Myisam против innodb mysql engine для wordpress что лучше и конвертация таблиц базы данных
Содержание:
- Описание
- Недостатки
- Сжатие таблиц MyISAM в MySQL
- 4 ответа
- Approach 2. A More Nuanced Approach
- InnoDB Buffer Pool Size Calculator
- Word of Caution for InnoDB Buffer Pool Size Calculations
- Other Provisions For Performance
- Обзор InnoDB
- Вас заинтересует / Intresting for you:
- Недостатки
- Решение 1
- Таблицы только для чтения или преимущественно для чтения
- ALTER TABLE
- Решение 2
- Approach 1. Rule of Thumb Method
- История InnoDB
Описание
Таблицы MyISAM прекрасно подходят для использования в небольших интернет-проектах (WWW) и других средах, где преобладают запросы на чтение и нет жестких требований к надежности. Таблицы типа MyISAM показывают относительно хорошие результаты при выборках данных (запросы SELECT). Во многом это связано с отсутствием поддержки транзакций и внешних ключей. Однако при модификации и добавлении записей вся таблица кратковременно блокируется, это может привести к серьёзным задержкам при большой загрузке.
Для таблиц этого типа создан ряд специализированных утилит, позволяющих манипулировать табличными файлами. Сюда входят утилита myisamchk для проверки и восстановления таблиц и индексов (требует полной остановки процесса MySQL и создает время неработоспособности системы, исполнение заключается в создании с нуля нового целостного файла таблицы и перезаписи данных в него) и утилита myisampack для создания сжатых таблиц.
Таблицы MyISAM являются платформенно-независимыми. Табличные файлы можно перемещать между компьютерами разных архитектур и разными операционными системами без всякого преобразования. Для этого MySQL хранит все числа с плавающей запятой в формате IEEE, а все целые числа — в формате с прямым порядком следования байтов.
Индексные файлы имеют расширение .MYI (MYIndex). Файлы с расширением .MYD (MYData) содержат данные, а с расширением .frm — схему таблицы. Если индексный файл по какой-то причине теряется, программа перестраивает индексы, используя информацию из frm-файла.
По умолчанию в каждой таблице может быть не более тридцати двух индексов, но это значение можно повысить до шестидесяти четырёх. Индексы создаются в виде двоичных деревьев. Разрешается индексировать столбцы типа BLOB и TEXT, и столбцы, допускающие значения NULL.
В таблицах MyISAM могут быть фиксированные по длине, динамические либо сжатые записи. Выбор между фиксированным и динамическим форматом диктуется определениями столбцов. Для создания сжатых таблиц предназначена утилита myisampack.
Недостатки
- Отсутствует поддержка транзакций и внешних ключей.
- Отсутствие самовосстановления по журналу при сбоях (возможность присутствует во всех развитых СУБД).
- Отсутствие блокировок регионов, меньших, чем целые таблицы. Приводит к отсутствию масштабируемости, то есть к сильной деградации производительности с повышением нагрузки.
- Отсутствие средств резервного копирования. Утилита mysqldump, предлагаемая для создания резервных копий, является не инструментом резервного копирования, а инструментом экспорта в текст (в последовательность операторов INSERT, воссоздающих содержимое таблицы). Для выполнения задачи с сохранением целостности базы данных mysqldump блокирует таблицы, приводя к полной остановке работы системы на всё время своего исполнения.
- Для лучшей работы оптимизатора запросов может потребоваться периодическое исполнение команды ANALYZE.
- Слабая реализация сортировки, при использовании предложения ORDER BY языка SQL и отсутствии подходящего индекса. MyISAM сортирует данные слиянием, с использованием qsort для первоначально сливаемых небольших регионов. Это требует не только крайне неоптимального по дисковому вводу-выводу создания на каждую операцию сортировки 2 временных файлов, растущих с нулевого размера, с работой с ними через неоптимальные вызовы fopen() и fwrite(), но и выделения sort buffer для каждого клиента MySQL. Размер sort buffer (устанавливается параметром настройки MySQL sort_buffer_size) для достижения оптимальной производительности должен быть порядка сотен килобайт, что под большой нагрузкой приводит к полному исчерпанию не только кучи, но и пользовательского адресного пространства в 32-битных ОС семейства UNIX (во FreeBSD на x86 — 3 ГБ), и влечет за собой отказы вызовов malloc() во всем коде MySQL, а не только в коде сортировки. Поскольку во всем исходном коде MySQL (а не только MyISAM) вызовы malloc() зачастую забывают проверяться на ошибки, это влечет за собой крах всего mysqld, что как правило приводит к разрушению индексов, которые приходится пересоздавать вручную. В редких случаях такой крах может привести и к повреждению таблицы с утратой данных.
