Команда tr в linux
Содержание:
- Скорость сортировки в Python
- Other Options
- Повторить последнюю команду
- Примеры использования tree
- Примеры использования
- Опции uniq
- Остаточный правильный вариант алгоритма:
- Examples
- Using sort And join Together
- Comparing Only Selected Fields Of Data
- Сравнение строк по алфавиту на Bash
- Примеры использования uniq
- Основные параметры команды find
- COLOPHON top
- Handling Mixed-Case Data
- Примеры использования
- Своя сортирующая функция
- Ожидать завершения команды и выключить компьютер
Скорость сортировки в Python
Python
# speed/main.py
import random
from boxx import timeit
def list_sort(arr):
return arr.sort()
def sorted_builtin(arr):
return sorted(arr)
def main():
arr =
with timeit(name=»sorted(list)»):
sorted_builtin(arr)
with timeit(name=»list.sort()»):
list_sort(arr)
if __name__ == «__main__»:
main()
|
1 |
# speed/main.py importrandom fromboxx importtimeit deflist_sort(arr) returnarr.sort() defsorted_builtin(arr) returnsorted(arr) defmain() arr=random.randint(,50)forrinrange(1_000_000) withtimeit(name=»sorted(list)») sorted_builtin(arr) withtimeit(name=»list.sort()») list_sort(arr) if__name__==»__main__» main() |
Указанный выше код выводит следующий результат:
Shell
$ python main.py
«sorted(list)» spend time: 0.1104379
«list.sort()» spend time: 0.0956471
|
1 |
$python main.py «sorted(list)»spend time0.1104379 «list.sort()»spend time0.0956471 |
Как видите, метод немного быстрее, чем функция . Почему так получается? Разберем обе функции и посмотрим, сможет ли байтовый код дать ответ:
Python
>>> import dis
>>> dis.dis(list_sort)
12 0 LOAD_FAST 0 (arr)
2 LOAD_METHOD 0 (sort)
4 CALL_METHOD 0
6 RETURN_VALUE
>>> dis.dis(sorted_builtin)
16 0 LOAD_GLOBAL 0 (sorted)
2 LOAD_FAST 0 (arr)
4 CALL_FUNCTION 1
6 RETURN_VALUE
|
1 |
>>>importdis >>>dis.dis(list_sort) 12LOAD_FAST(arr) 2LOAD_METHOD(sort) 4CALL_METHOD 6RETURN_VALUE >>>dis.dis(sorted_builtin) 16LOAD_GLOBAL(sorted) 2LOAD_FAST(arr) 4CALL_FUNCTION1 6RETURN_VALUE |
Байтовый код обеих функций практически идентичен. Единственное различие в том, что функция сначала загружает список, и за методом (sort) следует вызванный метод списка без аргументов. Если сравнить, функция сначала загружает встроенную функцию , а за ней следует список и вызов загруженной функции со списком в качестве аргумента.
Почему же временные результаты отличаются?
Можно предположить, что в то время как может работать с известным размером и менять элементы внутри данного размера, должен работать c неизвестным размером. Следовательно, если при добавлении нового элемента не хватает памяти, нужно изменить размер нового списка, созданного через . На это требуется время! Если просмотреть исходный код CPython, можно найти следующий комментарий об изменении размера списка объектов:
Помните, что сейчас мы работаем со списком из 1 000 000 элементов — изменений размера будет довольно много! К несчастью, пока что это лучший ответ на вопрос, почему на 13% быстрее, чем .
Python
new_array = arr.copy()
arr.sort()
|
1 |
new_array=arr.copy() arr.sort() |
Имплементация приводит к разнице во времени выполнения, поскольку создание копии списка занимает некоторое время.
Other Options
| —batch-size=NMERGE | Merge at most NMERGE inputs at once; for more use temp files. |
| -c, —check, —check=diagnose-first | Check for sorted input; do not sort. |
| -C, —check=quiet, —check=silent | Like -c, but do not report first bad line. |
| —compress-program=PROG | Compress temporaries with PROG; decompress them with PROG -d. |
| —debug | Annotate the part of the line used to sort, and warn about questionable usage to stderr. |
| —files0-from=F | Read input from the files specified by NUL-terminated names in file F; If F is ‘-‘ then read names from standard input. |
| -k, —key=POS1[,POS2] | Start a key at POS1 (origin 1), end it at POS2 (default end of line). See POS syntax below. |
| -m, —merge | Merge already sorted files; do not sort. |
| -o, —output=FILE | Write result to FILE instead of standard output. |
| -s, —stable | Stabilize sort by disabling last-resort comparison. |
| -t, —field-separator=SEP | Use SEP instead of non-blank to blank transition. |
| -T, —temporary-directory=DIR | Use DIR for temporaries, not $TMPDIR or /tmp; multiple options specify multiple directories. |
| —parallel=N | Change the number of sorts run concurrently to N. |
| -u, —unique | With -c, check for strict ordering; without -c, output only the first of an equal run. |
| -z, —zero-terminated | End lines with 0 byte, not newline. |
| —help | Display a help message, and exit. |
| —version | Display version information, and exit. |
POS takes the form F[.C][OPTS], where F is the field number and C the character position in the field; both are origin 1. If neither -t nor -b is in effect, characters in a field are counted from the beginning of the preceding whitespace. OPTS is one or more single-letter ordering options, which override global ordering options for that key. If no key is given, use the entire line as the key.
SIZE may be followed by the following multiplicative suffixes:
| % | 1% of memory |
| b | 1 |
| K | 1024 (default) |
…and so on for M, G, T, P, E, Z, Y.
With no FILE, or when FILE is a dash («—«), sort reads from the standard input.
Also, note that the locale specified by the environment affects sort order; set LC_ALL=C to get the traditional sort order that uses native byte values.
Повторить последнюю команду
Если мы уже начали говорить о возможностях Bash пойдем дальше. Символ !! означает выполнить последнюю команду. Часто ли у вас случалось такое, что вы набираете команду нажимаете Enter и понимаете, что для ее работы нужно было использовать sudo? Тогда приходиться набирать ту же команду только уже правильно. Но можно пойти другим путем, выполнить:
Кроме символа !! В Bash есть еще несколько указателей на команды:
- !^ — первый аргумент предыдущей команды;
- !$ — последний аргумент предыдущей команды;
- !* — все аргументы предыдущей команды;
- !-2 — вторая с конца команда;
- *— содержимое текущего каталога.
А вот так можно сохранить последнюю выполненную команду в скрипт:
Примеры использования tree
Самый простой способ использовать команду tree Linux — напечатать в терминале всего лишь одно слово:
Результатом станет стандартное отображение структуры папок. Размер выдачи зависит от того, сколько хлама накопилось на жестком диске. У автора его столько, что листать — не перелистать:

Немного сократить объем информации можно, попросив команду показывать только папки. Для этого служит опция -d. А чтобы отпилить от дерева еще больше ненужных веток, установим ограничение на количество файлов, которые хранятся в папках (если файлов больше, папка не попадет в выдачу). В этом нам поможет опция —filelimit.
Кстати, нельзя устанавливать лимит меньше, чем 25 файлов.

По умолчанию команда tree в linux не показывает скрытые папки. Чтобы увидеть их, следует воспользоваться опцией -a. Заодно не помешает упорядочить выдачу — например, по уровням вложенности (параметр -v). Ну и почему бы не узнать, когда тот или иной файл был изменен последний раз — добавим к команде еще и -D.

Теперь поработаем с определенной группой файлов. Для примера отберем те, у которых формат pdf — сделать это позволяет опция -P. Она дает команде понять, что нужно выводить только документы, соответствующие маске. Чтобы задать маску для любого количества символов от 0 до бесконечности используется знак *, а чтобы обозначить только 1 символ — знак ?. Название файла или папки следует заключить в одинарные кавычки.
Опция —prune нужна для того, чтобы исключить из выдачи папки, внутри которых нет искомых документов (по умолчанию команда выводит даже те папки, которые не имеют отношения к поисковому запросу).
Вот что получаем в итоге:

Стандартно результат команды tree направляется в терминал. Но есть возможность напечатать его в файл и сохранить для дальнейшего использования. С этой целью создадим документ txt с названием tree_command_results и поместим его в корневой каталог. После этого выполним команду следующего вида:
Опция -d использована для сокращения количества информации и ее присутствие здесь не обязательно. Опция -o отвечает за перенаправление вывода в файл.
В терминале никакой результат не отображается:

Зато в указанном файле находим перечень папок, который занимает 45 страниц:

Для получения дополнительной информации о файлах дополним команду tree опциями -h (показывает размер), -u (указывает на аккаунт, с которого файл был создан), -p (так мы узнаем, что можно делать с каждым конкретным файлом — только просматривать или также изменять его содержимое). Также используем параметр -f, чтобы видеть полный путь к каждому документу.

