Реляционная субд
Содержание:
Настраиваем SSD
В частности, SSD требуют действий, называемых непереводимым словом overprovisioning. Дело в том, что в SSD присутствует слой трансляции адресов. Адреса блоков, видные операционной системе, совсем не соответствуют физическим блокам во флеш-памяти. Как ты знаешь, число циклов перезаписи у флеш-памяти ограничено. К тому же операция записи состоит из двух этапов: стирания (часто — сразу нескольких блоков) и собственно записи. Поэтому, для обеспечения долговечности накопителя (равномерного износа) и хорошей скорости записи, контроллер диска чередует физические блоки памяти при записи. Когда операционная система пишет блок по какому-то адресу, физически запись происходит на некий чистый свободный блок памяти, а старый блок помечается как доступный для последующего (фонового) стирания. Для всех этих манипуляций контроллеру диска нужны свободные блоки, чем больше, тем лучше. Заполненный на 100% SSD может работать весьма медленно.
Свободные блоки могут получиться несколькими способами. Можно с помощью команды hdparm (с ключом ‘-N’) указать количество секторов диска, видимых операционной системой. Остальное будет в полном распоряжении контроллера. Однако это работает не на всяком железе (в AWS EC2, например, не работает). Другой способ — оставить не занятое разделами место на диске (имеются в виду разделы, создаваемые, например, fdisk). Контроллер достаточно умен, чтобы задействовать это место. Третий способ — использовать файловые системы и версии ядра, которые умеют сообщать контроллеру о свободных блоках. Это та самая команда TRIM. На нашем железе хватило hdparm, мы отдали на растерзание контроллеру 20% от общего объема дисков.
Для SSD важен также планировщик ввода-вывода. Это такая подсистема ядра, которая группирует и переупорядочивает операции ввода-вывода (в основном записи на диск) с целью повысить эффективность. По умолчанию линукс использует CFQ (Completely Fair Queuing), который старается переставить операции записи так, чтобы записать как можно больше блоков последовательно. Это хорошо для обычных вращающихся (так и говорят — spinning :)) дисков, потому что для них скорость линейного доступа заметно выше доступа к случайным блокам (головки нужно перемещать). Но для SSD линейная и случайная запись — одинаково эффективны (теоретически), и работа CFQ только вносит лишние задержки. Поэтому для SSD-дисков нужно включать другие планировщики, например NOOP, который просто выполняет команды ввода-вывода в том порядке, в каком они поступили. Переключить планировщик можно, например, такой командой: «echo noop > /sys/block/sda/queue/scheduler», где sda — твой диск. Справедливости ради стоит упомянуть, что свежие ядра сами умеют определять SSD-накопители и включать для них правильный планировщик.
Любая СУБД любит интенсивно писать на диск, а также интенсивно читать. А Linux очень любит делать read-ahead, упреждающее чтение данных, — в надежде, что, раз ты прочитал этот блок, ты захочешь прочитать и несколько следующих. Однако с СУБД, и особенно при случайном чтении (а этот как раз наш вариант), этим надеждам не суждено сбыться. В результате имеем никому не нужное чтение и использование памяти. Разработчики MongoDB рекомендуют по возможности уменьшить значение read-ahead. Сделать это можно командой «blockdev —setra 8 /dev/sda», где sda — твой диск.
Любая СУБД любит открывать много-много файлов. Поэтому необходимо заметно увеличить лимиты nofile (количество доступных файловых дескрипторов для пользователя) в файле /etc/security/limits.conf на значение сильно больше 4k.
Также возник интересный вопрос: как использовать четыре SSD? Если Aerospike просто подключает их как хранилища и как-то самостоятельно чередует доступ к дискам, то другие БД подразумевают, что у них есть лишь один каталог с данными. (В некоторых случаях можно указать и несколько каталогов, но это не предполагает чередования данных между ними.) Пришлось создавать RAID 0 (с чередованием) с помощью утилиты mdadm. Я полагаю, что можно было бы поиграть с LVM, но производители СУБД описывают только использование mdadm.
Как хранится информация в БД¶
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т. д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
1. Создадим для сайта новую БД и дадим ей название .
2. Создадим в БД новую таблицу с именем и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
3. При сохранении формы будем добавлять в таблицу новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение.
А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой.
Что это за связи?
