Sql foreign key ограничение
Содержание:
- SQL Учебник
- Модель данных “ключ-значение” и документная модель
- Ссылочная целостность
- Тестирование
- Добавить уникальное ограничение
- Первичный ключ
- Составной ключ (composite key)
- Связи между отношениями
- SQL Справочник
- Внешние ключи FOREIGN KEY
- Что такое внешний ключ?
- Определение
- Внешний ключ и целостность данных в БД
- Ключи
- Типы данных в базах
- Отношение один к одному
- Выводы
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
Модель данных “ключ-значение” и документная модель
Ранее мы говорили о том, что базы данных типа “ключ—значение” и документные базы данных являются сильно агрегатно-ориентированными. Мы имели в виду, что эти базы данных в основном были сконструированы из агрегатов. Базы данных обоих типов состоят из множества агрегатов, каждый из которых имеет ключ или идентификатор, который используется для доступа к данным.
Эти две модели отличаются друг от друга тем, что в базе данных “ключ- значение” агрегат является непроницаемым для базы данных — просто большой черный ящик, состоящий из преимущественно бессмысленных битов. В противоположность этому документная база может видеть структуру агрегата. Преимущество непрозрачности заключается в том, что в агрегате можно хранить все что угодно. База данных может ограничивать общий размер агрегата, но в остальном мы имеем полную свободу. Документная база данных накладывает ограничения на то, что можно хранить в агрегате, определяя допустимые структуры и типы. Однако за это мы получаем большую гибкость доступа. В хранилище типа “ключ-значение” мы можем просматривать агрегат только с помощью его ключа. В документной базе данных мы можем посылать базе данных запросы, касающиеся полей в агрегате, извлекать части агрегата, а не весь агрегат целиком, причем база данных может создавать индексы с учетом содержимого агрегата. На практике разделительная линия между базами данных типа “ключ-значение” и документными базами данных довольна расплывчата. Люди часто записывают идентификаторы в документные базы данных, чтобы выполнять поиск в стиле “ключ-значение”. Базы данных, классифицированные как базы типа “ключ-значение”, могут предлагать новые структуры для данных, помимо непрозрачных агрегатов. Например, база данных Riak позволяет добавлять метаданные к агрегатам для индексирования и установления связей между агрегатами, a Redis позволяет разбивать агрегаты на списки или множества. Кроме того, можно обеспечить механизм запросов с помощью интегрированных средств поиска, как в базе данных Solr. Например, поисковый механизм базы данных Riak, аналогичный поисковому механизму базы Solr, выполняет поиск агрегатов, хранящихся в виде структур JSON или XML.
Несмотря на такое нечеткое разделение, эти две категории в целом отличаются друг от друга. Базы данных типа “ключ—значение”, как правило, выполняют поиск агрегатов по ключу. В документных базах данных пользователь должен подать запрос, основанный на внутренней структуре документа; это может быть ключ, но, скорее всего, это будет нечто другое.
Ссылочная целостность
Первое из правил ссылочной целостности фактически уже изложено в предыдущем абзаце: в таблице не допускается появления (неважно, при добавлении или при модификации) строк, внешний ключ которых не совпадает с каким-либо из имеющихся значений родительского ключа. Более интересные моменты возникают, когда мы удаляем или изменяем строки родительской таблицы
Как при этом не допустить появления \»болтающихся в воздухе\» строк дочерней таблицы? Для этого существуют правила ссылочной целостности ON UPDATE и ON DELETE, которые, по стандарту SQL 92, могут содержать следующие инструкции:
Более интересные моменты возникают, когда мы удаляем или изменяем строки родительской таблицы. Как при этом не допустить появления \»болтающихся в воздухе\» строк дочерней таблицы? Для этого существуют правила ссылочной целостности ON UPDATE и ON DELETE, которые, по стандарту SQL 92, могут содержать следующие инструкции:
- CASCADE — обеспечивает автоматическое выполнение в дочерней таблице тех же изменений, которые были сделаны в родительском ключе. Если родительский ключ был изменен — ON UPDATE CASCADE обеспечит точно такие же изменения внешнего ключа в дочерней таблице. Если строка родительской таблицы была удалена, ON DELETE CASCADE обеспечит удаление всех соответствующих строк дочерней таблицы.
