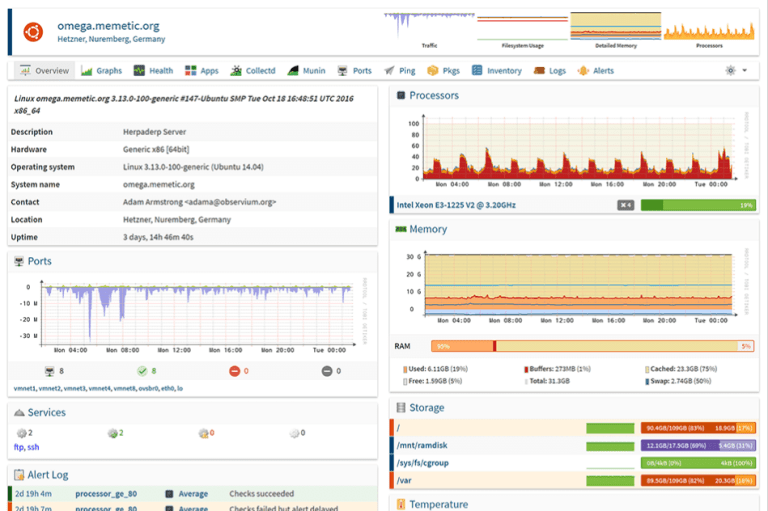
Методы мониторинга и обеспечения безопасности для поддержания работоспособности корпоративной сети
Содержание:
- ПРЕИМУЩЕСТВА
- Мониторинг оперативной памяти
- Состояние вентиляторов в коммутаторах
- okerr — это не просто софт, но еще и сервис
- Температурные показатели
- Наш подход
- Сценарии использования
- А вот еще был случай…
- Что дальше?
- IQBuzz
- Технические детали
- Просмотр результатов
- BuzzLook
- ПРЕИМУЩЕСТВА
- Состояние процессоров
- ВЕРСИИ: ОБЫЧНАЯ И PRO
ПРЕИМУЩЕСТВА
Сканирование сети, распознавание типов устройств.
Построение графической карты сети и наглядный просмотр состояния хостов.
Работа с несколькими картами одновременно.
Обнаружение новых устройств в сети.
Наглядное администрирование по карте.
Выключение, перезагрузка, включение удаленных серверов и рабочих станций.
Показ схемы сети удаленным пользователям через Web-интерфейс (в версии Pro).
Для работы программы не требуется установка каких-либо компонентов на удаленные сервера и рабочие станции.
Работаем на рынке ПО с 1998 года (22 года). Разработка решений для мониторинга ведется уже 17 лет с 2003 года!
- Дополнительная информация:
- История версий
- Узнать цены
- Скриншоты
- Отличия версии Pro
- Видеоролики
- Документация по программе
- FAQ (частые вопросы и ответы)
СКАЧАТЬ ПРОГРАММУ
Мониторинг оперативной памяти
Одна из самых опасных ситуаций в случае с оперативной памятью – утечка (memory leak)
Предупреждать и устранять ее важно своевременно, так как в небольших интервалах (день, неделя) медленное, но неотвратимое уменьшение свободной памяти можно просто не заметить
Частично решить эту проблему позволяет сбор долгосрочной статистики в Cacti. Мы можем отследить тенденцию к переполнению памяти и запланировать технологическое окно для перезагрузки оборудования. К сожалению, в большинстве случаев это единственный абсолютный метод «лечения» утечки.
Вот еще один пример из жизни нашей сети:
При очередном анализе показателей мониторинга инженеры обнаружили динамику уменьшения объема свободной памяти на одном из коммутаторов. Изменения были почти незаметны на коротких интервалах времени, но, если увеличить масштаб времени, скажем до месяца, появлялся тренд на плавное уменьшение свободной памяти. При заполнении памяти последствия для коммутатора могут быть непредсказуемы, вплоть до странностей в поведении протоколов маршрутизации. Например, часть маршрутов может перестать анонсироваться своему соседу. Или случайным образом начнет отказывать peer-link на системе VSS.
Ситуация, описанная выше, закончилась вполне благополучно. Мы согласовали с клиентами техокно и перегрузили коммутатор.
