Язык обработки шаблонов awk
Содержание:
Множественные поля
Awk хорошо подходит для обработки текста, разбитого на множество логических полей, и дает возможность без усилий обращаться к каждому отдельному полю из awk-скрипта. Следующий скрипт распечатает список всех учетных записей в системе:
$ awk -F»:» «{ print $1 }» /etc/passwd
В вызове awk в вышеприведенном примере параметр –F задает «:» в качестве разделителя полей. Обрабатывая команду print $1, awk выводит первое поле, встреченное в каждой строке входного файла. Вот еще один пример:
$ awk -F»:» «{ print $1 $3 }» /etc/passwd
Вот фрагмент из вывода на экран этого скрипта:
halt7
operator11
root0
shutdown6
sync5
bin1
….etc.
Как видим, awk выводит первое и третье поля файла /etc/passwd, которые представляют собой соответственно поля имени пользователя и uid. При этом, хотя скрипт и работает, он не совершенен — нет пробелов между двумя выходными полями! Те, кто привык программировать в bash или python, возможно ожидали, что команда
print $1 $3 вставит пробел между этими двумя полями. Однако когда в программе на awk две строки оказываются рядом друг с другом, awk сцепляет их без добавления между ними пробела. Следующая команда вставит пробел между полями:
$ awk -F»:» «{ print $1 » » $3 }» /etc/passwd
Когда print вызывается таким способом, он последовательно соединяет
$1 , » » и
$3 , создавая удобочитаемый вывод на экране. Конечно, мы можем также вставить метки полей, если нужно:
$ awk -F»:» «{ print «username: » $1 «\t\tuid:» $3″ }» /etc/passwd
В результате получаем такой вывод:
username: halt uid:7
username: operator uid:11
username: root uid:0
username: shutdown uid:6
username: sync uid:5
username: bin uid:1
….etc.
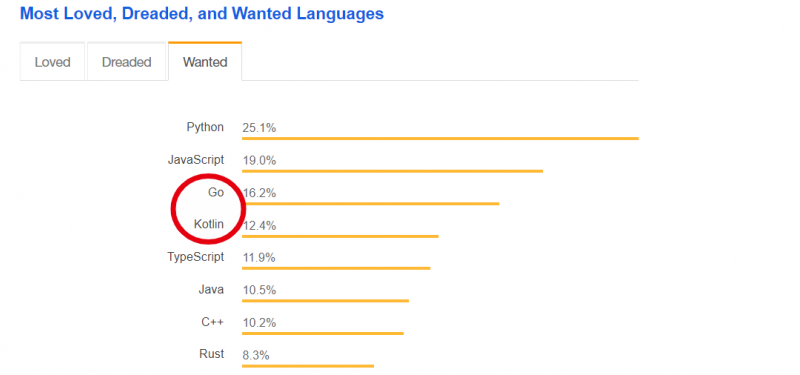
操作记录和字段
当 GAWK 读入一个记录时,它会将该记录中所有的字段存储到变量中。您可以通过使用 加上字段编号来引用每个字段,所以 引用第 1 个字段, 引用第 2 个字段,依此类推,直到记录中的最后一个字段。
以缺省的记录和字段显示了示例文本。
图 4. 将示例文件分解为 AWK 记录和字段
如中所述,您可以使用 来引用整个记录,其中包括所有的字段和字段分隔符。这是许多命令的缺省值。所以例如,正如前面使用过的 ,它等价于 ,这两个命令都将打印出当前整个记录。
打印特定的字段
要输出某个特定的字段,可以将该字段的名称作为参数提供给 。下面的命令尝试打印示例文件中每个记录的第 1 个字段:
$ awk ' { print $1 } ' sample
Heigh-ho!