- SET NULL — при удалении строки родительской таблицы ON DELETE SET NULL установит значение NULL во всех столбцах вторичного ключа в соответствующих строках дочерней таблицы. При изменении родительского ключа ON UPDATE SET NULL установит значение NULL в соответствующих столбцах соответствующих строк (о как:) дочерней таблицы.
- SET DEFAULT — работает аналогично SET NULL, только записывает в соответствующие ячейки не NULL, а значения, установленные по умолчанию.
- NO ACTION (установлено по умолчанию) — при изменении родительского ключа никаких действий с внешним ключом в дочерней таблице не производится. Но если изменение значений родительского ключа приводит к нарушению ссылочной целосности (т.е. к появлению «висящих в воздухе» строк дочерней таблицы), то СУБД не даст произвести такие изменения родительской таблицы.
Ну а сейчас — от общего к частному.
Тестирование
этой ссылке
- Всего три серии тестов с длиной текстового поля в записи 80, 800 и 8000 байт соответственно (количество символов в тестовой программе будет в два раза меньше в каждом из случаев, так как один символ в NVARCHAR занимает два байта).
- В каждой из серий — по 5 запусков, каждый из которых добавляет по 10000 записей в каждую из таблиц. По результатам каждого из запусков можно будет проследить зависимость времени вставки от количества строк, уже находящихся в таблице.
- Перед началом каждой из серий таблицы полностью очищаются.
- Использование генерации GUID на стороне базы данных в разы медленнее, чем генерации на стороне клиента. Это связано с затратами на чтение только что добавленного идентификатора. Детали этой проблемы рассмотрены в конце статьи.
- Вставка записей с автоинкрементным ключом даже немного медленнее, чем с GUID-ом, присвоенным на клиенте.
- Разницы между последовательным и непоследовательным GUID практически не видно на небольших записях. На больших записях разница появляется с ростом количества строк в таблице, но она не выглядит существенной.
Добавить уникальное ограничение
Если ваша таблица уже существует и вы хотите добавить уникальное ограничение позже, вы не можете использовать оператор ALTER TABLE, чтобы добавить уникальное ограничение. Вместо этого вы должны создать новую таблицу с уникальным ограничением и скопировать данные в эту новую таблицу.
Синтаксис
Синтаксис для добавления уникального ограничения к таблице в SQLite:
PRAGMA foreign_keys=off;
BEGIN TRANSACTION;
ALTER TABLE table_name RENAME TO old_table;
CREATE TABLE table_name ( column1 datatype , column2 datatype , … CONSTRAINT constraint_name UNIQUE (uc_col1, uc_col2, … uc_col_n) );
INSERT INTO table_name SELECT * FROM old_table;
COMMIT;
PRAGMA foreign_keys=on;
table_name Имя таблицы для изменения. Это таблица, к которой вы хотите добавить уникальное ограничение.
old_table Название оригинальной таблицы. Оно останется после того, как вы создадите новую таблицу с добавленным уникальным ограничением.
constraint_name Имя уникального ограничения.
uc_col1, uc_col2, … uc_col_n Столбцы, которые составляют уникальное ограничение.
