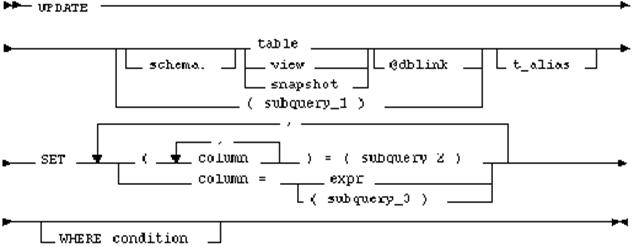
Оператор between (transact-sql)between (transact-sql)
Содержание:
- Order By clause in SQL Union vs Union All clause
- Пример — использование оператора INSERT для вставки нескольких записей
- SQL Server
- Demo Database
- Example — Different Field Names
- UNION vs. UNION ALL Examples With Sort on Non-indexed Column
- SQL References
- DB2
- Пример — использование условия IN с символьными значениями
- Правила использования
- Frequently Asked Questions
- Функция SQL Replace
- Примеры
- Синтаксис
Order By clause in SQL Union vs Union All clause
We cannot use the Order by clause with each Select statement. SQL Server can perform a sort in the final result set only.
Let’s try to use Order by with each Select statement.
|
1 |
SELECTNationalIDNumber, LoginID, JobTitle, BirthDate, MaritalStatus, Gender FROMAdventureWorks2017.HumanResources.Employee_M OrderbyJobTitle UNION SELECTNationalIDNumber, LoginID, JobTitle, BirthDate, MaritalStatus, Gender FROMAdventureWorks2017.HumanResources.Employee_F OrderbyJobTitle UNION SELECTNationalIDNumber, LoginID, JobTitle, BirthDate, MaritalStatus, Gender FROM AdventureWorks2017.HumanResources.Employee_All OrderbyJobTitle |
We get the following error message. It gives a “incorrect syntax” error message.
The valid query to sort result using Order by clause in SQL Union operator is as follows.
|
1 |
SELECTNationalIDNumber, LoginID, JobTitle, BirthDate, MaritalStatus, Gender FROMAdventureWorks2017.HumanResources.Employee_M UNION SELECTNationalIDNumber, LoginID, JobTitle, BirthDate, MaritalStatus, Gender FROMAdventureWorks2017.HumanResources.Employee_F UNION SELECTNationalIDNumber, LoginID, JobTitle, BirthDate, MaritalStatus, Gender FROMAdventureWorks2017.HumanResources.Employee_All ORDERBYJobTitle; |
We get the following output with result set sorted by JobTitle column.
Пример — использование оператора INSERT для вставки нескольких записей
Поместив оператор SELECT в оператор INSERT, вы можете быстро выполнить несколько операций вставки. Давайте рассмотрим пример того, как это сделать.
В этом примере у нас есть таблица employees со следующими данными:
| employee_number | first_name | last_name | salary | dept_id |
|---|---|---|---|---|
| 1001 | Justin | Bieber | 62000 | 500 |
| 1002 | Selena | Gomez | 57500 | 500 |
| 1003 | Mila | Kunis | 71000 | 501 |
| 1004 | Tom | Cruise | 42000 | 501 |
И таблица customers со следующими данными:
| customer_id | first_name | last_name | favorite_website |
|---|---|---|---|
| 4000 | Justin | Bieber | google.com |
| 5000 | Selena | Gomez | bing.com |
| 6000 | Mila | Kunis | yahoo.com |
| 7000 | Tom | Cruise | oracle.com |
| 8000 | Johnny | Depp | NULL |
| 9000 | Russell | Crowe | google.com |
Теперь давайте вставим некоторую информацию из таблицы employees в таблицу customers:
PgSQL
INSERT INTO customers
(customer_id, last_name, first_name)
SELECT employee_number AS customer_id,
last_name,
first_name
FROM employees
WHERE employee_number < 1003;
|
1 2 3 4 5 6 7 |
INSERTINTOcustomers (customer_id,last_name,first_name) SELECTemployee_numberAScustomer_id, last_name, first_name FROMemployees WHEREemployee_number<1003; |
СОВЕТ: С этим типом INSERT некоторые базы данных требуют от вас псевдонимов имен столбцов в SELECT, чтобы они соответствовали именам столбцов таблицы, в которую вы вставляете. Как вы можете видеть в приведенном выше примере, мы связали первый столбец в операторе SELECT с customer_id.
