Обзор программ для администрирования баз данных sqlite
Содержание:
- Situations Where A Client/Server RDBMS May Work Better
- 2.3. Registers
- 4.1. Sort Order
- Special Services (details below)
- Исключения SQLite3
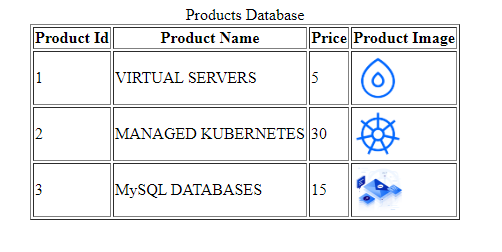
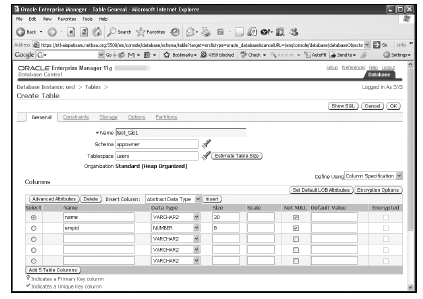
- Create a Table
- Basic SQLite tutorial
- Устранение неполадок при открытии файлов SQLITE
- Установка SQLite на Mac OS X
- Connect To Database
- Testing Services
- 3.1. Determination Of Column Affinity
- Compiling
- Version Control
- 2019: Возможность взлома iPhone через уязвимости в SQLite
- 2.5. Subroutines, Coroutines, and Subprograms
- UPDATE Operation
- Obtaining The Code
- 16.4. SQLite Archive Insert And Update Commands
- Further Information
- C/C++ Interface APIs
Situations Where A Client/Server RDBMS May Work Better
-
Client/Server Applications
If there are many client programs sending SQL to the same
database over a network, then use a client/server database
engine instead of SQLite. SQLite will work over a network filesystem,
but because of the latency associated with most network filesystems,
performance will not be great. Also, file locking logic is buggy in
many network filesystem implementations (on both Unix and Windows).
If file locking does not work correctly,
two or more clients might try to modify the
same part of the same database at the same time, resulting in
corruption. Because this problem results from bugs in
the underlying filesystem implementation, there is nothing SQLite
can do to prevent it.A good rule of thumb is to avoid using SQLite
in situations where the same database will be accessed directly
(without an intervening application server) and simultaneously
from many computers over a network. -
High-volume Websites
SQLite will normally work fine as the database backend to a website.
But if the website is write-intensive or is so busy that it requires
multiple servers, then consider using an enterprise-class client/server
database engine instead of SQLite. -
Very large datasets
An SQLite database is limited in size to 281 terabytes
(247 bytes, 128 tibibytes).
And even if it could handle larger databases, SQLite stores the entire
database in a single disk file and many filesystems limit the maximum
size of files to something less than this. So if you are contemplating
databases of this magnitude, you would do well to consider using a
client/server database engine that spreads its content across multiple
disk files, and perhaps across multiple volumes. -
High Concurrency
SQLite supports an unlimited number of simultaneous readers, but it
will only allow one writer at any instant in time.
For many situations, this is not a problem. Writers queue up. Each application
does its database work quickly and moves on, and no lock lasts for more
than a few dozen milliseconds. But there are some applications that require
more concurrency, and those applications may need to seek a different
solution.
2.3. Registers
Every bytecode program has a fixed (but potentially large) number of
registers. A single register can hold a variety of objects:
- A NULL value
- A signed 64-bit integer
- An IEEE double-precision (64-bit) floating point number
- An arbitrary length strings
- An arbitrary length BLOB
- A RowSet object (See the , , and
opcodes) - A Frame object (Used by — see )
A register can also be «Undefined» meaning that it holds no value
at all. Undefined is different from NULL. Depending on compile-time
options, an attempt to read an undefined register will usually cause
a run-time error. If the code generator (sqlite3_prepare_v2())
ever generates a prepared statement that reads an Undefined register,
that is a bug in the code generator.
Registers are numbered beginning with 0.