Данные недостатки проявляются в заметной степени при высокой нагрузке: более 400 клиентов, исполняющих сложные запросы по базе данных размером 2-3 ГБ.
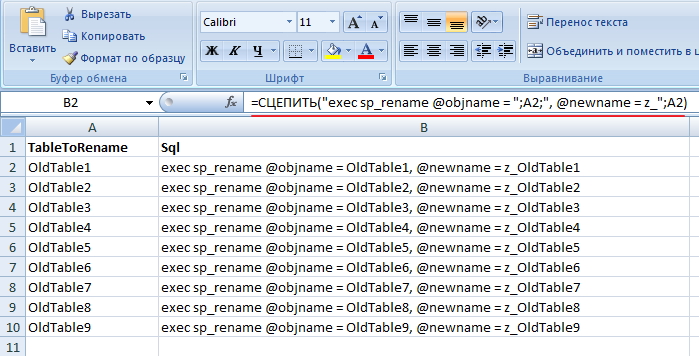
Сжатие таблиц MyISAM в MySQL
Для сжатия таблиц формата Myisam, нужно использовать специальный запрос с консоли сервера, а не в консоли mysql. Чтобы сжать нужную таблицу выполните:
Где /var/lib/mysql/test/modx_session — путь до вашей таблицы. К сожалению, у меня не было раздутой БД и пришлось выполнять сжатие на небольших таблицах, но результат все равно виден (файл сжался с 25 до 18 Мб):
25M modx_session.MYD
Compressing /var/lib/mysql/test/modx_session.MYD: (4933 records) - Calculating statistics - Compressing file 29.84% Remember to run myisamchk -rq on compressed tables
18M modx_session.MYD
В запросе, мы указали ключ -b, при его добавлении, перед сжатием создается бэкап таблицы и помечается как OLD:
-rw-r----- 1 mysql mysql 25550000 Dec 17 15:20 modx_session.OLD
25M modx_session.OLD
4 ответа
18
Два ответа приведены @RickJames и @drogart являются, по сути, средствами защиты. (+1 для каждого).
Справа от журнала ошибок, который вы представляете, последние две строки говорят:
В этот момент было очевидно, что вы установите до 256M (268435456) в , в то время как журналы транзакций InnoDB (, ) соответствовали соответственно 128 М (134217728). Оглядываясь назад на ссылку на мой ответ StackOverflow в вашем вопросе, вам нужно было сделать следующее
Шаг 01) Добавьте это в :
Шаг 02) Запустите эту команду в ОС
Чтобы иметь уверенность в том, что происходит, запустите против журнала ошибок. Вы увидите сообщение, сообщающее вам, когда создается файл журнала innodb.
4
Основываясь на ошибке в журнале, я предполагаю, что вы сделали это:
- отключить mysql
- отредактировано my.cnf, чтобы изменить размер файла журнала innodb
- попытался запустить mysql (тогда он не сработал)
Если вы измените размер файла журнала, вам нужно удалить старые файлы журналов. Innodb не запускается успешно, если существующие файлы не соответствуют указанному размеру в файле конфигурации. Если вы перемещаете их в другом месте, innodb будет создавать новые файлы журнала транзакций правильного размера при запуске.
Я бы рекомендовал переносить старые файлы в другой каталог, а не просто удалять их, пока сервер не будет запущен с новыми файлами журнала, и все будет выглядеть нормально.
3
Буфер-буфер должен быть установлен примерно на 70% от доступной ОЗУ, если вы используете только InnoDB.
Размер журнала не имеет большого значения. Оптимальным является его установка таким образом, чтобы (Uptime * innodb_log_file_size /Innodb_os_log_written) грубо 3600 (1 час).
Чтобы изменить размер журнала, нужно
- отключить mysqld cleanly
- удалить значение в my.cnf (my.ini)
- удалить файлы журнала
- retstart — новые файлы журнала будут восстановлены.