Будет вставлено 2 записи. Выберите данные из таблицы customers еще раз:
PgSQL
SELECT *
FROM customers;
|
1 2 |
SELECT* FROMcustomers; |
Вот результаты, которые вы должны получить:
| customer_id | first_name | last_name | favorite_website | |
|---|---|---|---|---|
| 4000 | Justin | Bieber | google.com | |
| 5000 | Selena | Gomez | bing.com | |
| 6000 | Mila | Kunis | yahoo.com | |
| 7000 | Tom | Cruise | oracle.com | |
| 8000 | Johnny | Depp | NULL | |
| 9000 | Russell | Crowe | google.com | |
| 1001 | Justin | Bieber | 62000 | NULL |
| 1002 | Selena | Gomez | 57500 | NULL |
В этом примере последние 2 записи в таблице customers были вставлены с использованием данных из таблицы employees.
SQL Server
Платформа SQL Server поддерживает ключевые слова UNION и UNION ALL стандартного синтаксиса ANSI.
инструкция SELECT 1 UNION
инструкция SELECT 2 UNION
SQL Server не поддерживает предложение CORRESPONDING. Предложение UNION DISTINCT не поддерживается, но функциональным эквивалентом является предложение UNION.
С предложениями UNION и UNION ALL вы можете использовать инструкцию SELECT…INTO, но ключевое слово INTO должно находиться в первом запросе оператора объединения. Специальные ключевые слова, такие, как SELECT ТОР и GROUP BY…WITH CUBE, можно использовать во всех запросах объединения. Однако обязательно включайте эти предложения во все запросы объединения. Если вы используете предложения SELECT ТОР или GROUP BY… WITH CUBE в одном запросе, операция выполнена не будет.
Все запросы в объединении должны содержать одно и то же количество столбцов. Типы данных столбцов не обязательно должны быть идентичны, но они должны быть неявным образом приводимы друг к другу. Например, совместное применение столбцов CHAR и VARCHAR допускается. При выводе данных SQL Server при определении размера типа данных для столбца результирующего набора использует размер наибольшего столбца. Таким образом, если в инструкции SELECT… UNION используются столбцы CHAR(5) и CHAR(IO), то данные обоих столбцов будут выводиться в столбце CHAR(IO). Числовые типы данных приводятся и отображаются в виде типа с наибольшей точностью.
Например, в следующем запросе объединяются результаты двух независимых запросов, использующих предложение GROUP BY…WITH CUBE.
На уроке будет рассмотрена тема использования операций объединения, пересечения и разности запросов. Разобраны примеры того, как используется SQL запрос Union, Exists, а также использование ключевых слов SOME, ANY и All. Рассмотрены строковые функции
Над множеством можно выполнять операции объединения, разности и декартова произведения. Те же операции можно использовать и в sql запросах (выполнять операции с запросами).
Использование оператора UNION требует выполнения нескольких условий:
- количество выходных столбцов каждого из запросов должно быть одинаковым;
- выходные столбцы каждого из запросов должны быть сравнимы между собой по типам данных (в порядке их очередности);
- в итоговом наборе используются имена столбцов, заданные в первом запросе;
- ORDER BY может быть использовано только в конце составного запроса, так как оно применяетя к результату объединения.
Пример:
Вывести цены на компьютеры и ноутбуки, а также их номера (т.е. произвести выгрузку из двух разных таблиц в одном запросе)
Решение:
| 1 2 3 4 5 6 |
SELECT FROM SELECT FROM |
SELECT `Номер` , `Цена`
FROM pc
UNION
SELECT `Номер` , `Цена`
FROM notebook
ORDER BY `Цена`
Результат:
Рассмотрим более сложный пример с объединением inner join:
Пример:
Найти тип продукции, номер и цену компьютеров и ноутбуков
Решение:
| 1 2 3 4 5 6 7 8 |
SELECT FROM UNION SELECT FROM ORDER |
SELECT product.`Тип` , pc.`Номер` , `Цена`
FROM pc
INNER JOIN product ON pc.`Номер` = product.`Номер`
UNION
SELECT product.`Тип` , notebook.`Номер` , `Цена`
FROM notebook
INNER JOIN product ON notebook.`Номер` = product.`Номер`
ORDER BY `Цена`
Результат:
SQL Union 1.
