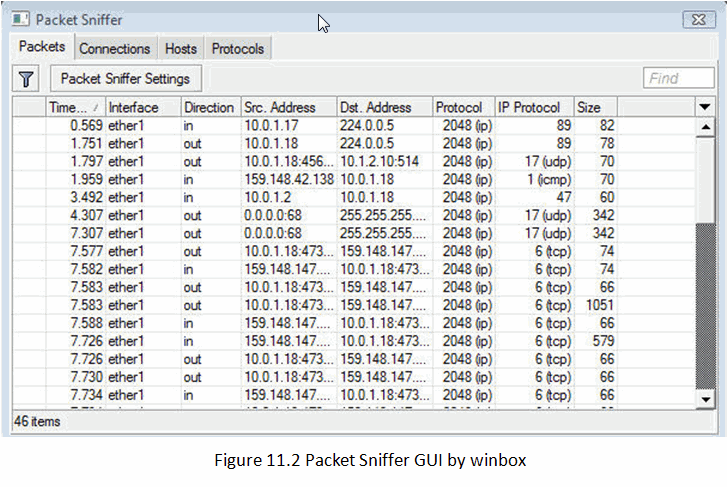
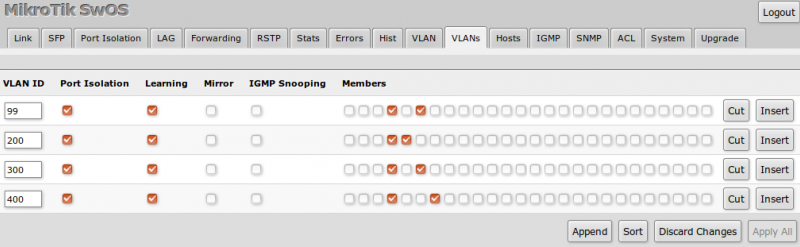
When linux conntrack is no longer your friend
Содержание:
What are the trade-offs of bypassing conntrack?
- Do-not-track network policy typically has to be symmetric. In the SaaS-provider’s case their workload was internal so using network policy they could very narrowly whitelist traffic to and from all workloads that were allowed to access the memcached service.
- Do-not-track policy is oblivious to the direction of the connection. So in the event that a memcached server was compromised, it could in theory attempt to connect out to any of the memcached clients so long as it used the right source port. However, assuming you correctly defined network policy for your memcached clients then these connection attempts will still be rejected at the client end.
- Do-not-track network policy is applied to every packet, whereas normal network policy is only applied to the first packet in a flow. This can increase the CPU cost per packet since every packet needs to be processed by network policy. But with short-lived connections this extra processing is outweighed by the reduction in conntrack processing. For example, in the SaaS provider’s case, the number of packets in each connection was very small so the additional overhead of applying policy to every packet was a reasonable trade-off.
3.2 Packet Selection: IP Tables
A packet selection system called IP Tables has been built over the
netfilter framework. It is a direct descendent of ipchains (that came
from ipfwadm, that came from BSD’s ipfw IIRC), with extensibility.
Kernel modules can register a new table, and ask for a packet to
traverse a given table. This packet selection method is used for
packet filtering (the `filter’ table), Network Address Translation
(the `nat’ table) and general pre-route packet mangling (the `mangle’
table).
The hooks that are registered with netfilter are as follows (with
the functions in each hook in the order that they are actually
called):
Packet Filtering
This table, `filter’, should never alter packets: only filter them.
One of the advantages of iptables filter over ipchains is that it is
small and fast, and it hooks into netfilter at the NF_IP_LOCAL_IN,
NF_IP_FORWARD and NF_IP_LOCAL_OUT points. This means that for any
given packet, there is one (and only one) possible place to filter it.
This makes things much simpler for users than ipchains was. Also, the
fact that the netfilter framework provides both the input and output
interfaces for the NF_IP_FORWARD hook means that many kinds of
filtering are far simpler.
Note: I have ported the kernel portions of both ipchains and ipfwadm
as modules on top of netfilter, enabling the use of the old ipfwadm
and ipchains userspace tools without requiring an upgrade.
NAT
This is the realm of the `nat’ table, which is fed packets from two
netfilter hooks: for non-local packets, the NF_IP_PRE_ROUTING and
NF_IP_POST_ROUTING hooks are perfect for destination and source
alterations respectively. If CONFIG_IP_NF_NAT_LOCAL is defined, the
hooks NF_IP_LOCAL_OUT and NF_IP_LOCAL_IN are used for altering the
destination of local packets.
This table is slightly different from the `filter’ table, in that only
the first packet of a new connection will traverse the table: the
result of this traversal is then applied to all future packets in the
same connection.
Masquerading, Port Forwarding, Transparent Proxying
I divide NAT into Source NAT (where the first packet has its source
altered), and Destination NAT (the first packet has its destination
altered).
Masquerading is a special form of Source NAT: port forwarding and
transparent proxying are special forms of Destination NAT. These are
now all done using the NAT framework, rather than being independent
entities.
Packet Mangling
The packet mangling table (the `mangle’ table) is used for actual
changing of packet information. Example applications are the TOS and
TCPMSS targets. The mangle table hooks into all five netfilter hooks.
(please note this changed with kernel 2.4.18. Previous kernels didn’t
have mangle attached to all hooks)
7.4 Target Specifications
Now we know what examinations we can do on a packet, we need a way
of saying what to do to the packets which match our tests. This is
called a rule’s target.