Итак, продолжим. Графики Cacti помогают определить точное время начала утечки, и, сопоставив логи, мы находим и «лечим» причину.
Делаем запрос загрузки оперативной памяти:
OID: 1.3.6.1.4.1.9.9.221.1.1.1.1.18.index
Ответ: iso.3.6.1.4.1.9.9.221.1.1.1.1.18.52690955.1 = Counter64: 2734644292
Значение указывает количество байтов из пула памяти, используемое операционной системой.
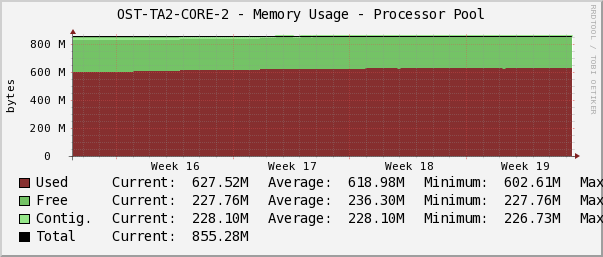
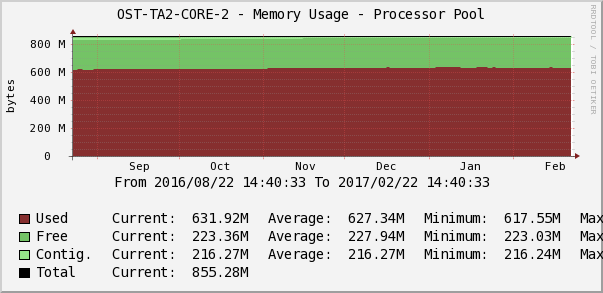 Статистика загрузки оперативной памяти в Cacti.
Статистика загрузки оперативной памяти в Cacti.
Дежурный инженер следит за тем, чтобы не было аномальных перепадов или тренда на постоянное заполнение свободной памяти по параметру Memory Usage. График в Cacti показывает память под процессы, ввод/вывод, общую память, количество свободной/занятой памяти.
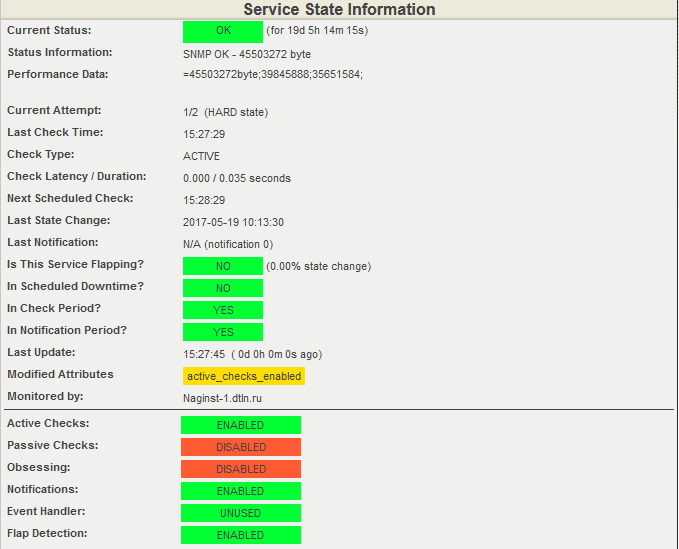 Текущее значение свободной оперативной памяти коммутатора – выгрузка из Nagios.
Текущее значение свободной оперативной памяти коммутатора – выгрузка из Nagios.
В момент создания скриншота было свободно 45503272 байт ОП, установлены пороги срабатывания: для WARNING — в интервале от 35651584 до 39845888 байт, для CRITICAL — от 0 до 35651584 байт.
Состояние вентиляторов в коммутаторах
Чтобы оборудование не перегревалось, с помощью системы холодоснабжения нашего дата-центра и системы холодных и горячих коридоров мы обеспечиваем постоянный приток воздуха в стойку из холодного коридора и одновременное «выдувание» нагревшегося воздуха в горячий коридор. Роль «насосов», которые качают воздух через оборудование, выполняют вентиляторы внутри коммутаторов – не путать с вентиляторами на стойках. Мы отслеживаем их статус, чтобы не допустить перегрев оборудования.
