Как загрузить русский в экранный диктор?
Содержание:
Настройка экранного диктора Orca.
Теперь необходимо сделать так чтобы Orca запускалась при старте системы. Жмем «Menu» -> «Центр управления» -> «Вспомогательные технологии» и ставим галочку напротив «Включить вспомогательные технологии».
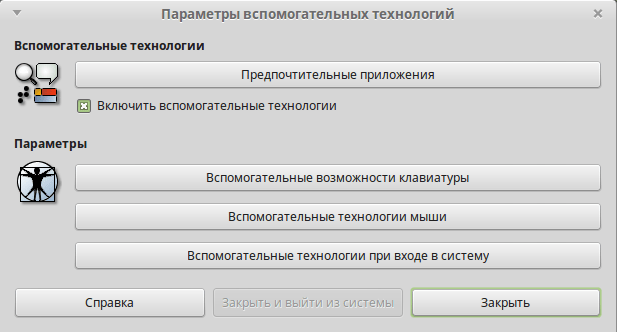
Далее жмем кнопку «Предпочтительные приложения», во вкладке «Вспомогательные технологии» ставим галочку под Orca напротив «Запускать при входе».
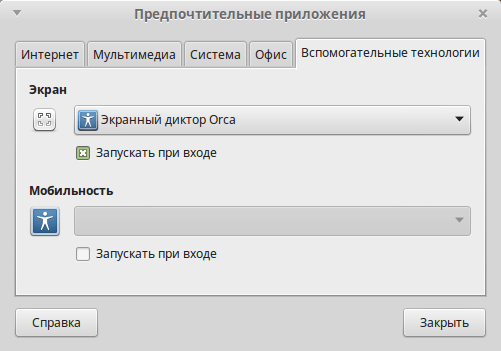
Осталось только перезагрузить компьютер и выбрать RHVoice в настройках Orca. После перезагрузки Orca начнет говорить довольно мерзким голосом. Ее можно настроить из терминала, но удобнее это будет сделать в окне настроек. Чтобы вызвать окно настроек необходимо для начала отключить дополнительную цифровую клавиатуру клавишей NumLock, а потом нажать комбинацию 0+Пробел, где 0 — цифра на дополнительной цифровой клавиатуре. Появится вот такое окно, где во вкладке «Речь» можно будет выбрать синтезатор и голоса к нему.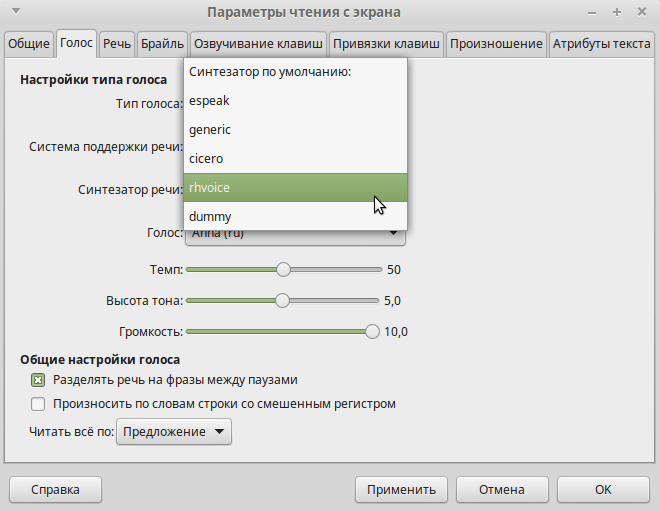
У синтезатора есть целых четыре русских голоса Alexandr, Elena, Irina и Anna. Мне больше всего понравился голос Anna.
Доступные решения
В материале разберём добавление русского голоса на такие программы, как NVDA и Экранный Диктор Windows.Данные программы доступнее остальных, так Экранный Диктор, является предустановленной программой операционной системы Windows? Не требует особых знаний и входит в лицензию системы. А программа NVDA, является уникальным продуктом для голосового доступа к экрану компьютера, она уже ни первый год помогает людям с нарушениями зрения. Главной особенностью программы, можно отметить её бесплатность и широкий спектр возможностей, по решаемой проблеме.
Как было сказано в прошлой статье, существует множество синтезаторов речи. В большинстве они выпускаются в нескольких вариантах, что облегчает выбор для вашего рабочего диктора. Синтезаторы речи можно поделить на две большие группы:
- Коммерческие – выпускаемые по платным лицензиям, имеющие ограничения на пробный период.