Полезный лайфхак — если объединить опции -P и -f, можно быстро находить файлы, затерявшиеся в памяти компьютера:

Примеры использования
А теперь давайте рассмотрим примеры find, чтобы вы лучше поняли, как использовать эту утилиту.
2. Поиск файлов в определенной папке
Показать все файлы в указанной директории:
Искать файлы по имени в текущей папке:
Не учитывать регистр при поиске по имени:
5. Несколько критериев
Поиск командой find в Linux по нескольким критериям, с оператором исключения:
Найдет все файлы, начинающиеся на test, но без расширения php. А теперь рассмотрим оператор ИЛИ:
8. Поиск по разрешениям
Найти файлы с определенной маской прав, например, 0664:
Найти файлы с установленным флагом suid/guid:
Или так:
Поиск файлов только для чтения:
Найти только исполняемые файлы:
Найти все файлы, принадлежащие пользователю:
Поиск файлов в Linux принадлежащих группе:
10. Поиск по дате модификации
Поиск файлов по дате в Linux осуществляется с помощью параметра mtime. Найти все файлы модифицированные 50 дней назад:
Поиск файлов в Linux открытых N дней назад:
Найти все файлы, модифицированные между 50 и 100 дней назад:
Найти файлы измененные в течении часа:
Найти все файлы размером 50 мегабайт:
От пятидесяти до ста мегабайт:
Найти самые маленькие файлы:
Самые большие:
13. Действия с найденными файлами
Для выполнения произвольных команд для найденных файлов используется опция -exec. Например, выполнить ls для получения подробной информации о каждом файле:
Удалить все текстовые файлы в tmp
Удалить все файлы больше 100 мегабайт:
Опции uniq
У команды uniq есть такие основные опции:
- -u (—unique) — выводит исключительно те строки, у которых нет повторов.
- -d (—repeated) — если какая-либо строка повторяется несколько раз, она будет выведена лишь единожды.
- -D — выводит только повторяющиеся строки.
- —all-repeated — то же самое, что и -D, но при использовании этой опции между группами из одинаковых строк при выводе будет отображаться пустая строка. может иметь одно из трех значений — none (применяется по умолчанию), separate или prepend.
- —group — выводит весь текст, при этом разделяя группы строк пустой строкой. имеет значения separate (по умолчанию), prepend, append и both, среди которых нужно выбрать одно.
Вместе с основными опциями могут применяться дополнительные. Они нужны для более тонких настроек работы команды:
- -f (—skip-fields=N) — будет проведено сравнение полей, начиная с номера, который следует после указанного вместо буквы N. Поля — это слова, хотя, называть их словами в прямом смысле слова нельзя, ведь словом команда считает любую последовательность символов, отделенную от других последовательностей пробелом либо табуляцией.
- -i (—ignore-case) — при сравнении не будет иметь значение регистр, в котором напечатаны символы (строчные и заглавные буквы).
- -s (—skip-chars=N) — работает по аналогии с -f, однако, игнорирует определенное количество символов, а не строк.
- -c (—count) — в начале каждой строки выводит число, которое обозначает количество повторов.
- -z (—zero-terminated) — вместо символа новой строки при выводе будет использован разделитель строк NULL.
- -w (—check-chars=N) — указание на то, что нужно сравнивать только первые N символов в строках.
Остаточный правильный вариант алгоритма:
Сигнатура такая же как и в предыдущем варианте
Но следует заметить, что данный вариант предполагает первым параметром указатель, на котором можно вызвать операцию delete[] (почему — мы увидим далее). То-есть когда мы выделяли память, мы именно для этого указателя присваивали адрес начала массива.
Предварительная подготовка
В данном примере так называемый «коэффициент навёрстывания» (catch up coefficient) — это просто константа со значением 8. Она показывает сколько максимум элементов мы попытаемся пройти, чтобы вставить новый «недо-максимум» или «недо-минимум» на своё место.
Теперь, самое главное — правильная выборка элементов из исходного массива