Если вентилятор остановится, у нас будет некоторое количество времени на его замену, иначе оборудование может пострадать.
Чтобы получить актуальный статус вентилятора, делаем запрос, аналогичный приведенному выше:
iso.3.6.1.4.1.9.9.117.1.1.2.1.2.24330783 = INTEGER: 2
Ответ 2 означает ON. Вентилятор работает, Nagios не паникует.
 Так отображается состояние вентиляторов в Nagios.
Так отображается состояние вентиляторов в Nagios.
Небольшая ремарка: при настройке систем мониторинга наши специалисты в качестве пороговых используют значения, полученные при тестовых нагрузках и «краш-тестах». Выход из «нормального» диапазона предупреждает о надвигающейся проблеме, и у нас есть время на «гладкое» устранение неисправности. При этом во многих случаях в режиме реального времени нам достаточно простой индикации «работает/не работает».
okerr — это не просто софт, но еще и сервис
Серверная часть любого мониторинга — штука большая и сложная, ее сложно ставить и настраивать, она требует ресурсов. С okerr вы можете поставить свой собственный сервер мониторинга (он бесплатный и opensource), а можно просто использовать только клиентскую часть, и пользоваться сервисом нашего сервера. Тоже бесплатно.
Если мониторинг позволяет компенсировать, прикрыть нехватку надежности у серверов и приложений, то возникает философский вопрос — кто сторожит стражника? Как мониторинг нам сообщит о проблеме, если он сам «умер» по какой-то причине, отдельно или вместе с другими вашими ресурсами (например, упал канал в дата-центр)? При использовании внешнего сервиса okerr — эта проблема решается — вы получите алерт даже если весь дата-центр с вашими серверами будет обесточен или подвергнется атаке зомби.
Конечно, есть риск, что сервер okerr сам будет недоступен, это так (как известно, 90% надежности получаются всегда просто и «бесплатно», 99% — с минимумом усилий, и каждая следующая девяточка — экспоненциально сложнее). Но, во-первых шансы этого ниже, а во-вторых, проблема может оказаться незамеченной только если ли она совпадет по времени с проблемами на наших серверах. Если у нас надежность 99.9%, и у вас 99.9% (не слишком уж высокие числа), то шанс незамеченного сбоя — 0.1% от 0.1% = 0.0001%. Добавить себе три девятки в надежность почти без усилий и без затрат — это очень неплохо!
Еще одно преимущество мониторинга как сервиса — хостинг-провайдер или веб-студия может установить у себя сервер okerr и предоставлять доступ клиентам как платную или бесплатную дополнительную услугу. У ваших конкурентов просто хостинг и сайты — а у вас надежный хостинг с мониторингом.
Температурные показатели
Для мониторинга сетевой инфраструктуры нужно знать показания температурных датчиков с каждой единицы оборудования. Это позволяет выявлять и устранять не только возможные перегревы хостов, но и определять на ранней стадии локальные перегревы стоек.
Для получения статуса устройства мы отправляем запрос вида snmpwalk <параметры> <устройство> | grep <что ищем> и получаем список всех OID по заданным фильтрам.
 Запрос температурных показателей маршрутизатора Cisco ASR9006.
Запрос температурных показателей маршрутизатора Cisco ASR9006.
Изучив вывод, делаем более детальный запрос:
 Делаем запрос параметра Inlet Temperature Sensordie для снятия значения температур.
Делаем запрос параметра Inlet Temperature Sensordie для снятия значения температур.
И еще более детальный:
 Выбираем параметры NP1 и NP2.
Выбираем параметры NP1 и NP2.
В итоге мы получаем OID 1.3.6.1.4.1.9.9.91.1.1.1.1.4.index и можем отследить показания нужного температурного датчика. На нашем примере – значение 590, т. е. 59 градусов по Цельсию.
В графическом представлении Nagios результаты опроса выглядят так:

На скриншоте мы видим следующее:
- Temperature 0/0, 0/1, 0/2 – датчики линейных карт маршрутизатора ASR9006;
- RSP – датчик карты Route Switch Processor;
- RSP/CPU – датчик температуры CPU карты Route Switch Processor.