1
Также может возникнуть проблема в вашем размере для размера пула буферов . как это случилось в моем случае …
При увеличении или уменьшении операция выполняется в кусках. Размер блока определяется параметром конфигурации , который имеет значение по умолчанию 128M. Для получения дополнительной информации см. Настройка размера блока буфера пула InnoDB .
Размер пула буферов должен быть всегда равным или кратным . Если вы настроите на значение, которое не равно или несколько из , размер пула буферов автоматически настраивается на значение, равное или несколько из , который не меньше заданного размера пула буферов.
В этом примере установлено значение 8G, а для установлено значение 16. — 128M, что является значением по умолчанию .
8G является допустимым значением , потому что 8G является кратным , который равен 2G.
Approach 2. A More Nuanced Approach
This approach is based on a more detailed understanding of the internals of the InnoDB buffer pool and its interactions, which is described very well in the book High Performance MySQL.
Let’s look at the following method to compute the InnoDB buffer pool size.
- Start with total RAM available.
- Subtract suitable amount for the OS needs.
- Subtract suitable amount for all MySQL needs (like various MySQL buffers, temporary tables, connection pools, and replication related buffers).
- Divide the result by 105%, which is an approximation of the overhead required to manage the buffer pool itself.
For example, let’s look at a system with 192GB RAM using only InnoDB and having a total log file size of about 4GB. We can use a rule like ‘maximum of 2GB or 5% of total RAM’ for OS needs allocation as recommended in the above book, which comes to about 9.6GB. Then, we’ll also allocate about 4GB for other MySQL needs, mainly taking into account the log file size. This method results in about 170GB for our InnoDB buffer pool size, which is about 88.5% utilization of the available RAM size.
Though we used the ‘maximum of 2GB or 5% of total RAM’ rule to compute our memory allocation for OS needs above, the same rule does not work very well in all cases, specifically for systems with medium-sized RAMs between 2GB and 32GB. For instance, in a system with 3GB RAM, allocating 2GB for OS needs does not leave much for the InnoDB buffer pool, while allocating 5% of RAM is just too little for our OS needs.
So, let’s fine-tune the above OS allocation rule and examine the InnoDB computation method across various RAM configurations:
For Systems with Small-Sized RAM (<= 1GB)
For systems running with less than 1GB of RAM, it is better to go with the MySQL default configuration value of 128MB for InnoDB buffer pool size.
For Systems with Medium-Sized RAM (1GB – 32GB)
Considering the case of systems with a RAM size of 1GB – 32GB, we can compute OS needs using this rough heuristics:
256MB + 256 * log2(RAM size in GB)
The rationalization here is that, for low RAM configurations, we start with a base value of 256MB for OS needs and increase this allocation in a logarithmic scale as the amount of RAM increases. This way, we can come up with a deterministic formula to allocate RAM for our OS needs. We’ll also allocate the same amount of memory for our MySQL other needs. For example, in a system with 3GB of RAM, we would make a fair allocation of 660MB for OS needs, and another 660MB for MySQL other needs, resulting in a value of about 1.6GB for our InnoDB buffer pool size.
For Systems with Higher-Sized RAM (> 32GB)
For systems with RAM sizes greater than 32GB, we would revert back to calculating OS needs as 5% of our system RAM size, and the same amount for MySQL other needs. So, for a system with a RAM size of 192GB, our method will land at about 165GB for InnoDB buffer pool size, which is again, an optimal value to be used.
InnoDB Buffer Pool Size Calculator
Calculate the optimal value for any-sized RAM:
Compute
InnoDB Buffer Pool Size Calculator — Compute the optimal number for any system RAM sizeClick To Tweet
Word of Caution for InnoDB Buffer Pool Size Calculations
The considerations in this blog post are for Linux systems that are dedicated for MySQL. For Windows systems or systems that run multiple applications along with MySQL, these observations can be inaccurate. It’s also important to note that, though we can use these tools as references, it really takes good experience, experimentation, continuous monitoring, and fine-tuning to get the right sizing for your innodb_buffer_pool_size.
Other Provisions For Performance
slow_query_log
Of course, this variable does not help boost your MySQL server. However, this variable can help you out analyze slow performing queries. Value can be set to 0 or OFF to disable logging. Setting it to 1 or ON to enable this. The default value depends on whether the —slow_query_log option is given. The destination for log output is controlled by the log_output system variable; if that value is NONE, no log entries are written even if the log is enabled. You might set the filename or destination of the query log file by setting the variable slow_query_log_file.
long_query_time
If a query takes longer than this many seconds, the server increments the Slow_queries status variable. If the slow query log is enabled, the query is logged to the slow query log file. This value is measured in real time, not CPU time, so a query that is under the threshold on a lightly loaded system might be above the threshold on a heavily loaded one. The minimum and default values of long_query_time are 0 and 10, respectively. Take note also that if variable min_examined_row_limit is set > 0, it won’t log queries even if it takes too long if the number of rows returned are less than the value set in min_examined_row_limit.
sync_binlog
This variable controls how often MySQL will sync binlogs to the disk. By default (>=5.7.7), this is set to 1 which means it will sync to disk before transactions are committed. However, this impose a negative impact on performance due to increased number of writes. But this is the safest setting if you want strictly ACID compliant along with your slaves. Alternatively, you can set this to 0 if you want to disable disk synchronization and just rely on the OS to flush the binary log to disk from time to time. Setting it higher than 1 means the binlog is sync to disk after N binary log commit groups have been collected, where N is > 1.
Dump/Restore Buffer Pool
It is pretty common thing that your production database needs to warm up from a cold start/restart. By dumping the current buffer pool before a restart, it would save the contents from the buffer pool and once it’s up, it’ll load the contents back into the buffer pool.. Thus, this avoids the need to warm up your database back to the cache. Take note that, this version was since introduced in 5.6 but Percona Server 5.5 has it already available, just in case you wonder. To enable this feature, set both variables innodb_buffer_pool_dump_at_shutdown = ON and innodb_buffer_pool_load_at_startup = ON.
Обзор InnoDB
InnoDB сохраняет данные в одном или нескольких файлах данных, которые называются табличным пространством (tablespace). Табличное пространство, в сущности, является черным ящиком, которым управляет сама InnoDB. В MySQL 4.1 и более поздних версиях InnoDB может хранить данные и индексы каждой таблицы в отдельных файлах. Кроме того, она может располагать табличные пространства в «сырых» (неформатированных) разделах диска. Но современные файловые системы делают эту возможность бессмысленной.
InnoDB использует MVCC для обеспечения высокой степени конкурентности и реализует все четыре стандартных уровня изолированности SQL. Уровнем изоляции по умолчанию является REPEATABLE READ, а стратегия блокировки следующего ключа предотвращает фантомные чтения на этом уровне: вместо того чтобы блокировать только строки, затронутые в запросе, InnoDB блокирует пропуски в структуре индекса, предотвращая вставку фантомных строк.
Таблицы InnoDB строятся на кластеризованных индексах, которые мы детально рассмотрим в следующих главах. Структуры индексов в InnoDB значительно отличаются от используемых в других подсистемах хранения. В результате эта подсистема обеспечивает более быстрый поиск по первичному ключу. Однако вторичные индексы (индексы, не являющиеся первичным ключом) содержат все столбцы первичного ключа, так что если первичный ключ большой, то все прочие индексы тоже будут большими. Если в таблице планируется много индексов, нужно стремиться к тому, чтобы первичный ключ был небольшим. Формат хранения данных не зависит от платформы. Это означает, что вы можете без проблем скопировать файлы данных и индексов с сервера Intel на PowerPC или Sun SPARCI.
InnoDB поддерживает множество внутренних оптимизаций. В их число входят прогнозное упреждающее чтение для предварительной выборки данных с диска, адаптивный хеш-индекс, который автоматически выстраивает хеш-индексы в памяти для обеспечения очень быстрого поиска, и буфер вставок для ускорения операций вставки. Мы еще рассмотрим эти вопросы.
Подсистема InnoDB очень сложна, и если вы ее используете, то мы настоятельно рекомендуем вам прочитать раздел «InnoDB Transaction Model and Locking» («Транзакционная модель и блокировки в InnoDB») руководства по MySQL. Из-за наличия архитектуры MVCC в работе подсистемы InnoDB есть много тонкостей, о которых вы должны узнать прежде, чем создавать приложения. Работа с подсистемой хранения, поддерживающей согласованные представления данных для всех пользователей, даже когда некоторые пользователи меняют данные, может быть сложной.
