noël Köthe <noel@debian.org> Bugs: https://bugs.launchpad.net/ubuntu/+filebug Installed-Size: 992 Depends: libc6 (>= 2.17), libidn2-0 (>= 0.6), libpcre2-8-0 (>= 10.32), libpsl5 (>= 0.16.0), libssl1.1 (>= 1.1.0), libuuid1 (>= 2.16), zlib1g (>= 1:1.1.4) Recommends: ca-certificates Conflicts: wget-ssl Filename: pool/main/w/wget/wget_1.20.3-1ubuntu1_amd64.deb Size: 348824 MD5sum: ae9eb859432505828dab97c80edcb5b5 SHA1: 45504b6e948d4f1a7e2ba0233bb57a67b392ceea SHA256: 68144dde6d45e1a54fa983d6d10be7043e6695e259c8d2b12fd03ea5e475d56a Homepage: https://www.gnu.org/software/wget/ Description-en: retrieves files from the web Wget is a network utility to retrieve files from the web using HTTP(S) and FTP, the two most widely used internet protocols. It works non-interactively, so it will work in the background, after having logged off. The program supports recursive retrieval of web-authoring pages as well as FTP sites -- you can use Wget to make mirrors of archives and home pages or to travel the web like a WWW robot. . Wget works particularly well with slow or unstable connections by continuing to retrieve a document until the document is fully downloaded. Re-getting files from where it left off works on servers (both HTTP and FTP) that support it. Both HTTP and FTP retrievals can be time stamped, so Wget can see if the remote file has changed since the last retrieval and automatically retrieve the new version if it has. . Wget supports proxy servers; this can lighten the network load, speed up retrieval, and provide access behind firewalls. Description-md5: 63a4a740bcd9e8e94bf661e4f1806e02 Task: standard |
How Do I Limit the Download Speed?
You can limit the download speed to amount bytes per second. Amount may be expressed in bytes, kilobytes with the k suffix, or megabytes with the m suffix. For example, –limit-rate=100k will limit the retrieval rate to 100KB/s. This is useful when, for whatever reason, you don’t want Wget to consume the entire available bandwidth. This is useful when you want to download a large file file, such as an ISO image: Use m suffix for megabytes (–limit-rate=1m). The above command will limit the retrieval rate to 50KB/s. It is also possible to specify disk quota for automatic retrievals to avoid disk DoS attack. The following command will be aborted when the quota is (100MB+) exceeded. From the wget man page: