Offset-fetch в t-sql
Содержание:
CONTAINS
CONTAINS – это ключевое слово, которое используется в конструкции WHERE для поиска слов или фраз в столбце, который участвует в полнотекстовом поиске.
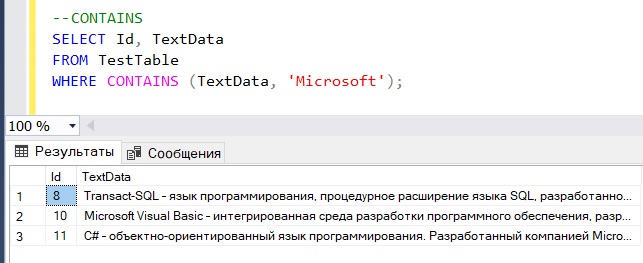
В следующем примере мы просто ищем строки, которые содержат слово Microsoft
--CONTAINS SELECT Id, TextData FROM TestTable WHERE CONTAINS (TextData, 'Microsoft');
Логические операторы
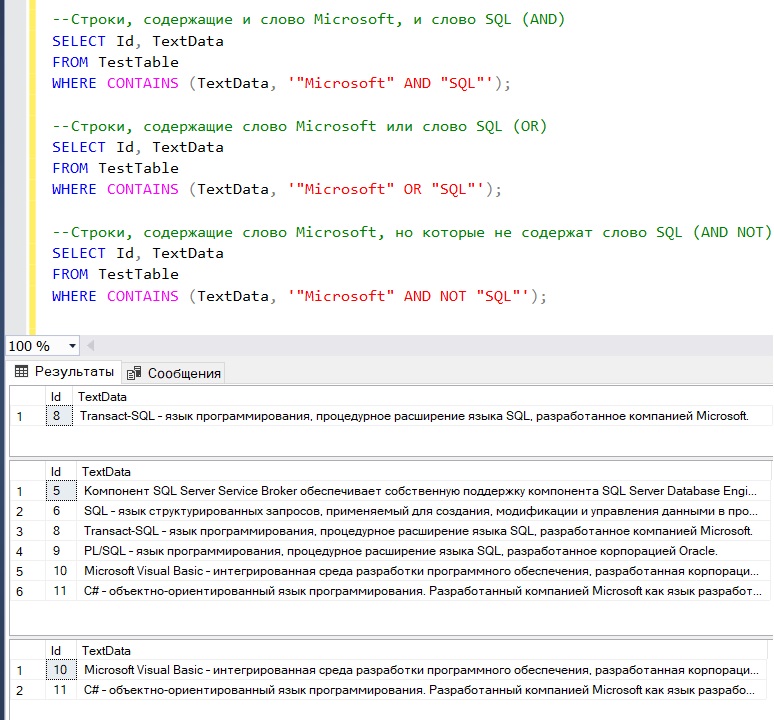
При составлении критерия поиска можно использовать логические операторы AND, OR, AND NOT, т.е., например, можно построить запрос так, чтобы искались строки со словами и Microsoft и SQL
--Строки, содержащие и слово Microsoft, и слово SQL (AND) SELECT Id, TextData FROM TestTable WHERE CONTAINS (TextData, '"Microsoft" AND "SQL"'); --Строки, содержащие слово Microsoft или слово SQL (OR) SELECT Id, TextData FROM TestTable WHERE CONTAINS (TextData, '"Microsoft" OR "SQL"'); --Строки, содержащие слово Microsoft, но которые не содержат слово SQL (AND NOT) SELECT Id, TextData FROM TestTable WHERE CONTAINS (TextData, '"Microsoft" AND NOT "SQL"');
Поиск по префиксным выражениям
Префиксные выражения означают, что мы можем искать слова, не указывая их полностью, например, указав только начало, это делается с помощью знака *
Допустим, нам необходимо найти строки, где есть упоминания о программах или программировании, для этого мы напишем следующее:
--CONTAINS. Поиск по префиксным выражениям SELECT Id, TextData FROM TestTable WHERE CONTAINS (TextData, '"програм*"');
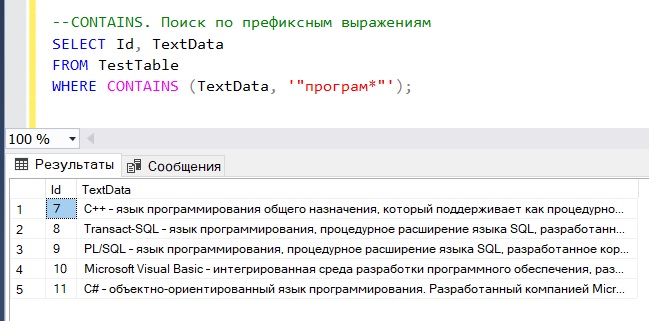
Поиск слова по словоформам
Полнотекстовый поиск SQL сервера позволяет искать различные формы глаголов или существительные в единственном и во множественном числе, например, давайте найдем записи, в которых есть слово «запрос» и его производные выражения.
--CONTAINS. Поиск слова по словоформам SELECT Id, TextData FROM TestTable WHERE CONTAINS (TextData, 'FORMSOF(INFLECTIONAL, "запрос")');
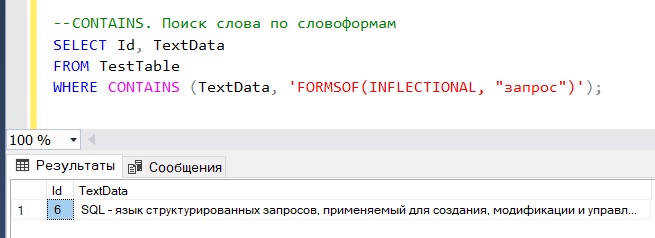
Как видим слова «запрос» у нас нет, но есть слово «запросов» поэтому эта строка и вывелась. Для поиска по словоформам мы использовали функцию FORMSOF().
Поиск слов или фраз с учетом расположения
Если Вам нужно найти слова или фразы, которые располагаются недалеко друг от друга, то можно использовать ключевое слово NEAR. Допустим, мы хотим получить все строки, в которых есть упоминание о любом языке программирования, но при условии, что компания Microsoft должна иметь к нему какое-то отношение, другими словами, фраза «язык программирования» должна располагаться неподалеку от слова Microsoft.
--CONTAINS. Поиск слов или фраз с учетом расположения SELECT Id, TextData FROM TestTable WHERE CONTAINS (TextData, '"язык программирования" NEAR "Microsoft"');
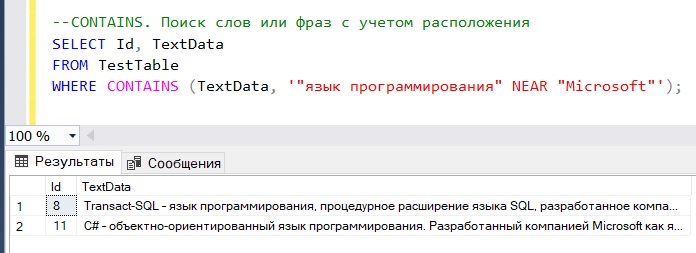
Настройка max_connections
Открываем конфигурационный файл mysql:
# vi /etc/my.cnf.d/server.cnf
* в более ранних версиях данный файл находится по пути /etc/my.cnf
В директиве добавляем или изменяем следующую строку:
…
max_connections = 500
* в данном примере мы разрешим 500 одновременных подключений к MySQL. При превышении данного значения будет отображаться ошибка too many connections.
Перезагружаем mysql:
# systemctl restart mysql || systemctl restart mariadb
* в некоторых системах перезагрузка сервера баз данных выполняется командой service mysql restart или service mysqld restart или service mysql-server restart
Оптимальное значение
Для данного лимита нет золотого стандарта — маленькое значение может привести к выстраиванию очередей запросов, большое — к перегрузке серверного оборудования. Правильнее всего постоянно наблюдать за значениями max_connections и threads_connected и определить для себя свой, так называемый, Best Practices.
На первое время, для сервера можно поставить лимит в 200-300 подключений.
Просмотр текущих значений
Выполняется в оболочке mysql — для подключения вводим:
mysql -uroot -p
Посмотреть максимально разрешенное количество подключений:
> SHOW VARIABLES WHERE `variable_name`=’max_connections’;
Максимально разрешенное количество подключений на пользователя:
> SHOW VARIABLES WHERE `variable_name`=’max_user_connections’;
Посмотреть текущее количество подключений:
> SHOW status WHERE `variable_name` = ‘threads_connected’;
Тайм-аут ожидания для запросов:
> SHOW VARIABLES WHERE `variable_name`=’wait_timeout’;
Максимальный размер пакета:
> SHOW VARIABLES WHERE `variable_name`=’max_allowed_packet’;
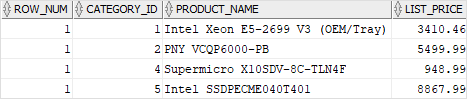
Fetch the Top X Percent of Rows in Oracle
[]
You can use the Oracle row limiting clause to get the top percentage of rows. This is done using the PERCENT keyword within this clause.
Let’s take a look at this query:
We’ve added the PERCENT keyword into the FETCH clause to indicate we only want to see the top 25% of rows. This top 25% is calculated by ordering the revenue in descending order, as specified by the ORDER BY clause.
The results of this query are:
| CUSTOMER_ID | REVENUE |
| 2 | 9384760 |
| 10 | 5131750 |
| 11 | 4431791 |
| 8 | 4341421 |
There are 4 rows shown because the table has 13 rows. 25% of 13 is 3.25, which is rounded up to 4.
You can use the same concept to get the last percentage of rows. Rather than changing the FIRST keyword to LAST, you can change the ORDER BY to sort in the opposite direction. This example shows ORDER BY revenue ASC instead of ORDER BY revenue DESC:
This will show the lowest 25% of customers according to their revenue.
| CUSTOMER_ID | REVENUE |
| 5 | 82495 |
| 1 | 109470 |
| 12 | 245583 |
| 7 | 654796 |
Вопросы и ответы
Вопрос:
Я пытаюсь вытащить некоторую информацию из таблицы. Для простоты, скажем таблица (report_history) имеет 4 колонки: user_name, report_job_id, report_name и report_run_date.
Каждый раз, когда выполняется отчет в Oracle, запись фиксируется в таблице, отмечая вышеперечисленную информацию. То, что я пытаюсь сделать, это вытащить из этой таблицы, когда и кем был запущен последний отдельный отчет.
Мой первоначальный запрос:
Oracle PL/SQL
SELECT report_name, MAX(report_run_date)
FROM report_history
GROUP BY report_name
|
1 2 3 |
SELECTreport_name,MAX(report_run_date) FROMreport_history GROUPBYreport_name |
работает нормально. Тем не менее, это не дает имя пользователя, запустившего отчет.
Добавление user_name к списку выборки и к оператору GROUP BY возвращает несколько строк для каждого отчета; результаты показывают последнее время, когда каждый человек запускал каждый отчет остается вопросом. (т.е. User1 запускал ОТЧЕТ1 01-Июль-14, User2 запускал ОТЧЕТ1 01-АВГ-14). Я не хочу этого … Я просто хочу знать, кто запускал определенный отчет и когда последний раз он был запущен.
Есть предложения?
Ответ:
Это все становится немного сложнее. В запросе ниже SQL SELECT вернет результаты, которые вы хотите:
Oracle PL/SQL
SELECT rh.user_name,
rh.report_name,
rh.report_run_date
FROM report_history rh,
(SELECT MAX(report_run_date) AS maxdate,
report_name
FROM report_history
GROUP BY report_name) maxresults
WHERE rh.report_name = maxresults.report_name
AND rh.report_run_date= maxresults.maxdate;
|
1 2 3 4 5 6 7 8 9 10 |
SELECTrh.user_name, rh.report_name, rh.report_run_date FROMreport_historyrh, (SELECTMAX(report_run_date)ASmaxdate, report_name FROMreport_history GROUPBYreport_name)maxresults WHERErh.report_name=maxresults.report_name ANDrh.report_run_date=maxresults.maxdate; |
Во-первых, мы присвоим псевдоним rh первому экземпляру таблицы report_history. Во-вторых, мы включили два компонента в оператор FROM. Первый из них является таблица report_history (псевдоним RH). Второй является подзапрос с псевдонимом maxresults:
Oracle PL/SQL
(SELECT MAX(report_run_date) AS maxdate, report_name
FROM report_history
GROUP BY report_name) maxresults
|
1 2 3 |
(SELECTMAX(report_run_date)ASmaxdate,report_name FROMreport_history GROUPBYreport_name)maxresults |
Имеем псевдоним MAX(report_run_date) как maxdate и имеем псевдоним всего результирующего набора как maxresults.
