Список поддерживаемых фонем в ssml
Содержание:
- Настраиваем доступ
- Внешний вид
- Управление умным домом Яндекса
- Русский
- Как работает речевая аналитика
- Командная строка Яндекса
- Условия и ограничения
- Знакомство с API Yandex SpeechKit
- Подготовимся. Настройка профиля CLI
- Запуск и внедрение речевой аналитики
- Использование сервиса
- Примеры использования
- Получение команд от станции
- Installation
Настраиваем доступ
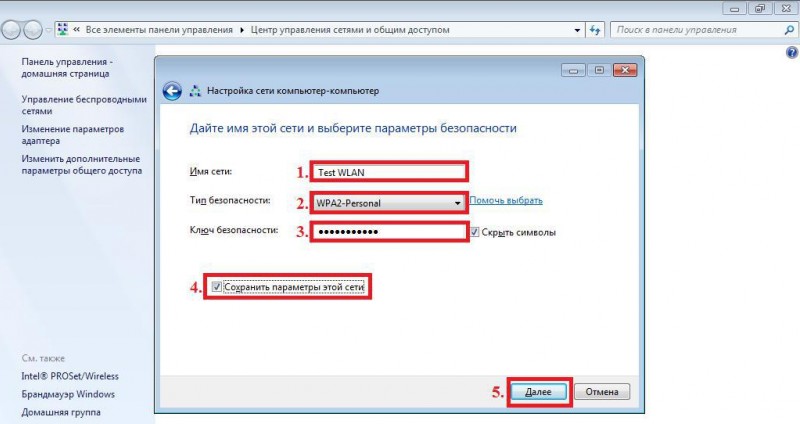
Есть два способа работать с сервисом SpeechKit: через IAM-токен, который нужно запрашивать заново каждые 12 часов, или через API-ключ, который постоянный и менять его не нужно. Мы будем работать через ключ, потому что так удобнее.
Чтобы его получить, нам нужен сервисный аккаунт в «Облаке». Создадим его так.
1. Заходим в консоль управления и нажимаем на единственную папку в нашем облаке:

2. Выбираем «Сервисные аккаунты» → «Создать»:

3. Вводим имя (какое понравится), затем нажимаем «Добавить роль» и выбираем «editor»:
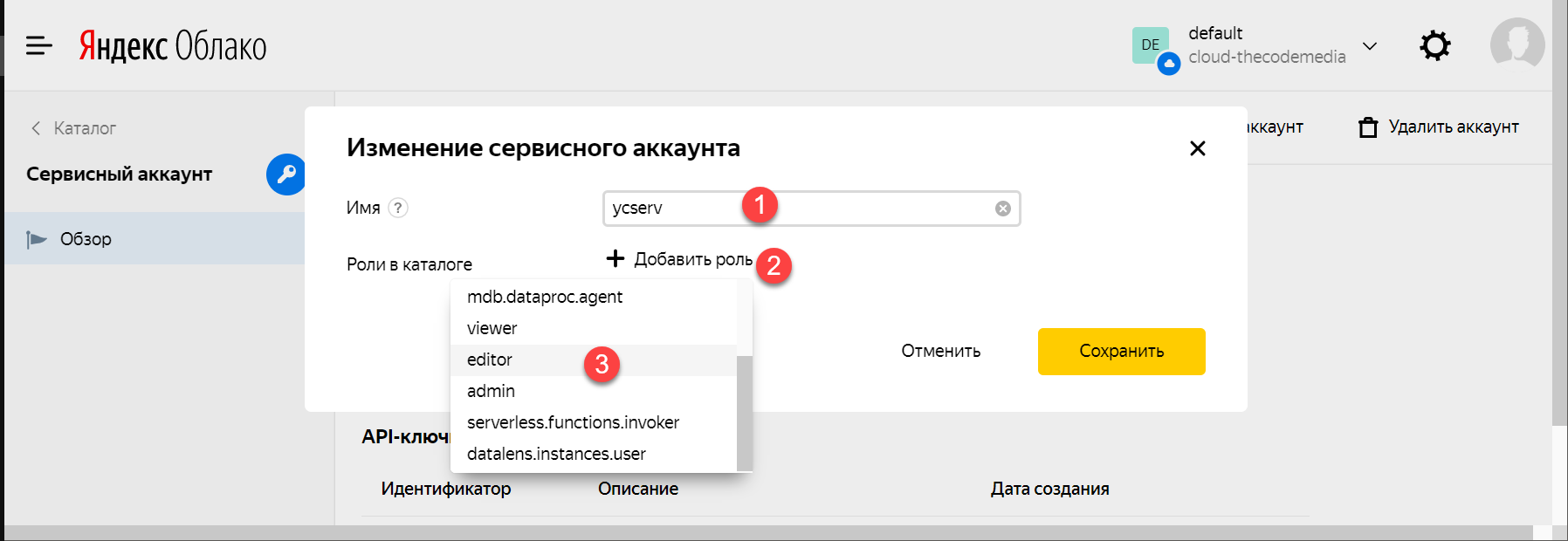
4. Заходим в сервисный аккаунт, который только что создали:

5. Нажимаем на кнопку «Создать новый ключ» и выбираем пункт «Создать API-ключ»:

Сервис спросит про описание — можно ничего не заполнять.
6. Сохраняем отдельно секретный ключ — он выдаётся только один раз и восстановить его нельзя. Выделяем, копируем и сохраняем в безопасное место:

Внешний вид
Красивые иконки Яндекс устройств можно установить через HACS.
Красивый медиа плеер можно установить через HACS.
Внимание: правильно указывайте название вашего TTS сервиса. По умолчанию он
Если вы его не изменили на по инструкции про . Тут на конце не нужно указывать.
Пример как настроить карточку Яндекс Мини:
entity: media_player.yandex_station_mini
shortcuts:
attribute: sound_mode
buttons:
- icon: 'mdi:voice'
id: Произнеси текст