Наш подход
Наша практика «мониторинга всего» длится уже более пяти лет. В каких-то областях мы не изобретаем велосипед и действуем стандартными методами, а где-то, в силу специфики, прибегаем к своим решениям. В частности, это касается мониторинга логического уровня сети, но, как я сказал ранее, это тема уже будущей статьи.
В случае с опросом физического уровня сети всё достаточно просто. Система мониторинга сетевой инфраструктуры построена на базе Open-source инструментов Nagios и Cacti. На всякий случай напомню их различия: Nagios регистрирует события в реальном времени, а Cacti агрегирует статистику, строит графики и отслеживает динамику показателей в долгосрочной перспективе.
Состояние сетевого оборудования отслеживается через запросы по стандартному протоколу SNMP:
запрос сервер–агент: GetRequest и агент–сервер: Trap.
Разумеется, оборудование периодически меняется и модернизируется, и мы дорабатываем систему мониторинга под новые задачи. Прежде чем вводить новый хост в продуктив, параллельно с тестированием мы добавляем этот хост в систему мониторинга и определяем список объектов, которые будем отслеживать.
Мы собираем основные метрики подключенного оборудования, из самого элементарного – это проверка на UP/DOWN.
В целом нас интересуют:
- внешние факторы (температура, питание и т.д);
- состояние портов (текущее состояние, доступность);
- состояние процессора;
- память;
- специфика «железа» в зависимости от типа оборудования.
Нельзя сказать, что какой-то узел важнее остальных. Продуктивная сеть – она и в Африке продуктивная. «Забитая» память или перегруженный процессор могут вызвать деградацию сети в целом и проблемы у клиента – в частности. Макрозадача в мониторинге сетевого железа – своевременная профилактика и устранение неисправностей раньше, чем они дадут о себе знать.
Сценарии использования
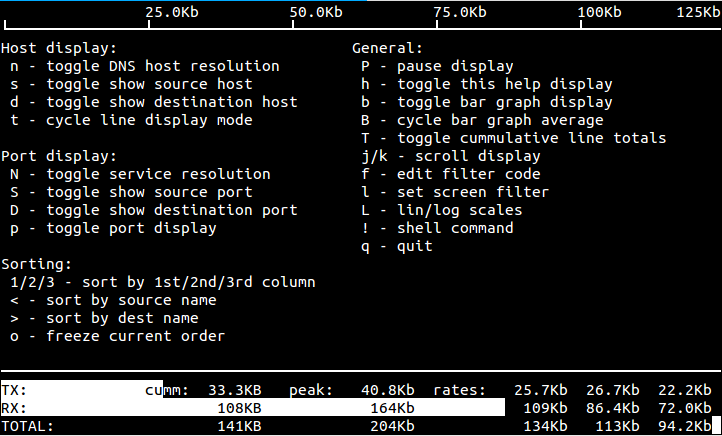
Мониторим сетевое оборудование
В идеале нам нужно установить и настроить по одному агенту на каждый из дата центров или удалённых офисов, чтобы агент мог локально опрашивать устройства внутри дата центра по snmp и отправлять собранные данные на центральный сервер, который может находится в одном из датацентров или где-нибудь в облаке (Amazon, DigitalOcean, Azure, etc).
Если же у вас один дата центр или есть «быстрые» линки до остальных ДЦ, то достаточно установить сервер и агента на одной и той же linux-машине, с которой и будут опрашиваться все устройства сети. Или, например, на той же машине, где у вас уже стоит cacti – не нужно будет настраивать snmp-доступ на сетевом оборудовании (если он у вас есть 🙂
Основной «минус» этой схемы: нужен snmp-доступ к сетевому оборудованию.
Мониторим сетевые интерфейсы на серверах
Для мониторинга сетевых интерфейсов на серверах нам нужно на каждый из них установить snmp-демона, например, через ansible-playbook. В этом случае каждый linux-сервер для агента будет выглядеть как отдельное сетевое устройство с одним или несколькими сетевыми интерейсами.
Плюсы:
- Можно обойтись без доступа к сетевому оборудованию
-
Можем довольно просто автоматизировать установку и настройку мониторинга
Минусы: - Нет capacity по портам (если оно нужно)
- Потребуется ручное добавление новых серверов в конфиг агента
Смешаный режим
Тут всё ясно, можно мониторить и свитчи/роутеры и серверы вместе – агент не различает тип устройства, а информацию по интерфейсам берёт из MIBv2-базы. Кстати, это ещё один минус – если у вас есть девайс, у которого информация по интерфейсам отдаётся с «нестандартных» MIB’ов (например, BTI 7000), то Inperfo, на данный момент, вам не подойдёт.