Цикл начинается с localCatchUp (потому что предыдущие элементы уже попали в нашу выборку как значения от которых мы будем отталкиваться). И проходит до конца. Так что после в конце концов все элементы распределятся либо в массив выборки либо в один из массивов недо-выборки.
Для проверки, можем ли мы вставить элемент в выборку, мы просто будем проверять больше (или равен) ли он элементу на 8 позиций левее (right − localCatchUp). Если это так, то мы просто одним проходом по этим элементам вставляем его на нужную позицию. Это было для правой стороны, то-есть для максимальных элементов. Таким же образом делаем с обратной стороны для минимальных. Если не удалось вставить его ни в одну сторону выборки значит кидаем его в один из rest-массивов.
Цикл будет выглядеть примерно так:
Опять же, что здесь происходит? Сначала пытаемся пихнуть элемент в максимумы. Не получается? — Если возможно, кидаем его в минимумы. При невозможности и это сделать — кладём его в restFirst или restSecond.
Самое сложное уже позади. Теперь после цикла у нас есть отсортированный массив с выборкой (элементы начинаются с индекса и оканчиваются в ), а также массивы restFirst и restSecond длиной restFirstLen и restSecondLen соответственно.
Теперь запускаем нашу функцию сортировки рекурсивно для массивов restFirst и restSecond
Для понимания того как оно всё отработает, сначала нужно посмотреть код до конца. Пока что нужно просто поверить что после рекурсивных вызовов массивы restFirst и restSecond будут отсортированными.
И, наконец, нам нужно слить 3 массива в результирующий и назначить его указателю arr.
Можно было бы сначала слить restFirst + restSecond в какой-нибудь массив restFull, а потом уже производить слияние selection + restFull. Но данный алгоритм обладает таким свойством, что скорее всего массив selection будет содержать намного меньше элементов, чем любой из rest-массивов. Припустим в selection содержится 100 элементов, в restFirst — 990, а в restSecond — 1010. Тогда для создания restFull массива нужно произвести 990 + 1010 = 2000 операций копирования. После чего для слияния с selection — ещё 2000 + 100 копирований. Итого при таком подходе всего копирований будет 2000 + 2100 = 4100.
Давайте применим здесь оптимизацию. Сначала сливаем selection и restFirst в массив selection. Операций копирования: 100 + 990 = 1090. Далее сливаем массивы selection и restSecond на что потратим ещё 1090 + 1010 = 2100 копирований. Суммарно выйдет 2100 + 1090 = 3190, что почти на четверть меньше, нежели при предыдущем подходе.
Выводы
Как видим, алгоритм работает, и работает хорошо. По крайней мере всё чего мы хотели, было достигнуто. На счёт стабильности, не уверен, не проверял. Можете сами проверить. Но по-идее она должна достигаться очень легко. Просто в некоторых местах вместо знака > поставить ≥ или что-то того.
Examples
Let’s say you have a file, data.txt, which contains the following ASCII text:
apples oranges pears kiwis bananas
To sort the lines in this file alphabetically, use the following command:
sort data.txt
…which will produce the following output:
apples bananas kiwis oranges pears
Note that this command does not actually change the input file, data.txt. If you want to write the output to a new file, output.txt, redirect the output like this:
sort data.txt > output.txt
…which will not display any output, but will create the file output.txt with the same sorted data from the previous command. To check the output, use the cat command:
cat output.txt
…which displays the sorted data:
apples bananas kiwis oranges pears
You can also use the built-in sort option -o, which allows you to specify an output file:
sort -o output.txt data.txt
Using the -o option is functionally the same as redirecting the output to a file; neither one has an advantage over the other.
Using sort And join Together
sort can be especially useful when used in conjunction with the join command. Normally join will join the lines of any two files whose first field match. Let’s say you have two files, file1.txt and file2.txt. file1.txt contains the following text:
3 tomato 1 onion 4 beet 2 pepper
