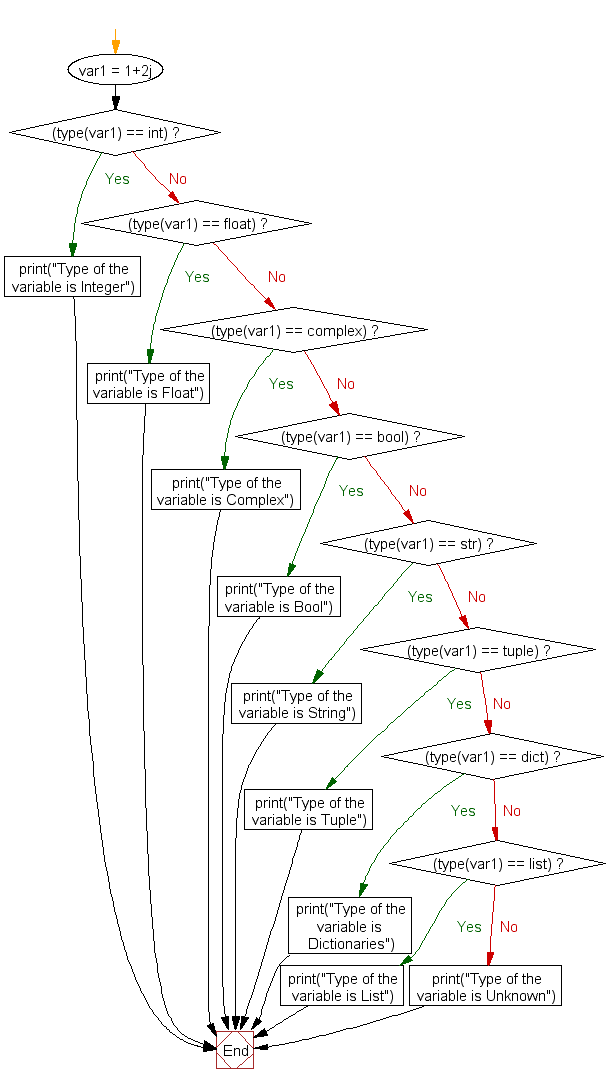
5 мин для чтенияинтерпретатор python
Содержание:
- Каково было программировать
- Как это выглядело
- Таймеры
- Почему вам тоже нужно сделать это
- Альтернативы СPython
- Грамматика языка
- Выбор транслятора
- В каких языках используются интерпретаторы?
- Регистры и арифметика
- Управления исполнением (Прим. перевод «flow control»)
- Регистры и память
- Все остальное
- Конец
- Что такое компилятор?
- История
- Типы интерпретаторов
- Примечания
- Что такое компиляторы и интерпретаторы?
- Преимущества
- Интерпретатор
- Типы интерпретаторов
- Еще идеи
Каково было программировать
Вначале, я писал все программы для SVM на чистом машинном коде, в шестнадцатиричном редакторе. Это быстро надоело, так что я написал ассемблер с поддержкой меток и строковых литералов. Например, «Hello, World» выглядел так:
Когда ассемблер видит строковый литерал, он пушит каждый байт в стек. — это не инструкция, это просто макрос, который генерирует цикл. Цикл печатает каждый символ из стека пока не дойдет до 0.
Писать и читать код для стековой машины — странный опыт. Вот чуть более продвинутый пример, так выглядел подсчет наибольшего общего делителя:
Тут продемонстрировано использование меток и условных переходов.
Если хотите увидеть еще более продвинутый пример, то почитайте ассемблерный код для сортировки вставками, но я не обижусь, если вы решите пропустить его. Это довольно длинный листинг, поэтому я не включил его в пост.
Если интересно, то можете также взглянуть на код виртуальной машины и ассемблера, которые я нашел в старых файлах. Там ничего необычного, и вообще, это скорее пример того, как НЕ НУЖНО писать интерпретатор байт-кода. Чтобы заставить стековые машины работать также хорошо, как регистровые машины, требуется реализовать несколько трюков. Конечно, я ничего не знал о них, и мой подход был наивным, что негативно сказалось на производительности.
Как это выглядело
Stupid Virtual Machine (или SVM для краткости) следовала самой простой возможной идее. Размер слова (word) был 32 бита, и доступ к памяти осуществлялся по словам (нельзя было обращаться к отдельным байтам). Области памяти для программного кода и для данных были полностью изолированы друг от друга (позже я узнал, что это является отличительной чертой Гарвардской архитектуры). Даже стек находился в своей отдельной части памяти.