- Бесплатные – синтезаторы, предоставляемые пользователям на правах свободного распространения .
Люблю повторять фразу: «Бесплатно, не значит хуже!». В нашем случае эта фраза подходит, как нельзя лучше. Бесплатные синтезаторы речи развиваются и имеют место быть.
RHVoice
Советую попробовать лёгкий, быстрый и грамотный синтезатор речи RHVoice . Данный продукт помимо того что направлен на российских пользователей, распространяется совершенно бесплатно. Радует и тот факт, что данное решение для дикторов не останавливается в развитии, так на протяжении времени выходят новые версии, в которых, конечно, исправляются ошибки и добавляются нововведения.
Для того чтобы установить синтезатор речи RHVoice на свой компьютер, следует определиться с программой диктором. Если Вы будете использовать встроенную программу Windows , то формат скачиваемого файла будет иметь вид .EXE, а если ваш выбор диктора остановился на NVDA, то файл будет оканчиваться на .NVDA.
Установка на Windows
По умолчанию операционная система Windows не имеет русского языка для Экранного диктора, поэтому пользователям придётся самостоятельно дополнить голоса.
, рассмотренного выше, запустите установку двойным щелчком мыши или клавишей клавиатуры – Enter.
Никаких изменений в установочный процесс вносить не потребуется, поэтому сложностей возникнуть не должно!
По завершении установки, откройте настройки Экранного диктора и измените голос. В списке голосов должны появиться несколько русских голосов, таких как: Александр, Елена и Ирина. Сохраните настройки выбора и попробуйте по перемещаться в системе.
Установка на NVDA
В отличии от стандартной программы Windows, программа экранного доступа NVDA имеет предустановленный синтезатор речи с поддержкой русского языка. Только стоит отметить, что качество произношения этого голоса далеко от совершенства. Его можно слышать при установки программы NVDA на свой компьютер.
В последних версиях NVDA было сделано полезное нововведение, которое позволило разрабатывать файлы плагинов и синтезаторов речи с оригинальным расширением, что позволяет быстрее устанавливать любые дополнения на программу.
, запустите установку двойным щелчком мыши или по нажатии клавиши – Enter. В появившемся уведомлении дайте согласие на установку. Подождите пару секунд и согласитесь с перезапуском программы NVDA (при этом Вы услышите характерные звуки выгрузки и запуска программы NVDA).
По окончании установки синтезатор запустится вместе с стартом диктора. Вам останется лишь настроить голоса с вашими предпочтениями!
В качестве бонуса, Вы можете прослушать пару вариантов голосов входящих в состав синтезатора RHVoice.
Голос Александр и Елена:
Сборка и установка RHVoice.
|
1 |
mkdir build cd build |
устанавливаем программы необходимые для сборки
| 1 | sudo apt-get-qinstall git sconsg++libglibmm-2.4-dev libpulse-dev pkg-config |
скачиваем синтезатор речи
| 1 | git clonehttps//github.com/Olga-Yakovleva/RHVoice.git |
заходим в скачанную папку, собираем и устанавливаем
|
1 |
cd RHVoice scons sudo scons install sudo ldconfig sudo cp-ausrlocalbinsd_rhvoiceusrlibspeech-dispatcher-modules |
После команды scons начнется процесс сборки, он довольно долгий. Но результат должен выглядеть следующим образом.
Голос установлен. Теперь необходимо настроить операционную систему, чтобы она могла без проблем работать с синтезатором.
создадим конфигурационный файл
| 1 | sudo nanoetcspeech-dispatchermodulesrhvoice.conf |
внесем в него следующие строчки
|
1 |
RHVoiceDataPath»/usr/local/share/RHVoice» RHVoiceConfigPath»/usr/local/etc/RHVoice/» RHVoicePunctuationMode #RHVoicePunctuationList «@+_» RHVoiceDefaultVoice»Aleksandr» RHVoiceDefaultVariant»Pseudo-English» Debug |
После внесения строк жмем Ctrl+X, подтверждаем изменения написав Y, затем Enter и ещё раз Enter.
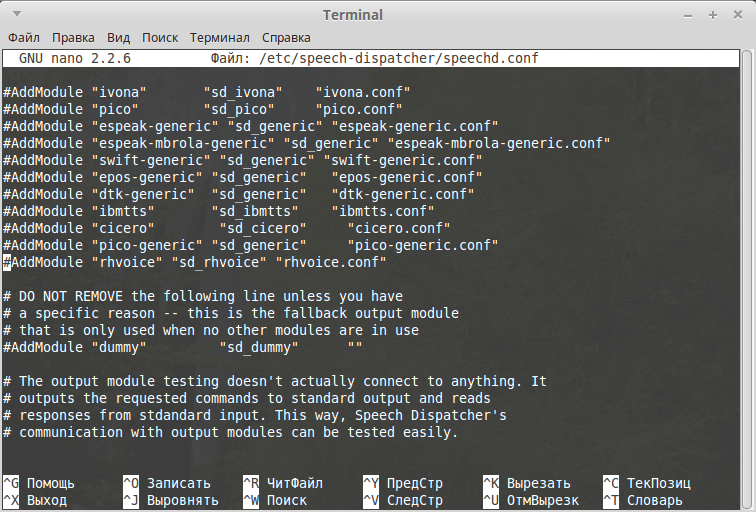
Теперь внесем изменения в ещё один конфигурационный файл.
| 1 | sudo nanoetcspeech-dispatcherspeechd.conf |
ищем строки где добавляются модули (строка начинается с #AddModule) речевых синтезаторов и добавляем новый модуль
| 1 | #AddModule «rhvoice» «sd_rhvoice» «rhvoice.conf» |
вот что получается в итоге
Список синтезаторов речи:
1. Acapela
Acapela — один из самых распространенных речевых синтезаторов во всем мире. Программа распознает и озвучивает тексты более, чем на тридцати языках. Русский язык поддерживается двумя голосами: мужской голос — Николай, женский — Алена. Женский голос появился значительно позднее мужского и является более усовершенствованным.
Прослушать, как звучат голоса, можно на официальном сайте программы. Достаточно лишь выбрать язык и голос, и набрать свой небольшой текст.
Кстати, для мужского голоса был разработан отдельный словарь ударений, что позволяет достичь еще большей четкости произношения.
Установка программы проходит без проблем. Разработаны версии для операционных систем Windows, Linux, Mac, а также для мобильных ОС Android u IOS.
Программа платная, скачать ее можно с официального
2. Vokalizer
Вторым в нашем списке, но не по популярности является движок Милена от разработчика программы Vocalizer компании Nuance. Голос звучит очень естественно, речь чистая
Есть возможность установить различные словари, а также подкорректировать громкость, скорость и ударение, что не маловажно. Как и в случае с Акапелой, программа имеет различные версии для мобильных, автомобильных и компьютерных приложений
Прекрасно подходит для чтения книг.
Скачать все версии Vokalizer и русскоязычный движок Милена можно на производителя программы.
3. RHVoice
Синтезатор речи RHVoice был разработан Ольгой Яковлевой. Программа озвучивает русские тексты тремя голосами: Елена, Ирина и Александр. Подробнее об установке и применении, а также прослушать голоса Вы сможете в прошлой статье
Код синтезатора открыт для всех, программы же абсолютно бесплатны. RHVoice выпущена в двух вариантах: как отдельная программа, так и как приложение к NVDA. Все версии можно скачать с разработчика.
4. ESpeak
Первая версия бесплатного синтезатора речи eSpeak была выпущена в 2006 году. С тех пор компания-разработчик постоянно выпускает все более усовершенствованные версии. Последняя версия была представлена в конце весны две тысячи тринадцатого года.
- Microsoft Windows,
- Mac OS X,
- Linux,
- RISC OS
Возможна также компиляция кода для Windows Mobile, но делать ее придется самостоятельно. А вот с мобильной ОС Android программа работает без проблем, хотя русские словари еще не до конца разработаны. Русскоязычных голосов много, можно выбрать на свой вкус.
Для разработчиков будет интересно узнать, что C++ код программы доступен в сети. Скачать программу, а также посмотреть ее код можно на
5. Festival
Festival — это целая система распознавания и синтеза речи, которая была разработана в эдинбургском университете. Программы и все модули абсолютно бесплатно и распространяются по системе open source. Скачать их и ознакомиться с демо-версиями можно на официальномуниверситета Эдинбурга.