Пример
Рассмотрим пример того, как добавить уникальное ограничение к существующей таблице в SQLite. Скажем так, у нас уже есть таблица products со следующим определением:
PgSQL
CREATE TABLE products
( product_id INTEGER PRIMARY KEY AUTOINCREMENT,
product_name VARCHAR NOT NULL,
quantity INTEGER NOT NULL DEFAULT 0
);
|
1 2 3 4 5 |
CREATETABLEproducts product_nameVARCHARNOT NULL, quantityINTEGERNOT NULLDEFAULT0 |
И мы хотели добавить уникальное ограничение в таблицу products, которая состоит из product_name. Мы могли бы запустить следующие команды:
PgSQL
PRAGMA foreign_keys=off;
BEGIN TRANSACTION;
ALTER TABLE products RENAME TO old_products;
CREATE TABLE products
( product_id INTEGER PRIMARY KEY AUTOINCREMENT,
product_name VARCHAR NOT NULL,
quantity INTEGER NOT NULL DEFAULT 0,
CONSTRAINT product_name_unique UNIQUE (product_name)
);
INSERT INTO products SELECT * FROM old_products;
COMMIT;
PRAGMA foreign_keys=on;
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
PRAGMAforeign_keys=off; BEGINTRANSACTION; ALTERTABLEproductsRENAMETOold_products; CREATETABLEproducts product_nameVARCHARNOT NULL, quantityINTEGERNOT NULLDEFAULT0, CONSTRAINTproduct_name_uniqueUNIQUE(product_name) INSERTINTOproductsSELECT*FROMold_products; COMMIT; |
В этом примере мы создали уникальное ограничение для таблицы products с именем product_name_unique, которое состоит из столбца product_name. Исходная таблица все еще будет существовать в базе данных с именем old_products. Вы можете удалить таблицу old_products после того, как убедитесь, что таблица products и данные соответствуют ожиданиям.
PgSQL
DROP TABLE old_products;
| 1 | DROPTABLEold_products; |
Первичный ключ
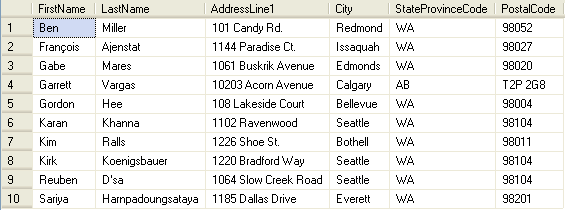
Столбец, который в базе данных должен быть уникальным помечают первичным ключом. Первичный ключ или primary key означает, что в таблице значение колонки primary key не может повторяться. Таким образом данный ключ позволяет однозначно идентифицировать запись в таблице не боясь при этом, что значение столбца повториться. Сразу пример: допустим у Вас есть таблица пользователей. В данной таблице есть поля: ФИО, год рождения, телефон. Как идентифицировать пользователя? Таким параметрам как ФИО и телефон доверять нельзя. Ведь у нас может быть несколько пользователей не только с одинаковой фамилией, но и с именем. Телефон может меняться со временем и пользователь с номером телефона может оказаться не тем кто у нас в базе данных.
Вот для этого и придумали первичный ключ. Один раз присвоили уникальный идентификатор и все. В mySql на примере которой мы выполняем все примеры из цикла статей по SQL поле AUTO_INCREMENT нельзя задать если не указать, что это первичный ключ.
К стати, в предыдущей теме мы уже познакомились с первичным ключом: что это такое и как его создавать. Синтаксис по созданию этого ключа Вы найдете в статье Создание, изменение, удаление таблиц SQL.
Думаю, что не стоит упоминать, что поле помеченное как первичный ключ не может быть пустым при создании записи.
Составной ключ (composite key)
Что касается составного ключа — это несколько первичных ключей в таблице. Таким образом, создав composite key, уникальность записи будет проверяться по полям, которые объединенные в этот ключ.
Бывают ситуации, когда при вставке в таблицу нужно проверять запись на уникальность сразу по нескольким полям. Вот для этого и придуман составной ключ. Для примера я создам простую таблицу с composite key, чтобы показать синтаксис:
create table test(field_1 int, field_2 text, field_3 bigint, primary key (field_1, field_3));
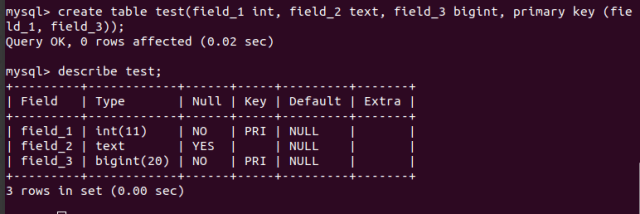
В примере выше два поля объединенные в составной ключ и в таблице не будет записей с этими одинаковыми полями.