Набор инструкций был тоже достаточно простым. Стандартные арифметические и логические инструкции, работа с памятью, манипуляции со стеком и переходы (jump). Все работало самым очевидным образом. Например, инструкция брала 2 первых 32-битных значения из стека, складывала их в виде целых чисел со знаком и пушила результат в стек.
Ввод/вывод был примитивным, привязанным к stdin/stdout. Были инструкции и . Первая пушила результат чтения в стек, вторая выводила на экран первое значение из стека. Для удобства я добавил специальный флаг: нужно ли считать ввод потоком сырых байтов или строковым представлением целого числа со знаком.
Таймеры
В CHIP-8 есть два таймера. Один таймер отсчитывает задержку (прим. перевод Delay Timer), другой «Звуковой таймер» (прим. перевод Sound Timer) воспроизводит звук пока значение таймера больше нуля. Оба таймера уменьшают собственные значения с частотой 60Hz (60 раз в секунду). Из таймера задержек можно читать, а из «Звукового таймера» нельзя.
FX15 — Установить значение таймера задержек в значения регистра X.
FX07 — Установить значение регистра X в значение таймера задержек.
Здесь все понятно 🙂
FX18 — Установить значение звукового таймера в значения регистра X.
NOTE: Стоит помнить, что в COSMAC VIP указанно, что значение 1 не даст никакого эффекта.
Почему вам тоже нужно сделать это
Написание даже примитивного интерпретатора байт-кода и нескольких программ для него заставит вас задуматься о таких вещах под капотом, которые обычно принимаются как само собой разумеющееся.
Например, когда я задумался о реализации процедур в SVM, я понял, что вызов функции это ничто иное как переход с дополнительным набором правил, с которыми неявно должны согласится и вызывающий, и вызываемый. Это помогло мне понять концепцию соглашения о вызове, а волшебные штуки вроде и вдруг стали иметь смысл.
Конечно, такой проект не научит вас всем хитрым нюансам С++ или С, но поможет сформировать правильный образ мышления. В те годы я у меня был определенный ментальный барьер, из-за которого я не решался заглянуть внутрь черных ящиков, полных волшебства
Очень важно сломать этот барьер если вы собираетесь заниматься программированием серьезно, и особенно если вас интересует ~низкоуровневое программирование на языках вроде С++ или С. Такой управляемый контакт с «симулированным низкоуровневым» программированием научило меня не бояться segfault’ов и без страха работать с дизассемблером
Это очень помогло мне в карьере, и я считаю этот проект одним из самых важных в своей жизни.
Альтернативы СPython
CPython является стандартной реализацией, но существуют и другие реализации, созданные для специфических целей и задач.
Jython
Основная цель данный реализации – тесная интеграция с языком Java. Работает следующим образом:
- Java-классы выполняют компиляцию программного кода на языке Python в байт-код Java
- Полученный байт-код запускается на виртуальной машине Java (JVM)
Jython позволить Python-программам управлять Java-приложениями. Во время выполнения такая программа ведет себя точно так же, как настоящая программа на языке Java.
IronPython
Предназначена для обеспечения интеграции Python-программ с C# приложениями на Microsoft .NET Framework или Mono. Принцип работы такой же, как и у Jython.
PyPy
PyPy — это интерпретатор Python, написанный на Python (если быть точнее, то на RPython).
Особенностью PyPy является использование трассирующего JIT-компилятора (just-in-time), который на лету транслирует некоторые элементы в машинный код. Благодаря этому, при выполнении некоторых операций PyPy обгоняет CPython в несколько раз. Но плата за такую производительность – более высокое потребление памяти.
Грамматика языка
Любая конструкция, кроме запроса статистики (это у нас как бы служебная команда) и создания функции начинается и заканчивается ключевыми словами. Благодаря этому мы можем смело расставлять как угодно переносы строк и отступы. Кроме этого (мы же работаем с русским языком) я специально создал по паре инструкций для случаев, когда надо передавать и переменную, и значение. Позже увидите, зачем это было нужно. Итак, наш файл yobaParser.mly:
%{
open YobaType
%}
%token <string> ID
%token <int> INT
%token RULEZ
%token GIVE TAKE
%token WASSUP DAMN
%token CONTAINS THEN ELSE
%token FUCKOFF
%token STATS
%token MEMORIZE IS
%token CALL
%start main
%type <YobaType.action> main
%%
main:
expr { $1 }
expr:
fullcommand { $1 }
| MEMORIZE ID IS fullcommandlist DAMN { AddFunction($2, $4) }
fullcommandlist:
fullcommand { $1 :: [] }
| fullcommand fullcommandlist { $1 :: $2 }
fullcommand:
WASSUP command DAMN { $2 }
| STATS { Stats }
command:
FUCKOFF { DoNothing }
| GIVE ID INT { Increment($3, $2) }
| GIVE INT ID { Increment($2, $3) }
| TAKE ID INT { Decrement($3, $2) }
| TAKE INT ID { Decrement($2, $3) }
| RULEZ ID { Create($2) }
| CALL ID { CallFunction($2) }
| CONTAINS ID INT THEN command ELSE command { Conditional($3, $2, $5, $7) }
| CONTAINS INT ID THEN command ELSE command { Conditional($2, $3, $5, $7) }
%%
Первым делом мы вставляем заголовок — открытие модуля YobaType, который содержит наш тип action, описанный в самом начале. Для чисел и строк, не являющихся ключевыми словами языка (переменных) мы объявляем два специальных типа, которым указываем, что именно они в себе содержат. Для каждого из ключевых слов с помощью директивы %token мы создаём тоже свой тип, который будет идентифицировать это слово в грамматике. Можно было бы указать их все хоть в одну строчку, просто такая запись группирует всё по видам инструкций. Имейте в виду, что все созданные нами токены — это именно подстановочные типы, по которым парсер грамматики определяет, что ему делать. Обозвать их можно как угодно, то, как они будут выглядеть в самом языке, мы опишем позже. Указываем, что входной точкой для грамматики является main, и что возвращать он всегда должен объект типа action — инструкцию для интерпретатора. Наконец, после двух знаков %% мы описываем саму грамматику:
- Инструкция состоит либо из команды (fullcommand), либо из создания функции.
- Функция, в свою очередь, состоит из списка команд (fullcommandlist).
- Команда бывает либо служебной (STATS), либо обычной (command), в таком случае она должна быть обёрнута в ключевые слова.
- С обычной командой всё просто, даже расписывать не буду.
В фигурных скобках мы указываем, что делать при совпадении строки с данным вариантом, при этом $N обозначает N-ный член конструкции. Например, если мы встречаем «CALL ID» (ID — это строка, не забываем), то мы создаём инструкцию CallFunction, которой в качестве параметра передаём $2 (как раз ID) — имя вызываемой функции.
Выбор транслятора
Выбор транслятора для работы с той или иной программой, прежде всего, определяется рекомендациями разработчиков этой программы, затем, целями и личными предпочтениями программиста.
Если Вы хотите разобраться в этой теме глубже, рекомендуем прочесть:
Альфред В. Ахо, Моника С. Лам, Рави Сети, Джеффри Д. Ульман. Компиляторы: принципы, технологии и инструментарий
Это учебник по теории написания компиляторов, в котором подробно описаны принципы работы разноуровневых компиляторов (начиная от простейших однопроходных, заканчивая современным компилятором на языке Java), уделяется повышенное внимание лексическому, синтаксическому и семантическому разбору программ в исходном коде, генерации машинного кода. В.А.Серебряков, М.П.Галочкин
Основы конструирования компиляторов
В.А.Серебряков, М.П.Галочкин. Основы конструирования компиляторов
Ещё один учебник по созданию компиляторов, только теперь отечественный. Глубоко раскрыты темы лексического и семантического анализа, рассмотрены темы автоматизации процесса разработки компиляторов, получения оптимального кода.
В каких языках используются интерпретаторы?
В современном мире программирования чаще всего используют только самые популярные языки программирования, ведь именно они развиваются наиболее быстро, что позволяет воплотить весь потенциал программистов. Примером таких языков могут стать Java и С\С++. Веб-языки не стоит относить сюда, потому что реализации их кода не требуются дополнительные приспособления, кроме рабочей станции и приложения, способного запустить код. Многие программисты считают лучшим интерпретатором Windows именно MVS, поскольку он разработан исключительно только для работы с операционной системной Windows.
Регистры и арифметика
6XNN — Загрузить в регистр константу.
Самая простая инструкция для регистров это (шестнадцатеричная запись). Где X это регистр, а NN это константа загружаемая в регистр. Например 6ABB — Загрузить в регистр под номером 10 (V, регистров 16 от нуля до пятнадцати) значение (187).
Псевдокод:
7XNN — Добавить константу к регистру (ADDI)
Добавляет константу NN к регистру под номером X и сохраняет в регистре под номером X. Не меняет регистр переполнения.
8XY0 — Сохранить регистр в другой регистр (MOV)
Еще одна инструкция работающая с регистрами. Имеет запись . Где X это номер регистра куда будет скопирован регистр под номером Y.
Псевдокод:
8XY4 — Сложить два регистра (ADD)
Добавляет значение регистра под номером Y к регистру X и сохраняет значение в регистр X. Если переполнение произошло регистр переполнения будет установлено в значение 1. Если переполнения не произошло регистр переполнения будет сброшен в значение 0.
Не совершайте моих ошибок: Регистр переполнения будет модифицирован в любом случае.
Упущение в спецификации: Что будет если регистр X будет регистром переполнения?
8XY5 — Вычесть из регистра (SUB)
Вычитает из регистра под номером X значение регистра Y и если произошло заимствование (прим. перевод Borrow) установить регистр переполнения в 1. И установить регистр переполнения в 0 если заимствование не произошло.
8XY7 — «Обратное» вычитание (SUB)
Установить регистр под номером X в результат вычитания значения регистра X из регистра Y. И если произошло заимствование установить регистр переполнения в 1. И установить регистр переполнения в 0 если заимствование не произошло.
8XY2, 8XY1 и 8XY3 — Логические операции (AND, OR, XOR)
Установить регистр X в результат операции
8XY2 — Логической «И»,
8XY1 — Логической «ИЛИ»,
8XY3 — Исключающее «ИЛИ»
двух операндов: регистра X и регистра Y. Не модифицирует регистр переполнения.
Не совершайте моих ошибок: Эти операции НЕ МОДИФИЦИРУЮТ регистр переполнения.
NOTE: Здесь нет опечатки. 8XY2 — AND. 8XY1 OR. 8XY3 XOR.
8XY6 — Сдвиг Вправо (Shift Right)
Сохранить в регистр X результат сдвига регистра Y вправо.
Установить регистр переполнения в значение младшего бита регистра Y.
Не совершайте моих ошибок: Результат сдвига регистра Y сохраняется в регистр X, а не в регистр Y. Хотя многие интерпретаторы это правило игнорируют.
8XYE — Сдвиг Влево (Shift Right)
Сохранить старший бит регистра Y в регистр переполнения.
Сохранить результат сдвига регистра Y в регистр X.
CXNN — Рандом Случайное число
Установить значение регистра X в результат логической «И» константы NN и рандомного случайного числа.
Управления исполнением (Прим. перевод «flow control»)
1NNN — Прыжок в NNN
Ставит PC в значение NNN.
Следующая инструкция будет исполнена из адреса NNN
BNNN — Прыжок в NNN+V0
Ставит PC в значение NNN+V0.
Следующая инструкция будет исполнена из адреса NNN+V0
2NNN — Вызов функции (Call Subroutine)
Вызывает функции по адресу 2NNN. В стек записывается значение PC + 2.
00EE — Возврат из функции (Return from Subroutine)
Регистр PC будет установлен в значение последнего элемента стека.
3XNN — Пропустить инструкцию, если константа и регистр равны.
Пропускает инструкцию (PC+4) если константа NN и регистр X равны. Иначе не пропускать (PC+2).
5XY0 — Пропустить инструкцию, если оба регистра равны.
Пропускает инструкцию (PC+4) если регистр Y и регистр X равны. Иначе не пропускать (PC+2).
4XNN — Пропустить инструкцию, если константа и регистр не равны.
Пропускает инструкцию (PC+4) если константа NN и регистр X НЕ равны. Иначе не пропускать (PC+2).
9XY0 — Пропустить инструкцию, если регистры не равны.
Пропускает инструкцию (PC+4) если регистр Y и регистр X НЕ равны. Иначе не пропускать (PC+2).
Регистры и память
FX55 — Сохранить значения регистров V0 до VX включительно в память начиная адреса I.
После выполнения регистр I будет равен I + X + 1. Хотя некоторые интерпретаторы игнорируют это правило.
FX65 — Загрузить регистры V0 до VX включительно в значения сохраненный в памяти начиная с адреса I.
После выполнения регистр I будет равен I + X + 1. Хотя некоторые интерпретаторы игнорируют это правило.
Все остальное
На какой частоте работает интерпретатор?
Про это ничего не могу найти в оригинале. Из интернета были получены самые разные частоты: 1000Hz, 840Hz, 540Hz, 500Hz, даже 60Hz.
Что будет если прыжок (Jump) будет не выровнен?
Никакой информации об этом я не нашел, но думаю что инструкция будет загружаться и исполняться.
Что будет если прочитать или записать из первых 512 байт?
Снова ничего не найдено. Думаю надо отдавать 0 а при записи игнорировать.
Конец
На этом конец. При опечатках писать в личные сообщения. Буду рад любым замечаниям. Практическая часть находиться в процессе создания. Практическая часть будет на C (не C++) и SDL2.
Тут можно найти оригинал. Еще чуть-чуть информации тут. Еще практический туториал тут.
Что такое компилятор?
Компилятор (от английского Compile – собирать, накапливать) – это вариант реализации транслятора, который создаётся для перевода программы, написанной на высокоуровневом языке программирования в машинный код, который в последствие будет исполняться процессором компьютера. Этот тип трансляции называется компиляцией.
В большинстве случаев компиляция программы происходит полностью (AOT-компиляция). Компилятор целиком считывает программу, проводит её пошаговый анализ (лексический, синтаксический, семантический), оптимизирует её, очищая от излишних конструкций, но сохраняя исходный смысл операций, и также целиком переводит её в машинный код.
Однако, иногда используется и построчная компиляция. В этом случае машинный код генерируется и исполняется для каждой полной грамматической конструкции исходного кода. От интерпретации такая компиляция отличается способом исполнения.
Для каждого языка программирования и практически для каждой операционной системы используется свой компилятор. Иногда для одного семейства операционных систем может использоваться один и тот же компилятор.
Компиляторы для C++
Так, например, для C++ можно использовать:
- Microsoft Visual C++ 6.0
- MS Visual Studio 2005 Professional
- Intel C++ Compiler 4.5
- Borland Builder 6.0
- Borland C++ Compiler
- g++
- gcc
- MinGW 3.2
Подходящий компилятор выбирается, исходя из особенностей программ, с которыми предстоит работать и, как уже говорилось выше, операционной системы.
Компилятор для Python
Необходимость самостоятельно компилировать исходный код с Питона в exe-файл для последующей интерпретации возникает нечасто. В тех случаях, когда на компьютер, на котором планируется выполнение программы, уже установлен интерпретатор Python, компиляция обычно не требуется.
Если программе всё же необходима компиляция, можно использовать cx_Freeze.
Компилятор для Java
Язык программирования Java работает с виртуальной машиной Java, которая обрабатывает байт-код (промежуточный код) и передаёт инструкции оборудованию. Виртуальная машина Java, по сути, является интерпретатором.
Компиляторы в Java используются для того, чтобы преобразовать исходный код в байт-код, доступный пониманию виртуальной машины и пригодный для последующей интерпретации.
Чаще всего используются:
- GNU Compiler for Java
- Javac
Javac помимо анализа и трансляции, производит ещё и оптимизацию кода.
В целом, за счёт использования виртуальной машины, Java выполняет операции, описанные в исходном коде куда медленнее, чем, скажем, С++. При исполнении некоторых операций Java может уступать в скорости до 7 раз. Для ускорения работы программ на Java используется оптимизация библиотек (в них широко используется native-код), некоторые аппаратные решения для ускоренной обработки байт-кода и JIT-компиляция.
JIT-компиляция
JIT-компиляция – это трансляция байт-кода в машинный код непосредственно во время работы программы. JIT-компиляция может быть применена к любой части программы или ко всей программе в целом.
Использование этой технологии позволяет существенно ускорить процесс исполнения задач, поставленных в исходном коде, по сравнению с пошаговой интерпретацией, традиционно применяемой виртуальными машинами.
История
В ранние годы развития программирования на языки сильно влиял выбор способа выполнения. Например, компилируемые языки требовали задания типа данных переменной в момент её описания или первого использования. В то время как интерпретируемые языки в силу своей динамической природы позволяли отказаться от этого требования, что давало больше гибкости и ускоряло разработку.
Изначально интерпретируемые языки преобразовывались в машинный код построчно, то есть каждая логическая строка компилировалась непосредственно перед выполнением. В результате каждая инструкция, заключенная в тело цикла и исполняемая несколько раз, столько же раз обрабатывалась транслятором. В настоящее время такие эффекты редки. Большинство интерпретируемых языков предварительно транслируются в промежуточное представление. Оно представляет собой байт-код или шитый код (threaded code). Это набор инструкций по вызову небольших фрагментов более низкоуровневого кода, эквивалентный нескольким командам ассемблера или командам виртуальной машины соответственно. Уже этот код исполняется интерпретатором или виртуальной машиной.
Например, такую схему используют следующие языки:
- Java
- Python
- Ruby (использует представление кода в виде абстрактного синтаксического дерева)
Промежуточный код может создаваться как явной процедурой компиляции всего проекта (Java), так и скрытой трансляцией каждый раз перед началом выполнения программы (Perl, Ruby) и при изменении исходного кода (Python).