Русский голос представлен в одном варианте, но звучание довольно хорошее и ясное, без акцента и с правильной расстановкой ударений. К сожалению, программа пока может быть установлена только в среде API, Linux. Также есть модуль для работы в Mac OS, но русский язык пока поддерживается не очень хорошо.
Как включить и выключить экранный диктор в Windows 10
woodhummer 29.01.2016 — 07:20 Практикум
Про такую полезную программу, как «Экранный диктор» мы уже писали раньше. В Windows 10 управление этим приложение несколько изменилось. Рассмотрим ответы на два наиболее частых вопроса пользователей: «Как включить и выключить экранный диктор».
Включение экранного диктора
- На клавиатуре нажимаем комбинацию клавиш «Win+Enter».
- В окне «Выполнить» (Win+R) вводим команду narrator и кликаем ОК.
- Кликаем иконку поиска, пишем в строке narrator, запускаем приложение.
- Запускаем командную строку и в ответ на системное приглашение вводим команду narrator.
- Открываем Windows PowerShell, вводим narrator и нажимаем Enter.
- Кликаем «Пуск»-«Все приложения», находим группу «Спец. Возможности», а в ней «Экранный диктор».
- Кликаем «Пуск»-«Параметры»-«Специальные возможности». Переходим в подраздел «Экранный диктор» и выставляем соответствующий ползунок в положение «Вкл».
- В классической панели управления выбираем «Центр специальных возможностей», вить соответствующее расширение. В следующем окне кликаем «Включить».
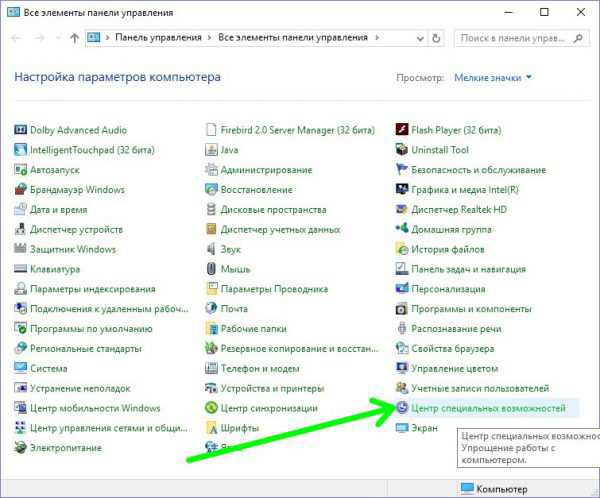
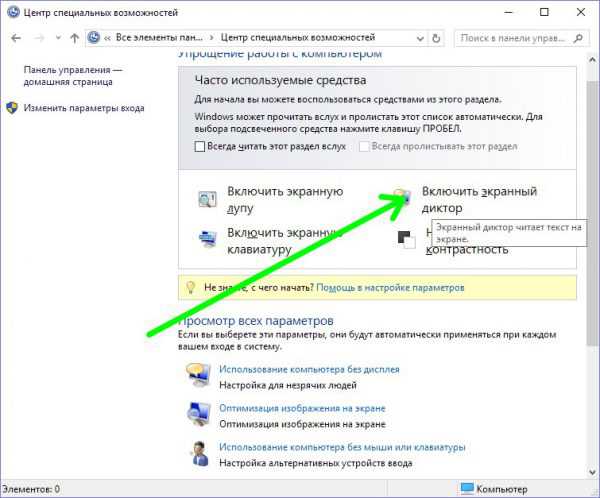
Выключение экранного диктора
- Для того чтобы закрыть экранный диктор, нажимаем комбинацию клавиш Caps Lock+Esc.
- Кликаем правой кнопкой на иконку экранного диктора в панели задач и выбираем «Закрыть окно».
- Кликаем иконку экранного диктора в таскбаре, открываем «Настройки» и там выбираем «Выход».
P.S.
Мы рассмотрели несколько различных способов, с помощью которых можно включить и выключить экранный диктор в Windows 10.
обновлено: 29.01.2016
оставить комментарий
RHVoseдля NVDA
Чтец экрана NVDA может использовать синтезатор RHVose, установленный в операционную систему как SAPI5, так и в качестве плагина NVDA, то есть дополнения. В последнем варианте синтезатор будет присутствовать как в установочном варианте, так и при создания переносной копии. К тому же, в этом случае можно добиться более высокой скорости чтения синтезатором.