type: sound_mode
- icon: 'mdi:google-assistant'
id: Выполни команду
type: sound_mode
- icon: 'mdi:playlist-star'
id: включи мою любимую музыку вперемешку
type: command
- icon: 'mdi:playlist-music'
id: включи плейлист дня
type: command
- icon: 'mdi:heart'
id: лайк
type: command
- icon: 'mdi:heart-off'
id: снять лайк
type: command
columns: 6
tts:
platform: yandex_station
type: 'custom:mini-media-player'
Пример как настроить карточку Яндекс Станции:
entity: media_player.yandex_station artwork: full-cover sound_mode: icon hide: sound_mode: false runtime: false tts: platform: yandex_station type: 'custom:mini-media-player'
Управление умным домом Яндекса
На данный момент поддерживаются:
- Кондиционеры — добавленные как через ИК-пульт, так и напрямую (например LG с Wi-Fi)
- Обученные вручную ИК-команды — обученные вручную команды ИК-пульта (Пульт => Добавить устройство => Настроить вручную)
В конфиге нужно перечислить имена ваших устройств:
yandex_station: username: myuser password: mypass include: - Кондиционер # имя вашего кондиционера - Приставка # имя не ИК-пульта, а устройства, настроенного вручную
Кондиционер будет добавлен как термостат:
script:
volume_up:
alias: Сделай громче
sequence:
- service: remote.send_command
entity_id: remote.yandex_station_remote # поменяйте на ваше устройство
data:
command: Сделай громче # имя кнопки в интерфейсе
num_repeats: 5 # (опционально) количество повторов
delay_secs: 0.4 # (опционально) пауза между повторами в секундах
turn_on:
alias: Включи телевизор
sequence:
- service: remote.send_command
entity_id: remote.yandex_station_remote # поменяйте на ваше устройство
data:
command: # можно несколько кнопок
delay_secs: 0.4 # (опционально) пауза между повторами в секундах
Русский
Список поддерживаемых фонем при использовании русского языка (). Подробнее о русской фонологии.