…and file2.txt contains the following:
4 orange 3 apple 1 mango 2 grapefruit
If you’d like sort these two files and join them, you can do so all in one command if you’re using the bash command shell, like this:
join <(sort file1.txt) <(sort file2.txt)
Here, the sort commands in parentheses are each executed, and their output is redirected to join, which takes their output as standard input for its first and second arguments; it is joining the sorted contents of both files and gives results similar to the below results.
1 onion mango 2 pepper grapefruit 3 tomato apple 4 beet orange
Comparing Only Selected Fields Of Data
Normally, sort decides how to sort lines based on the entire line: it compares every character from the first character in a line, to the last one.
If, on the other hand, you want sort to compare a limited subset of your data, you can specify which fields to compare using the -k option.
For instance, if you have an input file data.txt With the following data:
01 Joe 02 Marie 03 Albert 04 Dave
…and you sort it without any options, like this:
sort data.txt
…you will receive the following output:
01 Joe 02 Marie 03 Albert 04 Dave
…as you can see, nothing was changed from the original data ordering, because of the numbers at the beginning of the line — which were already sorted. However, if you want to sort based on the names, you can use the following command:
sort -k 2,2 data.txt
This command will sort the second field, and ignore the first. (The «k» in «-k» stands for «key» — we are defining the «sorting key» used in the comparison.)
Fields are defined as anything separated by whitespace; in this case, an actual space character. Our command above will produce the following output:
03 Albert 04 Dave 01 Joe 02 Marie
…which is sorted by the second field, listing the lines alphabetically by name, and ignoring the numbers in the sorting process.
You can also specify a more complex -k option. The complete positional argument looks like this:
-k POS1,POS2
…where POS1 is the starting field position, and POS2 is the ending field position. Each field position, in turn, is defined as:
F.C
…where F is the field number and C is the character within that field to begin the sort comparison.
So, let’s say our input file data.txt contains the following data:
01 Joe Sr.Designer 02 Marie Jr.Developer 03 Albert Jr.Designer 04 Dave Sr.Developer
…we can sort by seniority if we specify the third field as the sort key:
sort -k 3 data.txt
…this produces the following output:
03 Albert Jr.Designer 02 Marie Jr.Developer 01 Joe Sr.Designer 04 Dave Sr.Developer
Or, we can ignore the first three characters of the third field, and sort solely based on title, ignoring seniority:
sort -k 3.3 data.txt
01 Joe Sr.Designer 03 Albert Jr.Designer 02 Marie Jr.Developer 04 Dave Sr.Developer
We can also specify where in the line to stop comparing. If we sort based on only the third-through-fifth characters of the third field of each line, like this:
sort -k 3.3,3.5 data.txt
…sort will see only the same thing on every line: «.De» … and nothing else. As a result, sort will not see any differences in the lines, and the sorted output will be the same as the original file:
01 Joe Sr.Designer 02 Marie Jr.Developer 03 Albert Jr.Designer 04 Dave Sr.Developer
Сравнение строк по алфавиту на Bash
Задача усложняется при попытке определить, является ли строка предшественницей другой строки в последовательности сортировки по возрастанию. Люди, пишущие сценарии на языке командного интерпретатора bash, нередко сталкиваются с двумя проблемами, касающимися операций «больше» и «меньше» относительно сравнения строк Linux, у которых достаточно простые решения:
Во-первых, символы «больше» и «меньше» нужно экранировать, добавив перед ними обратный слэш (\), потому что в противном случае в командном интерпретаторе они будут расцениваться как символы перенаправления, а строки — как имена файлов. Это один из тех случаев, когда отследить ошибку достаточно сложно.
Пример:
Что получится, если сравнить строки bash:

Как видно, один лишь символ «больше» в своём непосредственном виде привёл к неправильным результатам, хотя и не было сформировано никаких ошибок. В данном случае этот символ привёл к перенаправлению потока вывода, поэтому никаких синтаксических ошибок не было обнаружено и, как результат, был создан файл с именем hockey:

Для устранения этой ошибки нужно экранировать символ «>», чтобы условие выглядело следующим образом:
Тогда результат работы программы будет правильным:

Во-вторых, упорядочиваемые с помощью операторов «больше» и «меньше» строки располагаются иначе, чем это происходит с командой sort. Здесь проблемы сложнее поддаются распознаванию, и с ними вообще можно не столкнуться, если при сравнении не будет учитываться регистр букв. В команде sort и test сравнение происходит по разному:
Результат работы кода:

В команде test строки с прописными буквами вначале будут предшествовать строкам со строчными буквами. Но если эти же данные записать в файл, к которому потом применить команду sort, то строки со строчными буквами будут идти раньше:

Разница их работы заключается в том, что в test для определения порядка сортировки за основу взято расположение символов по таблице ASCII. В sort же используется порядок сортировки, указанный для параметров языка региональных установок.
Примеры использования uniq
Прежде всего следует отметить главную особенность команды uniq — она сравнивает только строки, которые находятся рядом. То есть, если две строки, состоящие из одинакового набора символов, идут подряд, то они будут обнаружены, а если между ними расположена строка с отличающимся набором символов — то не будут поэтому перед сравнением желательно отсортировать строки с помощью sort. Без задействования файлов uniq работает так:

После команды uniq можно использовать её опции. Вот пример вывода, где не просто удалены повторы, но и указано количество одинаковых строк:

Теперь применим команду к тексту, который находится в файле.

Как можно заметить, глядя на снимок экрана, команда вывела в качестве повторяющихся только вторую и третью группу строк.

Причина этого — незаметный глазу символ пробела, который стоит в конце одной из строк первой группы. Нужно быть предельно внимательным при использовании uniq, чтобы получить качественный результат.
Используемая опция —all-repeated=prepend выполнила свою работу — добавила пустые строки в начало, в конец и между группами строк. Теперь попробуем сравнить только первые 5 символов в каждой строке.

Как видно на скриншоте, повторяющиеся строки, которые начинались словом «облака», были удалены. Осталась только первая из них. Вывод только уникальных строк с использованием опции -u выглядит так:

Чтобы проигнорировать определенное количество символов в начале одинаковых строк, воспользуемся опцией —skip-chars. В данном случае команда пропустит слово «облака», сравнив слова «перистые» и «белые».

А вот наглядная демонстрация отличий при использовании опции —group с разными значениями. both добавило пустые строки как перед текстом, так и после него, а также между группами строк.

Тогда как append не добавило пустую строку перед текстом:

Основные параметры команды find
Я не буду перечислять здесь все параметры, рассмотрим только самые полезные.
-P никогда не открывать символические ссылки
-L — получает информацию о файлах по символическим ссылкам
Важно для дальнейшей обработки, чтобы обрабатывалась не ссылка, а сам файл.
-maxdepth — максимальная глубина поиска по подкаталогам, для поиска только в текущем каталоге установите 1.
-depth — искать сначала в текущем каталоге, а потом в подкаталогах
-mount искать файлы только в этой файловой системе.
-version — показать версию утилиты find
-print — выводить полные имена файлов
-type f — искать только файлы
-type d — поиск папки в Linux
COLOPHON top
This page is part of the coreutils (basic file, shell and text
manipulation utilities) project. Information about the project can
be found at ⟨http://www.gnu.org/software/coreutils/⟩. If you have a
bug report for this manual page, see
⟨http://www.gnu.org/software/coreutils/⟩. This page was obtained
from the tarball coreutils-8.32.tar.xz fetched from
⟨http://ftp.gnu.org/gnu/coreutils/⟩ on 2020-08-13. If you discover
any rendering problems in this HTML version of the page, or you
believe there is a better or more up-to-date source for the page, or
you have corrections or improvements to the information in this
COLOPHON (which is not part of the original manual page), send a mail
to man-pages@man7.org
GNU coreutils 8.32 March 2020 SORT(1)
Pages that refer to this page:
column(1),
egrep(1),
fgrep(1),
grep(1),
look(1),
procps(1),
ps(1),
uniq(1),
qsort(3),
qsort_r(3),
environ(7)
Handling Mixed-Case Data
But what about situations where you have a mixture of upper- and lower-case letters at the beginning of your lines? In cases like this, the behavior of sort can seem confusing, but really it just needs some more information from you to sort the data the way you want. Let’s take a closer look.
Let’s say our input file data.txt contains the following data:
a b A B b c D d C
sorting this data without any options, like this:
sort data.txt
…will produce the following output:
a A b b B c C d D
As you can see, it’s sorted alphabetically, with lowercase letters always appearing before uppercase letters. This sort is «case-insensitive», and this is the default for GNU sort, which is the version of sort used in GNU/Linux.
At this point you might be asking yourself, well, if case-insensitive sorting is the default, then what is the «-f/—ignore-case» option for? The answer has to do with localization settings and bytewise sorting.
In brief, «localization» refers to what language the operating system uses, which at the most basic level defines what characters it uses. Each letter in the system is represented in a certain order. Changing the locale settings will affect what characters the operating system is using, and — most relevant to sorting — what order they are encoded in. For an example, refer to the United States English ASCII encoding table. As you can see from the table, a capital A («A«) is character number 65, and lowercase a («a«) is character number 97. So you might expect sort to arrange its output so that capital letters come before lowercase letters.
Defining operating system locale is a subject which goes beyond the scope of this document, but for now, it will suffice to say that to achieve bytewise sorting, we need to set the environment variable LC_ALL to C.
Under the default Linux shell, bash, we can accomplish this with the following command:
export LC_ALL=C
This sets the environment variable LC_ALL to the value C, which will enforce bytewise sorting. Now if we run the command:
sort data.txt
…we will see the following output:
A B C D a b b c d
…and now, the -f/—ignore-case option has the following effect:
A a B b b C c D d
…performing a «case-insensitive bytewise» sort.
Note
if you are using the join command in conjunction with sort, be aware that there is a known incompatibility between the two programs — unless you define the locale. If you are using join and sort to process the same input, it is highly recommended that you set LC_ALL to C, which will standardize the localization used by all programs.
Примеры использования
1. Простое использование команды tee
Команда ls -la нужна в Linux для показа списка файлов с описанием в текущем каталоге. Здесь команда tee используется для сохранения вывода ls -la в файл вывод.txt Введите следующие команды в терминале, чтобы проверить как работает команда tee.
Здесь первая команда показала вывод списка файлов в текущем каталоге в терминал и записала полученные данные в файл вывод.txt