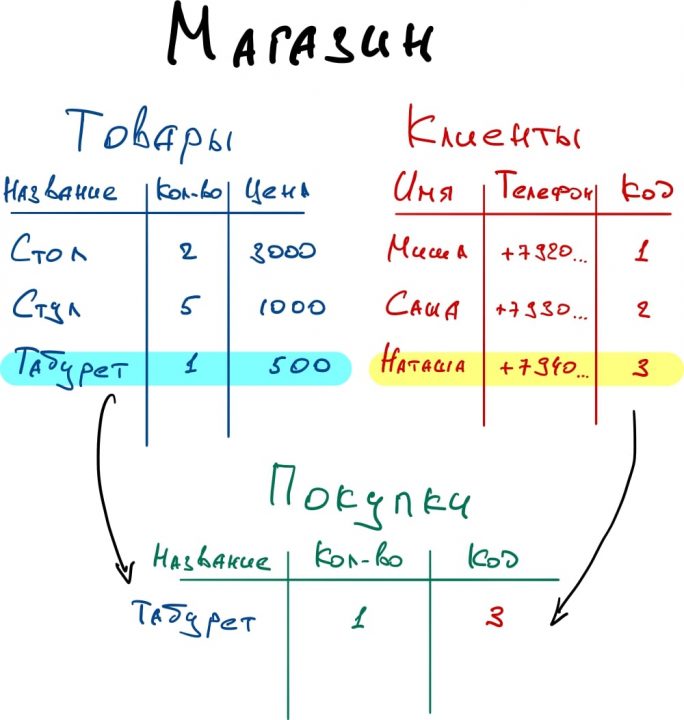
Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации.
В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными.
Но можно поступить иначе:
- Создать новую таблицу с именем .
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа , чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов.
В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот!
Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Сильные и слабые стороны NoSQL
Сильные стороны
- Возможность хранения больших объемов неструктурированной информации. В NoSQL нет ограничений на типы хранимых данных, а при необходимости можно добавлять новые типы данных.
- NoSQL-базы лучше поддаются масштабированию. Хотя масштабирование поддерживается и в SQL-базах, это требует гораздо больших затрат человеческих и аппаратных ресурсов.
Вычислительные мощности железа ограничены. А цена нескольких простых серверов меньше, чем одного высокопроизводительного. Горизонтальное масштабирование( несколько независимых машин соединяются вместе и каждая из них обрабатывает свою часть запросов) позволяет увеличить мощность кластера добавлением нового сервера.
Рассчитанные на работу в распределенных системах NoSQL хранилища проектируются так, что все процедуры распределения данных и обеспечения отказоустойчивости выполняются NoSQL базой. - Ключевые преимущества NoSQL баз в распределенных системах заключаются в процедурах шаринга и репликации.
Репликация — это копирование обновленных данных на другие сервера. Это позволяет добиться большей отказоустойчивости и масштабируемости системы.
Тип master-slave — это один мастер-сервер и несколько дочерних серверов. Запись может производиться только на мастер-сервер, который передает изменения на дочерние машины. Этот тип репликации даёт хорошую масштабируемость на чтение, но не на запись, так как запись идет только на мастер-сервер. Этот тип репликации имеет свой минус — в случае неисправности мастер-сервера нужно выбирать(автоматически или вручную) новый мастер-сервер.
Второй тип — peer-to-peer — все узлы равны в возможности обслуживать запросы на чтение и запись. Информация о обновлении данных передается от сервера к серверу.
Шаринг — это разделение информации по разным узлам сети. Каждый узел отвечает только за определенный набор данных и обрабатывает запросы, относящиеся только к этому набору данных. NoSQL предполагает, что шаринг реализует сама база данных, он будет производиться автоматически. - Использование облачных вычислений и хранилищ. Использование для тестирования и разработки локального оборудования, а затем перенос системы в облако.
- Быстрая разработка. NoSQL базы данных не требуют большого объема подготовительных действий, который нужен для реляционных баз.
- Многие NoSQL решения имеют ограниченную функциональность, т.к решают определенные задачи. Поэтому для работы с такими базами данных не требуется глубоких знаний SQL-запросов. Это сильно снижает входной порог для начала работы с NoSQL хранилищами.
- Более простые технологии запросов в NoSQL позволяют совершать меньше ошибок. Хотя и существует альтернатива упрощения работы с базой данных — технология ORM, позволяющая автоматически транслировать операции с объектами в запросы к базе данных, но подобные решения могут работать неэффективно или создавать множество ненужных и ошибочных запросов в некоторых случаях.
- Собственные языки запросов современных NoSQL хранилищ гораздо больше подходят для выполнения простых манипуляций с базой данных.
Слабые стороны
- Приложение сильно привязывается к конкретной СУБД. Язык SQL универсален для всех реляционных хранилищ и поэтому в случае смены СУБД не придётся переписывать весь код.
- Ограниченная емкость встроенного языка запросов. SQL имеет очень богатую историю и множество стандартов. Это очень мощный и сложный инструмент для операций с данными и составления отчетов. Практически все языки запросов и методы API хранилищ NoSQL были созданы на основе тех или иных функций SQL, но они имеют куда меньшую функциональность.
- Процесс создания реляционного хранилища включает в себя этап проектирования модели данных. На этой стадии можно оценить узкие места выбранной стратегии и спроектировать действительно надежную и удобную систему. NoSQL решения не требуют определять схему базы данных перед началом работы, поэтому в процессе разработки можно наткнуться на непредвиденные трудности, которые могут привести к отказу от данного NoSQL решения.
- Трудности быстрого перехода с одной нереляционной базы данных на другую.
- Приходится разрабатывать собственные инструменты для работы с БД.