Производительность
Хорошо себя чувтсвует на «среднем» железе (16CPU/16GB) до 100 устройств (6000+ портов), на большем кол-ве запускать и наблюдать работу пока что не приходилось. Но посколько агент для опроса каждого устройства создаёт отдельный процесс (fork), то golang с go-рутинами просто изнывает и просится в этот кусок кода. Аналогично работает и сервер при получении данных.
Что добавится в следующих версиях
– Указание максимальной скорости для интерфейса. Нужно в ситуациях, когда к провайдеру вы подключены по 1Гб-линку, но оплаченный канал по факту меньше, аля ограничен до 500Мб.
– Еженедельные отчёты по топам на почту.
– Уведомления на почту.
– Отдельная сборка docker-контейнера с сервером и агентом. Для небольших сетей это идеальный вариант. Плюс появится возможность добавлять хосты через web-интерфейс.
– Топы/графики по пакетам
– Поиск по имени устройства, по интерфейсу, по описанию и по алиасу
– Переписать агента и часть сервера на golang.
На данных момент сервис не шлёт никаких алертов и прочего, но по URI /export/ можно импортировать данные в тот же заббикс, и получать уведомления. Сервис ещё немного сыроват, но поставленные задачи решает.
Install & enjoy.
А вот еще был случай…
Другой раз в похожей ситуации: после уязвимости в SSH нужно было обновить все серваки. А когда ставишь задачу — нужно контролировать исполнение. (Подчиненные имеют свойство не так понимать, забывать, путаться, совершать ошибки). Поэтому, сначала мы в okerr добавили проверку версии SSH на всех серверах, и через okerr следили, чтобы обновления накатили на всех серверах. (Удобно! Выбрал этот тип индикатора, и сразу видно, на каком сервере какая версия). Когда мы убедились, что задача выполнена на всех серверах — мы удалили индикаторы.
Пару раз была ситуация, что некоторая проблема возникает, а потом сама проходит. (наверное, всем знакомо?). Пока заметишь, пока проверишь — а там уже и проверять нечего — все уже хорошо работает. Но потом снова поломается. У нас это было, например, с товарами, которые мы загружали в Amazon Marketplace (MWS). В какой-то момент загруженные inventory были неверными (не те количества товаров и не те цены). Разобрались
Но чтобы разобраться — важно было узнать о проблеме сразу. К сожалению, MWS как и все сервисы амазона — немного тормозной, поэтому всегда был лаг, но все таки — удалось хотя бы примерно уловить связь между проблемой, и скриптами, которые ее вызывают (сделали проверку, приляпали ее к окерру, и проверяли сразу по получении алерта)
Интересный случай в копилочку совсем недавно добавил крупный и дорогой европейский хостер, которым пользуется наш заказчик. Внезапно вдруг с радаров пропали ВСЕ наши сервера! Сначала заказчик сам «ручками» (быстрее окерра!) заметил, что сайт с которым он работал — не открывается и сделал тикет про это. Но, полег не один сайт, а вообще все! (Наташа, мы все уронили!). Тут и Okerr начал слать длинные портянки со всеми индикаторами, которые у него загорелись. Паника-паника, бегаем кругами (а что еще делать?). Потом все поднялось. Оказывается, в дата-центре были регламентные работы (раз в много лет) и нас, конечно же, должны были предупредить. Но вот запердыка случилась у них какая-то и не предупредили. Ну инфарктом больше, инфарктом меньше. Но после восстановления всего — нужно же все перепроверить! Я не представляю, как я бы это делал руками. Okerr за несколько минут все оттестировал. Оказалось, что бОльшая часть серверов просто была временно недоступна, но работала. Некоторые — перегрузились, но тоже встали как надо. Из всех потерь — мы потеряли два бэкапа, которые по крону должны были создаться и загрузиться в то время, пока шел этот полный бананас. Я даже не стал их создавать, просто через сутки прилетели алерты, что все ОК, бэкапы появились. Мне этот пример очень нравится, потому что okerr оказался очень полезным в ситуации, о которой мы даже и не думали заранее, но в этом и задача мониторинга — противостоять непредсказуемому.