Most opcodes refer to at least one register.
The number of registers in a single prepared statement is fixed
at compile-time. The content of all registers is cleared when
a prepared statement is reset or
finalized.
The internal Mem object stores the value for a single register.
The abstract sqlite3_value object that is exposed in the API is really
just a Mem object or register.
4.1. Sort Order
The results of a comparison depend on the storage classes of the
operands, according to the following rules:
-
A value with storage class NULL is considered less than any
other value (including another value with storage class NULL). -
An INTEGER or REAL value is less than any TEXT or BLOB value.
When an INTEGER or REAL is compared to another INTEGER or REAL, a
numerical comparison is performed. -
A TEXT value is less than a BLOB value. When two TEXT values
are compared an appropriate collating sequence is used to determine
the result. -
When two BLOB values are compared, the result is
determined using memcmp().
Special Services (details below)
| 9. |
TH3 Testing Support. The TH3 test harness is an aviation-grade test suite for SQLite. SQLite developers can run TH3 on specialized hardware and/or using specialized compile-time options, according to customer specification, either remotely or on customer premises. Pricing for this services is on a case-by-case basis depending on requirements. |
call | More InfoRequest A Quote |
-
TH3 Testing Support.
The TH3 test harness
is an aviation-grade test suite for SQLite. SQLite developers
can run TH3 on specialized hardware and/or using specialized
compile-time options, according to customer specification,
either remotely or on customer premises. Pricing for this
services is on a case-by-case basis depending on requirements.Cost: call
More Info
Request A Quote
Исключения SQLite3
Исключением являются ошибки времени выполнения скрипта. При программировании на Python все исключения являются экземплярами класса производного от BaseException.
В SQLite3 у есть следующие основные исключения Python:
DatabaseError
Любая ошибка, связанная с базой данных, вызывает ошибку DatabaseError.
IntegrityError
IntegrityError является подклассом DatabaseError и возникает, когда возникает проблема целостности данных, например, когда внешние данные не обновляются во всех таблицах, что приводит к несогласованности данных.
ProgrammingError
Исключение ProgrammingError возникает, когда есть синтаксические ошибки или таблица не найдена или функция вызывается с неправильным количеством параметров / аргументов.
OperationalError
Это исключение возникает при сбое операций базы данных, например, при необычном отключении. Не по вине программиста.
NotSupportedError
При использовании некоторых методов, которые не определены или не поддерживаются базой данных, возникает исключение NotSupportedError.
Create a Table
Following C code segment will be used to create a table in the previously created database −
#include <stdio.h>
#include <stdlib.h>
#include <sqlite3.h>
static int callback(void *NotUsed, int argc, char **argv, char **azColName) {
int i;
for(i = 0; i<argc; i++) {
printf("%s = %s\n", azColName, argv ? argv : "NULL");
}
printf("\n");
return 0;
}
int main(int argc, char* argv[]) {
sqlite3 *db;
char *zErrMsg = 0;
int rc;
char *sql;
/* Open database */
rc = sqlite3_open("test.db", &db);
if( rc ) {
fprintf(stderr, "Can't open database: %s\n", sqlite3_errmsg(db));
return(0);
} else {
fprintf(stdout, "Opened database successfully\n");
}
/* Create SQL statement */
sql = "CREATE TABLE COMPANY(" \
"ID INT PRIMARY KEY NOT NULL," \
"NAME TEXT NOT NULL," \
"AGE INT NOT NULL," \
"ADDRESS CHAR(50)," \
"SALARY REAL );";
/* Execute SQL statement */
rc = sqlite3_exec(db, sql, callback, 0, &zErrMsg);
if( rc != SQLITE_OK ){
fprintf(stderr, "SQL error: %s\n", zErrMsg);
sqlite3_free(zErrMsg);
} else {
fprintf(stdout, "Table created successfully\n");
}
sqlite3_close(db);
return 0;
}
When the above program is compiled and executed, it will create COMPANY table in your test.db and the final listing of the file will be as follows −
-rwxr-xr-x. 1 root root 9567 May 8 02:31 a.out -rw-r--r--. 1 root root 1207 May 8 02:31 test.c -rw-r--r--. 1 root root 3072 May 8 02:31 test.db
Basic SQLite tutorial
This section presents basic SQL statements that you can use with SQLite. You will first start querying data from the sample database. If you are already familiar with SQL, you will notice the differences between SQL standard and SQL dialect used in SQLite.