Теперь, когда мы составили этот запрос в пределах нашего FROM, Oracle позволит нам объединить эти результаты нашей исходной таблицы report_history. Таким образом, мы объединили поля report_name и report_run_date таблицы с псевдонимами rh и maxresults. Это позволили нам получить report_name, MAX(report_run_date), а также user_name.
Row Limiting Without the FETCH Clause
[]
There are a few ways to do row limiting and top-N queries without the FETCH clause in Oracle. This could be because you’re not working on a 12c or 18c database. Perhaps you’re running Oracle Express 11g, or using an 11g database at work.
There are a few ways to do this.
Using an Inline View with ROWNUM
You can use an inline view with the ROWNUM pseudocolumn to perform top-N queries. This is one of the most common ways to do row limiting without the FETCH clause.
The syntax looks like this:
You just need to specify the columns to view, the column to order by, and the number of rows to limit it to.
If we want to see the top 5 customers by revenue using our sample data, our query would look like this:
The results would be the same as the earlier examples:
| CUSTOMER_ID | REVENUE |
| 2 | 9384760 |
| 10 | 5131750 |
| 11 | 4431791 |
| 8 | 4341421 |
| 4 | 3596297 |
This works because the data is ordered before ROWNUM is applied.
However, this is the kind of query we want to avoid:
This will perform the limiting on the row number before the ordering, and give us these results:
| CUSTOMER_ID | REVENUE |
| 2 | 9384760 |
| 4 | 3596297 |
| 3 | 1852828 |
| 1 | 109470 |
| 5 | 82495 |
It has limited the results to the first 5 rows it has found in the table, and then performed the ordering. This will likely give you results you are not expecting. This is why we use a subquery such as an inline view.
Pagination with ROWNUM in Oracle
We can use this method to perform pagination of records in SQL. While it looks a little messier than the FETCH and OFFSET methods, it does work well:
This query does a few things:
- It includes two nested inline views. The innermost view gets the data and orders it by the revenue.
- The next inline view limits the results of the innermost view where the ROWNUM is less than or equal to 10.
- The inline view then calculates the ROWNUM of these new results and labels it as “rnum”
- The outer query then limits the entire result set to where the rnum is greater than 5.
So, in theory, it should show us rows 6 to 10. This is the result from this query:
| CUSTOMER_ID | REVENUE |
| 13 | 3596297 |
| 9 | 3378075 |
| 3 | 1852828 |
| 6 | 935191 |
| 7 | 654796 |
It shows rows 6 to 10 when ordering by the revenue in descending order.
Using a WITH Clause with ROWNUM
You can use the WITH clause to write the earlier query. For example, to find the top 5 customers by revenue, you can write the query that orders the customers in the WITH clause, and select from that.
This works in a similar way to an inline view.
The query would look like this:
This will show the same results:
| CUSTOMER_ID | REVENUE |
| 2 | 9384760 |
| 10 | 5131750 |
| 11 | 4431791 |
| 8 | 4341421 |
| 4 | 3596297 |
Using RANK and DENSE_RANK for Top-N Queries
You can use the RANK function in Oracle to find the top-N results from a query. It’s a bit more complicated, as you’ll need to use RANK as an analytic function, but the query works.
The query to find the top 5 customers by revenue would look like this:
The ordering is done within the parameters of the RANK function, and the limiting is done using the WHERE clause.
The results of this query are:
| CUSTOMER_ID | REVENUE |
| 2 | 9384760 |
| 10 | 5131750 |
| 11 | 4431791 |
| 8 | 4341421 |
| 4 | 3596297 |
| 13 | 3596297 |
This shows 6 results because customer_id 4 and 13 have the same revenue. This is because the RANK function does not exclude rows where there are ties.
You can also use the DENSE_RANK function instead of the RANK function.
The difference between these two functions is that the rank numbers that are assigned do not include gaps. However, it still shows us the top 6 rows as there is a tie.
| CUSTOMER_ID | REVENUE |
| 2 | 9384760 |
| 10 | 5131750 |
| 11 | 4431791 |
| 8 | 4341421 |
| 4 | 3596297 |
| 13 | 3596297 |
Using ROW_NUMBER For Top-N Queries
You can use the Oracle analytic function ROW_NUMBER to write top-N queries. It’s similar to the RANK function. The ROW_NUMBER function assigns a unique number for each row returned, but can be used over a window of data (just like all analytic queries).