Ну и еще — раз заговорили о VPS хостингах — мы всегда используем недорогие (hetzner, ovh, scaleway). И по бенчмаркам и по стабильности — очень нравится. Используем и гораздо более дорогой Amazon EC2 для других проектов. Так вот, благодаря okerr у нас есть свое обоснованное мнение. Падают — и те и другие. И я бы не сказал, что за долгое время наших наблюдений дешевые хостинги вроде hetzner оказались заметно менее стабильны, чем EC2. Поэтому, если вы не завязаны на другие фичи Амазона — зачем платить больше? 🙂
Что дальше?
После регистрации будет предложено пройти тренинг (выполнить несколько не очень сложных обучающих задач). Изначальные лимиты очень небольшие, но для тренинга или одного сервера их достаточно. После прохождения тренинга — лимиты (например, максимальное количество индикаторов) будут повышены.
Если будете использовать всерьез и этих повышенных лимитов будет не хватать — тоже, напишите в саппорт, увеличим (бесплатно).
IQBuzz
Система проводит круглосуточный мониторинг социальных сетей, что позволяет получать информацию в режиме реального времени. Существует возможность коллективной работы с сервисом, а также открытия общего доступа к анализируемым данным для всех желающих.
Система определяет тональность пользовательских сообщений, анализирует социально-демографические характеристики их авторов на основании информации из профайлов соцсетей.
На сайте системы указано, что есть возможность бесплатного тестирования в течение 7 дней.
Пример сводного отчёта — показатели упоминаемости Cossa.ru за последний месяц:
Стоимость: от 3 500 до 21 000 рублей в месяц.
Технические детали
Описание системы
Список сервисов:
- Agent Client — клиент, разворачиваемый на устройстве. Собирает информацию о процессоре, загрузке памяти и сетевом взаимодействии. Отправляет информацию в Agent Server.
- Agent Server — обработчик информации, поступающей от клиента. Собирает список клиентов в Mongo, а информацию от агентов передает в Storage.
- Application Monitoiring — мониторинг приложений, осуществляемый путем добавления модулей/пакетов Squzy в приложения, собирающих информацию о транзакциях. На текущий момент поддерживается GoLang и NodeJS, в краткосрочной перспективе — PHP & Java имплементации.
- Monitoring — мониторинг external/internal сервисов.
- Storage — сервис для доступа к собранной статистике. Текущая имплементация использует Postgres, но в дальнейшем планируется перейти на ClickHouse.
- Incident Manager- обработка инцидентов. Система позволяет пользователю создавать свои собственные правила обработки нештатных ситуаций (подробнее об этом расскажем чуть позже). Сами правила хранятся в Mongo, в то время как инциденты в случае возникновения передаются в Storage.
- Notification Manager — сервис для уведомления пользователей в случае возникновения инцидента. На текущий момент поддерживает уведомления в Webhook & Slack.
- API — является API Gateway для системы
- Tcp — проверка открытого порта;
- Http — проверка на соответствие статус коду;
- SiteMap — проверка того, что все URL из Sitemap отвечают 200 OK;
- JsonValue — сбор определенных значений из JSON ответа.
Squzy позволяет добавлять свои заголовки ко всем видам HTTP проверок.
- Длительность проверки (время получения ответа от сервера);
- Статус (возвращаемый статус код);
- Значение (информация, передаваемая в чекере).
Squzy agent
- CPU — нагрузка по процессорам;
- Memory — Used/Free/Total/Shared;
- Disk — Used/Free/Total по каждому из дисков;
- Net — по каждому сетевому интерфейсу.
Timeline агента:
- Агент регистрируется в Agent Server и получает ID (при регистрации есть возможность указать интервал мониторинга и имя агента);
- Агент с определенным интервалом отправляет статистику на сервер;
- ….
- Агент уведомляет сервер о выключении.
Если связи с сервером нет, агент продолжает собирать статистику и она будет отправлена при восстановлении соединения.