Section 3. Filtering data
- Select Distinct – query unique rows from a table using the clause.
- Where – filter rows of a result set using various conditions.
- Limit – constrain the number of rows returned by a query and how to get only the necessary data from a table.
- Between – test whether a value is in a range of values.
- In – check if a value matches any value in a list of values or subquery.
- Like – query data based on pattern matching using wildcard characters: percent sign () and underscore ().
- Glob – determine whether a string matches a specific UNIX-pattern.
- IS NULL – check if a value is null or not.
Section 4. Joining tables
- SQLite join – learn the overview of joins including inner join, left join, and cross join.
- Inner Join – query data from multiple tables using the inner join clause.
- Left Join – combine data from multiple tables using the left join clause.
- Cross Join – show you how to use the cross join clause to produce a cartesian product of result sets of the tables involved in the join.
- Self Join – join a table to itself to create a result set that joins rows with other rows within the same table.
- Full Outer Join – show you how to emulate the full outer join in the SQLite using left join and union clauses.
Section 5. Grouping data
- Group By – combine a set of rows into groups based on specified criteria. The clause helps you summarize data for reporting purposes.
- Having – specify the conditions to filter the groups summarized by the clause.
Section 6. Set operators
- Union – combine result sets of multiple queries into a single result set. We also discuss the differences between and clauses.
- Except – compare the result sets of two queries and returns distinct rows from the left query that are not output by the right query.
- Intersect – compare the result sets of two queries and returns distinct rows that are output by both queries.
Section 7. Subquery
- Subquery – introduce you to the SQLite subquery and correlated subquery.
- Exists operator – test for the existence of rows returned by a subquery.
Section 9. Changing data
This section guides you on how to update data in the table using insert, update, delete, and replace statements.
- Insert – insert rows into a table
- Update – update existing rows in a table.
- Delete – delete rows from a table.
- Replace – insert a new row or replace the existing row in a table.
Section 11. Data definition
In this section, you’ll learn how to create database objects such as tables, views, indexes using SQL data definition language.
- SQLite Data Types – introduce you to the SQLite dynamic type system and its important concepts: storage classes, manifest typing, and type affinity.
- Create Table – show you how to create a new table in the database.
- Alter Table – show you how to use modify the structure of an existing table.
- Rename column – learn step by step how to rename a column of a table.
- Drop Table – guide you on how to remove a table from the database.
- VACUUM – show you how to optimize database files.
Section 12. Constraints
- Primary Key – show you how to define the primary key for a table.
- NOT NULL constraint – learn how to enforce values in a column are not NULL.
- UNIQUE constraint – ensure values in a column or a group of columns are unique.
- CHECK constraint – ensure the values in a column meet a specified condition defined by an expression.
- AUTOINCREMENT – explain how the column attribute works and why you should avoid using it.
Section 13. Views
- Create View – introduce you to the view concept and show you how to create a new view in the database.
- Drop View – show you how to drop a view from its database schema.
Section 14. Indexes
- Index – teach you about the index and how to utilize indexes to speed up your queries.
- Index for Expressions – show you how to use the expression-based index.
Section 15. Triggers
- Trigger – manage triggers in the SQLite database.
- Create INSTEAD OF triggers – learn about triggers and how to create an trigger to update data via a view.
Section 17. SQLite tools
- SQLite Commands – show you the most commonly used command in the sqlite3 program.
- SQLite Show Tables – list all tables in a database.
- SQLite Describe Table – show the structure of a table.
- SQLite Dump – how to use dump command to backup and restore a database.
- SQLite Import CSV – import CSV files into a table.
- SQLite Export CSV – export an SQLite database to CSV files.