A query to find the top 5 customers by revenue using ROW_NUMBER would look like this:
It looks very similar to the RANK and DENSE_RANK methods.
The results of this query are:
| CUSTOMER_ID | REVENUE |
| 2 | 9384760 |
| 10 | 5131750 |
| 11 | 4431791 |
| 8 | 4341421 |
| 4 | 3596297 |
Примеры использования OFFSET-FETCH в T-SQL
Сейчас давайте рассмотрим несколько примеров использования конструкции OFFSET-FETCH в языке T-SQL, но сначала давайте определимся с исходными данными.

Исходные данные для примеров
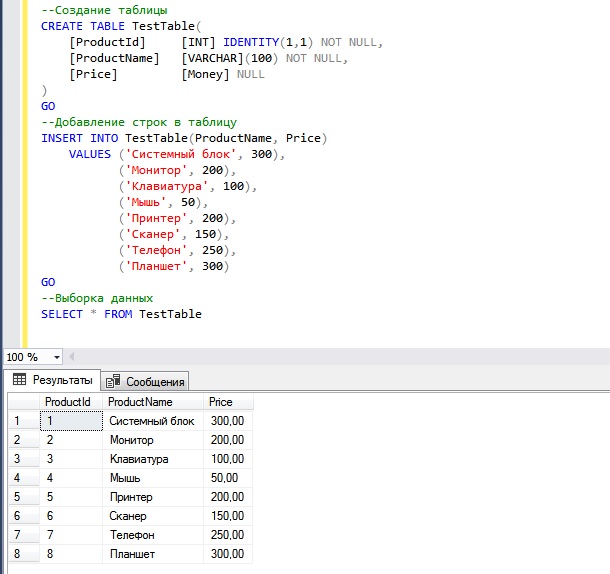
Допустим, у нас есть таблица TestTable, и она содержит следующие данные. В качестве сервера у меня выступает Microsoft SQL Server 2016 Express.
--Создание таблицы
CREATE TABLE TestTable(
IDENTITY(1,1) NOT NULL,
(100) NOT NULL,
NULL
)
GO
--Добавление строк в таблицу
INSERT INTO TestTable(ProductName, Price)
VALUES ('Системный блок', 300),
('Монитор', 200),
('Клавиатура', 100),
('Мышь', 50),
('Принтер', 200),
('Сканер', 150),
('Телефон', 250),
('Планшет', 300)
GO
--Выборка данных
SELECT * FROM TestTable
OFFSET-FETCH – пропуск первых 3 строк
В этом примере мы пропустим первые три строки результирующего набора и вернем все последующие строки. Для этого мы просто напишем OFFSET 3 ROWS после определения инструкции ORDER BY.
--Пропуск первых 3 строк SELECT * FROM TestTable ORDER BY ProductId OFFSET 3 ROWS
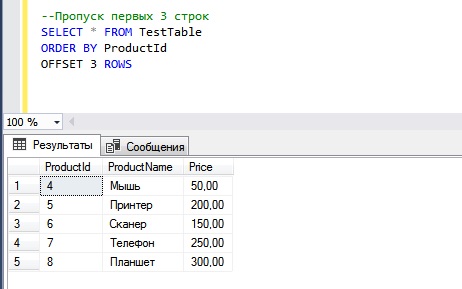
OFFSET-FETCH – пропуск первых 3 строк и возвращение следующих 3
В данном случае мы также пропустим первые три строки, только дополнительно мы еще укажем инструкцию FETCH NEXT 3 ROWS ONLY, которая будет говорить SQL серверу о том, что нужно вернуть не все последующие строки, а только 3 следующие.
Как Вы понимаете, значение 3 в обоих случаях можно изменять на то значение, которое нужно Вам, также вместо константы (т.е. цифры 3) можно подставлять и переменные, и выражения, которые возвращают целое значение.
--Пропуск первых 3 строк и возвращение следующих 3 SELECT * FROM TestTable ORDER BY ProductId OFFSET 3 ROWS FETCH NEXT 3 ROWS ONLY
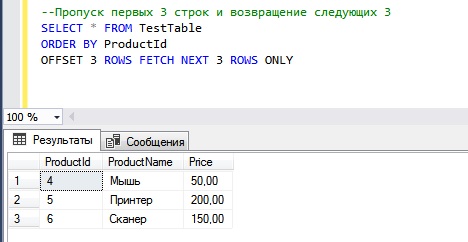
Вот мы с Вами и рассмотрели конструкцию OFFSET-FETCH языка T-SQL, надеюсь, всё было понятно, удачи!