| IPA | X-SAMPA | Описание | Примеры |
|---|---|---|---|
| Согласные | |||
| b | b | твердая «б» (voiced bilabial plosive) | рыба |
| bʲ | b’ | мягкая «б» (palatalized voiced bilabial plosive) | бюро |
| d | d | твердая «д» (voiced alveolar plosive) | дом |
| dʲ | d’ | мягкая «д» (palatalized voiced alveolar plosive) | дядя |
| f | f | твердая «ф» (voiceless labiodental fricative) | форт |
| fʲ | f’ | мягкая «ф» (palatalized voiceless labiodental fricative) | финал |
| g | g | твердая «г» (voiced velar plosive) | гол |
| ɡʲ | g’ | мягкая «г» (palatalized voiced velar plosive) | герой |
| j | j | звук «й» (palatal approximant) | я , дизайн |
| k | k | твердая «к» (voiceless velar plosive) | кот , ку |
| kʲ | k’ | мягкая «к» (palatalized voiceless velar plosive) | кино , кю |
| l | l | твердая «л» (alveolar lateral approximant) | луч |
| lʲ | l’ | мягкая «л» (palatalized alveolar lateral approximant) | лес |
| m | m | твердая «м» (bilabial nasal) | мама |
| mʲ | m’ | мягкая «м» (palatalized bilabial nasal) | меч |
| n | n | твердая «н» (alveolar nasal) | нос |
| nʲ | n’ | мягкая «н» (palatalized alveolar nasal) | няня |
| p | p | твердая «п» (voiceless bilabial plosive) | папа |
| pʲ | p’ | мягкая «п» (palatalized voiceless bilabial plosive) | пена |
| r | r | твердая «р» (alveolar trill) | рок |
| rʲ | r’ | мягкая «р» (palatalized alveolar trill) | рис |
| s | s | твердая «с» (voiceless alveolar fricative) | суд |
| sʲ | s’ | мягкая «с» (palatalized voiceless alveolar fricative) | сено , русь |
| ɕ: | s: | шипящая «щ» (long voiceless alveolo-palatal fricative) | щит |
| ʂ | s` | шипящая «ш» (voiceless retroflex fricative) | шест |
| t | t | твердая «т» (voiceless alveolar plosive) | танк |
| tʲ | t’ | мягкая «т» (palatalized voiceless alveolar plosive) | тётя |
| t͡s | ts | звонкая «ц» (voiceless alveolar affricate) | царь |
| t͡ɕ | ts\ | глухая «ч» (voiceless alveolo-palatal affricate) | чуть |
| v | v | твердая «в» (voiced labiodental fricative) | вон |
| vʲ | v’ | мягкая «в» (palatalized voiced labiodental fricative) | весы |
| x | x | твердая «х» (voiceless velar fricative) | хор |
| xʲ | x’ | мягкая «х» (palatalized voiceless velar fricative) | химия |
| z | z | твердая «з» (voiced alveolar fricative) | зуб |
| zʲ | z’ | мягкая «з» (palatalized voiced alveolar fricative) | зима |
| ʑ: | z: | буквосочетания «зж» и «жж» (long voiced alveolo-palatal fricative) | езжу , вожжи |
| ʐ | z` | короткая «ж» (voiced retroflex fricative) | жена |
| Гласные | |||
| ə | @ | Шва — безударные «а», «о» или «э» (mid central vowel) | корова , молоко |
| a | a | ударная «а» или «я» (open front unrounded vowel) | там , мяч , яма |
| ɐ | 6 | безударная «а» (near-open central vowel | каравай , голова |
| e | e | ударная «е» (close-mid front unrounded vowel) | печь |
| ɛ | E | ударная «э» (open-mid front unrounded vowel) | это |
| i | i | ударная «и» (close front unrounded vowel) | лист |
| ɪ | I | «е» или «и» после палатализованной согласной в безударном слоге (near-close front unrounded vowel) | дерево |
| ɨ̞ | I\ | «е» или «и» после непалатализованной согласной в безударном слоге (near-close central unrounded vowe) | жена |
| ɨ | 1 | ударная «ы» (close central unrounded vowel) | рыло |
| o | o | ударная «о» (close-mid back rounded vowel) | кот |
| u | u | ударная «у» или «ю» (close back rounded vowel) | муж , вьюга |
| ʊ | U | безударная «у» или «ю» (near-close back rounded vowel) | сухой , мужчина |
Как работает речевая аналитика
Сервис Yandex SpeechKit, а именно его функциональность speech-to-text, позволяет преобразовать неструктурированную аудиоинформацию в текст. Распознанный текст — это основа для структурирования и разметки. Его можно преобразовать в данные, которые позволят «подсвечивать» важные события о клиентах и сотрудниках в учётных системах, принимать решения, планировать маркетинговые и sales-активности.