Most
Then,
$
您可以在 语句中提供多个字段,并且它们可以使用任意的顺序:
$ awk ' { print $7, $3, $1 } ' sample
holly: heigh-ho! Heigh-ho!
mere is Most
the Then,
$
请注意,有些行中没有第 7 个字段,在这种情况下,将不打印任何内容。
当使用逗号进行分隔时,这些字段在输出时将使用空格隔开。您可以省略逗号,以便将它们连接起来。要打印第 7 个和第 8 个字段,并将它们连接起来,可以使用下面的命令:
$ awk ' { print $7 $8 } ' sample
holly:
merefolly:
$
您可以将使用引号括起来的文本和字段组合在一起。尝试下面的命令:
$ awk ' { print "Field 2: " $2 } ' sample
Field 2: sing,
Field 2: friendship
Field 2: heigh-ho,
$
您已经了解了处理字段和记录的强大功能,使用 AWK,很容易对表型数据进行解析、操作,并使用一些简单的命令重新进行格式化。您可以使用 Shell 重定向机制将经过重新格式化的输出定向到一个新的文件,或使用管道进行传输。
如果使用,那么可以将这种功能与其他的命令联合使用,这是非常有价值的。例如,下面的命令修改了日期的缺省输出,以便以日 月,年 的格式进行输出:
$ date|awk '{print $3 " " $2 ", " $6}'
29 Nov, 2006
$
更改字段分隔符
到目前为止,示例中的字段都使用空格字符进行分隔。这是缺省的行为,即任意个数的空格或制表符,您可以对其进行更改。字段分隔符的值保存在 变量中。与 AWK 中的其他变量一样,可以在程序中的任何位置对其进行重新定义。要对整个文件使用不同的字段分隔符,可以在 语句重新定义它。
使用感叹号 (!) 作为字段分隔符打印示例数据的第 1 个字段:
$ awk ' BEGIN { FS = "!" } { print $1 } ' sample
Heigh-ho
Most friendship is feigning, most loving mere folly:
Then, heigh-ho, the holly
$
请注意在打印第 2 个和第 3 个字段时的差别:
$ awk ' BEGIN { FS = "!" } { print $2 } ' sample
sing, heigh-ho
$ awk ' BEGIN { FS = "!" } { print $3 } ' sample
unto the green holly:
$
尝试将输出中的字段与 中列出的字段进行比较。
但是字段分隔符并不一定必须是单个字符。可以使用一个短语:
$ awk ' BEGIN { FS = "Heigh-ho" } { print $2 } ' sample
! sing, heigh-ho! unto the green holly:
$
在 GAWK 中,字段分隔符可以是任何正则表达式。要使每个输入字符成为一个独立的字段,可以让 的值为空。
算出大写字母的总数。上面的示例仅在整个文件中匹配一个分隔符,而下面的示例将匹配短语,无论大小写:
$ awk ' BEGIN { FS = "eigh-ho" } { print $2 } ' sample
! sing,
, the holly!
$
通过在命令行中使用引号将其括起来并作为 选项的参数,也可以更改字段分隔符:
$ awk -F "," ' { print $2 } ' sample
heigh-ho! unto the green holly:
most loving mere folly:
heigh-ho
$
使用这种功能,很容易创建可以对文件进行解析的单行程序,如 /etc/passwd,其中的字段由冒号 (:) 进行分隔。您可以轻松地从中提取完整的用户名称列表,例如:
$ awk -F ":" ' { print $5 } ' /etc/passwd
更改记录分隔符
与字段分隔符一样,您可以将记录分隔符的缺省值(换行符)更改为所需的任何内容。其当前值保存在 变量中。
将记录分隔符更改为逗号,并对示例文件使用它:
$ awk ' BEGIN { RS = "," } //' sample
Heigh-ho! sing
heigh-ho! unto the green holly:
Most friendship is feigning
most loving mere folly:
Then
heigh-ho
the holly!