Найти производителя, номер и цену всех ноутбуков и принтеров
SQL Union 2.
Найти номера и цены всех продуктов, выпущенных производителем Россия
Demo Database
In this tutorial we will use the well-known Northwind sample database.
Below is a selection from the «Customers» table:
| CustomerID | CustomerName | ContactName | Address | City | PostalCode | Country |
|---|---|---|---|---|---|---|
| 1 | Alfreds Futterkiste | Maria Anders | Obere Str. 57 | Berlin | 12209 | Germany |
| 2 | Ana Trujillo Emparedados y helados | Ana Trujillo | Avda. de la Constitución 2222 | México D.F. | 05021 | Mexico |
| 3 | Antonio Moreno Taquería | Antonio Moreno | Mataderos 2312 | México D.F. | 05023 | Mexico |
And a selection from the «Suppliers» table:
| SupplierID | SupplierName | ContactName | Address | City | PostalCode | Country |
|---|---|---|---|---|---|---|
| 1 | Exotic Liquid | Charlotte Cooper | 49 Gilbert St. | London | EC1 4SD | UK |
| 2 | New Orleans Cajun Delights | Shelley Burke | P.O. Box 78934 | New Orleans | 70117 | USA |
| 3 | Grandma Kelly’s Homestead | Regina Murphy | 707 Oxford Rd. | Ann Arbor | 48104 | USA |
Example — Different Field Names
It is not necessary that the corresponding columns in each SELECT statement have the same name, but they do need to be the same corresponding data types.
When you don’t have the same column names between the SELECT statements, it gets a bit tricky, especially when you want to order the results of the query using the ORDER BY clause.
Let’s look at how to use the UNION ALL operator with different column names and order the query results.
For example:
SELECT supplier_id, supplier_name FROM suppliers WHERE supplier_id > 2000 UNION ALL SELECT company_id, company_name FROM companies WHERE company_id > 1000 ORDER BY 1;
In this SQL UNION ALL example, since the column names are different between the two SELECT statements, it is more advantageous to reference the columns in the ORDER BY clause by their position in the result set. In this example, we’ve sorted the results by supplier_id / company_id in ascending order, as denoted by the . The supplier_id / company_id fields are in position #1 in the result set.
Now, let’s explore this example further with data.
If you had the suppliers table populated with the following records:
| supplier_id | supplier_name |
|---|---|
| 1000 | Microsoft |
| 2000 | Oracle |
| 3000 | Apple |
| 4000 | Samsung |
And the companies table populated with the following records:
| company_id | company_name |
|---|---|
| 1000 | Microsoft |
| 3000 | Apple |
| 7000 | Sony |
| 8000 | IBM |
And you executed the following UNION ALL statement:
SELECT supplier_id, supplier_name FROM suppliers WHERE supplier_id > 2000 UNION ALL SELECT company_id, company_name FROM companies WHERE company_id > 1000 ORDER BY 1;
You would get the following results:
| supplier_id | supplier_name |
|---|---|
| 3000 | Apple |
| 3000 | Apple |
| 4000 | Samsung |
| 7000 | Sony |
| 8000 | IBM |
First, notice that the record with supplier_id of 3000 appears twice in the result set because the UNION ALL query returns all rows and does not remove duplicates.
Second, notice that the column headings in the result set are called supplier_id and supplier_name. This is because these were the column names used in the first SELECT statement in the UNION ALL.
If you had wanted to, you could have aliased the columns as follows:
SELECT supplier_id AS ID_Value, supplier_name AS Name_Value FROM suppliers WHERE supplier_id > 2000 UNION ALL SELECT company_id AS ID_Value, company_name AS Name_Value FROM companies WHERE company_id > 1000 ORDER BY 1;
Now the column headings in the result will be aliased as ID_Value for the first column and Name_Value for the second column.
| ID_Value | Name_Value |
|---|---|
| 3000 | Apple |
| 3000 | Apple |
| 4000 | Samsung |
| 7000 | Sony |
| 8000 | IBM |
UNION vs. UNION ALL Examples With Sort on Non-indexed Column
Here is another example doing the same thing, but this time doing a SORT on a
non indexed column. As you can see the execution plans are again identical for these
two queries, but this time instead of using a MERGE JOIN, a CONCATENATION and SORT
operations are used.