Это все, что касается ключей в SQL. Это небольшое пособие — подготовка к статье связи sql где мы подробно рассмотрим как объединять таблицы, чтобы они составляли единую базу данных.
Связи между отношениями
Итак, первичный ключ в базе данных – это один или несколько столбцов таблицы, позволяющий однозначно идентифицировать строку этого отношения. Для чего же он нужен?
Вернемся к первому примеру с отношением «Студенты». В базе данных, кроме этого отношения, хранится и другая информация, например, успеваемость каждого учащегося. Чтобы не повторять всю информацию, что уже содержится в БД, пользуются ключом, ссылаясь на нужную запись. Это выглядит так.
В двух отношениях примера мы видим поле ID. Это первичные ключи в базе данных для этих таблиц. Как видим, в успеваемости содержатся только ссылки на эти поля из других таблиц без необходимости указывать всю информацию из них.
SQL Справочник
SQL Ключевые слова
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Функции
Функции строк
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Функции дат
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Функции расширений
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server функции
Функции строк
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Функции дат
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Функции расширений
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access функции
Функции строк
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Функции чисел
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Функции дат
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Другие функции
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL ОператорыSQL Типы данныхSQL Краткий справочник
Внешние ключи FOREIGN KEY
Последнее обновление: 27.04.2019
Внешние ключи позволяют установить связи между таблицами. Внешний ключ устанавливается для столбцов из зависимой, подчиненной таблицы, и
указывает на один из столбцов из главной таблицы. Как правило, внешний ключ указывает на первичный ключ из связанной главной таблицы.
Общий синтаксис установки внешнего ключа на уровне таблицы:
FOREIGN KEY (столбец1, столбец2, ... столбецN) REFERENCES главная_таблица (столбец_главной_таблицы1, столбец_главной_таблицы2, ... столбец_главной_таблицыN)
Для создания ограничения внешнего ключа после FOREIGN KEY указывается столбец таблицы, который будет представляет
внешний ключ. А после ключевого слова REFERENCES указывается имя
связанной таблицы, а затем в скобках имя связанного столбца, на который будет указывать внешний ключ. После выражения REFERENCES
идут выражения ON DELETE и ON UPDATE, которые задают действие при удалении и обновлении строки из
главной таблицы соответственно.
Например, определим две таблицы и свяжем их посредством внешнего ключа:
CREATE TABLE Customers
(
Id INT PRIMARY KEY AUTO_INCREMENT,
Age INT,
FirstName VARCHAR(20) NOT NULL,
LastName VARCHAR(20) NOT NULL,
Phone VARCHAR(20) NOT NULL UNIQUE
);
CREATE TABLE Orders
(
Id INT PRIMARY KEY AUTO_INCREMENT,
CustomerId INT,
CreatedAt Date,
FOREIGN KEY (CustomerId) REFERENCES Customers (Id)
);
В данном случае определены таблицы Customers и Orders. Customers является главной и представляет клиента. Orders является зависимой и
представляет заказ, сделанный клиентом. Таблица Orders через столбец CustomerId связана с таблицей Customers и ее столбцом Id. То есть столбец
CustomerId является внешним ключом, который указывает на столбец Id из таблицы Customers.
С помощью оператора CONSTRAINT можно задать имя для ограничения внешнего ключа:
CREATE TABLE Orders
(
Id INT PRIMARY KEY AUTO_INCREMENT,
CustomerId INT,
CreatedAt Date,
CONSTRAINT orders_custonmers_fk
FOREIGN KEY (CustomerId) REFERENCES Customers (Id)
);
ON DELETE и ON UPDATE
С помощью выражений ON DELETE и ON UPDATE можно установить действия, которые выполняются
соответственно при удалении и изменении связанной строки из главной таблицы. В качестве действия могут использоваться следующие опции:
-
CASCADE: автоматически удаляет или изменяет строки из зависимой таблицы при удалении или изменении связанных строк в главной таблице.