Типы интерпретаторов
Простой интерпретатор анализирует и тут же выполняет (собственно интерпретация) программу покомандно (или построчно), по мере поступления её исходного кода на вход интерпретатора. Достоинством такого подхода является мгновенная реакция. Недостаток — такой интерпретатор обнаруживает ошибки в тексте программы только при попытке выполнения команды (или строки) с ошибкой.
Интерпретатор компилирующего типа — это система из компилятора, переводящего исходный код программы в промежуточное представление, например, в байт-код или p-код, и собственно интерпретатора, который выполняет полученный промежуточный код (так называемая виртуальная машина). Достоинством таких систем является большее быстродействие выполнения программ (за счёт выноса анализа исходного кода в отдельный, разовый проход, и минимизации этого анализа в интерпретаторе). Недостатки — большее требование к ресурсам и требование на корректность исходного кода. Применяется в таких языках, как Java, PHP, Tcl, Perl, REXX (сохраняется результат парсинга исходного кода), а также в различных СУБД.
В случае разделения интерпретатора компилирующего типа на компоненты получаются компилятор языка и простой интерпретатор с минимизированным анализом исходного кода. Причём исходный код для такого интерпретатора не обязательно должен иметь текстовый формат или быть байт-кодом, который понимает только данный интерпретатор, это может быть машинный код какой-то существующей аппаратной платформы. К примеру, виртуальные машины вроде QEMU, Bochs, VMware включают в себя интерпретаторы машинного кода процессоров семейства x86.
Некоторые интерпретаторы (например, для языков Лисп, Scheme, Python, Бейсик и других) могут работать в режиме диалога или так называемого цикла чтения-вычисления-печати (англ. read-eval-print loop, REPL). В таком режиме интерпретатор считывает законченную конструкцию языка (например, s-expression в языке Лисп), выполняет её, печатает результаты, после чего переходит к ожиданию ввода пользователем следующей конструкции.
Уникальным является язык Forth, который способен работать как в режиме интерпретации, так и компиляции входных данных, позволяя переключаться между этими режимами в произвольный момент, как во время трансляции исходного кода, так и во время работы программ.
Следует также отметить, что режимы интерпретации можно найти не только в программном, но и аппаратном обеспечении. Так, многие микропроцессоры интерпретируют машинный код с помощью встроенных микропрограмм, а процессоры семейства x86, начиная с Pentium (например, на архитектуре Intel P6), во время исполнения машинного кода предварительно транслируют его во внутренний формат (в последовательность микроопераций).
Примечания
- Кочергин В. И. interpreter // Большой англо-русский толковый научно-технический словарь компьютерных информационных технологий и радиоэлектроники. — 2016. — ISBN 978-5-7511-2332-1.
- Интерпретатор // Математический энциклопедический словарь / Гл. ред. Прохоров Ю. В.. — М.: Советская энциклопедия, 1988. — С. 820. — 847 с.
- ГОСТ 19781-83; СТ ИСО 2382/7-77 // Вычислительная техника. Терминология: Справочное пособие. Выпуск 1 / Рецензент канд. техн. наук Ю. П. Селиванов. — М.: Издательство стандартов, 1989. — 168 с. — 55 000 экз. — ISBN 5-7050-0155-X.
- Першиков В. И., Савинков В. М. Толковый словарь по информатике / Рецензенты: канд. физ.-мат. наук А. С. Марков и д-р физ.-мат. наук И. В. Поттосин. — М.: Финансы и статистика, 1991. — 543 с. — 50 000 экз. — ISBN 5-279-00367-0.
- Борковский А. Б. Англо-русский словарь по программированию и информатике (с толкованиями). — М.: Русский язык, 1990. — 335 с. — 50 050 (доп,) экз. — ISBN 5-200-01169-3.
- Толковый словарь по вычислительным системам = Dictionary of Computing / Под ред. В. Иллингуорта и др.: Пер. с англ. А. К. Белоцкого и др.; Под ред. Е. К. Масловского. — М.: Машиностроение, 1990. — 560 с. — 70 000 (доп,) экз. — ISBN 5-217-00617-X (СССР), ISBN 0-19-853913-4 (Великобритания).
- Dave Martin. . Rexx FAQs. Дата обращения 22 декабря 2009.
- Jeff Fox. (англ.). Thoughtful Programming and Forth. UltraTechnology. Дата обращения 25 января 2010.