С помощью речевой аналитики Yandex SpeechKit вы сможете контролировать 100% звонков в автоматическом режиме. Вы сможете не только оценить работу оператора, но и лучше узнать клиентов. В результате — не только сделать выводы о конкретных операторах, но и о клиентах. Например, если из 10 000 звонков 500 закончились негативом, система сообщит вам, что этим абонентам нужно перезвонить и устранить негатив.
Преимущества речевой аналитики на базе Yandex SpeechKit
Облачный сервис Yandex SpeechKit распознаёт речь с помощью технологии транскрибации. Она переводит длинные аудиозаписи в текст, разделяя речь по каналам и проставляя временные метки начала и конца каждого слова. Загрузка аудиофайлов для распознавания не требует нарезки и это ускоряет процесс распознавания.
Yandex SpeechKit способен обработать миллионы часов аудио в кратчайшие сроки. Например, 100 часов аудио из 200 файлов можно обработать меньше, чем за час.
Командная строка Яндекса
С её помощью мы сможем получать нужные ключи доступа, чтобы отправлять файлы с записями на сервер для обработки.
Весь процесс установки мы опишем для Windows. Если у вас Mac OS или Linux, то всё будет то же самое, но с поправкой на операционную систему. Поэтому если что — .
Для установки и дальнейшей работы нам понадобится PowerShell — это программа для работы с командной строкой, но с расширенными возможностями. Запускаем PowerShell и пишем там такую команду:
iex (New-Object System.Net.WebClient).DownloadString(‘https://storage.yandexcloud.net/yandexcloud-yc/install.ps1’)
Она скачает и запустит установщик командной строки Яндекса. В середине скрипт спросит нас, добавить ли путь в системную переменную PATH, — в ответ пишем Y и нажимаем Enter:
Командная строка Яндекса установлена в системе, закрываем PowerShell и запускаем его заново. Теперь нам нужно получить токен авторизации — это такая последовательность символов, которая покажет «Облаку», что мы — это мы, а не кто-то другой.
Переходим по специальной ссылке, которая даст нам нужный токен. Сервис спросит у нас, разрешаем ли мы доступ «Облака» к нашим данным на Яндексе — нажимаем «Разрешить». В итоге видим страницу с токеном:
Теперь нужно закончить настройку командной строки Яндекса, чтобы можно было с ней полноценно работать. Для этого в PowerShell пишем команду:
yc init
Когда скрипт попросит — вводим токен, который мы только что получили:
Сначала отвечаем «1», затем «Y» и «4».
Условия и ограничения
Распознавание речи — платная услуга, но Яндекс даёт 60 дней и 3000 ₽ для тестирования. За эти деньги можно распознать 83 часа аудио — больше трёх суток непрерывного разговора. Это очень много: за время подготовки этой статьи и тестирования технологии мы потратили 4 рубля за 3 дня.
Если отправлять файлы с записью больше минуты, то одна секунда аудио стоит одну копейку. Чтобы распознать запись длиной в час, нужно 36 рублей. Это примерно в 20 раз дешевле, чем берут транскрибаторы — люди, которые сами набирают текст на слух, прослушивая запись.
