Тюнинг сетевого стека linux для ленивых
Содержание:
- Разбивка и опции монтирования дисков для изоляции
- Install Keepalived
- Запуск
- Установка и обновление программного обеспечения в Linux (CentOS)
- Файлы конфигурации и логи планировщика cron
- VRRP synchronization group(s)
- Проверка latency диска с помощью ioping
- Настройка VLAN через отдельный файл vlanXX
- Использование Virt-Manager для управления виртуальными машинами KVM
- 1.1. Авторские права
- Настройка нескольких сетевых интерфейсов в CentOS
Разбивка и опции монтирования дисков для изоляции
При установке CentOS (и любого дистрибутива Linux) на этапе разбивки диска, не создавайте один раздел, а отделите web-пространство от основного раздела, также создайте системные разделы:
- /root
- /boot
- /var
- /tmp
При изоляции разделов злоумышленники не смогут подняться выше директории web при взломе сайта и внедрения в него вредоносных скриптов.
Используйте специальные опции для безопасного монтирования некоторых разделов диска:
- noexec – не позволяет запускать бинарные файлы (нельзя использовать на корневой директории, так как это приведет к неработоспособности системы);
- nodev – предполагает, что на монтируемой файловой системе не будут созданы файлы устройств /dev. Так же не применимо к корневому каталогу;
- nosuid – запрещает операции с suid и sgid битами.
Данные параметры могут быть установлены на директорию, только если она существует как отдельный раздел. Вы можете настроить /etc/fstab согласно следующим рекомендациям, если таковые разделы на диске у вас существуют:
- /home — смонтировать с опциями nodev, nosuid, usrquota (включение квоты);
- /boot – смонтировать с опциями nodev, nosuid, noexeс — данный раздел требуется для загрузки системы, запретим что-либо менять в нем;
- /var — nosuid — под root пользователем выполнение процессов не запрещено;
- /var/log — смонтировать с опциями nodev, nosuid, noexeс;
- /var/www — смонтировать с опциями nodev, nosuid;
- /tmp — смонтировать с опциями nodev, nosuid, noexeс – данный раздел нужен только для хранения и записи временных файлов.
Все вышеперечисленные разделы монтируются с опцией rw (возможность записи).
Install Keepalived
Visit keepalived.org to grab latest source code. You can use the wget command to download the same (you need to install keepalived on both lb0 and lb1):
Install Kernel Headers
You need to install the following packages:
- Kernel-headers – includes the C header files that specify the interface between the Linux kernel and userspace libraries and programs. The header files define structures and constants that are needed for building most standard programs and are also needed for rebuilding the glibc package.
- kernel-devel – this package provides kernel headers and makefiles sufficient to build modules against the kernel package.
Make sure kernel-headers and kernel-devel packages are installed. If not type the following install the same:
Compile keepalived
Type the following command: Sample outputs:
checking for gcc... gcc checking for C compiler default output file name... a.out checking whether the C compiler works... yes checking whether we are cross compiling... no checking for suffix of executables... checking for suffix of object files... o ... ..... .. config.status: creating keepalived/check/Makefile config.status: creating keepalived/libipvs-2.6/Makefile Keepalived configuration ------------------------ Keepalived version : 1.1.19 Compiler : gcc Compiler flags : -g -O2 Extra Lib : -lpopt -lssl -lcrypto Use IPVS Framework : Yes IPVS sync daemon support : Yes Use VRRP Framework : Yes Use Debug flags : No
Compile and install the same:
Configuration
Your main configuration directory is located at /usr/local/etc/keepalived and configuration file name is keepalived.conf. First, make backup of existing configuration: Edit keepalived.conf as follows on lb0:
vrrp_instance VI_1 {
interface eth0
state MASTER
virtual_router_id 51
priority 101
authentication {
auth_type PASS
auth_pass Add-Your-Password-Here
}
virtual_ipaddress {
202.54.1.1/29 dev eth1
}
}
Edit keepalived.conf as follows on lb1 (note priority set to 100 i.e. backup load balancer):
vrrp_instance VI_1 {
interface eth0
state MASTER
virtual_router_id 51
priority 100
authentication {
auth_type PASS
auth_pass Add-Your-Password-Here
}
virtual_ipaddress {
202.54.1.1/29 dev eth1
}
}
Save and close the file. Finally start keepalived on both lb0 and lb1 as follows:
Verify: Keepalived Working Or Not
/var/log/messages will keep track of VIP: Sample outputs:
Feb 21 04:06:15 lb0 Keepalived_vrrp: Netlink reflector reports IP 202.54.1.1 added Feb 21 04:06:20 lb0 Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 202.54.1.1
Verify that VIP assigned to eth1: Sample outputs:
3: eth1: mtu 1500 qdisc pfifo_fast qlen 10000
link/ether 00:30:48:30:30:a3 brd ff:ff:ff:ff:ff:ff
inet 202.54.1.11/29 brd 202.54.1.254 scope global eth1
inet 202.54.1.1/29 scope global secondary eth1
ping failover test
Open UNIX / Linux / OS X desktop terminal and type the following command to ping to VIP: Login to lb0 and halt the server or take down networking: Within seconds VIP should move from lb0 to lb1 and you should not see any drops in ping. On lb1 you should get the following in /var/log/messages:
Feb 21 04:10:07 lb1 Keepalived_vrrp: VRRP_Instance(VI_1) forcing a new MASTER election Feb 21 04:10:08 lb1 Keepalived_vrrp: VRRP_Instance(VI_1) Transition to MASTER STATE Feb 21 04:10:09 lb1 Keepalived_vrrp: VRRP_Instance(VI_1) Entering MASTER STATE Feb 21 04:10:09 lb1 Keepalived_vrrp: VRRP_Instance(VI_1) setting protocol VIPs. Feb 21 04:10:09 lb1 Keepalived_healthcheckers: Netlink reflector reports IP 202.54.1.1 added Feb 21 04:10:09 lb1 Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 202.54.1.1
Conclusion
Your server is now configured with IP failover. However, you need to install and configure the following software in order to configure webserver and security:
- nginx or lighttpd
- iptables
Stay tuned, for more information on above configuration.
This entry is 1 of 10 in the CentOS / RHEL nginx Reverse Proxy Tutorial series. Keep reading the rest of the series:
- CentOS / Redhat Linux: Install Keepalived To Provide IP Failover For Web Cluster
- CentOS / Redhat: Install nginx As Reverse Proxy Load Balancer
- Handling nginx Failover With KeepAlived
- nginx: Setup SSL Reverse Proxy (Load Balanced SSL Proxy)
- mod_extforward: Lighttpsd Log Clients Real IP Behind Reverse Proxy / Load Balancer
- HowTo: Merge Apache / Lighttpsd / Nginx Server Log Files
- Linux nginx: Chroot (Jail) Setup
- HowTo: SPDY SSL Installation and Configuration
- Install Nginx Using Yum Command on CentOS/RHEL
- Create a Self-Signed SSL Certificate on Nginx
Запуск
Открываем порты
|
1 |
firewall-cmd—permanent—add-service=high-availability firewall-cmd—add-service=high-availability |
Данную процедуру выполняем на каждом из серверов.
Первым делом, необходимо авторизоваться на серверах следующей командой
|
1 |
Password node2Authorized node1Authorized |
Создаем кластер
|
1 |
pcs cluster setup—force—name CLUSETR node1 node2 Destroying cluster on nodesnode1,node2… node1Stopping Cluster(pacemaker)… node2Stopping Cluster(pacemaker)… node2Successfully destroyed cluster node1Successfully destroyed cluster Sending’pacemaker_remote authkey’to’node1′,’node2′ node1successful distribution of the file’pacemaker_remote authkey’ node2successful distribution of the file’pacemaker_remote authkey’ Sending cluster config files tothe nodes… node1Succeeded node2Succeeded Synchronizing pcsd certificates on nodes node1,node2… node2Success node1Success Restarting pcsd on the nodes inorder toreload the certificates… node2Success node1Success |
Разрешаем автозапуск и запускаем созданный кластер pcs cluster enable –all и pcs cluster start –all:
|
1 |
pcs cluster enable—all node1Cluster Enabled node2Cluster Enabled pcs cluster start—all node1Starting Cluster(corosync)… node2Starting Cluster(corosync)… node2Starting Cluster(pacemaker)… node1Starting Cluster(pacemaker)… |
При использовании 2-х нод (как в данном примере) отключаем stonith (нужен для «добивания» серверов, которые не смогли полностью завершить рабочие процессы) и кворум. STONITH (Shoot The Other Node In The Head) или Shoot является дополнительной защитой Pacemaker. При выполнении команды pcs status вы увидите предупреждение в выходных данных о том, что никакие устройства STONITH не настроены, и STONITH не отключен. Если вы используете данное решение в продакшене, то лучше включить STONITH. Так как даная система будет работать в DMZ, мы отключаем STONITH. Наличие кворума означает, что в кластере должно быть не менее 3-х узлов. Причем, необязательно все три узла должны быть с СУБД, достаточно на двух узлах иметь Мастер и Реплику, а третий узел выступает в роли «голосующего».
Наличие устройств фенсинга на узлах с СУБД. При возникновении сбоя устройства «фенсинга» изолируют сбойнувший узел – посылают команду на выключение питания или перезагрузку (poweroff или hard-reset). Выполняем на обоих нодах
|
1 |
pcs propertyset stonith-enabled=false pcs propertyset no-quorum-policy=ignore |
Если получаем ошибку
|
1 |
Errorunable toget cib Errorunable toget cib |
То скорее всего не запущены сервисы pcs cluster enable –all и pcs cluster start –all или не установлен пакет fence-agents-all
Что такое кворум? Говорят, что кластер имеет кворум при достаточном количестве «живых» узлов кластера. Достаточность количества «живых» узлов определяется по формуле ниже
|
1 |
n>N2 |
где n – количество живых узлов, N – общее количество узлов в кластере.
Как видно из простой формулы, кластер с кворумом – это когда количество «живых» узлов, больше половины общего количества узлов в кластере. Как вы, наверное, понимаете, в кластере, состоящем из двух узлов, при сбое на одном из 2-х узлов не будет кворума. По умолчанию, если нет кворума, Pacemaker останавливает ресурсы. Чтобы этого избежать, нужно при настройке Pacemaker указать ему, чтобы наличие или отсутствие кворума не учитывалось. Делается это с помощью опции no-quorum-policy=ignore.
Рассмотрим самый распространенный вариант использования Pacemaker. Он заключается в использовании виртуального IP-адреса, который будет назначаться активному узлу кластера.
Для этого создаем ресурс командой:
|
1 |
pcs resource create CLUSTER_IP ocfheartbeatIPaddr2 ip=100.201.203.50cidr_netmask=24op monitor interval=60s |
,где CLUSTER_IP — название ресурса (может быть любым);
ip=100.201.203.50 — виртуальный IP, который будет назначен кластеру;
cidr_netmask=24 — префикс сети (соответствует маске 255.255.255.0);
op monitor interval=60s — критическое время простоя, которое будет означать недоступность узла
Установка и обновление программного обеспечения в Linux (CentOS)
При усановке сервера никогда не используйте дистрибутивы ОС, собранные неизвестными лицами. Скачивайте дистрибутивы только с официальных зеркал и не пользуйтесь чужими кикстарт файлами для установки. Если вы не разбираетесь в чужом коде, лучше вообще отменить эту затею и установить все вручную, либо проанализировать кикстарт файл полностью, чтобы не установить что-то вредоносное на свой сервер.
Устанавливайте только минимально необходимое ПО. Установка и настройка только по делу и с помощью установщика yum и dnf. Проверьте все установленное ПО и удалите ненужные пакеты:
Используйте только официальные и доверенные репозитории пакетов.
Не используйте нешифрованные протоколы FTP, Telnet, Rlogin, Rsh.
Отключайте неиспользуемые сервисы на своем сервере, если в данный момент удаление сервиса вам не подходит.
Чтобы проверить список всех сервисов, используйте команду:
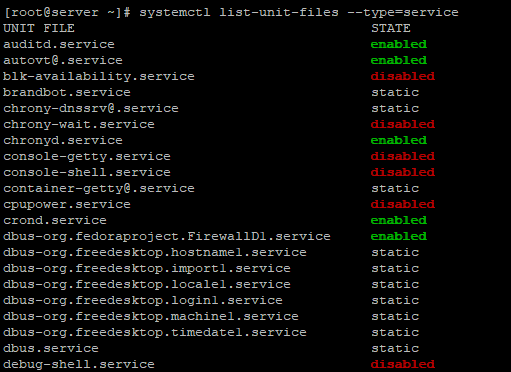
Чтобы отключить и убрать службу из автозагрузки в CentOS используется systemctl:
Например, для отключения сервиса httpd используется такая команда:
Всегда держите в актуальном состоянии установленное программное обеспечение на вашем сервере. Вовремя обновленное ПО, защитит вас от известных уязвимостей. Вы можете настроить автоматическое обновление системы, чтобы каждый раз не выполнять это вручную.
— обновление системы
Файлы конфигурации и логи планировщика cron
Основной файл конфигурации демона cron — /etc/crontab. Помимо cron-файла, задачи можно запускать из следующих директорий:
- /etc/cron.daily – запуск скриптов один раз в день
- /etc/cron.hourly – запуск скриптов ежечасно
- /etc/cron.monthly – запуск скриптов раз в месяц
- /etc/cron.weekly – запуск скриптов раз в неделю
Просто разместите нужны скрипты в нужную директорию, и они будут выполняться согласно расписания.
Можно ограничить доступ к планировщику с помощью файлов /etc/cron.allow и /etc/cron.deny. Достаточно создать эти файлы и добавить в него пользователей, которым, соотвественно, разрешено и запрещено запускать задания cron.
В файл /etc/crontab тоже можно помещать задания. Обычно данный файл используется root пользователем или для настройки системных задач. Личные файлы пользователей для cron заданий, хранятся в директории /var/spool/cron/ или /var/cron/tabs/.
Чтобы отследить выполнение задач или отследить ошибки, можно обратиться к лог-файлу /var/log/cron. В данном файле фиксируется запуск всех задач и ошибки в работе демона, если они есть:
VRRP synchronization group(s)
#string, name of group of IPs that failover together vrrp_sync_group VG_1 { group { inside_network # name of vrrp_instance (below) outside_network # One for
each moveable IP. … }
# notify scripts and alerts are optional # # filenames of scripts to run on transitions # can be unquoted (if just filename) # or quoted (if has parameters)
# to MASTER transition notify_master /path/to_master.sh # to BACKUP transition notify_backup /path/to_backup.sh # FAULT transition notify_fault «/path/fault.sh
VG_1»
# for ANY state transition. # «notify» script is called AFTER the # notify_* script(s) and is executed # with 3 arguments provided by keepalived # (ie don’t
include parameters in the notify line). # arguments # $1 = «GROUP»|»INSTANCE» # $2 = name of group or instance # $3 = target state of transition #
(«MASTER»|»BACKUP»|»FAULT») notify /path/notify.sh
Проверка latency диска с помощью ioping
Помимо IOPS есть еще один важный параметр, характеризующий качество вашей дисковой подсистемы – latency. Latency – это время задержки выполнения запроса ввода/вывода и характеризуют время доступа к системе хранения (измеряется в миллисекундах). Чем выше latency, тем больше приходится ждать вашему приложения данных от дисковой подсистемы. Для типовых систем хранения значения latency более 20 мс считаются плохими.
Для проверки latency диска используется утилита ioping:
Запустите тест latency для диска (выполняется 20 запросов):
4 KiB <<< /tmp/ (ext4 /dev/md126p5): request=1 time=1.55 ms (warmup) ...................... 4 KiB <<< /tmp/ (ext4 /dev/md126p5): request=11 time=368.9 us (slow) ................ 4 KiB <<< /tmp/ (ext4 /dev/md126p5): request=19 time=176.3 us (fast) 4 KiB <<< /tmp/ (ext4 /dev/md126p5): request=20 time=356.9 us --- /tmp/ (ext4 /dev/md126p5) ioping statistics --- 19 requests completed in 5.67 ms, 76 KiB read, 3.35 k iops, 13.1 MiB/s generated 20 requests in 19.0 s, 80 KiB, 1 iops, 4.21 KiB/s min/avg/max/mdev = 176.3 us / 298.7 us / 368.9 us / 45.7 us
Среднее значение 298.7 us (микросекунд), т.е. средняя latency диска в нашем случае 0.3 ms, что очень хорошо.
Значение latency может быть указано в us (микросекундах) или в ms (миллисекундах). Т.е. для получения из us значения в ms нужно разделить его на 1000.
Настройка VLAN через отдельный файл vlanXX
Теперь попробуем создать VLAN с ID 8 через отдельный файл конфигурации:
Добавим в него следующие строки:
ONBOOT=yes TYPE=Ethernet VLAN=yes VLAN_NAME_TYPE=VLAN_PLUS_VID_NO_PAD DEVICE=vlan8 PHYSDEV=eth0.8 VLAN_ID=8 BOOTPROTO=static IPADDR=10.16.20.10 NETMASK=255.255.255.0
Обратите внимание, что файл конфигурации немного отличается от предыдущего. В данной настройке, нужно указывать строку «PHYSDEV», которая направляет конфигурационный файл на физический сетевой интерфейс

После всех настроек, так же требуется перезагрузка сервиса network:
Если при перезапуске службы сетти вы получаете ошибку No suitable device found for this connection, проверьте что в конфигурационном файле ifcfg-vlan8 указано значение для опции VLAN_ID.
Сделаем проверку:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:1d:4b:67 brd ff:ff:ff:ff:ff:ff 5: eth0.7@eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:1d:4b:67 brd ff:ff:ff:ff:ff:ff 6: vlan8@eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:1d:4b:67 brd ff:ff:ff:ff:ff:ff
Нужный сетевой интерфейс с VLAN8 так же доступен.
Использование Virt-Manager для управления виртуальными машинами KVM
Щелкнув ПКМ по виртуальной машине, вы можете выключить, перезагрузить, включить ВМ.

Далее я хочу изменить директорию для хранения файлов виртуальных машин, так как основное место на диске при установке операционной системы на сервере с KVM, я отдал под директорию VZ. Чтобы поменять стандартную директорию, перейдите в меню “Edit -> Connection Details”.
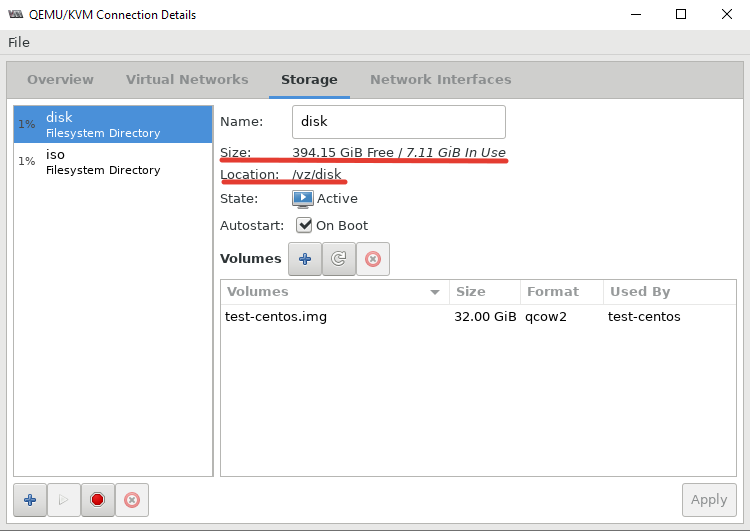
 В открывшемся окне, нужно перейти во вкладку “Storage”. Для создания нового пула, нужно остановить работу текущего и после чего удалить его:
В открывшемся окне, нужно перейти во вкладку “Storage”. Для создания нового пула, нужно остановить работу текущего и после чего удалить его:

После установки пула, кнопка удаления станет активна:

Теперь можно создать пул в нужной вам директории или разделе:


После этого, у меня стал активным мой основной раздел для файлов ВМ:
Либо просто удалить первоначальную директорию и создал симлинк на нужный раздел:
Теперь можно попробовать создать новую виртуальную машину KVM. Ниже я прикреплю ряд скриншотов, на которых по шагам будет все более-менее понятно. В конце опишу весь процесс создания машины.



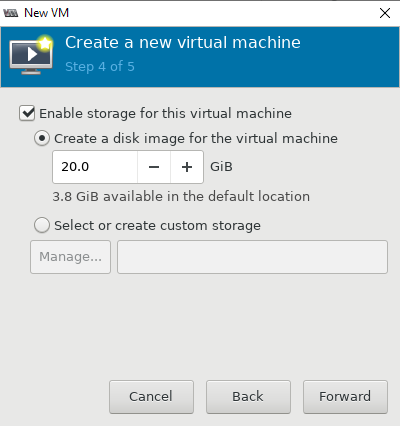
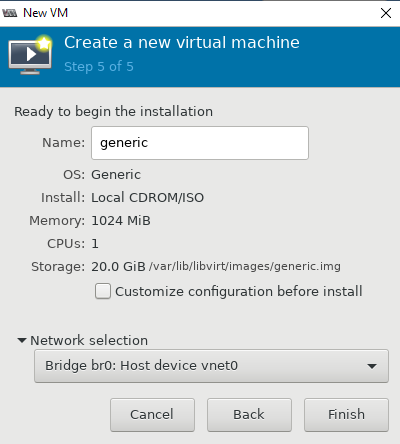

- При нажатии кнопки на первом скриншоте, запускается процесс создания новой виртуальной машины KVM;
- Затем указываем, откуда запускать установку ОС на виртуальной машине. Я использовал локальный ISO образ с дистрибутивом CentOS 8;
- Далее настраиваются ресурсы виртуальной машины: количество памяти и vCPU, размер виртуального диска (при необходимости его можно будет расширить или уменьшить), имя, и указываем сеть;
- После создания ВМ к ней сразу будет примонтирован установочный образ ОС, который указали при создании.
Чтобы изменить ресурсы или какие-то параметры уже созданной машины, вам нужно выделить ее и нажать кнопку “Open”. В открывшемся меню нажмите на лампочку и у вас откроется список параметров виртуальной машины KVM.

Чтобы добавить новый сервер KVM, выполните следующее “File -> Add Connection” и заполните данные в открывшемся окне:
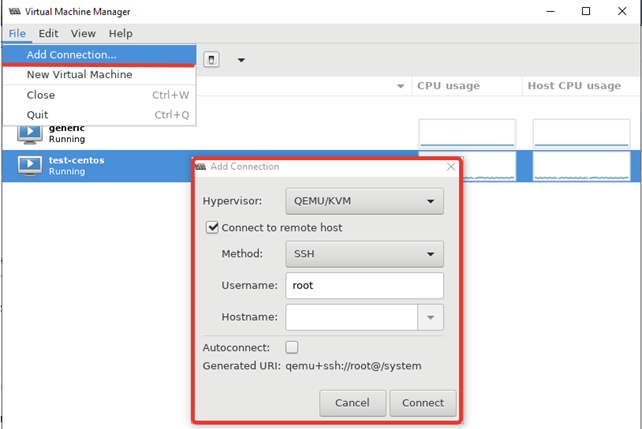
Red Hat Linux изменила статус virt-manager в RHEL 8 на deprecated, и возможно в следующих релизах OC этот пакет будет недоступен. Вместо него предлагается использовать веб интерфейс Cockpit. Однако на данный момент в модуле управления KVM в Cockpit пока нет хватает всех необходимых функций, доступных в virt-manager.
1.1. Авторские права
Авторские права на русский перевод этого текста принадлежат 2000 SWSoft Pte Ltd.
Все права зарезервированы.
Этот документ является частью проекта Linux HOWTO.