В качестве транзакционной подсистемы хранения InnoDB поддерживает горячее онлайновое резервное копирование с помощью различных механизмов, включая запатентованную Oracle Enterprise Backup и Percona XtraBackup с открытым исходным кодом. В других подсистемах хранения MySQL нет горячих резервных копий — чтобы получить согласованную резервную копию, вам необходимо остановить все процессы записи в таблицу, которые при смешанной рабочей нагрузке на чтение и запись обычно заканчиваются также остановкой чтения.
Вас заинтересует / Intresting for you:
MyISAM: подсистема хранения ба… 677 просмотров Ирина Светлова Mon, 07 Jan 2019, 13:15:48
Использование MySQL в качестве… 707 просмотров Андрей Волков Tue, 01 Oct 2019, 05:41:51
Обзор версий MySQL — какой рел… 2468 просмотров Ирина Светлова Thu, 10 Jan 2019, 08:02:16
Модель развития базы данных My… 527 просмотров Ирина Светлова Thu, 10 Jan 2019, 12:29:03
Author: Ирина Светлова
Другие статьи автора:
Недостатки
- Отсутствует поддержка транзакций и внешних ключей.
- Отсутствие самовосстановления по журналу при сбоях (возможность присутствует во всех развитых СУБД).
- Отсутствие блокировок регионов, меньших, чем целые таблицы. Приводит к отсутствию масштабируемости, то есть к сильной деградации производительности с повышением нагрузки.
- Отсутствие средств резервного копирования. Утилита mysqldump, предлагаемая для создания резервных копий, является не инструментом резервного копирования, а инструментом экспорта в текст (в последовательность операторов INSERT, воссоздающих содержимое таблицы). Для выполнения задачи с сохранением целостности базы данных mysqldump блокирует таблицы, приводя к полной остановке работы системы на всё время своего исполнения.
- Для лучшей работы оптимизатора запросов может потребоваться периодическое исполнение команды ANALYZE.
- Слабая реализация сортировки, при использовании предложения ORDER BY языка SQL и отсутствии подходящего индекса. MyISAM сортирует данные слиянием, с использованием qsort для первоначально сливаемых небольших регионов. Это требует не только крайне неоптимального по дисковому вводу-выводу создания на каждую операцию сортировки 2 временных файлов, растущих с нулевого размера, с работой с ними через неоптимальные вызовы fopen() и fwrite(), но и выделения sort buffer для каждого клиента MySQL. Размер sort buffer (устанавливается параметром настройки MySQL sort_buffer_size) для достижения оптимальной производительности должен быть порядка сотен килобайт, что под большой нагрузкой приводит к полному исчерпанию не только кучи, но и пользовательского адресного пространства в 32-битных ОС семейства UNIX (во FreeBSD на x86 — 3 ГБ), и влечет за собой отказы вызовов malloc() во всем коде MySQL, а не только в коде сортировки.
Данные недостатки проявляются в заметной степени при высокой нагрузке: более 400 клиентов, исполняющих сложные запросы по базе данных размером 2-3 ГБ.
Решение 1
The biggest table you have makes up 16.47% (28/170) of the total data. Even if the table was highly written and highly read, not all 28G of the table is loaded in the buffer pool at one given moment. What you need to calculate is how much of the InnoDB Buffer Pool is loaded at any given moment on the current DB Server.
Here is a more granular way to determine innodb_buffer_pool_size for a new DB Server given the dataset currently loaded in the current DB Server’s InnoDB Buffer Pool.
Run the following on your current MySQL Instance (server you are migrating from)
SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool_pages_data'; -- IBPDataPages SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool_pages_total'; -- IBPTotalPages SHOW GLOBAL STATUS LIKE 'Innodb_page_size'; -- IPS
Run the formula IBPPctFull = IBPDataPages * 100.0 / IBPTotalPages.