Нейросеть часто понимает, когда текст нужно разбить на абзацы, но делает это не всегда правильно. Ещё она не ставит запятые, тире и двоеточия. Максимум, что она делает — ставит точку в конце предложения и начинает новое с большой буквы. Но при этом почти все слова распознаются правильно, и отредактировать такой текст намного проще, чем набирать его с нуля.
Последнее — из-за особенностей нашей речи и произношения SpeechKit может путать слова, которые звучат одинаково (код — кот) или ставить неправильное окончание («слава обрушилось на него неожиданно»). Решение простое: прогоняем такой текст через орфонейрокорректор и всё в порядке. Одна нейронка исправляет другую — реальность XXI века
Всё, приступаем.
 Иногда результат получается вот таким, но на понимание текста это не сильно влияет.
Иногда результат получается вот таким, но на понимание текста это не сильно влияет.
Знакомство с API Yandex SpeechKit
Представьте простую, максимально идеальную ситуацию без подводных камней типа “а если..”. Вы организуете закрытую вечеринку и хотите общаться с гостями, ни на что не отвлекаясь. Тем более на тех, кого вы не ждали.
Давайте попробуем создать виртуального дворецкого, который будет встречать гостей и открывать дверь только приглашенным.
Синтез текста через cURL
С помощью встроенной в bash команды export запишем данные в переменные:
Теперь их можно передать в POST-запрос с помощью cURL:
Рассмотрим параметры запроса:
speech.raw – файл формата LPSM (несжатый звук). Это и есть озвученный текст в бинарном виде, который будет сохранен в текущую папку.
lang=ru-RU – язык текста.
emotion=good – эмоциональный окрас голоса. Пусть будет дружелюбным.
voice=ermil – текст будет озвучен мужским голосом Ermil. По умолчанию говорит Оксана.
https://tts.api.cloud.yandex.net/speech/v1/tts:synthesize – url, на который отправляется post-запрос на синтез речи дворецкого.
Бинарный файл послушать не получится, тогда установим утилиту SoX и сделаем конвертацию в wav:
speech.wav – приветствие готово и сохранено в текущую папку.
Для проигрывания wav внутри кода Python, можно взять, например, библиотеку simpleaudio. Она простая и не создает других потоков:
Итак, наш первый гость стоит перед входом на долгожданную party. Пытается открыть дверь, и вдруг слышит голос откуда-то сверху:
«Привет, чувак! Назови-ка мне свои имя и фамилию?» (или ваш вариант)
Отлично! Вы научили дворецкого приветствовать гостей, используя командную строку и cURL. А пока гость вспоминает ответ, научимся работать с API на языке Python.
Распознавание текста с помощью requests
Мы могли бы снова воспользоваться cURL для отправки ответа гостя на распознавание. Но мы пойдем дальше и напишем небольшую программу, основанную на подобных запросах.
Создайте готовый аудио-файл с ответом гостя. Сделать это можно через встроенный микрофон на вашем ноутбуке разными инструментами. Для macos подойдет Quick Time Player. Сконвертируйте аудио в формат ogg: name_guest.ogg. Можно онлайн, например, тут
Итак, пишем код на Python:
Для отправки запросов в Python воспользуемся стандартной библиотекой requests:
Импортируем в код:
Зададим параметры, которые мы получили в командной строке:
Аудио необходимо передавать в запрос в бинарном виде:
Давайте обернем весь процесс распознавания в функцию recognize:
Итак, чтобы дворецкий смог проверить гостя по списку, вызовем функцию и распознаем ответ:
Теперь очередь за дворецким. В нашем случае, он вежлив ко всем. И прежде чем открыть или не открыть гостю дверь, он обратится лично. Например, так:
“Мы вам очень рады, <имя_и фамилия_гостя>, но вас нет в списке, сорян”
Для последующего синтеза вы можете снова воспользоваться CURL или так же написать функцию на Python. Принцип работы с API для синтеза и распознавания речи примерно одинаков.
Подготовимся. Настройка профиля CLI
Активация аккаунта на облаке
Для использования сервиса YSK у вас должна быть почта на Yandex. Если у вас её нет, то самое время завести.