Авторские права на документы Linux HOWTO принадлежат их авторам, если явно
не указано иное. Документы Linux HOWTO, а также их переводы, могут
быть воспроизведены и распространены полностью или частично на любом
носителе, физическом или электронном, при условии сохранения этой заметки об
авторских правах на всех копиях. Коммерческое распространение разрешается и
поощряется; но, так или иначе, автор текста и автор перевода желали бы знать о
таких дистрибутивах.
Все переводы и производные работы, выполненные по документам Linux HOWTO,
должны сопровождаться этой заметкой об авторских правах. Это делается в
целях предотвращения случаев наложения дополнительных ограничений на
распространение документов HOWTO. Исключения могут составить случаи
получения специального разрешения у координатора Linux HOWTO, с которым
можно связаться по адресу приведенному ниже.
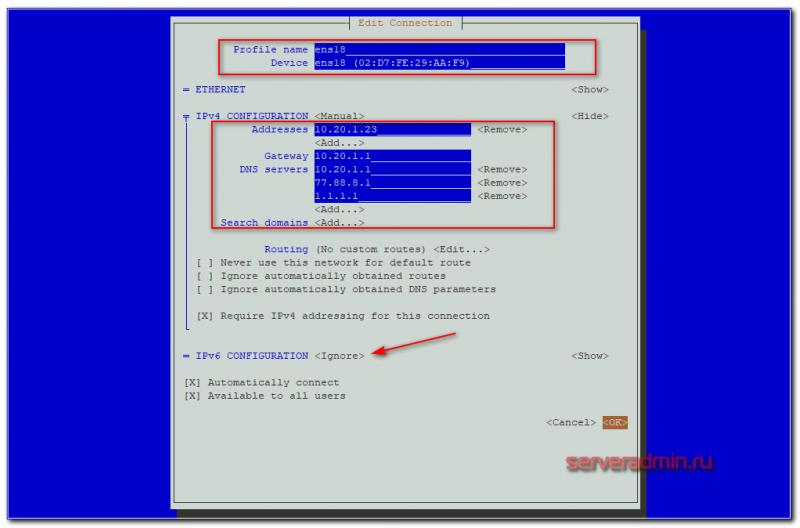
Настройка нескольких сетевых интерфейсов в CentOS
Если у вас на сервере несколько сетевых интерфейсов, для них можно указать разные IP-адреса. Разберемся как это сделать. Если у вас на сервере более одного сетевого интерфейса, команда “ip a” должна отобразить эту информацию:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 52:54:00:d3:1c:3e brd ff:ff:ff:ff:ff:ff inet 185.*.*.*/16 brd 185.*.*.255 scope global eth0 valid_lft forever preferred_lft forever 3: eth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether 52:54:00:5f:f3:b8 brd ff:ff:ff:ff:ff:f
Чтобы сконфигурировать второй интерфейс, нужно создать для него файл:
И добавьте следующую конфигурацию:
IPADDR="*.*.*.*" GATEWAY="*.*.*.*" NETMASK="255.255.255.0" BOOTPROTO="static" DEVICE="eth1" ONBOOT="yes"

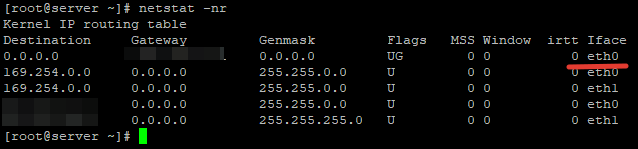
После этого на сервере нужно установить шлюз по умолчанию. Проверим какой шлюз установлен в данный момент и при необходимости поменяем его:
Kernel IP routing table Destination Gateway Genmask Flags MSS Window irtt Iface 0.0.0.0 185.*.*.1 0.0.0.0 UG 0 0 0 eth1 169.254.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0 169.254.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth1 185.*.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0 185.*.*.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1
В качестве основного шлюза у нас выступает интерфейс eth1. Я же хочу использовать eth0, для этого изменим его:
– заменяем шлюз на тот, который указан в сетевом интерфейсе eth0
— удаляем шлюз интерфейса eth1
Если вы хотите, чтобы данная настройка сохранилась после перезагрузки сервера, добавьте эти команды в rc.local (см. статью об автозагрузке сервисов в CentOS).