$
更改输出
对 AWK 输出的处理与 AWK 输入数据一样,它被分解为许多字段和记录,输出流具有自己的分隔符,初始情况下与输入分隔符的缺省值相同,即空格和换行。 语句中的字段由逗号分隔,该语句中使用的输出字段分隔符 设置为单个空格,您可以重新定义 变量,以对其进行更改。输出记录分隔符 设置为换行符,您可以通过重新定义 变量对其进行更改。
要从文件中删除所有的换行,并将文件中所有的文本置于一行,只需将输出记录分隔符更改为空字符即可,对于某些文本分析和筛选来说,这样做是非常有价值的。
使用示例文件尝试下面的命令:
$ awk 'BEGIN {ORS=""} //' sample
Heigh-ho! sing, heigh-ho! unto the green holly:Most friendship\
is feigning, most loving mere folly:Then, heigh-ho, the holly!$
删除了所有的换行,包括最后一个。返回的 Shell 提示符与输出数据出现在同一行中。要在结尾添加一个换行,可以将其放在 规则中:
$ awk 'BEGIN {ORS=""} // { print } END {print "\n"}' sample
Heigh-ho! sing, heigh-ho! unto the green holly:Most friendship\
is feigning, most loving mere folly:Then, heigh-ho, the holly!
$
更多 GAWK 变量
变量包含当前记录中字段的个数。使用 可以引用其数值,而使用 则表示引用实际字段本身的内容。所以,如果记录有 100 个字段, 将输出整数 100,而 则与 输出相同的结果,都是该记录中最后一个字段的内容。
变量包含当前的记录个数。当读取到第 1 个记录时,其值为 1,当读取到第 2 个记录时,其值增为 2,依此类推。在 模式中使用它,以便输出输入中的行数:
$ awk 'END { print "Input contains " NR " lines." }' sample
Input contains 3 lines.
$
注意:如果上面的 语句位于 模式中,那么该程序将报告其输入包含 0 行内容,因为在执行时 的值为 0,因为此时尚未读入任何输入记录。
使用 打印相对于当前记录个数的字段:
$ awk '{ print NR, $NR }' sample
1 Heigh-ho!
2 friendship
3 the
$
再来研究一下,可以看到第 1 个记录中的字段 1 的值、第 2 个记录中的字段 2 的值,以及最后一个记录中字段 3 的值。将其与您的程序输出进行比较。
尝试列出每个记录中字段的个数,以及最后一个字段的值:
$ awk ' { print "Record " NR " has " NF " fields and ends with " $NF}' sample
Record 1 has 7 fields and ends with holly:
Record 2 has 8 fields and ends with folly:
Record 3 has 4 fields and ends with holly!
通常可以使用大量特殊的 GAWK 变量。 列出了这些变量,并对其含义进行了描述。
表 2. 常见的 GAWK 变量
| 变量 | 描述 |
|---|---|
| 该变量包含每个记录的字段个数。 | |
| 该变量包含当前的记录个数。 | |
| 该变量是字段分隔符。 | |
| 该变量是记录分隔符。 | |
| 该变量是输出字段分隔符。 | |
| 该变量是输出记录分隔符。 | |
| 该变量包含所读取的输入文件的名称。 | |
| 当 设置为非空值,GAWK 将忽略模式匹配中的大小写。 |
Строчные переменные
Одной из приятных особенностей переменных awk является то, что они «простые и строчные.» Я называю переменные awk «строчными», потому что все переменные awk внутри хранятся как строки. В то же время переменные awk «простые», потому что с переменной можно производить математические операции, и если она содержит правильную числовую строку, awk автоматически позаботится о преобразовании строки в число. Чтобы понять, что я имею в виду, взглянем на этот пример:
x="1.01" # Мы сделали так, что x содержит *строку* "1.01" x=x+1 # Мы только что прибавили 1 к *строке* print x # Это, кстати, комментарий :)
Awk выведет:
2.01
Любопытно! Хотя мы присвоили переменной x строковое значение 1.01, мы все же смогли прибавить к ней единицу. Нам бы не удалось сделать это в bash или python. Прежде всего, bash не поддерживает арифметику с плавающей запятой. И, хотя в bash есть «строчные» переменные, они не являются «простыми»; для выполнения любых математических операций bash требует, чтобы мы заключили наши вычисления в уродливые конструкции . Если бы мы использовали python, нам бы потребовалось явно преобразовать нашу строку
в значение с плавающей запятой, прежде чем выполнять какие-либо расчеты с ней. Хоть это и не трудно, но это все-таки дополнительный шаг. В случае с awk все это делается автоматически, и это делает наш код красивым и чистым. Если бы нам потребовалось возвести первое поле каждой входной строки в квадрат и прибавить к нему единицу, мы бы воспользовались таким скриптом:
{ print ($1^2)+1 }
Если немного поэкспериментировать, то можно обнаружить, что если в какой-то переменной не содержится правильного числа, awk при вычислении математического выражения будет обращаться с этой переменной как с числовым нулем.