Будьте готовы к тому, что вам потребуется еще подтвердить свой номер мобильного телефона. Без этого, увы, сервисы будут недоступны.
Почта есть. Теперь самое время перейти на cloud.yandex.ru. Перейдя в консоль надо активировать пробный период пользования сервисом. Для этого надо привязать платежную карту. Как только вы это сделаете вам будет доступен грант на 60 дней.
В облака – через командную строку
Для понимания, как работает распознавание и синтез, мы потренируемся в командной строке. Например, в iTerm.
Для отправки запросов на API через командную строку установим утилиту cURL. Перед установкой проверьте, возможно, она у вас уже есть ($ curl —version):
Теперь настроим Интерфейс Яндекс.Облака для командной строки (CLI). Запустим скрипт:
Перезапустите командную оболочку. В переменную окружения PATH добавится путь к исполняемому файлу – install.sh.
Теперь нам нужно, чтобы в CLI заработало автодополнение команд в bash:
Если у вас еще нет менеджера пакетов Homebrew, установите его. Он вам не раз пригодится, обещаю.
Затем ставим пакет bash-completion:
и посмотрим, что изменилось в файле ~/.bash_profile:
Примечание: ~/.bash_profile используется для пользовательских настроек, в частности – для определения переменных окружения.
Видим, что в конце bash_profile добавились новые строчки:
Выше новых строк вставьте эту:
Набираем команду:
и получаем приветственное сообщение:
Вам предложат выбрать облако (скорее всего у вас оно единственное):
Далее по желанию выберете Compute zone. Пока пользователь один – этим можно пренебречь.
Посмотрим, как выглядят настройки профиля CLI:
Мы в шаге от старта. Осталось добыть второй ключ (в настройках профиля он не будет отображаться):
Полетели!
Запуск и внедрение речевой аналитики
Чтобы внедрить речевую аналитику на базе Yandex SpeechKit, нужно подготовиться: выстроить логику разговора и маршрутизацию звонков, настроить интеграцию, подобрать правильные словари синонимов. Вы можете сделать это самостоятельно или пригласить наших партнёров, которые умеют решать такие задачи.
Что могут компании-партнёры?
- Построить логику целевого разговора, подобрать словари синонимов и подготовить основу для разметки текста.
- Автоматизировать процесс передачи аудиофайлов на распознавание и перевод в текст.
- Автоматизировать анализ текста и выделить показатели, важные для вашего бизнес-процесса. Обычно это: профили клиентов, источники информации о компании или предложении, факт следования скрипту, наличие или отсутствие кросс-продажи, соблюдение стандартов (приветствие, прощание, представление), эмоциональный фон речи и причины негатива, наличие дополнительных запросов и т. д.
- Настроить передачу данных об отклонениях во внутренние системы для выделения отклонений и оперативных мер, настроить отчетность.
Совет
У Яндекс.Облака более 50 компаний-партнёров, которые реализуют решения на базе Yandex SpeechKit. , и мы подберём лучшего исполнителя для вашей задачи и ответим на любые вопросы.
Использование сервиса
Создание клиентского приложения
Для распознавания речи приложение сначала должно отправить , а потом отправлять .
Параллельно с тем как отправляются аудиофрагменты, в ответ сервис будет возвращать , которые необходимо обрабатывать, например выводить их в консоль.
Чтобы приложение смогло обращаться к сервису, необходимо сгенерировать код интерфейса клиента для используемого языка программирования. Сгенерируйте этот код из файла stt_service.proto из репозитория Yandex.Cloud API.
Ниже представлены клиентских приложений. Помимо этого, в документации gRPC вы можете найти подробные инструкции по генерации интерфейсов и реализации клиентских приложений для различных языков программирования.
Авторизация в сервисе
В каждом запросе приложение должно передавать идентификатор каталога, на который у вас есть роль или выше. Подробнее в разделе Управление доступом.
Также приложение должно аутентифицироваться при каждом запросе, например при помощи IAM-токена. Подробнее об аутентификации в сервисе.