Вторая команда показала содержимое файла вывод.txt

2. Добавление вывода в существующий файл
Если вывод любой команды записать в существующий файл с применением команды tee и операции -a, содержимое файла не будет перезаписано. Здесь вывод команды pwd будет добавлен в конец файла вывод.txt Запустите следующие команды с помощью терминала:
Здесь первая команда отображает вывод pwd в терминал и записывает вывод в конец файла вывод.txt Вторая команда используется для выделения вывода файла. Показано, что файл вывод.txt содержит оба результата: из предыдущего примера и из этого.

3. Запись вывода в несколько файлов
Команда tee может использоваться для вывода любой команды сразу в несколько файлов. Для этого необходимо указать имена файлов, разделив их пробелом. Используйте следующие команды для сохранения вывода date в два файла: вывод1.txt и вывод2.txt
Здесь первая команда выводит текущее системное время и сохраняет полученные результаты в два файла вывод1.txt и вывод2.txt Вторая команда показывает идентичное содержимое обоих файлов.

4. Игнорируем прерывание сигнала
Команда tee linux с опцией -i используется в этом примере, чтобы игнорировать любые прерывания во время ее выполнения. Таким образом, команда будет выполнена правильно, даже если пользователь нажимает CTRL+C. Выполните следующие команды в терминале.
Здесь первая команда считает количество строчек в файле вывод.txt и сохраняет полученный результат в файл вывод3.txt Вторая команда показывает содержимое файла вывод.txt, который содержит 37 строчек. Третья команда показывает содержимое файла вывод3.txt, в котором указано, что он действительно содержит 37 строчек.

5. Перенос вывода команды tee в другую команду
Вывод команды tee может быть перенесен в другую команду. В этом примере вывод из первой команды переносится в tee, а ее вывод — в другую команду. Запустите следующие команды в терминале:
Здесь первая команда используется для записи вывода ls в файл вывод4.txt и подсчета общего числа строк, слов и символов в файле вывод4.txt Вторая команда используется для отображения вывода команды ls, а третья — для отображения содержимого файла вывод4.txt

6. Команда tee и скрипты
Команда tee также может использоваться для записи вывода bash-скрипта в файл. Создайте bash-файл с приведенным кодом, который возьмет два входных числа из аргументов командной строки и выведет сумму этих чисел. Команда tee используется в этом примере для записи вывода add.sh в файл результат.txt
Запустите следующую команду в терминале для записи файла и отображения его содержимого.
Здесь числа 40 и 80 переносятся в качестве аргументов командной строки в скрипт add.sh и вывод записывается в файл результат.txt Команда cat выводит соответствующий результат.