SET @IBPDataPages = (SELECT VARIABLE_VALUE FROM information_schema.global_status WHERE VARIABLE_NAME = 'Innodb_buffer_pool_pages_data'); -- SELECT @IBPDataPages; SET @IBPTotalPages = (SELECT VARIABLE_VALUE FROM information_schema.global_status WHERE VARIABLE_NAME = 'Innodb_buffer_pool_pages_total'); -- SELECT @IBPTotalPages; SET @IBPPctFull = CAST(@IBPDataPages * 100.0 @IBPTotalPages AS DECIMAL(5,2)); SELECT @IBPPctFull;
If IBPPctFull is 95% or more, you should set innodb_buffer_pool_size to 75% of the DB Server’s RAM.
If IBPPctFull is less than 95%, run this formula : IBPSize = IPS X IBPDataPages / (1024*1024*1024) X 1.05.
SET @IBPSize = (SELECT VARIABLE_VALUE FROM information_schema.global_status WHERE VARIABLE_NAME = 'Innodb_page_size'); -- SELECT @IBPSize; SET @IBPDataPages = (SELECT VARIABLE_VALUE FROM information_schema.global_status WHERE VARIABLE_NAME = 'Innodb_buffer_pool_pages_data'); -- SELECT @IBPDataPages; SET @IBPSize = concat(ROUND(@IBPSize * @IBPDataPages (1024*1024*1024) * 1.05, 2), ' GB' ); SELECT @IBPSize;
The number for IBPSize (in GB) is the number that more closely fits your actual working dataset.
Now, if IBPSize is still too big for the biggest Amazon EC2 RAM Config, use 75% of the RAM for the Amazon EC2 DB Server.
Таблицы только для чтения или преимущественно для чтения
Таблицы с данными, которые используются для создания каталога или списка (вакансии, аукционы, недвижимость и т. п.), обычно характеризуются тем, что считывание из них происходит значительно чаще, чем запись в них. С такими таблицами хорошо применять MyISAM — если не думать о том, что происходит при ее сбое
Но не стоит недооценивать важность этого фактора. Многие пользователи не понимают, как рискованно применять подсистему хранения, которая даже не пытается извлечь данные, записанные на диск
(MyISAM просто записывает данные в память и предполагает, что операционная система сбросит их на диск позже.)
Не стоит слепо доверять народной мудрости сообщества, которая гласит: «MyISAM быстрее, чем InnoDB». Категоричность этого утверждения спорна. Мы можем перечислить десятки ситуаций, когда InnoDB на голову опережает MyISAM, особенно в приложениях, где применяются кластерные индексы или данные целиком размещаются в памяти. По мере дальнейшего чтения вы начнете понимать, какие факторы влияют на производительность подсистемы хранения (размер данных, требуемое количество операций ввода/вывода, первичные ключи и вторичные индексы и т. п.) и какие из них более значимы в вашем приложении.
Проектируя подобные системы, мы используем InnoDB. Сначала MyISAM может произвести впечатление хорошо работающей подсистемы, но при большой нагрузке она просто рухнет. Все будет заблокировано, и при сбое сервера вы потеряете данные.
ALTER TABLE
Простейший способ преобразования таблицы из одной подсистемы в другую — использование команды . Следующая команда преобразует таблицу mytable к типу InnoDB:
Такой синтаксис работает для всех подсистем хранения, но есть одна загвоздка — это может занять много времени. MySQL будет построчно копировать старую таблицу в новую. В это время, скорее всего, будет задействована вся пропускная способность диска сервера, а исходная таблица окажется заблокированной для чтения. Поэтому будьте осторожны, применяя этот подход для активно используемых таблиц. Вместо него можно задействовать один из рассмотренных далее методов, которые сначала создают копию таблицы.
При изменении подсистемы хранения утрачиваются все присущие старой подсистеме возможности. Например, после преобразования таблицы InnoDB в MyISAM, а потом обратно будут потеряны все внешние ключи, определенные в исходной таблице InnoDB.
Решение 2
Here is what you should do. First run this query
SELECT CEILING(Total_InnoDB_Bytes*1.6POWER(1024,3)) RIBPS FROM (SELECT SUM(data_length+index_length) Total_InnoDB_Bytes FROM information_schema.tables WHERE engine='InnoDB') A;
This will give you the RIBPS, Recommended InnoDB Buffer Pool Size based on all InnoDB Data and Indexes with an additional 60%.