-
SET NULL: при удалении или обновлении связанной строки из главной таблицы устанавливает для столбца внешнего ключа
значение NULL. (В этом случае столбец внешнего ключа должен поддерживать установку NULL) -
RESTRICT: отклоняет удаление или изменение строк в главной таблице при наличии связанных строк в зависимой таблице.
-
NO ACTION: то же самое, что и .
-
SET DEFAULT: при удалении связанной строки из главной таблицы устанавливает для столбца внешнего ключа значение по
умолчанию, которое задается с помощью атрибуты DEFAULT. Несмотря на то, что данная опция в принципе доступна, однако движок InnoDB не поддерживает данное выражение.
Каскадное удаление
Каскадное удаление позволяет при удалении строки из главной таблицы автоматически удалить все связанные строки из зависимой таблицы.
Для этого применяется опция CASCADE:
CREATE TABLE Orders
(
Id INT PRIMARY KEY AUTO_INCREMENT,
CustomerId INT,
CreatedAt Date,
FOREIGN KEY (CustomerId) REFERENCES Customers (Id) ON DELETE CASCADE
);
Подобным образом работает и выражение ON UPDATE CASCADE. При изменении значения первичного ключа автоматически изменится
значение связанного с ним внешнего ключа. Однако поскольку первичные ключи изменяются очень редко, да и с принципе не рекомендуется использовать в
качестве первичных ключей столбцы с изменяемыми значениями, то на практике выражение ON UPDATE используется редко.
Установка NULL
При установки для внешнего ключа опции SET NULL необходимо, чтобы столбец внешнего ключа допускал значение NULL:
CREATE TABLE Orders
(
Id INT PRIMARY KEY AUTO_INCREMENT,
CustomerId INT,
CreatedAt Date,
FOREIGN KEY (CustomerId) REFERENCES Customers (Id) ON DELETE SET NULL
);
НазадВперед
Что такое внешний ключ?
Внешний ключ относится к полю или коллекции полей в записи базы данных, которая однозначно идентифицирует ключевое поле другой записи базы данных в другой таблице. Проще говоря, он устанавливает связь между записями в двух разных таблицах в базе данных. Это может быть столбец в таблице, который указывает на столбцы первичного ключа, что означает, что внешний ключ, определенный в таблице, относится к первичному ключу какой-либо другой таблицы. Ссылки имеют решающее значение в реляционных базах данных для установления связей между записями, которые необходимы для сортировки баз данных. Внешние ключи играют важную роль в нормализации реляционных баз данных, особенно когда таблицы нуждаются в доступе к другим таблицам.
Определение
Связи между данными, хранимыми в разных отношениях, в реляционной БД устанавливаются с помощью использования внешних ключей — для установления связи между кортежем из отношения A с определённым кортежем отношения B в предусмотренные для этого атрибуты кортежа отношения A записывается значение первичного ключа (а в общем случае значение потенциального ключа) целевого кортежа отношения B. Таким образом, всегда имеется возможность выполнить две операции:
- определить, с каким кортежем в отношении B связан определённый кортеж отношения A;
- найти все кортежи отношения A, имеющие связи с определённым кортежем отношения B.
Благодаря наличию связей в реляционной БД можно хранить факты без избыточного дублирования, то есть в нормализованном виде. Ссылочная целостность может быть проиллюстрирована следующим образом:
База данных обладает свойством ссылочной целостности, когда для любой пары связанных внешним ключом отношений в ней условие ссылочной целостности выполняется.
Если вышеприведённое условие не выполняется, говорят, что в базе данных нарушена ссылочная целостность. Такая БД не может нормально эксплуатироваться, так как в ней разорваны логические связи между зависимыми друг от друга фактами. Непосредственным результатом нарушения ссылочной целостности становится то, что корректным запросом не всегда удаётся получить корректный результат.
Внешний ключ и целостность данных в БД
Все вышеизложенное приводит нас к внешнему ключу (Foreign key) и целостности БД. Foreign key – это поле, ссылающееся на Primary key внешнего отношения. В таблице успеваемости это столбцы «Студент» и «Дисциплина». Их данные отсылают нас к внешним таблицам. То есть поле «Студент» в отношении «Успеваемость» — это Foreign key, а в отношении «Студент» это первичный ключ в базе данных.