运行 GAWK 程序
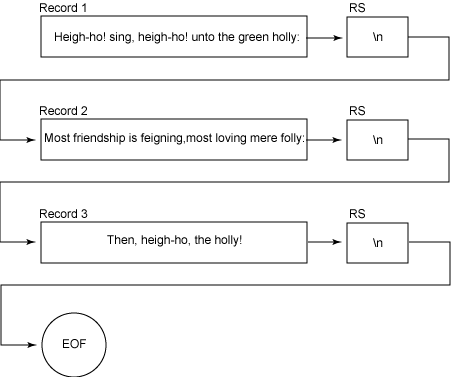
GAWK 接受两个输入文件,即包含 AWK 程序本身的命令文件和要进行处理的数据文件。您需要一些示例数据,所以可以使用文本编辑器向名为 sample 的文件加入 中所有的内容(三行内容)。
清单 4. 示例文本
Heigh-ho! sing, heigh-ho! unto the green holly: Most friendship is feigning, most loving mere folly: Then, heigh-ho, the holly!
在命令行中
不需要将命令保存到文件中:您可以将它们作为参数传递。这是运行 GAWK 单行程序 的常用方法。
其格式是:
awk 'program' filespec
尝试使用下面的单行程序,以打印出示例文件中的每行内容:
$ awk '{ print }' sample
Heigh-ho! sing, heigh-ho! unto the green holly:
Most friendship is feigning, most loving mere folly:
Then, heigh-ho, the holly!
$
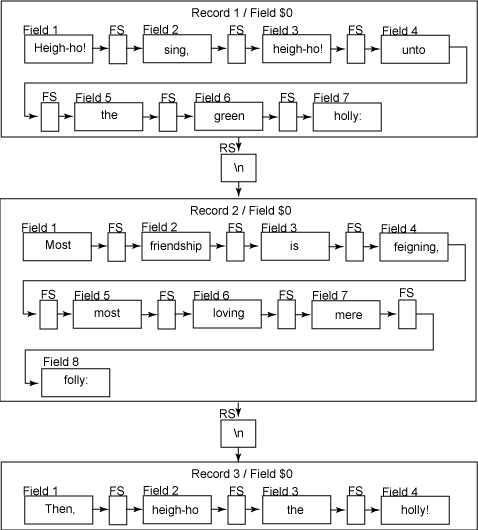
这个程序读取示例文件,并打印出其中的每个记录,换句话说,它仅仅逐字地输出整个文件。对于 GAWK,该文件中的数据与 所示类似。
图 3. GAWK 对示例文件的解释
因为 GAWK 可以接受多个输入文件,所以如果您指定多个输入文件作为参数,该程序可以将它们连接起来。
单行程序并不仅限于一行中的程序。例如,您可以在命令行中使用引号将 中的所有内容括起来,该程序将运行 中的代码。
清单 5. 多行内容的单行程序
$ awk 'BEGIN { print "Beginning of file.";
print "------------------" },
//
END { print "------------";
print "End of file."}' sample
Beginning of file
-----------------
Heigh-ho! sing, heigh-ho! unto the green holly:
Most friendship is feigning, most loving mere folly:
Then, heigh-ho, the holly!
------------
End of file.
$
除了任意长度输入程序的实用性之外,在命令行中运行 AWK 程序需要注意一点:必须小心地使用引号!AWK 中的变量,如 ,可以表示字段,这一点将在下一个部分中进行描述,在许多 Shell 中,这些字段是特殊的变量,而这些变量将转换为在命令行中给定的参数。
作为筛选器
AWK 通常用作管道中的文本筛选器。在这种情况下,GAWK 从标准输入读取数据:
awk 'program'
尝试使用示例文件测试下面的命令:
$ cat sample | awk '{ print }'
Heigh-ho! sing, heigh-ho! unto the green holly:
Most friendship is feigning, most loving mere folly:
Then, heigh-ho, the holly!