Next Steps
- Take a look at these other tips that may be useful for using the union operators
-
Comparing Multiple Datasets with the INTERSECT
and EXCEPT operators - SQL Server Four-part naming
-
Compare SQL Server Results of Two Queries using UNION
-
Comparing Multiple Datasets with the INTERSECT


Greg Robidoux is the President of Edgewood Solutions and a co-founder of MSSQLTips.com.
View all my tips
Related Resources
- SQL Server Join Example…
- Join SQL Server tables where columns include NULL …
- UNION vs. UNION ALL in SQL Server…
- Compare SQL Server Datasets with INTERSECT and EXC…
- SQL Server CROSS APPLY and OUTER APPLY…
- More Database Developer Tips…
Become a paid author
SQL References
SQL Keywords
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Functions
String Functions
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Numeric Functions
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Date Functions
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Advanced Functions
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server Functions
String Functions
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Numeric Functions
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Date Functions
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Advanced Functions
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access Functions
String Functions
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Numeric Functions
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Date Functions
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Other Functions
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL OperatorsSQL Data TypesSQL Quick Ref
DB2
Платформа DB2 поддерживает ключевые слова UNION и UNION ALL стандарта ANSI плюс предложение VALUES.
Позволяет указывать один или несколько наборов определяемых вручную значений для записей в объединенном результирующем наборе. Каждое из этих значений должно содержать в точности такое же число столбцов, как в запросах оператора UNION. Строки значений в результирующем наборе разделяются запятыми.
Хотя предложение UNION DISTINCT не поддерживается, функциональным эквивалентом является предложение UNION. Предложение CORRESPONDING не поддерживается.
С ключевым словом UNION нельзя использовать такие типы данных, как VARCHAR, LONG VARGRAPHIC, BLOB, CLOB, DBCLOB, DATALINK, и структурные типы (но их можно использовать с предложением UNION ALL).
Если во всех таблицах используется одно имя столбца, в результирующем наборе используется это имя. Если же имена столбцов различаются, то DB2 генерирует новое имя столбца. После этого этот столбец нельзя использовать в предложении ORDER BY или предложении FOR UPDATE.
Если в одном запросе используется несколько операторов для наборов данных, то первыми выполняются те, которые заключены в скобки. После этого операторы выполняются в порядке слева направо. Однако все операции INTERSECT выполняются до операций UNION или ЕХСЕРТ. Например:
SELECT empno
FROM employee
WHERE workdept LIKE «E%»
UNION
SELECT empno FROM emp_act
WHERE projno IN («IF1000», «IF2000», «AD3110»)
UNION
VALUES («AA0001), (AB0002»), («AC0003»)
В этом примере мы получаем все ID сотрудников из таблицы employee, которые состоят в любом департаменте, с названием, начинающимся с «Е», а также ID всех сотрудников из бухгалтерской таблицы emp_act, которые работают в проектах IF1000″, «IF2000», and «AD3110». Кроме того, сюда всегда включаются ID сотрудников «AA000T, «АВ0002», and «АС00031.
Пример — использование условия IN с символьными значениями
Условие IN может использоваться с любым типом данных в SQL. Давайте посмотрим, как использовать условие IN с символьными (строковыми) значениями. В этом примере у нас есть таблица suppliers со следующими данными:
| supplier_id | supplier_name | city | state |
|---|---|---|---|
| 100 | Yandex | Moscow | Russian |
| 200 | Lansing | Michigan | |
| 300 | Oracle | Redwood City | California |
| 400 | Bing | Redmond | Washington |
| 500 | Yahoo | Sunnyvale | Washington |
| 600 | DuckDuckGo | Paoli | Pennsylvania |
| 700 | Qwant | Paris | France |
| 800 | Menlo Park | California | |
| 900 | Electronic Arts | San Francisco | California |
Введите следующий SQL оператор:
PgSQL
SELECT *
FROM suppliers
WHERE supplier_name IN (‘Yandex’, ‘Oracle’, ‘Facebook’);
|
1 2 3 |
SELECT* FROMsuppliers WHEREsupplier_nameIN(‘Yandex’,’Oracle’,); |
Будет выбрано 3 записи. Вот результаты, которые вы должны получить:
| supplier_id | supplier_name | city | state |
|---|---|---|---|
| 100 | Yandex | Moscow | Russian |
| 300 | Oracle | Redwood City | California |
| 800 | Menlo Park | California |
В этом примере будут возвращены все строки из таблицы suppliers, где supplier_name — Yandex, Oracle или Facebook. Поскольку в SELECT используется , то все поля из таблицы suppliers будут отображаться в наборе результатов.