Устранение неполадок при открытии файлов SQLITE
Общие проблемы с открытием файлов SQLITE
SQLite не установлен
Дважды щелкнув по файлу SQLITE вы можете увидеть системное диалоговое окно, в котором сообщается «Не удается открыть этот тип файла». В этом случае обычно это связано с тем, что на вашем компьютере не установлено SQLite для %%os%%. Так как ваша операционная система не знает, что делать с этим файлом, вы не сможете открыть его дважды щелкнув на него.
Совет: Если вам извстна другая программа, которая может открыть файл SQLITE, вы можете попробовать открыть данный файл, выбрав это приложение из списка возможных программ.
Установлена неправильная версия SQLite
В некоторых случаях у вас может быть более новая (или более старая) версия файла SQLite Database File, не поддерживаемая установленной версией приложения. При отсутствии правильной версии ПО SQLite (или любой из других программ, перечисленных выше), может потребоваться загрузить другую версию ПО или одного из других прикладных программных средств, перечисленных выше. Такая проблема чаще всего возникает при работе в более старой версии прикладного программного средства с файлом, созданным в более новой версии, который старая версия не может распознать.
Совет: Иногда вы можете получить общее представление о версии файла SQLITE, щелкнув правой кнопкой мыши на файл, а затем выбрав «Свойства» (Windows) или «Получить информацию» (Mac OSX).
Резюме: В любом случае, большинство проблем, возникающих во время открытия файлов SQLITE, связаны с отсутствием на вашем компьютере установленного правильного прикладного программного средства.
Даже если на вашем компьютере уже установлено SQLite или другое программное обеспечение, связанное с SQLITE, вы все равно можете столкнуться с проблемами во время открытия файлов SQLite Database File. Если проблемы открытия файлов SQLITE до сих пор не устранены, возможно, причина кроется в других проблемах, не позволяющих открыть эти файлы. Такие проблемы включают (представлены в порядке от наиболее до наименее распространенных):
Установка SQLite на Mac OS X
Последняя версия Mac OS X предварительно установленной SQLite, но если у вас нет в наличии, просто выполните следующие действия:
-
Выполните следующие действия:
$ TAR xvfz SQLite-Autoconf-3071502.tar.gz $ Cd-Autoconf SQLite-3071502 $. / Настройка prefix = / USR / местные $ Сделать $ Сделать установки
Вышеуказанные шаги будут установить SQLite на компьютере Mac OS X, вы можете проверить с помощью следующей команды:
$ Sqlite3 SQLite версии 3.7.15.2 2013-01-09 11:53:05 Введите ".help" для получения инструкций Введите SQL-операторы завершаться ";" SQLite>
И, наконец, в командной строке SQLite, используйте SQLite команду, чтобы выполнять упражнения.
Предыдущий: SQLite Введение
Далее: команда SQLite
Connect To Database
Following C code segment shows how to connect to an existing database. If the database does not exist, then it will be created and finally a database object will be returned.
#include <stdio.h>
#include <sqlite3.h>
int main(int argc, char* argv[]) {
sqlite3 *db;
char *zErrMsg = 0;
int rc;
rc = sqlite3_open("test.db", &db);
if( rc ) {
fprintf(stderr, "Can't open database: %s\n", sqlite3_errmsg(db));
return(0);
} else {
fprintf(stderr, "Opened database successfully\n");
}
sqlite3_close(db);
}
Now, let’s compile and run the above program to create our database test.db in the current directory. You can change your path as per your requirement.
$gcc test.c -l sqlite3 $./a.out Opened database successfully
If you are going to use C++ source code, then you can compile your code as follows −
$g++ test.c -l sqlite3
Here, we are linking our program with sqlite3 library to provide required functions to C program. This will create a database file test.db in your directory and you will have the following result.
-rwxr-xr-x. 1 root root 7383 May 8 02:06 a.out -rw-r--r--. 1 root root 323 May 8 02:05 test.c -rw-r--r--. 1 root root 0 May 8 02:06 test.db
Testing Services
The Test Harness #3 (TH3) is
a suite of test cases for SQLite that provide 100% branch test coverage
(and 100% modified condition/decision coverage) for the core SQLite in
an as-deployed configuration using only published and documented interfaces.