There are two very simple built-in targets: DROP and ACCEPT. We’ve
already met them. If a rule matches a packet and its target is one of
these two, no further rules are consulted: the packet’s fate has been
decided.
There are two types of targets other than the built-in ones:
extensions and user-defined chains.
User-defined chains
One powerful feature which inherits from
is the ability for the user to create new chains, in
addition to the three built-in ones (INPUT, FORWARD and OUTPUT). By
convention, user-defined chains are lower-case to distinguish them
(we’ll describe how to create new user-defined chains below in
).
When a packet matches a rule whose target is a user-defined chain, the
packet begins traversing the rules in that user-defined chain. If
that chain doesn’t decide the fate of the packet, then once traversal
on that chain has finished, traversal resumes on the next rule in the
current chain.
Time for more ASCII art. Consider two (silly) chains: (the
built-in chain) and (a user-defined chain).
Consider a TCP packet coming from 192.168.1.1, going to 1.2.3.4. It
enters the chain, and gets tested against Rule1 — no match.
Rule2 matches, and its target is , so the next rule examined
is the start of . Rule1 in matches, but doesn’t
specify a target, so the next rule is examined, Rule2. This doesn’t
match, so we have reached the end of the chain. We return to the
chain, where we had just examined Rule2, so we now examine
Rule3, which doesn’t match either.
So the packet path is:
User-defined chains can jump to other user-defined chains (but
don’t make loops: your packets will be dropped if they’re found to
be in a loop).
Extensions to iptables: New Targets
The other type of extension is a target. A target extension
consists of a kernel module, and an optional extension to
to provide new command line options. There are
several extensions in the default netfilter distribution:
- LOG
-
This module provides kernel logging of matching
packets. It provides these additional options:- —log-level
-
Followed by a level number or name. Valid
names are (case-insensitive) `debug’, `info’, `notice’, `warning’,
`err’, `crit’, `alert’ and `emerg’, corresponding to numbers 7
through 0. See the man page for syslog.conf for an explanation of
these levels. The default is `warning’. - —log-prefix
-
Followed by a string of up to 29 characters,
this message is sent at the start of the log message, to allow it to
be uniquely identified.
This module is most useful after a limit match, so you don’t flood
your logs. - REJECT
-
This module has the same effect as `DROP’, except
that the sender is sent an ICMP `port unreachable’ error message.
Note that the ICMP error message is not sent if (see RFC 1122):- The packet being filtered was an ICMP error message in the
first place, or some unknown ICMP type. - The packet being filtered was a non-head fragment.
- We’ve sent too many ICMP error messages to that destination
recently (see /proc/sys/net/ipv4/icmp_ratelimit).
REJECT also takes a `—reject-with’ optional argument which alters the
reply packet used: see the manual page. - The packet being filtered was an ICMP error message in the
Special Built-In Targets
There are two special built-in targets: and
.
has the same effect of falling off the end of a
chain: for a rule in a built-in chain, the policy of the chain is
executed. For a rule in a user-defined chain, the traversal continues
at the previous chain, just after the rule which jumped to this chain.
is a special target, which queues the packet for
userspace processing. For this to be useful, two further components are
required:
- a «queue handler», which deals with the actual mechanics of
passing packets between the kernel and userspace; and - a userspace application to receive, possibly manipulate, and
issue verdicts on packets.
The following is a quick example of how to use iptables to queue packets
for userspace processing:
To write a userspace application, use the libipq API. This is
distributed with iptables. Example code may be found in the testsuite
tools (e.g. redirect.c) in CVS.
The status of ip_queue may be checked via:
3.2 condition match
This patch by Stephane Ouellette <ouellettes@videotron.ca> adds a new match that is used
to enable or disable a set of rules using condition variables stored in `/proc’ files.
Notes:
- The condition variables are stored in the `/proc/net/ipt_condition/’ directory.
- A condition variable can only be set to «0» (FALSE) or «1» (TRUE).
- One or many rules can be affected by the state of a single condition variable.
- A condition proc file is automatically created when a new condition is first referenced.
- A condition proc file is automatically deleted when the last reference to it is removed.
Supported options for the condition match are :
- —condition conditionfile
-
-> match on condition variable.
For example, if you want to prohibit access to your web server while doing maintenance, you can use the
following :
The following rule will match only if the «webdown» condition is set to «1».
Спасти HLDS
-A JOINPGN-INPUT -p tcp -m tcp --dport XXXXXX:XXXXXX-m length --length 0:32 -j DROP -A JOINPGN-INPUT -p udp -m udp --dport XXXXXX:XXXXXX -m length --length 0:32 -j DROP -A JOINPGN-INPUT -p tcp -m tcp --dport XXXXXX:XXXXXX -m length --length 222 -j DROP -A JOINPGN-INPUT -p udp -m udp --dport XXXXXX:XXXXXX -m length --length 222 -j DROP -A JOINPGN-INPUT -p tcp -m tcp --dport XXXXXX:XXXXXX -m length --length 222 -m string --hex-string "|a090909090909090901809a5000000000000000000000000000000000000000000000000|" --algo bm --to 65535 -j DROP -A JOINPGN-INPUT -p udp -m udp --dport XXXXXX:XXXXXX -m length --length 222 -m string --hex-string "|a090909090909090901809a5000000000000000000000000000000000000000000000000|" --algo bm --to 65535 -j DROP