Squzy Application Monitoring
GoNodeJsHttpRoutergRPCWebSocket
Можно создавать инциденты на транзакции, основываясь на следующих данных:
- Длительность транзакции;
- Статус транзакции;
- Полученные ошибки;
- Тип транзакции.
Squzy Incident Manager + Notification Manager
Last Use
Заключение
- добавление Java/PHP интеграций;
- чекеры баз данных;
- переход с Postgres на ClickHouse;
- больше методов нотификаций;
- интеграция с kubernetes;
- улучшение документации;
- GQL API;
- Интеграционные и E2E тесты ;
- мониторинг мобильных приложений.
- Автодополнения для правилов инцидентов на UI
Просмотр результатов
Во время сканирования в верхней части любой страницы Spiceworks отображается шкала
Как только она пропадет, значит сканирование завершено. А наши модули наполнятся собранной информацией.
Модули Spiceworks обладают большой интерактивностью. Например, мы можем кликнуть по диаграмме состояния антивирусов в том месте, где показывается количество незащищенных ПК и сразу же увидим список этих компьютеров.
Кликнув по диаграмме журнала событий мы сможем увидеть на каких компьютерах какие ошибки возникают.
Кликая по компьютеру мы можем увидеть всю информацию о нем: модель, серийный номер, характеристики железа, ОС, список установленных программ, кто сейчас работает за этим ПК, какой IP адрес назначен, в какой коммутатор и в какой порт воткнут. Вообщем всё что нужно знать.
Здесь же можно внести свои коментарии, отредактировать другую информацию, пересканировать ПК и пр.
Если был просканирован ИБП, то будет доступна информация о статусе батереи. При сканировании управляемого коммутатора система может сама сделать резерную копию его конфигурации, показать к каким портам что подключено и есть ли трафик.
Не менее интересная информация и по принтерам:
Причем здесь Spiceworks способен «добывать» информацию, даже если принтер не сетевой, а работает через Ethernet-USB принт-сервер.
Таким образом у нас всегда перед глазами есть исчерпывающая информация обо всей инфраструктуре. Кстати, если всё правильно настроить, то Spiceworks еще и карту сети нарисует.
Вобщем функций настолько много, что в рамках одной статьи всё это не рассказать. На этом я пока прервусь, а продолжение рассказа будет в следующей части.
BuzzLook
Система представляет собой панель для обработки упоминаний в социальных медиа, на форумах, в YouTube и Flickr. С её помощью можно следить за репутацией собственной компании и деятельностью конкурентов, собирать предложения клиентов и поддерживать онлайн-сообщество бренда. Сервис предоставляет бесплатную возможность 14-дневного тестирования, после чего можно выбрать один из 3-х тарифов обслуживания:
Так, по запросу «Cossa.ru» удалось обнаружить упоминания наших материалов в Facebook и Twitter, а вот с YouTube начались проблемы — помимо видео из проекта «Индекс влияния», система выделила как содержащие упоминания о нашем портале видео об элитном отеле и массажном салоне в Италии.
ПРЕИМУЩЕСТВА
Распределенный мониторинг устройств в удалённых сетях.
Мониторинг активного сетевого оборудования, управляемых коммутаторов, UPS, служб, серверов, систем видеонаблюдения, видеокамер, IP-камер, цифровых видео-регистраторов, каналов связи.
Отображение результатов на карте.
Анализ исторических данных и трендов на графиках.
Оповещения об авариях и отклонениях значений параметров.
Мониторинг S.M.A.R.T. и жёстких дисков.
Поддержка SNMP trap и разнообразных датчиков.
Простота установки и настройки. Не нужно пробрасывать порты через NAT для проверки хостов в удаленной сети!
Программа от российских разработчиков (русскоязычная поддержка, в росреестре ПО Минкомсвязи).
Работаем на рынке ПО с 1998 года (22 года). Разработка решений для мониторинга ведется уже 17 лет с 2003 года!
Десятки видов проверок (пинг ICMP, SNMP, Traps, WMI, HTTP, базы данных SQL, SSH, TCP, ARP, Event Log, процессы, службы, скрипты, диски, S.M.A.R.T., загрузка процессора, температура, принтеры, уровень тонера, коммутаторы, ИБП, камеры систем видеонаблюдения, видеорегистраторы, трафик сети, NetFlow, …).