Результат распознавания
В каждом сервер возвращает один или несколько фрагментов речи, которые он успел распознать за этот промежуток (). Для каждого фрагмента речи указывается список вариантов распознанного текста ().
В процессе распознавания речь делится на фразы, а конец фразы помечается флагом . По умолчанию сервер возвращает ответ только после распознавания всей фразы. С помощью флага вы можете указать, чтобы сервер возвращал и промежуточные результаты распознавания. Получение промежуточных результатов позволит быстрее реагировать на распознаваемую речь, не дожидаясь окончания фразы.
Ограничения сессии распознавания речи
После получения сообщения с настройками распознавания сервис начнет сессию распознавания. Для каждой сессии действуют следующие ограничения:
-
Нельзя отправлять аудиофрагменты слишком часто или редко. Время между отправкой сообщений в сервис должно примерно совпадать с длительностью отправляемых аудиофрагментов, но не должно превышать 5 секунд.
Например, каждые 400 мс отправляйте на распознавание 400 мс аудио.
-
Максимальная длительность переданного аудио за всю сессию — 5 минут.
-
Максимальный размер переданных аудиоданных — 10 МБ.
Если в течение 5 секунд в сервис не отправлялись сообщения или достигнут лимит по длительности или размеру данных, сессия обрывается. Чтобы продолжить распознавание речи, надо заново установить соединение и отправить новое сообщение с настройками распознавания.
Примеры использования
Подключение
require_once 'vendor/autoload.php';
или
require_once 'yandex-speechkit-php-sdk/autoload.php';
Импорт
use Panda\Yandex\SpeechKitSDK\Cloud; use Panda\Yandex\SpeechKitSDK\Speech; use Panda\Yandex\SpeechKitSDK\Text; use Panda\Yandex\SpeechKitSDK\Lang; use Panda\Yandex\SpeechKitSDK\Ru; use Panda\Yandex\SpeechKitSDK\En; use Panda\Yandex\SpeechKitSDK\Tr; use Panda\Yandex\SpeechKitSDK\Emotion; use Panda\Yandex\SpeechKitSDK\Speed; use Panda\Yandex\SpeechKitSDK\Format; use Panda\Yandex\SpeechKitSDK\Rate; use Panda\Yandex\SpeechKitSDK\Topic; use Panda\Yandex\SpeechKitSDK\Filter; use Panda\Yandex\SpeechKitSDK\Exception\ClientException;
Создание сервиса и аутентификация
try {
// Обязательные параметры: "OAUTH-токен", "ID каталога"
$cloud = new Cloud('AgAAAAASeN6XAATuwduwAAZFyUEYsEW1gGjh56d', 'b1g89h70fg5jgg8e1j4d');
} catch (ClientException $e) {
echo $e->getMessage();
}
Синтез речи
Создание задачи
try {
// Обязательный параметр: "Текст"
$speech = new Speech('Привет, разработчик!');
} catch (ClientException $e) {
echo $e->getMessage();
}
Добавление параметров речи (необязательно)
// Уточнение параметра текста признаком "SSML-формата" (необязательно)
$speech->setSSML()
/*
* Добавление обязательного параметра: "Голос"
* Возможно использование других констант классов "Ru", "En", "Tr" в качестве параметра
*/
->setVoice(Ru::OKSANA);
try {
/*
* Добавление обязательного параметра, произвольно: "Голос"
* Возможно использование статического метода "random" в классах: "Ru", "En", "Tr"
*/
$speech->setVoice(Ru::random());
} catch (ClientException | ArgumentCountError $e) {
echo $e->getMessage();
/*
* Добавление обязательного параметра, произвольно: "Голос"
* Возможно использование статического метода "random" в классах: "Ru", "En", "Tr"
*/
$speech->setVoice(Ru::OKSANA);
}
/*
* Добавление обязательного параметра: "Язык"
* Возможно использование других констант класса "Lang" в качестве параметра
*/
$speech->setLang(Lang::RU)
/*
* Добавление обязательного параметра: "Эмоциональная окраска"
* Возможно использование других констант класса "Emotion" в качестве параметра
*/
->setEmotion(Emotion::GOOD)
/*
* Добавление обязательного параметра: "Темп"
* Возможно использование других констант класса "Speed" в качестве параметра