Компоненты установки
Если установить только голосовой пакет русского языка и хотя бы один русский голос, то английские буквы будут читаться в латинской транскрипции.
Если установить дополнительно английский языковой пакет, то включится псевдоанглийское проговаривание слов.
Рекомендую устанавливать все голоса для каждого из языков, так как места они занимают мало, а возможности настройки при этом расширяются.
Например, для русского и английского языков в этом случае появилась возможность выбора не одного голоса синтезатора, а ещё двух пар:
Александр+Alan;
Елена+Clb.
При чтении голоса в такой паре переключаются между собой автоматически.
Конфигурационный файл
Первое время начинающего устраивает та скорость чтения, которая доступна после установки. Но со временем хочется её увеличить ещё. Это возможно только в случае настройки с помощью конфигурационного файла. При этом имейте ввиду, что скорость чтения при одних и тех же настройках, но для разных вариантов исполнения синтезатора будет несколько отличаться. О замерах скорости чтения можно прочитать .
максимальной скорости можно достичь, если сделать настройки в специальном файле и расположить его по тому пути, откуда синтезатор будет брать настройки после очередного запуска.
Сам файл конфигурации можно взять по пути, для установочной версии:
«C»:\Program Files\RHVoice\config-examples\RHVoice.ini»
Отсюда файл копируют, настраивают и размещают в папке, откуда синтезатор RHVoice возьмёт настройки сразу после очередного запуска.
для SAPI5 файл «RHVoice.ini» копируется в папку RHVoice расположенную примерно по такому пути —
C:\Users\Администратор\AppData\Roaming\RHVoice
Учтите, что на вашем компе диск «C:» и имя пользователя «Администратор» могут быть другими. А папка «ApplicationData» относится к скрытым папкам и чтобы её увидеть, нужно в «свойствах папки» отметить галкой «показывать скрытые файлы и папки»
В портабельной версии программы файл настроек лежит по пути:
\nvda\userConfig\RHVoice-config\RHVoice.ini
В самом файле есть комментарии о том, что и для чего можно менять, а на сайте GitHub есть рекомендации от создателя синтезатора.
В архивах на Яндекс-диске, ссылки на которые были выше по тексту, есть настроенный конфигурационный файл и батник для его автоматического размещения в нужную папку для установочных вариантов программ.
Решение некоторых проблем, возникающих при настройке синтезатора RHVoice
Перед установкой новой версии старые версии синтезатора лучше удалить, с последующей очисткой остатков из Program» Files и из папок пользователя локальной учётной записи.
Или, как советует пользователь Kvark, нажмите windows+r и в появившийся диалог вставьте
%appdata%\nvda\addons
В открывшемся каталоге найдите папку RHVoice.pendingInstall и переименуйте её в RHVoice. Далее перезагрузите NVDA и пробуйте в диалоге выбора синтезатора (NVDA+control+s) найти RHVoice.
Этот и другие советы можно прочитать в папке «Вопрос-ответ», в сборнике «Азы незрячего», который выкладывается для свободного скачивания на этом сайте.
Documentation
First create TTS object:
from rhvoice_wrapper import TTS tts = TTS(threads=1)
You may set options when creating or through variable environments (UPPER REGISTER). Options override variable environments. To set the default value use :
- threads or THREADED. If equal to , created one thread object, if more running in multiprocessing mode and create a lot of processes. Default .
-
force_process or PROCESSES_MODE: If engines run in multiprocessing mode, if in threads mode.
Default if threads == 1, else .
Threads mode and threads > 1 causes a segmentation faults or may return corrupted data - lib_path or RHVOICELIBPATH: Path to RHVoice library. Default in Linux, in macOS and in Windows.
- data_path or RHVOICEDATAPATH: Path to folder, containing voices and languages folders. Default .
- config_path or RHVOICECONFIGPATH: Path to folder, contain RHVoice.conf in linux and RHVoice.ini in windows. Default .
- resources or RHVOICERESOURCES: A list of paths to language and voice data. It should be used when it is not possible to collect all the data in one place. Default .
- lame_path or LAMEPATH: Path to , optional. Lame must be present for support. Default .
- opus_path or OPUSENCPATH: Path to , optional. File must be present for support. Default .
- flac_path or FLACPATH: Path to , optional. File must be present for support. Default .
- quiet or QUIET: If don’t info output. Default .