Это эквивалентно следующему оператору SQL:
PgSQL
SELECT *
FROM suppliers
WHERE supplier_name = ‘Yandex’
OR supplier_name = ‘Oracle’
OR supplier_name = ‘Facebook’;
|
1 2 3 4 5 |
SELECT* FROMsuppliers WHEREsupplier_name=’Yandex’ ORsupplier_name=’Oracle’ ORsupplier_name=; |
Как вы можете видеть, использование условия IN облегчает чтение оператора и делает его более эффективным, чем использование нескольких условий OR.
Правила использования
Существуют два основных правила, регламентирующие порядок использования оператора :
- Число и порядок извлекаемых столбцов должны совпадать во всех объединяемых запросах;
- Типы данных в соответствующих столбцах должны быть совместимы.
Определения столбцов, данные из которых извлекаются в объединяемых запросах, не должны совпадать, однако должны быть совместимыми путём неявного преобразования. Если типы данных различаются, то получившийся тип данных определяется на основе правил очередности типов данных (для конкретной СУБД). Если типы совпадают, но различаются в точности, масштабе или длине, результат определяется на основе правил, используемых для объединения выражений (для конкретной СУБД). Типы не определенные ANSI, такие как DATA и BINARY, обычно должны совпадать с другими столбцами такого же нестандартного типа.
В Microsoft SQL Server столбцы с типом данных XML должны быть эквивалентными. Все столбцы должны либо иметь тип, определенный в XML-схеме, либо быть нетипизированными. Типизированные столбцы должны относиться к одной и той же коллекции XML-схем.
Ещё одно ограничение на совместимость — это запрет пустых значений (NULL) в любом столбце объединения, причем эти значения необходимо запретить и для всех соответствующих столбцов в других запросах объединения, поскольку пустые значения (NULL) запрещены с ограничением NOT NULL. Кроме того, нельзя использовать UNION в подзапросах, а также нельзя использовать агрегатные функции в предложении SELECT запроса в объединении (однако большинство СУБД пренебрегают этими ограничениями).
Frequently Asked Questions
Question: I need to compare two dates and return the count of a field based on the date values. For example, I have a date field in a table called last updated date. I have to check if trunc(last_updated_date >= trunc(sysdate-13).
Answer: Since you are using the COUNT function which is an aggregate function, we’d recommend using the Oracle UNION operator. For example, you could try the following:
SELECT a.code AS Code, a.name AS Name, COUNT(b.Ncode) FROM cdmaster a, nmmaster b WHERE a.code = b.code AND a.status = 1 AND b.status = 1 AND b.Ncode <> 'a10' AND TRUNC(last_updated_date) <= TRUNC(sysdate-13) GROUP BY a.code, a.name UNION SELECT a.code AS Code, a.name AS Name, COUNT(b.Ncode) FROM cdmaster a, nmmaster b WHERE a.code = b.code AND a.status = 1 AND b.status = 1 AND b.Ncode <> 'a10' AND TRUNC(last_updated_date) > TRUNC(sysdate-13) GROUP BY a.code, a.name;
The Oracle UNION allows you to perform a count based on one set of criteria.
TRUNC(last_updated_date) <= TRUNC(sysdate-13)
As well as perform a count based on another set of criteria.
TRUNC(last_updated_date) > TRUNC(sysdate-13)
Функция SQL Replace
Синтаксис:
SELECT `name` , REPLACE(`name` , «а», «аа»)
FROM `teachers`
Я уже писал о . И там вывод одной таблицы зависил от содержимого другой. Но бывает нужно, когда требуется полная независимость вывода одной таблицы от другой. Всё, что хочется — это просто в одном запросе вытащить записи сразу из нескольких таблиц
, не более того. И вот для этого используется в SQL ключевое слово UNION
.
Давайте с Вами разберём SQL-запрос с использованием UNION
:
SELECT `login`, `amount` FROM `employers` UNION SELECT `login`, `amount` FROM `staff`;
Данный запрос вернёт логины и суммы на счетах всех работодателей и сотрудников некоего сайта. То есть данные были в разных таблицах, но их схожесть позволяет вывести их сразу. Отсюда, кстати, идёт правило использования UNION-запросов
: число и порядок полей должно совпадать во всех частях запроса.