For Example
mysql> SELECT CEILING(Total_InnoDB_Bytes*1.6/POWER(1024,3)) RIBPS FROM
-> (SELECT SUM(data_length+index_length) Total_InnoDB_Bytes
-> FROM information_schema.tables WHERE engine='InnoDB') A;
+-------+
| RIBPS |
+-------+
| 8 |
+-------+
1 row in set (4.31 sec)
mysql>
With this output, you would set the following in /etc/my.cnf
innodb_buffer_pool_size=8G
Next, service mysql restart
After the restart, run mysql for a week or two. Then, run this query:
SELECT (PagesData*PageSize)POWER(1024,3) DataGB FROM (SELECT variable_value PagesData FROM information_schema.global_status WHERE variable_name='Innodb_buffer_pool_pages_data') A, (SELECT variable_value PageSize FROM information_schema.global_status WHERE variable_name='Innodb_page_size') B;
This will give you how many actual GB of memory is in use by InnoDB Data in the InnoDB Buffer Pool at this moment.
Approach 1. Rule of Thumb Method
The most commonly followed practice is to set this value at 70% – 80% of the system RAM. Though it works well in most cases, this method may not be optimal in all configurations. Let’s take the example of a system with 192GB of RAM. Based on the above method, we arrive at about 150GB for the buffer pool size. However, this isn’t really an optimal number as it does not fully leverage the large RAM size that’s available in the system, and leaves behind about 40GB of memory. This difference can be even more significant as we move to systems with larger configurations where we should be utilizing the available RAM to a greater extent.
История InnoDB
История релизов InnoDB довольно сильно запутана, но очень помогает разобраться в этой подсистеме хранения данных. В 2008 году для версии MySQL 5.1 был выпущен так называемый плагин InnoDB. Это было следующее поколение InnoDB, созданное компанией Oracle, которой в то время принадлежала InnoDB, но не MySQL. По разным причинам, которые лучше обсуждать за кружкой пива, MySQL продолжала поставлять более старую версию InnoDB, скомпилированную на сервер. Но вы могли по собственному желанию отключить ее и установить новый, более эффективный и лучше масштабируемый плагин InnoDB. В конце концов компания Oracle приобрела компанию Sun Microsystems и, следовательно, СУБД MySQL и удалила старую кодовую базу, заменив ее «плагином» по умолчанию в версии MySQL 5.5. (Да, это означает, что теперь «плагин» фактически скомпилирован, а не установлен как плагин. Старая терминология изживается с трудом.)
Современная версия InnoDB, представленная в качестве плагина InnoDB в MySQL 5.1, обеспечивает новый функционал, например построение индексов путем сортировки, возможность удаления и добавления индексов без перестройки всей таблицы, новый формат хранения данных, который предполагает сжатие, новый способ хранения больших объемов данных, таких как столбцы BLOB, и управления форматом файлов. Многие люди, которые работают с MySQL 5.1, не применяют этот плагин, чаще всего потому, что не подозревают о нем. Если вы используете MySQL 5.1, убедитесь, пожалуйста, в том, что применяете плагин InnoDB. Он намного лучше более ранней версии InnoDB.
InnoDB настолько важна, что в ее разработку внесли свой вклад не только команда Oracle, но и многие другие люди и компании, в частности Ясуфуми Киносита (Yasufumi Kinoshita), а также компании Google, Percona и Facebook. Некоторые из внесенных ими усовершенствований были включены в официальный исходный код InnoDB, многие другие были немного переработаны командой InnoDB и затем внедрены. В целом развитие InnoDB значительно ускорилось за последние несколько лет, улучшения коснулись инструментария, масштабируемости, способности к изменению конфигурации, производительности, функций и поддержки для Windows и прочих важных вещей. Лабораторные превью и релизы ключевых изменений, вносимых в версию MySQL 5.6, также представляют множество замечательных новых функций InnoDB.
Oracle инвестирует колоссальные ресурсы и проделывает огромную работу для улучшения производительности InnoDB (и здесь очень полезным оказывается вклад, который вносят внешние разработчики). Во втором издании этой книги мы отмечали, что InnoDB выглядела довольно жалко, работая на основе четырехпроцессорных ядер. Теперь она хорошо масштабируется до 24 ядер процессора, а возможно, и до 32 или даже большего количества в зависимости от сценария.