Что такое компиляторы и интерпретаторы?
Статья рассчитана на пользователей, которые хотя бы немного знают о том, как устроены сети, операционные системы и языки программирования. Если вы вообще не имеете никакого представления о перечисленном, то рекомендуем почитать, ибо информация будет выглядеть достаточно сумбурно.
Для начал стоит разобраться, что же такое компилятор, ведь он буквально является основой основ. После написания кода на каком-либо языке он обязательно должен пройти стадию компиляции, т. е. сборки всех частей кода воедино. Дело в том, что проект всегда и обязательно разделяется на множество частей, каждая из которых выполняет лишь определенную роль. Будь то работа с сетью, файлами, пользователем и т. д. Такие куски кода могут быть написаны самим пользователем или взяты из стандартной библиотеки STL.
При взятии какого-либо элемента есть два варианта компиляции: автоматический и динамический. При автоматическом берутся все необходимые (включенные) библиотеки, а при динамическом — лишь выбранные части эти библиотек. Это весьма большая тема, поэтому рекомендуем прочитать про каждый способ отдельно.
Итак, все библиотеки, части кода в форме исходных файлов собраны, а что дальше? Правильно, теперь самое время заставить компьютер понимать наш код. Делается это для того, чтоб компьютер мог вообще взаимодействовать с пользователем. Промежуточным звеном между аппаратной и программной частью является полумашинный язык программирования – ассемблер, именно в этот язык интерпретатор переводит вами написанный код.
Из сказанного выше можно сказать, что интерпретатор – это определенная программа для перекодировки в полумашинный язык ассемблер. В следующей части статьи мы поговорим подробнее про современные компиляторы и интерпретаторы.
Преимущества
Есть ряд возможностей, которые значительно легче реализовать в интерпретаторе, чем в компиляторе:
- кроссплатформенность
- рефлексия и интроспекция
- динамическая типизация
- использование динамической области видимости и замыканий
- пошаговое отслеживание выполнения программы
- модификация программы во время исполнения
- меньшие затраты времени на разработку и отладку
- простой способ создания переносимых программ
- не требует затрат на компиляцию небольших программ
Кроме того, принципы и стиль программирования часто не требуют создания и описания специальных конструкций, оформляющих программу (манифестов, классов, типов данных).
Это позволяет разрабатывать и тестировать код постепенно, что удобно как для написания небольших программ, так и для изолированной разработки модулей для сложных систем.
В силу своей универсальности их удобно применять в качестве скриптовых языков.
Интерпретатор
Осталась последняя часть — сам интерпретатор, который обрабатывает наши конструкции языка.
open YobaType
let identifiers = Hashtbl.create 10;;
let funcs = Hashtbl.create 10;;
let print_stats () =
let print_item id amount =
Printf.printf ">> Йо! У тебя есть %s: %d" id amount;
print_newline ();
flush stdout in
Hashtbl.iter print_item identifiers;;
let arithm id op value () =
try
Hashtbl.replace identifiers id (op (Hashtbl.find identifiers id) value);
Printf.printf ">> Гавно вопрос\n"; flush stdout
with Not_found -> Printf.printf ">> Х@#на, ты %s не любишь\n" id; flush stdout;;
let rec cond amount id act1 act2 () =
try
if Hashtbl.find identifiers id >= amount then process_action act1 () else process_action act2 ()
with Not_found ->
Printf.printf ">> Човаще?!\n";
flush stdout
and process_action = function
| Create(id) -> (function () -> Hashtbl.add identifiers id 0)
| Decrement(amount, id) -> arithm id (-) amount
| Increment(amount, id) -> arithm id (+) amount
| Conditional(amount, id, act1, act2) -> cond amount id act1 act2
| DoNothing -> (function () -> ())
| Stats -> print_stats
| AddFunction(id, funclist) -> (function () -> Hashtbl.add funcs id funclist)
| CallFunction(id) -> callfun id
and callfun id () =
let f: YobaType.action list = Hashtbl.find funcs id in
List.iter (function x -> process_action x ()) f
;;
while true do
try
let lexbuf = Lexing.from_channel stdin in
process_action (YobaParser.main YobaLexer.token lexbuf) ()
with
YobaLexer.Eof ->
print_stats ();
exit 0
| Parsing.Parse_error ->
Printf.printf ">> Ни@#я не понял б@#!\n";
flush stdout
| Failure(_) ->
Printf.printf ">> Ни@#я не понял б@#!\n";
flush stdout
done
Первым делом мы создадим две хэштаблицы — для переменных и для функций. Начальный размер 10 взят от фонаря, у нас же тренировочный язык, зачем нам сразу много функций.