TH3 is designed for use with embedded devices, and is compatible with
DO-178B. Every release of the public-domain SQLite is tested using TH3,
and so all users benefit from the TH3 tests. But the TH3 tests are not
themselves public. Hardware or system manufactures who want to have
TH3 test run on their systems can negotiate a service agreement to have
the SQLite Developers run those tests.
3.1. Determination Of Column Affinity
The affinity of a column is determined by the declared type
of the column, according to the following rules in the order shown:
-
If the declared type contains the string «INT» then it
is assigned INTEGER affinity. -
If the declared type of the column contains any of the strings
«CHAR», «CLOB», or «TEXT» then that
column has TEXT affinity. Notice that the type VARCHAR contains the
string «CHAR» and is thus assigned TEXT affinity. -
If the declared type for a column
contains the string «BLOB» or if
no type is specified then the column has affinity BLOB. -
If the declared type for a column
contains any of the strings «REAL», «FLOA»,
or «DOUB» then the column has REAL affinity. -
Otherwise, the affinity is NUMERIC.
Note that the order of the rules for determining column affinity
is important. A column whose declared type is «CHARINT» will match
both rules 1 and 2 but the first rule takes precedence and so the
column affinity will be INTEGER.
3.1.1. Affinity Name Examples
The following table shows how many common datatype names from
more traditional SQL implementations are converted into affinities by the five rules of the
previous section. This table shows only a small subset of the
datatype names that SQLite will accept. Note that numeric arguments
in parentheses that following the type name (ex: «VARCHAR(255)») are
ignored by SQLite — SQLite does not impose any length restrictions
(other than the large global limit) on the length of
strings, BLOBs or numeric values.
Note that a declared type of «FLOATING POINT» would give INTEGER
affinity, not REAL affinity, due to the «INT» at the end of «POINT».
And the declared type of «STRING» has an affinity of NUMERIC, not TEXT.
Compiling
First create a directory in which to place
the build products. It is recommended, but not required, that the
build directory be separate from the source directory. Cd into the
build directory and then from the build directory run the configure
script found at the root of the source tree. Then run «make».
For example:
See the makefile for additional targets.
The configure script uses autoconf 2.61 and libtool. If the configure
script does not work out for you, there is a generic makefile named
«Makefile.linux-gcc» in the top directory of the source tree that you
can copy and edit to suit your needs. Comments on the generic makefile
show what changes are needed.
Version Control
SQLite sources are managed using the
Fossil, a distributed version control system
that was specifically designed and written to support SQLite development.
The Fossil repository contains the urtext.
If you are reading this on GitHub or some other Git repository or service,
then you are looking at a mirror. The names of check-ins and
other artifacts in a Git mirror are different from the official
names for those objects. The offical names for check-ins are
found in a footer on the check-in comment for authorized mirrors.
The official check-in name can also be seen in the file
in the root of the tree. Always use the official name, not the
Git-name, when communicating about an SQLite check-in.
If you pulled your SQLite source code from a secondary source and want to
verify its integrity, there are hints on how to do that in the
section below.
2019: Возможность взлома iPhone через уязвимости в SQLite
16 августа 2019 года стало известно, что специалисты компании Check Point продемонстрировали, как можно взломать iPhone через ядро базы данных, которое использует iOS — SQLite. В этом случае хакеры смогут получить права администратора над устройством.
SQLite — распространенные базы данных. Они доступны в любой операционной системе, персональном компьютере и на мобильном телефоне. Пользователи SQLite — Windows 10, MacOS, iOS, Chrome, Safari, Firefox и Android. Контакты на вашем iPhone, некоторые из сохраненных паролей на вашем ноутбуке — вся эта информация c большой вероятностью хранится в базе данных SQLite.
Специалисты Check Point нашли несколько уязвимостей и изобрели способ их эксплуатации. Проще говоря, теперь стало возможным получение контроля над всем, что обращается к базам данных SQLite.