Нравится2Не нравится
Пример — использование ключевого слова LIMIT
Рассмотрим, как использовать в SQLite оператор SELECT LIMIT.
Например:
PgSQL
SELECT employee_id,
last_name,
first_name
FROM employees
WHERE favorite_website = ‘Google.com’
ORDER BY employee_id DESC
LIMIT 5;
|
1 2 3 4 5 6 7 |
SELECTemployee_id, last_name, first_name FROMemployees WHEREfavorite_website=’Google.com’ ORDERBYemployee_idDESC LIMIT5; |
В этом SQLite примере SELECT LIMIT будут выбраны первые 5 записей из таблицы employees, где любимый веб-сайт — ‘Google.com’
Обратите внимание, что результаты сортируются по employee_id в порядке убывания, поэтому это означает, что 5 самых больших значений employee_id будут возвращены оператором SELECT LIMIT
Если в таблице employees есть другие записи со значением веб-сайта Google.com, они не будут возвращены оператором SELECT LIMIT в SQLite.
Если бы мы хотели выбрать 5 самых минимальных значений employee_id вместо самых больших, мы могли бы изменить порядок сортировки следующим образом:
PgSQL
SELECT employee_id,
last_name,
first_name
FROM employees
WHERE favorite_website = ‘Google.com’
ORDER BY employee_id ASC
LIMIT 5;
|
1 2 3 4 5 6 7 |
SELECTemployee_id, last_name, first_name FROMemployees WHEREfavorite_website=’Google.com’ ORDERBYemployee_idASC LIMIT5; |
Теперь результаты будут отсортированы по employee_id в порядке возрастания, поэтому первые 5 наименьших записей employee_id, которые имеют fav_website ‘Google.com’, будут возвращены этим оператором SELECT LIMIT. Никакие другие записи не будут возвращены этим запросом.
CREATE SEQUENCE
Синтаксис
CREATE SEQUENCE sequence_name MINVALUE value MAXVALUE value START WITH value INCREMENT BY value CACHE value;
sequence_name имя последовательности, которую вы хотите создать.
Пример
Oracle PL/SQL
CREATE SEQUENCE supplier_seq
MINVALUE 1
MAXVALUE 999999999999999999999999999
START WITH 1
INCREMENT BY 1
CACHE 20;
|
1 2 3 4 5 6 |
CREATESEQUENCEsupplier_seq MINVALUE1 MAXVALUE999999999999999999999999999 STARTWITH1 INCREMENTBY1 CACHE20; |
Этот код создаст объект последовательность под названием supplier_seq. Первый номер последовательности 1, каждый последующий номер будет увеличиваться на 1 (т.е.. 2,3,4, …). Это будет кэшировать до 20 значений для производительности.
Если вы опустите параметр MAXVALUE, ваша последовательность по умолчанию до:
MAXVALUE 999999999999999999999999999
Таким образом, вы можете упростить CREATE SEQUENCE. Написав следующее:
Oracle PL/SQL
CREATE SEQUENCE supplier_seq
MINVALUE 1
START WITH 1
INCREMENT BY 1
CACHE 20;
|
1 2 3 4 5 |
CREATESEQUENCEsupplier_seq MINVALUE1 STARTWITH1 INCREMENTBY1 CACHE20; |
Теперь, когда вы создали объект последовательности для автонумерации поля счетчика, мы рассмотрим, как получить значение из этого объекта последовательности. Чтобы получить следующее значение, вам нужно использовать NEXTVAL. Например:
supplier_seq.NEXTVAL;
Это позволит извлечь следующее значение из последовательности supplier_seq. Предложение NEXTVAL нужно использовать в SQL запросе. Например:
Oracle PL/SQL
INSERT INTO suppliers
(supplier_id, supplier_name)
VALUES
(supplier_seq.NEXTVAL, ‘Kraft Foods’);
|
1 2 3 4 |
INSERTINTOsuppliers |
Этот isert запрос будет вставлять новую запись в таблицу suppliers (поставщики). Полю Supplier_id будет присвоен следующий номер из последовательности supplier_seq. Поле supplier_name будет иметь значение ‘Kraft Foods’.