7. Как скрыть вывод команды в терминале
Если вы хотите записать вывод прямо в файл и не показывать его в терминале, используйте /dev/null с командой tee. Для этого выполните следующие команды.
Здесь первая команда используется для записи вывода команды df в файл вывод5.txt, при этом вывод не показывается в терминале. Вторая команда показывает полученный результат.

Своя сортирующая функция
Язык Python позволяет
создавать свои сортирующие функции для более точной настройки алгоритма
сортировки. Давайте для начала рассмотрим такой пример. Пусть у нас имеется вот
такой список:
a=1,4,3,6,5,2
и мы хотим,
чтобы вначале стояли четные элементы, а в конце – нечетные. Для этого создадим
такую вспомогательную функцию:
def funcSort(x): return x%2
И укажем ее при
сортировке:
print( sorted(a, key=funcSort) )
Мы здесь
используем именованный параметр key, который принимает ссылку на
сортирующую функцию. Запускаем программу и видим следующий результат:
Разберемся,
почему так произошло. Смотрите, функция funcSort возвращает вот
такие значения для каждого элемента списка a:
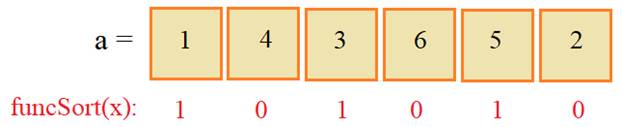
И, далее, в sorted уже
используются именно эти значения для сортировки элементов по возрастанию. То
есть, сначала, по порядку берется элемент со значением 4, затем, 6 и потом 2.
После этого следуют нечетные значения в порядке их следования: 1, 3, 5. В
результате мы получаем список:
А теперь,
давайте модифицируем нашу функцию, чтобы выполнялась сортировка и самих
значений:
def funcSort(x): if x%2 == : return x else: return x+100
Здесь четные
значения возвращаются такими как они есть, а к нечетным прибавляем 100. В
результате получим:

Здесь элементам
нашего списка ставятся в соответствие указанные числа, и по этим числам
выполняется их сортировка. То есть, эти числа можно воспринимать как некие
ключи, по которым и происходит сортировка элементов списка. Поэтому в Python
такую
сортировку называют сортировкой по ключам.
Конечно, здесь
вместо определения своей функции можно также записывать анонимные функции,
например:
print( sorted(a, key=lambda x: x%2) )
Получим ранее
рассмотренный результат:
Или, то же самое
можно делать и со строками:
lst = "Москва", "Тверь", "Смоленск", "Псков", "Рязань"
Отсортируем их
по длине строки:
print( sorted(lst, key=len) )
получим
результат:
Или по
последнему символу, используя лексикографический порядок:
print( sorted(lst, key=lambda x: x-1) )
Или, по первому
символу:
print( sorted(lst, key=lambda x: x) )
И так далее. Этот
подход часто используют при сортировке сложных структур данных. Допустим, у нас
имеется вот такой список из книг:
books = {
("Евгений Онегин", "Пушкин А.С.", 200),
("Муму", "Тургенев И.С.", 250),
("Мастер и Маргарита", "Булгаков М.А.", 500),
("Мертвые души", "Гоголь Н.В.", 190)
}
И нам нужно его
отсортировать по возрастанию цены (последнее значение). Это можно сделать так:
print( sorted(books, key=lambda x: x2) )
На выходе
получим список:
Вот так можно
выполнять сортировку данных в Python.
Ожидать завершения команды и выключить компьютер
Это скорее не команда, а небольшая стандартная функция оболочки Bash, о которой не все знают. Иногда нам нужно оставить на выполнение какую-нибудь долго работающую утилиту, например, обновление системы, а самим куда-то отойти. И при этом мы хотим чтобы после завершения работы утилиты компьютер автоматически выключился. Можно просто объединить команды с помощью стандартного синтаксиса Bash. Для объединения используются символы && и ||. Первый — выполнить другую команду если первая завершилась успешно, второй если первая завершилась ошибкой.
Например, обновить систему и если все хорошо выключить PC:
Или выключить компьютер если обновление не удалось:
Или выключить независимо от того произошла ошибка или нет:
Здесь приведена команда обновления Ubuntu, но в других дистрибутивах нужно заменить эту команду на свою.