Так как SQLite является одним из наиболее широко распространенных компонентов программного обеспечения, подобные уязвимости можно применять бесконечное количество раз.
Исследователи Check Point продемонстрировали эти уязвимости двумя способами. В первом случае инженеры перехватили злоумышленника, который заразил тестируемое устройство популярным вредоносным ПО, известным как «похититель паролей». Когда вредоносная программа забирает сохраненный пароль с зараженного компьютера и отправляет его своему оператору, мы получаем контроль над самим оператором.
Вторая демонстрация была на iPhone, на операционной системе iOS. Специалистам удалось обойти доверенный механизм безопасной загрузки Apple и получить права администратора на последнем iPhone.
SQLite практически встроен практически в любую платформу, поэтому можно сказать, что эксперты едва поцарапали верхушку айсберга, если говорить о потенциале эксплуатации уязвимостей.
Компания Check Point надеется, что данное исследование подтолкнет мировое сообщество по кибербезопасности работать дальше над этими уязвимостями.
2.5. Subroutines, Coroutines, and Subprograms
The bytecode engine has no stack on which to store the return address
of a subroutine. Return addresses must be stored in registers.
Hence, bytecode subroutines are not reentrant.
The opcode stores the current program counter into
register P1 then jumps to address P2. The opcode jumps
to address P1+1. Hence, every subroutine is associated with two integers:
the address of the entry point in the subroutine and the register number
that is used to hold the return address.
The opcode swaps the value of the program counter with
the integer value in register P1. This opcode is used to implement
coroutines. Coroutines are often used to implement subqueries from
which content is pulled on an as-needed basis.
Triggers need to be reentrant.
Since bytecode
subroutines are not reentrant a different mechanism must be used to
implement triggers. Each trigger is implemented using a separate bytecode
program with its own opcodes, program counter, and register set. The
opcode invokes the trigger subprogram. The instruction
allocates and initializes a fresh register set for each invocation of the
subprogram, so subprograms can be reentrant and recursive. The
opcode is used by subprograms to access content in registers
of the calling bytecode program.
UPDATE Operation
Following C code segment shows how we can use UPDATE statement to update any record and then fetch and display updated records from the COMPANY table.
#include <stdio.h>
#include <stdlib.h>
#include <sqlite3.h>
static int callback(void *data, int argc, char **argv, char **azColName){
int i;
fprintf(stderr, "%s: ", (const char*)data);
for(i = 0; i<argc; i++) {
printf("%s = %s\n", azColName, argv ? argv : "NULL");
}
printf("\n");
return 0;
}
int main(int argc, char* argv[]) {
sqlite3 *db;
char *zErrMsg = 0;
int rc;
char *sql;
const char* data = "Callback function called";
/* Open database */
rc = sqlite3_open("test.db", &db);
if( rc ) {
fprintf(stderr, "Can't open database: %s\n", sqlite3_errmsg(db));
return(0);
} else {
fprintf(stderr, "Opened database successfully\n");
}
/* Create merged SQL statement */
sql = "UPDATE COMPANY set SALARY = 25000.00 where ID=1; " \
"SELECT * from COMPANY";
/* Execute SQL statement */
rc = sqlite3_exec(db, sql, callback, (void*)data, &zErrMsg);
if( rc != SQLITE_OK ) {
fprintf(stderr, "SQL error: %s\n", zErrMsg);
sqlite3_free(zErrMsg);
} else {
fprintf(stdout, "Operation done successfully\n");
}
sqlite3_close(db);
return 0;
}
When the above program is compiled and executed, it will produce the following result.