$
来自文件
在实际中,通常只在命令行中运行单行程序。大型的 GAWK 程序通常保存在文件中。可以使用 选项指定程序文件。
所以,假设一个名为 progfile 的文件中包含下面的内容:
{ print }
当您运行下面的命令时,将与在运行 得到相同的结果:
$ awk -f progfile sample Heigh-ho! sing, heigh-ho! unto the green holly: Most friendship is feigning, most loving mere folly: Then, heigh-ho, the holly! $
请注意,如果程序放在文件中,那么就不需要在 Shell中使用引号将内容括起来。
作为脚本
另一种运行 GAWK 程序的方法是将其放到文件中,并使用 shebang 命令(井号加感叹号)将该文件变成可执行的脚本,如果您的 Shell 支持这种方法。
将程序放到一个名为 awkat 的 GAWK 脚本文件中,使其具有执行权限,并尝试使用示例文件运行该脚本,如 中所示。
清单 6. 将简单的程序作为可执行文件运行
$ cat > awkat#!/usr/bin/awk -f{ print }Ctrl-d
$ chmod u+x awkat
$ ./awkat sample
Heigh-ho! sing, heigh-ho! unto the green holly:
Most friendship is feigning, most loving mere folly:
Then, heigh-ho, the holly!
$
Чтение awk-скриптов из командной строки
Скрипты awk, которые можно писать прямо в командной строке, оформляются в виде текстов команд, заключённых в фигурные скобки. Кроме того, так как awk предполагает, что скрипт представляет собой текстовую строку, его нужно заключить в одинарные кавычки:
Если теперь ввести что-нибудь в консоль и нажать , awk обработает введённые данные с помощью скрипта, заданного при его запуске. Awk обрабатывает текст из потока ввода построчно, этим он похож на sed. В нашем случае awk ничего не делает с данными, он лишь, в ответ на каждую новую полученную им строку, выводит на экран текст, заданный в команде .

Первый запуск awk, вывод на экран заданного текста
Что бы мы ни ввели, результат в данном случае будет одним и тем же — вывод текста.
Для того, чтобы завершить работу awk, нужно передать ему символ конца файла (EOF, End-of-File). Сделать это можно, воспользовавшись сочетанием клавиш .
Неудивительно, если этот первый пример показался вам не особо впечатляющим. Однако, самое интересное — впереди.
Встроенные переменные: сведения о данных и об окружении
Помимо встроенных переменных, о которых мы уже говорили, существуют и другие, которые предоставляют сведения о данных и об окружении, в котором работает awk:
Переменные и позволяют работать с аргументами командной строки. При этом скрипт, переданный awk, не попадает в массив аргументов . Напишем такой скрипт:
После его запуска можно узнать, что общее число аргументов командной строки — 2, а под индексом 1 в массиве записано имя обрабатываемого файла. В элементе массива с индексом 0 в данном случае будет «awk».

Работа с параметрами командной строки
Переменная представляет собой ассоциативный массив с переменными среды. Опробуем её:
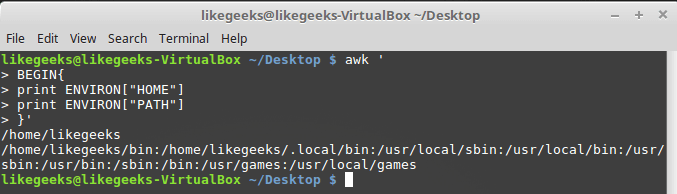
Работа с переменными среды
Переменные среды можно использовать и без обращения к . Сделать это, например, можно так:

Работа с переменными среды без использования ENVIRON
Переменная позволяет обращаться к последнему полю данных в записи, не зная его точной позиции:
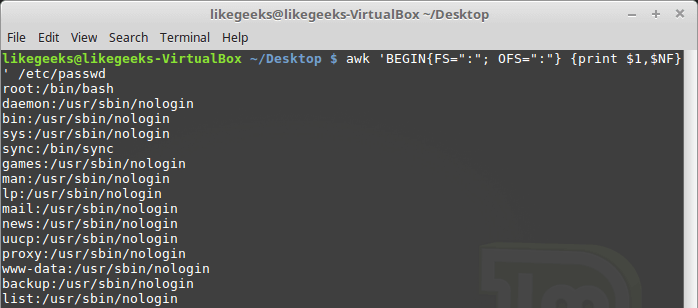
Пример использования переменной NF
Эта переменная содержит числовой индекс последнего поля данных в записи. Обратиться к данному полю можно, поместив перед знак .