- stream or RHVOICESTREAM: Processing and sending chunks soon as possible, otherwise processing and sending only full data including length: will return one big chunk, formats other than and will be generated much slower. Default .
Usage
Start synthesis generator and get audio data, chunk by chunk:
def generator_audio(text, voice='anna', format_='wav', buff=4096, sets=None):
with tts.say(text, voice, format_, buff, sets) as gen:
for chunk in gen:
yield chunk
Or get all audio data in one big chunk:
data = tts.get('Hello world!', format_='wav')
print('data size: ', len(data), ' bytes')
subprocess.check_output(, input=data)
Or just save to file:
tts.to_file(filename='esperanto.ogg', text='Saluton mondo', voice='spomenka', format_='opus', sets=None)
is output audio format. Must be present in .
is a voice of speaker. Must be present in .
equal , more priority.
may set as dict containing synthesis parameters as in .
This parameters only work for current phrase. Default .
If equal , for pcm and wav chunks return as is (probably little faster).
For others used default chunk size (4 KiB).
Text as iterable object
If iterable object, all its fragments will processing successively.
This is a good method for processing incredibly large texts.
Remember, the generator cannot be transferred to another process. Example:
def _text():
with open('wery_large_book.txt') as fp:
text = fp.read(5000)
while text:
yield text
text = fp.read(5000)
def generator_audio():
with tts.say(_text()) as gen:
for chunk in gen:
yield chunk
Other methods
set_params
Changes voice synthesizer settings:
tts.set_params(**kwargs)
Allow: , , , , , , , , , , . See RHVoice documentation for details.
Return if change, else .
get_params
Get voice synthesizer settings:
tts.get_params(param=None)
If param is return all settings in , else parameter value by name. If parameter not found return .
join
Join thread or processes. Don’t use object after join:
tts.join()
- : List of supported formats, and always present.
- : Number of synthesis threads.
- : If , TTS running in multiprocessing mode.
- : List of supported voices.
- : List of supported voice profiles.
- : Dictionary of supported voices with voices information.
- : Supported RHVoice library version. If different from , may incorrect work.
- : RHVoice library version.
- : Dictionary of external calls, as it is.
Выводим текст через NVDA
Мы научились озвучивать приложение с помощью установленных в системе синтезаторов. Но что если большинству пользователей эта фишка не нужна, и мы хотим добавить речь исключительно как опцию для слабовидящих? В таком случае не обязательно писать код озвучивания: достаточно передать текст интерфейса другому приложению — экранному диктору.
Одна из самых популярных программ экранного доступа в Windows — бесплатная и открытая NVDA. Для связи с ней к нашему приложению нужно привязать библиотеку nvdaControllerClient (есть варианты для 32- и 64-разрядных систем). Узнавать разрядность системы вы уже умеете.
Еще для работы с экранным диктором нам понадобятся модули ctypes и time. Создадим файл nvda.py, где напишем модуль связи с NVDA:
import time, ctypes, platform
# Загружаем библиотеку клиента NVDA
bit = platform.architecture()
if bit == ’32bit’:
clientLib = ctypes.windll.LoadLibrary(‘nvdaControllerClient32.dll’)
elif bit == ’64bit’:
clientLib = ctypes.windll.LoadLibrary(‘nvdaControllerClient64.dll’)
else:
errorMessage=str(ctypes.WinError(res))
ctypes.windll.user32.MessageBoxW(0,u»Ошибка! Не удалось определить разрядность системы!»,0)
# Проверяем, запущен ли NVDA
res = clientLib.nvdaController_testIfRunning()
if res != 0:
errorMessage=str(ctypes.WinError(res))
ctypes.windll.user32.MessageBoxW(0,u»Ошибка: %s»%errorMessage,u»нет доступа к NVDA»,0)
def say(msg):
clientLib.nvdaController_speakText(msg)
time.sleep(1.0)
def close_speech():
clientLib.nvdaController_cancelSpeech()
Теперь эту заготовку можно применить в коде основной программы:
import nvda
nvda.say(‘Начать игру’)
# … другие реплики или сон
nvda.close_speech()
Если NVDA неактивна, после запуска кода мы увидим окошко с сообщением об ошибке, а если работает — услышим от нее заданный текст.
Плюс подхода в том, что незрячий пользователь будет слышать тот голос, который сам выбрал и настроил в NVDA.