Opened database successfully Callback function called: ID = 1 NAME = Paul AGE = 32 ADDRESS = California SALARY = 25000.0 Callback function called: ID = 2 NAME = Allen AGE = 25 ADDRESS = Texas SALARY = 15000.0 Callback function called: ID = 3 NAME = Teddy AGE = 23 ADDRESS = Norway SALARY = 20000.0 Callback function called: ID = 4 NAME = Mark AGE = 25 ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
Obtaining The Code
If you do not want to use Fossil, you can download tarballs or ZIP
archives or as follows:
-
Lastest trunk check-in as
Tarball,
ZIP-archive, or
SQLite-archive. -
Latest release as
Tarball,
ZIP-archive, or
SQLite-archive. -
For other check-ins, substitute an appropriate branch name or
tag or hash prefix in place of «release» in the URLs of the previous
bullet. Or browse the timeline
to locate the check-in desired, click on its information page link,
then click on the «Tarball» or «ZIP Archive» links on the information
page.
If you do want to use Fossil to check out the source tree,
first install Fossil version 2.0 or later.
(Source tarballs and precompiled binaries available
here. Fossil is
a stand-alone program. To install, simply download or build the single
executable file and put that file someplace on your $PATH.)
Then run commands like this:
After setting up a repository using the steps above, you can always
update to the lastest version using:
Or type «fossil ui» to get a web-based user interface.
16.4. SQLite Archive Insert And Update Commands
The —update and —insert commands work like —create command, except that
they do not delete the current archive before commencing. New versions of
files silently replace existing files with the same names, but otherwise
the initial contents of the archive (if any) remain intact.
For the —insert command, all files listed are inserted into the archive.
For the —update command, files are only inserted if they do not previously
exist in the archive, or if their «mtime» or «mode» is different from what
is currently in the archive.
Compatibility node: Prior to SQLite version 3.28.0 (2019-04-16) only
the —update option was supported but that option worked like —insert in that
it always reinserted every file regardless of whether or not it had changed.
Further Information
SQLite is free and works great.
Most people use SQLite without
any kind of license or support.
Free support for SQLite is available on the public
SQLite Forum.
The forum is monitored by a large
community of experts, including the core SQLite development team,
who are able to resolve just about
any problems with SQLite that you are likely to have.
Users with more advanced support needs can opt for a
Technical Support
Agreement.
Technical support agreements are customized to the needs of each
individual client, but generally include direct telephone support
and priority handling of issues and bugs. Guaranteed response time
is available as an option. The cost of
technical support varies but is generally
in the range of $8000 to $35000 per year.
If SQLite is «mission critical» to your company, then you may
want to become an
SQLite Consortium
Member. The SQLite
Consortium is a collaboration of companies who sponsor ongoing development
of SQLite in exchange for enterprise-level technical support, on-site
visits from the SQLite developers, unlimited access to all licensed
products, and strong guarantees that SQLite will remain in the public
domain, free and independent, and will not come under the control of
a competitor.
C/C++ Interface APIs
Following are important C/C++ SQLite interface routines, which can suffice your requirement to work with SQLite database from your C/C++ program. If you are looking for a more sophisticated application, then you can look into SQLite official documentation.
| Sr.No. | API & Description |
|---|---|
| 1 |
sqlite3_open(const char *filename, sqlite3 **ppDb) This routine opens a connection to an SQLite database file and returns a database connection object to be used by other SQLite routines. If the filename argument is NULL or ‘:memory:’, sqlite3_open() will create an in-memory database in RAM that lasts only for the duration of the session. If the filename is not NULL, sqlite3_open() attempts to open the database file by using its value. If no file by that name exists, sqlite3_open() will open a new database file by that name. |
| 2 |
sqlite3_exec(sqlite3*, const char *sql, sqlite_callback, void *data, char **errmsg) This routine provides a quick, easy way to execute SQL commands provided by sql argument which can consist of more than one SQL command. Here, the first argument sqlite3 is an open database object, sqlite_callback is a call back for which data is the 1st argument and errmsg will be returned to capture any error raised by the routine. SQLite3_exec() routine parses and executes every command given in the sql argument until it reaches the end of the string or encounters an error. |
| 3 |
sqlite3_close(sqlite3*) This routine closes a database connection previously opened by a call to sqlite3_open(). All prepared statements associated with the connection should be finalized prior to closing the connection. If any queries remain that have not been finalized, sqlite3_close() will return SQLITE_BUSY with the error message Unable to close due to unfinalized statements. |