Переменные и , хотя и могут показаться похожими, на самом деле различаются. Так, переменная хранит число записей, обработанных в текущем файле. Переменная хранит общее число обработанных записей. Рассмотрим пару примеров, передав awk один и тот же файл дважды:
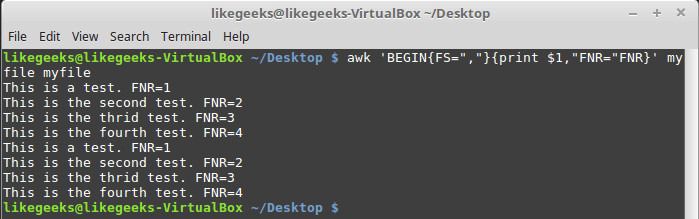
Исследование переменной FNR
Передача одного и того же файла дважды равносильна передаче двух разных файлов
Обратите внимание на то, что сбрасывается в начале обработки каждого файла
Взглянем теперь на то, как ведёт себя в подобной ситуации переменная :
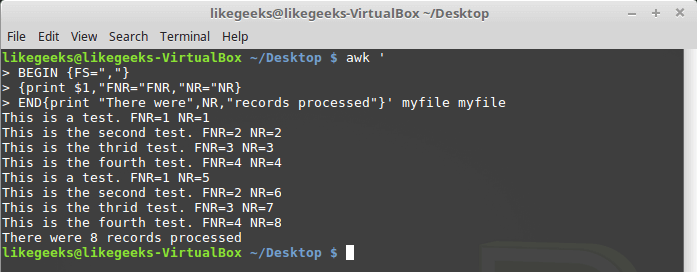
Различие переменных NR и FNR
Как видно, , как и в предыдущем примере, сбрасывается в начале обработки каждого файла, а вот , при переходе к следующему файлу, сохраняет значение.
开始之前
了解本教程中介绍的内容、如何最好地利用它以及在学习本教程的过程中需要完成哪些工作。
关于本教程
GNU AWK (GAWK) 是历史悠久的 AWK 编程语言的开放源代码实现,可用于所有的 UNIX 系统。AWK 语言是一种 UNIX 备用工具,它是一种功能强大的文本操作和模式匹配语言,特别适用于进行信息检索,这使得它非常适合用于当今的数据库驱动的应用程序。因为它集成于 UNIX 环境,所以可以设计、构建和快速地执行完整的工作程序,并且立即就能得到结果。
本教程为 AWK 文本处理语言提供了实践性的介绍。它介绍了如何使用开放源代码 GAWK 解释器来编写和执行 AWK 程序,以便通过各种方式来搜索和操作数据。
目标
本教程面向那些需要利用 AWK 强大的文本操作功能的读者。在本教程中,您将使用 GAWK,以了解各种运行 AWK 程序的方法。您还将了解如何组织程序,并学习 AWK 的记录和字段范例。在完成本教程后,您可以学习到该语言的基本内容,包括格式化输出、记录和字段操作以及模式匹配。您还应该能够编写自定义的 AWK 程序,以使用 UNIX 命令行执行复杂的文本处理。
系统要求
您必须在系统中安装 GAWK 的工作副本,最好是 Version 3.0 或更高版本。很容易获得 GAWK 的源代码和二进制包(请参见部分)。如果您使用源代码安装 GAWK,请参考 GAWK 源代码分发版中的 README 文件,其中列出了进行成功的编译和安装所需的任何附加软件。