Таких UNION-частей
может быть очень много, но самое главное после последнего UNION надо обязательно поставить точку с запятой
.
Ещё одной хорошей особенностью UNION
является отсутствие повторений. Например, если один и тот же человек находится и среди сотрудников, и среди работодателей, разумеется, с той же самой суммой на счету, то в выборке он будет не 2 раза, а только 1
, что, как правило, и требуется. А если всё-таки нужны повторения, то тогда есть UNION ALL
:
SELECT `login`, `amount` FROM `employers` UNION ALL SELECT `login`, `amount` FROM `staff`;
Вот так используется достаточно простой оператор UNION в SQL-запросе
, упрощающий процедуру вывода сразу из множества таблиц однотипных данных, что в свою очередь очень хорошо скажется на производительности.
Примеры
Использование UNION при выборке из двух таблиц
Даны две таблицы:
| person | amount |
|---|---|
| Иван | 1000 |
| Алексей | 2000 |
| Сергей | 5000 |
| person | amount |
|---|---|
| Иван | 2000 |
| Алексей | 2000 |
| Петр | 35000 |
При выполнении следующего запроса:
(SELECT * FROM sales2005) UNION (SELECT * FROM sales2006);
получается результирующий набор, однако порядок строк может произвольно меняться, поскольку ключевое выражение не было использовано:
| person | amount |
|---|---|
| Иван | 1000 |
| Алексей | 2000 |
| Иван | 2000 |
| Сергей | 5000 |
| Петр | 35000 |
В результате отобразятся две строки с Иваном, так как эти строки различаются значениями в столбцах. Но при этом в результате присутствует лишь одна строка с Алексеем, поскольку значения в столбцах полностью совпадают.
Использование UNION ALL при выборке из двух таблиц
Применение дает другой результат, так как дубликаты не скрываются. Выполнение запроса:
(SELECT * FROM sales2005) UNION ALL (SELECT * FROM sales2006);
даст следующий результат, выводимый без упорядочивания ввиду отсутствия выражения :
| person | amount |
|---|---|
| Иван | 1000 |
| Иван | 2000 |
| Алексей | 2000 |
| Алексей | 2000 |
| Сергей | 5000 |
| Петр | 35000 |
Использование UNION при выборке из одной таблицы
Аналогичным образом можно объединять два разных запроса из одной и той же таблицы (хотя вместо этого, как правило, необходимые параметры комбинируют в одном запросе при помощи ключевых слов AND и OR в условии WHERE):
(SELECT person, amount FROM sales2005 WHERE amount=1000) UNION (SELECT person, amount FROM sales2005 WHERE person like 'Сергей');
В результате получится:
| person | amount |
|---|---|
| Иван | 1000 |
| Сергей | 5000 |
Использование UNION как внешнее объединение
При помощи можно создавать также (иногда используется в случае отсутствия встроенной прямой поддержки внешних объединений):
(SELECT *
FROM employee
LEFT JOIN department
ON employee.DepartmentID = department.DepartmentID)
UNION
(SELECT *
FROM employee
RIGHT JOIN department
ON employee.DepartmentID = department.DepartmentID);
Но при этом необходимо помнить, что это все же не одно и то же, что и оператор .
Синтаксис
Синтаксис SQL оператора INSERT при вставке одной записи в таблицу:
INSERT INTO table (column1, column2, … ) VALUES (expression1, expression2, … );
Или синтаксис SQL оператора INSERT при вставке нескольких записей в таблицу:
INSERT INTO table (column1, column2, … ) SELECT expression1, expression2, … FROM source_tables ;
Параметры или аргументы
- table
- Таблица, в которую нужно вставить записи.
- column1, column2
- Это столбцы в table для вставки значений.
- expression1, expression2
- Эти значения присваиваются столбцам в таблице. Поэтому column1 будет присвоено значение expression1, column2 будет присвоено значение expression2 и т.д. ,
- source_tables
- Используется при вставке записей из другой таблицы. Это исходная таблица при выполнении вставки.
- WHERE conditions
- Необязательный. Используется при вставке записей из другой таблицы. Это те условия, которые должны быть соблюдены для вставки записей.