Важным принципом построения баз данных является их целостность. И одно из ее правил – целостность по ссылкам. Это значит, что внешний ключ таблицы не может ссылаться на несуществующий Primary key другого отношения. Нельзя удалить из отношения «Студент» запись с кодом 1000 – Иванов Иван, если на нее ссылается запись из таблицы успеваемости. В правильно построенной БД при попытке удаления вы получите ошибку, что это поле используется.
Существуют и другие группы правил целостности, а также другие ограничения баз данных, которые также заслуживают внимания и должны быть учтены разработчиками.
Ключи
Последнее обновление: 02.07.2017
Ключи представляют способ идентификации строк в таблице. С помощью ключей мы также можем связывать строки между различными таблицами в отношения.
Суперключ
Superkey (суперключ) — комбинация атрибутов (столбцов), которые уникально идентифицируют каждую строку таблицы. Это могут быть и все столбцы, и
несколько и и один. При этом строки, которые содержат значения этих атрибутов, не должны повторяться.
Например, у нас есть сущность Student, которая представляет данные о пользователях и которая имеет следующие атрибуты:
-
FirstName (имя)
-
LastName (фамилия)
-
Year (год рождения)
-
Phone (номер телефона)
Какие атрибуты в данном случае могут составлять суперключ:
-
{FirstName, LastName, Year, Phone}
-
{FirstName, Year, Phone}
-
{LastName, Year, Phone}
-
{FirstName, Phone}
-
{LastName, Phone}
-
{Year, Phone}
-
{Phone}
Каждого студента уникально может идентифицировать телефонный номер, поэтому любые наборы, в которых встречается атрибут Phone, представляют суперключ.
А вот, к примеру, набор не является суперключом, так как у нас теоретически могут быть как минимум
два студента с одинаковыми именем, фамилией и годом рождения.
Потенциальный ключ
Candidate key (потенциальный ключ) — представляет собой минимальный суперключ отношения (таблицы), то есть набор атрибутов, который удовлетворяет ряду условий:
-
Неприводимость: он не может быть сокращен, он содержит минимально возможный набор атрибутов
-
Уникальность: он должен иметь уникальные значения вне зависимости от изменения строки
-
Наличие значения: он не должен иметь значения NULL, то есть он обязательно должен иметь значение.
Возьмем ранее выделенные суперключи и найдем среди них candidate key. Первый пять суперключей не соответствуют первому условию, так как все их можно сократить до суперключа {Phone}:
-
{FirstName, LastName, Year, Phone}
-
{FirstName, Year, Phone}
-
{LastName, Year, Phone}
-
{FirstName, Phone}
-
{LastName, Phone}
-
{Year, Phone}
Суперключ {Phone} соответствует первому и второму условию, так как он имеет уникальное значение (в данном случае все пользователи могут иметь только уникальные телефонные номера). Но соответствует ли он третьему условию?
В целом нет, так как теоретически студент может и не иметь телефона. В этом случае атрибут Phone будет иметь значение NULL, то есть значение
будет отсутствовать.
В то же время это может зависеть от ситуации. Если в какой-то систему номер телефона является неотъемлемым атрибутом, например, используется для регистрации и входа в систему, то его можно считать потенциальным ключом. Но
в данном случае мы рассматриваем общую ситуацию. И для понимания потенциального ключа необходимо отталкиваться от конкретной системы, которую описывает база данных.
И в таком случае суперключи таблицы не содержат потенциального ключа.
Первичный ключ
Первичный ключ (primary key) непосредственно применяется для идентификации строк в таблице. Он должен соответствовать следующим ограничениям:
-
Первичный ключ должен быть уникальным все время
-
Он должен постоянно присутствовать в таблице и иметь значение
-
Он не должен часто менять свое значение. В идеале он вообще не должен изменять значение.
Как правило, первичный ключ представляет один столбец таблицы, но также может быть составным и состоять из нескольких столбцов.