*/
->setSpeed(Speed::NORMAL)
/*
* Добавление обязательного параметра: "Формат аудио"
* Возможно использование других констант класса "Format" в качестве параметра
*/
->setFormat(Format::LPCM)
/*
* Добавление обязательного параметра: "Частота дискретизации"
* Возможно использование других констант класса "Rate" в качестве параметра
*/
->setRate(Rate::HIGH);
Выполнение задачи
try {
// Обязательный параметр: "Задача"
file_put_contents('greeting_developer.ogg', $cloud->request($speech));
} catch (ClientException $e) {
echo $e->getMessage();
}
Распознавание речи
Создание задачи
// Обязательный параметр: "Указатель на файл"
$text = new Text('greeting_developer.ogg');
Добавление параметров речи (необязательно)
/*
* Добавление обязательного параметра: "Язык"
* Возможно использование других констант класса "Lang" в качестве параметра
*/
$text->setLang(Lang::RU)
/*
* Добавление обязательного параметра: "Языковая модель"
* Возможно использование других констант класса "Topic" в качестве параметра
*/
->setTopic(Topic::GENERAL)
/*
* Добавление обязательного параметра: "Фильтр ненормативной лексики"
* Возможно использование других констант класса "Filter" в качестве параметра
*/
->setFilter(Filter::FALSE)
/*
* Добавление обязательного параметра: "Формат аудио"
* Возможно использование других констант класса "Format" в качестве параметра
*/
->setFormat(Format::LPCM)
/*
* Добавление обязательного параметра: "Частота дискретизации"
* Возможно использование других констант класса "Rate" в качестве параметра
*/
->setRate(Rate::HIGH);
Выполнение задачи
try {
// Обязательный параметр: "Задача"
print_r($cloud->request($text));
} catch (ClientException $e) {
echo $e->getMessage();
}
Получение команд от станции
Только для продвинутых пользователей
Для работы функционала должна быть настроена интеграция Home Assistant с умным домом Яндекса!
- Настройте список фраз, на которые ваши станции должны реагировать и ответы на них. Если не хотите ответ — просто поставьте точку как в примере. При первом запуске копонент создаёт служебный медиа-плеер .
- Синхронизируйте ваши устройства в мобильном приложении Яндекса, чтоб этот плеер появился и там. Не нужно его переименовывать и перемещать в комнаты.
- Перезапустите Home Assistant. В мобильном приложении Яндекса должны появиться ваши сценарии.
В ответ на эти фразы в Home Assistan будет генерироваться событие типа с произнесённым текстом. Теперь можете писать свои автоматизации на YAML или Node-RED.
yandex_station:
username: myuser
password: mypass
intents:
Покажи сообщение: ага
Какая температура в комнате: .
Какая влажность в комнате: .
automation:
- trigger:
platform: event
event_type: yandex_intent
event_data:
text: Покажи сообщение
action:
service: persistent_notification.create
data:
title: Сообщение со станции
message: Шеф, станция чего-то хочет
Installation
There are several ways to add SpeechKit to a project.
Installing with CocoaPods
$ gem install cocoapods
Podfile
To integrate SpeechKit into your project using CocoaPods, create a file in the project directory:
source 'https://github.com/CocoaPods/Specs.git' platform :ios, '8.0' target 'TargetName' do pod 'YandexSpeechKit', '~> 3.12.2' end
Then run the command:
$ pod install
Adding SpeechKit directly
You can add SpeechKit directly to a project as a static library, without using a dependency manager.
In the Xcode project settings, choose -> , then click -> and choose SpeechKit. Also add all the frameworks and libraries required by SpeechKit in the same section. For a complete list, see .
In -> , add the bundle with the resources, which is located in the directory.
In -> -> , set the path to the directory that contains SpeechKit.