- Дополнительная информация:
- История версий
- Узнать цены
- Скриншоты
- Документация
- FAQ (частые вопросы и ответы)
Состояние процессоров
Загрузка процессора, приближенная к 100%, может негативно повлиять на здоровье сетевого хоста или сети в целом. Это тот случай, когда мы должны мгновенно узнавать о превышении допустимых порогов. Для этого, как вы уже поняли, мы используем Nagios. Изучая графики из Cacti и наблюдая за системой в реальном времени, мы понимаем тренды и цикличность работы процессоров. Все это помогает инженерам находить и обезвреживать проблемы до того, как они скажутся на работе сети.
Производим запрос состояния процессора сетевых устройств:
- OID: 1.3.6.1.4.1.9.9.109.1.1.1.1.7.index
- Ответ: iso.3.6.1.4.1.9.9.109.1.1.1.1.7.2098 = Gauge32: 2
Получаем значение загрузки CPU в минуту.

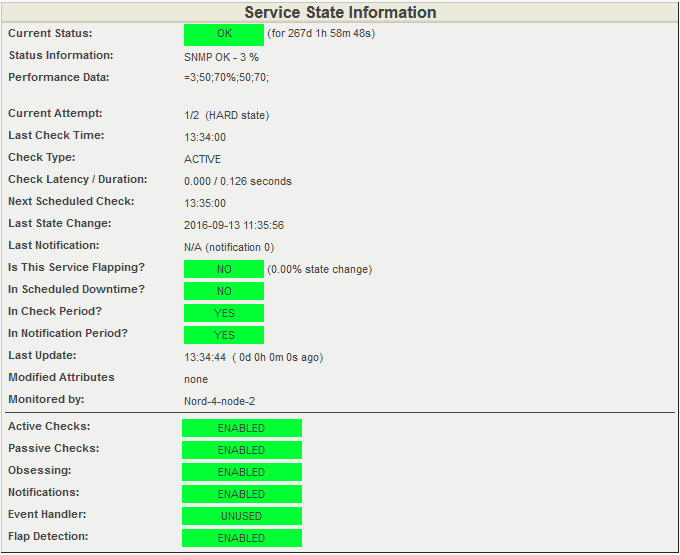
Состояние загрузки процессора в Nagios
Открываем подробную информацию о состоянии процессора
Снова обратим внимание на пункт Performance Data на скриншоте ниже. Он содержит информацию о текущей загрузке процессора и пороговые значения
Текущая загрузка составляет 3%. Предупреждение система выдаст при загрузке 50% и даст сигнал CRITICAL при 70% загруженности.
ВЕРСИИ: ОБЫЧНАЯ И PRO
| Функции \ Программы |
10-Страйк: Мониторинг Сети |
10-Strike LANState Pro |
|
|---|---|---|---|
|
Обычная |
Pro |
||
| Графическая схема сети | — | + | + |
| Сканирование топологии сети | — | — | + |
| Фоновая работа в режиме службы | + | + | — |
| Мониторинг распределенных сетей | — | + | — |
| Проверки хостов за роутером без форвардинга портов через NAT | — | + | — |
| Хранение результатов и настроек в единой SQL-СУБД | — | + | — |
| Возможность использования удаленных агентов на ПК | — | + | — |
| Мониторинг температуры ЦП и скорости вентиляторов (в агенте) | — | + | — |
| Мониторинг параметров SMART на жестких дисках (в агенте) | — | + | — |
| Встроенный веб-сервер для просмотра результатов | — | + | + |
| Управление через веб-интерфейс | — | + | — |
| Многопользовательский режим, разграничение доступа | — | + | — |
В версии Pro также есть графическая карта.
Мы добавили в таблицу другую нашу программу «10-Strike LANState Pro» для сравнения. В ней реализован тот же самый набор проверок и оповещений, но есть графическая карта с расположенными на ней хостами (удобно видеть сразу что работает/не работает), по которой можно администрировать хосты и просматривать информацию по ним. Однако эта программа не работает в режиме службы.
Позже мы также добавили отображение результатов проверок на карте и в Pro-версию «10-Страйк: Мониторинг Сети».
СКАЧАТЬ ПРОГРАММУ