Если для таблицы можно выделить потенциальный ключ, то его можно использовать в качестве первичного ключа.
Если же потенциальные ключи отсутствуют, то для первичного ключа можно добавить к сущности специальный атрибут, который, как правило, называется, Id или
имеет форму Id (например, StudentId), либо может иметь другое название. И обычно данный атрибут принимает целочисленное значение, начиная с 1.
Если же у нас есть несколько потенциальных ключей, то те потенциальные ключи, которые не составляют первичный ключ, являются альтернативными ключами
(alternative key).
Например, возьмем представление пользователей на сайтах с двухфакторной авторизацией, где нам обязательно иметь электронный адрес, который нередко выступает в качестве
логина, и какой-нибудь номер телефона. В этом случае таблицу пользователей мы можем задать с помощью следующих атрибутов:
-
Name (имя пользователя)
-
Password (пароль)
-
Phone (телефонный номер)
НазадВперед
Типы данных в базах
Важно понимать, что можно создавать базы для любых типов данных: текстов, дат, времени, событий, цифр. В зависимости от типа информации реляционные базы данных делят на типы
Каждый тип данных (атрибут) имеет свое обозначение:
- INTEGER- данные из целых чисел;
- FLOAT — данные из дробных чисел, так называемые данные с плавающей точкой;
- CHAR, VARCHAR — текстовые типы данных (символьные);
- LOGICAL — логический тип данных (да/нет);
- DATE/TIME — временные данные.
Это основные типы данных, которых на самом деле гораздо больше. Причем, каждый язык программирования имеет свой набор системных атрибутов (типов данных).
Отношение один к одному
Пока что мы рассмотрели классическую связь, когда одной строке основной таблицы данных соответствует одна строка из связанной таблицы. Такая связь называется один ко многим. Но существуют и другие связи, и сейчас мы рассмотрим еще одну – один к одному, когда одна запись основной таблице связана с одной записью другой. Чтобы это реализовать, достаточно связать первичные ключи обеих таблиц. Так как первичные ключи не могут повторяться, то в обеих таблицах связанными могут быть только одна строка.
Следующий пример создает две таблицы, у которых создана связь между первичными ключами:
CREATE TABLE Names ( idName uniqueidentifier DEFAULT NEWID(), vcName varchar(50), CONSTRAINT PK_guid PRIMARY KEY (idName) ) CREATE TABLE Phones ( idPhone uniqueidentifier DEFAULT NEWID(), vcPhone varchar(10), CONSTRAINT PK_idPhone PRIMARY KEY (idPhone), CONSTRAINT FK_idPhone FOREIGN KEY (idPhone) REFERENCES Names (idName) )
Внешний ключ нужен только у одной из таблиц. Так как связь идет один к одному, то не имеет значения, в какой таблице создать его.
Выводы
- Если по каким-либо критериям, указанным в начале статьи, возникла надобность использовать GUID в качестве первичного ключа — наилучшим вариантом в плане производительности будет последовательный GUID, сгенерированный для каждой записи на клиенте.
- Если создание GUID на клиенте по каким-либо причинам неприемлемо — можно воспользоваться генерацией идентификатора на стороне базы через NEWSEQUENTIALID(). Entity Framework делает это по умолчанию для GUID ключей, генерируемых на стороне базы. Но следует учесть, что производительность вставки будет заметно меньше по сравнению с созданием идентификатора на стороне клиента. Для проектов, где количество вставок в таблицы невелико, эта разница не будет критична. Еще, скорее всего, этот оверхед можно избежать в сценариях, где не нужно сразу же получать идентификатор вставленной записи, но такое решение не будет универсальным.
- Если в вашем проекте уже используются непоследовательные GUID, то следует задуматься об исправлении, если количество вставок в таблицы велико и размер базы значительно больше, чем размер доступной оперативной памяти.
- У других СУБД разница в производительности может быть совершенно другой, поэтому полученные результаты можно рассматривать только применительно к Microsoft SQL Server. В то время как базовые критерии, указанные в начале статьи, справедливы независимо от конкретной СУБД.