- Специалистов с хорошим знанием SQL гораздо проще найти, в то время когда спецификой работы API некоторых NoSQL решений на серьёзном уровне мало кто увлекается — это значит, что многие специфические моменты оператору базы данных придется осваивать “на ходу”.
История
Реляционные системы берут свое начало в математической теории множеств. Эдгар Кодд, сотрудник исследовательской лаборатории корпорации IBM в Сан-Хосе, по существу, создал и описал концепцию реляционных баз данных в своей основополагающей работе «Реляционная модель для крупных, совместно используемых банков данных» (A Relational Model of Data for Large Shared Data Banks. Communications of the ACM, июнь 1970).
Нечеткость многих терминов, используемых в сфере обработки данных, заставила Кодда отказаться от них и придумать новые или дать более точные определения существующим. Так, он не мог использовать широко распространенный термин «запись», который в различных ситуациях может означать экземпляр записи, либо тип записей, запись в стиле Кобола (которая допускает повторяющиеся группы) или плоскую запись (которая их не допускает), логическую запись или физическую запись, хранимую запись или виртуальную запись и т.д. Вместо этого он использовал термин «кортеж длины n» или просто «кортеж», которому дал точное определение.
Кодд предложил модель, которая позволяет разработчикам разделять свои базы данных на отдельные, но взаимосвязанные таблицы, что увеличивает производительность, но при этом внешнее представление остается тем же, что и у исходной базы данных. С тех пор Кодд считается отцом-основателем отрасли реляционных баз данных. Кодд сформулировал 12 правил для реляционных баз данных, большинство которых касаются целостности и обновления данных, а также доступа к ним.
Структура реляционной модели данных
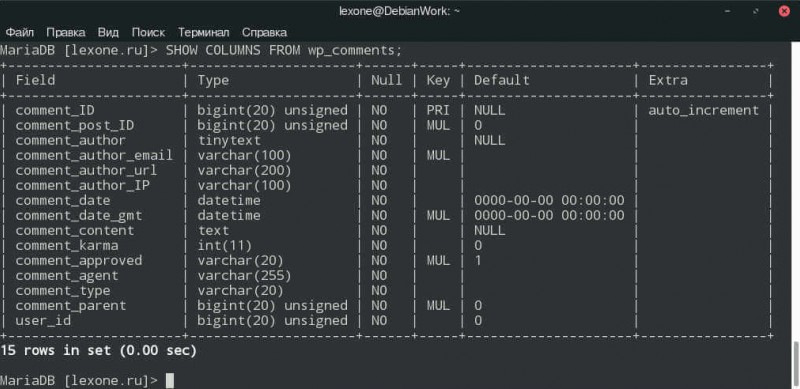
При табличной организации данных отсутствует иерархия элементов. Строки и столбцы могут быть просмотрены в любом порядке, поэтому высока гибкость выбора любого подмножества элементов в строках и столбцах. Любая таблица в реляционной базе состоит из строк, которые называют записями, и столбцов, которые называют полями. На пересечении строк и столбцов находятся конкретные значения данных. Для каждого поля определяется множество его значений.
В реляционной модели данных применяются разделы реляционной алгебры, откуда и была заимствованна соответствующая терминология.В реляционной алгебре поименованный столбец отношения называется атрибутом, а множество всех возможных значений конкретного атрибута – доменом. Строки таблицы со значениями разных атрибутов называют кортежами. Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). Так ключевое поле – это такое поле, значения которого в данной таблице не повторяется. В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Записи в таблице хранятся упорядоченными по ключу. Ключ может быть простым, состоящим из одного поля, и сложным, состоящим из нескольких полей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Кроме первичного ключа в таблице могут быть вторичные ключи, называемые еще внешними ключами, или индексами. Индекс – это поле или совокупность полей, чьи значения имеются в нескольких таблицах и которое является первичным ключом в одной из них. Значения индекса могут повторяться в некоторой таблице. Индекс обеспечивает логическую последовательность записей в таблице, а также прямой доступ к записи.
По первичному ключу всегда отыскивается только одна строка, а по вторичному – может отыскиваться группа строк с одинаковыми значениями первичного ключа. Ключи нужны для однозначной идентификации и упорядочения записей таблицы, а индексы для упорядочения и ускорения поиска.
Индексы можно создавать и удалять, оставляя неизменным содержание записей реляционной таблицы. Количество индексов, имена индексов, соответствие индексов полям таблицы определяется при создании схемы таблицы.
Индексы позволяют эффективно реализовать поиск и обработку данных, формирую дополнительные индексные файлы. При корректировке данных автоматически упорядочиваются индексы, изменяется местоположение каждого индекса согласно принятому условию (возрастанию или убыванию значений). Сами же записи реляционной таблицы не перемещаются при удалении или включении новых экземпляров записей, изменении значений их ключевых полей.
С помощью индексов и ключей устанавливаются связи между таблицами. Связь устанавливается путем присвоения значений внешнего ключа одной таблицы значениям первичного ключа другой. Группа связанных таблиц называется схемой данных. Информация о таблицах, их полях, ключах и т.п. называется метаданными.