Затем объявим две небольших функции: одна — для вывода статистики, вторая — для инкремента/декремента переменных.
Дальше идёт группа из сразу трёх функций: cond обрабатывает условные конструкции (наш if), callfun отвечает за вызов функций, а process_action отвечает за обработку пришедшей на вход инструкции как таковой. Надеюсь, почему все три функции зависят друг от друга, объяснять не надо.
Обратите внимание, все варианты в process_action не выполняют действие, а всего лишь возвращают функцию, которая его выполнит. Изначально это было не так, но именно это маленькое изменение позволило мне легко и непринужденно добавить в язык поддержку пользовательских функций.. Наконец, последняяя часть кода до посинения в цикле читает и обрабатывает результат работы парсера.
Наконец, последняяя часть кода до посинения в цикле читает и обрабатывает результат работы парсера.
Добавим к этому Makefile:
all: ocamlc -c yobaType.ml ocamllex yobaLexer.mll ocamlyacc yobaParser.mly ocamlc -c yobaParser.mli ocamlc -c yobaLexer.ml ocamlc -c yobaParser.ml ocamlc -c yoba.ml ocamlc -o yoba yobaLexer.cmo yobaParser.cmo yoba.cmo clean: rm -f *.cmo *.cmi *.mli yoba yobaLexer.ml yobaParser.ml
Типы интерпретаторов
Простой интерпретатор анализирует и тут же выполняет (собственно интерпретация) программу покомандно (или построчно), по мере поступления её исходного кода на вход интерпретатора. Достоинством такого подхода является мгновенная реакция. Недостаток — такой интерпретатор обнаруживает ошибки в тексте программы только при попытке выполнения команды (или строки) с ошибкой.
Интерпретатор компилирующего типа — это система из компилятора, переводящего исходный код программы в промежуточное представление, например, в байт-код или p-код, и собственно интерпретатора, который выполняет полученный промежуточный код (так называемая виртуальная машина). Достоинством таких систем является большее быстродействие выполнения программ (за счёт выноса анализа исходного кода в отдельный, разовый проход, и минимизации этого анализа в интерпретаторе). Недостатки — большее требование к ресурсам и требование на корректность исходного кода. Применяется в таких языках, как Java, PHP, Tcl, Perl, REXX (сохраняется результат парсинга исходного кода), а также в различных СУБД.
В случае разделения интерпретатора компилирующего типа на компоненты получаются компилятор языка и простой интерпретатор с минимизированным анализом исходного кода. Причём исходный код для такого интерпретатора не обязательно должен иметь текстовый формат или быть байт-кодом, который понимает только данный интерпретатор, это может быть машинный код какой-то существующей аппаратной платформы. К примеру, виртуальные машины вроде QEMU, Bochs, VMware включают в себя интерпретаторы машинного кода процессоров семейства x86.
Некоторые интерпретаторы (например, для языков Лисп, Scheme, Python, Бейсик и других) могут работать в режиме диалога или так называемого цикла чтения-вычисления-печати (англ. read-eval-print loop, REPL). В таком режиме интерпретатор считывает законченную конструкцию языка (например, s-expression в языке Лисп), выполняет её, печатает результаты, после чего переходит к ожиданию ввода пользователем следующей конструкции.
Уникальным является язык Forth, который способен работать как в режиме интерпретации, так и компиляции входных данных, позволяя переключаться между этими режимами в произвольный момент, как во время трансляции исходного кода, так и во время работы программ.
Следует также отметить, что режимы интерпретации можно найти не только в программном, но и аппаратном обеспечении. Так, многие микропроцессоры интерпретируют машинный код с помощью встроенных микропрограмм, а процессоры семейства x86, начиная с Pentium (например, на архитектуре Intel P6), во время исполнения машинного кода предварительно транслируют его во внутренний формат (в последовательность микроопераций).
Еще идеи
- Можно пойти чуть дальше и реализовать какие-нибудь графические возможности в вашей виртуальной машине. Можно даже написать простые игры!
- Попробуйте написать компилятор из простого высокоуровневого языка в ваш байт-код. К сожалению, я так и не написал компилятор для Stupid Virtual Machine (вместо этого я написал компилятор, генерирующий x86-ассемблер в рамках курса о компиляторах). Это было бы отличным упражнением, требующим некоторых дополнительных теоретических знаний.
- Заставить ваш интерпретатор работать максимально быстро — это еще одна интересная, но требующая усилий задача. Это не так уж просто.